30 अग॰ 2025·8 मिनट
Nginx बनाम HAProxy: सही रिवर्स प्रॉक्सी कैसे चुनें
Nginx और HAProxy की तुलना: प्रदर्शन, लोड बैलेंसिंग, TLS, ऑब्ज़रवेबिलिटी, सुरक्षा और सामान्य सेटअप — किसे कब चुनें।
Nginx और HAProxy की तुलना: प्रदर्शन, लोड बैलेंसिंग, TLS, ऑब्ज़रवेबिलिटी, सुरक्षा और सामान्य सेटअप — किसे कब चुनें।
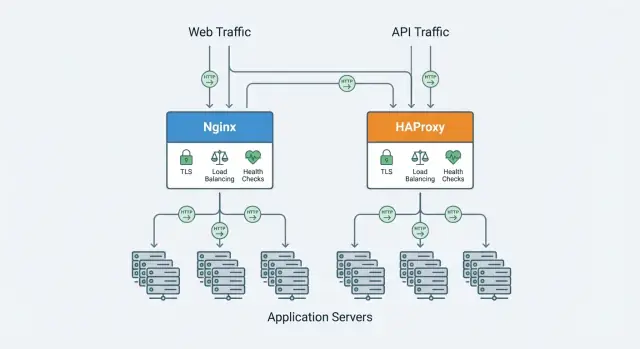
एक रिवर्स प्रॉक्सी वह सर्वर है जो आपके एप्लिकेशन्स के आगे बैठता है और पहले क्लाइंट अनुरोध प्राप्त करता है। यह प्रत्येक अनुरोध को सही बैकएंड सर्विस (आपके ऐप सर्वरों) पर फॉरवर्ड करता है और फिर क्लाइंट को response लौटाता है। उपयोगकर्ता proxy से बात करते हैं; proxy आपके ऐप्स से बात करता है।
एक फॉरवर्ड प्रॉक्सी उल्टा काम करता है: यह क्लाइंट्स (उदाहरण के लिए कंपनी नेटवर्क के अंदर) के आगे बैठता है और उनके आउटबाउंड अनुरोध इंटरनेट पर फॉरवर्ड करता है। इसका मुख्य उद्देश्य क्लाइंट ट्रैफ़िक को नियंत्रित करना, फ़िल्टर करना, या छिपाना है।
एक लोड बैलेंसर अक्सर रिवर्स प्रॉक्सी के रूप में लागू होता है, पर उसका विशेष फ़ोकस ट्रैफ़िक को कई बैकएंड इंस्टैंसों में वितरित करना होता है। कई प्रोडक्ट्स (Nginx और HAProxy सहित) दोनों—रिवर्स प्रॉक्सी और लोड बैलेंसर—का काम करते हैं, इसलिए शब्द कभी-कभी परस्पर उपयोग किए जाते हैं।
अधिकतर डिप्लॉयमेंट इनमें से एक या अधिक कारणों से शुरू होते हैं:
/api API सेवा को, / वेब ऐप को)।रिवर्स प्रॉक्सी आमतौर पर वबसाइट्स, APIs, और माइक्रोसर्विसेस के आगे खड़ा होता है—या तो एज पर (पब्लिक इंटरनेट) या अंदरूनी तौर पर सर्विसेज़ के बीच। आधुनिक स्टैक्स में इन्हें ingress gateways, blue/green deployments, और हाई-एविलेबिलिटी सेटअप्स के लिए भी बिल्डिंग ब्लॉक्स की तरह उपयोग किया जाता है।
Nginx और HAProxy में ओवरलैप है, पर वे ज़ोर अलग तरह से देते हैं। आगे के सेक्शन्स में हम निर्णय कारकों की तुलना करेंगे जैसे कई कनेक्शनों के तहत प्रदर्शन, लोड बैलेंसिंग और हेल्थ चेक्स, प्रोटोकॉल सपोर्ट (HTTP/2, TCP), TLS सुविधाएँ, ऑब्ज़रवेबिलिटी, और दैनिक कॉन्फ़िगरेशन व ऑपरेशन।
Nginx व्यापक रूप से एक वेब सर्वर और एक रिवर्स प्रॉक्सी दोनों के रूप में इस्तेमाल होता है। कई टीमें इसे पब्लिक साइट सर्व करने के लिए चुनती हैं और बाद में इसके रोल को बढ़ाकर एप्लिकेशन सर्वरों के सामने बैठा देती हैं—TLS हैंडलिंग, रूटिंग, और स्पाइक्स को स्मूद करने के लिए।
जब आपका ट्रैफ़िक मुख्य रूप से HTTP(S) हो और आप एक ऐसा "फ्रंट डोर" चाहते हों जो थोड़ा बहुत सब कर सके, तो Nginx चमकता है। यह विशेष रूप से अच्छा है:
X-Forwarded-For, सुरक्षा हेडर्स)क्योंकि यह कंटेंट सर्व करने और ऐप्स को प्रॉक्सी करने दोनों में सक्षम है, Nginx छोटे से मध्यम सेटअप्स के लिए आम चुनाव है जहाँ आप कम मूविंग पार्ट्स चाहते हैं।
लोकप्रिय क्षमताओं में शामिल हैं:
Nginx अक्सर चुना जाता है जब आपको एक एंट्री पॉइंट चाहिए:
यदि आपकी प्राथमिकता समृद्ध HTTP हैंडलिंग है और आप वेब सर्विंग व रिवर्स प्रॉक्सी दोनों को मिलाना पसंद करते हैं, तो Nginx अक्सर डिफ़ॉल्ट प्रारंभिक विकल्प होता है।
HAProxy (High Availability Proxy) आमतौर पर एक रिवर्स प्रॉक्सी और लोड बैलेंसर के रूप में काम करता है जो एक या अधिक एप्लिकेशन सर्वरों के सामने बैठता है। यह इनकमिंग ट्रैफ़िक स्वीकार करता है, रूटिंग और ट्रैफ़िक नियम लागू करता है, और अनुरोधों को हेल्दी बैकएंड्स पर फॉरवर्ड करता है—अक्सर भारी concurrency के दौरान प्रतिक्रिया समय स्थिर रखते हुए।
टीमें सामान्यतः HAProxy को ट्रैफ़िक मैनेजमेंट के लिए डिप्लॉय करती हैं: अनुरोधों को फैलाना, विफलताओं के दौरान सेवाओं को उपलब्ध रखना, और ट्रैफ़िक स्पाइक्स को स्मूद करना। यह अक्सर सर्विस के "एज" (north–south ट्रैफ़िक) पर चुना जाता है और आंतरिक सेवाओं (east–west) के बीच भी तब उपयोग किया जाता है, खासकर जब आपको प्रत्याशित व्यवहार और कनेक्शन हैंडलिंग पर मजबूत नियंत्रण चाहिए।
HAProxy कई concurrent connections को कुशलता से हैंडल करने के लिए जाना जाता है। यह तब महत्वपूर्ण होता है जब आपके पास एक साथ कई क्लाइंट्स जुड़े हों (व्यस्त APIs, लंबी-जीवित कनेक्शंस, चैटी माइक्रोसर्विसेज) और आप चाहते हैं कि प्रॉक्सी प्रतिक्रियाशील बना रहे।
इसके लोड बैलेंसिंग क्षमताएँ एक बड़ा कारण हैं कि लोग इसे चुनते हैं। साधारण round-robin से परे, यह कई एल्गोरिथ्म और रूटिंग रणनीतियाँ सपोर्ट करता है जो मदद करती हैं:
हेल्थ चेक्स भी एक मजबूत बिंदु हैं। HAProxy सक्रिय रूप से बैकएंड की जाँच कर सकता है और अस्वस्थ इंस्टैंसों को रोटेशन से हटाकर, जब वे पुनर्प्राप्त हों तो फिर से जोड़ सकता है। व्यवहार में, इससे डाउनटाइम कम होता है और "आधा-टूटा" डिप्लॉयमेंट सभी उपयोगकर्ताओं को प्रभावित नहीं करते।
HAProxy Layer 4 (TCP) और Layer 7 (HTTP) दोनों पर काम कर सकता है।
व्यावहारिक अंतर: L4 सामान्यतः सरल और बहुत तेज़ है TCP फॉरवर्डिंग के लिए, जबकि L7 समृद्ध रूटिंग और अनुरोध लॉजिक देता है जब आपको इसकी ज़रूरत हो।
HAProxy अक्सर चुना जाता है जब प्राथमिक लक्ष्य भरोसेमंद, उच्च-प्रदर्शन लोड बैलेंसिंग और मजबूत हेल्थ चेकिंग हो—उदाहरण के लिए, API ट्रैफ़िक को कई ऐप सर्वरों में वितरित करना, उपलब्धता ज़ोन के बीच फेलओवर प्रबंधित करना, या ऐसी सेवाओं का फ़्रंट-एंड बनाना जहाँ कनेक्शन वॉल्यूम और प्रत्याशित ट्रैफ़िक व्यवहार वेब-सर्वर सुविधाओं से ज़्यादा मायने रखता हो।
प्रदर्शन की तुलना अक्सर गलत हो जाती है क्योंकि लोग एकल संख्या (जैसे "मैक्स RPS") को देखते हैं और उपयोगकर्ता अनुभव पर पड़ने वाले प्रभावों की अनदेखी कर देते हैं।
एक प्रॉक्सी थ्रूपुट बढ़ा सकता है जबकि टेल लेटेंसी बदतर कर सकता है अगर वह लोड के दौरान बहुत काम को कतारबद्ध कर देता है।
अपने एप्लिकेशन के "आकार" के बारे में सोचें:
यदि आप किसी पैटर्न के साथ बेंचमार्क करते हैं लेकिन दूसरे पैटर्न के साथ डिप्लॉय करते हैं, तो परिणाम लागू नहीं होंगे।
बफ़रिंग मदद कर सकती है जब क्लाइंट्स धीरे-धीरे भेजते हैं या बर्स्ट हुए हों, क्योंकि प्रॉक्सी अनुरोध (या रिस्पॉन्स) को पूरा पढ़कर आपके ऐप को अधिक स्थिर गति दे सकता है।
बफ़रिंग तब हानिकारक हो सकती है जब आपका ऐप स्ट्रीमिंग से लाभ उठाता है (server-sent events, बड़े डाउनलोड, रियल-टाइम APIs)। अतिरिक्त बफ़रिंग मेमोरी दबाव बढ़ाती है और टेल लेटेंसी बढ़ा सकती है।
"मैक्स RPS" से ज़्यादा मापें:
यदि p95 तेजी से बढ़ता है जबकि एरर नहीं आ रहे, तो आप संतृप्ति के शुरुआती चेतावनी संकेत देख रहे हैं—यह "फ्री हेडरूम" नहीं है।
Nginx और HAProxy दोनों कई एप्लिकेशन इंस्टैंसों के आगे बैठकर ट्रैफ़िक फैलाने में सक्षम हैं, पर वे डिफ़ॉल्ट रूप से अपने लोड-बैलेंसिंग फीचर सेट में गहराई के मामले में भिन्न हैं।
Round-robin तब अच्छा है जब आपके बैकएंड समान हों (एक जैसे CPU/मेमोरी, एक जैसी अनुरोध लागत)। यह सरल, प्रत्याशित है, और stateless ऐप्स के लिए अच्छा काम करता है।
Least connections तब उपयोगी है जब अनुरोध अवधि बदलती हो (फाइल डाउनलोड, लंबे API कॉल, चैट/वेबसोकेट प्रकार के वर्कलोड)। यह धीमे सर्वरों को ओवरलोड होने से रोकने में मदद करता है क्योंकि यह कम सक्रिय अनुरोध संभाल रहे बैकेंड को प्राथमिकता देता है।
Weighted balancing (वेटेड राउंड-रॉबिन, या वेटेड लीस्ट कनेक्शंस) व्यावहारिक विकल्प है जब सर्वर समान नहीं हैं—पुराने और नए नोड्स का मिश्रण, अलग instance साइज, या माइग्रेशन के दौरान धीरे-धीरे ट्रैफ़िक शिफ्ट करना।
सामान्य तौर पर, HAProxy और अधिक एल्गोरिथ्म और सूक्ष्म नियंत्रण प्रदान करता है Layer 4/7 पर, जबकि Nginx सामान्य मामलों को साफ़-सुथरे तरीके से कवर करता है (और एडिशन/मॉड्यूल के आधार पर विस्तारित किया जा सकता है)।
Stickiness यूज़र को लगातार उसी बैकएंड पर भेजता है:
जब तक ज़रूरी न हो परसिस्टेंस का उपयोग न करें: legacy server-side sessions के अलावा stateless ऐप्स बेहतर scale और recover करते हैं।
Active health checks बैकेंड्स को नियमित रूप से probe करते हैं (HTTP endpoint, TCP connect, अपेक्षित स्टेटस)। वे तब भी विफलताओं का पता लगा लेते हैं जब ट्रैफ़िक कम हो।
Passive health checks वास्तविक ट्रैफ़िक पर प्रतिक्रिया करते हैं: टाइमआउट, कनेक्शन त्रुटियाँ, या खराब रिस्पॉन्स सर्वर को अस्वस्थ के रूप में चिह्नित करते हैं। वे हल्के होते हैं पर समस्याओं का पता लगाने में अधिक समय लगा सकते हैं।
HAProxy को अक्सर समृद्ध हेल्थ-चेक और फेलियर-हैंडलिंग नियंत्रणों के लिए जाना जाता है (थ्रेशोल्ड, rise/fall काउंट्स, विस्तृत चेक)। Nginx भी ठोस चेक्स सपोर्ट करता है, लेकिन क्षमताएँ बिल्ड और एडिशन पर निर्भर करती हैं।
रोलिंग डिप्लॉय्स के लिए देखें:
जो भी आप चुनें, ड्रेनिंग को छोटे, स्पष्ट timeouts और एक स्पष्ट "ready/unready" हेल्थ endpoint के साथ जोड़ें ताकि डिप्लॉय्स के दौरान ट्रैफ़िक स्मूदली शिफ्ट हो।
रिवर्स प्रॉक्सीज़ आपके सिस्टम के एज पर बैठते हैं, इसलिए प्रोटोकॉल और TLS विकल्प ब्राउज़र प्रदर्शन से लेकर सेवाओं के आपसी संवाद तक सब कुछ प्रभावित करते हैं।
दोनों Nginx और HAProxy TLS "terminate" कर सकते हैं: वे क्लाइंट से इनक्रिप्टेड कनेक्शंस स्वीकार करते हैं, ट्रैफ़िक डिक्रिप्ट करते हैं, और फिर रिक्वेस्ट को आपके ऐप्स पर HTTP या रिइन्क्रिप्टेड TLS के रूप में फॉरवर्ड करते हैं।
ऑपरेशनल वास्तविकता है सर्टिफिकेट मैनेजमेंट। आपको योजना चाहिए:
जब TLS टर्मिनेशन वेब-सर्वर सुविधाओं के साथ जोड़ा जाता है तो Nginx अक्सर चुना जाता है। जब TLS मुख्य रूप से ट्रैफ़िक-मैनेजमेंट लेयर का हिस्सा हो तो HAProxy आम चुनाव होता है।
HTTP/2 ब्राउज़रों के लिए पेज लोड समय कम कर सकता है क्योंकि यह एक ही कनेक्शन पर कई अनुरोध multiplex करता है। दोनों टूल क्लाइंट-फेसिंग साइड पर HTTP/2 सपोर्ट करते हैं।
मुख्य विचार:
यदि आपको नॉन-HTTP ट्रैफ़िक रूट करना है (डेटाबेस, SMTP, Redis, कस्टम प्रोटोकॉल), तो आपको HTTP राउटिंग की बजाय TCP प्रॉक्सिंग चाहिए। HAProxy उच्च-प्रदर्शन TCP लोड बैलेंसिंग के लिए व्यापक रूप से उपयोग होता है। Nginx भी TCP प्रॉक्सी कर सकता है (अपने stream capability के माध्यम से), जो सीधे-पास के सेटअप्स के लिए पर्याप्त हो सकता है।
mTLS दोनों पक्षों की सत्यापन करता है: क्लाइंट्स भी सर्टिफिकेट प्रस्तुत करते हैं, सिर्फ सर्वर नहीं। यह सेवा-से-सेवा संचार, पार्टनर इंटीग्रेशन, या ज़ीरो‑ट्रस्ट डिज़ाइनों के लिए उपयुक्त है। कोई भी प्रॉक्सी एज पर client cert validation लागू कर सकता है, और कई टीमें आंतरिक रूप से भी mTLS का उपयोग करती हैं ताकि "विश्वसनीय नेटवर्क" मान्यताओं को कम किया जा सके।
रिवर्स प्रॉक्सी हर अनुरोध के बीच में बैठता है, इसलिए अक्सर यह जवाब देने के लिए सबसे अच्छा स्थान होता है—"क्या हुआ?" अच्छी ऑब्ज़रवेबिलिटी का मतलब है सुसंगत लॉग्स, उच्च-सिग्नल मीट्रिक्स का छोटा सेट, और टाइमआउट्स व गेटवे त्रुटियों को डिबग करने का एक दोहराने योग्य तरीका।
प्रोडक्शन में कम से कम access logs और error logs सक्षम रखें। एक्सेस लॉग में अपस्ट्रीम टाइमिंग शामिल करें ताकि आप बता सकें कि सुस्ती प्रॉक्सी की वजह से थी या एप्लिकेशन की।
Nginx में सामान्य फ़ील्ड्स हैं request time और upstream timing (उदा., $request_time, $upstream_response_time, $upstream_status)। HAProxy में HTTP log मोड सक्षम करें और timing फ़ील्ड्स कैप्चर करें (queue/connect/response times) ताकि आप "बैकएंड स्लॉट के लिए प्रतीक्षा" और "बैकएंड धीमा था" को अलग कर सकें।
लॉग्स को संरचित रखें (संभव हो तो JSON) और एक request ID जोड़ें (इनकमिंग हेडर से या जेनरेट किया हुआ) ताकि आप प्रॉक्सी लॉग्स को ऐप लॉग्स के साथ correlate कर सकें।
चाहे आप Prometheus scrape करें या मीट्रिक्स कहीं और भेजें, एक सुसंगत सेट एक्सपोर्ट करें:
Nginx अक्सर stub status endpoint या Prometheus exporter का उपयोग करता है; HAProxy में बिल्ट‑इन stats endpoint होता है जिसे कई exporters पढ़ते हैं।
एक हल्का-weight /health (प्रोसेस चल रहा है) और /ready (निर्भरता तक पहुँच सकती है) एंडपॉइंट एक्सपोज़ करें। ऑटोमेशन में दोनों का उपयोग करें: लोड बैलेंसर हेल्थ चेक्स, डिप्लॉयमेंट्स, और ऑटो‑स्केलिंग निर्णयों के लिए।
ट्रबलशूटिंग के दौरान प्रॉक्सी की timing (connect/queue) की तुलना upstream response time से करें। यदि connect/queue उच्च है, तो क्षमता बढ़ाएँ या लोड-बैलेंसिंग समायोजित करें; यदि upstream time उच्च है, तो ऐप और DB पर ध्यान दें।
रिवर्स प्रॉक्सी चलाना केवल पीक थ्रूपुट का मामला नहीं है—यह भी मायने रखता है कि आपकी टीम 2pm (या 2am) पर कितनी जल्दी सुरक्षित बदलाव कर सकती है।
Nginx कॉन्फ़िग निर्देश-आधारित और हायरार्किकल है। यह "ब्लॉक्स के अंदर ब्लॉक्स" पढ़ता है (http → server → location), जिसे कई लोग साइट्स और रूट्स के संदर्भ में सहज आंकते हैं।
HAProxy कॉन्फ़िग अधिक "पाइपलाइन-जैसा" है: आप frontends (क्या स्वीकार करें) और backends (कहाँ भेजें) परिभाषित करते हैं, और फिर ACLs (नियम) लगाकर दोनों को जोड़ते हैं। यह मॉडल एक बार आंतरिक हो जाने पर अधिक स्पष्ट और प्रत्याशित महसूस कराता है, खासकर ट्रैफ़िक रूटिंग लॉजिक के लिए।
Nginx आमतौर पर कॉन्फ़िग reload करके नए वर्कर्स स्टार्ट करता है और पुराने को graceful तरीके से ड्रेन करता है। यह अक्सर बार-बार रूट अपडेट और सर्टिफिकेट नवीनीकरण के लिए अनुकूल है।
HAProxy भी seamless reloads कर सकता है, पर टीमें इसे अक्सर एक "अप्लायंस" की तरह संभालती हैं: कड़े बदलाव नियंत्रण, वर्शनड कॉन्फ़िग, और reload कमांड के आसपास सावधानीपूर्वक समन्वय।
दोनों reload से पहले कॉन्फ़िग टेस्टिंग सपोर्ट करते हैं (CI/CD में अनिवार्य)। व्यवहार में, आप संभवतः कॉन्फ़िग्स को DRY रखेंगे और उन्हें जेनरेट करेंगे:
मुख्य ऑपरेशनल आदत: प्रॉक्सी कॉन्फ़िग को कोड की तरह मानें—reviewed, tested, और application changes की तरह deploy करें।
जैसे‑जैसे सेवाओं की संख्या बढ़ती है, सर्टिफिकेट और रूटिंग का फैलाव वास्तविक दर्द बन जाता है। योजना बनाएं:
यदि आप सैकड़ों होस्ट की उम्मीद करते हैं, तो कॉन्फ़िग्स को मैन्युअली संपादित करने के बजाय सर्विस मेटाडेटा से जनरेट करने पर विचार करें।
यदि आप कई सेवाएँ बना रहे और iterate कर रहे हैं, तो रिवर्स प्रॉक्सी केवल delivery pipeline का एक हिस्सा है—आपको फिर भी दोहराए जाने योग्य ऐप स्कैफोल्डिंग, environment parity, और सुरक्षित रोलआउट्स चाहिए।
Koder.ai टीमों को तेजी से आइडिया से चल रही सेवाओं तक पहुँचने में मदद कर सकता है—यह chat‑आधारित वर्कफ़्लो के माध्यम से React वेब ऐप्स, Go + PostgreSQL बैकएंड्स, और Flutter मोबाइल ऐप्स जेनरेट करता है, फिर source code export, deployment/hosting, custom domains, और snapshots with rollback सपोर्ट करता है। व्यवहार में, आप एक API + वेब फ्रंटेंड प्रोटोटाइप कर सकते हैं, उसे डिप्लॉय कर सकते हैं, और फिर असली ट्रैफ़िक पैटर्न देखकर निर्णय ले सकते हैं कि Nginx या HAProxy कौन‑सा 'फ्रंट डोर' बेहतर है—अनुमान के बजाय वास्तविकता के आधार पर।
सुरक्षा शायद किसी "मैजिक" फ़ीचर का मामला नहीं है—यह blast radius कम करने और ट्रैफ़िक पर डिफ़ॉल्ट रूप से कड़े नियम लागू करने के बारे में है जिसे आप पूरी तरह नियंत्रित नहीं करते।
प्रॉक्सी को जितना संभव हो न्यूनतम विशेषाधिकार के साथ चलाएँ: Linux पर capabilities के माध्यम से privileged ports bind करें या एक fronting service उपयोग करें, और worker processes को बिना विशेषाधिकार वाले रखें। कॉन्फ़िग और key material (TLS private keys, DH params) को सर्विस अकाउंट द्वारा read-only रखें।
नेटवर्क पर, केवल अपेक्षित स्रोतों से इनबाउंड की अनुमति दें (इंटरनेट → प्रॉक्सी; प्रॉक्सी → बैकएंड)। जब संभव हो बैकएंड्स तक डायरेक्ट एक्सेस रोकें, ताकि प्रॉक्सी authentication, rate limits, और logging के लिए सिंगल चोक पॉइंट बने।
Nginx में limit_req / limit_conn जैसे प्रथम-श्रेणी प्रिमिटिव्स होते हैं। HAProxy आमतौर पर stick tables का उपयोग करता है ताकि request rates, concurrent connections, या error पैटर्न ट्रैक कर के अभद्र क्लाइंट्स को deny, tarp, या slow down किया जा सके।
आपके थ्रेट मॉडल के अनुरूप एक दृष्टिकोण चुनें:
X-Forwarded-For, Host)यह स्पष्ट रखें कि आप किन हेडर्स पर भरोसा करते हैं। केवल ज्ञात upstreams से X-Forwarded-For (और संबंधित) स्वीकार करें; अन्यथा attackers क्लाइंट IP spoof करके IP-आधारित नियंत्रण को बायपास कर सकते हैं। इसी तरह, host-header आक्रमण और कैश पॉयज़निंग से बचने के लिए Host को validate या सेट करें।
एक सरल नियम: प्रॉक्सी forwarding headers सेट करे, उन्हें अंधाधुंध पास न करे।
Request smuggling अक्सर अस्पष्ट पार्सिंग का फायदा उठाता है (conflicting Content-Length / Transfer-Encoding, अजीब whitespace, या अमान्य हेडर फॉर्मेट)। कड़े HTTP पार्सिंग मोड पसंद करें, malformed headers reject करें, और संरक्षित सीमाएँ सेट करें:
Connection, Upgrade, और hop-by-hop हेडर्स के लिए स्पष्ट हैंडलिंगइन नियंत्रणों का सिन्टेक्स Nginx और HAProxy में अलग होगा, पर परिणाम समान होना चाहिए: अस्पष्टता पर fail‑closed और सीमाएँ स्पष्ट रखना।
रिवर्स प्रॉक्सी आमतौर पर दो तरीकों में पेश होते हैं: एकल एप्लिकेशन के लिए समर्पित फ्रंट-डोर या कई सेवाओं के आगे साझा गेटवे। दोनों Nginx और HAProxy यह कर सकते हैं—महत्वपूर्ण यह है कि एज पर कितनी रूटिंग लॉजिक चाहिए और आप इसे रोज़मर्रा कैसे ऑपरेट करना चाहते हैं।
यह पैटर्न रिवर्स प्रॉक्सी को सीधे एक वेब ऐप (या कुछ तादात्म्य वाली सेवाओं) के सामने रखता है। यह तब अच्छा फिट होता है जब आपको मुख्यतः TLS टर्मिनेशन, HTTP/2, कंप्रेशन, कॅशिंग (Nginx के साथ), या सार्वजनिक इंटरनेट और निजी ऐप के बीच साफ़ अलगाव चाहिए।
इसे उपयोग करें जब:
यहाँ एक (या छोटे क्लस्टर) प्रॉक्सी कई एप्लिकेशन्स को होस्टनेम, पाथ, हेडर, या अन्य अनुरोध गुणों के आधार पर रूट करते हैं। यह सार्वजनिक एंट्री पॉइंट्स की संख्या कम करता है पर साफ़ कॉन्फ़िग प्रबंधन और परिवर्तन नियंत्रण का महत्व बढ़ा देता है।
इसे उपयोग करें जब:
app1.example.com, app2.example.com) और एक सिंगल ingress परत चाहते हैं।प्रॉक्सी ट्रैफ़िक को "पुराने" और "नए" संस्करणों के बीच बिना DNS बदले या एप्लिकेशन को बदले विभाजित कर सकता है। सामान्य तरीका दो अपस्ट्रीम पूल (blue और green) या दो बैकएंड (v1 और v2) परिभाषित करना और ट्रैफ़िक को धीरे-धीरे शिफ्ट करना है।
सामान्य उपयोग:
यह तब बहुत उपयोगी है जब आपकी डिप्लॉयमेंट टूलिंग weighted rollouts नहीं कर पाती, या जब आप टीमों के बीच एक सुसंगत rollout मेकैनिज़्म चाहते हैं।
एक सिंगल प्रॉक्सी एक single point of failure है। सामान्य HA पैटर्न में शामिल हैं:
अपने वातावरण के आधार पर चुनें: पारंपरिक VMs/bare metal पर VRRP लोकप्रिय है; क्लाउड में managed load balancers अक्सर सबसे सरल होते हैं।
एक सामान्य "फ्रंट‑टू‑बैक" चेन है: CDN (वैकल्पिक) → WAF (वैकल्पिक) → रिवर्स प्रॉक्सी → एप्लिकेशन।
यदि आप पहले से CDN/WAF का उपयोग कर रहे हैं, तो प्रॉक्सी को एप्लिकेशन डिलीवरी और रूटिंग पर केंद्रित रखें बजाय इसके कि यह आपका एकमात्र सुरक्षा परत बन जाए।
कुबेरनेट्स यह बदल देता है कि आप ऐप्स को कैसे "फ्रंट" करते हैं: सेवाएँ अस्थायी हैं, IP बदलते हैं, और रूटिंग निर्णय अक्सर क्लस्टर के एज पर Ingress controller के माध्यम से होते हैं। दोनों Nginx और HAProxy यहाँ अच्छी तरह फिट हो सकते हैं, पर वे थोड़े अलग रोल में चमकते हैं।
व्यवहार में, निर्णय अक्सर "कौन बेहतर है" नहीं, बल्कि "कौन आपके ट्रैफ़िक पैटर्न और एज पर आवश्यक HTTP हेरफेर से मेल खाता है" होता है।
यदि आप सर्विस मेष चला रहे हैं (उदा., आंतरिक mTLS और ट्रैफ़िक नीतियाँ), तब भी आप Nginx/HAProxy को perimeter पर north–south ट्रैफ़िक के लिए रख सकते हैं (इंटरनेट → क्लस्टर)। मेष east–west ट्रैफ़िक संभालेगा। यह विभाजन एज चिंताओं (TLS टर्मिनेशन, WAF/rate limiting, बुनियादी राउटिंग) को आंतरिक विश्वसनीयता सुविधाओं (retries, circuit breaking) से अलग रखता है।
gRPC और लंबी-जीवित कनेक्शंस शॉर्ट HTTP अनुरोधों से प्रॉक्सीज़ को अलग तरह से तनाव देते हैं। देखें:
जो भी आप चुनें, वास्तविक अवधि (मिनट/घंटे) के साथ टेस्ट करें, सिर्फ quick smoke tests नहीं।
प्रॉक्सी कॉन्फ़िग को कोड की तरह रखें: इसे Git में रखें, परिवर्तन CI में validate करें (linting, config test), और CD के माध्यम से controlled deployments (canary या blue/green) से रोलआउट करें। यह upgrades को सुरक्षित बनाता है और जब कोई रूटिंग या TLS परिवर्तन प्रोडक्शन पर असर डाले तो आपको ऑडिट ट्रेल देता है।
सबसे तेज़ तरीका यह है कि आप यह तय करें कि प्रॉक्सी दिन‑प्रतिदिन क्या करने वाला है: कंटेंट सर्व करना, HTTP ट्रैफ़िक आकार देना, या सख्त कनेक्शन और बैलेंसिंग लॉजिक प्रबंधित करना।
यदि आपका रिवर्स प्रॉक्सी वेब ट्रैफ़िक के लिए "फ्रंट डोर" भी होगा, तो Nginx अक्सर अधिक सुविधाजनक डिफ़ॉल्ट है:
यदि प्राथमिकता है सटीक ट्रैफ़िक वितरण और लोड के तहत सख़्त नियंत्रण, तो HAProxy बेहतर महसूस होता है:
दोनों का उपयोग सामान्य है जब आप चाहते हैं वेब‑सर्वर सुविधाएँ और विशेषीकृत बैलेंसिंग:
यह विभाजन टीमों को ज़िम्मेदारियाँ अलग करने में भी मदद कर सकता है: वेब‑संबंधी चिंताएँ बनाम ट्रैफ़िक इंजीनियरिंग।
खुद से पूछें:
A reverse proxy आपके एप्लिकेशन्स के सामने बैठता है: क्लाइंट proxy से जुड़ते हैं, और proxy सही बैकएंड सर्विस को requests भेजकर response वापस क्लाइंट को देता है।
A forward proxy क्लाइंट्स के सामने बैठता है और उनके आउटबाउंड इंटरनेट अनुरोधों को नियंत्रित करता है (कॉर्पोरेट नेटवर्क में आम)।
एक load balancer का फोकस कई बैकएंड इंस्टैंसों के बीच ट्रैफ़िक वितरित करना होता है। कई load balancers को reverse proxy के रूप में लागू किया जाता है, इसलिए दोनों शब्द अक्सर ओवरलैप करते हैं।
व्यवहार में, आप अक्सर एक ही टूल (जैसे Nginx या HAProxy) से reverse proxying और load balancing दोनों करते हैं।
इसे उस सीमा पर रखें जहाँ आप एक सिंगल नियंत्रण बिंदु चाहते हैं:
मुख्य बात: बैकएंड्स को सीधे क्लाइंट से जुड़ने न दें ताकि proxy नीति और विज़िबिलिटी का choke point बने रहे।
TLS/SSL टर्मिनेशन का मतलब है कि proxy HTTPS संभालता है: यह एन्क्रिप्टेड क्लाइंट कनेक्शन स्वीकार करता है, उन्हें डिक्रिप्ट करता है, और ट्रैफ़िक को आपस्ट्रीम पर HTTP या फिर से एन्क्रिप्टेड TLS के रूप में फॉरवर्ड करता है।
ऑपरेशनल तौर पर आपको योजना बनानी होगी:
जब आपका प्रॉक्सी वेब "फ्रंट डोर" के रूप में भी काम कर रहा हो तो Nginx चुनें:
जब ट्रैफिक मैनेजमेंट और लोड के तहत प्रेडिक्टेबिलिटी प्राथमिकता हो तो HAProxy चुनें:
समान बैकएंड्स और सामान्य अनुरोध लागत के लिए round-robin इस्तेमाल करें।
जब अनुरोधों की अवधि बदलती हो (डाउनलोड, लंबे API कॉल, लम्बी कनेक्शन वाली सर्विस) तो least connections उपयोगी है, ताकि धीमे इंस्टैंसों को ओवरलोड न किया जाये।
जब बैकएंड अलग हों (विभिन्न instance आकार, मिश्रित हार्डवेयर, चरणबद्ध माइग्रेशन) तो weighted वेरिएंट इस्तेमाल करें, ताकि आप ट्रैफ़िक को जानबूझकर शिफ्ट कर सकें।
Stickiness उपयोगकर्ता को लगातार एक ही बैकएंड पर रूट करने के लिए होती है।
यदि संभव हो तो stickiness से बचें: stateless सेवाएँ अधिक बेहतर स्केल और फेलओवर करती हैं।
बफरिंग धीमे या बर्स्टरी क्लाइंट्स के लिए मदद कर सकता है ताकि आपका ऐप अधिक स्थिर गति पर काम करे।
यह तब हानिकारक हो सकता है जब आपको स्ट्रीमिंग व्यवहार चाहिए (SSE, WebSockets, बड़े डाउनलोड), क्योंकि अतिरिक्त बफरिंग मेमोरी दबाव बढ़ाती है और tail latency बढ़ा सकती है।
यदि आपकी ऐप स्ट्रीम-ओरिएंटेड है, तो डिफ़ॉल्ट पर भरोसा न करें—टेस्ट और ट्यून करें।
शुरू में प्रॉक्सी देरी को बैकएंड देरी से अलग करें—लॉग्स/मेट्रिक्स देखें।
सामान्य अर्थ:
मूल संकेत जो तुलना करने चाहिए:
सुधार अक्सर timeouts समायोजित करने, बैकएंड क्षमता बढ़ाने, या हेल्थ चेक/ready endpoints बेहतर करने से होते हैं।