14 अप्रैल 2025·8 मिनट
माइक्रोफ्रेमवर्क कैसे लचीली कस्टम आर्किटेक्चर सक्षम करते हैं
जानें कि माइक्रोफ्रेमवर्क टीमों को स्पष्ट मॉड्यूल, मिडलवेयर और सीमाओं के साथ कस्टम आर्किटेक्चर कैसे बनाने देते हैं—साथ ही इससे जुड़े ट्रेड‑ऑफ, पैटर्न और जोखिम।
जानें कि माइक्रोफ्रेमवर्क टीमों को स्पष्ट मॉड्यूल, मिडलवेयर और सीमाओं के साथ कस्टम आर्किटेक्चर कैसे बनाने देते हैं—साथ ही इससे जुड़े ट्रेड‑ऑफ, पैटर्न और जोखिम।
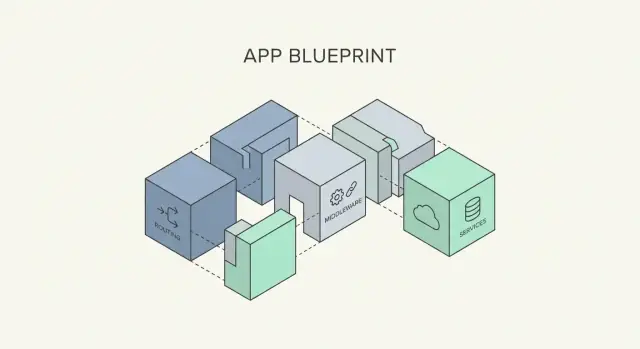
माइक्रोफ्रेमवर्क हल्के वेब फ़्रेमवर्क होते हैं जो अनिवार्य तत्वों पर ध्यान देते हैं: एक रिक्वेस्ट लेना, उसे सही हैंडलर पर रूट करना, और एक रिस्पॉन्स लौटाना। फुल‑स्टैक फ़्रेमवर्क के विपरीत, वे आमतौर पर हर वह चीज़ साथ नहीं देते जिसकी आपको ज़रूरत पड़ सकती है (एडमिन पैनल, ORM/डेटाबेस लेयर, फॉर्म बिल्डर, बैकग्राउंड जॉब्स, ऑथ)। इसके बजाय, वे एक छोटा, स्थिर कोर प्रदान करते हैं और आपको सिर्फ़ वही जोड़ने देते हैं जिसकी आपके प्रोडक्ट को वास्तव में ज़रूरत है।
एक फुल‑स्टैक फ़्रेमवर्क बिलकुल ऐसा है जैसे एक पूरी तरह सुसज्जित घर खरीदना: सुसंगत और सुविधाजनक, पर रिपेयर या रीमोडल करना मुश्किल। एक माइक्रोफ्रेमवर्क खाली‑पर‑स्ट्रक्चरलली‑साउंड स्पेस की तरह है: आप तय करते हैं कमरे, फर्नीचर और यूटिलिटीज़।
यही स्वतंत्रता है जिसे हम कस्टम आर्किटेक्चर कहते हैं—एक सिस्टम डिज़ाइन जो आपकी टीम की ज़रूरतों, आपके डोमेन और आपके ऑपरेशनल प्रतिबंधों के चारों ओर आकार लेता है। सरल शब्दों में: आप घटक चुनते हैं (लॉगिंग, डेटाबेस एक्सेस, वैलिडेशन, ऑथ, बैकग्राउंड प्रोसेसिंग) और तय करते हैं कि वे कैसे जुड़ें, बजाय इसके कि किसी पूर्व‑निर्धारित “एक सही तरीका” को स्वीकार करें।
टीमें अक्सर माइक्रोफ्रेमवर्क चुनती हैं जब वे चाहती हैं:
हम ध्यान केंद्रित करेंगे कि माइक्रोफ्रेमवर्क मॉड्युलर डिज़ाइन को कैसे सपोर्ट करते हैं: बिल्डिंग ब्लॉक्स को कंपोज़ करना, मिडलवेयर का उपयोग, और डिपेंडेंसी इंजेक्शन जोड़ना बिना प्रोजेक्ट को साइंस‑एक्सपेरिमेंट में बदलने के।
हम किसी विशिष्ट फ़्रेमवर्क की लाइन‑बाय‑लाइन तुलना नहीं करेंगे और न ही यह दावा करेंगे कि माइक्रोफ्रेमवर्क हमेशा बेहतर हैं। लक्ष्य यह है कि आप संरचना को जानबूझकर चुनें—और जैसे‑जैसे आवश्यकताएँ बदलें उसे सुरक्षित तरीके से विकसित कर सकें।
माइक्रोफ्रेमवर्क सबसे अच्छा तब काम करते हैं जब आप अपने एप्लिकेशन को किट की तरह व्यवहार करते हैं, न कि प्री‑बिल्ट घर की तरह। एक ओपिनन्ड स्टैक स्वीकार करने के बजाय, आप एक छोटा कोर लेते हैं और केवल वही क्षमताएँ जोड़ते हैं जो अपने‑आप में लाभप्रद हों।
एक व्यावहारिक “कोर” आमतौर पर सिर्फ़ होता है:
इतना काफी है एक काम करने वाले API एंडपॉइंट या वेब पेज शिप करने के लिए। बाकी सब वैकल्पिक है जब तक आपके पास ठोस कारण न हो।
जब आपको ऑथ, वैलिडेशन, या लॉगिंग चाहिए, तो उन्हें अलग घटकों के रूप में जोड़ें—आदर्श रूप से स्पष्ट इंटरफेस के पीछे। इससे आपकी आर्किटेक्चर समझने लायक बनी रहती है: हर नया टुकड़ा यह जवाब देना चाहिए कि "यह किस समस्या को हल करता है?" और "यह कहाँ प्लग इन होता है?"
"आवश्यकतानुसार जोड़ें" मॉड्यूल के उदाहरण:
शुरुआत में ऐसे समाधान चुनें जो आपको फंसाकर न रखें। गहरे फ़्रेमवर्क मैजिक की बजाय पतले रैपर और कॉन्फ़िगरेशन को प्राथमिकता दें। अगर आप किसी मॉड्यूल को बिना बिजनेस लॉजिक फिर से लिखे बदल सकें, तो आप सही कर रहे हैं।
आर्किटेक्चरल चुनावों के लिए एक सरल परिभाषा‑ऑफ‑डन: टीम हर मॉड्यूल का उद्देश्य समझा सके, उसे एक‑दो दिनों में बदल सके, और स्वतंत्र रूप से टेस्ट कर सके।
माइक्रोफ्रेमवर्क डिज़ाइन के हिसाब से छोटे रहते हैं, जिसका अर्थ है कि आप अपने एप्लिकेशन के “अंग” चुनते हैं बजाय इसके कि आपको पूरा शरीर विरासत में मिले। यही कस्टम आर्किटेक्चर व्यवहार्य बनाता है: आप न्यूनतम से शुरू कर सकते हैं और तभी नए टुकड़े जोड़ते हैं जब वास्तविक ज़रूरत आ जाए।
अधिकांश माइक्रोफ्रेमवर्क‑आधारित ऐप्स एक राउटर से शुरू होते हैं जो URLs को कंट्रोलर्स (या सरल request handlers) से मैप करता है। कंट्रोलर्स को फीचर (billing, accounts) या इंटरफ़ेस (web बनाम API) के आधार पर व्यवस्थित किया जा सकता है, इस पर निर्भर करता है कि आप कोड कैसे मेंटेन करना चाहते हैं।
मिडलवेयर आमतौर पर रिक्वेस्ट/रिस्पॉन्स फ्लो को रैप करता है और क्रॉस‑कटिंग चिंताओं के लिए सबसे अच्छा स्थान होता है:
क्योंकि मिडलवेयर कंपोज़ेबल है, आप इसे ग्लोबल रूप से लागू कर सकते हैं (हर चीज़ को लॉग करना ज़रूरी है) या केवल कुछ रूट्स पर (एडमिन एंडपॉइंट्स के लिए कड़ा ऑथ)।
माइक्रोफ्रेमवर्क शायद ही कभी एक डेटा लेयर फोर्स करते हैं, इसलिए आप उस स्तर का चयन कर सकते हैं जो आपकी टीम और वर्कलोड से मेल खाता है:
एक अच्छा पैटर्न यह है कि डेटा एक्सेस को किसी रिपॉज़िटरी या सर्विस लेयर के पीछे रखें, ताकि बाद में टूल बदलने से आपके हैंडलर्स में एक लहर न चले।
हर प्रोडक्ट को पहले दिन से async प्रोसेसिंग की ज़रूरत नहीं होती। जब ज़रूरत पड़े, तब एक job runner और एक 큐 जोड़ें (ईमेल भेजना, वीडियो प्रोसेसिंग, वेबहुक्स)। बैकग्राउंड जॉब्स को आपके डोमेन लॉजिक में एक अलग "एंट्री पॉइंट" जैसा माना जाना चाहिए, और HTTP लेयर के समान सर्विसेज़ साझा करनी चाहिए बजाय नियमों को डुप्लिकेट करने के।
मिडलवेयर वह जगह है जहाँ माइक्रोफ्रेमवर्क सबसे ज़्यादा लीवरेज देता है: यह आपको क्रॉस‑कटिंग जरूरतों को संभालने देता है—वे चीज़ें जो हर रिक्वेस्ट को मिलनी चाहिए—बिना हर रूट हैंडलर को फूलने दिए। लक्ष्य सरल है: हैंडलर्स को बिजनेस लॉजिक पर केंद्रित रखें, और मिडलवेयर को प्लम्बिंग संभालने दें।
हर एंडपॉइंट में वही चेक और हेडर्स दोहराने के बजाय, मिडलवेयर एक बार जोड़ें। एक क्लीन हैंडलर इस तरह दिखता है: इनपुट पार्स करें, एक सर्विस को कॉल करें, रिस्पॉन्स लौटाएं। बाकी सब—ऑथ, लॉगिंग, वैलिडेशन डिफॉल्ट्स, रिस्पॉन्स फॉर्मैटिंग—शुरू होने से पहले या बाद में हो सकता है।
ऑर्डर ही व्यवहार है। एक सामान्य, पढ़ने योग्य क्रम है:
यदि कंप्रेशन बहुत जल्दी चलता है, तो यह एरर्स को मिस कर सकता है; और अगर एरर हैंडलिंग बहुत देर से आती है, तो आप स्टैक‑ट्रेस लीक कर सकते हैं या असंगत फॉर्मैट लौट सकते हैं।
X-Request-Id हेडर जोड़ें और इसे लॉग में शामिल करें।{ error, message, requestId })।मिडलवेयर को उद्देश्य के अनुसार समूहबद्ध करें (observability, security, parsing, response shaping) और इसे सही स्कोप पर लागू करें: जो नियम वाकई सार्वभौमिक हों उनके लिए ग्लोबल, और विशिष्ट क्षेत्रों (उदा., /admin) के लिए route‑group मिडलवेयर। हर मिडलवेयर को स्पष्ट नाम दें और सेटअप के पास एक संक्षिप्त टिप्पणी में अपेक्षित ऑर्डर डॉक्यूमेंट करें ताकि भविष्य के परिवर्तन चुपके से व्यवहार न तोड़ें।
माइक्रोफ्रेमवर्क आपको एक पतला “रिक्वेस्ट इन, रिस्पॉन्स आउट” कोर देता है। बाकी सब—डेटाबेस एक्सेस, कैशिंग, ईमेल, थर्ड‑पार्टी APIs—स्वैपेबल होना चाहिए। यही जगह है जहाँ IoC और DI मदद करते हैं, बिना आपका कोडबेस साइंस‑प्रयोग बनने के।
यदि किसी फीचर को डेटाबेस चाहिए, तो उस फीचर के अंदर सीधे एक क्लाइंट बनाना tempting होता है ("यहाँ नया डेटाबेस क्लाइंट"). नतीजा: हर जगह जो ऐसा करती है वह अब उस खास डेटाबेस क्लाइंट से टाइट‑टाईड हो जाती है।
IoC इसे उलट देता है: आपका फीचर जो चाहिए पूछता है, और ऐप वाइरिंग उसे दे देती है। आपका फीचर फिर आसान हो जाता है पुनः उपयोग और बदलने के लिए।
डिपेंडेंसी इंजेक्शन का मतलब बस है कि डिपेंडेंसीज़ को अंदर से बनाने के बजाय पास किया जाए। माइक्रोफ्रेमवर्क सेटअप में अक्सर यह स्टार्टअप पर किया जाता है:
आपको बड़े DI कंटेनर की ज़रूरत नहीं होती ताकि लाभ मिलें। एक सरल नियम से शुरू करें: डिपेंडेंसीज़ एक जगह बनाएं, और नीचे पास करें।
कंपोनेंट्स को इंटरचेंज करने योग्य बनाने के लिए, "जो चाहिए" को एक छोटा इंटरफ़ेस बनाकर परिभाषित करें, फिर विशिष्ट टूल्स के लिए एडैप्टर्स लिखें।
उदाहरण पैटर्न:
UserRepository (इंटरफ़ेस): findById, create, listPostgresUserRepository (एडैप्टर): Postgres का उपयोग करके उन मेथड्स को इम्प्लीमेंट करता हैInMemoryUserRepository (एडैप्टर): टेस्ट्स के लिए वही मेथड्स इम्प्लीमेंट करता हैआपका बिजनेस लॉजिक केवल UserRepository के बारे में जानता है, न कि Postgres के बारे में। स्टोरेज बदलना एक कॉन्फ़िगरेशन विकल्प बन जाता है, न कि री‑राइट।
यह वही विचार बाहरी APIs के लिए भी काम करता है:
PaymentsGateway इंटरफ़ेसStripePaymentsGateway एडाप्टरFakePaymentsGatewayमाइक्रोफ्रेमवर्क्स के साथ यह आसान होता है कि गलती से कॉन्फ़िगरेशन मॉड्यूल्स में बिखर जाए। इससे बचें।
एक मेंटेन करने योग्य पैटर्न यह है:
इससे आप जो मुख्य लक्ष्य चाहते हैं वह मिलता है: कम्पोनेंट्स को रिप्लेस करें बिना ऐप को फिर से लिखे। डेटाबेस बदलना, API क्लाइंट बदलना, या 큐 जोड़ना वाइरिंग‑लेयर में एक छोटा बदलाव बन जाता है—बाकी कोड स्थिर रहता है।
माइक्रोफ्रेमवर्क आपका कोड संरचित करने के लिए "एक सही तरीका" ज़बरदस्ती नहीं बताते। इसके बजाय वे रूटिंग, रिक्वेस्ट/रिस्पॉन्स हैंडलिंग और एक छोटे एक्सटेंशन पॉइंट का सेट देते हैं—ताकि आप उन पैटर्न्स को अपना सकें जो आपकी टीम साइज, प्रोडक्ट परिपक्वता, और परिवर्तन दर के अनुकूल हों।
यह परिचित "साफ और सरल" सेटअप है: कंट्रोलर्स HTTP संबंधी चिंताओं को संभालते हैं, सर्विसेज बिजनेस नियम रखते हैं, और रिपॉज़िटरीज़ DB से बात करते हैं।
यह तब अच्छा बैठता है जब आपका डोमेन सरल हो, टीम छोटी‑मध्यम हो, और आप चाहते हैं कि कोड के लिए प्रेडिक्टेबल जगहें हों। माइक्रोफ्रेमवर्क इसे नेचुरल तरीके से सपोर्ट करते हैं: रूट्स कंट्रोलर्स से मैप होते हैं, कंट्रोलर्स सर्विसेज को कॉल करते हैं, और रिपॉज़िटरीज़ हाथ से कम्पोजिशन के द्वारा वायर्ड होते हैं।
हैक्सागोनल आर्किटेक्चर तब उपयोगी है जब आप उम्मीद करते हैं कि आपका सिस्टम आज के चुनावों (DB, मेसेज बस, थर्ड‑पार्टी APIs, या UI) से ज्यादा लंबा चलेगा।
माइक्रोफ्रेमवर्क यहां अच्छी तरह से काम करते हैं क्योंकि “एडैप्टर” लेयर अक्सर आपके HTTP हैंडलर्स और डोमेन कमांड में एक पतला ट्रांसलेशन चरण होती है। आपके पोर्ट्स डोमेन में इंटरफेसेज़ होते हैं, और एडैप्टर्स उन्हें इम्प्लिमेंट करते हैं (SQL, REST क्लाइंट्स, 큐ज़)। फ़्रेमवर्क किनारे पर रहता है, केंद्र में नहीं।
यदि आप बिना ऑपरेशनल ओवरहेड के माइक्रोसर्विस‑ जैसा स्पष्टता चाहते हैं, तो एक मॉड्युलर मोनोलिथ अच्छा विकल्प है। आप एक ही डिप्लॉयेबल ऐप रखते हैं, पर उसे फ़ीचर मॉड्युल्स (उदा., Billing, Accounts, Notifications) में बाँटते हैं जिनकी सार्वजनिक APIs स्पष्ट हों।
माइक्रोफ्रेमवर्क इसे आसान बनाते हैं क्योंकि वे ऑटो‑वायर कुछ नहीं करते: हर मॉड्युल अपना रूट्स, डिपेंडेंसीज़ और डेटा एक्सेस रजिस्टर कर सकता है, जिससे सीमाएँ दिखाई देती हैं और गलती से पार करना कठिन होता है।
इन तीनों पैटर्न्स में लाभ समान है: आप नियम चुनते हैं—फ़ोल्डर लेआउट, डिपेंडेंसी दिशा, और मॉड्यूल सीमाएँ—जबकि माइक्रोफ्रेमवर्क एक स्थिर, छोटा सतह‑क्षेत्र प्रदान करता है जिसमें आप प्लग कर सकें।
माइक्रोफ्रेमवर्क आपको छोटा शुरू करने और लचीला रहने में मदद करते हैं, पर वे बड़े सवाल का उत्तर नहीं देते: आपके सिस्टम का सही "आकृति" क्या होनी चाहिए? सही चुनाव तकनीक से कम और टीम साइज, रिलीज़ कैडेंस, और समन्वय कितना दर्दनाक हो गया है उस पर अधिक निर्भर करता है।
एक मोनोलिथ एक डिप्लॉयेबल यूनिट के रूप में शिप होता है। यह अक्सर एक काम करने वाले प्रोडक्ट की तेज़ी से पहुंच प्रदान करता है: एक बिल्ड, एक लॉग सेट, एक डिबग पॉइंट।
एक मॉड्युलर मोनोलिथ अभी भी एक ही डिप्लॉयेबल है, पर अंदरूनी रूप से स्पष्ट मॉड्युल्स में विभाजित है (पैकेजेस, बाउंडेड कॉन्टेक्स्ट, फीचर फ़ोल्डर्स)। यह अक्सर अगला सर्वश्रेष्ठ कदम होता है जब कोडबेस बड़ा हो जाता है—खासतौर पर माइक्रोफ्रेमवर्क्स के साथ, जहाँ आप मॉड्युल्स को स्पष्ट रख सकते हैं।
माइक्रोसर्विसेज डिप्लॉयबल को कई सेवाओं में बाँट देते हैं। इससे टीमों के बीच कपलिंग कम हो सकती है, पर ऑपरेशनल काम भी बढ़ जाता है।
वहां विभाजन करें जहाँ सीमा आपके काम में पहले से वास्तविक हो:
उस समय विभाजित करने से बचें जब यह ज़्यादातर सुविधा के लिए हो ("यह फ़ोल्डर बड़ा है") या जब सेवाएँ एक ही डेटाबेस तालिकाएँ साझा करें। यह संकेत है कि आपने अभी स्थिर सीमा नहीं पायी है।
एक API गेटवे क्लाइंट्स को सरल बना सकता है (एक एंट्री पॉइंट, केंद्रीकृत ऑथ/रेट‑लिमिटिंग)। नुकसान: यदि यह बहुत स्मार्ट हो जाए तो यह एक बॉटलनेक और एक सिंगल फेल्योर पॉइंट बन सकता है।
शेयरड लाइब्रेरीज़ विकास को तेज करती हैं (साझा वैलिडेशन, लॉगिंग, SDKs), पर वे छिपा हुआ कपलिंग भी उत्पन्न कर सकती हैं। यदि कई सेवाओं को साथ में अपग्रेड करना पड़े, तो आपने एक वितरित मोनोलिथ दोबारा बना लिया।
माइक्रोसर्विसेज़ नियमित लागतें जोड़ते हैं: अधिक डिप्लॉय पाइपलाइन्स, वर्शनिंग, सर्विस डिस्कवरी, मॉनिटरिंग, ट्रेसिंग, इनसिडेंट रेस्पांस, और ऑन‑कॉल रोटेशन। अगर आपकी टीम वह मशीनरी आराम से नहीं चला सकती, तो माइक्रोफ्रेमवर्क कम्पोनेंट्स के साथ बना एक मॉड्युलर मोनोलिथ अक्सर सुरक्षित आर्किटेक्चर होता है।
माइक्रोफ्रेमवर्क आपको आज़ादी देते हैं, पर मेंटेनबिलिटी आपको डिजाइन करनी पड़ती है। लक्ष्य यह है कि “कस्टम” हिस्से आसानी से मिलें, आसानी से बदले जाएँ, और गलत उपयोग के लिए कठिन हों।
एक संरचना चुनें जिसे आप एक मिनट में समझा सकें और कोड रिव्यू से लागू कर सकें। एक व्यावहारिक विभाजन:
app/ (composition root: मॉड्युल्स को वायर करता है)modules/ (बिजनेस क्षमताएँ)transport/ (HTTP रूटिंग, request/response मैपिंग)shared/ (क्रॉस‑कटिंग यूटिलिटीज़: config, logging, error types)tests/नामकरण सुसंगत रखें: मॉड्यूल फ़ोल्डर्स संज्ञा उपयोग करें (billing, users), और एंट्री‑पॉइंट्स प्रत्याशित हों (index, routes, service)।
प्रत्येक मॉड्युल को एक छोटे प्रोडक्ट की तरह मानें:
modules/users/public.ts)modules/users/internal/*)"reach‑through" इम्पोर्ट्स से बचें जैसे modules/orders/internal/db.ts किसी अन्य मॉड्युल से। यदि किसी अन्य हिस्से को इसकी ज़रूरत है, तो उसे सार्वजनिक API में प्रमोट करें।
छोटी सेवाओं को भी मूल दृश्यता चाहिए:
इन्हें shared/observability में रखें ताकि हर रूट हैंडलर एक ही कन्वेंशंस का उपयोग करे।
क्लाइंट्स के लिए एरर्स को अनुमान्य बनाएं और इंसानों के लिए डिबग करना आसान बनाएं। एक एरर शेप पर सहमति बनाएं (उदा., code, message, details, requestId) और हर एंडपॉइंट के लिए एक वैलिडेशन स्कीमा रखें। इंटरनल एक्सेप्शन्स से HTTP रिस्पॉन्स में मैपिंग केंद्रीकृत करें ताकि हैंडलर्स बिजनेस लॉजिक पर केंद्रित रहें।
अगर आपका लक्ष्य तीव्रता से आगे बढ़ना है और फिर भी माइक्रोफ्रेमवर्क‑शैली की आर्किटेक्चर स्पष्ट रखना है, तो Koder.ai स्कैफ़ोल्डिंग और इटरशन टूल के रूप में उपयोगी हो सकता है—हैंड‑बिल्ट डिज़ाइन की जगह नहीं। आप चैट में अपने मॉड्यूल बॉउंड्रीज़, मिडलवेयर स्टैक और एरर फॉर्मैट का वर्णन कर सकते हैं, एक वर्किंग बेसलाइन ऐप जेनरेट कर सकते हैं (उदा., React फ्रंटेंड के साथ Go + PostgreSQL बैकएंड), और फिर वायरिंग को जानबूझकर परिष्कृत कर सकते हैं।
दो फीचर खासकर कस्टम आर्किटेक्चर वर्क के साथ अच्छी तरह मैप होते हैं:
क्योंकि Koder.ai सॉर्स कोड एक्सपोर्ट सपोर्ट करता है, आप आर्किटेक्चर का ओनरशिप रख सकते हैं और इसे अपने रेपो में उसी तरह विकसित कर सकते हैं जैसे आप हाथ से बनाए गए माइक्रोफ्रेमवर्क प्रोजेक्ट के साथ करते।
माइक्रोफ्रेमवर्क‑आधारित सिस्टम अक्सर “हाथ‑से‑जोडे हुए” लगते हैं, इसलिए परीक्षण किसी फ्रेमवर्क की एकल परंपरा से अधिक आपके हिस्सों के बीच सीमाओं की रक्षा के बारे में होता है। लक्ष्य है आत्म‑विश्वास बिना हर बदलाव को पूरा end‑to‑end रन बनाए।
यूनिट टेस्ट्स से शुरू करें जो बिजनेस रूल्स (वैलिडेशन, प्राइसिंग, परमिशन्स लॉजिक) के लिए तेज़ और स्पष्ट फेल्योर पॉइंट देते हैं।
फिर कुछ उच्च‑मूल्य वाले इंटीग्रेशन टेस्ट्स में निवेश करें जो वायरिंग को चेक करें: routing → middleware → handler → persistence boundary। ये उन छोटे बग्स को पकड़ते हैं जो कम्पोनेंट्स के संयोजन पर ही आते हैं।
मिडलवेयर वह जगह है जहाँ क्रॉस‑कटिंग बिहेवियर छिपता है (ऑथ, लॉगिंग, रेट‑लिमिट)। इसे पाइपलाइन की तरह टेस्ट करें:
हैंडलर्स के लिए, आंतरिक फ़ंक्शन कॉल की बजाय सार्वजनिक HTTP शेप (स्टेटस कोड्स, हेडर्स, रिस्पॉन्स बॉडी) को टेस्ट करना बेहतर है। इससे टेस्ट्स इंटर्नल चेंजेस के साथ स्थिर रहते हैं।
DI (या सरल कंस्ट्रक्टर पैरामीटर्स) का उपयोग करके असली डिपेंडेंसीज़ को फेक्स से बदलें:
जब कई सेवाएँ या टीमें किसी API पर निर्भर हों, तो कॉन्ट्रैक्ट टेस्ट्स जोड़ें जो रिक्वेस्ट/रिस्पॉन्स अपेक्षाओं को लॉक करें। प्रदाता‑साइड कॉन्ट्रैक्ट टेस्ट यह सुनिश्चित करते हैं कि आप कंज्यूमर को गलती से न तोड़ें, भले ही आपकी माइक्रोफ्रेमवर्क सेटअप और आंतरिक मॉड्युल्स विकसित हों।
माइक्रोफ्रेमवर्क आपको स्वतंत्रता देते हैं, पर स्वतंत्रता स्वतः स्पष्टता नहीं लाती। मुख्य जोखिम बाद में आते हैं—जब टीम बढ़े, कोडबेस फैलता है, और “अल्पकालिक” निर्णय स्थायी बन जाते हैं।
कम बिल्ट‑इन कन्वेंशन के साथ, दो टीमें एक समान फीचर को दो अलग‑अलग स्टाइल में बना सकती हैं (रूटिंग, एरर हैंडलिंग, रिस्पॉन्स फॉर्मैट, लॉगिंग)। वह असंगति रिव्यू को धीमा करती है और ऑनबोर्डिंग मुश्किल बनाती है।
एक सरल गार्डरेल मदद करता है: एक छोटा “सर्विस टेम्पलेट” डॉक लिखें (प्रोजेक्ट स्ट्रक्चर, नामकरण, एरर फॉर्मैट, लॉगिंग फील्ड्स) और इसे एक स्टार्ट‑र रेपो और कुछ लिंट्स के साथ लागू करें।
माइक्रोफ्रेमवर्क प्रोजेक्ट अक्सर साफ़ शुरू होते हैं, फिर एक utils/ फ़ोल्डर जमा होता है जो धीरे‑धीरे एक दूसरा फ्रेमवर्क बन जाता है। जब मॉड्युल्स हेल्पर्स, कॉन्स्टेंट्स और ग्लोबल स्टेट साझा करते हैं, तो सीमाएँ धुंधली हो जाती हैं और बदलाव अनपेक्षित ब्रेक पैदा करते हैं।
स्पष्ट साझा पैकेजेस को प्राथमिकता दें जिनका वर्शनिंग करें, या साझा करने को न्यूनतम रखें: टाइप्स, इंटरफेस और अच्छे से टेस्टेड प्रिमिटिव्स। यदि कोई हेल्पर बिजनेस रूल पर निर्भर है, तो वह संभवतः utils में नहीं, बल्कि डोमेन मॉड्युल में होना चाहिए।
जब आप ऑथेंटिकेशन, ऑथराइज़ेशन, इनपुट वैलिडेशन और रेट‑लिमिटिंग को मैन्युअली वायर करते हैं, तो कोई रूट छूट सकता है, कोई मिडलवेयर भूल सकता है, या केवल “हैप्पी‑पाथ” इनपुट वैलिडेट किया जा सकता है।
सिक्योरिटी डिफॉल्ट्स को केंद्रीय बनाएं: सुरक्षित हेडर्स, सुसंगत ऑथ चेक, और किनारे पर वैलिडेशन। ऐसे टेस्ट जोड़ें जो सुनिश्चित करें कि सुरक्षित एंडपॉइंट्स वास्तव में सुरक्षित हैं।
अनियोजित मिडलवेयर परतें ओवरहेड जोड़ती हैं—खासकर अगर कई मिडलवेयर बॉडी पार्स करते हैं, स्टोरेज को हिट करते हैं, या लॉग्स को सीरियलाइज़ करते हैं।
मिडलवेयर को छोटा और मापनीय रखें। मानक ऑर्डर डॉक्यूमेंट करें, और नए मिडलवेयर के लागत के लिए समीक्षा करें। अगर आपको संदेह है कि बLOAT है, तो रिक्वेस्ट्स को प्रोफाइल करें और अनावश्यक स्टेप्स हटाएँ।
माइक्रोफ्रेमवर्क्स आपको विकल्प देते हैं—पर विकल्पों के लिए निर्णय प्रक्रिया चाहिए। लक्ष्य "सर्वश्रेष्ठ" आर्किटेक्चर नहीं ढूँढना, बल्कि एक ऐसा आकार चुनना है जिसे आपकी टीम बिना ड्रामा के बना, ऑपरेट और बदल सके।
"मोनोलिथ" या "माइक्रोसर्विसेज़" चुनने से पहले इन सवालों का जवाब दें:
अगर अनिश्चित हैं, तो माइक्रोफ्रेमवर्क के साथ एक मॉड्युलर मोनोलिथ को डिफ़ॉल्ट रखें। यह सीमाएँ स्पष्ट रखता है और शिप करना आसान बनाता है।
माइक्रोफ्रेमवर्क स्वतः आप के लिए सुसंगति लागू नहीं करते, इसलिए शुरू में कन्वेंशंस चुनें:
/docs में एक‑पेज की “सर्विस कॉन्ट्रैक्ट” अक्सर काफी होती है।
शुरू करें उन क्रॉस‑कटिंग हिस्सों के साथ जो हर जगह ज़रूरी होंगे:
इन्हें साझा मॉड्युल मानें, न कि कॉपी‑पेस्ट किए गए स्निपेट्स।
आर्किटेक्चर को आवश्यकताएँ बदलने पर बदलना चाहिए। हर तिमाही समीक्षा करें कि किस वजह से डिप्लॉय धीमे पड़ रहे हैं, किन हिस्सों का स्केल अलग है, और क्या अक्सर ब्रेक हो रहा है। यदि कोई डोमेन बाधा बन रहा है, तो वही अगला विभाजन का उम्मीदवार है—पूरे सिस्टम को नहीं।
माइक्रोफ्रेमवर्क सेटअप शायद ही कभी "पूरी तरह से डिजाइन किया हुआ" शुरू होता है। आम तौर पर यह एक API, एक टीम और एक तंग डेडलाइन से शुरू होता है। मूल्य तब दिखता है जब प्रोडक्ट बढ़ता है: नए फीचर्स आते हैं, अधिक लोग कोड को छूते हैं, और आपकी आर्किटेक्चर को बिना टूटे खिंचना पड़ता है।
आप एक न्यूनतम सेवा से शुरू करते हैं: रूटिंग, रिक्वेस्ट पार्सिंग, और एक DB एडाप्टर। अधिकांश लॉजिक एंडपॉइंट के पास ही रहता है क्योंकि शिप करना तेज़ होता है।
जैसे‑जैसे आप ऑथ, पेमेंट्स, नोटिफिकेशंस, और रिपोर्टिंग जोड़ते हैं, आप उन्हें मॉड्युल्स (फ़ोल्डर या पैकेज) में अलग करते हैं जो स्पष्ट सार्वजनिक इंटरफेसेज़ रखते हैं। हर मॉड्युल अपने मॉडल्स, बिजनेस रूल्स और डेटा एक्सेस का मालिक होता है, और केवल वही एक्सपोज़ करता है जिसकी अन्य मॉड्युल्स को ज़रूरत है।
लॉगिंग, ऑथ चेक्स, रेट‑लिमिटिंग और रिक्वेस्ट वैलिडेशन मिडलवेयर में चली जाती हैं ताकि हर एंडपॉइंट एकसमान व्यवहार करे। चूँकि ऑर्डर मायने रखता है, इसे डॉक्यूमेंट करना चाहिए।
डॉक्यूमेंट करें:
रिफैक्टर तब करें जब मॉड्युल्स बहुत सारी आंतरिक बातें साझा करने लगें, बिल्ड टाइम्स घोर रूप से धीमे हों, या "छोटे बदलाव" के लिए कई मॉड्युल्स में संपादन करना पड़े।
सर्विसेज़ में विभाजित करने पर विचार तब करें जब टीमें साझा डिप्लॉयमेंट्स से फंसी हों, अलग हिस्सों को अलग स्केलिंग चाहिए, या कोई इंटीग्रेशन सीमा पहले से अलग प्रोडक्ट की तरह व्यवहार कर रही हो।
माइक्रोफ्रेमवर्क उन मामलों के लिए उपयुक्त हैं जब आप एप्लिकेशन को अपने डोमेन के चारों ओर आकार देना चाहते हैं बजाय किसी निर्धारित स्टैक के। वे खासकर उन टीमों के लिए काम करते हैं जो स्पष्टता को सुविधाजनकता पर तरजीह देती हैं: आप कुछ प्रमुख बिल्डिंग ब्लॉक्स चुनते और मेंटेन करते हैं ताकि कोडबेस आवश्यकताओं के बदलने पर भी समझने योग्य रहे।
आपकी लचीलापन तभी फायदेमंद रहेगी जब आप इसे कुछ आदतों से सुरक्षित रखें:
शुरू करें इन दो हल्के‑वेट आर्टिफैक्ट्स से:
अंततः, निर्णयों को दस्तावेज़ करें—भले ही संक्षिप्त नोट्स हों। अपने रेपो में एक “Architecture Decisions” पेज रखें और इसे समय‑समय पर समीक्षा करें ताकि कल की शॉर्टकट्स आज की बाधाएँ न बनें।
एक माइक्रोफ्रेमवर्क अनिवार्य तत्वों पर केंद्रित एक हल्का वेब फ़्रेमवर्क होता है: रीक्वेस्ट लेना, उसे सही हैंडलर तक रूट करना और एक रिस्पॉन्स लौटाना।
एक फुल‑स्टैक फ़्रेमवर्क आमतौर पर कई “बॅटरियों सहित” फीचर (ORM, ऑथ, एडमिन, फॉर्म्स, बैकग्राउंड जॉब्स) देता है। माइक्रोफ्रेमवर्क सुविधा के बदले में अधिक नियंत्रण देते हैं—आप वही जोड़ते हैं जिसकी ज़रूरत है और तय करते हैं कि घटक कैसे जुड़ें।
माइक्रोफ्रेमवर्क तब अच्छा विकल्प है जब आप:
एक “सबसे छोटा उपयोगी कोर” आमतौर पर:
यहाँ से शुरू करें: एक एंडपॉइंट शिप करें, फिर सिर्फ़ जब किसी फीचर से स्पष्ट लाभ हो तभी मॉड्यूल जोड़ें (ऑथ, वैलिडेशन, ऑब्ज़र्वेबिलिटी, 큐)।
मिडलवेयर उन क्रॉस‑कटिंग चिंताओं के लिए उपयुक्त होता है जो व्यापक रूप से लागू होती हैं, जैसे:
रूट हैंडलरों को बिजनेस लॉजिक पर केंद्रित रखें: parse → call service → return response।
ऑर्डर व्यवहार बदलता है। एक सामान्य, भरोसेमंद अनुक्रम है:
सेटअप कोड के पास ऑर्डर को डॉक्यूमेंट करें ताकि भविष्य के बदलाव रिस्पॉन्स या सिक्योरिटी अपेक्षाओं को चुपके से तोड़ न दें।
Inversion of Control का अर्थ है कि आपका बिजनेस कोड अपनी_dependencies_ खुद नहीं बनाता (वह “खुद खरीददारी” नहीं करता)। बल्कि, एप्लिकेशन की वाइरिंग उसे वह देती है जिसकी उसे ज़रूरत है।
प्रैक्टिकल तरीका: स्टार्टअप पर DB क्लाइंट, लॉगर और API क्लाइंट बनाएं, फिर उन्हें सर्विसेज/हैंडलर्स में पास करें। इससे टाइट कपलिंग घटती है और टेस्टिंग/स्वैपेबलिटी आसान हो जाती है।
नहीं। अधिकतर DI के लाभ आप एक सरल composition root से पा सकते हैं:
जब dependency ग्राफ़ हाथ से संभालना मुश्किल हो जाए तो ही कंटेनर जोड़ें—डिफ़ॉल्ट रूप से जटिलता से शुरू न करें।
स्टोरेज और एक्सटर्नल APIs को छोटे इंटरफ़ेस (पोर्ट्स) के पीछे रखें, फिर adapters लिखें:
UserRepository इंटरफ़ेस: findById, create, listPostgresUserRepository प्रोडक्शन के लिएएक व्यवहारिक स्ट्रक्चर जो सीमाएँ स्पष्ट रखे:
app/ — composition root (wiring)modules/ — फीचर मॉड्यूल्स (डोमेन क्षमता)transport/ — HTTP रूटिंग + request/response मैपिंगshared/ — config, logging, error types, observabilityबिजनेस रूल्स के लिए तेज़ यूनिट टेस्ट्स को प्राथमिकता दें, फिर कुछ उच्च‑मूल्य इंटीग्रेशन टेस्ट्स जोड़ें जो पूरा पाइपलाइन (routing → middleware → handler → persistence boundary) जांचें।
DI/fakes का उपयोग बाहरी सेवाओं को आइसोलेट करने के लिए करें। मिडलवेयर को पाइपलाइन की तरह टेस्ट करें (हेडर, साइड‑इफेक्ट्स, और ब्लॉकिंग बिहेवियर को अस्सर्ट करें)। यदि कई टीमें APIs पर निर्भर हैं, तो कॉन्ट्रैक्ट टेस्ट जोड़ें।
InMemoryUserRepository टेस्ट्स के लिएहैंडलर/सर्विसेज़ सिर्फ़ इंटरफ़ेस को जानें, कंक्रीट टूल को नहीं। डेटाबेस या थर्ड‑पार्टी प्रोवाइडर बदलना वाइरिंग/कन्फ़िग बदलाव बन जाता है, फिर रीराइट नहीं।
tests/मॉड्यूल public APIs लागू करें (उदा., modules/users/public.ts) और internals में से “reach‑through” इंपोर्ट से बचें।