04 जून 2025·8 मिनट
क्यों हॉरिज़ॉन्टल स्केलिंग वर्टिकल स्केलिंग से ज़्यादा कठिन है
वर्टिकल स्केलिंग अक्सर सिर्फ़ CPU/RAM बढ़ाना होता है। हॉरिज़ॉन्टल स्केलिंग में समन्वय, पार्टिशनिंग, संगति और ऑपरेशनल काम ज़्यादा होता है—यही कारण है कि यह कठिन है।
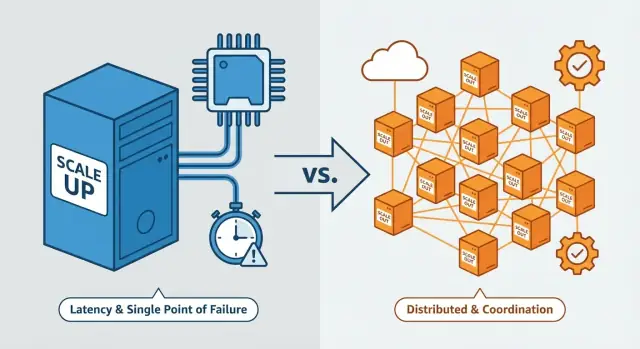
वर्टिकल स्केलिंग अक्सर सिर्फ़ CPU/RAM बढ़ाना होता है। हॉरिज़ॉन्टल स्केलिंग में समन्वय, पार्टिशनिंग, संगति और ऑपरेशनल काम ज़्यादा होता है—यही कारण है कि यह कठिन है।
स्केलिंग का मतलब है “ज़्यादा चीज़ें हैंडल करना बिना गिरने के।” वह “ज़्यादा” कुछ भी हो सकता है:
जब लोग स्केलिंग की बात करते हैं, वे आमतौर पर इन में से एक या अधिक को बेहतर करना चाहते हैं:
इन सब का एक सामान्य विषय है: स्केल-अप से “एक एकल सिस्टम” जैसा अनुभव रखा जाता है, जबकि स्केल-आउट में आपका सिस्टम कई स्वतंत्र मशीनों का समन्वित समूह बन जाता है—और यही समन्वय है जहाँ कठिनाई बढ़ती है।
वर्टिकल स्केलिंग का मतलब एक मशीन को शक्तिशाली बनाना है। आप उसी आर्किटेक्चर को रखते हैं, लेकिन सर्वर (या VM) को अपग्रेड करते हैं: ज़्यादा CPU कोर, ज़्यादा RAM, तेज़ डिस्क, ऊँचा नेटवर्क थ्रूपुट।
इसे बड़े ट्रक खरीदने की तरह सोचिए: ड्राइवर और वाहन वही हैं, बस वह ज़्यादा सामान ले जाता है।
हॉरिज़ॉन्टल स्केलिंग का मतलब है और मशीनें/इंस्टेंस जोड़ना और काम को इनके बीच बाँटना—अक्सर लोड बैलेंसर के पीछे। एक मजबूत सर्वर की बजाय आप कई सर्वर चलाते हैं जो मिलकर काम करते हैं।
यह कई ट्रकों का उपयोग करने जैसा है: कुल मिलाकर ज़्यादा सामान ले जा सकते हैं, लेकिन अब शेड्यूलिंग, रूटिंग और समन्वय की चिंता होती है।
सामान्य ट्रिगर्स में शामिल हैं:
टीमें अक्सर पहले स्केल-अप करती हैं क्योंकि यह तेज़ है (बॉक्स अपग्रेड करें), फिर जब एक मशीन की सीमा आ जाती है या ऊँची उपलब्धता चाहिए तो स्केल-आउट करती हैं। परिपक्व आर्किटेक्चर आमतौर पर दोनों मिलाकर चलते हैं: बडे़ नोड और अधिक नोड, बॉटलनेक के आधार पर।
वर्टिकल स्केलिंग आकर्षक है क्योंकि यह आपका सिस्टम एक जगह पर रखती है। एक नोड में, आमतौर पर मेमोरी और लोकल स्टेट का एक ही स्रोत होता है। एक प्रोसेस इन-मेमोरी कैश, जॉब क्यू, सेशन स्टोर (यदि सेशन्स मेमोरी में हैं) और अस्थायी फाइलें नियंत्रित करता है।
एक सर्वर पर अधिकांश ऑपरेशन्स सीधे होते हैं क्योंकि इंटर-नोड समन्वय बहुत कम होता है:
जब आप स्केल-अप करते हैं, आप परिचित लीवर्स खींचते हैं: CPU/RAM बढ़ाएँ, तेज़ स्टोरेज इस्तेमाल करें, इंडेक्स सुधारें, क्वेरीज और कन्फिग्रेशन ट्यून करें। आपको यह नहीं बदलना पड़ता कि डेटा कैसे वितरित होता है या कई नोड्स "अगला क्या होगा" पर कैसे सहमत होते हैं।
वर्टिकल स्केलिंग “मुफ़्त” नहीं है—यह बस जटिलता को सीमित रखती है।
अंत में आप सीमाओं पर पहुँच जाते हैं: सबसे बड़ा इंस्टेंस जो आप किराए पर ले सकते हैं, घटती वापसी, या ऊँची लागत वक्र। आप अधिक डाउनटाइम रिस्क भी लेते हैं: यदि एक बड़ा मशीन फेल हो जाए या मेंटेनेंस में जाए तो सिस्टम का बड़ा हिस्सा प्रभावित होगा जब तक आपने redundancy नहीं जोड़ी हो।
जब आप स्केल-आउट करते हैं, आपको सिर्फ "ज़्यादा सर्वर" नहीं मिलते। आपको अधिक स्वतंत्र एक्टर्स मिलते हैं जिन्हें तय करना होता है कि किसका जिम्मा कौन सा काम संभालेगा, किस समय और किस डेटा के साथ।
एक मशीन पर समन्वय अक्सर निहित होता है: एक मेमोरी स्पेस, एक प्रोसेस, एक जगह स्टेट देखने के लिए। कई मशीनों में समन्वय को एक फीचर समझ कर डिज़ाइन करना पड़ता है।
आम टूल और पैटर्न में शामिल हैं:
समन्वय की बग अक्सर साफ क्रैश की तरह नहीं दिखतीं। ज़्यादातर बार आप देखते हैं:
ये समस्याएँ अक्सर वास्तविक लोड, डिप्लॉयमेंट्स या आंशिक विफलताओं के दौरान ही दिखती हैं। सिस्टम सामान्य दिखता है—जब तक कि वह तनाव में न आए।
जब आप स्केल-आउट करते हैं, अक्सर आप सभी डेटा को एक जगह नहीं रख सकते। आप इसे मशीनों के बीच बाँटते हैं (शार्ड्स) ताकि कई नोड्स समानांतर में स्टोर और सर्व कर सकें। यही विभाजन जटिलता की शुरुआत है: हर रीड और राइट का सवाल होता है “यह रिकॉर्ड किस शार्ड पर है?”
रेंज पार्टिशनिंग ordered key के आधार पर डेटा को समूहित करती है (उदा. यूज़र्स A–F शार्ड 1 पर, G–M शार्ड 2 पर)। यह सहज है और रेंज क्वेरीज को बेहतर सपोर्ट करती है। खराबी यह है कि लोड असमान हो सकता है: यदि एक रेंज लोकप्रिय हो जाए तो वह शार्ड बोझ बन जाता है।
हैश पार्टिशनिंग किसी की को एक हैश फ़ंक्शन से गुज़ार कर शार्ड्स में वितरित करती है। यह ट्रैफ़िक को अधिक समान रूप से फैलाती है, पर रेंज क्वेरीज को कठिन बनाती है क्योंकि संबंधित रिकॉर्ड बिखरे होते हैं।
नोड जोड़ें और आप उसे इस्तेमाल करना चाहेंगे—इसका मतलब कुछ डेटा मूव होगा। नोड हटाएँ (योजनाबद्ध या फेल होने पर) और दूसरे शार्ड्स को ओवरले लेना होगा। रीबैलेंसिंग बड़े स्थानांतरण, कैश वार्म-अप और अस्थायी परफ़ॉर्मेंस ड्रॉप ट्रिगर कर सकती है। मूव के दौरान आपको स्टेल रीड्स और मिसराउटेड राइट्स रोकनी होंगी।
हैशिंग के साथ भी, असली ट्रैफ़िक यूनिफ़ॉर्म नहीं रहता। कोई सिलेबरिटी अकाउंट, लोकप्रिय प्रोडक्ट, या समय-आधारित पैटर्न पढ़/लिख के अनुरोधों को एक शार्ड पर केंद्रित कर सकता है। एक हॉट शार्ड पूरे सिस्टम की थ्रूपुट को सीमित कर सकता है।
शार्डिंग निरंतर ज़िम्मेदारियाँ लाती है: राउटिंग नियम बनाये रखना, माइग्रेशन चलाना, स्कीमा बदलाव के बाद बैकफिल करना, और क्लाइंट्स को तोड़े बिना स्प्लिट/मर्ज की योजना बनाना।
जब आप स्केल-आउट करते हैं, आप सिर्फ़ और सर्वर नहीं जोड़ते—आप अपने एप्लिकेशन की और प्रतियाँ जोड़ देते हैं। मुश्किल हिस्सा है स्टेट: कुछ भी जो आपका ऐप अनुरोधों के बीच "याद" रखता है या काम के दौरान।
यदि यूज़र सर्वर A पर लॉगिन करता है लेकिन अगला अनुरोध सर्वर B पर जाता है, तो क्या B उसे पहचानता है?
कैश चीज़ों को तेज़ बनाते हैं, पर कई सर्वरों का मतलब कई कैश। अब आप इन्हें संभालते हैं:
कई वर्कर्स के साथ, बैकग्राउंड जॉब दो बार चल सकता है यदि आपने डिजाइन नहीं किया। आमतौर पर आपको क्यू, लीज़/लॉक्स या आइडेम्पोटेंट जॉब लॉजिक चाहिए ताकि “इनवॉयस भेजो” या “कार्ड चार्ज करो” दो बार न हो—खासतौर पर रीट्राई और रीस्टार्ट के दौरान।
एक अकेले नोड (या एक प्राथमिक DB) में आमतौर पर स्पष्ट “सत्य का स्रोत” होता है। जब आप स्केल-आउट करते हैं, डेटा और अनुरोध विभिन्न मशीनों में फैलते हैं, और सबको सिंक में रखना लगातार चिंता बन जाता है।
इवञ्चुअल संगति अक्सर तेज़ और सस्ती होती है, पर यह अचरज भरे कोनों को जन्म देती है।
आम समस्याएँ:
आप विफलताओं को मिटा नहीं सकते, पर आप उनके लिए डिज़ाइन कर सकते हैं:
सर्विसेज़ (ऑर्डर + इन्वेंट्री + पेमेंट) के पार एक ट्रांज़ैक्शन में कई सिस्टम्स का सहमति चाहिए। अगर कोई स्टेप बीच में फेल हो जाए, तो आपको कम्पेन्सेटिंग कार्रवाइयाँ और सावधानीपूर्वक बहीखाता चाहिए। क्लासिक “सब-या-कुछ नहीं” व्यवहार नेटवर्क और नोड्स की स्वतंत्र विफलताओं में कठिन हो जाता है।
वे चीज़ें जिनका सही होना अनिवार्य है: पेमेंट्स, अकाउंट बैलेंस, इन्वेंट्री काउंट्स, सीट रिज़र्वेशन. कम महत्वपूर्ण डेटा (एनालिटिक्स, रिकमेंडेशन) के लिए इवञ्चुअल संगति अक्सर स्वीकार्य है।
जब आप स्केल-अप करते हैं, कई कॉल वही प्रक्रिया के फ़ंक्शन कॉल होते हैं: तेज़ और भविष्यवाणीयोग्य। जब आप स्केल-आउट करते हैं, वही इंटरैक्शन नेटवर्क कॉल बन जाता है—जिससे लैटेंसी, जिटर और ऐसे विफलता मोड आते हैं जिनसे आपका कोड निपटना चाहिए।
नेटवर्क कॉल में फिक्स्ड ओवरहेड (सीरियलाइज़ेशन, कतारबद्धी, हॉप्स) और वैरियेबल ओवरहेड (कंजेशन, रूटिंग, noisy neighbors) होता है। भले औसत विलंबता ठीक हो, पर टेल विलंबता (सबसे धीमे 1–5%) उपयोगकर्ता अनुभव को हावी कर सकती है क्योंकि एक धीमा निर्भरता पूरी रिक्वेस्ट को रोक देता है।
बैंडविड्थ और पैकेट लॉस भी बाधाएँ बन जाते हैं: उच्च अनुरोध दरों पर "छोटी" payloads जोड़कर बड़ी बन जाती हैं, और रिट्रांसमिट्स धीरे-धीरे लोड बढ़ाते हैं।
बिना टाइमआउट के, धीमे कॉल जमा हो जाते हैं और थ्रेड्स अटक जाते हैं। टाइमआउट्स और रीट्राई से आप ठीक हो सकते हैं—जब तक कि रीट्राई लोड को बढ़ा कर समस्या को और बिगाड़ न दे।
एक सामान्य फेलियर पैटर्न है रीट्राई श्टॉर्म: बैकएंड धीमा होता है, क्लाइंट टाइमआउट कर के रीट्राई करता है, रीट्राईज़ लोड बढ़ाती हैं, और बैकएंड और धीमा हो जाता है।
सुरक्षित रीट्राई के लिए अक्सर चाहिए:
कई इंस्टेंस होने पर क्लाइंट्स को पता होना चाहिए कि रिक्वेस्ट कहाँ भेजें—लोड बैलेंसर के जरिए या सर्विस डिस्कवरी + क्लाइंट-साइड बैलेंसिंग के जरिए। किसी भी तरह, आप मूविंग पार्ट्स जोड़ते हैं: हेल्थ चेक्स, कनेक्शन ड्रेनिंग, असमान ट्रैफ़िक वितरण, और आधे-टूटे इंस्टेंस की ओर रूटिंग का जोखिम।
ओवरलोड को फैलने से रोकने के लिए आपको बैकप्रेशर चाहिए: बाउंडेड क्यूज़, सर्किट ब्रेकर्स, और रेट लिमिटिंग। लक्ष्य है तेज़ और अनुमाननीय ढंग से फेल करना बजाय इसके कि एक छोटा धीमा हिस्सा पूरे सिस्टम को क्रैश कर दे।
वर्टिकल स्केलिंग साधारण तरीके से फेल होती है: एक बड़ा मशीन अभी भी एक सिंगल पॉइंट है। अगर वह धीमा या क्रैश हो जाए, असर स्पष्ट होता है।
हॉरिज़ॉन्टल स्केलिंग गणित बदल देता है। कई नोड्स में से कुछ का अनहेल्दी होना सामान्य हो जाता है जबकि बाकी ठीक हों। सिस्टम "अप" है, पर उपयोगकर्ताओं को फिर भी एरर, धीमी पेजेस या असंगत व्यवहार दिखाई दे सकता है। यह है आंशिक विफलता, और इसे डिज़ाइन का डिफ़ॉल्ट स्थिति मान कर काम करना पड़ता है।
एक स्केल-आउट सेटअप में, सर्विसेज़ अन्य सर्विसेज़ पर निर्भर रहती हैं: DB, 캐श, क्यूज़, डाउनस्ट्रीम APIs. एक छोटी समस्या लहर बन सकती है:
आंशिक विफलताओं से बचने के लिए सिस्टम रेडंडेंसी जोड़ते हैं:
यह उपलब्धता बढ़ाता है, पर किनारे के मामले लाते हैं: स्प्लिट-ब्रेन, स्टेल रेप्लिका, और तब क्या करें जब क्वोरम न बन पाए—इनके फ़ैसले करने होते हैं।
आम पैटर्न:
एक मशीन में, सिस्टम की कहानी एक जगह रहती है: एक सेट लॉग्स, एक CPU ग्राफ, एक प्रोसेस। हॉरिज़ॉन्टल स्केल में कहानी बिखर जाती है।
हर अतिरिक्त नोड एक और लॉग, मैट्रिक और ट्रेस स्ट्रीम जोड़ता है। कठिनाई डाटा इकट्ठा करने में नहीं—बल्कि इसे कॉरिलेट करने में है। एक चेकआउट एरर वेब नोड पर शुरू हो सकती है, दो सर्विसेज़ को कॉल कर सकती है, कैश से टकरा सकती है, और एक विशिष्ट शार्ड से पढ़ सकती है—लगातार अलग जगहों पर सुराग छोड़ती हुई।
समस्याएँ चयनात्मक भी हो सकती हैं: एक नोड की गलत कॉन्फ़िग, एक शार्ड का हॉट होना, एक ज़ोन की अधिक लैटेंसी। डिबगिंग महसूस हो सकती है कि यह "अक्सर काम करता है" और तभी टूटता है।
वितरित ट्रेसिंग एक अनुरोध पर ट्रैकिंग नंबर लगाना जैसा है। कॉरिलेशन ID वही नंबर है। आप इसे सर्विसेज़ में पास करते हैं और लॉग में शामिल करते हैं ताकि आप एक ID लेकर एंड-टू-एंड यात्रा देख सकें।
अधिक घटक अक्सर अधिक अलर्ट लाते हैं। बिना ट्यूनिंग के टीमें अलर्ट थकान का शिकार हो जाती हैं। लक्ष्य है कार्यशील अलर्ट जो स्पष्ट करें:
क्षमता की समस्याएँ अक्सर विफलता से पहले दिखती हैं। CPU, मेमोरी, क्यू डैप्थ और कनेक्शन पूल उपयोग जैसे सैचुरेशन संकेत मॉनिटर करें। यदि सैचुरेशन केवल कुछ नोड्स पर दिखे तो बैलेंसिंग, शार्डिंग या कन्फिग्रेशन ड्रिफ्ट पर शक करें—सिर्फ़ "ज़्यादा ट्रैफ़िक" नहीं।
जब आप स्केल-आउट करते हैं, एक डिप्लॉय "एक बॉक्स बदलो" नहीं रह जाता। यह कई मशीनों में बदलाव समन्वित करने और सेवा उपलब्ध रखकर करना होता है।
हॉरिज़ॉन्टल डिप्लॉयमेंट्स अक्सर रोलिंग अपडेट्स (नोड्स को धीरे-धीरे बदलना), केनरी (छोटा हिस्सा ट्रैफ़िक को नई वर्ज़न पर भेजना), या ब्लू/ग्रीन (दो पूरे एनवायरनमेंट के बीच ट्रैफ़िक स्विच करना) का उपयोग करते हैं। ये ब्लास्ट रेडियस कम करते हैं, पर आवश्यकताएँ बढ़ती हैं: ट्रैफ़िक शिफ्टिंग, हेल्थ चेक्स, कनेक्शन ड्रेनिंग, और "अगेन प्रॉसीड" के लिए परिभाषा।
किसी भी क्रमिक डिप्लॉय के दौरान, पुराने और नए वर्ज़न साथ चलते हैं। उस वर्ज़न स्क्यू का मतलब है कि सिस्टम को मिश्रित व्यवहार सहन करना होगा:
APIs को बैकवार्ड/फॉरवर्ड संगत होना चाहिए, सिर्फ़ स correctness नहीं। DB स्कीमा बदलावों को संभवतः additive रखें (पहले nullable कॉलम जोड़ें, फिर आवश्यक बनाएं)। मैसेज फॉर्मैट्स को वर्ज़न करें ताकि कंज्यूमर्स पुराने और नए दोनों पढ़ सकें।
कोड रोलबैक आसान है; डेटा रोलबैक नहीं। यदि कोई माइग्रेशन फ़ील्ड drop या rewrite करता है, तो पुराना कोड क्रैश कर सकता है या रिकॉर्ड्स गलत हैंडल कर सकता है। “Expand/contract” माइग्रेशन्स मदद करती हैं: ऐसा कोड डिप्लॉय करें जो दोनों स्कीम्स सपोर्ट करे, डेटा माइग्रेट करें, फिर पुरानी पाथ्स हटाएँ।
कई नोड्स के साथ, कन्फिग मैनेजमेंट डिप्लॉय का हिस्सा बन जाता है। एक सिंगल नोड का stale कन्फिग, गलत फीचर फ्लैग, या एक्सपायर्ड क्रेडेंशियल्स फ्लेकी, मुश्किल-से-रिप्रोड्यूस होने वाली विफलताएँ बना सकते हैं।
हॉरिज़ॉन्टल स्केलिंग पेपर पर सस्ती दिख सकती है: कई छोटे इंस्टेंस, प्रत्येक कम घंटे का मूल्य। पर कुल लागत सिर्फ़ कंप्यूट नहीं है। नोड्स जोड़ने का मतलब अधिक नेटवर्किंग, अधिक मॉनिटरिंग, अधिक समन्वय, और सब कुछ लगातार सुसंगत रखने में अधिक समय है।
वर्टिकल स्केलिंग खर्च को कुछ ही मशीनों में केंद्रित करती है—अक्सर पैच करने के लिए कम होस्ट, चलाने के लिए कम एजेंट्स, भेजने के लिए कम लॉग्स, स्क्रैप करने के लिए कम मैट्रिक्स।
स्केल-आउट में प्रति-यूनिट कीमत कम हो सकती है, पर आप अक्सर भुगतान करते हैं:
स्पाइक्स संभालने के लिए वितरित सिस्टम अक्सर अधूरा चलते हैं। आपको कई स्तरों (वेब, वर्कर्स, DB, कैश) पर हेडरूम रखना पड़ता है, जिसका मतलब दर्जनों या सैकड़ों इंस्टेंस पर बासी क्षमता का भुगतान करना हो सकता है।
स्केल-आउट ऑन-कॉल लोड बढ़ाता है और परिपक्व टूलिंग की मांग करता है: अलर्ट ट्यूनिंग, रनबुक्स, इंसिडेंट ड्रिल्स, और ट्रेनिंग। टीमें ओनरशिप बॉउंड्रीज़ (किसका कौन सा सर्विस?) और इंसिडेंट समन्वय पर भी समय खर्च करती हैं।
परिणाम: "प्रति यूनिट सस्ता" कुल मिलाकर अधिक महंगा हो सकता है जब आप लोगों का समय, ऑपरेशनल रिस्क, और कई मशीनों को एक सिस्टम की तरह व्यवहर कराने का काम जोड़ते हैं।
स्केल-अप और स्केल-आउट के बीच चुनना सिर्फ़ कीमत का सवाल नहीं है। यह वर्कलोड के स्वरूप और आपकी टीम कितनी ऑपरेशनल जटिलता संभाल सकती है, इसके बारे में है।
वर्कलोड से शुरू करें:
एक सामान्य, समझदारी भरा रास्ता:
कई टीमें DB को वर्टिकली रखते हुए (या हल्का-क्लस्टर्ड) स्टेटलेस ऐप लेयर को हॉरिज़ॉन्टली स्केल करती हैं। इससे शार्डिंग का दर्द सीमित रहता है जबकि आप वेब क्षमता जल्दी जोड़ सकते हैं।
जब आपके पास मजबूत मॉनिटरिंग और अलर्ट्स, टेस्टेड फेलओवर, लोड टेस्ट्स, और रिपीटेबल डिप्लॉयमेंट्स हों जिनमें सुरक्षित रोलबैक हो—तब आप स्केल-आउट के करीब हैं।
कई स्केलिंग दर्द सिर्फ़ "आर्किटेक्चर" नहीं हैं—यह ऑपरेशनल लूप है: सुरक्षित तरीके से इटरेट करना, भरोसेमंद तैनाती, और जब योजना अस्वीकार करे तो तेज़ी से रोलबैक करना।
यदि आप वेब, बैकएंड, या मोबाइल सिस्टम बना रहे हैं और जल्दी बढ़ना चाहते हैं बिना कंट्रोल खोए, तो Koder.ai आपको प्रोटोटाइप और शिप करने में तेज़ी से मदद कर सकता है। यह एक vibe-coding प्लेटफ़ॉर्म है जहाँ आप चैट के माध्यम से एप्लिकेशन बनाते हैं, और एजेंट-आधारित आर्किटेक्चर अंदर काम करता है। व्यवहार में इसका मतलब:
Koder.ai ग्लोबली AWS पर चलता है, इसलिए यह विभिन्न रीजन में तैनाती का भी समर्थन कर सकता है ताकि लेटेंसी और डेटा-ट्रांसफरConstraints को पूरा किया जा सके—यह उपयोगी होता है जब मल्टी-ज़ोन या मल्टी-रीजन उपलब्धता आपके स्केलिंग कहानी का हिस्सा बनती है।
वर्टिकल स्केलिंग में एक ही मशीन को बड़ा किया जाता है (ज़्यादा CPU/RAM/तेज़ डिस्क)। हॉरिज़ॉन्टल स्केलिंग में कई मशीनें जोड़ी जाती हैं और काम उनमे फैल जाता है।
वर्टिकल अक्सर सरल लगता है क्योंकि आपका एप अभी भी “एक सिस्टम” जैसा ही व्यवहर करता है, जबकि हॉरिज़ॉन्टल में कई सिस्टमों को समन्वय और संगति बनाए रखने की ज़रूरत होती है।
क्योंकि जैसे ही आपके पास कई नोड होते हैं, आपको स्पष्ट समन्वय की ज़रूरत पड़ती है:
एक अकेली मशीन इन कई वितरित-प्रणाली समस्याओं से स्वयं को बचाती है।
यह कई मशीनों को एक जैसा व्यवहर कराने में लगने वाला समय और लॉजिक है:
हर नोड साधारण हो सकता है, पर पूरे सिस्टम का व्यवहार लोड और विफलता में समझना मुश्किल हो जाता है।
शार्डिंग (पार्टिशनिंग) डेटा को नोड्स में बाँटती है ताकि कोई एक मशीन सब कुछ न संभाले। कठिनाइयाँ:
साथ ही यह ऑपरेशनल काम बढ़ाता है (माइग्रेशन, बैकफिल, शार्ड मैप रखरखाव)।
स्टेट वह है जो आपका ऐप अनुरोधों के बीच "याद" रखता है (सेशन, इन-मेमोरी कैश, अस्थाई फाइलें, जॉब प्रोग्रेस)।
हॉरिज़ॉन्टल स्केल में, अनुरोध अलग सर्वरों पर जा सकते हैं, इसलिए आपको साझा स्टोर (Redis/DB) चाहिये होगा या आप sticky sessions जैसे trade-offs स्वीकार करते हैं।
यदि कई वर्कर्स वही जॉब उठा सकते हैं या जॉब रीट्राई होता है, तो डुप्लिकेट प्रोसेसिंग हो सकती है—जैसे दो बार चार्ज होना या दो बारी ईमेल भेजना।
आम उन्मूलन:
स्ट्रांग संगति का मतलब है कि एक बार राइट सफल होते ही सारे रीडर्स तुरंत नया वैल्यू देखें। इवञ्चुअल संगति में अपडेट्स फैलने में समय लेते हैं, इसलिए कुछ रीडर्स थोड़ी देर तक पुरानी वैल्यू देख सकते हैं।
स्ट्रांग संगति भुगतान, बैलेंस, इन्वेंट्री जैसे निर्णायक डेटा के लिए ज़रूरी है; एनालिटिक्स और रिकमेंडेशन जैसे कम-संवेदनशील मामलों में इवञ्चुअल संगति स्वीकार्य हो सकती है।
वितरित सिस्टम में कॉल नेटवर्क कॉल बन जाते हैं—जिससे लैटेंसी, जिटर और नए विफलता मोड आते हैं।
बुनियादी बातें जो अक्सर मायने रखती हैं:
आंशिक विफलता का मतलब है कि कुछ घटक बिगड़े या धीमे हैं जबकि बाकी ठीक हैं। बड़ी तादाद में यह सामान्य हो जाता है।
इसका जवाब देने के लिए प्रतिकृति, क्वोरम, मल्टी-ज़ोन तैनाती, सर्किट ब्रेकर और graceful degradation जैसी रणनीतियाँ अपनाई जाती हैं ताकि विफलताएँ लहर की तरह न फैलें।
कई सर्वरों पर चलते हुए सबूत बिखरे होते हैं: अलग नोड्स के लॉग्स, मैट्रिक्स और ट्रेसेज़।
व्यवहारिक कदम: