21 सित॰ 2025·8 मिनट
अपने ऐप्स में त्वरित सर्वर‑साइड खोज के लिए Meilisearch
तेज़, टाइपो‑सहिष्णु खोज के लिए Meilisearch को अपने बैकएंड में कैसे जोड़ें: सेटअप, इंडेक्सिंग, रैंकिंग, फ़िल्टर, सुरक्षा और स्केलिंग के मूल बातें।
तेज़, टाइपो‑सहिष्णु खोज के लिए Meilisearch को अपने बैकएंड में कैसे जोड़ें: सेटअप, इंडेक्सिंग, रैंकिंग, फ़िल्टर, सुरक्षा और स्केलिंग के मूल बातें।
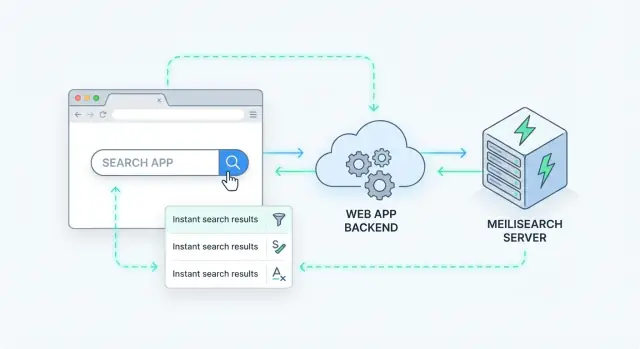
सर्वर-साइड खोज का मतलब है कि क्वेरी आपके सर्वर (या समर्पित सर्च सर्विस) पर प्रोसेस होती है, न कि ब्राउज़र के अंदर। आपका ऐप एक सर्च रिक्वेस्ट भेजता है, सर्वर उसे इंडेक्स के खिलाफ चलाता है, और रैंक किए हुए परिणाम लौटाता है।
यह तब मायने रखता है जब आपका डेटासेट क्लाइंट पर भेजने के लिए बहुत बड़ा हो, जब आपको प्लेटफ़ॉर्म्स के बीच लगातार रेलेवेंसी चाहिए, या जब एक्सेस कंट्रोल अनिवार्य हो (उदा., आंतरिक टूल जहाँ यूजर केवल वही देख पाए जो उसके लिए मान्य हो)। यह वही डिफ़ॉल्ट चुनाव भी है जब आप एनालिटिक्स, लॉगिंग और अनुमान्य प्रदर्शन चाहते हैं।
लोग सर्च इंजनों के बारे में नहीं सोचते—वे अनुभव को न्याय करते हैं। एक अच्छा “तुरंत” सर्च फ़्लो आमतौर पर मतलब रखता है:
यदि इनमें से कोई गायब है, तो यूज़र्स अलग क्वेरीज आज़माकर, ज़्यादा स्क्रॉल करके, या खोज छोड़ कर प्रतिक्रिया देते हैं।
यह लेख Meilisearch के साथ उस अनुभव को बनाने के लिए एक व्यवहारिक वॉकथ्रू है। हम कवर करेंगे कि इसे सुरक्षित तरीके से कैसे सेट करें, इंडेक्सेड डेटा को कैसे संरचित और सिंक करें, रेलेवेंसी और रैंकिंग नियम कैसे ट्यून करें, फ़िल्टर/सॉर्ट/फेसैट कैसे जोड़ें, और सुरक्षा तथा स्केलिंग के बारे में कैसे सोचें ताकि आपके ऐप के बढ़ने पर भी सर्च तेज़ रहे।
Meilisearch अच्छा फ़िट है उन जगहों के लिए:
यहाँ लक्ष्य: ऐसे परिणाम जो तुरंत, सटीक और भरोसेमंद महसूस हों—बिना सर्च को एक बड़ा इंजीनियरिंग प्रोजेक्ट बनाए।
Meilisearch एक सर्च इंजन है जिसे आप अपने ऐप के साथ चलाते हैं। आप इसे डॉक्यूमेंट्स भेजते हैं (जैसे प्रोडक्ट्स, आर्टीकल्स, यूज़र्स, या सपोर्ट टिकट्स), और यह एक इंडेक्स बनाता है जो तेज़ सर्च के लिए ऑप्टिमाइज़्ड होता है। आपका बैकएंड (या फ्रंटेंड) Meilisearch को HTTP API के माध्यम से क्वेरी करता है और मिलीसेकंड में रैंक किए हुए परिणाम पाता है।
Meilisearch आधुनिक सर्च से अपेक्षित फीचर पर ध्यान देता है:
यह डिजाइन किया गया है ताकि यह उत्तरदायी और सहनशील लगे, भले ही क्वेरी छोटी, हल्की‑सी गलत या अस्पष्ट हो।
Meilisearch आपकी प्राथमिक डेटाबेस का विकल्प नहीं है। आपका डेटाबेस लेखन, ट्रांज़ैक्शन्स और constraints के लिए स्रोत सत्य बना रहता है। Meilisearch उन फ़ील्ड की एक प्रति रखता है जिन्हें आप searchable, filterable, या displayable बनाना चुनते हैं।
एक अच्छा मानसिक मॉडल है: डेटाबेस डेटा स्टोर और अपडेट के लिए, Meilisearch तेज़ी से खोज करने के लिए।
Meilisearch बहुत तेज़ हो सकता है, पर परिणाम कुछ व्यावहारिक फ़ैक्टर पर निर्भर करते हैं:
छोटे‑मध्यम डेटासेट के लिए, आप अक्सर एक ही मशीन पर चला सकते हैं। जैसे‑जैसे आपका इंडेक्स बढ़ेगा, आप यह सोचेंगे कि क्या इंडेक्स करना है और अपडेट कैसे रखें—इन विषयों को हम बाद के सेक्शनों में कवर करेंगे।
कुछ भी इंस्टॉल करने से पहले तय करें कि आप वास्तव में क्या खोजने जा रहे हैं। Meilisearch तभी “तुरंत” लगेगा जब आपके इंडेक्स और डॉक्यूमेंट्स उस तरीके से मेल खाते हों जिस तरह लोग आपके ऐप को ब्राउज़ करते हैं।
सबसे पहले अपने सर्चेबल एंटिटीज़ की सूची बनाएं—आमतौर पर products, articles, users, help docs, locations, आदि। कई ऐप्स में सबसे साफ़ तरीका है एक इंडेक्स प्रति एंटिटी टाइप (उदा., products, articles)। इससे रैंकिंग नियम और फ़िल्टर्स पूर्वानुमान्य रहते हैं।
यदि आपका UX एक बॉक्स में कई प्रकार खोजता है (“सब कुछ खोजें”), तो आप अलग‑अलग इंडेक्स रख सकते हैं और बैकएंड में परिणाम मर्ज कर सकते हैं, या बाद में एक समर्पित "ग्लोबल" इंडेक्स बना सकते हैं। तब तक सब कुछ एक ही इंडेक्स में फोर्स न करें जब तक फ़ील्ड्स और फ़िल्टर्स वास्तव में मेल न खाते हों।
प्रत्येक डॉक्यूमेंट को एक स्थिर पहचानकर्ता (primary key) चाहिए। कुछ ऐसा चुनें जो:
id, sku, slug)डॉक्यूमेंट के आकार के लिए, जहाँ संभव हो फ्लैट फ़ील्ड्स पसंद करें। फ्लैट स्ट्रक्चर फिल्टर और सॉर्ट के लिए आसान होते हैं। नेस्टेड फ़ील्ड ठीक हैं जब वे एक तंग, अपरिवर्तनीय बंडल को दर्शाते हैं (उदा., author ऑब्जेक्ट), पर अपनी पूरी रिलेशनल स्कीमा जैसा नेस्टिंग न बनाएं—सर्च डॉक्यूमेंट्स read‑optimized होने चाहिए, न कि database‑shaped।
डॉक्यूमेंट डिज़ाइन का व्यावहारिक तरीका है कि हर फ़ील्ड को एक रोल दें:
यह एक आम गलती रोकता है: किसी फ़ील्ड को “बस‑मामूली” इंडेक्स करना और बाद में यह आश्चर्य हो कि परिणाम शोर वाले या फ़िल्टर धीमे क्यों हैं।
“भाषा” आपके डेटा में अलग‑अलग अर्थ रख सकती है:
lang: "en")जल्दी निर्णय लें कि आप प्रति‑भाषा अलग इंडेक्स उपयोग करेंगे (सरल और पूर्वानुमान्य) या एकल इंडेक्स में भाषा फ़ील्ड्स (कम इंडेक्स, अधिक लॉजिक)। सही उत्तर इस बात पर निर्भर करता है कि क्या यूज़र्स एक समय में एक भाषा में खोजते हैं और आप अनुवाद कैसे स्टोर करते हैं।
Meilisearch चलाना सीधा है, पर "डिफ़ॉल्ट से सुरक्षित" बनाने के लिए कुछ जानबूझ कर फैसले लेने पड़ते हैं: आप इसे कहाँ तैनात करते हैं, डेटा कैसे परसेव होता है, और मास्टर की कैसे संभाली जाती है।
Storage: Meilisearch अपना इंडेक्स डिस्क पर लिखता है। डेटा डायरेक्टरी को विश्वसनीय, परसिस्टेंट स्टोरेज पर रखें (эпhemeral कंटेनर स्टोरेज नहीं)। ग्रोथ के लिए क्षमता प्लान करें: बड़े टेक्स्ट फ़ील्ड और कई एट्रिब्यूट्स के साथ इंडेक्स तेजी से बढ़ सकते हैं।
Memory: peak लोड के तहत सर्च रिस्पॉन्सिव रखने के लिए पर्याप्त RAM अलोकेट करें। स्वैपिंग दिखाई दे तो परफ़ॉर्मेंस प्रभावित होगी।
Backups: Meilisearch डेटा डायरेक्टरी का बैकअप लें (या स्टोरेज लेयर पर स्नैपशॉट्स का उपयोग करें)। कम से कम एक बार रिस्टोर टेस्ट करें; रिस्टोर न हो सकने वाला बैकअप सिर्फ़ फ़ाइल है।
Monitoring: CPU, RAM, डिस्क उपयोग और डिस्क I/O ट्रैक करें। प्रोसेस हेल्थ और लॉग एरर्स भी मॉनिटर करें। कम से कम अलर्ट रखें यदि सर्विस बंद हो या डिस्क स्पेस कम हो।
लोकल डेवलपमेंट के बाहर हमेशा Meilisearch को master key के साथ चलाएँ। इसे किसी सीक्रेट मैनेजर या एन्क्रिप्टेड एन्वायरनमेंट वेरिएबल स्टोर में रखें (न कि Git में, न ही plain‑text .env में)।
उदाहरण (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
नेटवर्क नियमों पर भी विचार करें: एक निजी इंटरफ़ेस पर बाइंड करें या इनबाउंड एक्सेस को प्रतिबंधित करें ताकि केवल आपका बैकएंड Meilisearch तक पहुँच सके।
curl -s http://localhost:7700/version
Meilisearch इंडेक्सिंग असिंक्रोनस है: आप डॉक्यूमेंट भेजते हैं, Meilisearch एक टास्क कतार में डालता है, और केवल उस टास्क के सफल होने के बाद वे डॉक्यूमेंट्स सर्चेबल होते हैं। इंडेक्सिंग को एक जॉब सिस्टम की तरह व्यवहार करें, न कि एक सिंगल रिक्वेस्ट।
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
taskUid शामिल होता है। पोल करें जब तक वह succeeded (या failed) न हो।curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
यदि काउंट्स मेल नहीं खाते, अनुमान न लगाएं—सबसे पहले टास्क एरर डिटेल्स चेक करें।
बैचिंग का मतलब है कि टास्क्स पूर्वानुमान्य और रिकवरबल रहें।
addDocuments एक upsert की तरह काम करता है: एक ही primary key वाले डॉक्यूमेंट अपडेट होते हैं, नए इन्सर्ट होते हैं। इसे सामान्य अपडेट के लिए उपयोग करें।
पूर्ण रीइंडेक्स तब करें जब:
रिमूवल के लिए स्पष्ट रूप से deleteDocument(s) कॉल करें; अन्यथा पुराने रिकॉर्ड लटके रह सकते हैं।
इंडेक्सिंग को रिट्राईेबल होना चाहिए। कुंजी है स्थिर डॉक्यूमेंट ids।
taskUid को अपने बैच/जॉब id के साथ स्टोर करें, और टास्क स्टेटस के आधार पर रिट्राई करें।प्रोडक्शन डेटा से पहले, अपने असली फ़ील्ड्स के मेल वाला एक छोटा सेट (200–500 आइटम) इंडेक्स करें। उदाहरण: products सेट जिसमें id, name, description, category, brand, price, inStock, createdAt हों। यह टास्क फ़्लो, काउंट्स, और अपडेट/डिलीट व्यवहार को सत्यापित करने के लिए पर्याप्त है—बड़े इम्पोर्ट का इंतज़ार किए बिना।
सर्च "रेलेवेंसी" बस यह है: क्या पहले दिखाई देता है, और क्यों। Meilisearch इसे बिना अपना स्कोरिंग सिस्टम बनाए समायोज्य बनाता है।
दो सेटिंग्स यह तय करती हैं कि Meilisearch आपके कंटेंट के साथ क्या कर सकता है:
searchableAttributes: वे फ़ील्ड जिन्हें Meilisearch क्वेरी करते समय देखता है (उदा.: title, summary, tags)। क्रम मायने रखता है: पहले वाले फ़ील्ड्स को अधिक महत्व दिया जाता है।displayedAttributes: वे फ़ील्ड्स जो रेस्पॉन्स में लौटती हैं। यह प्राइवेसी और पेलोड साइज के लिए मायने रखता है—अगर कोई फ़ील्ड डिस्प्ले नहीं है तो वह वापस नहीं भेजी जाएगी।एक व्यावहारिक बेसलाइन यह है कि कुछ हाई‑सिग्नल फ़ील्ड्स searchable रखें (title, key text), और displayed फ़ील्ड्स को UI की जरूरत तक सीमित रखें।
Meilisearch मैचिंग डॉक्यूमेंट्स को ranking rules के माध्यम से सॉर्ट करता है—यह "टाई‑ब्रेकर्स" का एक पाइपलाइन है। वैचारिक रूप से, यह पसंद करता है:
इसे प्रभावी रूप से ट्यून करने के लिए आपको आंतरिकताओं को याद रखने की ज़रूरत नहीं; आप मुख्यतः चुनते हैं कौन‑से फ़ील्ड महत्वपूर्ण हैं और कब कस्टम सॉर्टिंग लागू करनी है।
लक्ष्य: “Title matches जीतें।” title को पहले रखें:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
लक्ष्य: “नया कंटेंट पहले आए।” सॉर्ट रूल जोड़ें और क्वेरी समय पर सॉर्ट करें (या कस्टम रैंकिंग सेट करें):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
फिर अनुरोध करें:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
लक्ष्य: “लोकप्रिय आइटम प्रमोट करें।” popularity को sortable बनाकर और आवश्यकतानुसार उस पर सॉर्ट करके प्रमोट करें।
5–10 असली यूज़र क्वेरीज लें। बदलाव से पहले टॉप परिणाम सहेजें, फिर बदलें और तुलना करें।
उदाहरण:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerयदि “बाद” की लिस्ट यूज़र इरादे से बेहतर मेल खाती है, तो सेटिंग्स रखें। यदि किन्हीं एज केस पर यह नुकसान पहुंचा रही है, तो एक‑एक करके चीज़ें बदलें (पहले attribute order, फिर ranking rules) ताकि आप जान सकें किससे सुधार आया।
एक अच्छा सर्च बॉक्स केवल “शब्द टाइप करो, मिलान पाओ” नहीं है। लोग परिणाम संकुचित करना चाहते हैं (“सिर्फ उपलब्ध आइटम”) और उन्हें क्रम देना चाहते हैं (“सबसे सस्ता पहले”)। Meilisearch में आप यह filters, sorting, और facets के साथ करते हैं।
एक filter वह नियम है जो आप रिज़ल्ट सेट पर लागू करते हैं। एक facet UI में वह है जो आप यूज़र्स को उन नियमों को बनाने में मदद करने के लिए दिखाते हैं (अक्सर चेकबॉक्स या काउंट्स के रूप में)।
गैर‑तकनीकी उदाहरण:
तो यूज़र “running” खोज सकता है और फिर category = Shoes और status = in_stock फ़िल्टर कर सकता है। फेसैट्स काउंट्स दिखा सकते हैं जैसे “Shoes (128)” और “Jackets (42)” ताकि यूज़र समझ सकें क्या उपलब्ध है।
Meilisearch को उन फ़ील्ड्स की स्पष्ट अनुमति देनी पड़ती है जिनका आप फ़िल्टर या सॉर्ट के लिए उपयोग करेंगे।
category, status, brand, price, created_at (यदि आप समय के अनुसार फ़िल्टर करते हैं), tenant_id (अगर आप ग्राहकों को अलग‑थलग करते हैं)।price, rating, created_at, popularity।इस सूची को संकुचित रखें। हर चीज़ को filterable/sortable बनाने से इंडेक्स साइज बढ़ सकता है और अपडेट्स धीमे हो सकते हैं।
भले ही आपके पास 50,000 मैच हों, यूज़र्स केवल पहला पेज देखते हैं। छोटे पेजेस (अक्सर 20–50 परिणाम) का उपयोग करें, sensibile limit सेट करें, और offset के साथ पेजिनेट करें (या यदि आप चाहें तो नए पेजिनेशन फीचर्स उपयोग करें)। अपने ऐप में अधिकतम पेज गहराई को कैप करें ताकि महंगे “page 400” रिक्वेस्ट्स न किए जाएँ।
सर्वर‑साइड सर्च जोड़ने का साफ़ तरीका है Meilisearch को एक स्पेशलाइज़्ड डेटा सर्विस की तरह अपने API के पीछे मानना। आपका ऐप एक सर्च रिक्वेस्ट प्राप्त करता है, Meilisearch को कॉल करता है, फिर क्लाइंट को एक क्यूरेटेड रिस्पॉन्स लौटाता है।
ज्यादातर टीमें इस तरह के फ़्लो के साथ काम करती हैं:
GET /api/search?q=wireless+headphones&limit=20).यह पैटर्न Meilisearch को बदला‑जाने योग्य बनाता है और फ्रंटएंड को इंडेक्स इंटरनल्स पर निर्भर होने से रोकता है।
यदि आप एक नया ऐप बना रहे हैं (या एक आंतरिक टूल रीबिल्ड कर रहे हैं) और इस पैटर्न को जल्दी लागू करना चाहते हैं, तो Koder.ai जैसा कोई प्लेटफ़ॉर्म React UI, Go बैकएंड, और PostgreSQL के साथ पूरा फ़्लो स्कैफ़ोल्ड कर सकता है—फिर Meilisearch को एकल /api/search एंडपॉइंट के पीछे इंटीग्रेट कर सकता है ताकि क्लाइंट सरल रहे और परमिशन्स सर्वर‑साइड रहें।
Meilisearch क्लाइंट‑साइड क्वेरींग को सपोर्ट करता है, पर बैकएंड क्वेरी करना आम तौर पर सुरक्षित होता है क्योंकि:
पब्लिक डेटा के लिए क्लाइंट‑साइड क्वेरी काम कर सकती है बशर्ते कीज़ सीमित हों, पर यदि कोई भी यूज़र‑विशिष्ट दृश्यता नियम है, तो सर्च को अपने सर्वर के माध्यम से रूट करें।
सर्च ट्रैफ़िक में अक्सर रिपीट्स होते हैं (“iphone case”, “return policy”)। अपने API लेयर पर कैशिंग जोड़ें:
सर्च को सार्वजनिक‑सामना वाला एंडपॉइंट मानें:
limit और अधिकतम क्वेरी लंबाई सेट करें।Meilisearch अक्सर आपके ऐप के "पीछे" रखा जाता है क्योंकि यह संवेदनशील बिजनेस डेटा तेज़ी से लौटाता है। इसे एक डेटाबेस की तरह लॉक डाउन करें, और केवल वही एक्सपोज़ करें जो हर कॉलर को दिखना चाहिए।
Meilisearch की एक master key होती है जो सब कुछ कर सकती है: इंडेक्स बनाना/हटाना, सेटिंग्स अपडेट करना, और पढ़ना/लिखना। इसे सर्वर‑ओनली रखें।
एप्लिकेशन के लिए सीमित क्रियाओं और सीमित इंडेक्स पर API कीज़ जेनरेट करें। एक सामान्य पैटर्न:
न्यूनतम अधिकार का मतलब है कि एक लीकेड की डेटा डिलीट या अनधिकृत इंडेक्स पढ़ नहीं सके।
यदि आप कई ग्राहकों (टेनेट्स) को सेवा देते हैं, तो आपके पास दो मुख्य विकल्प हैं:
1) हर टेनेट के लिए एक इंडेक्स।
इसका तर्क सरल है और क्रॉस‑टेनेंट एक्सेस जोखिम कम रहता है। कमियाँ: ज़्यादा इंडेक्स मैनेज करना और सेटिंग्स अपडेट्स को सुसंगत लागू करना।
2) साझा इंडेक्स + tenant filter।
हर डॉक्यूमेंट पर tenantId फ़ील्ड रखें और हर सर्च पर tenantId = "t_123" जैसा फ़िल्टर लागू कराएँ। यह अच्छी तरह स्केल कर सकता है, पर सुनिश्चित करें कि हर रिक्वेस्ट हमेशा यह फ़िल्टर लागू करे (आदर्शतः scoped key के ज़रिये ताकि कॉलर्स इसे हटा न सकें)।
भले ही सर्च सही हो, परिणाम ऐसे फ़ील्ड्स लीक कर सकते हैं जिन्हें आप वापस नहीं भेजना चाहते (e-mails, internal notes, cost prices)। यह नियंत्रित करें:
एक त्वरित “worst‑case” टेस्ट करें: एक सामान्य शब्द खोजें और पुष्टि करें कि कोई प्राइवेट फ़ील्ड दिखाई नहीं देता।
यदि आप सुनिश्चित नहीं हैं कि कोई की क्लाइंट‑साइड होनी चाहिए, तो मान लें “नहीं” और सर्च सर्वर‑साइड रखें।
Meilisearch तेज़ है जब आप दो वर्कलोड्स को अलग रखते हैं: इंडेक्सिंग (लेखन) और सर्च क्वेरीज (पठन)। अधिकांश "रहस्यमयी धीमर" बस यही हैं कि ये दोनों CPU, RAM, या डिस्क पर प्रतिस्पर्धा कर रहे हैं।
इंडेक्सिंग लोड तब स्पाइक कर सकता है जब आप बड़े बैच इम्पोर्ट करते हैं, बार‑बार अपडेट करते हैं, या कई searchable फ़ील्ड जोड़ते हैं। इंडेक्सिंग बैकग्राउंड टास्क है, पर यह CPU और डिस्क बैंडविड्थ भी खपत करता है। यदि आपकी टास्क कतार बढ़े, तो सर्च धीरे लगने लगेगा भले ही क्वेरी वॉल्यूम नहीं बदला हो।
क्वेरी लोड ट्रैफ़िक के साथ बढ़ता है, पर फीचर्स भी काम बढ़ाते हैं: अधिक फ़िल्टर्स, अधिक फेसैट्स, बड़े रिज़ल्ट सेट्स, और ज़्यादा टाइपो‑टॉलरेंस प्रति रिक्वेस्ट काम बढ़ा सकते हैं।
डिस्क I/O अक्सर चुपचाप दोषी होता है। धीमे डिस्क (या साझा वॉल्यूम पर नॉइज़ी नेइबर्स) “तुरंत” को “कभी‑कभी” बना सकते हैं। NVMe/SSD स्टोरेज प्रोडक्शन के लिए सामान्य बेसलाइन है।
सरल साइज़िंग से शुरू करें: Meilisearch को पर्याप्त RAM दें ताकि इंडेक्स गर्म रहे और पर्याप्त CPU दें ताकि पीक QPS संभाल सके। फिर चिंताओं को अलग करें:
छोटा सा सिग्नल सेट ट्रैक करें:
बैकअप सामान्य रूटीन होना चाहिए। Meilisearch के snapshot फीचर का उपयोग शेड्यूल पर करें, स्नैपशॉट्स को बॉक्स के बाहर स्टोर करें, और समय‑समय पर रिस्टोर टेस्ट करें। अपग्रेड के लिए, रिलीज नोट्स पढ़ें, नॉन‑प्रोड में स्टेज करें, और प्लान रखें कि यदि वर्ज़न चेंज इंडेक्सिंग बिहेवियर को प्रभावित करे तो रीइंडेक्स की आवश्यकता पड़ेगी।
यदि आप अपने ऐप प्लेटफ़ॉर्म में environment snapshots और rollback उपयोग करते हैं (उदा., Koder.ai के snapshots/rollback वर्कफ़्लो के माध्यम से), तो अपने सर्च रोलआउट को समान अनुशासन के साथ अलाइन करें: बदलने से पहले स्नैपशॉट लें, हेल्थ चेक सत्यापित करें, और जानें कि कैसे जल्दी से किसी ज्ञात‑अच्छे स्थिति पर वापस जाना है।
साफ़ इंटीग्रेशन के बाद भी, सर्च समस्याएँ कुछ सामान्य बकेट्स में आती हैं। अच्छी ख़बर: Meilisearch आपको पर्याप्त दृश्यता देता है (tasks, logs, deterministic settings) ताकि आप जल्दी डिबग कर सकें—अगर आप व्यवस्थित तरीके से जाएँ।
filterableAttributes में नहीं जोड़ा गया, या डॉक्यूमेंट्स ने उस फ़ील्ड को अपेक्षित आकृति में स्टोर नहीं किया (string vs array vs nested object)।sortableAttributes/rankingRules की कमी गलत आइटम ऊपर धकेल रही है।सबसे पहले देखें कि क्या Meilisearch ने आपका आख़िरी चेंज सफलतापूर्वक लागू किया।
filter, फिर sort, फिर facets।यदि आप किसी परिणाम को समझा नहीं पाते, तो अस्थायी रूप से अपनी कॉन्फ़िगरेशन को पीछे हटाएँ: synonyms हटाएँ, ranking tweaks घटाएँ, और एक छोटे dataset पर टेस्ट करें। जटिल प्रासंगिकता समस्याएँ 50 डॉक्यूमेंट पर 5 मिलियन पर तुलना करने से कहीं आसान होती हैं।
your_index_v2 को पैरेलल में बनाएं, सेटिंग्स लागू करें, और प्रोडक्शन क्वेरीज का सैंपल रिप्ले करें।filterableAttributes और sortableAttributes आपकी UI आवश्यकताओं से मेल खाते हैं।Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
सर्वर-साइड खोज का मतलब है कि क्वेरी ब्राउज़र के अंदर नहीं बल्कि आपके बैकएंड (या समर्पित सर्च सर्विस) पर चलती है। यह सही विकल्प है जब:
उपयोगकर्ता तुरंत चार बातों को नोटिस करते हैं:
यदि इनमें से कोई गायब है, तो लोग क्वेरी दोहराते हैं, ज़्यादा स्क्रॉल करते हैं, या खोज छोड़ देते हैं।
इसे एक सर्च इंडेक्स के रूप में देखें, न कि आपकी प्राथमिक डेटाबेस के रूप में। आपका डेटाबेस लेखन, ट्रांज़ैक्शन्स, और constraints के लिए स्रोत सत्य रहेगा; Meilisearch उन फ़ील्ड की एक प्रति रखता है जिन्हें आप तेज़ी से खोजने के लिए चुनते हैं।
एक उपयोगी मानसिक मॉडल:
एक सामान्य डिफ़ॉल्ट है प्रति एंटिटी टाइप एक इंडेक्स (उदा., products, articles)। इससे:
यदि आपको “सब कुछ खोजो” चाहिए, तो आप कई इंडेक्स क्वेरी करके बैकएंड में परिणाम मर्ज कर सकते हैं, या बाद में एक समर्पित ग्लोबल इंडेक्स बना सकते हैं।
एक प्राइमरी की चुनें जो:
id, sku, slug)स्थिर IDs इंडेक्सिंग को आइडेम्पोटेंट बनाते हैं: यदि आप रिट्राई करते हैं तो डुप्लिकेट नहीं बनेंगे क्योंकि अपडेट सुरक्षित upsert होते हैं।
प्रत्येक फ़ील्ड को उद्देश्य के अनुसार वर्गीकृत करें ताकि आप ओवर‑इंडेक्सिंग से बचें:
इन भूमिकाओं को स्पष्ट रखने से शोर और बड़े/धीमे इंडेक्स से बचा जा सकता है।
इंडेक्सिंग असिंक्रोनस है: डॉक्यूमेंट्स अपलोड करने पर एक टास्क बनता है, और जब तक वह टास्क सफल नहीं होता, दस्तावेज़ searchable नहीं होते।
एक भरोसेमंद फ़्लो:
taskUid की स्थिति पोल करें जब तक वह succeeded या failed न हो जाएयदि परिणाम पुराने दिखते हैं, तो डिबग करने से पहले टास्क स्टेटस देखें।
एक सामान्य शुरुआत के बिंदु हैं:
छोटे बैच को वरीयता दें: इन्हें रिट्राई करना आसान है, खराब रिकॉर्ड ढूँढना आसान होता है, और टाइमआउट की संभावना कम रहती है।
दो उच्च‑प्रभाव वाले लीवर हैं:
searchableAttributes: कौन‑से फ़ील्ड खोजे जाएंगे और किस प्राथमिकता मेंpublishedAt, price, या popularity जैसे फ़ील्ड के आधार पर सॉर्ट करने देंगेव्यवहारिक तरीका: 5–10 असली यूज़र क्वेरीज लें, पहले के टॉप परिणाम सहेजें, एक सेटिंग बदलें, फिर बाद के साथ तुलना करें।
अधिकतर फ़िल्टर/सॉर्ट समस्याएं कॉन्फ़िगरेशन की कमी से आती हैं:
filterableAttributes में जोड़ा जाना चाहिएsortableAttributes में होना चाहिएसाथ ही डॉक्यूमेंट्स में फ़ील्ड की आकृति और प्रकार (string vs array vs nested object) सत्यापित करें। यदि फ़िल्टर फेल हो रहा है, तो हालिया settings/task स्टेटस और इंडेक्स्ड डॉक्यूमेंट्स को चेक करें कि वे अपेक्षित फ़ील्ड वैल्यूज़ रखते हैं या नहीं।