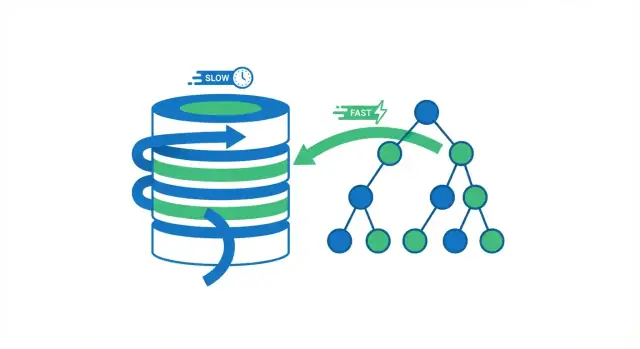
डाटाबेस इंडेक्सिंग वास्तव में क्या करती है
डाटाबेस इंडेक्स एक अलग लुकअप संरचना है जो डेटाबेस को पंक्तियाँ तेज़ी से खोजने में मदद करती है। यह आपकी तालिका की दूसरी प्रति नहीं है। इसे एक किताब के इंडेक्स पृष्ठों की तरह समझें: आप इंडेक्स का उपयोग करके सही जगह के पास कूदते हैं, फिर वह सटीक पृष्ठ (पंक्ति) पढ़ते हैं जिसकी आपको ज़रूरत है।
इंडेक्स के बिना, डेटाबेस के पास अक्सर एक ही सुरक्षित विकल्प बचता है: कई पंक्तियों को पढ़ना और यह जांचना कि कौन‑सी आपकी क्वेरी से मेल खाती हैं। छोटे तालिकाओं पर यह ठीक हो सकता है। जैसे‑जैसे तालिका लाखों पंक्तियों तक बढ़ती है, “ज़्यादा पंक्तियाँ जांचो” का मतलब और अधिक डिस्क रीड, अधिक मेमोरी दबाव और अधिक CPU काम होता है—इसलिए वही क्वेरी जो पहले त्वरित लगती थी, अब धीमी लगने लगती है।
इंडेक्स क्या बदलता है (और क्या नहीं)
इंडेक्स उस डेटा की मात्रा को घटाते हैं जिसे डेटाबेस को आपके प्रश्नों का उत्तर देने के लिए जांचनी पड़ती है, जैसे “ID 123 वाला ऑर्डर ढूँढो” या “इस ईमेल वाले यूज़र लाओ।” सब कुछ स्कैन करने के बजाय, डेटाबेस पहले एक संकुचित संरचना को देखता है जो खोज को तीव्रता से संकुचित कर देता है।
लेकिन इंडेक्सिंग सार्वभौमिक समाधान नहीं है। कुछ क्वेरियों को अभी भी बहुत सारी पंक्तियाँ प्रोसेस करनी पड़ती हैं (बड़े रिपोर्ट, कम‑सेलेक्टिव फिल्टर, भारी एग्रीगेशन)। और इंडेक्स के असली लागतें भी हैं: अतिरिक्त स्टोरेज और धीमी लिखाई, क्योंकि इन्सर्ट और अपडेट को भी इंडेक्स अपडेट करना पड़ता है।
इस गाइड में क्या सीखेंगे
आप जानेंगे:
- क्यों फुल टेबल स्कैन से बचना सबसे बड़ा स्पीड‑विन है
- सामान्य इंडेक्स संरचनाएँ (जैसे B-tree) खोजों को कैसे तेज़ बनाती हैं
- कौन‑सी क्वेरियाँ सबसे ज़्यादा लाभ उठाती हैं, और कब नहीं
- कंपोजिट/कवेरिंग इंडेक्स कैसे चुनें और उन्हें EXPLAIN प्लान से सत्यापित करें
- समय के साथ इंडेक्स का रखरखाव कैसे करें ताकि प्रदर्शन चुपचाप बिगड़ने न पाए
मुख्य स्पीड‑विन: फुल टेबल स्कैन से बचना
जब डेटाबेस कोई क्वेरी चलाता है, उसके पास दो बड़े विकल्प होते हैं: तालिका को पंक्ति‑दर‑पंक्ति स्कैन करना, या सीधे उन पंक्तियों पर कूदना जो मेल खाती हैं। अधिकांश इंडेक्सिंग लाभ अनावश्यक रीड्स से बचने से आते हैं।
फुल टेबल स्कैन बनाम इंडेक्स लुकअप
एक फुल टेबल स्कैन ठीक वही है जैसा लगता है: डेटाबेस हर पंक्ति पढ़ता है, जांचता है कि क्या वह WHERE शर्त से मेल खाती है, और तभी परिणाम लौटाता है। यह छोटे तालिकाओं के लिए स्वीकार्य है, लेकिन तालिका के बढ़ने के साथ यह प्रत्याशित रूप से धीमा होता जाता है—अधिक पंक्तियाँ = अधिक काम।
इंडेक्स का उपयोग करने पर, डेटाबेस अक्सर अधिकांश पंक्तियाँ पढ़ने से बच सकता है। इसके बजाय, वह पहले इंडेक्स को देखता है (खोज के लिए बना एक संकुचित संरचना) ताकि पता चल सके कि मेल खाने वाली पंक्तियाँ कहाँ हैं, और फिर केवल उन विशिष्ट पंक्तियों को पढ़ता है।
एक सरल उपमा
एक किताब की कल्पना करें। अगर आप "photosynthesis" वाले हर पृष्ठ को खोजना चाहें, तो आप पूरी किताब पढ़ सकते हैं (फुल स्कैन)। या आप किताब के इंडेक्स का उपयोग कर सकते हैं, सूचीबद्ध पृष्ठों पर कूद सकते हैं और केवल उन हिस्सों को पढ़ सकते हैं (इंडेक्स लुकअप)। दूसरा तरीका तेज़ है क्योंकि आप अधिकांश पृष्ठों को स्किप कर देते हैं।
कम रीड्स आम तौर पर क्यों तेज़ होते हैं
डेटाबेस बहुत समय पढ़ने की प्रतीक्षा में बिताते हैं—खासकर जब डेटा मेमोरी में पहले से नहीं है। टच की जाने वाली पंक्तियों (और पेजों) की संख्या घटाने से आम तौर पर घटता है:
- डिस्क/SSD रीड
- फ़िल्टर लागू करने में लगाया गया CPU समय
- अनावश्यक डेटा को कैश में खींचने से होने वाला मेमोरी दबाव
गति का लाभ कब दिखता है
इंडेक्स तब अधिक मदद करते हैं जब डेटा बड़ा हो और क्वेरी पैटर्न चयनात्मक हो (उदा., 10 मिलियन में से 20 मिलान)। अगर आपकी क्वेरी वैसे भी अधिकांश पंक्तियाँ लौटाती है, या तालिका इतनी छोटी है कि वह आराम से मेमोरी में फिट हो जाती है, तो फुल स्कैन उतना ही तेज़—या तेज़ भी—हो सकता है।
इंडेक्स संरचनाएँ कैसे खोजों को तेज़ बनाती हैं
इंडेक्स इसलिए काम करते हैं क्योंकि वे मानों को इस तरीके से व्यवस्थित करते हैं कि डेटाबेस हर पंक्ति की जाँच करने के बजाय सीधे उस पास पहुँच सके जिसे आप चाहते हैं।
B-tree इंडेक्स: डिफ़ॉल्ट वर्कहॉर्स
SQL डाटाबेस में सबसे सामान्य इंडेक्स संरचना B-tree (अक्सर "B-tree" या "B+tree") है। संक्षेप में:
- मान क्रमबद्ध रखे जाते हैं
- इंडेक्स को पेजेस (चंक्स) में बाँटा जाता है जो अन्य पेजों की ओर पॉइंटर करते हैं और अंततः तालिका पंक्तियों की ओर इशारा करते हैं
क्योंकि यह क्रमबद्ध है, B-tree समानता लुकअप (WHERE email = ...) और रेंज क्वेरीज़ (WHERE created_at >= ... AND created_at < ...) दोनों के लिए अच्छा है। डेटाबेस सही पड़ोस (neighborhood) तक नेविगेट कर सकता है और फिर आगे बढ़कर क्रम में स्कैन कर सकता है।
"लॉगरिदमिक" का अर्थ (गणित के बिना)
लोग कहते हैं कि B-tree लुकअप "लॉगरिदमिक" हैं। व्यवहार में इसका मतलब यह है: जैसे‑जैसे आपकी तालिका हजारों से मिलियनों में बढ़ती है, किसी मान को खोजने के लिए कदमों की संख्या धीरे‑धीरे बढ़ती है, न कि आनुपातिक रूप से।
"डेटा दोगुना हुआ तो काम भी दोगुना होगा" के बजाय यह ज़्यादा कुछ ऐसा है: "काफ़ी अधिक डेटा का मतलब सिर्फ़ कुछ अतिरिक्त नेविगेशन कदम", क्योंकि डेटाबेस पेड़ के छोटे‑से स्तरों के माध्यम से पॉइंटर फ़ॉलो करता है।
हैश इंडेक्स: सटीक मैच के लिए तेज़ (सीमाओं के साथ)
कुछ इंजन हैश इंडेक्स भी देते हैं। ये सटीक समानता जाँचों के लिए बहुत तेज़ हो सकते हैं क्योंकि मान को हैश किया जाता है और सीधे एंट्री मिल जाती है।
ट्रेडऑफ़: हैश इंडेक्स सामान्यतः रेंज या क्रमिक स्कैन में मदद नहीं करते, और उपलब्धता/व्यवहार डेटाबेस के अनुसार भिन्न होता है।
इंजन के विवरण अलग हो सकते हैं, विचार एक जैसा रहता है
PostgreSQL, MySQL/InnoDB, SQL Server आदि इंडेक्स को अलग‑अलग तरीके से स्टोर और उपयोग करते हैं (पेज साइज, क्लस्टरिंग, शामिल कॉलम, विजिबिलिटी चेक)। लेकिन मूल विचार वही है: इंडेक्स एक संकुचित, नेविगेबल संरचना बनाते हैं जो डेटाबेस को मेल खाने वाली पंक्तियों का पता लगाने में बहुत कम काम करवाती है बनाम पूरी तालिका स्कैन।
कौन‑सी क्वेरियाँ इंडेक्स से सबसे ज़्यादा लाभ उठाती हैं
इंडेक्स सामान्य रूप से "SQL" को तेज़ नहीं बनाते—वे विशेष एक्सेस पैटर्न को तेज़ करते हैं। जब इंडेक्स आपके क्वेरी के फ़िल्टर, जॉइन, या सॉर्ट से मेल खाता है, तब डेटाबेस सीधे प्रासंगिक पंक्तियों पर कूद सकता है बजाय इसके कि वह पूरी तालिका पढ़े।
सबसे इंडेक्स‑फ्रेंडली पैटर्न
1) WHERE फ़िल्टर (खासकर चयनात्मक कॉलम पर)
यदि आपकी क्वेरी अक्सर बड़ी तालिका को कुछ ही पंक्तियों तक संकुचित कर देती है, तो इंडेक्स अक्सर पहली जगह है जहाँ देखना चाहिए। एक क्लासिक उदाहरण है किसी उपयोगकर्ता को उसके पहचानकर्ता से ढूँढना।
users.email पर इंडेक्स नहीं होने पर डेटाबेस हर पंक्ति स्कैन कर सकता है:
SELECT * FROM users WHERE email = '[email protected]';
email पर इंडेक्स होने पर यह मिलान करने वाली पंक्ति(यों) को तेज़ी से ढूँढ सकता है और रुक सकता है।
2) JOIN कीज़ (फॉरेन कीज़ और रेफ़रेंस किए गए कीज़)
जॉयन्स वे जगह हैं जहाँ "छोटी‑छोटी अक्षमताएँ" बड़े खर्च में बदल जाती हैं। यदि आप orders.user_id को users.id से जोड़ते हैं, तो जॉइन कॉलमों (आम तौर पर orders.user_id और प्राइमरी की users.id) को इंडेक्स करना डेटाबेस को बिना बार‑बार स्कैन किए मेल खाने में मदद करता है।
3) ORDER BY (जब आप परिणाम पहले से सॉर्टेड चाहते हैं)
जब डेटाबेस को बहुत सारी पंक्तियाँ इकट्ठा करके बाद में सॉर्ट करना पड़ता है तो सॉर्ट महंगा होता है। यदि आप अक्सर चलाते हैं:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
तो user_id और सॉर्ट कॉलम से मेल खाता हुआ एक इंडेक्स इंजन को आवश्यक क्रम में पंक्तियाँ पढ़ने दे सकता है बजाय बड़े मध्यवर्ती परिणाम को सॉर्ट करने के।
4) GROUP BY (जब ग्रुपिंग इंडेक्स से मेल खाती हो)
ग्रुपिंग को तब लाभ हो सकता है जब डेटाबेस डेटा को समूह के क्रम में पढ़ सके। यह गारंटी नहीं है, लेकिन यदि आप सामान्यतः किसी कॉलम से ग्रुप करते हैं जो फ़िल्टर के साथ भी उपयोग होता है (या इंडेक्स में प्राकृतिक रूप से क्लस्टर्ड है), तो इंजन कम काम कर सकता है।
रेंज फ़िल्टर: एक आम B-tree जीत
B-tree इंडेक्स रेंज कंडीशनों में ख़ासकर अच्छे होते हैं—सोचें डेट्स, प्राइस, और "बीच में" क्वेरीज़:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
डैशबोर्ड, रिपोर्ट और "हालिया गतिविधि" स्क्रीन के लिए यह पैटर्न हर जगह है, और रेंज कॉलम पर इंडेक्स अक्सर तुरंत सुधार देता है।
थीम सरल है: इंडेक्स तब सबसे ज़्यादा मदद करते हैं जब वे आपकी खोज और सॉर्ट करने के तरीके को प्रतिबिंबित करते हैं। अगर आपकी क्वेरियाँ इन एक्सेस पैटर्न से मेल खाती हैं, तो डेटाबेस लक्षित रीड कर सकता है बजाय व्यापक स्कैन के।
सेलेक्टिविटी: क्यों कुछ इंडेक्स मदद नहीं करते
इंडेक्स तब सबसे ज़्यादा मदद करता है जब यह स्पष्ट रूप से यह संकुचित कर दे कि डेटाबेस को कितनी पंक्तियाँ छूनी हैं। यह गुण सेलेक्टिविटी कहलाता है।
सेलेक्टिविटी का व्यावहारिक अर्थ
सेलेक्टिविटी मूलतः है: किसी दिए मान से कितनी पंक्तियाँ मिलती हैं? एक बहुत सेलेक्टिव कॉलम में कई अलग मान होते हैं, इसलिए हर लुकअप कुछ ही पंक्तियों से मेल खाता है।
- उच्च सेलेक्टिविटी:
email, user_id, order_number (अक्सर यूनिक या लगभग यूनिक)
- निम्न सेलेक्टिविटी:
is_active, is_deleted, status जिसमें कुछ सामान्य मान
उच्च सेलेक्टिविटी के साथ, एक इंडेक्स सीधे कुछ ही पंक्तियों तक कूद सकता है। निम्न सेलेक्टिविटी के साथ, इंडेक्स तालिका के बड़े हिस्से की ओर इशारा कर सकता है—इसलिए डेटाबेस को अभी भी काफी पढ़ना और फ़िल्टर करना पड़ता है।
बूलियन (और समान) इंडेक्स क्यों निराश करते हैं
मान लीजिए 10 मिलियन पंक्तियों वाली तालिका है और is_deleted कॉलम में 98% मान false हैं। is_deleted पर इंडेक्स निम्नलिखित जैसी क्वेरी के लिए ज्यादा मददगार नहीं है:
SELECT * FROM orders WHERE is_deleted = false;
"मिलान सेट" अभी भी लगभग पूरी तालिका है। इंडेक्स का उपयोग करना कभी‑कभी सीक्वेंशियल स्कैन से भी धीमा हो सकता है क्योंकि इंजन इंडेक्स प्रविष्टियों और तालिका पेजों के बीच अतिरिक्त कूद करता है।
डेटाबेस आपके इंडेक्स को कभी नज़रअंदाज़ क्यों कर सकता है
क्वेरी प्लानर लागत का अनुमान लगाता है। अगर इंडेक्स काम कम नहीं घटाएगा—क्योंकि बहुत सारी पंक्तियाँ मैच करती हैं, या क्वेरी को भी अधिकांश कॉलम चाहिए—तो वह फुल टेबल स्कैन चुन सकता है।
सेलेक्टिविटी समय के साथ बदलती है
डेटा का वितरण स्थिर नहीं रहता। एक status कॉलम पहले समान रूप से विभाजित हो सकता है, फिर ऐसा झुकाव आ सकता है कि एक मान हावी हो जाए। अगर आंकड़े (statistics) अपडेट नहीं होते हैं, प्लानर गलत निर्णय ले सकता है, और पहले उपयोगी इंडेक्स अब लाभ न दे पाए।
कंपोजिट और कवेरिंग इंडेक्स (और कॉलम ऑर्डर)
सिंगल‑कॉलम इंडेक्स एक अच्छी शुरुआत है, लेकिन कई असली क्वेरियाँ एक कॉलम पर फ़िल्टर करती हैं और दूसरे पर सॉर्ट/फिल्टर भी करती हैं। वहाँ कंपोजिट (मल्टी‑कॉलम) इंडेक्स काम आते हैं: एक इंडेक्स कई हिस्सों को सेवा दे सकता है।
कॉलम ऑर्डर: "बाय‑लेफ्ट" नियम
अधिकांश डाटाबेस (खासकर B-tree इंडेक्स के साथ) एक कंपोजिट इंडेक्स को केवल बाएँ से दाएँ कॉलम के हिसाब से प्रभावी रूप से उपयोग कर सकते हैं। इंडेक्स को पहले कॉलम A के अनुसार क्रमबद्ध, फिर भीतर कॉलम B के अनुसार समझें।
इसका अर्थ:
- (account_id, created_at) पर इंडेक्स उन क्वेरियों के लिए बेहतरीन है जो
account_id से फ़िल्टर करती हैं और फिर created_at से सॉर्ट/फिल्टर करती हैं
- वही इंडेक्स आम तौर पर
created_at पर केवल फ़िल्टर करने वाली क्वेरी के लिए मददगार नहीं है (क्योंकि यह लेफ्ट‑मोस्ट नहीं है)
एक व्यावहारिक पैटर्न: प्रति‑खाता टाइमलाइन
एक सामान्य वर्कलोड है "मुझे इस खाते के सबसे हाल के इवेंट दिखाओ।" यह पैटर्न:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
अक्सर काफी लाभ उठाता है यदि आप बनाते हैं:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
डेटाबेस इंडेक्स में सीधे एक अकाउंट के हिस्से तक कूद सकता है और समय के क्रम में पंक्तियाँ पढ़ सकता है, बजाय बड़ी सेट को स्कैन और सॉर्ट करने के।
कवेरिंग इंडेक्स: जब इंडेक्स ही उत्तर हो
एक कवेरिंग इंडेक्स में क्वेरी को चाहिए जितने भी कॉलम होते हैं वे सब शामिल होते हैं, इसलिए डेटाबेस तालिका पंक्तियाँ देखे बिना इंडेक्स से परिणाम दे सकता है (कम रीड्स, कम रैंडम I/O)।
सावधानी: अतिरिक्त कॉलम जोड़ने से इंडेक्स बड़ा और महँगा हो सकता है।
"बस‑सुरक्षित" के लिए चौड़े कंपोजिट मत बनाइए
चौड़े कंपोजिट इंडेक्स लिखने को धीमा कर सकते हैं और बहुत स्टोरेज लेते हैं। उन्हें केवल विशिष्ट उच्च‑मूल्य क्वेरियों के लिए जोड़ें, और EXPLAIN प्लान तथा वास्तविक माप के साथ पहले और बाद में सत्यापित करें।
ट्रेडऑफ़्स: लिखने में धीमापन और अतिरिक्त स्टोरेज
इंडेक्स अक्सर "मुफ्त स्पीड" की तरह बताए जाते हैं, पर वे मुफ्त नहीं होते। इंडेक्स संरचनाओं को तालिका बदलने पर मेंटेन करना पड़ता है, और वे वास्तविक संसाधन लेते हैं।
INSERT/UPDATE/DELETE धीमे होते हैं (क्योंकि हर इंडेक्स अपडेट होता है)
जब आप एक नई पंक्ति INSERT करते हैं, तो डेटाबेस सिर्फ पंक्ति ही नहीं लिखता—यह प्रत्येक इंडेक्स में भी संबंधित प्रविष्टियाँ डालता है। वही DELETE और कई UPDATE पर भी लागू होता है।
इसलिए "अधिक इंडेक्स" लिखने‑भारी वर्कलोड को लगातार धीमा कर सकते हैं। एक ऐसा UPDATE जो किसी इंडेक्स्ड कॉलम को छूता है खासकर महँगा हो सकता है: डेटाबेस को पुरानी इंडेक्स प्रविष्टि हटानी और नई जोड़नी पड़ सकती है (और कुछ इंजन में इससे पेज स्प्लिट या आंतरिक रीबैलेंसिंग भी हो सकती है)। यदि आपका ऐप बहुत लिखता है—ऑर्डर इवेंट्स, सेंसर डेटा, ऑडिट लॉग—तो हर चीज़ पर इंडेक्स लगाने से डेटाबेस सुस्त महसूस कर सकता है भले ही पढ़ना तेज़ हो।
अतिरिक्त स्टोरेज और मेमोरी दबाव
प्रत्येक इंडेक्स डिस्क स्पेस लेता है। बड़ी तालिकाओं पर, इंडेक्स तालिका के आकार के बराबर या उससे अधिक हो सकते हैं, खासकर अगर आपके पास कई ओवरलैपिंग इंडेक्स हों।
यह मेमोरी को भी प्रभावित करता है। डेटाबेस भारी रूप से कैशिंग पर निर्भर करते हैं; यदि आपका वर्किंग सेट कई बड़े इंडेक्स शामिल करता है, तो कैश को तेज़ रखने के लिए अधिक पेज होल्ड करने होंगे। अन्यथा आप अधिक डिस्क I/O और कम अनुमानित प्रदर्शन देखेंगे।
व्यावहारिक संतुलन
इंडेक्सिंग इस बात के बारे में है कि आप क्या तेज़ करना चाहते हैं। अगर आपका वर्कलोड पढ़ने‑भरा है, तो अधिक इंडेक्स देना उपयोगी हो सकता है। अगर यह लिखने‑मुख्य है, तो उन्हीं इंडेक्सों को प्राथमिकता दें जो आपके सबसे महत्वपूर्ण क्वेरियों का समर्थन करते हैं और डुप्लिकेट्स से बचें। एक उपयोगी नियम: तब ही इंडेक्स जोड़ें जब आप उस क्वेरी का नाम बता सकें जिसका वह मददगार है—और पढ़ने की गति लाभ लिखने और मेंटेनेंस लागत से अधिक है यह सत्यापित करें।
कैसे साबित करें कि कोई इंडेक्स मदद करता है: EXPLAIN और मापन
इंडेक्स जोड़ना लोगों को लगता है कि यह मदद करेगा—पर आपको इसे सत्यापित करना चाहिए। दो उपकरण जो इसे ठोस बनाते हैं वे हैं क्वेरी प्लान (EXPLAIN) और असली पहले/बाद माप।
प्लान पढ़ें: क्या इंडेक्स वास्तव में उपयोग हो रहा है?
ठीक उसी क्वेरी पर EXPLAIN (या EXPLAIN ANALYZE) चलाएँ जिसे आप देख रहे हैं।
- Scan type: Seq Scan / Full Table Scan का मतलब है डेटाबेस पूरी तालिका पढ़ रहा है। Index Scan / Index Seek (या Index Range Scan) यह संकेत देता है कि वह इंडेक्स का उपयोग कर रहा है।
- Estimated vs. actual rows (खासतौर पर
EXPLAIN ANALYZE में): अगर प्लान ने अनुमानित 100 पंक्तियाँ बताईं पर वास्तव में 100,000 छुए, तो ऑप्टिमाइज़र ने गलत अनुमान लगाया—अक्सर क्योंकि स्टैट्स पुराने हैं या फिल्टर अपेक्षाकृत कम‑सेलेक्टिव है।
- Sort steps: यदि आप एक स्पष्ट Sort ऑपरेशन देखते हैं, डेटाबेस परिणामों को फ़ेच करने के बाद ऑर्डर कर रहा है। अगर नया इंडेक्स
ORDER BY से मेल खाता है तो वह सॉर्ट गायब हो सकता है, जो बड़ा लाभ हो सकता है।
सही तरीके से मापें: पहले/बाद, समान परिस्थितियाँ
क्वेरी को उसी पैरामीटर के साथ बेंचमार्क करें, प्रतिनिधि डेटा आकार पर, और दोनों लेटेंसी और स्कैन की गई पंक्तियों को कैप्चर करें।
कैशिंग के साथ सावधान रहें: पहली बार का रन धीमा हो सकता है क्योंकि डेटा अभी मेमोरी में नहीं है; बार‑बार रन करने पर बिना इंडेक्स के भी स्थिति "ठीक" लग सकती है। खुद को धोका देने से बचने के लिए कई रन की तुलना करें और देखें कि क्या प्लान बदलता है (इंडेक्स उपयोग, कम रीड) सिर्फ़ रॉ टाइम के अलावा।
अगर EXPLAIN ANALYZE कम छुई हुई पंक्तियाँ और कम महँगे स्टेप्स (जैसे सॉर्ट) दिखाता है, तो आपने साबित कर दिया कि इंडेक्स मददगार है—सिर्फ़ उम्मीद नहीं की।
सामान्य गलतियाँ जो इंडेक्स लाभ रद्द कर देती हैं
आप सही इंडेक्स जोड़ सकते हैं और फिर भी स्पीड‑अप न देख पाएँ यदि क्वेरी ऐसी लिखी हो कि डेटाबेस उसे उपयोग नहीं कर सके। ये मुद्दे अक्सर सूक्ष्म होते हैं, क्योंकि क्वेरी अभी भी सही परिणाम देती है—बस धीमी होती है।
ऐसे एंटी‑पैटर्न जो इंडेक्स उपयोग रोकते हैं
1) लीडिंग वाइल्डकार्ड
जब आप लिखते हैं:
WHERE name LIKE '%term'
नॉर्मल B-tree इंडेक्स इस तरह के केस में सही शुरुआती बिंदु का पता नहीं लगा पाता, क्योंकि उसे पता नहीं होता कि "%term" क्रम में कहाँ शुरू होता है। वह अक्सर कई पंक्तियों को स्कैन करने पर उतर आता है।
विकल्प:
- यदि संभव हो, प्रेफिक्स सर्च का उपयोग करें:
WHERE name LIKE 'term%'।
- यदि आपको सचमुच "contains" सर्च चाहिए, तो सामान्य इंडेक्स पर भरोसा करने के बजाय विशेष इंडेक्स प्रकार (उदा., फ़ुल‑टेक्स्ट/ट्राइग्राम) पर विचार करें।
2) इंडेक्स्ड कॉलम पर फ़ंक्शन लागू करना
यह निर्दोष दिख सकता है:
WHERE LOWER(email) = '[email protected]'
पर LOWER(email) अभिव्यक्ति को बदल देता है, इसलिए email पर बना इंडेक्स सीधे उपयोग नहीं हो पाएगा।
विकल्प:
- सामान्यीकृत डेटा संग्रहीत करें (उदा., ईमेल लोअरकेस में स्टोर करें) और
WHERE email = ... क्वेरी करें।
- या एक एक्सप्रेशन/फ़ंक्शन‑आधारित इंडेक्स बनाएं (DB-निर्भर) खासकर
LOWER(email) के लिए।
छिपे हुए इंडेक्स ब्लॉकर जिन्हें लोग मिस कर देते हैं
इम्प्लिसिट टाइप कास्ट: अलग‑अलग डेटा प्रकार की तुलना करने पर डेटाबेस को एक साइड कैस्ट करना पड़ सकता है, जो इंडेक्स को अक्षम कर देता है। उदाहरण: एक इंटीजर कॉलम की तुलना स्ट्रिंग लिटरेल से।
मिसमैच्ड कोलेशन/एन्कोडिंग: यदि तुलना उस कोलेशन का उपयोग करती है जिसके साथ इंडेक्स नहीं बना था (अलग‑अलग लोकल सेटिंग्स में आम), तो ऑप्टिमाइज़र इंडेक्स से बच सकता है।
त्वरित चेकलिस्ट: "मेरा इंडेक्स क्यों उपयोग नहीं हो रहा?"
- क्या कंडीशन वाइल्डकार्ड से शुरू होती है (
LIKE '%x')?
- क्या आप इंडेक्स्ड कॉलम पर फ़ंक्शन लगा रहे हैं (
LOWER(col), DATE(col), CAST(col))?
- क्या दोनों तरफ प्रकार समान हैं (कोई इम्प्लिसिट कास्ट नहीं)?
- तुलना के लिए कोलेशन/लोकल सेटिंग कंसिस्टेंट है?
- क्या प्रेडिकेट काफी चयनात्मक है (तालिका का बड़ा हिस्सा नहीं मैच कर रहा)?
- क्या आप कंपोजिट इंडेक्स के लेफ्ट‑मोस्ट कॉलम्स पर फ़िल्टर/सॉर्ट कर रहे हैं?
- क्या आपने
EXPLAIN के साथ प्लान चेक किया है कि डेटाबेस ने वास्तव में क्या चुना?
इंडेक्स रखरखाव: स्टैट्स, ब्लोट, और दीर्घकालिक स्वास्थ्य
इंडेक्स "लगाएँ और भूल जाएँ" वाली चीज़ें नहीं हैं। समय के साथ डेटा बदलता है, क्वेरी पैटर्न शिफ्ट होते हैं, और तालिकाओं व इंडेक्सों का भौतिक आकार बदलता है। एक ठीक‑चुना इंडेक्स धीरे‑धीरे कम प्रभावी—या यहां तक कि हानिकारक—हो सकता है यदि आप उसका रखरखाव नहीं करते।
स्टैटिस्टिक्स: प्लानर का नक़्शा पुराना हो सकता है
अधिकांश डेटाबेस एक क्वेरी प्लानर (ऑप्टिमाइज़र) पर निर्भर करते हैं कि वह यह चुने कि क्वेरी कैसे चलेगी: कौन‑सा इंडेक्स उपयोग होगा, जॉइन ऑर्डर क्या होगा, और क्या इंडेक्स लुकअप उचित है। इन निर्णयों के लिए प्लानर स्टैटिस्टिक्स का उपयोग करता है—मान वितरण, पंक्ति गणना, और डेटा स्क्यू का सारांश।
जब स्टैटिस्टिक्स स्टेल हो जाती हैं, तो प्लानर के पंक्ति अनुमान बहुत गलत हो सकते हैं। इससे खराब प्लान आते हैं—जैसे ऐसा इंडेक्स चुनना जो अपेक्षाकृत बहुत अधिक पंक्तियाँ लौटाता है, या किसी इंडेक्स को छोड़ देना जो तेज़ होना चाहिए।
नियमित सुधार: नियमित रूप से स्टैट्स अपडेट करना (अक्सर "ANALYZE" या समान कमांड)। बड़े डेटा लोड, बड़े डिलीट, या उच्च चर्न के बाद स्टैट्स जल्दी रिफ्रेश करें।
ब्लोट और फ्रैगमेंटेशन: जब संरचनाएँ गंदी हो जाती हैं
जैसे‑जैसे पंक्तियाँ डाली, अपडेट या डिलीट होती हैं, इंडेक्स में ब्लोट (बेकार पेज) और फ्रैगमेंटेशन आ सकता है जो I/O बढ़ाता है। परिणाम: बड़े इंडेक्स, अधिक पढ़ाई, और सीमांकन क्वेरीज़ के लिए धीमी रेंज स्कैन—खासकर रेंज‑क्वेरीज़।
नियमित सुधार: भारी उपयोग वाले इंडेक्स को समय‑समय पर रिबिल्ड या रीऑर्गनाइज़ करें जब वे असमान रूप से बढ़ जाएँ या प्रदर्शन ड्रिफ्ट दिखाये। सटीक टूलिंग और प्रभाव DB पर निर्भर करता है—इसे एक मापी हुई प्रक्रिया मानें, सार्वभौमिक नियम नहीं।
समय के साथ मॉनिटर करें, सिर्फ़ एक बार नहीं
मॉनिटरिंग सेट करें:
- स्लो क्वेरियों (लेटेंसी, आवृत्ति, और सबसे बड़े अपराधी)
- इंडेक्स उपयोग (कभी उपयोग न हुए बनाम "हॉट" वाले)
- इंडेक्स साइज वृद्धि और अचानक प्लान परिवर्तन
यह फीडबैक लूप आपको पकड़ने में मदद करेगा कि कब रखरखाव चाहिए—और कब किसी इंडेक्स को समायोजित या हटाना चाहिए। अधिक सत्यापन के लिए देखें /blog/how-to-prove-an-index-helps-explain-and-measurements।
सही इंडेक्स जोड़ने के लिए व्यावहारिक वर्कफ़्लो
इंडेक्स जोड़ना एक सोच‑समझकर किया जाने वाला परिवर्तन होना चाहिए, अनुमान नहीं। एक हल्का वर्कफ़्लो आपको मापन योग्य लाभों पर ध्यान बनाए रखने में मदद करता है और "इंडेक्स स्प्राॅल" रोकता है।
1) असली समस्या‑क्वेरी की पहचान करें
सबूत से शुरू करें: स्लो‑क्वेरी लॉग्स, APM ट्रेस, या उपयोगकर्ता रिपोर्ट। एक ऐसी क्वेरी चुनें जो दोनों धीमी और आवृत्त हो—एक दुर्लभ 10‑सेकंड रिपोर्ट की तुलना में सामान्य 200 ms लुकअप अधिक मायने रखता है।
ठीक SQL और पैरामीटर पैटर्न कैप्चर करें (उदा., WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50)। छोटे फर्क भी यह बदल देते हैं कि कौन‑सा इंडेक्स मदद करेगा।
2) बेसलाइन मापें
वर्तमान लेटेंसी (p50/p95), स्कैन की गई पंक्तियाँ, और CPU/IO प्रभाव रिकॉर्ड करें। वर्तमान प्लान आउटपुट (EXPLAIN / EXPLAIN ANALYZE) भी सहेजें ताकि बाद में तुलना हो सके।
3) सबसे छोटा उपयोगी इंडेक्स डिज़ाइन करें
उन कॉलमों को चुनें जो क्वेरी के फ़िल्टर और सॉर्ट से मेल खाते हों। उस छोटे‑से इंडेक्स को प्राथमिकता दें जो प्लान को बड़े‑रेंज स्कैन से रोक दे।
प्रोडक्शन‑जैसे डेटा वॉल्यूम के साथ स्टेजिंग में टेस्ट करें। छोटे डेटासेट पर इंडेक्स अच्छा दिख सकता है पर स्केल पर निराश कर सकता है।
4) सुरक्षित रूप से बनाएँ
बड़ी तालिकाओं पर, उन विकल्पों का उपयोग करें जो ऑनलाइन बनाते हैं जहाँ समर्थित हो (उदा., PostgreSQL में CREATE INDEX CONCURRENTLY)। यदि आपका DB लिखाई में लॉक कर सकता है तो कम ट्रैफ़िक के समय बदलाव शेड्यूल करें।
5) पहले/बाद साक्ष्य के साथ मान्य करें
उसी क्वेरी को फिर से चलाएँ और तुलना करें:
- प्लान का आकार (क्या यह फुल स्कैन से इंडेक्स‑एक्सेस में बदल गया?)
- निष्पादन समय और स्कैन की गई पंक्तियाँ
- लिखने पर प्रभाव (insert/update लेटेंसी)
6) रोलबैक प्लान रखें
यदि इंडेक्स लिखने की लागत बढ़ा देता है या मेमोरी ब्लोट करता है, तो उसे साफ़ तरीके से हटाएँ (उदा., DROP INDEX CONCURRENTLY जहाँ उपलब्ध हो)। माइग्रेशन को उलटा करने योग्य रखें।
7) "क्यों" दस्तावेज़ करें
माइग्रेशन या स्कीमा नोट्स में लिखें कि इंडेक्स किस क्वेरी की सेवा करता है और कौन‑सा मेट्रिक सुधरा। भविष्य के आप (या टीम‑साथी) जान पाएंगे कि यह क्यों मौजूद है और कब इसे हटाना सुरक्षित है।
Koder.ai इस वर्कफ़्लो में कैसे मदद करता है
यदि आप नई सेवा बना रहे हैं और शुरू से ही "इंडेक्स स्प्राॅल" से बचना चाहते हैं, तो Koder.ai पूरा लूप तेज़ी से चलाने में मदद कर सकता है: चैट से React + Go + PostgreSQL ऐप जनरेट करें, ज़रूरतें बदलने पर स्कीमा/इंडेक्स माइग्रेशन एडजस्ट करें, और फिर स्रोत कोड एक्सपोर्ट करें जब आप मैन्युअल रूप से संभालने के लिए तैयार हों। व्यवहार में, इससे "यह एंडपॉइंट स्लो है" से लेकर "ये रहा EXPLAIN प्लान, मिनिमल इंडेक्स, और उल्टने योग्य माइग्रेशन" तक जल्दी पहुँचना आसान होता है।
जब इंडेक्सिंग पर्याप्त नहीं होती (और आगे क्या करें)
इंडेक्स बड़ा लीवर है, पर यह जादुई बटन नहीं है। कभी‑कभी किसी रिक्वेस्ट का धीमा हिस्सा उसके बाद आता है जब डेटाबेस सही पंक्तियाँ ढूँढ चुका होता है—या आपका क्वेरी पैटर्न ऐसे मामलों में इंडेक्स को प्राथमिक उपाय बनाना गलत हो सकता है।
ऐसे मामले जहाँ इंडेक्सिंग सबसे ऊपर सुधार नहीं है
यदि आपकी क्वेरी पहले से ही अच्छा इंडेक्स उपयोग कर रही है पर फिर भी धीमी है, तो इन सामान्य कारणों को देखें:
- पैगिनेशन गायब या गलत:
OFFSET 999000 के साथ पेज 1,000 लाना इंडेक्स होने पर भी धीमा हो सकता है। की‑सेट पैगिनेशन का उपयोग करें (उदा., आख़िरी देखे id/timestamp के बाद की पंक्तियाँ)।
- बहुत ज़्यादा डेटा लौटाया जा रहा है: चौड़ी पंक्तियाँ (
SELECT *) या हजारों रिकॉर्ड लौटाना नेटवर्क, JSON सीरियलाइज़ेशन, या एप्लिकेशन प्रोसेसिंग में बाधा डाल सकता है।
- स्कीमा मिसमैच: ओवर‑नॉर्मलाइज़ेशन, सर्च‑वैल्यूज़ को JSON/text blobs में रखना, या गलत डेटा टाइप्स का उपयोग महँगे ऑपरेशनों को मजबूर कर सकता है जिन्हें इंडेक्स पूरी तरह छिपा नहीं सकते।
पूरक सुधार जो अक्सर ज़्यादा मायने रखते हैं
- क्वेरी फिर से लिखें: अनावश्यक जॉइन्स हटाएँ, WHERE में इंडेक्स्ड कॉलम पर फ़ंक्शन लगाने से बचें, और OR‑भारी प्रेडिकेट्स को सरल करें।
- कॉलम और पंक्तियाँ सीमित करें: केवल वही चुनें जिसकी जरूरत है, समझदार
LIMIT लगाएँ, और परिणामों को जानबूझकर पेज करें।
- कैशिंग: एप्लिकेशन‑लेयर पर हॉट रीड्स कैश करें या महँगी, बार‑बार की जाने वाली क्वेरियों के लिए रीड‑थ्रू कैश का उपयोग करें।
- पार्टिशनिंग: यदि अधिकांश क्वेरियाँ "हालिया डेटा" को हिट करती हैं, तो टाइम या किसी प्राकृतिक सीमा पर पार्टिशन करें ताकि सर्च स्पेस घटे।
यदि आप बॉटलनेक्स डायग्नोज़ करने का गहरा तरीका चाहते हैं तो इसे /blog/how-to-prove-an-index-helps के वर्कफ़्लो के साथ पेयर्ड करें।
प्राथमिकता: पहले सबसे बड़ा बाधक ठीक करें
अनुमान न लगाएँ। मापन करें कि समय कहां खर्च हो रहा है (डेटाबेस निष्पादन बनाम लौटाई गई पंक्तियाँ बनाम ऐप कोड)। अगर डेटाबेस तेज़ है पर API धीमा है, तो और इंडेक्स मदद नहीं करेंगे।
त्वरित चेकलिस्ट