07 अग॰ 2025·8 मिनट
नोआम शेज़र और LLMs के पीछे का ट्रांसफॉर्मर आर्किटेक्चर
जानें कि नोआम शेज़र ने ट्रांसफॉर्मर को कैसे आकार दिया: self-attention, multi-head attention, और क्यों यह डिज़ाइन आधुनिक LLMs की रीढ़ बन गया।
जानें कि नोआम शेज़र ने ट्रांसफॉर्मर को कैसे आकार दिया: self-attention, multi-head attention, और क्यों यह डिज़ाइन आधुनिक LLMs की रीढ़ बन गया।
एक ट्रांसफॉर्मर कंप्यूटर को सिक्वेंस समझने में मदद करने का तरीका है—ऐसी चीज़ें जहाँ ऑर्डर और संदर्भ मायने रखते हैं, जैसे वाक्य, कोड, या खोज क्वेरीज़ की एक श्रृंखला। पुराने तरीके की तरह एक-एक टोकन पढ़ने और कमजोर मेमोरी आगे ले जाने के बजाय, ट्रांसफॉर्मर पूरे सिक्वेंस को देखता है और हर हिस्से की व्याख्या करते समय किस पर ध्यान देना चाहिए यह तय करता है।
यह सरल बदलाव बड़ा फर्क साबित हुआ। यही वजह है कि आधुनिक लार्ज लैंग्वेज मॉडल (LLMs) संदर्भ बनाए रख पाते हैं, निर्देशों का पालन करते हैं, सुसंगत पैराग्राफ लिखते हैं, और ऐसे कोड जेनरेट कर पाते हैं जो पहले दी गई फ़ंक्शन्स और वेरिएबल्स का संदर्भ देते हैं।
अगर आपने कभी चैटबोट, “इसे सारांशित करें” फीचर, सेमांटिक सर्च, या कोडिंग असिस्टेंट इस्तेमाल किया है, तो आपने ट्रांसफॉर्मर-आधारित सिस्टम का उपयोग किया है। वही मूल ब्लूप्रिंट समर्थन करता है:
हम मुख्य हिस्सों—self-attention, multi-head attention, positional encoding, और बेसिक ट्रांसफॉर्मर ब्लॉक—को तोड़कर समझाएँगे और बताएँगे कि यह डिज़ाइन बड़े मॉडल्स के साथ इतना अच्छा क्यों स्केल करता है।
हम आधुनिक वैरिएंट्स पर भी संक्षेप में चर्चा करेंगे जो उसी मूल विचार को बनाए रखते हैं पर गति, लागत, या लंबी कॉन्टेक्स्ट विंडो के लिए ट्वीक करते हैं।
यह एक उच्च-स्तरीय टूर है जिसमें सादा-भाषा वाले स्पष्टीकरण और न्यूनतम गणित होगा। लक्ष्य अंतर्ज्ञान बनाना है: किस हिस्से का क्या काम है, वे एक साथ क्यों काम करते हैं, और यह वास्तविक प्रोडक्ट क्षमताओं में कैसे बदलता है।
नोआम शेज़र एक AI रिसर्चर और इंजीनियर हैं, जिन्हें 2017 के पेपर “Attention Is All You Need” के सह-लेखक के रूप में सबसे अधिक पहचान मिली। उस पेपर ने ट्रांसफॉर्मर आर्किटेक्चर पेश किया, जो बाद में कई आधुनिक LLMs की नींव बन गया। शेज़र का योगदान टीम के साझा प्रयास का हिस्सा था: ट्रांसफॉर्मर गूगल की एक रिसर्च टीम द्वारा बनाया गया था, और इसे उसी तरह क्रेडिट देना महत्वपूर्ण है।
ट्रांसफॉर्मर से पहले, कई NLP सिस्टम रिकरेंट मॉडल्स पर निर्भर थे जो टेक्स्ट को कदम-दर-कदम प्रोसेस करते थे। ट्रांसफॉर्मर ने दिखाया कि आप बिना रिकरेंस के भी ध्यान को मुख्य मैकेनिज़्म बनाकर सिक्वेंस को प्रभावी ढंग से मॉडल कर सकते हैं।
यह बदलाव इसलिए महत्वपूर्ण था क्योंकि इससे ट्रेनिंग को पैरेलल करना आसान हुआ (आप एक समय में कई टोकन प्रोसेस कर सकते हैं), और इसने मॉडलों और डेटासेट्स को स्केल करने का रास्ता खोल दिया जो जल्दी ही वास्तविक उत्पादों के लिए व्यावहारिक बन गया।
शेज़र का योगदान—अन्य लेखकों के साथ—सिर्फ़ अकादमिक बेंचमार्क तक सीमित नहीं रहा। ट्रांसफॉर्मर एक रीयूजेबल मॉड्यूल बन गया जिसे टीमें अनुकूलित कर सकती हैं: कंपोनेंट्स बदलें, आकार बदलें, टास्क के लिए ट्यून करें, और बाद में बड़े पैमाने पर प्रीट्रेन करें।
यही तरीका है जिससे कई ब्रेकथ्रू चलते हैं: एक पेपर एक साफ़, सामान्य रेसिपी प्रस्तुत करता है; इंजीनियर उसे परिष्कृत करते हैं; कंपनियाँ उसे ऑपरेशनलाइज़ करती हैं; और अंत में यह भाषा फीचर्स बनाने के लिए एक डिफ़ॉल्ट विकल्प बन जाता है।
यह कहना सही होगा कि शेज़र एक प्रमुख योगदानकर्ता और ट्रांसफॉर्मर पेपर के सह-लेखक थे। यह गलत होगा कि उन्हें अकेला आविष्कारक बताया जाए। इस प्रभाव का श्रेय सामूहिक डिजाइन को जाता है—और उस मूल ब्लूप्रिंट पर समुदाय द्वारा किए गए कई बाद के सुधारों को भी।
ट्रांसफॉर्मर से पहले, अधिकांश सिक्वेंस समस्याओं (अनुवाद, भाषण, टेक्स्ट जनरेशन) पर Recurrent Neural Networks (RNNs) और बाद में LSTMs हावी थे। बड़ा विचार सरल था: टेक्स्ट को एक-एक करके पढ़ो, एक चलती “मेमोरी” (hidden state) रखो, और उसी से अगला शब्द भविष्यवाणि करो।
एक RNN वाक्य को एक चेन की तरह प्रोसेस करता है। हर स्टेप में hidden state को वर्तमान शब्द और पिछले hidden state के आधार पर अपडेट किया जाता है। LSTMs ने गेट्स जोड़े जो यह तय करते हैं कि क्या रखा जाए, क्या भुलाया जाए, और क्या आउटपुट किया जाए—जिससे उपयोगी संकेतों को लंबे समय तक थामे रखना आसान हुआ।
व्यवहार में, अनुक्रमिक मेमोरी में एक बॉटलनेक है: जैसे-जैसे वाक्य लंबा होता है, बहुत सी जानकारी को एक ही स्टेट में निचोड़ना पड़ता है। LSTMs के साथ भी, दूर के शब्दों से आने वाले सिग्नल फीके पड़ सकते हैं या ओवरराइट हो सकते हैं।
इससे कुछ रिश्ते भरोसेमंद तरीके से सीखना मुश्किल हो जाता था—जैसे किसी सर्वनाम को कई शब्द पहले सही संज्ञा से जोड़ना, या कई उपवाक्यों में किसी विषय को ट्रैक करना।
RNNs और LSTMs ट्रेनिंग में भी धीमे हैं क्योंकि वे समय पर पूरी तरह से पैरेललाइज़ नहीं हो सकते। आप अलग-अलग वाक्यों के ऊपर बैच कर सकते हैं, पर एक वाक्य के भीतर स्टेप 50 स्टेप 49 पर निर्भर करता है, जो स्टेप 48 पर निर्भर करता है—और इसी तरह।
जब आप बड़े मॉडल्स, अधिक डेटा और तेज़ प्रयोग चाहते हैं तो यह क्रमिक गणना एक गंभीर सीमा बन जाती है।
रिसर्चर्स को एक ऐसे डिज़ाइन की जरूरत थी जो शब्दों को एक-दूसरे से बिना कड़ाई से बायीं-से-दायीं तरीके से जोड़ सके—एक तरीका जो सीधे लंबी दूरी के रिश्तों को मॉडल करे और आधुनिक हार्डवेयर का बेहतर लाभ उठाए। इस दबाव ने Attention Is All You Need में पेश किए गए attention-फ़र्स्ट अप्रोच के लिए जगह बनाई।
Attention मॉडल का वह तरीका है जो पूछता है: “इस शब्द को समझने के लिए मुझे अभी कौन से अन्य शब्दों पर नज़र रखनी चाहिए?”
कठोर क्रम से पढ़ने और मेमोरी पर उम्मीद करने के बजाय, attention मॉडल को ज़रूरत पड़ने पर वाक्य के सबसे प्रासंगिक हिस्सों पर झांकने देता है।
एक उपयोगी मानसिक मॉडल यह है कि वाक्य के अंदर एक छोटा सर्च इंजन चल रहा है।
तो मॉडल वर्तमान पोजिशन के लिए एक क्वेरी बनाता है, सभी पोजिशन की कीज़ से इसकी तुलना करता है, और फिर वैल्यूज़ का एक मिश्रण पुनःप्राप्त करता है।
वे तुलना प्रासंगिकता स्कोर देती हैं: "यह कितना संबंधित है?" के संकेत। मॉडल इन्हें attention weights में बदलता है, जो 1 के बराबर जोड़ती हैं।
अगर एक शब्द बहुत प्रासंगिक है तो उसे मॉडल का बड़ा हिस्सा मिलता है। अगर कई शब्द मायने रखते हैं तो attention उन पर फैल सकती है।
लीजिए: “Maria told Jenna that she would call later.”
she की व्याख्या करने के लिए मॉडल को "Maria" और "Jenna" जैसे उम्मीदवारों की ओर देखना चाहिए। Attention उस नाम को अधिक वेट दे सकती है जो संदर्भ के अनुसार सही बैठता है।
या विचार करें: “The keys to the cabinet are missing.” Attention मदद करती है कि "are" को "cabinet" नहीं बल्कि "keys" से जोड़ा जाए—भले ही "cabinet" नज़दीक हो। यही मूल लाभ है: attention दूरी के पार अर्थ को जोड़ता है, जब ज़रूरी हो।
Self-attention का विचार यह है कि सिक्वेंस का हर टोकन उसी सिक्वेंस के अन्य टोकन्स को देख सकता है यह तय करने के लिए कि अभी क्या मायने रखता है। पुराने रिकरेंट मॉडल्स की तरह बाएँ-से-दाएँ क्रमिक प्रोसेस करने के बजाय, ट्रांसफॉर्मर हर टोकन को इनपुट के किसी भी हिस्से से संकेत इकट्ठा करने देता है।
कल्पना कीजिए वाक्य: “I poured the water into the cup because it was empty.” शब्द “it” को "cup" के साथ जोड़ना चाहिए, न कि "water" के साथ। self-attention में, "it" टोकन उन टोकन्स को उच्च महत्व देता है जो उसके अर्थ को हल करने में मदद करते हैं ("cup", "empty") और अप्रासंगिक वाले को कम दे देता है।
self-attention के बाद, हर टोकन अब केवल खुद नहीं रहता। वह एक संदर्भ-जागरूक संस्करण बन जाता है—बाकी टोकन्स से जानकारी का एक वेटेड मिश्रण। आप इसे इस तरह सोच सकते हैं कि हर टोकन पूरे वाक्य का एक व्यक्तिगत सारांश बनाता है, जो उस टोकन की ज़रूरत के अनुसार ट्यून होता है।
व्यवहार में, इसका मतलब है कि "cup" का प्रतिनिधित्व "poured", "water", और "empty" से संकेत ले सकता है, जबकि "empty" वही बता सकता है जिसे वह वर्णित कर रहा है।
क्योंकि हर टोकन एक ही समय में पूरे सिक्वेंस पर अपना attention कैलकुलेट कर सकता है, ट्रेनिंग को पिछली टोकन्स के क्रमशः प्रोसेस होने का इंतज़ार नहीं करना पड़ता। यह पैरेलल प्रोसेसिंग एक मुख्य वजह है कि ट्रांसफॉर्मर्स बड़े डेटासेट पर कुशलतापूर्वक ट्रेन करते हैं और विशाल मॉडलों तक स्केल करते हैं।
Self-attention दूर-दराज के टेक्स्ट हिस्सों को जोड़ना आसान कर देता है। एक टोकन सीधे किसी दूरवर्ती प्रासंगिक शब्द पर फोकस कर सकता है—बिना जानकारी को कई मध्यवर्ती स्टेप्स के जरिए पास किए।
यह कोरेफ़रेंस, कई पैरा के पार विषय ट्रैकिंग, और पहले बताई गई निर्देशों पर आधारित टास्क में मदद करता है।
एक सिंगल attention मैकेनिज़्म शक्तिशाली है, पर यह ऐसे समझने जैसा हो सकता है जैसे एक ही कैमरा कोण से बातचीत देखना। वाक्यों में अक्सर एक साथ कई रिश्ते होते हैं: किसने क्या किया, "it" किसे संदर्भित करता है, कौन से शब्द टोन सेट करते हैं, और कुल मिलाकर विषय क्या है।
जब आप पढ़ते हैं “The trophy didn’t fit in the suitcase because it was too small,” आपको एक साथ कई सुराग ट्रैक करने पड़ सकते हैं (व्याकरण, अर्थ, वास्तविक-जगत संदर्भ)। एक attention "व्यू" निकटतम संज्ञा पर फ़िक्स हो सकता है; दूसरा क्रिया-वाक्यांश का उपयोग कर सकता है यह तय करने के लिए कि "it" किसे संदर्भित करता है।
Multi-head attention कई attention कैलकुलेशन्स को पैरेलल में चलाता है। हर "हेड" वाक्य को अलग लेंस से देखने के लिए प्रेरित होता है—अक्सर उन्हें अलग सबस्पेस कहा जाता है। व्यवहार में, हेड्स विभिन्न पैटर्नों में विशेषज्ञता कर सकते हैं, जैसे:
हर हेड अपनी इनसाइट्स देता है; मॉडल एक को चुनता नहीं है। यह हेड आउटपुट्स को concatenate करता है (बगल में स्टैक करता है) और फिर उन्हें एक लीनियर लेयर से मुख्य वर्किंग स्पेस में प्रोजेक्ट करता है।
इसे कई आंशिक नोट्स को एक साफ सार में मिलाने जैसा सोचें ताकि अगली लेयर उसका उपयोग कर सके। नतीजा एक ऐसा प्रतिनिधित्व है जो एक साथ कई रिश्तों को पकड़ सकता है—यही कारण है कि ट्रांसफॉर्मर्स स्केल पर इतने अच्छे काम करते हैं।
Self-attention रिश्तों की पहचान में माहिर है—पर अपने आप यह नहीं जानता कि कौन पहले आया। अगर आप शब्दों को शफल कर दें तो एक सादा self-attention लेयर शफल किए हुए वर्शन को समान मान सकता है क्योंकि वह टोकन्स की तुलना बिना पोजिशन जानकारी के करता है।
Positional encoding इस समस्या को हल करता है: यह टोकन प्रतिनिधित्वों में "मैं सिक्वेंस में कहां हूँ" जानकारी जोड़ता है। एक बार पोजिशन जुड़ जाने पर, attention पैटर्न सीख सकता है जैसे "not के ठीक बाद आने वाला शब्द बहुत मायने रखता है" या "विषय आमतौर पर क्रिया से पहले आता है"—बिना क्रम को फिर से सेहीफ से सीखने के।
मूल विचार सरल है: प्रत्येक टोकन एम्बेडिंग को ट्रांसफॉर्मर ब्लॉक में जाने से पहले पोजिशन सिग्नल के साथ जोड़ा जाता है। वह पोजिशन सिग्नल एक अतिरिक्त फीचर सेट की तरह सोचा जा सकता है जो टोकन को इनपुट में 1st, 2nd, 3rd… आदि के रूप में टैग करता है।
कुछ सामान्य दृष्टिकोण:
पोज़िशनल विकल्प लंबी-कॉन्टेक्स्ट मॉडलिंग को प्रभावित कर सकते हैं—जैसे लंबे रिपोर्ट का सार, कई पैरा में एंटिटीज़ को ट्रैक करना, या हजारों टोकन्स पहले उल्लिखित किसी डिटेल को रीकॉल करना।
लंबे इनपुट्स के साथ, मॉडल सिर्फ़ भाषा नहीं सीख रहा; यह सीख रहा है कि कहाँ देखना है। रिलेटिव और रोटरी-शैली की योजनाएँ अक्सर दूर-दराज के टोकन्स की तुलना करने और पैटर्नों को कॉन्टेक्स्ट बढ़ने पर भी संरक्षित रखने में आसान बनाती हैं, जबकि कुछ एब्सोल्यूट स्कीम्स अधिक जल्दी बिगड़ सकती हैं जब इन्हें उनकी ट्रेनिंग विंडो से आगे पुश किया जाए।
व्यवहार में, positional encoding उन शांत डिज़ाइन निर्णयों में से एक है जो तय कर सकता है कि एक LLM 2,000 टोकन्स पर तेज और सुसंगत लगे—और 100,000 पर भी coherently बने रहे।
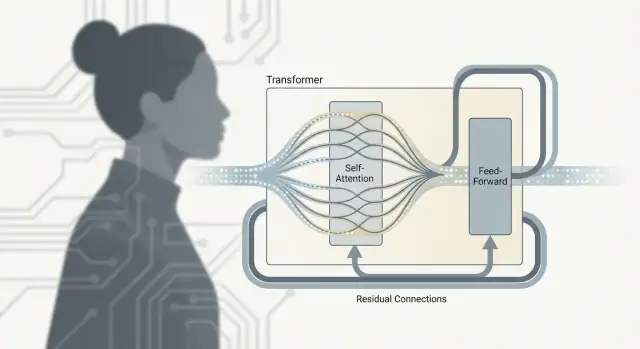
एक ट्रांसफॉर्मर केवल "attention" नहीं है। असली काम एक रिपीटिंग यूनिट में होता है—अक्सर इसे Transformer block कहा जाता है—जो टोकन्स के बीच जानकारी मिलाता है और फिर उसे परिमार्जित करता है। कई ऐसे ब्लॉक्स को स्टैक करने पर ही वह गहराई मिलती है जो बड़े भाषा मॉडलों को सक्षम बनाती है।
Self-attention कम्युनिकेशन स्टेप है: हर टोकन अन्य टोकन्स से संदर्भ इकट्ठा करता है।
Feed-forward network (FFN), जिसे MLP भी कहा जाता है, थिंकिंग स्टेप है: यह हर टोकन के अद्यतन प्रतिनिधित्व को लेता है और उसी छोटे न्यूरल नेटवर्क को स्वतंत्र रूप से उस पर चलाता है।
सादा शब्दों में, FFN हर टोकन अब क्या जानता है उसे बदलता और रूपांतरित करता है, जिससे मॉडल संदर्भ इकट्ठा करने के बाद समृद्ध फीचर्स (जैसे सिंटैक्स पैटर्न, तथ्य, या शैली-संकेत) बना सके।
यह वैकल्पिक क्रम इसलिए मायने रखता है क्योंकि दोनों भाग अलग काम करते हैं:
इस पैटर्न को दोहराने से मॉडल धीरे-धीरे उच्च-स्तरीय अर्थ बनाता है: कम्युनिकेट, कम्प्यूट, फिर से कम्युनिकेट, फिर कम्प्यूट।
हर सब-लेयर (attention या FFN) को residual connection के साथ लपेटा जाता है: इनपुट को आउटपुट में जोड़ दिया जाता है। इससे गहरे मॉडल्स को ट्रेन करना आसान होता है क्योंकि ग्रेडिएंट्स "स्किप लेन" से बह सकते हैं भले ही कोई विशेष लेयर अभी सीख रही हो। यह एक लेयर को सब कुछ फिर से सीखने की बजाय छोटे समायोजन करने की अनुमति भी देता है।
Layer normalization एक स्थिरीकरण है जो कई लेयर्स से गुजरते हुए एक्टिवेशन्स को बहुत बड़े या बहुत छोटे होने से रोकता है। इसे वॉल्यूम लेवल को लगातार रखने जैसा सोचें ताकि बाद की लेयर्स ओवरवेल्म न हों—यह ट्रेनिंग को स्मूथ और अधिक भरोसेमंद बनाता है, खासकर LLM पैमाने पर।
मूल ट्रांसफॉर्मर Attention Is All You Need में मशीन अनुवाद के लिए बनाया गया था, जहाँ एक सिक्वेंस (फ्रेंच) को दूसरे (अंग्रेज़ी) में बदलना है। यह काम स्वाभाविक रूप से दो भूमिकाओं में बंट जाता है: इनपुट को अच्छी तरह पढ़ना, और आउटपुट को प्रवाहमय ढंग से लिखना।
एक encoder–decoder ट्रांसफॉर्मर में, encoder पूरे इनपुट वाक्य को एक बार में प्रोसेस करता है और समृद्ध प्रतिनिधित्व देता है। decoder तब आउटपुट को एक-एक टोकन जेनरेट करता है।
महत्वपूर्ण बात यह है कि decoder सिर्फ़ अपने पिछले टोकन्स पर निर्भर नहीं करता; वह encoder के आउटपुट पर cross-attention भी करता है, जिससे वह स्रोत टेक्स्ट में मजबूती से लगा रहता है।
यह सेटअप तब बेहतरीन रहता है जब आपको किसी इनपुट पर कड़ाई से कंडीशन करना हो—अनुवाद, सारांशण, या किसी विशेष पैसिज के साथ प्रश्नोत्तर।
आधुनिक बड़े भाषा मॉडल अधिकांशतः decoder-only होते हैं। इन्हें एक सरल, शक्तिशाली टास्क पर ट्रेन किया जाता है: अगला टोकन अनुमान लगाओ।
ऐसा करने के लिए, वे masked self-attention (causal attention) का प्रयोग करते हैं। हर पोजिशन केवल पहले के टोकन्स को ही अटेन्ड कर सकता है, न कि भविष्य के—ताकि जनरेशन लगातार बाएँ से दाएँ हो।
यह LLMs के लिए प्रचलित है क्योंकि यह बड़े टेक्स्ट कॉर्पोरा पर ट्रेन करना सरल बनाता है, यह जेनरेशन के उपयोग-मामले से मेल खाता है, और यह डेटा और कंप्यूट के साथ कुशलता से स्केल होता है।
Encoder-only ट्रांसफॉर्मर्स (जैसे BERT-शैली मॉडल) टेक्स्ट जेनरेट नहीं करते; वे पूरे इनपुट को बिडायरेक्शनली पढ़ते हैं। वे क्लासिफिकेशन, सर्च, और एम्बेडिंग्स के लिए शानदार हैं—ऐसे काम जहां टेक्स्ट की समझ लंबी continuation के बजाय ज्यादा महत्वपूर्ण है।
ट्रांसफॉर्मर्स असाधारण रूप से स्केल-फ्रेंडली साबित हुए: यदि आप उन्हें अधिक टेक्स्ट, अधिक कंप्यूट और बड़े मॉडल दें, तो वे अपेक्षाकृत पूर्वानुमेय तरीके से बेहतर होते जाते हैं।
एक बड़ा कारण संरचनात्मक सादगी है। एक ट्रांसफॉर्मर दोहराए जाने वाले ब्लॉक्स (self-attention + छोटा feed-forward नेटवर्क, और normalization) से बना है, और वे ब्लॉक्स समान व्यवहार करते हैं चाहे आप लाख शब्दों पर ट्रेन करें या ट्रिलियन पर।
पहले के सिक्वेंस मॉडल (जैसे RNNs) को टोकन-एक-एक प्रोसेस करना पड़ता था, जो एक समय पर किए जा सकने वाले कामों को सीमित करता है। ट्रांसफॉर्मर्स के विपरीत, ट्रेनिंग के दौरान ये सभी टोकन्स को पैरेलल में प्रोसेस कर सकते हैं।
यह GPUs/TPUs और बड़े वितरित सेटअप के लिए एकदम उपयुक्त है—बिलकुल वही चीज़ जिसकी ज़रूरत होती है जब आधुनिक LLMs को ट्रेन करना हो।
कॉन्टेक्स्ट विंडो वह हिस्सा है जिसे मॉडल एक समय में "देख" सकता है—आपका प्रॉम्प्ट और हाल की बातचीत या दस्तावेज़ टेक्स्ट। बड़ी विंडो मॉडल को अधिक वाक्यों या पन्नों के विचारों को जोड़ने, प्रतिबंधों को याद रखने, और पहले के विवरणों पर निर्भर प्रश्नों का उत्तर देने की अनुमति देती है।
पर कॉन्टेक्स्ट मुफ्त नहीं है।
Self-attention टोकन्स की आपस में तुलना करता है। जैसे-जैसे सिक्वेंस लंबा होता है, तुलना की संख्या तेजी से बढ़ती है (लगभग सिक्वेंस लंबाई के वर्ग के अनुसार)।
इसीलिए बहुत लंबी कॉन्टेक्स्ट विंडो मेमोरी और कंप्यूट में महंगी हो सकती है, और कई आधुनिक कोशिशें ध्यान को अधिक कुशल बनाने पर केंद्रित हैं।
जब ट्रांसफॉर्मर्स को बड़े पैमाने पर ट्रेन किया जाता है, वे केवल एक संकुचित कार्य में बेहतर नहीं होते। वे अक्सर व्यापक, लचीली क्षमताएँ दिखाने लगते हैं—सारांशण, अनुवाद, लेखन, कोडिंग और तर्क आदि—क्योंकि एक ही सामान्य लर्निंग मैकेनिज़्म विशाल, विविध डेटा पर लागू होता है।
मूल ट्रांसफॉर्मर डिजाइन अब भी संदर्भ बिंदु है, पर अधिकांश प्रोडक्शन LLMs "ट्रांसफॉर्मर प्लस" वाले होते हैं: छोटे, प्रायोगिक एडिट्स जो मुख्य ब्लॉक (attention + MLP) को बनाए रखते हुए गति, स्थिरता, या कॉन्टेक्स्ट लंबाई सुधारते हैं।
कई अपग्रेड्स यह बदलने के बजाय कि मॉडल क्या है उसे ट्रेन और रन बेहतर बनाते हैं:
ये बदलाव आमतौर पर मॉडल की मूल "Transformer-ness" को नहीं बदलते—वे उसे परिष्कृत करते हैं।
कुछ हजार टोकन्स से लेकर दसियों या सैकड़ों हजार तक कॉन्टेक्स्ट बढ़ाना अक्सर sparse attention (केवल चयनित टोकन्स पर ध्यान) या efficient attention variants (ध्यान को अनुमानित या पुनर्गठित करके गणना काटना) पर निर्भर करता है।
ट्रेड-ऑफ़ आम तौर पर सटीकता, मेमोरी और इंजीनियरिंग जटिलता का मिश्रण होता है।
MoE मॉडल कई “expert” सब-नेटवर्क जोड़ते हैं और हर टोकन को केवल कुछ चुनिंदा experts के माध्यम से रूट करते हैं। सैद्धांतिक रूप से: आपको बड़ा ब्रेन मिलता है, पर हर बार आप उसका पूरा हिस्सा सक्रिय नहीं करते।
यह प्रति टोकन कंप्यूट को कम कर सकता है किसी दिए गए पैरामीटर काउंट के लिए, पर इसमें सिस्टम जटिलता बढ़ती है (राउटिंग, experts का संतुलन, सर्विंग)।
जब कोई मॉडल नया ट्रांसफॉर्मर वैरिएंट प्रमोट करे, तो पूछें:
ज्यादातर सुधार असल होते हैं—पर वे शायद मुफ्त नहीं होते।
Self-attention और स्केलिंग जैसी ट्रांसफॉर्मर आइडियाज़ रोचक हैं—पर प्रोडक्ट टीमें इन्हें ज़्यादातर ट्रेड-ऑफ़ के रूप में महसूस करती हैं: आप कितना टेक्स्ट फीड कर सकते हैं, जवाब कितनी तेज़ी से आता है, और प्रति अनुरोध लागत क्या है।
Context length: लंबा कॉन्टेक्स्ट आपको अधिक दस्तावेज़, चैट इतिहास और निर्देश शामिल करने देगा। यह टोकन खर्च बढ़ाता है और प्रतिक्रियाएँ धीमी कर सकता है। अगर आपकी फीचर “30 पेज पढ़ो और जवाब दो” पर निर्भर है, तो context length प्राथमिकता होनी चाहिए।
Latency: यूज़र-फेसिंग चैट और कोपायलट अनुभव प्रतिक्रिया समय पर ही चलते हैं। स्ट्रीमिंग आउटपुट मदद करती है, पर मॉडल का चुनाव, रीजन, और बैचिंग भी मायने रखते हैं।
Cost: प्राइसिंग आमतौर पर प्रति टोकन (इनपुट + आउटपुट) होती है। एक मॉडल जो 10% “बेहतर” है वह 2–5× की लागत हो सकता है। निर्धारित करें कि किस गुणवत्ता स्तर के लिए भुगतान करना मुफ़ीद है।
Quality: इसे अपने केस के लिए परिभाषित करें: तथ्यात्मक सटीकता, निर्देश-अनुसारता, टोन, टूल-यूज़, या कोड। असली डोमेन के उदाहरणों से मूल्यांकन करें, न कि सिर्फ़ सामान्य बेंचमार्क्स।
अगर आपका मुख्य काम सर्च, डुप्लीकेशन हटाना, क्लस्टरिंग, रिकमेंडेशन्स, या "समान खोजो" है, तो embeddings (अक्सर encoder-शैली मॉडल) आमतौर पर सस्ते, तेज़ और अधिक स्थिर होते हैं बनिस्बत चैट मॉडल को प्रॉम्प्ट करने के। जनरेशन का उपयोग अंतिम कदम के लिए रखें (सारांश, व्याख्या, ड्राफ्ट) retrieval के बाद।
एक गहरे विवरण के लिए, अपनी टीम को टेक्निकल एक्सप्लेनर /blog/embeddings-vs-generation पर लिंक करें।
जब आप ट्रांसफॉर्मर क्षमताओं को प्रोडक्ट में बदलते हैं, तो कठिन हिस्सा अक्सर आर्किटेक्चर से कम और उसके चारों ओर के वर्कफ़्लो—प्रॉम्प्ट इटरेशन, ग्राउन्डिंग, मूल्यांकन, और सुरक्षित डिप्लॉयमेंट—से ज्यादा जुड़ा होता है।
एक व्यावहारिक मार्ग है एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai का उपयोग करके LLM-समर्थित फीचर्स तेज़ी से प्रोटोटाइप और शिप करना: आप वेब ऐप, बैकएंड एंडपॉइंट्स, और डेटा मॉडल को चैट में वर्णित कर सकते हैं, प्लानिंग मोड में इटरेट कर सकते हैं, और फिर सोर्स कोड एक्सपोर्ट या होस्टिंग के साथ डिप्लॉय कर सकते हैं—कस्टम डोमेन्स और स्नैपशॉट के जरिए रोलबैक के साथ। यह खासकर तब उपयोगी है जब आप retrieval, embeddings, या टूल-कॉलिंग लूप्स के साथ प्रयोग कर रहे हों और बिना हर बार वही स्कैफ़ोल्डिंग बनाये तेज़ इटरेशन चाहिए।
एक ट्रांसफॉर्मर एक ऐसी न्यूरल नेटवर्क आर्किटेक्चर है जो सिक्वेंस डेटा के लिए बनी है और हर टोकन को उसी इनपुट के बाकी टोकनों से जोड़ने के लिए self-attention का उपयोग करती है।
RNNs/LSTMs की तरह कदम-दर-कदम जानकारी ले जाने के बजाय, यह पूरे सिक्वेंस में से यह तय करता है किस पर ध्यान देना चाहिए, जिससे लंबी दूरी की समझ बेहतर होती है और ट्रेनिंग अधिक पैरेलल-फ्रेंडली बन जाती है।
RNNs और LSTMs टेक्स्ट को एक-एक करके प्रोसेस करते हैं, जिससे ट्रेनिंग को पैरेललाइज़ करना मुश्किल होता है और लंबी दूरी की निर्भरताएँ (long-range dependencies) पकड़ना कठिन हो जाता है।
ट्रांसफॉर्मर सीधे ध्यान (attention) के ज़रिए दूर के टोकन्स को जोड़ते हैं, और ट्रेनिंग के दौरान कई टोकन-टू-टोकन इंटरैक्शन पैरेलल में किए जा सकते हैं—जिससे बड़े डेटासेट और अधिक कंप्यूट के साथ स्केल करना आसान हो गया।
Attention एक मैकेनिज़्म है जो यह पूछता है: “इस समय किसी टोकन को समझने के लिए किन अन्य टोकन्स पर ध्यान देना चाहिए?”
इसे इन-सेंटेंस रिट्रीवल की तरह सोचें:
आउटपुट संबंधित टोकन्स का वेटेड मिक्स होता है, जिससे हर पोजिशन का रिप्रेजेंटेशन कॉन्टेक्स्ट-सुसंगत बनता है।
Self-attention का मतलब है कि एक सिक्वेंस के टोकन्स उसी सिक्वेंस के अन्य टोकन्स पर ध्यान देते हैं।
यह मॉडल को कोरेफरेंस (जैसे कि “it” किसको रेफर करता है), सब्जेक्ट–वर्ब संबंध और दूर-दराज की निर्भरताएँ हल करने में मदद करता है—बिना सब कुछ एक ही क्रमिक ‘मेमोरी’ में ठूसने के।
Multi-head attention कई attention कैलकुलेशन्स को पैरेलल में चलाता है, और हर हेड अलग पैटर्न पर स्पेशलाइज़ कर सकता है।
अक्सर विभिन्न हेड्स अलग प्रकार के रिलेशनशिप पकड़ते हैं (सिंटैक्स, लंबी दूरी के लिंक, प्रोनाउन रिज़ॉल्यूशन, टॉपिकल संकेत)। मॉडल फिर इन अलग-अलग व्यूज़ को संयोजित कर लेता है ताकि एक ही समय में कई तरह की संरचना को रिकॉर्ड किया जा सके।
स्व-अटेन्शन अकेले टोकन क्रम (order) का एहसास नहीं कराता—बिना पोज़िशन संकेत के शब्दों को शफल करने पर मॉडल उन्हें समान मान सकता है।
Positional encodings टोकन एम्बेडिंग्स में यह बताने वाला सिग्नल जोड़ते हैं कि ‘‘मैं सिक्वेंस में किस पोजिशन पर हूँ।’’
सामान्य विकल्पों में सिनुसॉइडल (fixed), लर्न्ड एब्सोल्यूट पोजिशन और रिलेटिव/रोटरी-शैली के तरीके आते हैं।
एक ट्रांसफॉर्मर ब्लॉक आमतौर पर शामिल करता है:
इन ब्लॉक्स को स्टैक करने से मॉडल में गहराई आती है और अधिक समृद्ध फीचर्स बनते हैं।
मूल ट्रांसफॉर्मर encoder–decoder था:
आधुनिक बड़े भाषा मॉडल (LLMs) ज्यादातर हैं, जो अगले टोकन की भविष्यवाणी करने के लिए ट्रेन किए जाते हैं और का उपयोग करते हैं ताकि जनरेशन लेफ्ट-टू-राइट हो और सहज रहे।
नोआम शेज़र 2017 के पेपर “Attention Is All You Need” के सह-लेखक थे, जिसने ट्रांसफॉर्मर का परिचय कराया।
उन्हें एक प्रमुख योगदानकर्ता के रूप में क्रेडिट देना सही है, पर यह आर्किटेक्चर गूगल की एक टीम का सामूहिक काम था—और बाद के कई सुधारों का भी बड़ा हिस्सा समुदाय और उद्योग ने जोड़ा।
लंबे इनपुट्स में स्टैण्डर्ड self-attention की कॉम्प्यूट और मेमोरी लागत सिक्वेंस लंबाई के साथ लगभग वर्गानुपाती (square) रूप में बढ़ती है—जिससे मेमोरी और प्रोसेसिंग महंगी हो जाती है।
टीमें अक्सर इन तरीकों का उपयोग करती हैं: