03 नव॰ 2025·8 मिनट
लेस्ली लैम्पोर्ट और वितरित प्रणालियाँ: समय, क्रम, और सहीपन
लैम्पोर्ट के प्रमुख वितरित-प्रणाली विचार—लॉजिकल क्लॉक्स, क्रम निर्धारण, कंसेंसस, और सहीपन—सीखें और जानें कि ये आधुनिक इंफ़्रास्ट्रक्चर को आज भी क्यों निर्देशित करते हैं।
आधुनिक वितरित प्रणालियों के लिए लैम्पोर्ट का महत्व
लेस्ली लैम्पोर्ट उन कम शोधकर्ताओं में से हैं जिनका “सैद्धांतिक” काम हर बार एक असली सिस्टम भेजते समय सामने आता है। अगर आपने कभी डेटाबेस क्लस्टर, मैसेज क्यू, वर्कफ्लो इंजन या कोई भी ऐसी चीज़ चलाई है जो अनुरोधों को रीट्राय करती है और फेल्योर से बचती है, तो आप उन समस्याओं के बीच जी रहे हैं जिन्हें लैम्पोर्ट ने नाम दिए और हल किए।
उनके विचार इसलिए टिक जाते हैं क्योंकि वे किसी विशिष्ट तकनीक से बंधे नहीं हैं। वे उन कड़वी सच्चाइयों का वर्णन करते हैं जो तब उभरती हैं जब कई मशीनें एक ही सिस्टम की तरह काम करने की कोशिश करती हैं: क्लॉक्स असहमति करते हैं, नेटवर्क संदेशों को विलंबित या ड्रॉप कर देता है, और फेल्योर सामान्य हैं—असाधारण नहीं।
तीन थीम जिन्हें हम बार-बार उपयोग करेंगे
समय: एक वितरित सिस्टम में, “अब क्या समय है?” सरल प्रश्न नहीं है। भौतिक क्लॉक्स अलग-अलग बहकते हैं, और विभिन्न मशीनों द्वारा देखी गई घटनाओं का क्रम अलग हो सकता है।
क्रम: जब आप किसी एक क्लॉक पर भरोसा नहीं कर सकते, तो आपको यह बताने के अन्य तरीकों की ज़रूरत है कि कौन-सी घटनाएँ पहले हुईं—और कब आपको सबको एक ही अनुक्रम का पालन कराना चाहिए।
सहीपन: “यह अक्सर काम कर जाता है” एक डिज़ाइन नहीं है। लैम्पोर्ट ने फील्ड को स्पष्ट परिभाषाओं (सुरक्षा vs. जीवंतता) और ऐसे स्पेक्स की ओर धकेला जिन्हें आप सिर्फ़ टेस्ट नहीं कर, बल्कि तर्कसंगत तरीके से जांच सकें।
क्या अपेक्षित है (कोई भारी गणित नहीं)
हम अवधारणाओं और intuition पर ध्यान देंगे: समस्याएँ, स्पष्ट सोच के लिए कम से कम उपकरण, और कैसे वे व्यावहारिक डिज़ाइनों को आकार देते हैं।
नक्शा यहाँ है:
- क्यों साझा क्लॉक न होने पर घटनाओं की एक एकल वैश्विक कहानी संभव नहीं
- कैसे कारण-परिणाम ("happened-before") लॉजिक क्लॉक्स और लैम्पोर्ट टाइमस्टैम्प की ओर ले जाता है
- कब आंशिक क्रम पर्याप्त नहीं होता और आपको एक समग्र समयरेखा की ज़रूरत होती है
- सहमति और पैक्सोस का क्रम पर सहमति से कैसे संबंध है
- जब क्रम साझा होता है तो स्टेट-मशीन रेप्लीकेशन कैसे काम करता है
- स्पेक में सहीपन कैसे कहा जाता है—और TLA+ जैसे मॉडलिंग उपकरण कैसे मदद करते हैं
मूल समस्या: साझा क्लॉक नहीं, एकल वास्तविकता नहीं
एक सिस्टम "वितरित" होता है जब वह कई मशीनों से मिलकर नेटवर्क पर समन्वय करके एक ही काम करता है। यह सरल लगता है जब तक आप दो बातों को स्वीकार कर लेते हैं: मशीनें स्वतंत्र रूप से फेल कर सकती हैं (आंशिक फेल्योर), और नेटवर्क संदेशों को विलंबित, ड्रॉप, डुप्लीकेट या री-ऑर्डर कर सकता है।
एक ही कंप्यूटर पर एक प्रोग्राम में आप आमतौर पर यह बता सकते हैं कि "कौन सी घटना पहले हुई।" एक वितरित सिस्टम में, अलग-अलग मशीनें विभिन्न घटनाओं के अनुक्रम देख सकती हैं—और दोनों अपने-अपने स्थानीय दृष्टिकोण से सही हो सकती हैं।
आप वैश्विक क्लॉक पर भरोसा क्यों नहीं कर सकते
समन्वय को हर चीज़ को टाइमस्टैम्प देने से हल करना लुभावना है। लेकिन मशीनों के बीच कोई एकल क्लॉक भरोसेमंद नहीं है:
- हर सर्वर का हार्डवेयर क्लॉक अपनी अलग दर पर बहकता है।
- क्लॉक सिंक्रोनाइज़ेशन (जैसे NTP) सर्वोत्तम-प्रयास होता है, गारंटी नहीं।
- वर्चुअलाइजेशन, CPU लोड, या पोज़ के कारण समय कूद या रुक सकता है।
इसलिए एक होस्ट पर “घटना A 10:01:05.123 पर हुई” दूसरे पर “10:01:05.120” से विश्वसनीय रूप से तुलना नहीं की जा सकती।
विलंब कैसे वास्तविकता को उलझाता है
नेटवर्क विलंब वे चीज़ें उलट सकते हैं जो आपने देखी थीं। कोई write पहले भेजा गया हो सकता है पर बाद में पहुँचे। एक retry मूल संदेश के बाद आ सकता है। दो डेटा सेंटर एक ही अनुरोध को उल्टे क्रम में प्रोसेस कर सकते हैं।
इससे डिबगिंग विशेष रूप से उलझन भरी हो जाती है: अलग-अलग मशीनों के लॉग असहमत हो सकते हैं, और "टाइमस्टैम्प के अनुसार सॉर्ट" एक ऐसी कहानी बना सकता है जो वास्तव में कभी नहीं हुई।
वास्तविक परिणाम
जब आप एक ऐसे समयरेखा का अनुमान लगाते हैं जो मौजूद नहीं है, तो आप ठोस विफलताएँ पाते हैं:
- दोहरा प्रोसेसिंग (रीट्राय के बाद एक ही भुगतान दो बार चार्ज होना)
- असंगतताएँ (दो उपयोगकर्ता दोनों "अंतिम आइटम" को सफलतापूर्वक दावा करते हैं)
- प्रत्याशित डेटा हानि (बाद में आने वाला अपडेट नए वाले को ओवरराइट कर दे)
यहाँ से लैम्पोर्ट की मुख्य अंतर्दृष्टि शुरू होती है: अगर आप समय साझा नहीं कर सकते, तो आपको क्रम के बारे में अलग तरह से तर्क करना होगा।
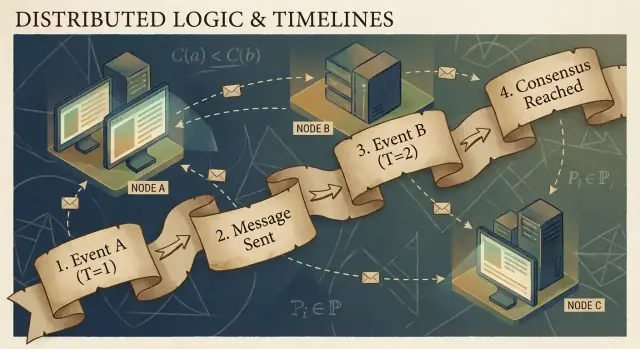
कारणता और Happened-Before संबंध
वितरित कार्यक्रम घटनाओं से बने होते हैं: किसी विशेष नोड (प्रोसेस, सर्वर, या थ्रेड) पर होने वाली कोई क्रिया। उदाहरण: “एक अनुरोध मिला”, “एक पंक्ति लिखी”, या “संदेश भेजा गया”। एक संदेश नोड्स के बीच कड़ी है: एक घटना send होती है, दूसरी घटना receive।
लैम्पोर्ट की महत्वपूर्ण समझ यह है कि एक भरोसेमंद साझा क्लॉक के बिना, सबसे भरोसेमंद चीज़ जिसे आप ट्रैक कर सकते हैं वह है कारणता—कौन-सी घटनाएँ किस अन्य घटनाओं को प्रभावित कर सकती हैं।
happened-before संबंध (→)
लैम्पोर्ट ने एक सरल नियम परिभाषित किया जिसे happened-before कहा जाता है, और इसे A → B लिखा जाता है (घटना A ने घटना B से पहले हुई):
- एक ही प्रोसेस क्रम: यदि A और B एक ही मशीन/प्रोसेस पर होते हैं, और उस प्रोसेस में A पहले होता है, तो A → B।
- संदेश क्रम: यदि A “संदेश m भेजा” है और B “संदेश m प्राप्त किया” है, तो A → B।
- ट्रांज़िटिविटी: यदि A → B और B → C, तो A → C।
यह संबंध आपको एक आंशिक क्रम देता है: यह बताता है कि कुछ जोड़े क्रमबद्ध हैं, पर सभी नहीं।
एक ठोस कहानी: उपयोगकर्ता → अनुरोध → DB → कैश
एक उपयोगकर्ता "खरीदो" पर क्लिक करता है। वह क्लिक API सर्वर को एक अनुरोध ट्रिगर करता है (घटना A)। सर्वर डेटाबेस में एक ऑर्डर रो लिखता है (घटना B)। लिखने के पूरा होने के बाद, सर्वर एक "order created" संदेश प्रकाशित करता है (घटना C), और एक कैश सेवा उसे प्राप्त कर के कैश अपडेट करती है (घटना D)।
यहाँ A → B → C → D है। भले ही क्लॉक्स असहमत हों, संदेश और प्रोग्राम संरचना वास्तविक कारणात्मक कड़ियाँ बनाती हैं।
"सहकालिक" होने का असली मतलब
दो घटनाएँ सहकालिक तब होती हैं जब न तो किसी का कारण दूसरे में है: न (A → B) और न (B → A)। सहकालिकता का मतलब “एक ही समय” नहीं है—यह मतलब है “उनके बीच कोई कारणात्मक पथ नहीं है।” इसलिए दो सेवाएँ हर एक दावा कर सकती हैं कि उन्होंने "पहले" कार्य किया, और दोनों सही हो सकती हैं जब तक आप कोई क्रम नियम नहीं जोड़ते।
लॉजिकल क्लॉक्स: लैम्पोर्ट टाइमस्टैम्प्स सरल शब्दों में
यदि आपने कभी कई मशीनों में "कौन पहले हुआ" फिर से reconstruct करने की कोशिश की है, तो आपने बुनियादी समस्या का सामना किया है: कंप्यूटर एक संपूर्ण समकालिक क्लॉक साझा नहीं करते। लैम्पोर्ट का हल यह है कि आप परफेक्ट समय के पीछे न भागें और इसके बजाय क्रम ट्रैक करें।
विचार: हर घटना पर एक काउंटर
एक लैम्पोर्ट टाइमस्टैम्प बस हर महत्वपूर्ण घटना पर संलग्न एक संख्या है (प्रत्येक प्रक्रिया/नोड पर)। इसे एक "इवेंट काउंटर" के रूप में सोचें जो आपको एक सुसंगत तरीका देता है कहने का, “यह घटना उस घटना से पहले हुई,” भले ही वॉल-क्लॉक अविश्वसनीय हो।
दो नियम (और वे सचमुच इतने ही सरल हैं)
-
स्थानीय वृद्धि: किसी घटना को रिकॉर्ड करने से पहले (जैसे "DB लिखा", "रिक्वेस्ट भेजा", "लॉग में जोड़ा"), अपने स्थानीय काउंटर को बढ़ाएँ।
-
प्राप्ति पर max + 1 लें: जब आप किसी संदेश को प्राप्त करते हैं जिसमें भेजने वाले का टाइमस्टैम्प होता है, तो अपने काउंटर को सेट करें:
max(local_counter, received_counter) + 1
फिर उस प्राप्ति घटना को उस मान से स्टैम्प करें।
ये नियम causality का सम्मान करते हैं: यदि घटना A ने घटना B को प्रभावित किया हो (संदेश के माध्यम से जानकारी गई), तब A का टाइमस्टैम्प B से कम होगा।
लैम्पोर्ट टाइमस्टैम्प क्या बता सकते हैं — और क्या नहीं
वे कारणात्मक क्रम के बारे में बता सकते हैं:
- अगर
TS(A) < TS(B), तो A शायद B से पहले हुआ। - यदि A ने B को कारण दिया है (प्रत्यक्ष या अप्रत्यक्ष), तो ज़रूरी रूप से
TS(A) < TS(B)होगा।
वे वास्तविक समय के बारे में नहीं बता सकते:
- एक छोटा टाइमस्टैम्प सेकंड में "पहले" होने का मतलब नहीं रखता।
- दो घटनाएँ सहकालिक हो सकती हैं (कोई कारणात्मक पथ नहीं) और फिर भी अलग टाइमस्टैम्प्स प्राप्त कर सकती हैं संदेश पैटर्न के कारण।
इसलिए लैम्पोर्ट टाइमस्टैम्प क्रम के लिए शानदार हैं, लेटेंसी नापने या "यह किस समय हुआ" जैसे प्रश्नों के जवाब के लिए नहीं।
व्यावहारिक उदाहरण: सेवाओं के पार लॉग एंट्रीज़ का क्रम
कल्पना कीजिए सर्विस A सर्विस B को कॉल करती है, और दोनों ऑडिट लॉग लिखते हैं। आप एक एकीकृत लॉग दृश्य चाहते हैं जो कारण और प्रभाव को बनाए रखता है।
- सर्विस A अपना काउंटर बढ़ाती है, "payment शुरू" लॉग करती है, B को अनुरोध भेजती है टाइमस्टैम्प 42 के साथ।
- सर्विस B 42 के साथ अनुरोध प्राप्त करती है, अपना काउंटर
max(local, 42) + 1सेट कर के, मान लीजिए 43, और "कार्ड Validate किया" लॉग करती है। - B 44 के साथ उत्तर भेजता है; A उसे प्राप्त कर 45 पर अपडेट करता है और "payment पूरा" लॉग करता है।
अब जब आप दोनों सेवाओं के लॉग एग्रीगेट करते हैं, तो (lamport_timestamp, service_id) के अनुसार सॉर्ट करने पर आपको एक स्थिर, समझाने योग्य टाइमलाइन मिलती है जो वास्तविक प्रभाव की श्रृंखला से मिलती है—भले ही वॉल-क्लॉक्स बहक गए हों या नेटवर्क विलंबित रहा हो।
आंशिक क्रम से कुल क्रम तक: कब आपको एक एकल टाइमलाइन चाहिए
कारणता आपको एक आंशिक क्रम देती है: कुछ घटनाएँ स्पष्ट रूप से दूसरों “से पहले” हैं (क्योंकि संदेश या निर्भरता उन्हें जोड़ते हैं), पर कई घटनाएँ बस सहकालिक होती हैं। यह कोई बग नहीं—यह वितरित वास्तविकता की प्रकृति है।
आंशिक क्रम: कई सवालों के लिए पर्याप्त
यदि आप यह डिबग कर रहे हैं कि "किसने इस पर प्रभाव डाला हो सकता है?", या ऐसे नियम लागू कर रहे हैं जैसे "एक उत्तर को उसके अनुरोध के बाद आना चाहिए", तो आंशिक क्रम बिल्कुल वही है जिसकी आपको ज़रूरत है। आपको केवल happened-before एज का सम्मान करना है; बाकी को स्वतंत्र माना जा सकता है।
कुल क्रम: जब सिस्टम को एक कहानी चुननी ही होगी
कुछ सिस्टम "दोनों आदेश ठीक हैं" के साथ नहीं रह सकते। उन्हें एक एकल अनुक्रम चाहिए, खासकर उन मामलों में:
- साझा ऑब्जेक्ट पर लिखाइयाँ ("बैलेंस सेट करें", "प्रोफाइल अपडेट करें", "लॉग में जोड़ें")
- कमांड जिन्हें हर जगह समान रूप से लागू होना चाहिए (स्टेट-मशीन रेप्लीकेशन)
- संघर्ष समाधान जहां "लेटेस्ट राइट विन्स" का मतलब हर नोड के लिए एक जैसा होना चाहिए
कुल क्रम के बिना, दो रेप्लिका दोनों स्थानीय रूप से "सही" रह सकते हैं पर वैश्विक रूप से अलग हो सकते हैं: एक A फिर B लागू कर सकता है, दूसरा B फिर A, और आपको अलग परिणाम मिलते हैं।
एक टाइमलाइन आप कैसे बनाते हैं?
आप एक ऐसा तंत्र जोड़ते हैं जो क्रम बनाता है:
- एक सीक्वेंसर/लीडर जो प्रत्येक कमांड को एक मोनोटोनिक बढ़ती स्थिति देता है।
- या कंसेंसस (जैसे Paxos-शैली) ताकि क्लस्टर अगला लॉग एंट्री किसका होगा इस पर देरी और फेल्योर के बावजूद सहमत हो सके।
आप जिन ट्रेड-ऑफ़्स से बच नहीं सकते
एक कुल क्रम शक्तिशाली है, पर इसकी कीमत होती है:
- लेटेंसी: आप कभी-कभी कमिट से पहले समन्वय का इंतजार करते हैं।
- थ्रूपुट: एक एकल ऑर्डर्ड लॉग बॉटलनेकट बन सकता है।
- फेल्योर के दौरान उपलब्धता: अगर आप पर्याप्त नोड्स तक नहीं पहुँच पाते, तो प्रोग्रेस रोक सकती है ताकि सहीपन सुरक्षित रहे।
डिज़ाइन विकल्प सरल है: जब सहीपन को एक साझा कहानी चाहिए, तो इसे पाने के लिए समन्वय लागत चुकानी होगी।
कंसेंसस: देरी और फेल्योर की उपस्थिति में सहमति हासिल करना
इसे प्रोडक्शन जैसा चलाएँ
अपना प्रोटोटाइप डिप्लॉय करें और partitions व timeouts टेस्ट करते समय इसे साझा रखने योग्य रखें।
कंसेंसस वह समस्या है जिसमें कई मशीनों को एक निर्णय—एक मान जिसे कमिट किया जाए, एक लीडर जिसे फॉलो किया जाए, या एक कॉन्फ़िगरेशन को सक्रिय किया जाए—पर सहमत होना होता है, भले ही प्रत्येक मशीन केवल अपने स्थानीय घटनाएँ और जो संदेश उसे मिले देखते हों।
यह सरल लगता है जब तक आप यह याद नहीं करते कि एक वितरित सिस्टम क्या कर सकता है: संदेश विलंबित, डुप्लिकेट, पुनः क्रमबद्ध, या खोए जा सकते हैं; मशीनें क्रैश और रीस्टार्ट कर सकती हैं; और आपको शायद ही कभी यह क्लीन सिग्नल मिलता है कि "यह नोड निश्चित रूप से मर चुका है।" कंसेंसस सुरक्षित सहमति पाने के बारे में है इन स्थितियों में।
सहमति कठिन क्यों है
अगर दो नोड अस्थायी रूप से बात नहीं कर सकते (नेटवर्क पार्टिशन), तो प्रत्येक तरफ़ अपना-सा "आगे बढ़ने" की कोशिश कर सकता है। अगर दोनों पक्ष अलग-अलग मानों को चुन लें, तो आप स्प्लिट-ब्रेन व्यवहार में आ सकते हैं: दो लीडर, दो अलग कॉन्फ़िगरेशन, या दो प्रतिस्पर्धी इतिहास।
यहाँ तक कि पार्टिशन के बिना भी, बस विलंब परेशानी पैदा करता है। जब तक किसी नोड को किसी प्रस्ताव के बारे में पता चलता है, बाकी नोड आगे बढ़ चुके हो सकते हैं। कोई साझा क्लॉक नहीं होने से, आप किसी प्रस्ताव A को प्रस्ताव B से पहले होने का भरोसा भौतिक समय के आधार पर नहीं बता सकते।
वास्तविक सिस्टमों में आप कंसेंसस कहां मिलते हैं
आप रोज़-रोज़ इसे "कंसेंसस" नहीं कह सकते, पर यह आम इन्फ्रास्ट्रक्चर टास्क में दिखाई देता है:
- लीडर चुनाव (अभी कौन प्रभारी है?)
- रेप्लिकेटेड लॉग (साझा इतिहास में अगली एंट्री क्या है?)
- कॉन्फ़िगरेशन बदलना (कौन से नोड्स वोट कर सकते/कमिट कर सकते?)
हर मामले में, सिस्टम को एक ही परिणाम चाहिए जिस पर सब समेकित हों, या कम से कम एक नियम जो ये सुनिश्चित करे कि विरोधी परिणाम दोनों वैध नहीं माने जाएँ।
पैक्सोस—लैम्पोर्ट का उत्तर
लैम्पोर्ट का Paxos इस "सुरक्षित सहमति" समस्या का मौलिक समाधान है। मुख्य विचार कोई जादुई टाइमआउट या परफेक्ट लीडर नहीं है—बल्कि नियमों का एक सेट है जो यह सुनिश्चित करता है कि केवल एक मान चुना जा सकता है, भले ही संदेश देर से आएँ और नोड फेल हों।
Paxos सुरक्षा ("दो अलग मान कभी न चुने जाएँ") और प्रगति ("आखिरकार कुछ चुना जाएगा") को अलग करता है, जो इसे व्यावहारिक ब्लूप्रिंट बनाता है: आप वास्तविक दुनिया के प्रदर्शन के लिए ट्यून कर सकते हैं जबकि मूल गारंटी बरकरार रहती है।
पैक्सोस, सिरदर्द के बिना: मुख्य सुरक्षा अंतर्दृष्टि
Paxos की ख्याति जटिल होने की है, पर इसका बड़ा कारण यह है कि "Paxos" एक सटीक एक-लाइनर एल्गोरिथ्म नहीं है। यह आपस में जुड़ी अनेक पैटर्न्स का परिवार है जो समूह को सहमत कराती हैं, भले ही संदेश विलंबित, डुप्लिकेट, या मशीनें अस्थायी रूप से फेल हों।
पात्र: प्रस्तावक, स्वीकर्ता, और क्वोरम
एक उपयोगी मानसिक मॉडल यह है कि "कौन सुझाता है" और "कौन मान्य करता है" को अलग करें।
- प्रपोज़र्स किसी मान को चुना जाने की कोशिश करते हैं (उदा.: "अगली लॉग एंट्री X है")।
- एक्सेप्टर्स प्रस्तावों पर वोट करते हैं।
- एक क्वोरम वह होता है जो प्रगति के लिए पर्याप्त स्वीकर्ता है—आम तौर पर बहुमत।
एक संरचनात्मक विचार यह है: किसी भी दो बहुमतों का ओवरलैप होता है। वही ओवरलैप सुरक्षा का घर है।
सुरक्षा लक्ष्य: दो अलग मान कभी न चुने जाएँ
Paxos सुरक्षा को सरल रूप में कहा जा सकता है: एक बार जब सिस्टम ने किसी मान का निर्णय कर लिया, तो उसे कभी किसी अलग मान का निर्णय नहीं करना चाहिए—कोई स्प्लिट-ब्रेन निर्णय नहीं।
मुख्य अंतर्दृष्टि यह है कि प्रस्ताव संख्याएँ (बैलट IDs की तरह) साथ लेकर आते हैं। एक्सेप्टर्स पुराने-संख्यांकित प्रस्तावों को तब तक नज़रअंदाज़ करने का वचन देते हैं जब तक उन्होंने नया नहीं देखा। और जब कोई प्रस्तावक नए नंबर के साथ कोशिश करता है, तो वह पहले क्वोरम से पूछता है कि उन्होंने पहले क्या एक्सेप्ट किया है।
क्वोरम के ओवरलैप के कारण, नया प्रस्तावक कम से कम एक ऐसे एक्सेप्टर से सुन-वालेगा जिसने सबसे हाल में एक्सेप्ट किया हुआ मान याद रखा होगा। नियम यह है: यदि क्वोरम में किसी ने कुछ एक्सेप्ट कर लिया है, तो आपको वही मान (या उनमें सबसे नया) प्रस्तावित करना चाहिए। यह बंधन दो अलग मानों के चुने जाने को रोकता है।
जीवंतता, उच्च-स्तर पर
जीवंतता का मतलब है कि सिस्टम अंततः कुछ निर्णय तक पहुँचता है उपयुक्त परिस्थितियों में (उदा., एक स्थिर लीडर उभरता है, और नेटवर्क अंततः संदेश पहुँचाता है)। Paxos अराजकता में गति की गारंटी नहीं देता; यह correctness (सहीपन) की गारंटी देता है, और एक बार चीज़ें शांत होने पर प्रगति।
स्टेट-मशीन रेप्लीकेशन: साझा क्रम के माध्यम से सहीपन
रिप्लिकेटेड लॉग का प्रोटोटाइप बनाएं
React UI और Go तथा PostgreSQL बैकएंड के साथ रिप्लिकेटेड लॉग API का प्रोटोटाइप बनाएं।
स्टेट-मशीन रेप्लीकेशन (SMR) कई "High availability" सिस्टमों के पीछे की वर्कहॉर्स पैटर्न है: एक सर्वर के निर्णय लेने के बजाय आप कई रेप्लिका चलाते हैं जो एक ही क्रम के कमांड प्रोसेस करते हैं।
रेप्लिकेटेड लॉग विचार
केंद्र में एक रेप्लिकेटेड लॉग होता है: कमांड्स की एक क्रमबद्ध सूची जैसे "put key=K value=V" या "A से B को $10 ट्रांसफर करें"। क्लाइंट्स कमांड्स को हर रेप्लिका को भेजने और उम्मीद करने के बजाय समूह को सबमिट करते हैं, और सिस्टम उन कमांड्स के लिए एक क्रम तय करता है, फिर हर रेप्लिका उन्हें लोकली लागू करती है।
क्यों क्रम आपको सहीपन देता है
अगर हर रेप्लिका एक ही प्रारंभिक स्थिति से शुरू होती है और एक ही आदेश में समान कमांड्स को निष्पादित करती है, तो वे एक ही स्थिति में समाप्त होंगी। यही मुख्य सुरक्षा विचार है: आप कई मशीनों को समय से सिंक्रोनाइज़ करने की कोशिश नहीं कर रहे; आप उन्हें deterministic और साझा क्रम के माध्यम से एकसमान बना रहे हैं।
इसी कारण से कंसेंसस (जैसे Paxos/Raft) अक्सर SMR के साथ जोड़ा जाता है: कंसेंसस अगली लॉग एंट्री तय करता है, और SMR उस निर्णय को रेप्लिकास में एक सुसंगत स्थिति में बदल देता है।
असली सिस्टमों में आप इसे कहाँ देखते हैं
- कॉर्डिनेशन सर्विसेज (जैसे कॉन्फ़िगरेशन और लीडर चुनाव के लिए)
- रिप्लिकेटेड write-ahead लॉग वाले डेटाबेस
- मैसेज सिस्टम जो कड़ियों के सख्त ऑर्डर की माँग करते हैं
व्यावहारिक चिंताएँ जिन्हें इंजीनियर्स अनदेखा नहीं कर सकते
लॉग अनंत तक बढ़ता रहेगा जब तक आप इसे प्रबंधित न करें:
- स्नैपशॉट्स: समय-समय पर वर्तमान स्थिति का स्नैपशॉट लें ताकि नए नोड्स पूरे इतिहास को रीकॅप्ले किए बिना पकड़ सकें।
- लॉग कम्पैक्शन: सुरक्षित तरीके से पुराने लॉग एंट्रीज़ को डिस्कार्ड करें जब वे स्नैपशॉट में परिलक्षित हों और अब ज़रूरी न हों।
- सदस्यता परिवर्तन: रेप्लिकास जोड़ना/हटाना भी क्रमबद्ध होना चाहिए, वरना अलग नोड्स समूह के बारे में असहमत हो सकते हैं और स्प्लिट-ब्रेन पैदा हो सकता है।
SMR जादू नहीं है; यह "ऑर्डर पर सहमति" को "स्टेट पर सहमति" में बदलने का अनुशासित तरीका है।
सहीपन: सुरक्षा, जीवंतता, और स्पष्ट स्पेक लिखना
वितरित सिस्टम अजीब तरह से फेल होते हैं: संदेश देरी से आते हैं, नोड्स रीस्टार्ट होते हैं, क्लॉक्स असहमत होते हैं, और नेटवर्क स्प्लिट होते हैं। "सहीपन" सिर्फ एक भावना नहीं है—यह वादों का एक सेट है जिसे आप सटीक रूप से बताकर हर स्थिति, सहित फेल्योर, के खिलाफ जाँच सकते हैं।
सुरक्षा बनाम जीवंतता (ठोस उदाहरणों के साथ)
सुरक्षा का मतलब है "कुछ भी गलत कभी न हो।" उदाहरण: एक रेप्लिकेटेड की-वैल्यू स्टोर में, एक ही लॉग इंडेक्स पर दो अलग मान कभी कमिट नहीं होने चाहिए। एक और उदाहरण: एक लॉक सर्विस एक ही समय पर दो क्लाइंट्स को उतना ही लॉक कभी न दे।
जीवंतता का मतलब है "अंततः कुछ अच्छा होता है।" उदाहरण: अगर अधिकाँश रेप्लिकास चल रहे हैं और नेटवर्क अंततः संदेश पहुँचाता है, तो एक write अनुरोध अंततः पूरा होता है। एक लॉक अनुरोध को अंततः हाँ या न मिलना चाहिए (अनंत प्रतीक्षा नहीं)।
सुरक्षा विरोधाभासों को रोकने के बारे में है; जीवंतता स्थायी स्टॉल्स से बचने के बारे में।
इन्वेरिएन्ट्स: आपके नॉन-नेगोशिएबल्स
एक इन्वेरिएन्ट ऐसी शर्त है जो हर पहुंचने योग्य स्थिति में हमेशा सत्य होनी चाहिए। उदाहरण:
- “हर लॉग इंडेक्स के लिए अधिकतम एक कमिटेड वैल्यू हो सकती है।”
- “एक लीडर का टर्म नंबर कभी घटता नहीं।”
यदि कोई इन्वेरिएन्ट क्रैश, टाइमआउट, रीट्राय, या पार्टिशन के दौरान उल्लंघन हो सकता है, तो वह वास्तव में लागू नहीं किया गया।
यहाँ ‘प्रूफ’ का मतलब क्या है
एक प्रूफ ऐसा तर्क है जो सभी संभावित निष्पादनों को कवर करे, सिर्फ सामान्य मार्ग को नहीं। आप हर केस के बारे में तर्क करते हैं: संदेश हानि, डुप्लीकेशन, रीर-ऑर्डरिंग; नोड क्रैश और रीस्टार्ट; प्रतिस्पर्धी लीडर; क्लाइंट्स के रीट्राय।
स्पेसिफ़िकेशन अचानक व्यवहारों को रोकती है
एक स्पष्ट स्पेक राज्य, अनुमति दी गई क्रियाएँ, और आवश्यक गुण परिभाषित करता है। यह अस्पष्ट अपेक्षाओं को रोकता है जैसे "सिस्टम सुसंगत होना चाहिए" जो उत्पादन में आपको कठोर तरीके से नहीं बताता कि विभाजन के दौरान क्या होगा, "commit" का क्या मतलब है, और क्लाइंट क्या भरोसा कर सकते हैं—उसे प्रोडक्शन से पहले निर्दिष्ट कर दें तो समस्याएँ कम होंगी।
सिद्धांत से अभ्यास तक: TLA+ के साथ मॉडलिंग
लैम्पोर्ट का एक सबसे व्यावहारिक सबक यह है कि आप (और अक्सर आपको करना चाहिए) एक वितरित प्रोटोकॉल को कोड से ऊपर एक उच्च स्तर पर डिज़ाइन करें। थ्रेड्स, RPCs, और रीट्राय लूप्स की चिंता करने से पहले, आप सिस्टम के नियम लिख सकते हैं: कौन-सी क्रियाएँ अनुमति है, किस स्थिति को बदल सकती हैं, और क्या कभी नहीं होना चाहिए।
TLA+ किसके लिए है
TLA+ एक स्पेसिफिकेशन भाषा और मॉडल-चेकिंग टूलकिट है जो समवर्ती और वितरित सिस्टमों का वर्णन करने के लिए है। आप सिस्टम का एक सरल, गणित-सा मॉडल लिखते हैं—राज्य और ट्रांज़िशन्स—साथ ही उन गुणों को भी जो आप चाहते हैं (उदा., "अधिकतम एक लीडर" या "किसी कमिटेड एंट्री का कभी गायब न होना").
फिर मॉडल-चेकर संभावित इंटरलिविंग्स, संदेश विलंब और फेल्यर्स की खोज करके एक काउंटरएक्ज़ैंपल देता है: एक ठोस चरणों का अनुक्रम जो आपकी संपत्ति तोड़ता है। बैठकों में किन्हीं किनारे-मामलों पर बहस करने के बजाय, आपको एक निष्पादन योग्य तर्क मिलता है।
एक बग जो मॉडल पकड़ सकता है
किसी रेप्लिकेटेड लॉग में "commit" कदम पर विचार करें। कोड में, दुर्लभ टाइमिंग में आप गलती से दो अलग नोड्स को एक ही इंडेक्स पर दो अलग एंट्रीज़ कमिट करने की अनुमति दे सकते हैं।
एक TLA+ मॉडल एक ट्रेस दिखा सकता है:
- नोड A क्वोरम से सुनकर इंडेक्स 10 पर एंट्री X को कमिट करता है।
- नोड B (स्टेल्ड डेटा के साथ) भी क्वोरम बना कर इंडेक्स 10 पर एंट्री Y को कमिट कर देता है।
यह एक डुप्लिकेट कमिट है—एक सुरक्षा उल्लंघन जो प्रोडक्शन में महीने में एक बार ही दिख सकता है, पर exhaustive search में जल्दी दिख जाता है। ऐसे मॉडल अक्सर खोए अपडेट्स, डबल-अप्लाई, या “ack पर परमानेंट न होना” जैसी समस्याएँ पकड़ते हैं।
कब मॉडल करना उपयोगी है
TLA+ सबसे ज़्यादा मूल्यवान है उन क्रिटिकल समन्वय तर्कों के लिए: लीडर चुनाव, सदस्यता परिवर्तन, कंसेंसस-जैसे फ्लो, और कोई भी प्रोटोकॉल जहाँ क्रम और फेल्योर हैंडलिंग इंटरैक्ट करते हैं। अगर एक बग डेटा को भ्रष्ट कर देगा या मैन्युअल रिकवरी माँगेगा, तो एक छोटा मॉडल आमतौर पर बाद में डिबग करने से सस्ता होता है।
यदि आप इन विचारों के चारों ओर आंतरिक टूलिंग बना रहे हैं, तो एक व्यावहारिक वर्कफ़्लो यह है कि एक हल्का स्पेक (यहाँ तक कि अनौपचारिक) लिखें, फिर सिस्टम इम्प्लिमेंट करें और स्पेक के इन्वेरिएन्ट्स से टेस्ट जेनरेट करें। Koder.ai जैसे प्लेटफ़ॉर्म इस प्रक्रिया को तेज़ कर सकते हैं: आप सामान्य भाषा में ऑर्डरिंग/कंसेंसस व्यवहार का वर्णन कर सकते हैं, सर्विस स्कैफोल्डिंग (React फ्रंटेंड, Go बैकएंड PostgreSQL के साथ, या Flutter क्लाइंट) पर तेज़ी से इटरेशन कर सकते हैं, और "क्या कभी नहीं होना चाहिए" को दिखाते हुए शिप कर सकते हैं।
भरोसेमंद सिस्टम बनाने और ऑपरेट करने के लिए व्यावहारिक निष्कर्ष
ऑर्डरिंग डेमो बनाएं
अपनी ऑर्डरिंग आइडियाज़ को एक कार्यशील Go सर्विस में बदलें और साधारण चैट से सुधारें।
लैम्पोर्ट का बड़ा उपहार प्रैक्टिशनर्स के लिए एक माइंडसेट है: समय और क्रम को ऐसी चीज़ के रूप में मॉडल करें जो आप परिभाषित करते हैं, न कि वॉल-क्लॉक से मिलने वाली धरोहर मान्यताओं के रूप में। यह माइंडसेट उन आदतों में बदल जाता है जिन्हें आप सोमवार से लागू कर सकते हैं।
सिद्धांत को रोज़मर्रा की इंजीनियरिंग प्रथाओं में बदलें
अगर संदेश विलंबित, डुप्लीकेट, या क्रमबद्ध नहीं आते हो सकते हैं, तो हर इंटरैक्शन को उन शर्तों के तहत सुरक्षित बनाएं।
- डिफ़ॉल्ट रूप से आइडेम्पोटेंसी: "दोबारा करना" हानिरहित बनाएँ। भुगतान, प्रोविज़निंग, या किसी भी ऐसे राइट के लिए आइडेम्पोटेंसी कीज़ का उपयोग करें जिन्हें आप रीट्राय कर सकते हैं।
- रीट्राय्स के साथ डेडुप्लिकेशन: रीट्राय्स ज़रूरी हैं, पर बिना डुप्लिकेशन के आप डबल-राइट बना देंगे। रिक्वेस्ट IDs ट्रैक करें और "पहले से प्रोसेस्ड" मार्कर स्टोर करें।
- कम से कम-एक बार डिलीवरी + बिल्कुल-एक बार प्रभाव: स्वीकार करें कि नेटवर्क दो बार डिलीवर कर सकता है; सुनिश्चित करें कि आपकी स्टेट चेंजेस दो बार नहीं हों।
टाइमआउट्स और क्लॉक्स के साथ सावधानी
टाइमआउट्स सत्य नहीं हैं; वे नीति हैं। एक टाइमआउट केवल यह बताता है "मुझे समय पर जवाब नहीं मिला," न कि "दूसरी तरफ़ ने कार्य नहीं किया।" दो ठोस निहितार्थ:
- टाइमआउट को निर्णायक न मानें। क्षतिपूर्ति और मेल-खाता-करने के रास्ते डिज़ाइन करें।
- नोड्स के पार घटनाओं को क्रम देने के लिए लोकल क्लॉक समय का उपयोग करने से बचें। सीक्वेंस नंबर, मोनोटोनिक काउंटर, या स्पष्ट कारणात्मक मेटाडेटा (उदा., "यह अपडेट वर्ज़न X को ओवरराइट करता है") का उपयोग करें।
ऑब्ज़र्वेबिलिटी जो कारणता का सम्मान करती है
अच्छे डिबगिंग टूल केवल टाइमस्टैम्प नहीं, बल्कि ऑर्डरिंग एन्कोड करते हैं।
- ट्रेस IDs हर जगह: हर हॉप और लॉग लाइনে एक correlation/trace ID propagate करें।
- लॉग में कारणात्मक सुराग: संदेश IDs, पैरेंट रिक्वेस्ट IDs, और निर्णय लेते समय "मैंने किस वर्ज़न को लेटेस्ट माना" लॉग करें।
- डिटरमिनिस्टिक रेप्ले: इनपुट्स (कमांड्स) रिकॉर्ड करें ताकि आप व्यवहार रीकॅप्ले कर सकें और पुष्टि कर सकें कि बग टाइमिंग-निर्भर है या लॉजिक-निर्भर।
शिप करने से पहले पूछने वाले डिज़ाइन सवाल
किसी वितरित फीचर को जोड़ने से पहले, स्पष्टता को मजबूर करने के लिए कुछ प्रश्न पूछें:
- यदि वही अनुरोध दो बार प्रोसेस हो जाए तो क्या होगा?
- हमें किस प्रकार का क्रम चाहिए (यदि कोई), और वह कहाँ लागू होता है?
- कौन-से फेल्यर्स "सुरक्षित" हैं (कोई खराब स्थिति नहीं), कौन "उच्च-ध्वनि" (यूज़र-देखने योग्य), और कौन "मौन" (छुपी हुई करप्शन)?
- आंशिक आउटेज या नेटवर्क स्प्लिट के बाद रिकवरी पाथ क्या होगा?
- उत्पादन में happened-before कहानी को फिर से बनाना के लिए हम क्या लॉग करेंगे?
इन प्रश्नों के लिए पीएचडी की ज़रूरत नहीं—सिर्फ़ अनुशासन चाहिए कि क्रम और सहीपन को प्रोडक्ट आवश्यकताओं का प्राथमिक दर्जा दें।
निष्कर्ष और सुझाए गए अगले कदम
लैम्पोर्ट का टिकाऊ उपहार यह सोचने का तरीका है जब सिस्टम क्लॉक साझा नहीं करते और "क्या हुआ" पर डिफ़ॉल्ट रूप से सहमत नहीं होते। परफेक्ट समय के पीछा करने के बजाय, आप कारणता को ट्रैक करते हैं (किसने किसे प्रभावित किया हो सकता है), उसे लॉजिकल टाइम (लैम्पोर्ट टाइमस्टैम्प) से प्रस्तुत करते हैं, और—जब उत्पाद एकल इतिहास माँगता है—सहमति (कंसेंसस) बनाते हैं ताकि हर रेप्लिका एक ही निर्णय अनुक्रम लागू करे।
यह धागा एक व्यावहारिक इंजीनियरिंग माइंडसेट की ओर ले जाता है:
पहले स्पेसिफ़ाई करें, फिर बनाएं
वे नियम लिखें जो आपको चाहिए: क्या कभी नहीं होना चाहिए (सुरक्षा) और क्या अंततः होना चाहिए (जीवंतता)। फिर उस स्पेक के अनुसार इम्प्लीमेंट करें, और सिस्टम को देरी, पार्टिशन्स, रीट्राय्स, डुप्लीकेट संदेश, और नोड रीस्टार्ट के तहत टेस्ट करें। कई "रहस्यमयी आउटेज" असल में गुम स्पष्टीकरण होते हैं जैसे "एक अनुरोध दो बार प्रोसेस हो सकता है" या "लीडर्स किसी भी समय बदल सकते हैं।"
अगला क्या सीखें — केंद्रित कदम
अगर आप बिना formalism में डूबे गहराई से जाना चाहते हैं:
- लैम्पोर्ट का "Time, Clocks, and the Ordering of Events in a Distributed System" पढ़ें ताकि happened-before को आतंरिक कर सकें।
- "Paxos Made Simple" को skim करें सुरक्षा अंतर्दृष्टि के लिए: एक बार मान चुना गया, भविष्य की प्रगति उसे खंडित नहीं कर सकती।
- किसी TLA+ का इंट्रो टॉक देखें, फिर एक छोटा प्रोोटोकॉल (एक लॉक सर्विस या दो-रेप्लिकास वाला रजिस्टर) मॉडल करें और चेक करें।
एक हैंड्स-ऑन अभ्यास आज़माएँ
एक कंपोनेंट चुनें जिसके आप मालिक हैं और एक पेज का "फेल्योर कॉन्ट्रैक्ट" लिखें: आप नेटवर्क और स्टोरेज के बारे में क्या मानते हैं, कौन-सी ऑपरेशन्स आइडेम्पोटेंट हैं, और आप कौन-सी ऑर्डरिंग गारंटी देते हैं।
अगर आप इस अभ्यास को और ठोस बनाना चाहते हैं, तो एक छोटा “ऑर्डरिंग डेमो” सर्विस बनाएं: एक रिक्वेस्ट API जो कमांड्स को लॉग में जोड़ता है, एक बैकग्राउंड वर्कर जो उन्हें लागू करता है, और एक एडमिन व्यू जो कारणात्मक मेटाडेटा और रीट्राय्स दिखाता है। Koder.ai पर ऐसा करना तेज़ इटरेशन और होस्टिंग के साथ आसान हो सकता है—विशेषकर यदि आप जल्दी स्कैफोल्डिंग, स्नैपशॉट/रोलबैक, और सोर्स-कोड एक्सपोर्ट चाहते हैं।
अच्छी तरह किया गया, ये विचार आउटेज को घटाते हैं क्योंकि कम व्यवहार अप्रत्यक्ष होते हैं। वे reasoning को सरल बनाते हैं: आप समय के बारे में बहस करना बंद कर देते हैं और यह साबित करना शुरू कर देते हैं कि क्रम, सहमति, और सहीपन आपके सिस्टम के लिए वास्तव में क्या मतलब रखते हैं।