ग्राफ डेटाबेस क्या हैं (हाइप के बिना)
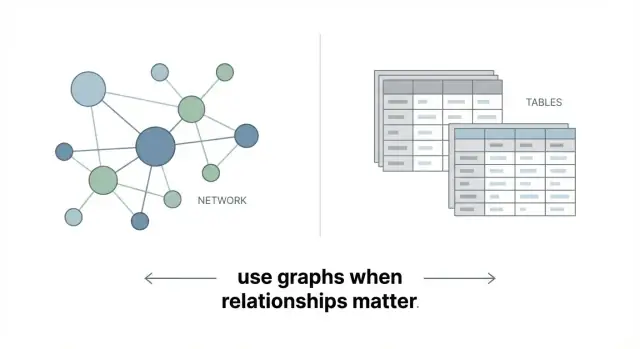
एक ग्राफ डेटाबेस डेटा को तालिकाओं के सेट के बजाय एक नेटवर्क के रूप में स्टोर करता है। मूल विचार सरल है:
- नोड्स वे “चीज़ें” हैं जिनकी आपको परवाह है (एक ग्राहक, उत्पाद, खाता, डिवाइस, स्थान)।
- रिलेशनशिप्स नोड्स को जोड़ते हैं (customer BOUGHT product, account TRANSFERRED_TO account, user FOLLOWS user)।
- प्रॉपर्टीज़ वे विवरण हैं जो आप नोड्स और रिलेशनशिप पर जोड़ते हैं (नाम, कीमत, टाइमस्टैम्प, राशि, स्टेटस)।
बस इतना: एक ग्राफ डेटाबेस कनेक्टेड डेटा को सीधे प्रतिनिधित्व करने के लिए बनाया गया है।
रिलेशनशिप्स “फर्स्ट-क्लास” होती हैं
ग्राफ डेटाबेस में, रिलेशनशिप्स कोई टिकाऊ विचार नहीं हैं—वे असली, क्वेरी करने योग्य ऑब्जेक्ट्स के रूप में स्टोर होते हैं। किसी रिलेशनशिप की अपनी प्रॉपर्टीज़ हो सकती हैं (उदाहरण के लिए, एक PURCHASED रिलेशनशिप तारीख, चैनल और डिस्काउंट स्टोर कर सकता है), और आप एक नोड से अगले नोड तक कुशलतापूर्वक ट्रैवर्स कर सकते हैं।
यह इसलिए मायने रखता है क्योंकि कई व्यावसायिक सवाल स्वाभाविक रूप से पाथ्स और कनेक्शन्स के बारे में होते हैं: “कौन किससे जुड़ा है?”, “यह एंटिटी कितने स्टेप्स दूर है?”, या “इन दोनों चीज़ों के बीच सामान्य लिंक क्या हैं?”
यह तालिकाओं और जॉइन्स से कैसे अलग है
रिलेशनल डेटाबेस संरचित रिकॉर्ड्स के लिए बेहतरीन हैं: customers, orders, invoices। वहां रिश्ते भी होते हैं, लेकिन वे आमतौर पर फॉरेन कीज़ के ज़रिए अप्रत्यक्ष रूप से दर्शाए जाते हैं, और कई हॉप्स जोड़ने के लिए अक्सर कई टेबलों में JOIN लिखने की ज़रूरत पड़ती है।
ग्राफ कनेक्शन्स को डेटा के पास ही रखते हैं, इसलिए मल्टी-स्टेप रिलेशनशिप का एक्सप्लोरेशन मॉडल और क्वेरी दोनों में आम तौर पर ज़्यादा सीधा होता है।
अपेक्षाएँ सेट करना
ग्राफ डेटाबेस उत्कृष्ट होते हैं जब रिलेशनशिप्स ही मुख्य बात हों—सिफारिशें, फ्रॉड रिंग्स, डिपेंडेंसी मैपिंग, नॉलेज ग्राफ। वे सरल रिपोर्टिंग, टोटल्स या उच्च-टेबलर वर्कलोड्स के लिए अपने आप बेहतर नहीं होते। लक्ष्य हर डेटाबेस को बदलना नहीं है, बल्कि उस जगह ग्राफ का उपयोग करना है जहाँ कनेक्टिविटी मूल्य बनाती है।
क्यों रिलेशनशिप्स गेम बदलते हैं
अधिकांश व्यावसायिक सवाल वास्तव में सिंगल रिकॉर्ड्स के बारे में नहीं होते—वे इस बात के बारे में होते हैं कि चीज़ें कैसे जुड़ी हैं।
एक ग्राहक सिर्फ़ एक रो नहीं है; वह ऑर्डर्स, डिवाइसेज़, पते, सपोर्ट टिकट्स, रेफरल्स और कभी-कभी अन्य ग्राहकों से जुड़ा होता है। एक ट्रांज़ैक्शन सिर्फ़ एक इवेंट नहीं है; वह एक मर्चेंट, पेमेंट मेथड, लोकेशन, समय विंडो और संबंधित गतिविधियों की एक चेन से जुड़ा होता है। जब सवाल होता है “कौन/क्या किससे जुड़ा है, और कैसे?”, तब रिलेशनशिप डेटा मुख्य पात्र बन जाता है।
ट्रैवर्सल: कनेक्शन्स का स्टेप-बाय-स्टेप अनुसरण
ग्राफ डेटाबेस ट्रैवर्सल के लिए डिज़ाइन किए गए हैं: आप एक नोड से शुरू करते हैं और एजेस को फॉलो करके नेटवर्क में “चलते” हैं।
बार-बार टेबल्स को जोइन करने के बजाय, आप उस पाथ को व्यक्त करते हैं जिसकी आपको परवाह है: Customer → Device → Login → IP Address → Other Customers। यह स्टेप-बाय-स्टेप फ्रेमिंग धोखाधड़ी जांचने, डिपेंडेंसी का पता लगाने, या सिफारिशों को समझाने के तरीके से मेल खाती है।
क्यों मल्टी-हॉप क्वेरीज़ सरल होती हैं
असल फर्क तब दिखता है जब आपको कई हॉप्स (दो, तीन, पाँच स्टेप्स दूर) की ज़रूरत होती है और आपको पहले से पता नहीं होता कि रोचक कनेक्शन्स कहाँ दिखेंगी।
रिलेशनल मॉडल में, मल्टी-हॉप सवाल अक्सर लंबे जॉइन चैन में बदल जाते हैं साथ ही डुप्लिकेट्स से बचने और पाथ की लंबाई नियंत्रित करने के लिए एक्स्ट्रा लॉजिक होता है। ग्राफ में, “मुझे N हॉप्स तक के सभी पाथs ढूँढो” एक सामान्य, पढ़ने योग्य पैटर्न है—खासकर प्रॉपर्टी ग्राफ मॉडल में जो कई ग्राफ डेटाबेस इस्तेमाल करते हैं।
रिलेशनशिप प्रॉपर्टीज़ अर्थ जोड़ती हैं
एजेस केवल रेखाएँ नहीं हैं; वे डेटा भी रख सकती हैं:
- Type: purchased, referred, works_with
- Time: जब रिलेशनशिप शुरू हुआ, खत्म हुआ, या आख़िरी बार हुआ
- Weight: फ्रिक्वेंसी, कॉन्फिडेंस स्कोर, राशि, रिस्क लेवल
ये प्रॉपर्टीज़ आपको बेहतर सवाल पूछने देती हैं: “पिछले 30 दिनों के भीतर जुड़े हुए,” “सबसे मजबूत टाईज़,” या “वे पाथ जो हाई-रिस्क ट्रांज़ैक्शंस शामिल करते हैं” — बिना हर चीज़ को अलग लुकअप टेबल में धकेले।
ग्राफ डेटाबेस के लिए सबसे उपयुक्त उपयोग के मामले
ग्राफ डेटाबेस तब चमकते हैं जब आपके सवाल कनेक्टेडनेस पर निर्भर हों: “कौन किससे जुड़ा है, किसके माध्यम से, और कितने कदम दूर?” यदि आपके डेटा का मूल्य रिलेशनशिप डेटा में है (सिर्फ एट्रीब्यूट्स की पंक्तियों में नहीं), तो ग्राफ मॉडलिंग और क्वेरी करना ज़्यादा नेचुरल लगेगा।
सोशल और प्रोफेशनल नेटवर्क
कुछ भी जो नेटवर्क जैसा आकार लेता है—दोस्त, फॉलोअर्स, सहकर्मी, टीमें, रेफरल्स—वह नोड्स और रिलेशनशिप्स में साफ़ मैप होता है। सामान्य प्रश्नों में “म्यूचुअल कनेक्शन्स,” “किसी व्यक्ति तक सबसे छोटा पाथ,” या “ये दो समूह कौन जोड़ता है?” शामिल हैं। इन क्वेरीज़ को जब कई जॉइन टेबल्स में ज़बरदस्ती दबाया जाता है तो वे अक्सर अजीब (या धीमे) हो जाते हैं।
सिफारिशें (और डिस्कवरी)
सिफारिश इंजन आमतौर पर मल्टी-स्टेप कनेक्शन्स पर निर्भर होते हैं: user → item → category → similar items → other users। ग्राफ डेटाबेस “जिन लोगों ने X को पसंद किया वे Y को भी पसंद करते हैं,” “आइटम अक्सर साथ में देखे गए,” और “मुझे उत्पाद दिखाइए जो साझा एट्रिब्यूट्स या व्यवहार से जुड़े हैं” जैसे सवालों के लिए उपयुक्त हैं। जब संकेत विविध हों और आप नए रिलेशनशिप टाइप जोड़ते रहें तो यह और भी उपयोगी होता है।
फ्रॉड और रिस्क जांच
फ्रॉड डिटेक्शन ग्राफ्स इसलिए अच्छे काम करते हैं क्योंकि संदिग्ध व्यवहार शायद ही कभी अकेला होता है। खाते, डिवाइसेज़, ट्रांज़ैक्शंस, फोन नंबर, ईमेल, और पते साझा पहचानकर्ताओं का जाल बनाते हैं। एक ग्राफ रिंग्स, दोहराए गए पैटर्न, और अप्रत्यक्ष लिंक (उदाहरण: दो “असंबद्ध” खाते एक ही डिवाइस का उपयोग कर रहे हैं) को ढूँढना आसान बनाता है।
नेटवर्क और आईटी डिपेंडेंसी मैपिंग
सर्विसेस, होस्ट्स, APIs, कॉल्स, और ओनरशिप के लिए प्राथमिक सवाल डिपेंडेंसी होता है: “अगर यह बदलेगा तो क्या टूटेगा?” ग्राफ इंपैक्ट एनालिसिस, रूट-कॉज़ एक्सप्लोरेशन, और जब सिस्टम्स इंटरकनेक्टेड हों तो “ब्लास्ट रेडियस” क्वेरीज़ का समर्थन करते हैं।
नॉलेज ग्राफ्स
नॉलेज ग्राफ्स एंटिटीज़ (लोग, कंपनियाँ, उत्पाद, दस्तावेज़) को फैक्ट्स और रेफ़रेंस से जोड़ते हैं। यह सर्च, एंटिटी रिज़ॉल्यूशन, और कई लिंक्ड सोर्सेज़ में यह ट्रेस करने में मदद करता है कि किसी फैक्ट का “क्यों” और “कहाँ से” पता चला (प्रोवेनेंस)।
सामान्य ग्राफ प्रश्न जिनके जवाब आसानी से मिलते हैं
ग्राफ डेटाबेस तब चमकते हैं जब सवाल सचमुच कनेक्शन्स के बारे में हो: कौन किससे जुड़ा है, किस चेन के जरिए, और कौन से पैटर्न दोहराए जा रहे हैं। तालिकाएँ बार-बार जोड़ने के बजाय, आप सीधे रिलेशनशिप का सवाल पूछते हैं और नेटवर्क बढ़ने पर भी क्वेरी पठनीय रहती है।
1) पाथ फाइंडिंग: “A और B कैसे जुड़े हैं?”
सामान्य प्रश्न:
- “इस ग्राहक से उस मर्चेंट तक सबसे छोटा पाथ क्या है?”
- “एलीस और बॉब को कौन-कौन से सहयोगी जोड़ते हैं, और कितने स्टेप्स में?”
- “3 हॉप के भीतर इस डिवाइस से उस खाते तक सभी रूट दिखाइए।”
यह ग्राहक समर्थन ("हमने यह क्यों सुझाया?"), अनुपालन ("ओनरशिप की चेन दिखाइए"), और जांचों ("यह कैसे फैला?") के लिए उपयोगी है।
2) कम्युनिटी डिटेक्शन: नेटवर्क के भीतर समूह और क्लस्टर्स
ग्राफ प्राकृतिक समूहों को पहचानने में मदद करते हैं:
- “कौन से ग्राहक साझा पते, फोन, और डिवाइसेज़ के आधार पर क्लस्टर बनाते हैं?”
- “हमारे सप्लायर नेटवर्क में कड़े समुदाय कहाँ हैं?”
आप इसे उपयोगकर्ता सेगमेंट करने, फ्रॉड क्रू ढूँढने, या यह समझने के लिए इस्तेमाल कर सकते हैं कि उत्पाद कैसे साथ में खरीदे जाते हैं। “ग्रुप” की परिभाषा इस बात पर आधारित होती है कि चीज़ें कैसे जुड़ी हैं, न कि किसी एक कॉलम पर।
3) सेंट्रालिटी और इन्फ्लुएंस: महत्वपूर्ण नोड्स खोजें
कभी-कभी सवाल सिर्फ़ “कौन जुड़ा है” नहीं होता, बल्कि “कौन सबसे ज़्यादा मायने रखता है” होता है:
- “कौन सा खाता दूसरों के बीच सबसे ज़्यादा पाथ्स पर बैठता है?”
- “कौन सा उत्पाद दो ग्राहक सेगमेंट के बीच सबसे मजबूत ब्रिज है?”
ये केंद्रीय नोड अक्सर इन्फ्लुएंसर, महत्वपूर्ण इन्फ्रास्ट्रक्चर, या वह बॉटलनेक दिखाते हैं जिनकी निगरानी करनी चाहिए।
4) पैटर्न मैचिंग: “त्रिकोण ढूँढो” और “संदिग्ध रिंग्स खोजो”
ग्राफ रिपीटेबल शेप्स खोजने में बेहतरीन हैं:
- त्रिकोण: “A जानता है B को, B जानता है C को, और C जानता है A को।”
- रिंग्स: “खातों द्वारा लूप में फंड ट्रांसफर।”
साइक़र (एक सामान्य ग्राफ क्वेरी भाषा) में एक त्रिकोण पैटर्न ऐसा दिख सकता है:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
अगर आप कभी Cypher खुद न भी लिखें, तो यह उदाहरण दिखाता है कि क्यों ग्राफ्स समझने में सरल होते हैं: क्वेरी आपके मन में बनी तस्वीर की तरह ही पढ़ती है।
ग्राफ बनाम रिलेशनल: असली फर्क
रिलेशनल डेटाबेस उन चीज़ों के लिए बेहतरीन हैं जिनके लिए वे बनाए गए थे: ट्रांज़ैक्शन्स और अच्छी तरह संरचित रिकॉर्ड्स। अगर आपका डेटा टेबल्स में अच्छी तरह फिट बैठता है (customers, orders, invoices) और आप ज्यादातर IDs, फिल्टर्स, और एग्रीगेट्स से उसे पुनः प्राप्त करते हैं, तो रिलेशनल सिस्टम अक्सर सबसे सरल, सुरक्षित विकल्प होते हैं।
जॉइन समस्या यह नहीं कि “जॉइन्स बुरे हैं”—यह है डीप जॉइन्स
जॉइन्स तब ठीक होते हैं जब वे कभी-कभार और शैलो हों। फ़्रिक्शन तब शुरू होता है जब आपके सबसे महत्वपूर्ण सवालों के लिए हमेशा कई जॉइन्स की ज़रूरत हो, कई टेबल्स में।
उदाहरण:
- “कौन से ग्राहक उन विक्रेताओं से खरीदे हैं जो इस सप्लायर से दो इंटरमीडियरीज के जरिए जुड़े हैं?”
- “सभी डिवाइसेज़ खोजिए जो इस खाते के करीबी संपर्कों द्वारा उपयोग किए गए नेटवर्क को साझा करते हैं।”
SQL में, ये लंबे क्वेरीज और बार-बार सेल्फ-जोइन में बदल सकते हैं और पाथ की डेप्थ बढ़ने पर ट्यून करना मुश्किल हो सकता है।
ग्राफ मल्टी-स्टेप “वॉक्स” को फर्स्ट-क्लास ऑपरेशन बनाते हैं
ग्राफ डेटाबेस रिलेशनशिप्स को स्पष्ट रूप से स्टोर करते हैं, इसलिए कनेक्शन्स पर कई स्टेप्स की ट्रैवर्सल एक नैचुरल ऑपरेशन है। क्वेरी टाइम पर टेबल्स को जोड़ने के बजाय आप जुड़ी नोड्स और एजेज़ को ट्रैवर्स करते हैं।
इसका मतलब अक्सर:
- मल्टी-हॉप पैटर्न्स के लिए छोटा क्वेरीज़ (क्वेरी प्रश्न की तरह पढ़ती है)
- वेरिएबल-डेप्थ पाथ्स के लिए अधिक भविष्यवाणीय जटिलता (उदा., 2 से 6 हॉप्स)
एक व्यवहारिक नियम
अगर आपकी टीम अक्सर मल्टी-हॉप सवाल पूछती है—“जुड़ा हुआ,” “के माध्यम से,” “एक ही नेटवर्क में,” “N स्टेप्स के भीतर”—तो ग्राफ डेटाबेस पर विचार करने लायक है।
अगर आपका मुख्य वर्कलोड हाई-वॉल्यूम ट्रांज़ैक्शन्स, सख्त स्कीमाज़, रिपोर्टिंग, और सीधे जॉइन्स है, तो रिलेशनल आम तौर पर बेहतर डिफ़ॉल्ट रहता है। कई वास्तविक सिस्टम दोनों का उपयोग करते हैं; देखें /blog/practical-architecture-graph-alongside-other-databases।
जब ग्राफ डेटाबेस गलत टूल हो
सुरक्षित रूप से इटरेट करें
ग्राफ-भारी बदलावों के साथ प्रयोग करें, और अगर आपका मॉडल पुनर्विचार मांगे तो रोलबैक करें।
ग्राफ डेटाबेस तब चमकते हैं जब रिलेशनशिप्स “मुख्य इवेंट” हों। अगर आपकी ऐप का मूल्य कनेक्शन्स ट्रैवर्स करने पर निर्भर नहीं करता (कौन-कौन जानता है, चीज़ें कैसे संबंधित हैं, पाथ्स, नेबरहुड्स), तो ग्राफ अतिरिक्त जटिलता जोड़ सकता है बिना ज्यादा लाभ के।
सरल CRUD जिनमें ज्यादातर सिंगल-रिकॉर्ड लुकअप्स हों
अगर अधिकांश अनुरोध “ID से यूज़र प्राप्त करें,” “प्रोफ़ाइल अपडेट करें,” “ऑर्डर बनाएं” जैसे हैं और ज़रूरी डेटा एक रिकॉर्ड या एक छोटे, पूर्वानुमानित टेबल सेट में रहता है, तो ग्राफ डेटाबेस अक्सर अनावश्यक होगा। आप नोड्स और एजेस मॉडल करने, ट्रैवर्सल्स ट्यून करने, और नई क्वेरी स्टाइल सीखने में समय खर्च करेंगे—जबकि रिलेशनल डेटाबेस इस पैटर्न को कुशलता से और परिचित टूलिंग के साथ संभालता है।
रिपोर्टिंग/BI जो मुख्यतः एग्रीगेट्स हैं
डैशबोर्ड्स जो टोटल्स, औसत और समूहबद्ध मेट्रिक्स (महीने के अनुसार राजस्व, क्षेत्र के अनुसार ऑर्डर्स, चैनल द्वारा कन्वर्ज़न रेट) दिखाते हैं, आमतौर पर SQL और कॉलमनल एनालिटिक्स के लिए बेहतर फिट होते हैं। ग्राफ इंजन कुछ एग्रीगेट सवालों का जवाब दे सकते हैं, पर भारी OLAP-स्टाइल वर्कलोड के लिए वे शायद सबसे आसान या तेज़ रास्ता नहीं होते।
मजबूत ट्रांज़ैक्शनल ज़रूरतें और "SQL-नेटिव" फीचर्स
जब आप परिपक्व SQL फीचर्स पर निर्भर होते हैं—जटिल जॉइन्स के साथ सख्त constraints, एडवांस्ड इंडेक्सिंग स्ट्रैटेजीज़, स्टोरड प्रोसीज़र्स, या स्थापित ACID पैटर्न—तो रिलेशनल सिस्टम अक्सर नेचुरल फिट होते हैं। कई ग्राफ डेटाबेस ट्रांज़ैक्शन्स सपोर्ट करते हैं, पर आसपास का इकोसिस्टम और ऑपरेशनल पैटर्न आपकी टीम की आदतों से मेल नहीं खा सकते।
ज्यादातर स्वतंत्र रिकॉर्ड जिनमें कम अर्थपूर्ण लिंक हों
अगर आपका डेटा ज्यादातर स्वतंत्र एंटिटीज़ (टिकट्स, इनवॉइस, सेंसर रीडिंग्स) का सेट है जिनमें सीमित क्रॉस-लिंकिंग है, तो ग्राफ मॉडल फोर्स्ड लग सकता है। ऐसे मामलों में क्लीन रिलेशनल स्कीमा (या डॉक्युमेंट मॉडल) पर ध्यान दें और बाद में तभी ग्राफ पर विचार करें जब रिलेशनशिप-भारी प्रश्न केंद्र में आ जाएँ।
एक अच्छा नियम: अगर आप अपने टॉप क्वेरीज को बिना “connected,” “path,” “neighborhood,” या “recommend” जैसे शब्दों के बयान कर सकते हैं, तो ग्राफ डेटाबेस शायद सही पहली पसंद नहीं है।
चुनने से पहले जानने योग्य ट्रेड-ऑफ्स
ग्राफ डेटाबेस उन जगहों पर तेज़ होते हैं जहाँ आपको कनेक्शन्स जल्दी फॉलो करने होते हैं—पर इस ताकत की कीमत भी होती है। कमिट करने से पहले यह समझना मददगार है कि ग्राफ्स कहाँ कम कुशल, महंगे, या रोज़मर्रा चलाने में अलग होते हैं।
लागत और फ़ुटप्रिंट
ग्राफ डेटाबेस अक्सर रिलेशनशिप्स को इस तरह स्टोर और इंडेक्स करते हैं कि हॉप्स तेज़ हों। ट्रेड-ऑफ यह है कि वे तुलनात्मक रिलेशनल सेटअप से मेमोरी और स्टोरेज में अधिक खरा हो सकते हैं, खासकर जब आप सामान्य लुकअप्स के लिए इंडेक्स जोड़ते हैं और रिलेशनशिप डेटा तुरंत उपलब्ध रखते हैं।
हर क्वेरी तेज़ नहीं होती
अगर आपका वर्कलोड स्प्रेडशीट जैसा है—बड़े टेबल-लाइक स्कैन्स, मिलियन्स की पंक्तियों पर रिपोर्टिंग क्वेरीज़, या भारी एग्रीगेशन—तो ग्राफ डेटाबेस वही परिणाम धीमे या महंगे तरीके से दे सकता है। ग्राफ्स ट्रैवर्सल्स के लिए ऑप्टिमाइज़्ड होते हैं (“कौन किससे जुड़ा है?”), न कि स्वतंत्र रिकॉर्ड्स के बड़े बैच्स को crunch करने के लिए।
ऑपरेशनल अंतर
ऑपरेशनल जटिलता एक वास्तविक कारक हो सकती है। बैकअप, स्केलिंग, और मोनिटरिंग उन चीज़ों से अलग होती हैं जिनके साथ कई टीमें रिलेशनल सिस्टम्स के साथ अभ्यस्त हैं। कुछ ग्राफ प्लेटफ़ॉर्म्स बेहतर तरीके से scale-up करते हैं (बड़े मशीनें), जबकि अन्य scale-out सपोर्ट करते हैं पर कंसिस्टेंसी, रेप्लिकेशन, और क्वेरी पैटर्न के आसपास सावधानीपूर्वक योजना की ज़रूरत होती है।
स्किल्स और टूलिंग
आपकी टीम को नए मॉडलिंग पैटर्न और क्वेरी अपप्रोच सीखने में समय लग सकता है (उदा., प्रॉपर्टी ग्राफ मॉडल और Cypher जैसी भाषाएँ)। लर्निंग कर्व संभालने योग्य है, पर यह भी एक लागत है—खासकर अगर आप परिपक्व SQL-आधारित रिपोर्टिंग वर्कफ़्लोज़ को बदल रहे हैं।
एक व्यवहारिक दृष्टिकोण यह है कि जहाँ रिलेशनशिप्स प्रोडक्ट हैं वहाँ ग्राफ का उपयोग करें, और रिपोर्टिंग, एग्रीगेशन, और टैबुलर एनालिटिक्स के लिए मौजूद सिस्टम रखें।
डेटा मॉडलिंग के बुनियादी सिद्धांत: नोड्स, एजेस, और स्कीमाज़
बिल्ड लागत कम करें
Koder.ai के साथ आपने जो बनाया उसे साझा करने या साथियों को रेफ़र करने पर क्रेडिट पाएं।
ग्राफ मॉडलिंग को सोचने का एक उपयोगी तरीका सरल है: नोड्स चीज़ें हैं, और एजेस चीज़ों के बीच रिश्ते हैं। लोग, खाते, डिवाइसेज़, ऑर्डर, प्रोडक्ट, लोकेशन—ये नोड्स हैं। “Bought,” “logged in from,” “works with,” “is parent of”—ये एजेस हैं।
प्रॉपर्टी ग्राफ बनाम RDF ट्रिपल्स
अधिकांश प्रोडक्ट-फोकस्ड ग्राफ डेटाबेस प्रॉपर्टी ग्राफ मॉडल का उपयोग करते हैं: नोड्स और एजेस दोनों प्रॉपर्टीज़ (की–वैल्यू फ़ील्ड्स) रख सकते हैं। उदाहरण के लिए, एक PURCHASED एज date, amount, और channel रख सकती है। यह “डिटेल्स वाले रिलेशनशिप्स” को मॉडल करना नेचुरल बनाता है।
RDF ज्ञान को ट्रिपल्स के रूप में पेश करता है: subject – predicate – object। यह इंटरऑपरेबल शब्दावली और सिस्टम्स के बीच डेटा लिंक करने के लिए अच्छा है, पर यह अक्सर “रिलेशनशिप डिटेल्स” को अतिरिक्त नोड्स/ट्रिपल्स में शिफ्ट कर देता है। व्यवहार में, आप देखेंगे कि RDF आपको मानक ओंटोलॉजीज़ और SPARQL पैटर्न की ओर धकेलता है, जबकि प्रॉपर्टी ग्राफ ऐप्लिकेशन-डेटा मॉडलिंग के करीब लगता है।
सरल शब्दों में क्वेरी भाषाएँ
- Cypher (प्रॉपर्टी ग्राफ्स में लोकप्रिय) उस पैटर्न की तरह पढ़ता है जिसे आप ढूँढना चाहते हैं: “(Customer)-[PURCHASED]->(Product).”
- Gremlin अधिक स्टेप-बाय-स्टेप ट्रैवर्सल जैसा है: यहाँ से शुरू करें, ऐसे एजेस चला कर जायें, फ़िल्टर करें, फिर एग्रीगेट करें।
- SPARQL RDF दुनिया की क्वेरी भाषा है, जो ट्रिपल्स पर पैटर्न मैच करती है और अक्सर साझा वोकैबुलरियों का उपयोग करती है।
शुरू में सिंटैक्स याद करने की ज़रूरत नहीं है—जो मायने रखता है वह यह है कि ग्राफ क्वेरीज आमतौर पर पाथ्स और पैटर्न्स के रूप में व्यक्त की जाती हैं, न कि टेबल्स को जोड़ने के रूप में।
ग्राफ सिस्टम्स में “स्कीमा” का मतलब
ग्राफ अक्सर स्कीमा-फ्लेक्सिबल होते हैं, यानी आप बिना भारी माइग्रेशन के नया नोड लेबल या प्रॉपर्टी जोड़ सकते हैं। पर फ्लेक्सिबिलिटी में भी अनुशासन चाहिए: नामकरण कन्वेंशन्स, आवश्यक प्रॉपर्टीज़ (उदा., id), और रिलेशनशिप टाइप्स के नियम निर्धारित करें।
रिलेशनशिप टाइप्स, डायरेक्शन, और प्रॉपर्टीज़
ऐसे रिलेशनशिप टाइप चुनें जो मतलब बताएं (“FRIEND_OF” बनाम “CONNECTED”)। अर्थ स्पष्ट करने के लिए दिशा का उपयोग करें (उदा., follower से creator की ओर FOLLOWS), और जब रिलेशनशिप के अपने फैक्ट हों तो एज प्रॉपर्टीज़ जोड़ें (समय, कॉन्फिडेंस, रोल, वेट)।
कैसे तय करें कि आपकी समस्या रिलेशनशिप-ड्रिवेन है
एक समस्या “रिलेशनशिप-ड्रिवेन” तब होती है जब कठिनाई रिकॉर्ड्स स्टोर करने में नहीं है—बल्कि यह समझने में है कि चीज़ें कैसे जुड़ी हैं, और वे कनेक्शन्स किस पाथ के आधार पर अर्थ बदलती हैं।
तालिकाओं के बजाय सवालों से शुरू करें
सबसे पहले अपने टॉप 5–10 सवाल सरल भाषा में लिखें—वे जो स्टेकहोल्डर्स बार-बार पूछते हैं और जिन्हें आपका वर्तमान सिस्टम धीरे या असंगत रूप से जवाब देता है। अच्छे ग्राफ उम्मीदवार अक्सर ऐसे वाक्यांशों को शामिल करते हैं जैसे “connected to,” “through,” “similar to,” “within N steps,” या “who else.”
उदाहरण:
- “कौन से ग्राहक साझा डिवाइसेज़ और पतों के जरिए इस फ्रॉड रिंग से जुड़े हैं?”
- “वे कौन से उत्पाद हैं जो लोग X को देखकर अक्सर खरीदते हैं?”
- “यदि यह फैक्टरी ऑफ़लाइन हो जाए तो किन सप्लायर्स पर अप्रत्यक्ष प्रभाव पड़ेगा?”
सवाल को एंटिटीज़ और इंटरैक्शन्स में ट्रांसलेट करें
एक बार जब आपके पास सवाल हों, तो नाउन्स और वर्ब्स को मैप करें:
- प्रमुख एंटिटीज़ नोड्स बन जाती हैं (Customer, Account, Device, Product, Supplier)।
- इंटरैक्शंस रिलेशनशिप्स बन जाती हैं (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES)।
फिर तय करें कि क्या कुछ रिलेशनशिप के बजाय नोड होना चाहिए। एक व्यावहारिक नियम: अगर किसी चीज़ को अपने गुण चाहिए और आप उसे कई पार्टियों से जोड़ना चाहेंगे, तो उसे नोड बनाइए (उदा., Order या Login event जब उसमें डिटेल्स हों और वह कई एंटिटीज़ से जुड़ा हो)।
फ़िल्टरिंग और स्कोरिंग को आसान बनाइए
ऐसी प्रॉपर्टीज़ जोड़ें जो बिना अतिरिक्त जॉइन्स या पोस्ट-प्रोसेसिंग के परिणामों को संकुचित और रैंक करने दें। सामान्य उच्च-मूल्य वाली प्रॉपर्टीज़ में time, amount, status, channel, और confidence score शामिल हैं।
यदि आपके महत्वपूर्ण प्रश्नों में मल्टी-स्टेप कनेक्शन्स के साथ उन प्रॉपर्टीज़ द्वारा फ़िल्टर करना और रैंक करना शामिल है, तो आप संभवतः एक रिलेशनशिप-ड्रिवेन समस्या संभाल रहे हैं जहाँ ग्राफ डेटाबेस चमक सकता है।
व्यावहारिक आर्किटेक्चर: ग्राफ को अन्य डेटाबेस के साथ रखना
अधिकांश टीमें सब कुछ ग्राफ से बदलकर नहीं चलातीं। एक अधिक व्यावहारिक तरीका यह है कि आपका “सिस्टम ऑफ़ रिकॉर्ड” वहीं रखें जहाँ वह पहले से अच्छा काम कर रहा है (अक्सर SQL), और रिलेशनशिप-भारी सवालों के लिए ग्राफ डेटाबेस को एक विशिष्ट इंजन के रूप में उपयोग करें।
सोर्स ऑफ़ ट्रुथ SQL में रखें (या आपका कोर डेटास्टोर)
ट्रांज़ैक्शन्स, constraints, और कानोनिकल एंटिटीज़ (customers, orders, accounts) के लिए रिलेशनल डेटाबेस का उपयोग करें। फिर रिलेशनशिप व्यू को ग्राफ डेटाबेस में प्रोजेक्ट करें—सिर्फ़ वही नोड्स और एजेस जो जुड़े हुए क्वेरीज के लिए ज़रूरी हैं।
यह ऑडिटिंग और डेटा गवर्नेंस को सरल रखता है जबकि तेज़ ट्रैवर्सल क्वेरीज अनलॉक करता है।
एक फीचर के लिए ग्राफ बनाइए, पूरे कंपनी के लिए नहीं
एक ग्राफ डेटाबेस तब सबसे बेहतर होता है जब आप इसे किसी स्पष्ट स्कोप वाले फीचर से जोड़ें, जैसे:
- सिफारिशें (“जिन लोगों ने X खरीदा उन्हें Y भी पसंद आया”)
- रिस्क स्कोरिंग (फ्रॉड रिंग्स, साझा डिवाइसेज़, सामान्य पेमेंट इंस्ट्रूमेंट)
- आइडेंटिटी रिज़ॉल्यूशन (सिस्टम्स के across प्रोफाइल्स लिंक करना)
एक फीचर, एक टीम, और एक मापनीय परिणाम से शुरू करें। अगर यह मान्य होता है तो आप बाद में बढ़ा सकते हैं।
अगर आपकी बाधा प्रोटोटाइप शिप करने में है (मॉडल पर बहस नहीं), तो एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai आपकी मदद कर सकता है ताकि आप तेज़ी से एक साधारण ग्राफ-पावर्ड ऐप खड़ा कर सकें: आप चैट में फीचर बताइए, React UI और Go/PostgreSQL बैकएंड जनरेट करें, और तब तक इटरेट करें जब तक आपकी डेटा टीम ग्राफ स्कीमा और क्वेरीज को मान्य न कर दे।
सिंक स्ट्रैटेजीज़: बैच बनाम नियर-रियल-टाइम
ग्राफ को कितना ताज़ा रखना है?
- बैच अपडेट्स (घंटेवारी/नाइटली) सरल होते हैं और अक्सर एनालिटिक्स, डिस्कवरी, और कई सिफारिश इंजन के लिए पर्याप्त होते हैं।
- नियर-रियल-टाइम स्ट्रीम्स (मिनटों/सेकंडों) फ्रॉड डिटेक्शन ग्राफ्स और ऑपरेशनल निर्णयों के लिए फिट बैठते हैं।
एक सामान्य पैटर्न: ट्रांज़ैक्शन्स SQL में लिखें → चेंज इवेंट्स प्रकाशित करें → ग्राफ अपडेट करें।
सुसंगत आइडेंटिफ़ायर्स और स्पष्ट ओनरशिप
ID ड्रिफ्ट होने पर ग्राफ गन्दा हो जाता है।
स्टेबल आइडेंटिफ़ायर्स (उदा., customer_id, account_id) परिभाषित करें जो सिस्टम्स में मेल खाते हों, और दस्तावेज़ करें कि कौन सा सिस्टम किस फ़ील्ड और रिलेशनशिप का “मालिक” है। अगर दो सिस्टम एक ही एज बना सकते हैं (मान लें, “knows”), तो तय करें कि कौन जीतेगा।
यदि आप पायलट की योजना बना रहे हैं, तो /blog/getting-started-a-low-risk-pilot-plan देखें एक चरणबद्ध रोलआउट दृष्टिकोण के लिए।
शुरुआत कैसे करें: एक कम-जोखिम पायलट योजना
परिणाम का स्वामित्व लें
जब आपका पायलट मुख्य repo के लिए तैयार हो, तो सोर्स कोड एक्सपोर्ट के साथ नियंत्रण रखें।
एक ग्राफ पायलट प्रयोग जैसा होना चाहिए, पुनः-लेखन जैसा नहीं। लक्ष्य यह साबित (या खंडित) करना है कि रिलेशनशिप-भारी क्वेरीज सरल और तेज़ हो जाती हैं—बगैर पूरे डेटा स्टैक पर दांव लगाए।
1) एक छोटा, उच्च-मूल्य वाला स्लाइस चुनें
पहले ऐसे सीमित डेटासेट से शुरू करें जो पहले से ही दर्द देता हो: बहुत सारे JOINs, भंगुर SQL, या धीमे “कौन किससे जुड़ा है?” सवाल। इसे एक वर्कफ़्लो तक सीमित रखें (उदा.: customer ↔ account ↔ device, या user ↔ product ↔ interaction) और कुछ क्वेरीज परिभाषित करें जिन्हें आप एंड-टू-एंड आंसर करना चाहते हैं।
2) निर्माण से पहले सफलता के मेट्रिक्स परिभाषित करें
सिर्फ़ स्पीड ही मापिए मत:
- क्वेरी जटिलता: आज बनाम ग्राफ में इसे व्यक्त करने के लिए कितनी लाइनों, जॉइन्स, या मध्यवर्ती टेबल्स की ज़रूरत है?
- लेटेंसी: वास्तविक डेटा वॉल्यूम पर परिणाम लौटने का समय।
- डेवलपर समय: जब आवश्यकताएँ बदलती हैं तो क्वेरीज बनाने और बदलने में कितना समय लगता है?
अगर आप “पहले” की संख्याएँ नहीं लिख सकते, तो आप “बाद” पर भरोसा नहीं करेंगे।
3) मॉडल उद्देश्यपूर्ण रखें (ग्राफ स्प्रॉल से बचें)
सब कुछ नोड्स और एजेस के रूप में मॉडल करने का प्रलोभन होता है। उससे बचें। “ग्राफ स्प्रॉल” तब होता है जब बहुत सारे नोड/एज टाइप बिना किसी स्पष्ट क्वेरी के हों। हर नए लेबल या रिलेशनशिप को उसकी जगह साबित करनी चाहिए—यानी वह वास्तविक प्रश्न सक्षम करे।
4) गवर्नेंस को पायलट का हिस्सा मानें
प्राइवेसी, एक्सेस कंट्रोल, और डेटा रिटेंशन के लिए योजना बनाइए। रिलेशनशिप डेटा व्यक्तिगत रिकॉर्ड्स से ज़्यादा कुछ खुलासा कर सकता है (उदा., ऐसे कनेक्शन्स जो व्यवहार का संकेत देते हैं)। परिभाषित करें कि कौन क्या क्वेरी कर सकता है, परिणाम कैसे ऑडिट होंगे, और आवश्यकतानुसार डेटा कैसे डिलीट होगा।
5) इसे अपने मौजूदा डेटाबेस के साथ चलाइए
ग्राफ में फ़ीड करने के लिए एक आसान सिंक (बैच या स्ट्रीमिंग) इस्तेमाल करें जबकि आपका मौजूदा सिस्टम स्रोत का सत्य बना रहे। जब पायलट मूल्य सिद्ध कर दे तो आप धीरे-धीरे स्कोप बढ़ा सकते हैं—ध्यान से, एक उपयोग-मामला प्रति बार।
त्वरित निर्णय चेकलिस्ट: रिश्तों के लिए ग्राफ का उपयोग करें
यदि आप डेटाबेस चुन रहे हैं, तो टेक्नोलॉजी से शुरू न करें—उन सवालों से शुरू करें जिनका आपको जवाब चाहिए। ग्राफ डेटाबेस तब चमकते हैं जब आपकी सबसे कठिन समस्याएँ कनेक्शन्स और पाथ्स के बारे में हों, सिर्फ रिकॉर्ड स्टोर करने के बारे में नहीं।
क्या यह रिलेशनशिप-ड्रिवेन है? एक त्वरित चेकलिस्ट
- रिलेशनशिप डेप्थ: क्या आपको नियमित रूप से संबंधों को 2+ हॉप्स (A→B→C→D) तक फॉलो करना पड़ता है?
- क्वेरी पैटर्न्स: क्या आपके प्रमुख सवाल पैटर्न्स के बारे में हैं (उदा., “एक ही नियोक्ता और फोन साझा करने वाले लोग”) बजाय सिंगल-टेबल फिल्टर्स के?
- अपडेट फ़्रीक्वेंसी: क्या रिलेशनशिप्स अक्सर बदलती हैं, और क्या आपको उन बदलावों को जल्दी दिखाना होता है?
- स्केल: क्या डेटासेट इतना बड़ा है कि कई टेबल्स को जोइन करना (या एप्लिकेशन कोड में जोड़ना) धीमा, महंगा, या नाज़ुक हो रहा है?
यदि आपने इनका अधिकांश उत्तर “हाँ” में दिया, तो ग्राफ एक मजबूत फिट हो सकता है—खासकर जब आपको मल्टी-हॉप पैटर्न मैचिंग चाहिए जैसे:
- “दो एंटिटीज़ के बीच सबसे छोटा पाथ ढूँढो।”
- “3 स्टेप्स के भीतर इस डिवाइस से जुड़े सभी अकाउंट दिखाइए।”
- “शेयर किए गए नेबरहुड्स पर आधारित आइटम सुझाव दीजिए, सिर्फ़ श्रेणियों पर नहीं।”
कब SQL/NoSQL के साथ बनी रहना चाहिए
अगर आपका काम ज्यादातर सिंपल लुकअप्स (ID/email से) या एग्रीगेशंस (“महीने द्वारा कुल बिक्री”) है, तो रिलेशनल डेटाबेस या की-वैल्यू/डॉक्यूमेंट स्टोर आमतौर पर सरल और सस्ता होता है।
निर्णय को कैसे कम जोखिम बनाएं
अपने टॉप 10 बिजनेस सवालों को साधारण वाक्यों में लिखें, फिर उन्हें असली डेटा पर छोटे पायलट में टेस्ट करें। क्वेरीज का समय लें, लिखिए किन चीज़ों को व्यक्त करना कठिन रहा, और मॉडल बदलने की छोटी लॉग रखें। अगर आपका पायलट ज़्यादातर “और जॉइन्स” या “और कैशिंग” में बदलता है, तो यह संकेत है कि ग्राफ फायदेमंद हो सकता है। अगर यह ज़्यादातर काउंट्स और फिल्टर्स बनता है, तो शायद नहीं।