07 जून 2025·8 मिनट
माइकल स्टोनब्रेकर और आधुनिक डेटाबेस: उन्होंने क्या बदला
Ingres, Postgres और Vertica के पीछे माइकल स्टोनब्रेकर के मुख्य विचारों और उन्होंने कैसे SQL डेटाबेस, एनालिटिक्स इंजन और आज के डेटा स्टैक्स को आकार दिया, जानें।
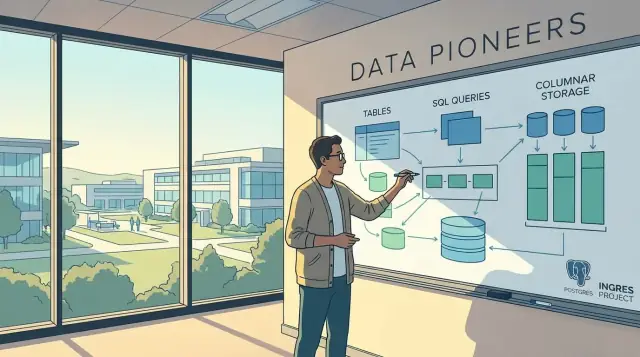
Ingres, Postgres और Vertica के पीछे माइकल स्टोनब्रेकर के मुख्य विचारों और उन्होंने कैसे SQL डेटाबेस, एनालिटिक्स इंजन और आज के डेटा स्टैक्स को आकार दिया, जानें।
माइकल स्टोनब्रेकर एक कंप्यूटर वैज्ञानिक हैं जिनकी परियोजनाओं ने केवल डेटाबेस शोध को प्रभावित नहीं किया—उन्होंने सीधे उन उत्पादों और डिज़ाइन पैटर्नों को आकार दिया जिन पर कई टीमें रोज़ निर्भर करती हैं। अगर आपने कोई रिलेशनल डेटाबेस, एनालिटिक्स वेयरहाउस, या स्ट्रीमिंग सिस्टम इस्तेमाल किया है, तो आप उन विचारों से लाभान्वित हुए हैं जिन्हें उन्होंने सिद्ध, बनाया, या लोकप्रिय किया।
यह कोई जीवनी या शुद्ध सैद्धांतिक डेटाबेस टूर नहीं है। इसके बजाय यह स्टोनब्रेकर की प्रमुख प्रणालियों (जैसे Ingres, Postgres, और Vertica) को आधुनिक डेटा स्टैक्स में मिलने वाले चुनावों से जोड़ता है:
एक आधुनिक डेटाबेस कोई भी सिस्टम है जो भरोसेमंद तरीके से कर सके:
विभिन्न डेटाबेस इन लक्ष्यों को अलग तरह से ऑप्टिमाइज़ करते हैं—खासकर जब आप transactional ऐप्स, BI डैशबोर्ड और रियल-टाइम पाइपलाइन्स की तुलना करते हैं।
हम व्यावहारिक प्रभाव पर फोकस करेंगे: वे विचार जो आज के “warehouse + lake + stream + माइक्रोसर्विसेज” दुनिया में दिखते हैं, और वे आपके खरीदने, बनाने, और ऑपरेट करने के फैसलों को कैसे प्रभावित करते हैं। उम्मीद करें साफ़ समझ, ट्रेडऑफ़, और असली दुनिया के निहितार्थ—ना कि प्रमाणों या इम्प्लीमेंटेशन विवरणों में गहराई।
स्टोनब्रेकर का करियर उन प्रणालियों के अनुक्रम के रूप में समझना सबसे आसान है जिन्हें विशिष्ट काम के लिए बनाया गया और फिर सर्वश्रेष्ठ विचार मुख्यधारा के उत्पादों में स्थानांतरित होते देखे गए।
Ingres एक अकादमिक परियोजना के रूप में शुरू हुआ जिसने सिद्ध किया कि रिलेशनल डेटाबेस तेज़ और व्यावहारिक हो सकते हैं, सिर्फ़ सिद्धांत नहीं। इसने SQL-शैली क्वेरींग और कॉस्ट-बेस्ड ऑप्टिमाइज़ेशन की सोच को लोकप्रिय बनाने में मदद की जो बाद में वाणिज्यिक इंजन में सामान्य हो गया।
Postgres (जिस अनुसंधान प्रणाली ने PostgreSQL को जन्म दिया) एक अलग शर्त पर आधारित था: डेटाबेस निश्चित-फ़ंक्शन नहीं होने चाहिए। आपको नए डेटा प्रकार, नए इंडेक्सिंग तरीके, और समृद्ध व्यवहार जोड़ने में सक्षम होना चाहिए बिना पूरे इंजन को फिर से लिखे।
कई “आधुनिक” फीचर इसी युग से आते हैं—विस्तारयोग्य प्रकार, उपयोगकर्ता-परिभाषित फ़ंक्शन, और एक ऐसा डेटाबेस जो वर्कलोड बदलने पर अनुकूल हो सके।
जैसे-जैसे एनालिटिक्स बढ़ा, रो-ओरिएंटेड सिस्टम बड़ी स्कैन और एग्रीगेशन में संघर्ष करने लगे। स्टोनब्रेकर ने कॉलम-आधारित स्टोरेज और संबंधित निष्पादन तकनीकों को बढ़ावा दिया—ऐसी तकनीकें जो केवल उन्हीं कॉलम्स को पढ़ती हैं जिनकी जरूरत होती है और उन्हें अच्छी तरह कम्प्रेस करती हैं—ये विचार अब एनालिटिक्स डेटाबेस और क्लाउड वेयरहाउस में मानक हैं।
Vertica ने कॉलम-स्टोर अनुसंधान विचारों को व्यावसायिक रूप से व्यवहार्य massively parallel processing (MPP) SQL इंजन में परिवर्तित किया जो बड़े एनालिटिकल क्वेरीज के लिए डिजाइन किया गया था। यह पैटर्न उद्योग में बार-बार दिखता है: एक शोध प्रोटोटाइप एक अवधारणा को मान्य करता है; एक उत्पाद इसे विश्वसनीयता, टूलिंग और असली ग्राहक प्रतिबंधों के साथ हार्डन करता है।
बाद का कार्य स्ट्रीम प्रोसेसिंग और वर्कलोड-विशिष्ट इंजनों में विस्तृत हुआ—यह तर्क देते हुए कि एक सामान्य प्रयोजन डेटाबेस शायद हर जगह नहीं जीतेगा।
एक प्रोटोटाइप किसी परिकल्पना को जल्दी परखने के लिए बनाया जाता है; एक उत्पाद ऑपरेबिलिटी को प्राथमिकता देता है: अपग्रेड्स, मॉनिटरिंग, सुरक्षा, पूर्वानुमेय प्रदर्शन, और सपोर्ट। स्टोनब्रेकर का प्रभाव इसलिए दिखाई देता है क्योंकि कई प्रोटोटाइप विचार वाणिज्यिक डेटाबेस में डिफ़ॉल्ट क्षमतियों के रूप में परिवर्तित हुए न कि किनारे के विकल्प के रूप में।
Ingres (INteractive Graphics REtrieval System) स्टोनब्रेकर का प्रारंभिक प्रमाण था कि रिलेशनल मॉडल सिर्फ़ सुंदर सिद्धांत नहीं बल्कि व्यावहारिक भी हो सकता है। उस समय कई सिस्टम कस्टम एक्सेस मेथड और एप्लिकेशन-विशेष डेटा पाथ पर बनाए जाते थे।
Ingres ने एक सरल, व्यापार-मित्र समस्या हल करने की कोशिश की:
लोगों को डेटा के लचीले प्रश्न कैसे करने दें बिना हर बार सॉफ़्टवेयर फिर से लिखे?
रिलेशनल डेटाबेस यह वादा करते थे कि आप क्या चाह रहे हैं (उदाहरण के लिए, “कैलिफ़ोर्निया के ग्राहक जिनके ओवरड्यू इनवॉइस हैं”) वर्णन कर सकते हैं बजाय यह बताए कि उसे कैसे चरण-दर-चरण निकाला जाए। पर यह वादा वास्तविक बनाने के लिए एक ऐसे सिस्टम की ज़रूरत थी जो:
Ingres उस “व्यवहारिक” रूप की ओर एक बड़ा कदम था—एक ऐसा रिलेशनल कंप्यूटिंग जो उस समय के हार्डवेयर पर भी चल सके और अभी भी उत्तरदायी लगे।
Ingres ने यह विचार लोकप्रिय बनाया कि डेटाबेस को क्वेरी की योजना बनाना चाहिए। डेवलपर्स के हर डेटा एक्सेस पाथ को मैन्युअली ट्यून करने के बजाय, सिस्टम यह चुन सकता था कि कौन सी तालिका पहले पढ़नी है, कौन से इंडेक्स उपयोग करने हैं, और तालिकाओं को कैसे जॉइन करना है।
इसने SQL-शैली की सोच को फैलाने में मदद की: जब आप घोषणात्मक क्वेरी लिख सकते हैं, तो आप तेज़ी से итरेट कर सकते हैं और ज़्यादा लोग सीधे प्रश्न पूछ सकते हैं—विश्लेषक, प्रोडक्ट टीमें, यहाँ तक कि फ़ाइनेंस—बिना कस्टम रिपोर्ट के लिए इंतज़ार किए।
बड़ा व्यावहारिक अंतर्ज्ञान है कॉस्ट-बेस्ड ऑप्टिमाइज़ेशन: उस क्वेरी योजना को चुनो जिसकी अपेक्षित “लागत” सबसे कम हो (आम तौर पर I/O, CPU, और मेमोरी का मिश्रण), डेटा के आँकड़ों के आधार पर।
इसका महत्व इसलिए है क्योंकि यह अक्सर मतलब रखता है:
Ingres ने हर आधुनिक ऑप्टिमाइज़ेशन का आविष्कार नहीं किया, लेकिन उसने यह पैटर्न स्थापित करने में मदद की: SQL + एक ऑप्टिमाइज़र वही है जो रिलेशनल सिस्टम्स को "अच्छा विचार" से दैनिक उपकरण बनाता है।
प्रारंभिक रिलेशनल डेटाबेस एक तय डेटा प्रकारों (संख्या, टेक्स्ट, तारीखें) और निश्चित ऑपरेशन्स के साथ काम करने का अनुमान लगाते थे। यह तब अच्छे से काम करता था—जब तक टीमें नए तरह की जानकारी (भूगोल, लॉग्स, टाइम सीरीज़, डोमेन-विशेष पहचानकर्ता) स्टोर करना न शुरू करें या विशिष्ट प्रदर्शन फीचर्स की ज़रूरत न पड़े।
एक कठोर डिज़ाइन के साथ, हर नया आवश्यकत एक खराब विकल्प बन जाती है: डेटा को टेक्स्ट ब्लॉब्स में ज़बरदस्ती फिट करना, अलग सिस्टम जोड़ना, या वेंडर के समर्थन का इंतज़ार करना।
Postgres ने एक अलग विचार रखा: डेटाबेस को विस्तारयोग्य होना चाहिए—जिसका मतलब है कि आप नियंत्रित तरीके से नई क्षमताएँ जोड़ सकें, बिना SQL से अपेक्षित सुरक्षा और सटीकता को तोड़े।
साधारण भाषा में, विस्तारयोग्यता उस पावर टूल में प्रमाणीकृत अटैचमेंट जोड़ने जैसा है न कि मोटर को खुद बदलने जैसा। आप डेटाबेस को "नई चालें" सिखा सकते हैं, जबकि ट्रांज़ैक्शन, अनुमतियाँ, और क्वेरी ऑप्टिमाइज़ेशन एक सुसंगत पूरे के रूप में काम करना जारी रखते हैं।
यह मानसिकता आज के PostgreSQL इकोसिस्टम (और कई Postgres-प्रेरित सिस्टम) में स्पष्ट दिखती है। कोर फीचर का इंतज़ार करने की बजाय, टीमें परखा हुआ एक्सटेंशन अपना लेती हैं जो SQL और ऑपरेशनल टूलिंग के साथ साफ़ इंटीग्रेट होते हैं।
उच्च-स्तरीय आम उदाहरणों में शामिल हैं:
कुंजी यह है कि Postgres ने "डेटाबेस क्या कर सकता है" बदलना एक डिज़ाइन लक्ष्य माना—not एक बाद की बात—और यह विचार आज भी आधुनिक डेटा प्लेटफ़ॉर्म्स के विकास को प्रभावित करता है।
डेटाबेस सिर्फ़ जानकारी स्टोर करने के लिए नहीं हैं—वे यह सुनिश्चित करने के लिए हैं कि जानकारी सही रहे, भले ही एक साथ बहुत कुछ हो रहा हो। यही ट्रांज़ैक्शन्स और कॉनकरेंसी कंट्रोल के लिए ज़रूरी है, और यही कारण है कि SQL सिस्टम्स वास्तविक व्यावसायिक काम के लिए भरोसेमंद बने।
एक ट्रांज़ैक्शन उन परिवर्तनों का समूह है जो या तो सफल होंगे या विफल।
अगर आप खातों के बीच पैसा ट्रांसफर करते हैं, एक ऑर्डर प्लेस करते हैं, या इन्वेंटरी अपडेट करते हैं, तो आप "आधी-पूरी" स्थितियाँ बर्दाश्त नहीं कर सकते। एक ट्रांज़ैक्शन सुनिश्चित करता है कि आप उस तरह के आंशिक परिणामों में न फँसें।
व्यावहारिक रूप से, ट्रांज़ैक्शन्स आपको देती हैं:
कॉनकरेंसी का अर्थ है कई लोग (और ऐप्स) एक साथ डेटा पढ़ रहे और बदल रहे हैं: ग्राहक चेकआउट, सपोर्ट एजेंट खाते एडिट करना, बैकग्राउंड जॉब्स स्टेटस अपडेट करना, विश्लेषक रिपोर्ट चला रहे।
बिना सावधानी के नियमों के, कॉनकरेंसी समस्याएँ पैदा करती है जैसे:
एक प्रभावशाली तरीका है MVCC (Multi-Version Concurrency Control)। अवधारणात्मक रूप से, MVCC अल्प समय के लिए एक पंक्ति के कई संस्करण रखता है, ताकि पढ़ने वाले एक स्थिर स्नैपशॉट पढ़ सकें जबकि लिखने वाले अपडेट कर रहे हों।
बड़ा लाभ यह है कि रीड्स अक्सर राइट्स को ब्लॉक नहीं करते, और राइटर्स लंबे चलने वाले क्वेरीज़ के पीछे बार-बार रुकते नहीं। आप फिर भी सटीकता पाते हैं, लेकिन कम इंतज़ार के साथ।
आज के डेटाबेस अक्सर मिक्स्ड वर्कलोड्स सर्व करते हैं: उच्च-वॉल्यूम ऐप लिखाइयां साथ ही डैशबोर्ड, ग्राहक दृश्य, और ऑपरेशनल एनालिटिक्स के लिए बार-बार पढ़ाई। आधुनिक SQL सिस्टम MVCC, स्मार्ट लॉकिंग, और隔离 स्तरों का उपयोग करके गति और सटीकता के बीच संतुलन बनाते हैं—ताकि आप गतिविधि बढ़ा सकें बिना डेटा पर विश्वास खोए।
रो-ओरिएंटेड डेटाबेस लेन-देन प्रोसेसिंग के लिए बनाए गए थे: बहुत सारी छोटी पढ़ाइयां और लिखाइयां, आमतौर पर एक ग्राहक, एक ऑर्डर, एक खाता एक बार में। यह डिज़ाइन तब शानदार है जब आपको एक पूरा रिकॉर्ड जल्दी लेना/अपडेट करना हो।
एक स्प्रेडशीट की कल्पना करें। एक रो स्टोर हर पंक्ति को अपनी फ़ोल्डर की तरह फाइल करता है: जब आपको “Order #123 के बारे में सब कुछ” चाहिए, तो आप एक फ़ोल्डर निकालते हैं और काम हो जाता है। एक कॉलम स्टोर हर कॉलम को अलग दराज की तरह फाइल करता है: एक दराज "order_total" के लिए, दूसरा "order_date" के लिए, तीसरा "customer_region" के लिए।
एनालिटिक्स के लिए, आपको शायद पूरा फ़ोल्डर नहीं चाहिए—आप आमतौर पर पूछ रहे होते हैं “पिछली तिमाही में क्षेत्र के अनुसार कुल राजस्व क्या था?” वह क्वेरी शायद लाखों रिकॉर्ड्स में केवल कुछ फ़ील्ड्स को छूती है।
एनालिटिक्स क्वेरीज अक्सर:
कॉलमर स्टोरेज के साथ, इंजन केवल उन्हीं कॉलम्स को पढ़ सकता है जिनका संदर्भ क्वेरी में है, बाकी छोड़ देता है। डिस्क से कम डेटा पढ़ना (और मेमोरी के माध्यम से कम स्थानांतरण) अक्सर सबसे बड़ा प्रदर्शन लाभ है।
कॉलम्स में अक्सर पुनरावृत्त मान होते हैं (क्षेत्र, स्थिति, श्रेणियाँ)। यह उन्हें उच्च रूप से कम्प्रेसिबल बनाता है—और कम्प्रेशन तेज़ कर सकता है क्योंकि सिस्टम कम बाइट्स पढ़ता है और कभी-कभी कम्प्रेस्ड डेटा पर और अधिक कुशलता से ऑपरेट कर सकता है।
कॉलम स्टोर्स ने OLTP-प्रथम डेटाबेस से एनालिटिक्स-प्रथम इंजनों की ओर बदलाव को चिह्नित किया, जहाँ स्कैनिंग, कम्प्रेशन, और तेज़ एग्रीगेट प्राथमिक डिज़ाइन लक्ष्य बन गए।
Vertica स्पष्ट रूप से दिखाता है कि कैसे स्टोनब्रेकर के एनालिटिक्स डेटाबेस विचार एक उत्पाद बने जिसे टीमें प्रोडक्शन में चला सकें। इसने कॉलमर स्टोरेज के पाठ से सबक लिया और उन्हें एक वितरित डिज़ाइन के साथ जोड़ा जो एक विशिष्ट समस्या के लिए बनाया गया था: बड़े एनालिटिकल SQL क्वेरीज का तेज़ उत्तर, भले ही डेटा वॉल्यूम एक सर्वर से बाहर चला जाए।
MPP मतलब कई मशीनें एक SQL क्वेरी पर एक साथ काम करती हैं।
एकल डेटाबेस सर्वर के बजाय जो सारा डेटा पढ़े और सभी ग्रुपिंग और सॉर्टिंग करे, डेटा नोड्स में विभाजित होता है। हर नोड अपने स्लाइस को समानांतर प्रोसेस करता है, और सिस्टम आंशिक परिणामों को मिलाकर अंतिम उत्तर बनाता है।
सही डेटा वितरण और क्वेरी के समानांतरकरण के साथ—a क्वेरी जो एक बॉक्स पर मिनट लेती है वह क्लस्टर पर सेकंड में आ सकती है।
Vertica-शैली के MPP एनालिटिक्स सिस्टम तब चमकते हैं जब आपके पास बहुत सारी पंक्तियाँ हों और आप उन्हें स्कैन, फ़िल्टर और कुशलतापूर्वक एग्रीगेट करना चाहें। सामान्य उपयोग-मामले:
MPP एनालिटिक्स इंजन ट्रांज़ैक्शनल (OLTP) सिस्टम का सीधा प्रतिस्थापन नहीं हैं। वे कई पंक्तियाँ पढ़ने और सारांश निकालने के लिए ऑप्टिमाइज़्ड हैं, न कि बहुत सारी छोटी अपडेट्स के लिए।
आम ट्रेडऑफ़्स:
कुंजी विचार: फोकस—Vertica और समान सिस्टम अपनी गति को स्टोरेज, कम्प्रेशन, और पैरेलल निष्पादन के लिए ट्यून करके कमाते हैं—और फिर उन सीमाओं को स्वीकार करते हैं जो ट्रांज़ैक्शनल सिस्टम टालते हैं।
एक डेटाबेस "स्टोर और क्वेरी" कर सकता है और फिर भी एनालिटिक्स के लिए धीमा महसूस कर सकता है। फर्क अक्सर इस बात में नहीं है कि आप क्या SQL लिखते हैं, बल्कि यह है कि इंजन उसे कैसे निष्पादित करता है: वह पृष्ठ कैसे पढ़ता है, डेटा CPU के माध्यम से कैसे ले जाता है, मेमोरी का उपयोग कैसे करता है, और बेकार काम को कैसे कम करता है।
स्टोनब्रेकर के एनालिटिक्स-फोकस्ड प्रोजेक्ट्स ने यह विचार बढ़ावा दिया कि क्वेरी प्रदर्शन एक निष्पादन समस्या है उतना ही जितना स्टोरेज समस्या। इस सोच ने टीमों को एकल-रो लुकअप्स को ऑप्टिमाइज़ करने से हटाकर लाखों (या अरबों) पंक्तियों पर लंबे स्कैन, जॉइन और एग्रीगेट ऑप्टिमाइज़ेशन की ओर मोड़ा।
पुराने इंजन अक्सर क्वेरीज को "ट्यूपल-एट-ए-टाइम" (रो-दर-रो) प्रोसेस करते थे, जिससे बहुत सारे फ़ंक्शन कॉल और ओवरहेड बनते थे। वेक्टराइज़्ड निष्पादन उस मॉडल को पलटता है: इंजन एक बैच (एक वेक्टर) मानों का तंग लूप में प्रोसेस करता है।
साधारण शब्दों में, यह किराने की चीज़ों को कार्ट से उठाने जैसा है बजाय एक-एक आइटम हाथ में लेकर जाने के। बैचिंग ओवरहेड कम करती है और आधुनिक CPUs को वही करने की अनुमति देती है जिसमें वे अच्छे हैं: अनुमानित लूप्स, कम ब्रांचेस, और बेहतर कैश उपयोग।
तेज़ एनालिटिक्स इंजन इस बात के प्रति उत्सुक रहते हैं कि वे CPU और कैश के अनुकूल कैसे रहें। निष्पादन नवाचार सामान्यतः इस पर फ़ोकस करते हैं:
ये विचार इसलिए महत्वपूर्ण हैं क्योंकि एनालिटिक्स क्वेरीज अक्सर मेमोरी बैंडविड्थ और कैश मिसेज से सीमित होती हैं, न कि केवल डिस्क गति से।
आधुनिक डेटा वेयरहाउसेस और SQL इंजन—क्लाउड वेयरहाउसेस, MPP सिस्टम, और तेज़ इन-प्रोसेस एनालिटिक्स टूल—अक्सर वेक्टराइज़्ड निष्पादन, कम्प्रेशन-अवेयर ऑपरेटर्स, और कैश-फ्रेंडली पाइपलाइन्स को मानक अभ्यास के रूप में उपयोग करते हैं।
यहाँ तक कि जब विक्रेता "ऑटोसकलिंग" या "स्टोरेज और कंप्यूट का पृथक्करण" जैसी सुविधाएँ बाज़ार में प्रस्तुत करते हैं, तब भी रोज़मर्रा की गति इन निष्पादन विकल्पों पर बहुत निर्भर करती है।
अगर आप प्लेटफ़ॉर्म्स का मूल्यांकन कर रहे हैं, तो पूछें न केवल क्या वे स्टोर करते हैं, बल्कि वे जॉइन और एग्रीगेट कैसे चलाते हैं—और क्या उनका निष्पादन मॉडल एनालिटिक्स के लिए बनाया गया है न कि ट्रांज़ैक्शनल वर्कलोड्स के लिए।
स्ट्रीमिंग डेटा सरलतः लगातार आने वाली घटनाओं की सीक्वेंस है—सोचें "एक नई चीज़ अभी हुई" संदेश। एक क्रेडिट-कार्ड स्वाइप, एक सेंसर रीडिंग, किसी उत्पाद पृष्ठ पर क्लिक, एक पैकेज स्कैन, एक लॉग लाइन: हर एक वास्तविक समय में आता है और लगातार बना रहता है।
परंपरागत डेटाबेस और बैच पाइपलाइन्स तब बेहतरीन होते हैं जब आप इंतज़ार कर सकते हैं: कल का डेटा लोड करें, रिपोर्ट चलाएं, डैशबोर्ड प्रकाशित करें। पर रियल-टाइम ज़रूरतें अगले आवर्ती जॉब का इंतज़ार नहीं करतीं।
यदि आप केवल बैच में डेटा प्रोसेस करते हैं, तो अक्सर परिणाम होते हैं:
स्ट्रीमिंग सिस्टम इस विचार के इर्द-गिर्द डिज़ाइन किए जाते हैं कि कम्प्यूटेशन्स घटनाओं के आने के साथ निरंतर चल सकते हैं।
एक निरंतर क्वेरी ऐसे SQL क्वेरी जैसा है जो कभी "खत्म" नहीं होती। यह एक बार परिणाम लौटाने के बजाय जैसे-जैसे नई घटनाएँ आती हैं परिणाम को अपडेट करती रहती है।
क्योंकि स्ट्रीम्स अनबाउंड हैं (वे समाप्त नहीं होते), स्ट्रीमिंग सिस्टम गणनाओं को प्रबंधनीय बनाने के लिए विंडोज़ का उपयोग करते हैं। एक विंडो समय या घटनाओं का एक स्लाइस है, जैसे "पिछले 5 मिनट", "हर मिनट", या "पिछले 1,000 इवेंट्स"। इससे आप रोलिंग काउंट्स, औसत, या टॉप-एन जैसी गणनाएँ बिना सब कुछ फिर से प्रोसेस किए कर सकते हैं।
रियल-टाइम स्ट्रीमिंग सबसे ज़्यादा कीमत तब देती है जब समय मायने रखता है:
स्टोनब्रेकर ने दशकों से यह तर्क दिया है कि डेटाबेस को सभी के लिए सामान्य-उद्देश्यीय मशीन के रूप में नहीं बनाया जाना चाहिए। कारण सरल है: अलग वर्कलोड्स अलग डिज़ाइन चुनावों को पुरस्कृत करते हैं। यदि आप एक काम (उदाहरण के लिए, छोटे ट्रांज़ैक्शनल अपडेट्स) के लिए ज़ोरदार रूप से ऑप्टिमाइज़ करते हैं, तो आप आमतौर पर किसी दूसरे काम को धीमा कर देते हैं (जैसे रिपोर्ट के लिए अरबों पंक्तियों को स्कैन करना)।
अधिकांश आधुनिक स्टैक्स एक से अधिक डेटा सिस्टम का उपयोग करते हैं क्योंकि व्यवसाय एक ही प्रकार के उत्तर से अधिक मांग करता है:
यह व्यावहारिकता है: "एक आकार सब पे फिट नहीं होता"—आप उन इंजनों को चुनते हैं जो काम की आकृति से मेल खाते हैं।
चुनने (या किसी अन्य सिस्टम को जायज़ ठहराने) के लिए यह त्वरित फ़िल्टर उपयोग करें:
कई इंजनों का होना स्वस्थ हो सकता है, पर केवल तब जब हर एक का स्पष्ट वर्कलोड हो। नया टूल तभी अपनाएँ जब वह लागत, लेटेंसी, या जोखिम कम करके अपनी जगह साबित करे—ना कि केवल नवीनता जोड़कर।
कम सिस्टम रखें जिनकी मजबूत ऑपरेशनल जिम्मेदारी हो, और वे कॉम्पोनेंट्स रेटायर करें जिनका कोई सटीक, मापने योग्य उद्देश्य नहीं है।
स्टोनब्रेकर के शोध सूत्र—रिलेशनल नींव, विस्तारयोग्यता, कॉलम स्टोर्स, MPP निष्पादन, और "वर्कलोड के लिए सही टूल"—आधुनिक डेटा प्लेटफ़ॉर्म्स के डिफ़ॉल्ट स्वरूपों में दिखाई देते हैं।
वेयरहाउस SQL ऑप्टिमाइज़ेशन, कॉलमर स्टोरेज, और पैरेलल निष्पादन पर दशकों के काम को दर्शाता है। जब आप बड़ी तालिकाओं पर तेज़ डैशबोर्ड देखते हैं, आप अक्सर कॉलम-आधारित फॉर्मैट्स के साथ वेक्टराइज़्ड प्रोसेसिंग और MPP-शैली स्केलिंग देख रहे होते हैं।
लेकहाउस वेयरहाउस विचारों (स्कीमास, आँकड़े, कैशिंग, कॉस्ट-बेस्ड ऑप्टिमाइज़ेशन) को खुले फ़ाइल फॉर्मैट्स और ऑब्जेक्ट स्टोरेज पर रखता है। "स्टोरेज सस्ता है, कंप्यूट इलास्टिक है" शिफ्ट नया है; नीचे की क्वेरी और ट्रांज़ैक्शन सोच नहीं।
MPP एनालिटिक्स सिस्टम्स (शेयर्ड-नथिंग क्लस्टर्स) उन अनुसंधान के प्रत्यक्ष उत्तराधिकारी हैं जिन्होंने सिद्ध किया कि SQL को पार्टिशन करके, डेटा पर कंप्यूट ले जाकर, और जॉइन्स/एग्रीगेशन्स के दौरान डेटा मूवमेंट को सावधानी से मैनेज करके स्केल किया जा सकता है।
SQL वेयरहाउस, MPP इंजन, और यहां तक कि "लेक" क्वेरी लेयर्स में सामान्य इंटरफ़ेस बन गया है। टीमें इसे ऊपर
यहाँ तक कि जब निष्पादन अलग इंजनों (बैच, इंटरएक्टिव, स्ट्रीमिंग) में होता है, SQL अक्सर उपयोगकर्ता-फेसिंग भाषा बनी रहती है।
लचीला स्टोरेज संरचना की ज़रूरत को खत्म नहीं करता। स्पष्ट स्कीमाएँ, डॉक्यूमेंटेड अर्थ, और नियंत्रित विकास डाउनस्ट्रीम ब्रेकेज़ कम करते हैं।
अच्छी गवर्नेंस नौकरशाही नहीं बल्कि डेटा को विश्वसनीय बनाना है: सुसंगत परिभाषाएँ, स्वामित्व, गुणवत्ता जांचें, और एक्सेस कंट्रोल्स।
प्लेटफ़ॉर्म का मूल्यांकन करते समय पूछें:
अगर कोई विक्रेता अपने उत्पाद को इन बुनियादी बातों से सामान्य भाषा में नहीं जोड़ पाता, तो "इनोवेशन" ज्यादातर पैकेजिंग हो सकती है।
स्टोनब्रेकर की केंद्रीय दिशा सरल है: डेटाबेस तब सबसे बेहतर काम करते हैं जब वे किसी विशेष काम के लिए डिज़ाइन किए गए हों—और जब वे उस काम के बदलने पर विकसित हो सकें।
फीचर्स तुलना करने से पहले, यह लिख दें कि आपको वास्तव में क्या करना है:
एक उपयोगी नियम: अगर आप अपने वर्कलोड को कुछ वाक्यों में नहीं बता सकते, तो आप buzzwords के हिसाब से खरीदारी कर लेंगे।
टीमें अक्सर आँकड़ों से कम आंकती हैं कि आवश्यकताएँ कितनी बार बदलती हैं: नए डेटा प्रकार, नए मैट्रिक्स, नए अनुपालन नियम, नए उपभोक्ता।
ऐसी प्लेटफ़ॉर्म और डेटा मॉडलों को चुनें जो बदलाव को रोज़मर्रा का और जोखिम-रहित बनाते हैं:
तेज़ उत्तर केवल तब मूल्यवान हैं जब वे सही हों। विकल्पों का मूल्यांकन करते समय पूछें कि सिस्टम कैसे हैंडल करता है:
एक डेमो ही काफी नहीं—अपने डेटा के साथ एक छोटा "प्रूफ" चलाएँ:
कई डेटाबेस मार्गदर्शक केवल "सही इंजन चुनो" पर ठहर जाते हैं, पर टीमों को उस इंजन के चारों ओर ऐप्स और आंतरिक टूल्स भी शिप करने होते हैं: एडमिन पैनल्स, मैट्रिक्स डैशबोर्ड्स, इन्गेसशन सर्विसेज, और बैक-ऑफिस वर्कफ़्लोज़।
यदि आप तीव्रता से प्रोटोटाइप बनाना चाहते हैं बिना अपने पूरे पाइपलाइन को फिर से बनाने के, तो एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai आपकी मदद कर सकता है—यह चैट-ड्रिवन वर्कफ़्लो से वेब ऐप्स (React), बैकेंड सर्विसेज (Go + PostgreSQL), और मोबाइल क्लाइंट्स (Flutter) स्पिन अप कर सकता है। यह अक्सर उपयोगी होता है जब आप स्कीमा डिज़ाइन पर तेज़ी से Итरेट कर रहे हों, एक छोटा आंतरिक "डेटा प्रोडक्ट" बना रहे हों, या वर्कलोड के व्यवहार को सत्यापित करना चाह रहे हों इससे पहले कि आप दीर्घकालिक इन्फ्रास्ट्रक्चर पर प्रतिबद्ध हों।
अगर आप और गहराई में जाना चाहते हैं, तो columnar storage, MVCC, MPP execution, और stream processing खोजें। और अधिक समझाने वाले लेख /blog में मिलेंगे।
वे एक दुर्लभ उदाहरण हैं जहाँ शोध परियोजनाएँ वास्तविक उत्पादों के मूल सिद्धांत बन गईं। Ingres (SQL + क्वेरी ऑप्टिमाइज़ेशन), Postgres (extensibility + MVCC विचार), और Vertica (कॉलम-आधारित + MPP एनालिटिक्स) में सिद्ध विचार आज वेयरहाउस, OLTP डेटाबेस और स्ट्रीमिंग प्लेटफ़ॉर्म के निर्माण और विपणन में दिखाई देते हैं।
SQL इसलिए विजयी रहा क्योंकि यह बताता है कि आप क्या चाहते हैं, जबकि डेटाबेस तय करता है कि उसे कुशलतापूर्वक कैसे प्राप्त करना है। यह अलगाव निम्न उपलब्ध कराता है:
एक कॉस्ट-बेस्ड ऑप्टिमाइज़र तालिका के आँकड़ों का उपयोग करके संभावित क्वेरी योजनाओं की तुलना करता है और सबसे कम अपेक्षित "कॉस्ट" (I/O, CPU, मेमोरी) वाली योजना चुनता है। व्यावहारिक रूप से, यह आपको:
MVCC (Multi-Version Concurrency Control) यह सुनिश्चित करता है कि पढ़ने वाले एक सुसंगत स्नैपशॉट देख सकें जबकि लिखने वाले अपडेट कर रहे होते हैं, इसके लिए पंक्तियों के कई संस्करण रखे जाते हैं। रोज़मर्रा की बातों में इसका मतलब:
Extensibility का अर्थ है कि डेटाबेस नए क्षमताओं (टाइप्स, फंक्शंस, इंडेक्स) को सुरक्षित तरीके से जोड़ सकता है बिना इंजन को फोर्क किए। आज के निर्माणों पर इसका प्रभाव:
ऑपरेशनल नियम: एक्सटेंशन्स को निर्भरताओं की तरह मानें—उनका वर्जन करें, अपग्रेड्स टेस्ट करें, और सीमित लोगों को इंस्टॉल की अनुमति दें।
रो-स्टोर्स तब बेहतरीन होते हैं जब आप अक्सर पूरे रिकॉर्ड को पढ़ते/लिखते हैं (OLTP)। कॉलम-स्टोर्स तब चमकते हैं जब आप बहुत सारी पंक्तियों को स्कैन करते हैं लेकिन केवल कुछ फ़ील्ड्स को छूते हैं (एनालिटिक्स)।
सरल हेजिस्टिक:
MPP (massively parallel processing) एक क्वेरी पर कई नोड एक साथ काम करते हैं—डेटा को नोड्स में बांटा जाता है और हर नोड अपने हिस्से को प्रोसेस करके आंशिक परिणाम देता है, जिन्हें मिलाकर अंतिम उत्तर बनता है। यह तब सार्थक है जब:
हालाँकि जटिलताएँ हैं: डेटा के वितरण के चुनाव, जॉइन के दौरान shuffle लागत, और उच्च-फ्रीक्वेंसी सिंगल-रो अपडेट्स के लिए कमजोर एर्गोनॉमिक्स।
वेक्टराइज़्ड एक्सेक्यूशन में इंजन एक-एक रो के बजाय बैच (वेक्टर) में मानों को प्रोसेस करता है, जिससे ओवरहेड कम होता है और CPU कैश बेहतर उपयोग होता है। आप इसे आमतौर पर महसूस करेंगे:
बॅच सिस्टम समय-समय पर नौकरियाँ चलाते हैं, इसलिए "ताज़ा" डेटा में देरी हो सकती है। स्ट्रीमिंग सिस्टम घटनाओं को निरंतर इनपुट मानते हैं और परिणामों को क्रमिक रूप से अपडेट करते हैं।
स्ट्रीमिंग तब लाभदायक है जब समय मायने रखता है:
स्ट्रीमिंग गणनाओं को सीमित रखने के लिए विंडोज़ (जैसे पिछले 5 मिनट) का उपयोग करती है न कि "सभी समय"।
बड़े उपकरण स्प्रोल से बचने के लिए हर सिस्टम के पास एक साफ वर्कलोड-बाउंडरी और मापनीय लाभ होना चाहिए (लागत, लेटेंसी, विश्वसनीयता)। स्प्रोल से बचने के उपाय:
पोस्ट में दिए गए चेकलिस्ट मानसिकता और /blog में संबंधित पीसों का पुन: उपयोग करें।