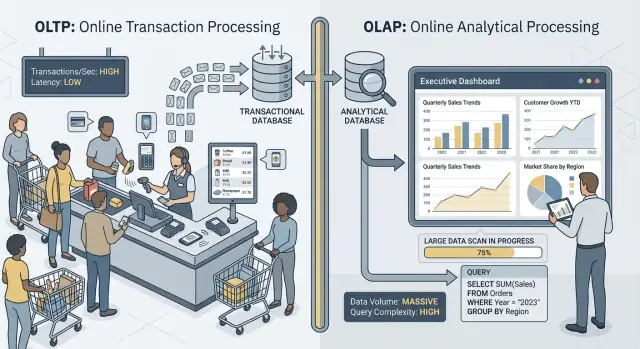
OLTP vs OLAP: बिना जार्गन के क्या हैं
जब लोग “OLTP” और “OLAP” कहते हैं, तो वे एक डेटाबेस के दो बहुत अलग उपयोग के तरीकों की बात कर रहे होते हैं।
OLTP: वह डेटाबेस जो बिज़नेस चलाता है
OLTP (ऑनलाइन ट्रांज़ैक्शन प्रोसेसिंग) वह वर्कलोड है जो रोज़मर्रा की क्रियाओं के पीछे होता है और हर बार तेज़ व सही होना चाहिए। सोचिए: “अब यह बदलाव सेव करो।”
साधारण OLTP कार्यों में एक ऑर्डर बनाना, इन्वेंटरी अपडेट करना, भुगतान रिकॉर्ड करना, या ग्राहक का पता बदलना शामिल हैं। ये ऑपरेशन्स आमतौर पर छोटे (कुछ ही रो), बार-बार होते हैं, और मिलीसेकंड में प्रतिक्रिया देनी होती है क्योंकि कोई व्यक्ति या दूसरा सिस्टम इंतज़ार कर रहा होता है।
OLAP: वह डेटाबेस जो बिज़नेस को समझाता है
OLAP (ऑनलाइन एनालिटिकल प्रोसेसिंग) वह वर्कलोड है जिसका उपयोग यह जानने के लिए होता है कि क्या हुआ और क्यों। सोचिए: “बहुत सा डेटा स्कैन करो और उसका सार निकाले।”
साधारण OLAP कार्यों में डैशबोर्ड, ट्रेंड रिपोर्ट्स, कोहोर्ट विश्लेषण, फोरकास्टिंग और “slice-and-dice” प्रश्न शामिल हैं जैसे: “पिछले 18 महीनों में क्षेत्र और उत्पाद श्रेणी के अनुसार राजस्व कैसे बदला?” ये क्वेरीज़ अक्सर बहुत सारी रो पढ़ती हैं, भारी एग्रीगेशन करती हैं, और सेकंड (या मिनट) तक चल सकती हैं—बशर्ते परिणाम "गलत" न हों।
वही डेटा, अलग लक्ष्य—और अलग ज़रूरतें
मुख्य विचार सरल है: OLTP तेज़, सुसंगत लिखाई और छोटे रीड्स के लिए ऑप्टिमाइज़ करता है, जबकि OLAP बड़े रीड्स और जटिल कैलकुलेशन्स के लिए ऑप्टिमाइज़ करता है। लक्ष्यों के भिन्न होने के कारण, सर्वश्रेष्ठ डेटाबेस सेटिंग्स, इंडेक्स, स्टोरेज लेआउट, और स्केलिंग दृष्टिकोण भी अक्सर भिन्न होते हैं।
ध्यान दें शब्दचयन: अकसर नहीं मतलब कभी नहीं। कुछ छोटी टीमें सीमित डेटा वॉल्यूम और सावधानी से क्वेरी अनुशासन के साथ एक डेटाबेस साझा कर सकती हैं। बाद के सेक्शन में बताया गया है कि क्या जल्दी टूटता है, सामान्य पृथक्करण पैटर्न, और रिपोर्टिंग को प्रोडक्शन से सुरक्षित तरीके से कैसे हटाया जाए।
त्वरित उदाहरण
- Checkout (OLTP): एक ग्राहक “Pay” पर क्लिक करता है, और आपका ऐप एक ऑर्डर, भुगतान स्थिति, और इन्वेंटरी अपडेट लिखता है।
- Reporting dashboard (OLAP): एक मैनेजर एक डैशबोर्ड खोलता है जो हजारों (या लाखों) ऑर्डर्स को एग्रीगेट करके कन्वर्ज़न रेट, औसत ऑर्डर वैल्यू, और साप्ताहिक ट्रेंड दिखाता है।
अलग लक्ष्य, अलग सफलता मीट्रिक
OLTP और OLAP दोनों “SQL” उपयोग कर सकते हैं, पर वे अलग कामों के लिए ऑप्टिमाइज़ होते हैं—और यह दिखता है कि हर एक क्या सफलता मानता है।
OLTP: गति, कंकरेन्सी, और सटीकता
OLTP (ट्रांज़ैक्शनल) सिस्टम रोज़मर्रा के ऑपरेशन्स को पावर करते हैं: चेकआउट फ्लोज़, खाता अपडेट, रिज़र्वेशन, सपोर्ट टूल्स। प्राथमिकताएँ सरल हैं:
- छोटे रीड/राइट्स के लिए तेज़ प्रतिक्रिया समय (मिलीसेकंड स्तर)
- कई समसामयिक उपयोगकर्ता बिना धीमे हुए
- सहीपन और कंसिस्टेंसी, क्योंकि गलत बैलेंस या डुप्लिकेट ऑर्डर वास्तविक बिजनेस समस्या है
सफलता का ट्रैकिंग अक्सर लेटेंसी मेट्रिक्स जैसे p95/p99 रिक्वेस्ट टाइम, एरर रेट, और पीक कंकरेन्सी के अंतर्गत सिस्टम के व्यवहार से किया जाता है।
OLAP: स्कैनिंग, एग्रीगेटिंग, और लचीलापन
OLAP (एनालिटिक्स) सिस्टम उन सवालों का जवाब देते हैं जैसे “इस तिमाही क्या बदला?” या “कौन सा सेगमेंट नई प्राइसिंग के बाद चर्न कर रहा है?” ये क्वेरीज़ अक्सर:
- बड़ी मात्रा में डेटा स्कैन करती हैं
- एग्रीगेशन (SUM, COUNT, पर्सेंटाइल) और जोइन करती हैं
- अक्सर एनालिस्ट्स द्वारा खोज और परिभाषा बदलने पर लचीली रहती हैं
यहाँ सफलता कुछ इस तरह दिखती है: क्वेरी थ्रूपुट, insight तक पहुँचने का समय, और बिना हरेक रिपोर्ट के हाथ से ट्यून किए जटिल क्वेरीज़ चलाने की क्षमता।
"सब कुछ के लिए एक सिस्टम" क्यों ट्रेड-ऑफ बनाता है
जब आप दोनों वर्कलोड्स को एक डेटाबेस में जोड़ने पर मजबूर करते हैं, तो आप उससे एक ही समय में छोटे, उच्च-आवृत्ति वाले ट्रांज़ैक्शन और बड़े, एक्सप्लोरेटरी स्कैन दोनों में उत्कृष्ट होने की उम्मीद करते हैं। परिणाम आमतौर पर समझौता होता है: OLTP अनपेक्षित लेटेंसी पाता है, OLAP को प्रोडक्शन की सुरक्षा के लिए थ्रॉटल किया जाता है, और टीमें बहस करती रहती हैं कि किसकी क्वेरीज़ "अनुमत" हैं। अलग लक्ष्य अलग सफलता मीट्रिक के हकदार होते हैं—और अक्सर अलग सिस्टम भी।
रिसोर्स कंटेंशन: जब एनालिटिक्स ट्रांज़ैक्शनस से चुरा लेती है
जब OLTP (आपके ऐप के रोज़मर्रा के ट्रांज़ैक्शन) और OLAP (रिपोर्टिंग और एनालिसिस) एक ही डेटाबेस पर चलते हैं, तो वे एक ही सीमित संसाधनों के लिए लड़ते हैं। परिणाम सिर्फ "रिपोर्ट धीमी" नहीं होता—यह अक्सर धीमे चेकआउट, अटक गए लॉगिन, और अनपेक्षित ऐप हिचकियाँ बनता है।
CPU और मेमोरी: लंबी क्वेरीज़ बनाम छोटी क्वेरीज़
एनालिटिकल क्वेरीज़ लम्बी चलने वाली और भारी होती हैं: बड़े टेबलों पर जोइन, एग्रीगेशन, सॉर्टिंग, और ग्रुपिंग। ये CPU को और हैश जॉइन/सॉर्ट बफर्स के लिए मेमोरी को हाइजैक कर सकती हैं।
वहीं, ट्रांज़ैक्शनल क्वेरीज़ आमतौर पर छोटी पर लेटेंसी-संवेदी होती हैं। अगर CPU संतृप्त है या मेमोरी प्रेशर से फ्रीक्वेंट इविक्शन हो रहे हैं, तो वे छोटे क्वेरीज़ भी बड़े क्वेरीज़ के पीछे इंतज़ार करने लगते हैं—भले ही हर ट्रांज़ैक्शन को केवल कुछ मिलीसेकंड ही लगे।
डिस्क I/O: बड़े स्कैन बनाम कई छोटे रीड/राइट
एनालिटिक्स अक्सर बड़े टेबल स्कैन और सीक्वेंशियल पेज रीड्स ट्रिगर करती है। OLTP वर्कलोड इसके विपरीत हैं: कई छोटे, रैंडम रीड्स और इंडेक्स/लॉग पर निरंतर राइट्स।
इन्हें मिलाने पर डेटाबेस स्टोरेज सबसिस्टम को असंगत एक्सेस पैटर्न संभालने होते हैं। कैश जो OLTP में मदद कर रहे थे, वे एनालिटिक्स स्कैन से “वॉश आउट” हो सकते हैं, और रिपोर्ट के लिए डिस्क स्ट्रीमिंग के दौरान राइट लेटेंसी बढ़ सकती है।
कनेक्शन पूल दबाव और कतारबद्धता
कुछ एनालिस्ट्स द्वारा चलायी गई व्यापक क्वेरीज़ मिनटों तक कनेक्शन्स बाँध कर रख सकती हैं। अगर आपका एप्लिकेशन फिक्स्ड-साइज़ पूल इस्तेमाल करता है, तो रिक्वेस्ट्स मुफ्त कनेक्शन के लिए कतार में लग जाती हैं। यह कतार प्रभाव एक स्वस्थ सिस्टम को टूटा हुआ महसूस करा सकता है: औसत लेटेंसी ठीक लग सकती है, पर टेल लेटेंसी (p95/p99) दर्दनाक हो जाती है।
यूज़र्स असल में क्या नोटिस करते हैं
बाहरी तौर पर यह टाइमआउट्स, धीमे चेकआउट फ्लोज़, देरी से खोज परिणाम, और सामान्यत: फ्लेकी व्यवहार के रूप में दिखता है—अक्सर "सिर्फ रिपोर्टिंग के दौरान" या "सिर्फ महीने के अंत में"। ऐप टीम को एरर दिखते हैं; एनालिटिक्स टीम को धीमी क्वेरीज़ दिखती हैं; असली समस्या साझा कंटेंशन होती है।
डेटा लेआउट और इंडेक्सिंग की अलग ज़रूरतें
OLTP और OLAP सिर्फ डेटाबेस का अलग उपयोग नहीं करते—वे भौतिक डिज़ाइनों को भी विपरीत रूप से पुरस्कृत करते हैं। जब आप दोनों को एक जगह पर संतुष्ट करने की कोशिश करते हैं, तो आप आमतौर पर महँगा और फिर भी कम प्रदर्शन वाला समझौता करते हैं।
OLTP: तेज़, चयनात्मक लुकअप के लिए ऑप्टिमाइज़
ट्रांज़ैक्शनल वर्कलोड छोटे हिस्सों को छूने वाली शॉर्ट क्वेरीज़ से डोमिनेट होता है: एक ऑर्डर प्राप्त करना, एक इन्वेंटरी रो अपडेट करना, किसी एक उपयोगकर्ता के अंतिम 20 इवेंट्स सूचीबद्ध करना।
यह OLTP स्कीमाओं को रो-ओरिएंटेड स्टोरेज और ऐसे इंडेक्स की ओर धकेलता है जो पॉइंट लुकअप और छोटे रेंज स्कैन का समर्थन करते हैं (अक्सर प्राइमरी कीज़, फ़ॉरेन कीज़, और कुछ हाई-वैल्यू सेकेंडरी इंडेक्स)। लक्ष्य है भरोसेमंद, कम लेटेंसी—खासकर राइट्स के लिए।
OLAP: स्कैनिंग, ग्रुपिंग, और समरी के लिए ऑप्टिमाइज़
एनालिटिक्स वर्कलोड अक्सर बहुत सारी रो पढ़ता है और केवल कुछ कॉलम चाहिए: “सप्ताहवार क्षेत्र के अनुसार राजस्व,” “कैंपेन के अनुसार कन्वर्ज़न रेट,” “सबसे ऊपर के प्रोडक्ट्स मार्जिन के हिसाब से।”
OLAP सिस्टम कॉलम-ओरिएंटेड स्टोरेज (केवल ज़रूरी कॉलम पढ़ने के लिए), पार्टिशनिंग (पुराने/अप्रासंगिक डेटा को जल्दी प्रून करने के लिए), और प्री-एग्रीगेशन (materialized views, rollups, summary tables) से लाभ उठाते हैं ताकि रिपोर्ट बार-बार वही टोटल्स नहीं री-कम्प्यूट करें।
"सब कुछ के लिए इंडेक्स" क्यों बैकफायर करता है
एक सामान्य प्रतिक्रिया यह होती है कि हर डैशबोर्ड तेज़ करने के लिए इंडेक्स जोड़ दिए जाएँ। पर हर अतिरिक्त इंडेक्स लिखने की लागत बढ़ाता है: inserts/updates/deletes को और संरचनाएँ बनाए रखनी होती हैं। यह स्टोरेज बढ़ाता है और मेंटेनेंस टास्क जैसे vacuuming, reindexing, और बैकअप धीमे कर देता है।
क्वेरी प्लानर और स्टैटिस्टिक्स का ड्रिफ्ट (साधारण शब्दों में)
डेटाबेस क्वेरी प्लान चुनते हैं स्टैटिस्टिक्स के आधार पर—अनुमान कि एक फिल्टर कितनी रो मैच करेगा, कोई इंडेक्स कितना चयनात्मक है, और डेटा कैसे वितरित है। OLTP लगातार डेटा बदलता रहता है। जैसे-जैसे वितरण बदलते हैं, स्टैटिस्टिक्स ड्रिफ्ट कर सकती हैं, और प्लानर एक ऐसा प्लान चुन सकता है जो कल के डेटा के लिए अच्छा था पर आज धीमा हो।
भारी OLAP क्वेरीज़ मिलाने पर और भी अधिक वैरिएबिलिटी आती है: "सर्वोत्तम प्लान" का अनुमान लगाना कठिन हो जाता है, और एक वर्कलोड के लिए ट्यून करना अक्सर दूसरे को बदतर बना देता है।
लॉकिंग, MVCC, और मेंटेनेंस साइड-इफेक्ट्स
यहां तक कि अगर आपका डेटाबेस "कंकरेन्सी सपोर्ट" करता है, तब भी भारी रिपोर्टिंग और लाइव ट्रांज़ैक्शन्स मिलाने से सूक्ष्म धीमापन पैदा होता है जो बताना मुश्किल होता है—और ग्राहक के सामने स्पिन करती चेकआउट स्क्रीन को समझाना और भी मुश्किल।
लंबी क्वेरीज़ फिर भी लॉक समस्या पैदा करती हैं
OLAP-शैली की क्वेरीज़ अक्सर बहुत सारी रो स्कैन करती हैं, कई तालिकाओं को जोड़ती हैं, और सेकंड या मिनट तक चलती हैं। इस दौरान वे लॉक पकड़ सकती हैं (उदा. स्कीमा ऑब्जेक्ट्स पर, या जब उन्हें टेम्पररी स्ट्रक्चर में सॉर्ट/एग्रीगेट करने की आवश्यकता होती है) और वे अक्सर अन्य तरीकों से लॉक कंटेंशन बढ़ा देती हैं क्योंकि वे कई रो को "इनेप्ले" रखती हैं।
MVCC (मल्टी-वर्ज़न कंकरेन्सी कंट्रोल) पढ़ने वालों और लिखने वालों को ब्लॉक होने से बचाने में मदद करता है, पर यह कंटेंशन को पूरी तरह समाप्त नहीं करता—खासकर जब क्वेरीज़ उन टेबल्स को छूती हैं जिन्हें ट्रांज़ैक्शन्स लगातार अपडेट कर रहे हैं।
MVCC की छिपी लागत: क्लीनअप कठिन हो जाता है
MVCC का मतलब है कि पुराने रो वर्ज़न्स तब तक बने रहते हैं जब तक डेटाबेस उन्हें सुरक्षित रूप से हटाने योग्य नहीं समझता। एक लंबी-चलने वाली रिपोर्ट पुराना स्नैपशॉट खुला रख सकती है, जो क्लीनअप को स्पेस वापस लेने से रोकता है।
इसका प्रभाव होता है:
- Vacuum/garbage collection: क्लीनअप मृत टुपल्स/वर्ज़न्स को जल्दी हटा नहीं पाता।
- Bloat/fragmentation: स्टोरेज बढ़ता है, इंडेक्स कम प्रभावी होते हैं, और कैश कम उपयोगी हो जाते हैं।
- Compaction pressure: कुछ इंजन पृष्ठभूमि में ज़्यादा काम करके प्रतिक्रिया देते हैं, जो ट्रांज़ैक्शन्स से I/O और CPU छीनता है।
नतीजा एक डबल हिट है: रिपोर्टिंग डेटाबेस को ज़्यादा मेहनत कराती है और समय के साथ सिस्टम को धीमा कर देती है।
आइसोलेशन लेवल्स लेटेंसी की अस्थिरता बढ़ाते हैं
रिपोर्टिंग टूल अक्सर मजबूत आइसोलेशन माँगते हैं (या गलती से लंबी ट्रांज़ैक्शन में चलते हैं)। उच्च आइसोलेशन लॉक पर इंतज़ार बढ़ा सकता है और इंजन को अधिक वर्ज़निंग प्रबंधित करने के लिए मजबूर कर सकता है। OLTP साइड से आप इसे अनपेक्षित स्पाइक्स के रूप में देखते हैं: अधिकतर ऑर्डर तेज़ी से लिखते हैं, फिर कुछ अचानक अटक जाते हैं।
व्यावहारिक उदाहरण: महीने के अंत की रिपोर्टिंग ऑर्डर्स को धीमा कर देती है
महीने के अंत में, फाइनेंस एक "उत्पादवार राजस्व" क्वेरी चलाती है जो संपूर्ण महीने के ऑर्डर्स और लाइन आइटम्स को स्कैन करती है। जब यह चलती है, तो नए ऑर्डर राइट्स स्वीकार किए जाते हैं, पर vacuum पुराने वर्ज़न्स को वापस नहीं ले पाता और इंडेक्स गरम रहते हैं। ऑर्डर API कभी-कभी टाइमआउट देखता है—यह इसलिए नहीं कि वह "डाउन" है, बल्कि क्योंकि कंटेंशन और क्लीनअप ओवरहेड चुपचाप आपकी लेटेंसी को आपके लिमिट से ऊपर धकेल देता है।
वर्कलोड की स्पाइकिनेस और अनपेक्षित लेटेंसी
टेबल और API बनाएं
ऑर्डर, पेमेंट और रिपोर्ट बताएं और Koder.ai टेबल और API का मसौदा तैयार कर देगा।
OLTP सिस्टम की जान प्रेडिक्टेबिलिटी पर निर्भर करती है। एक चेकआउट, सपोर्ट टिकट, या बैलेंस अपडेट "अधिकांश समय ठीक" होना नहीं चाहिए—उपयोगकर्ता धीमे पलों को नोटिस करते हैं। OLAP अक्सर बर्स्टरी होता है: कुछ भारी क्वेरीज़ घंटों तक शांत रहती हैं और फिर अचानक बहुत सा CPU, मेमोरी, और I/O खा जाती हैं।
स्पाइक्स सामान्य व्यावसायिक कारणों से होते हैं
एनालिटिक्स ट्रैफ़िक रूटीन के चारों ओर बंडल हो जाता है:
- सुबह "स्टैंडअप डैशबोर्ड्स" जहाँ कई लोग एक ही चार्ट रिफ़्रेश करते हैं
- निर्धारित रिपोर्ट्स जो घंटे की शुरुआत पर सब एक साथ चल जाती हैं
- महीने-के-अंत और तिमाही-समापन जो लम्बे स्कैन और जोइन ट्रिगर करते हैं
जब दोनों वर्कलोड एक ही डेटाबेस साझा करते हैं, तो ये एनालिटिक्स स्पाइक्स ट्रांज़ैक्शन्स के लिए अनपेक्षित लेटेंसी में बदल जाते हैं—टाइमआउट्स, धीमे पेज लोड्स, और कभी-कभी retries जो और भी लोड जोड़ देते हैं।
सीमाएँ और शेड्यूलिंग क्यों मदद करती हैं—पर मेल नहीं खाती
आप रिपोर्ट्स रात में चलाने, कंकरेन्सी सीमित करने, स्टेटमेंट टाइमआउट्स लागू करने, या क्वेरी कॉस्ट कैप लगाने जैसी रणनीतियाँ अपना कर नुकसान घटा सकते हैं। ये जरूरी गार्डरैलब्स हैं, खासकर "प्रोडक्शन पर रिपोर्टिंग" के लिए।
पर वे मौलिक तनाव को दूर नहीं करतीं: OLAP क्वेरीज़ बड़े सवालों के जवाब के लिए कई सारे रिसोर्स इस्तेमाल करने के लिए डिज़ाइन की जाती हैं, जबकि OLTP पूरे दिन छोटे तेज़ रिसोर्स स्लाइस चाहिए। जैसे ही कोई अनअपेक्षित डैशबोर्ड रिफ्रेश, एड-हॉक क्वेरी, या बैकफिल रिलीज़ हो जाती है, साझा डेटाबेस फिर जोखिम में आ जाता है।
noisy neighbor समस्या
शेयर्ड इन्फ्रास्ट्रक्चर पर एक "नॉइज़ी" एनालिटिक्स उपयोगकर्ता या जॉब कैश मॉनॉपोलाइज़ कर सकता है, डिस्क सैचुरेट कर सकता है, या CPU शेड्यूलिंग दबाव डाल सकता है—बिना किसी गलत काम के। OLTP वर्कलोड को कोलैटरल डैमेज होता है, और सबसे मुश्किल बात यह है कि विफलताएँ यादृच्छिक दिखती हैं: स्पष्ट, दोहराने योग्य त्रुटियों के बजाए लेटेंसी स्पाइक्स।
ऑपरेशनल जटिलता: बैकअप, सुरक्षा, और क्षमता योजना
OLTP (ट्रांज़ैक्शन्स) और OLAP (एनालिटिक्स) को मिलाने से सिर्फ प्रदर्शन समस्याएँ नहीं बढ़तीं—यह दिन-प्रतिदिन के संचालन को भी और कठिन बना देता है। डेटाबेस एक "सब कुछ बॉक्स" बन जाता है, और हर ऑपरेशनल टास्क दोनों वर्कलोड्स के संयुक्त जोखिम अपनाता है।
बैकअप, रिस्टोर, और डिजास्टर रिकवरी धीमा हो जाता है
एनालिटिक्स टेबल्स अक्सर चौड़ी और तेज़ी से बढ़ती हैं (अधिक हिस्ट्री, अधिक कॉलम, अधिक एग्रीगेट)। उस अतिरिक्त वॉल्यूम से आपकी रिकवरी स्टोरी बदल जाती है।
फुल बैकअप अधिक समय लेता है, अधिक स्टोरेज खपत करता है, और बैकअप विंडो चूकने का जोखिम बढ़ता है। रिस्टोर और भी बुरा: जब आपको जल्दी रीकवर करना होता है, आप न केवल ट्रांज़ैक्शनल डेटा वापस ला रहे हैं बल्कि बड़े एनालिटिकल डेटा भी जो बिज़नेस रन करने के लिए ज़रूरी नहीं होते। डिजास्टर रिकवरी टेस्ट भी लंबा हो जाता है, इसलिए वे कम होते हैं—बिलकुल उल्टा जो आप चाहेंगे।
क्षमता योजना अनुमान पर निर्भर हो जाती है
ट्रांज़ैक्शनल वृद्धि आमतौर पर प्रेडिक्टेबल होती है: अधिक ग्राहक, अधिक ऑर्डर्स, अधिक रो। एनालिटिक्स वृद्धि अक्सर लम्पी होती है: एक नया डैशबोर्ड, एक नई रिटेंशन पॉलिसी, या किसी टीम का "बस एक और साल" कच्चे इवेंट्स रखना।
जब दोनों साथ रहते हैं, तो आप आसानी से जवाब नहीं दे पाते:
- क्या हम बढ़ रहे हैं क्योंकि प्रोडक्ट सफल है, या क्योंकि रिपोर्ट्स अधिक हिस्ट्री स्टोर कर रही हैं?
- क्या हमें ट्रांज़ैक्शन के लिए तेज़ स्टोरेज चाहिए, या एनालिटिक्स के लिए सस्ता स्टोरेज?
यह अनिश्चितता ओवरप्रोविज़निंग (बेकार में प्रीमियम भुगतान) या अंडरप्रोविज़निंग (सप्राइज़ आउटेज) की ओर ले जाती है।
गार्डरैलब्स लागू करना निष्पक्ष रूप से कठिन हो जाता है
शेयर्ड डेटाबेस में एक "निष्पाप" क्वेरी भी incident बन सकती है। आप समाप्ततः गार्डरैलब्स जोड़ते हैं जैसे क्वेरी टाइमआउट, वर्कलोड कोटा, शेड्यूल्ड रिपोर्टिंग विंडोज, या वर्कलोड मैनेजमेंट नियम। ये मदद करते हैं, पर वे भंगुर होते हैं: ऐप और एनालिस्ट्स अब उन्हीं सीमाओं के लिए प्रतिस्पर्धा कर रहे हैं, और एक समूह के लिए नीति-परिवर्तन दूसरे को तोड़ सकता है।
सुरक्षा और एक्सेस कंट्रोल पेचीदा हो जाते हैं
एप्लिकेशन्स को आम तौर पर संकीर्ण, उद्देश्य-निर्मित अनुमतियाँ चाहिए। एनालिस्ट्स को अक्सर व्यापक रीड एक्सेस चाहिए, कभी-कभी कई टेबल्स में, खोज और वैलिडेशन के लिए। दोनों को एक ही डेटाबेस में रखने से रिपोर्ट को काम कराने के लिए व्यापक अनुमतियाँ देने का दबाव बढ़ता है, जिससे गलतियों का ब्लास्ट रेडियस बढ़ता है और संवेदनशील ऑपरेशनल डेटा को देखने वालों की संख्या बढ़ जाती है।
स्केलिंग और लागत: आप अंततः दो बार (या उससे भी अधिक) भुगतान करते हैं
अपनी रिपोर्टिंग आर्किटेक्चर की योजना बनाएं
प्रोडक्शन प्रदर्शन को जोखिम में डाले बिना रिप्लिका, वेयरहाउस या CDC के चरणों की योजना बनाएं।
एक ही डेटाबेस में OLTP और OLAP चलाने की कोशिश अक्सर सस्ती लगती है—जब तक आप स्केल नहीं करते। समस्या सिर्फ प्रदर्शन की नहीं है। हर वर्कलोड को स्केल करने का "सही" तरीका अलग इंफ्रास्ट्रक्चर की ओर धकेलता है, और मिलाकर रखना महँगे समझौतों पर मजबूर करता है।
OLTP स्केलिंग लिखाई-प्रेरित है (और अक्सर दर्दनाक)
ट्रांज़ैक्शनल सिस्टम्स राइट्स से सीमित होते हैं: कई छोटे अपडेट्स, सख्त लेटेंसी, और बर्स्ट जिन्हें तुरंत सोखा जाना चाहिए। OLTP स्केलिंग आमतौर पर वर्टिकल स्केलिंग (बड़ा CPU, तेज़ डिस्क, अधिक मेमोरी) की ओर जाती है क्योंकि राइट-हेवी वर्कलोड्स आसानी से फैला (fan-out) नहीं होते।
जब वर्टिकल लिमिट पहुँच जाती है, तो आप शार्डिंग या अन्य राइट-स्केलिंग पैटर्न पर नजर डालते हैं। यह इंजीनियरिंग ओवरहेड जोड़ता है और अक्सर एप्लिकेशन में सावधानीपूर्वक बदलाव माँगता है।
OLAP स्केलिंग compute-प्रेरित है (और अक्सर इलास्टिक)
एनालिटिक्स वर्कलोड्स अलग तरह से स्केल करते हैं: लंबे स्कैन, भारी एग्रीगेशन, और अधिक रीड थ्रूपुट। OLAP सिस्टम आमतौर पर डिस्ट्रिब्यूटेड compute जोड़कर स्केल होते हैं, और कई आधुनिक सेटअप स्टोरेज को compute से अलग करते हैं ताकि आप क्वेरी पावर बिना डेटा को डुप्लिकेट किए बढ़ा सकें।
अगर OLAP OLTP डेटाबेस साझा करता है, तो आप एनालिटिक्स को स्वतंत्र रूप से स्केल नहीं कर पाते। आपको पूरे डेटाबेस को स्केल करना पड़ता है—even जब ट्रांज़ैक्शन्स ठीक हों।
छुपा हुआ बिल: एनालिटिक्स के लिए OLTP-ग्रेड रिसोर्सेज का भुगतान करना
ट्रांज़ैक्शन्स को तेज़ रखने के लिए प्रोडक्शन डेटाबेस को ओवर-प्रोविज़न करना आम है: अतिरिक्त CPU हेडरूम, हाई-एंड स्टोरेज, और बड़े इंस्टेन्स "बस इन केस"। इसका मतलब यह है कि आप OLAP व्यवहार को चलाने के लिए OLTP की कीमतें चुका रहे हैं।
पृथक्करण से ओवर-प्रोविज़न कम होता है क्योंकि हर सिस्टम को उसके काम के हिसाब से साइज किया जा सकता है: OLTP के लिए प्रेडिक्टेबल लो-लेटेंसी राइट्स, OLAP के लिए बर्स्टी हैवी रीड्स। नतीजा अक्सर कुल मिलाकर सस्ता होता है—हालांकि यह "दो सिस्टम" है—क्योंकि आप प्रोडक्शन पर रिपोर्टिंग चलाने के लिए प्रीमियम ट्रांज़ैक्शनल क्षमता खरीदना बंद कर देते हैं।
सामान्य आर्किटेक्चर जो OLTP और OLAP को अलग रखते हैं
अधिकांश टीमें ट्रांज़ैक्शनल वर्कलोड (OLTP) को एनालिटिकल वर्कलोड (OLAP) से अलग रखती हैं, अक्सर एक दूसरे "रीड-ओरिएंटेड" सिस्टम को जोड़कर बजाय एक ही डेटाबेस को सब कुछ सर्व करने के।
पैटर्न 1: रिपोर्टिंग के लिए रीड रेप्लिका
एक सामान्य पहला कदम है OLTP डेटाबेस की रीड रेप्लिका (या फॉलोअर), जहाँ BI टूल्स क्वेरी चलाते हैं。
फायदे: न्यूनतम ऐप बदलाव, परिचित SQL, जल्दी सेटअप।
नुकसान: यह अभी भी वही इंजन और स्कीमा है, इसलिए भारी रिपोर्ट्स रेप्लिका CPU/I/O को संतृप्त कर सकती हैं; कुछ रिपोर्ट्स रेप्लिका पर उपलब्ध सुविधाओं की मांग कर सकती हैं; और रिप्लिकेशन लेग का मतलब है कि संख्याएँ मिनटों (या अधिक) पीछे हो सकती हैं। लेग भ्रमित करता है और घटनाओं के दौरान "यह प्रोडक्शन से क्यों मैच नहीं कर रहा?" जैसी बातचीत जन्म देता है।
बेस्ट फिट: छोटी टीमें, मामूली डेटा वॉल्यूम, "निएर-रियल-टाइम" अच्छा है पर अनिवार्य नहीं, और रिपोर्टिंग क्वेरीज नियंत्रित हों।
पैटर्न 2: समर्पित डेटा वेयरहाउस / एनालिटिक्स डेटाबेस
यहाँ, OLTP राइट्स और पॉइंट रीड्स के लिए ऑप्टिमाइज़ रहता है, जबकि एनालिटिक्स एक डेटा वेयरहाउस (या कॉलमर एनालिटिक्स DB) में जाता है जो स्कैन, कंप्रेशन, और बड़े एग्रीगेशन के लिए डिज़ाइन किया गया है。
फायदे: प्रेडिक्टेबल OLTP प्रदर्शन, तेज़ डैशबोर्ड्स, एनालिस्ट्स के लिए बेहतर कंकरेन्सी, और स्पष्ट लागत/प्रदर्शन ट्यूनिंग।
नुकसान: अब आप एक और सिस्टम चला रहे हैं और एक एनालिटिक्स-फ्रेंडली डेटा मॉडल (अक्सर स्टार स्कीमा) की जरूरत होती है।
बेस्ट फिट: बढ़ता हुआ डेटा, कई स्टेकहोल्डर्स, जटिल रिपोर्टिंग, या सख्त OLTP लेटेंसी आवश्यकताएँ।
पैटर्न 3: CDC-आधारित पाइपलाइन एनालिटिक्स में
पिरिओडिक ETL की जगह आप OLTP लॉग से CDC स्ट्रीम करके वेयरहाउस में भेजते हैं (अक्सर ELT के साथ)।
फायदे: OLTP पर कम लोड के साथ ताजा डेटा, आसान इनक्रिमेंटल प्रोसेसिंग, और बेहतर ऑडिटेबिलिटी।
नुकसान: अधिक मूविंग पार्ट्स और स्कीमा चेंज को सावधानी से संभालना।
बेस्ट फिट: बड़े वॉल्यूम, उच्च फ्रेशनैस की ज़रूरत, और टीमें जो डेटा पाइपलाइन्स के लिए तैयार हों।
OLTP से OLAP तक डेटा को सुरक्षित रूप से लाना
ट्रांज़ैक्शनल डेटाबेस (OLTP) से एनालिटिक्स सिस्टम (OLAP) में डेटा ले जाना सिर्फ "टेबल्स कॉपी करना" नहीं है—यह एक भरोसेमंद, कम-प्रभाव वाली पाइपलाइन बनाना है। लक्ष्य सरल है: एनालिटिक्स को उसकी ज़रूरत मिले, बिना प्रोडक्शन ट्रैफ़िक को जोखिम में डाले।
ETL बनाम ELT (साधारण अंग्रेज़ी में)
ETL (Extract, Transform, Load) का मतलब है कि आप डेटा को वेयरहाउस में लाने से पहले साफ़ और बदलते हैं। यह तब उपयोगी है जब वेयरहाउस में कंप्यूट महँगा हो, या आप यही तय करना चाहते हैं कि क्या स्टोर होगा।
ELT (Extract, Load, Transform) पहले कच्चा-सा डेटा लोड करता है, फिर वेयरहाउस के भीतर ट्रांसफॉर्म करता है। यह अक्सर जल्दी सेटअप होता है और विकसित करना आसान होता है: आप "सोर्स ऑफ़ ट्रुथ" हिस्ट्री रखते हैं और जब आवश्यकताएँ बदलें तो ट्रांसफॉर्मेशन समायोजित कर सकते हैं।
एक व्यावहारिक नियम: अगर बिज़नेस लॉजिक अक्सर बदलता है तो ELT रिवर्क कम कर देता है; अगर गवर्नेंस केवल क्यूरेटेड डेटा रखने को कहता है तो ETL बेहतर हो सकता है।
CDC बेसिक्स: भारी क्वेरीज के बिना चेंज कैप्चर करना
Change Data Capture (CDC) OLTP से inserts/updates/deletes स्ट्रीम करता है (अक्सर DB लॉग से) और उन्हें आपके एनालिटिक्स सिस्टम में भेजता है। बड़े टेबल्स को बार-बार स्कैन करने की बजाय, CDC सिर्फ़ वही मूव करता है जो बदला है।
यह क्या सक्षम करता है:
- नियर-रियल-टाइम रिपोर्टिंग बिना प्रोडक्शन पर बड़े रीड चलाये
- रीप्ले और बैकफिल जब आपको एनालिटिक्स टेबल्स फिर से बनानी हों
- हिस्ट्री ट्रैकिंग (किसने क्या बदला और कब), अगर आप चेंज इवेंट्स स्टोर करते हैं
डेटा ताजगी: रियल-टाइम बनाम निएर-रियल-टाइम बनाम दैनिक
ताजगी एक बिज़नेस निर्णय है जिसका तकनीकी लागत के साथ समझौता होता है。
- रियल-टाइम (सेकंड): ऑपरेशनल डैशबोर्ड्स के लिए बेस्ट, पर सबसे मुश्किल—छोटी पाइपलाइन हिचकियाँ तुरंत दिखती हैं।
- निएर-रियल-टाइम (मिनट): एक सामान्य मीठा स्थान—बहतर निर्णय-निर्माण बिना अत्यधिक जटिलता के।
- दैनिक बैच: सबसे सरल और सस्ता, वित्त जैसी रिपोर्टिंग के लिए शानदार जहाँ "कल" पर्याप्त है।
स्टेकहोल्डर्स को स्पष्ट SLA दें (उदा.: "डेटा 15 मिनट तक पीछे हो सकता है") ताकि सबको पता हो कि "ताज़ा" का मतलब क्या है।
साइलेंट फेल्स को रोकने वाले डेटा क्वालिटी चेक
पाइपलाइन अक्सर चुपचाप टूट जाती हैं—जब तक कोई देख नहीं लेता। हल्के_checks जोड़ें:
- स्कीमा चेंजेस: नए कॉलम, नाम बदलना, या टाइप चेंज जो डेटा को null कर सकते हैं।
- लेट-अराइविंग इवेंट्स: ऑर्डर्स या पेमेंट्स जो घंटे बाद आते हैं; "लुकबैक विंडो" के साथ संभालें।
- डुप्लिकेट हटाना: retries और replays डबल-काउंट कर सकते हैं; स्थिर IDs और idempotent लोड्स का उपयोग करें।
ये सावधानियाँ OLAP को भरोसेमंद बनाए रखती हैं और OLTP को सुरक्षित रखती हैं।
कब एक ही डेटाबेस साझा करना स्वीकार्य हो सकता है
अपना उपयुक्त टियर चुनें
पहले Koder.ai को मुफ्त में आज़माएँ, फिर जब ज़रूरत हो तो Pro, Business या Enterprise पर जाएँ।
OLTP और OLAP को एक साथ रखना स्वचालित रूप से "गलत" नहीं है। यह अस्थायी रूप से समझदार चुनाव हो सकता है जब एप्लिकेशन छोटा हो, रिपोर्टिंग की ज़रूरतें संकुचित हों, और आप कड़े सीमाएँ लागू कर सकें ताकि एनालिटिक्स अचानक से चेकआउट्स/भुगतान/टाइमआउट्स को प्रभावित न करे।
ऐसी परिस्थितियाँ जहाँ यह काम कर सकता है
छोटे ऐप्स जिनमें हल्की एनालिटिक्स और कड़े क्वेरी लिमिट हों अक्सर एक ही डेटाबेस पर ठीक काम कर लेते हैं—खासकर शुरू में। यहाँ "हल्का" का अर्थ साफ़ होना चाहिए: कुछ डैशबोर्ड्स, सीमित रो काउंट, और क्वेरी रनटाइम/कंकरेन्सी पर स्पष्ट सीमा।
कुछ नियमित रिपोर्ट्स के लिए materialized views या summary tables लागत कम कर सकते हैं। कच्चे ट्रांज़ैक्शन्स के बजाय दैनिक टोटल्स, शीर्ष श्रेणियाँ, या per-customer रोलअप प्रीकम्प्यूट करें—इससे ज़्यादातर क्वेरीज़ छोटी और प्रेडिक्टेबल रहती हैं।
अगर बिज़नेस यूज़र्स देर से नंबर सहन कर सकते हैं, तो ऑफ-पीक रिपोर्टिंग विंडोज मदद करती हैं। भारी जॉब्स रात या लो-ट्रैफ़िक पीरियड पर शेड्यूल करें, और रिपोर्टिंग के लिए एक समर्पित रोल/रोल-आधारित रिसोर्स लिमिट रखें।
जो गार्डरैलब्स आपको जोड़ने चाहिए
- स्टेटमेंट टाइमआउट सेट करें और runaway क्वेरीज़ को कैंसिल करें।
- रिपोर्टिंग उपयोगकर्ताओं के लिए कंकरेन्सी कैप लगाएं।
- मुख्य ट्रांज़ैक्शन्स के लिए p95/p99 लेटेंसी को अलग से मॉनिटर करें।
स्पष्ट चेतावनियाँ कि विभाजन का समय आ गया है
यदि आप पाते हैं कि ट्रांज़ैक्शन लेटेंसी बढ़ रही है, रिपोर्ट रन के दौरान आवर्ती incidents हो रहे हैं, कनेक्शन पूल बार-बार खत्म हो रहा है, या "एक क्वेरी ने प्रोडक्शन डाउन कर दिया" जैसी कहानियाँ सुनने को मिल रही हैं—तो आप सुरक्षित क्षेत्र से बाहर हैं। उस बिंदु पर डेटाबेस अलग करना (कम से कम रीड रेप्लिका का उपयोग) एक ऑप्टिमाइज़ेशन नहीं रहता बल्कि बुनियादी ऑपरेशनल हाइजीन बन जाता है।
व्यावहारिक माइग्रेशन चेकलिस्ट: साझा से अलग की ओर
एनालिटिक्स को प्रोडक्शन डेटाबेस से हटाना "बड़े री-राइट" के बारे में नहीं है—यह काम को दृश्य बनाना, लक्ष्यों का निर्धारण, और नियंत्रित चरणों में माइग्रेट करना है।
1) आज जो सच में हो रहा है उसकी इन्वेंटरी बनाएं
अनुमानों पर नहीं बल्कि साक्ष्य पर शुरू करें। एक सूची निकालें:
- ऊपर के OLTP एंडपॉइंट्स/क्वेरीज (फ्रीक्वेंसी और p95/p99 लेटेंसी के हिसाब से)
- ऊपर के OLAP रिपोर्ट्स/डैशबोर्ड्स (रनटाइम, स्कैन वॉल्यूम, और बिज़नेस इम्पोर्टेंस के हिसाब से)
"छुपी" एनालिटिक्स भी शामिल करें: BI टूल्स से एड-हॉक SQL, शेड्यूल्ड एक्सपोर्ट्स, और CSV डाउनलोड्स।
2) लक्ष्य परिभाषित करें: OLTP SLOs और एनालिटिक्स फ्रेशनैस
लिखें कि आप किन लक्ष्यों के लिए ऑप्टिमाइज़ करेंगे:
- OLTP SLOs: p95/p99 लेटेंसी, एरर रेट, और पीक थ्रूपुट जिसे आपको बनाए रखना है
- एनालिटिक्स फ्रेशनैस: कितना स्टेल स्वीकार्य है (5 मिनट, 1 घंटा, अगला दिन), और पाइपलाइन टूटने पर फिर से बनाने का समय
यह बहस रोकता है कि "यह धीमा है" बनाम "यह ठीक है" और सही आर्किटेक्चर चुनने में मदद करता है।
3) अलगाव पथ चुनें
लक्ष्यों को पूरा करने के लिए सबसे सरल विकल्प चुनें:
- रीड रेप्लिका: रीड-हेवी रिपोर्टिंग के लिए सबसे तेज अपनाने वाला, पर अभी भी महत्त्वपूर्ण सीमाएँ हैं
- वेयरहाउस: बड़े स्कैन, कई जोइन, और लंबी हिस्ट्री के लिए सबसे उपयुक्त; आम तौर पर BI के लिए सही घर
- CDC पाइपलाइन (ETL/ELT): निएर-रियल-टाइम एनालिटिक्स जब आप प्रोडक्शन पर हिट नहीं करना चाहते
4) सुरक्षित तरीके से रोल आउट करें (पहले पैरेलल)
- परिभाषाएँ मान्य करें (टाइमज़ोन, रिफंड्स, "एक्टिव यूज़र" आदि) ताकि नंबर मैच करें।
- एक पूरा बिज़नेस साइकिल के लिए पुराने और नए डैशबोर्ड्स को पैरेलल चलाएं।
- सबसे दर्दनाक क्वेरीज से शुरू करके रिपोर्ट-बाय-रिपोर्ट कटओवर करें।
- एक बार स्टेकहोल्डर्स नए स्रोत पर भरोसा करने लगें, तो प्रोडक्शन पर सीधी "रिपोर्टिंग" एक्सेस लॉक कर दें।
5) रिग्रेशन रोकने के लिए गार्डरैलब्स जोड़ें
रीप्लिका लेग/पाइपलाइन देरी, डैशबोर्ड रनटाइम, और वेयरहाउस खर्च को मॉनिटर करें। क्वेरी बजट (टाइमआउट्स, कंकरेन्सी लिमिट), और एक incident प्लेबुक रखें: फ्रेशनैस स्लिप होने पर, लोड spike होने पर, या प्रमुख मेट्रिक्स डाइव करने पर क्या करना है।
अगर आप खुद एप बना रहे हैं तो व्यावहारिक नोट
यदि आप उत्पाद में जल्दी हैं और तेज़ी से बढ़ रहे हैं, तो सबसे बड़ा खतरा अनजाने में एनालिटिक्स को उसी डेटापाथ में बनाना है जो मुख्य ट्रांज़ैक्शन्स के लिए है (उदा. डैशबोर्ड क्वेरीज़ जो धीरे-धीरे "प्रोडक्शन-क्रिटिकल" बन जाती हैं)। एक तरीका यह है कि शुरू में ही पृथक्करण को डिजाइन करें—भले ही आप एक मामूली रीड रेप्लिका से शुरू करें—और इसे अपनी आर्किटेक्चर चेकलिस्ट में शामिल करें।
प्लेटफॉर्म जैसे Koder.ai इसमें मदद कर सकते हैं क्योंकि आप OLTP साइड (React ऐप + Go सर्विसेज + PostgreSQL) का प्रोटोटाइप बना सकते हैं और रिपोर्टिंग/वेयरहाउस बॉउंड्री को प्लैनिंग मोड में स्केच कर सकते हैं इससे पहले कि आप शिप करें। जैसे-जैसे प्रोडक्ट बढ़ता है, आप सोर्स कोड एक्सपोर्ट कर सकते हैं, स्कीमा विकसित कर सकते हैं, और CDC/ELT कंपोनेंट्स जोड़ सकते हैं—बिना "प्रोडक्शन पर रिपोर्टिंग" को स्थायी आदत बनाए।