13 नव॰ 2025·8 मिनट
NoSQL डेटाबेस: स्केलिंग और लचीलापन की समस्याओं को हल करने का उदय
जानिए NoSQL डेटाबेस क्यों उभरे: वेब का स्केल, लचीली डाटा ज़रूरतें और रिलेशनल सिस्टम की सीमाएँ—साथ में प्रमुख मॉडल और समझौते।
जानिए NoSQL डेटाबेस क्यों उभरे: वेब का स्केल, लचीली डाटा ज़रूरतें और रिलेशनल सिस्टम की सीमाएँ—साथ में प्रमुख मॉडल और समझौते।
NoSQL उस समय उभरा जब कई टीमों को पता चला कि उनके एप्लिकेशन की ज़रूरतें और पारंपरिक रिलेशनल डेटाबेस (SQL डेटाबेस) जो चीज़ों के लिए ऑप्टिमाइज़ हैं, उनके बीच मेल नहीं बैठता। SQL "फेल" नहीं हुआ—पर वेब-स्केल पर कुछ टीमों ने अलग लक्ष्य अधिक प्राथमिकता देना शुरू कर दिया।
पहला, स्केल। लोकप्रिय कंज्यूमर ऐप्स को ट्रैफिक स्पाइक्स, लगातार लिखने और उपयोगकर्ता-जनित डेटा की भारी मात्रा का सामना करना पड़ा। इन वर्कलोड्स के लिए “बस बड़ा सर्वर खरीद लें” महंगा, लागू करने में धीमा, और अंततः उस सबसे बड़े मशीन की सीमा से सीमित हो गया जिसे आप संचालन में रख सकते थे।
दूसरा, परिवर्तन। प्रोडक्ट फीचर्स तेज़ी से विकसित होते थे, और उनके पीछे का डेटा हमेशा एक निश्चित सेट टेबल्स में सुचारू रूप से फिट नहीं होता था। यूज़र प्रोफाइल में नए एट्रिब्यूट जोड़ना, कई इवेंट प्रकार स्टोर करना, या अलग स्रोतों से अर्द्ध-संरचित JSON इनजेस्ट करना अक्सर बार-बार स्कीमा माइग्रेशन्स और टीमों के बीच समन्वय की आवश्यकता बन जाता था।
रिलेशनल डेटाबेस संरचना लागू करने और नॉर्मलाइज़्ड टेबल्स पर जटिल क्वेरीज सक्षम करने में बेहतरीन हैं। पर कुछ उच्च-स्केल वर्कलोड्स ने उन ताकतों से कम लाभ दिलाया:\n
परिणाम: कुछ टीमों ने ऐसे सिस्टम खोजे जो कुछ गारैंटीज़ और क्षमताओं के बदले में सरल स्केलिंग और तेज़ इटरेशन दें।
NoSQL कोई एक डेटाबेस या डिज़ाइन नहीं है। यह उन सिस्टमों के लिए एक चूँपन शब्द है जो कुछ मिश्रण पर ज़ोर देते हैं:
NoSQL कभी भी SQL का सार्वभौमिक प्रतिस्थापन बनने के लिए नहीं था। यह trade-offs का सेट है: आपको स्केलेबिलिटी या स्कीमा लचीलापन मिल सकता है, पर आप कमजोर कंसिस्टेंसी गारंटी, कम एड-हॉक क्वेरी विकल्प, या एप्लिकेशन-स्तर पर अधिक डेटा मॉडलिंग की ज़िम्मेदारी स्वीकार कर सकते हैं।
कई वर्षों तक, धीमे डेटाबेस का साधारण उत्तर था: बड़ा सर्वर खरीदो। और अधिक CPU, अधिक RAM, तेज़ डिस्क जोड़ो और वही स्कीमा और ऑपरेशनल मॉडल रखें। यह "स्केल अप" दृष्टिकोण काम करता था—जब तक यह व्यावहारिक न रह गया।
हाई-एंड मशीनें जल्दी महंगी हो जाती हैं, और प्राइस/परफॉर्मेंस कर्व अंततः अनफ्रेंडली हो जाता है। अपग्रेड के लिए बड़े, दुर्लभ बजट अनुमोदन और मेंटेनेंस विंडो चाहिए होती हैं ताकि डेटा को मूव और कटओवर किया जा सके। भले ही आप बड़े हार्डवेयर का खर्च उठा सकें, एक ही सर्वर की अपनी छत होती है: एक मेमोरी बस, एक स्टोरेज सबसिस्टम, और लेखन लोड को सहने वाला एक प्राइमरी नोड।
प्रोडक्ट बढ़ने पर, डेटाबेस लगातार रीड/राइट दबाव का सामना करने लगे, न कि कभी-कभार के पीक्स। ट्रैफिक सच्चाई में 24/7 हो गया, और कुछ फीचर्स अनियमित एक्सेस पैटर्न बनाते। थोड़े से अत्यधिक एक्सेस किए गए रो या पार्टिशन पूरा ट्रैफिक घेर सकते थे, जिससे hot tables (या hot keys) बन गए जो सब कुछ धीमा कर देते थे।
ऑपरेशनल बॉटलबेक्ष आम हो गए:\n
कई एप्लिकेशंस को केवल एक डाटा सेंटर में तेज़ होने के अलावा क्षेत्रों में उपलब्ध रहना भी आवश्यक था। एक स्थान में एक "मुख्य" डेटाबेस दूर के उपयोगकर्ताओं के लिए लेटेंसी बढ़ाता है और आउटेज को और विनाशकारी बनाता है। प्रश्न बदल गया: "हम बड़े बॉक्स का कैसे खरीदें?" से "हम डेटाबेस को कई मशीनों और स्थानों में कैसे चलाएँ?" पर।
रिलेशनल डेटाबेस तब शानदार होते हैं जब आपका डेटा आकार स्थिर हो। पर कई आधुनिक प्रोडक्ट्स स्थिर नहीं रहते। एक टेबल स्कीमा जानबूझ कर सख्त होता है: हर रो एक ही कॉलम्स, टाइप्स और constraints का पालन करता है। वह predictability मूल्यवान है—जब तक आप तेज़ी से इटरैट नहीं कर रहे।
व्यवहार में, बार-बार होने वाले स्कीमा परिवर्तन महंगे हो सकते हैं। एक मामूली अपडेट भी माइग्रेशन्स, बैकफिल, इंडेक्स अपडेट्स, समन्वित डिप्लॉयमेंट टाइमिंग, और पुराने कोड पाथ्स के साथ कम्पैटिबिलिटी प्लानिंग मांग सकता है। बड़े टेबल्स पर कॉलम जोड़ना या प्रकार बदलना समय लेने वाला ऑपरेशन बन सकता है और वास्तविक ऑपरेशनल जोखिम पैदा कर सकता है।
यह friction टीमों को परिवर्तन टालने, वर्कअराउंड इकट्ठा करने, या टेक्स्ट फ़ील्ड्स में गंदे ब्लॉब स्टोर करने के लिए दबाव डालता है—जो तेज़ इटरेशन के लिए आदर्श नहीं है।
कई एप्लिकेशन डेटा स्वाभाविक रूप से अर्द्ध-संरचित होता है: नेस्टेड ऑब्जेक्ट्स, ऑप्शनल फ़ील्ड्स, और समय के साथ विकसित होते एट्रिब्यूट्स।
उदाहरण के लिए, एक "user profile" नाम और ईमेल से शुरू हो सकता है, फिर.preferences, linked accounts, शिपिंग पते, नोटिफिकेशन सेटिंग्स, और experiment flags जोड़ सकता है। हर यूजर के पास हर फ़ील्ड नहीं होती, और नई फ़ील्ड्स धीरे-धीरे आती हैं। डॉक्यूमेंट-स्टाइल मॉडल नेस्टेड और अनईवन आकार सीधे स्टोर कर सकते हैं बिना हर रिकॉर्ड को एक कठोर टेम्पलेट में बाध्य किए।
लचीलापन कुछ डेटा आकारों के लिए जटिल जॉइन्स की ज़रूरत को भी घटाता है। जब एक स्क्रीन को एक संयुक्त ऑब्जेक्ट चाहिए (एक ऑर्डर जिसमें आइटम्स, शिपिंग जानकारी और स्टेटस इतिहास हो), रिलेशनल डिज़ाइन्स कई टेबल्स और जॉइन्स मांग सकते हैं—साथ ही ORM लेयर्स जो अक्सर उस जटिलता को छिपाने की कोशिश करते हैं पर अतिरिक्त friction जोड़ते हैं।
NoSQL विकल्पों ने डेटा को उस तरीके के करीब मॉडल करना आसान बनाया जिस तरीके से एप्लिकेशन उसे पढ़ता/लिखता है, जिससे टीमें तेजी से बदलाव भेज सकीं।
वेब एप्लिकेशंस सिर्फ बड़े नहीं हुए—उनका स्वरूप बदल गया। पूर्वानुमानित संख्या में आंतरिक उपयोगकर्ताओं की सेवा करने के बजाय, प्रोडक्ट्स करोड़ों वैश्विक उपयोगकर्ताओं को चौबीसों घंटे सेवा देने लगे, लॉन्च, समाचार या सोशल शेयरिंग से अचानक स्पाइक्स के साथ।
हमेशा-ऑन अपेक्षाओं ने बार की अपेक्षा बढ़ा दी: डाउनटाइम सुर्खियाँ बन गया। साथ ही, टीमों से तेज़ी से फीचर्स भेजने की मांग थी—अक्सर तब भी जब कोई नहीं जानता था कि "अंतिम" डेटा मॉडल कैसा होगा।
टिके रहने के लिए, एकल डेटाबेस सर्वर को स्केल अप करना पर्याप्त नहीं रहा। जितना अधिक ट्रैफिक, उतनी अधिक ऐसी क्षमता चाहिए थी जिसे आप क्रमिक रूप से जोड़ सकें—एक और नोड जोड़ें, लोड फैलाएँ, विफलताओं को अलग करें।
इसने आर्किटेक्चर को कई मशीनों के बेड़े की ओर धकेला, न कि एक "मुख्य" बॉक्स की ओर, और टीमों की अपेक्षाएँ बदल गईं: केवल correctness नहीं, बल्कि उच्च concurrency के तहत पूर्वानुमानित प्रदर्शन और सिस्टम के हिस्सों के अस्वस्थ होने पर अनुग्रह व्यवहार।
"NoSQL" मुख्यधारा बनने से पहले कई टीम पहले ही वेब-स्केल हकीकतों के अनुसार सिस्टम को मोड़ चुकी थीं:
ये तकनीकें काम करती थीं, पर उन्होंने जटिलता को एप्लिकेशन कोड में शिफ्ट कर दिया: कैश इनवैलिडेशन, डुप्लिकेट डेटा को सुसंगत रखना, और "ready-to-serve" रिकॉर्ड्स के लिए पाइपलाइंस बनाना।
जैसे-जैसे ये पैटर्न मानक बन गए, डेटाबेसों को डेटा को कई मशीनों में वितरित करने, आंशिक विफलताओं को सहन करने, उच्च लिखने की मात्रा को संभालने, और विकसित होते डेटा को साफ़-सुथरे तरीके से प्रतिनिधित्व करने का समर्थन करना पड़ा। NoSQL डेटाबेस आंशिक रूप से इसलिए उभरे ताकि सामान्य वेब-स्केल रणनीतियों को पहले दर्जे का नागरिक बनाया जा सके, न कि निरंतर वर्कअराउंड।
जब डेटा एक मशीन पर रहता है, नियम सरल लगते हैं: एकल सत्य का स्रोत है, और हर पढ़ाई या लिखाई तुरंत चेक की जा सकती है। जब आप डेटा को सर्वरों पर फैला देते हैं (अक्सर क्षेत्रों में), एक नई वास्तविकता उभरती है: संदेश विलंबित हो सकते हैं, नोड्स फेल कर सकते हैं, और सिस्टम के हिस्से अस्थायी रूप से संवाद बंद कर सकते हैं।
एक वितरित डेटाबेस को तय करना होता है कि जब यह सुरक्षित रूप से समन्वय नहीं कर सकता तो क्या करे। क्या यह रिक्वेस्ट्स देने पर बने रहे ताकि एप "अप" रहे, भले ही परिणाम थोड़े पुराने हो सकते हैं? या क्या यह कुछ ऑपरेशन्स को अस्वीकार कर दे जब तक कि यह प्रतियों के सहमति की पुष्टि नहीं कर ले—जो उपयोगकर्ताओं के लिए डाउनटाइम जैसा दिख सकता है?
ऐसे परिदृश्य राउटर फेल्योर, ओवरलोडेड नेटवर्क, रोलिंग डिप्लॉयमेंट्स, फ़ायरवॉल मिसकॉनफ़िगरेशन, और क्रॉस-रीजन रेप्लिकेशन विलंब के दौरान होते हैं।
CAP थियोरम तीन गुणों का संक्षेप है जिन्हें आप एक साथ चाहते हैं:
मुख्य बात यह है कि जब नेटवर्क विभाजन होता है, तो आपको संगति और उपलब्धता के बीच चुनाव करना होगा। वेब-स्केल सिस्टम्स में विभाजन अनिवार्य माना जाता है—खासकर मल्टी-रीजन सेटअप्स में।
कल्पना कीजिए आपका ऐप दो क्षेत्रों में चल रहा है। एक फाइबर कट या रूटिंग समस्या सिंक को रोक देता है।
विभिन्न NoSQL सिस्टम (और एक ही सिस्टम के विभिन्न कॉन्फिगरेशन) अलग-अलग समझौते करते हैं, निर्भर करता है कि विफलताओं के दौरान क्या सबसे ज़्यादा मायने रखता है: उपयोगकर्ता अनुभव, correctness गारंटी, ऑपरेशनल सरलता, या रिकवरी व्यवहार।
स्केल आउट (हॉरिजॉन्टल स्केलिंग) का अर्थ है क्षमता बढ़ाने के लिए और मशीनें (नोड्स) जोड़ना बजाय एक ही बड़े सर्वर को खरीदने के। कई टीमों के लिए यह एक वित्तीय और ऑपरेशनल बदलाव था: कमोडिटी नोड्स को क्रमिक रूप से जोड़ा जा सकता था, विफलताओं की उम्मीद रहती थी, और वृद्धि जोखिमभरे "बड़े बॉक्स" माइग्रेशन की मांग नहीं करती थी।
कई नोड्स उपयोगी बनाने के लिए, NoSQL सिस्टम शार्डिंग (जिसे पार्टिशनिंग भी कहा जाता है) पर निर्भर हुए। एक डेटाबेस हर अनुरोध को संभालने की बजाय, डेटा को पार्टिशन्स में बाँटा और नोड्स पर वितरित किया जाता है।
साधारण उदाहरण में user_id जैसे की द्वारा पार्टिशन करना:\n
रीड्स और राइट्स फैल जाते हैं, hotspots घटते हैं और आप नोड जोड़ने पर थ्रूपुट बढ़ा सकते हैं। पार्टिशन की कुंजी एक डिज़ाइन निर्णय बन जाती है: अगर आप उसे क्वेरी पैटर्न से मेल नहीं खाते तो आप गलती से बहुत सारा ट्रैफ़िक एक शार्ड में भेज सकते हैं।
रेप्लिकेशन का मतलब है एक ही डेटा की कई प्रतियाँ अलग नोड्स पर रखना। इससे सुधार होता है:
रेप्लिकेशन डेटा को रैक्स या रीजन में फैलाने में भी सक्षम बनाती है ताकि स्थानीय आउटेज से बचाव हो सके।
शार्डिंग और रेप्लिकेशन लगातार ऑपरेशनल काम लाते हैं। जैसे-जैसे डेटा बढ़ता है या नोड्स बदलते हैं, सिस्टम को रीबैलेंस करना पड़ता है—ऑनलाइन रहते हुए पार्टिशन्स को मूव करना। खराब हैंडल करने पर रीबैलेंसिंग लेटेंसी स्पाइक्स, असमान लोड, या अस्थायी कैपेसिटी कमी पैदा कर सकती है।
यह एक मूल trade-off है: अधिक नोड्स के ज़रिये सस्ता स्केलिंग, बदले में अधिक जटिल वितरण, मॉनिटरिंग और फेल्योर हैंडलिंग।
एक बार डेटा वितरित हो जाने पर, डेटाबेस को यह परिभाषित करना होता है कि जब अपडेट समवर्ती हों, नेटवर्क स्लो हो या नोड्स संवाद न कर रहे हों तब "सही" क्या माना जाएगा।
स्ट्रॉंग कंसिस्टेंसी के साथ, एक बार write की पुष्टि हो जाने पर हर रीडर उसे तुरंत देखना चाहिए। यह कई लोगों द्वारा रिलेशनल डेटाबेस के साथ जुड़ी "सिंगल सोर्स ऑफ ट्रुथ" अनुभूति से मेल खाता है।
चुनौती समन्वय है: नोड्स के बीच सख्त गारंटी के लिए कई मैसेज, पर्याप्त प्रतिक्रियाओं के लिए प्रतीक्षा, और फ्लाइट के बीच विफलताओं को संभालना ज़रूरी है। नोड्स जितने दूर होंगे (या जितने व्यस्त होंगे), उतनी अधिक लेटेंसी हर लिखाई पर आ सकती है।
परिणामी संगति उस गारंटी को ढीला करती है: एक लिखाई के बाद, अलग नोड्स अस्थायी रूप से अलग उत्तर दे सकते हैं, पर सिस्टम समय के साथ समरूप हो जाता है।
उदाहरण:\n
कई यूजर अनुभवों के लिए यह अस्थायी असमानता स्वीकार्य है अगर सिस्टम तेज़ और उपलब्ध रहता है।
अगर दो रेप्लिकास लगभग एक साथ अपडेट स्वीकार कर लें, तो डेटाबेस को मर्ज नियम चाहिए। सामान्य तरीके:
मनी मूवमेंट, इन्वेंटरी लिमिट्स, यूनिक यूज़रनेम्स, अनुमतियाँ—और कोई भी वर्कफ़्लो जहाँ "क्षणिक दो सत्य" वास्तविक नुकसान कर सकता है—उनके लिए आमतौर पर स्ट्रॉंग कंसिस्टेंसी का खर्च लेना सही होता है।
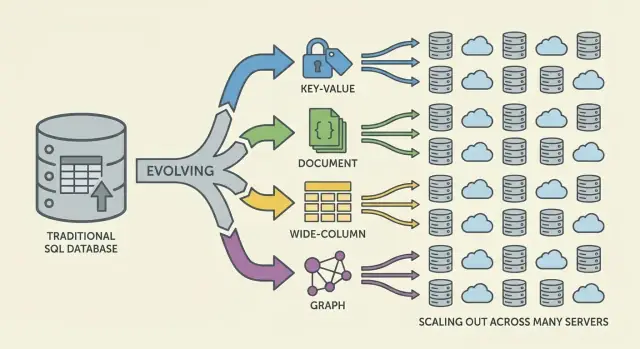
NoSQL मॉडल्स का सेट ऐसे trade-offs करता है जो स्केल, लेटेंसी और डेटा आकार के आसपास भिन्न होते हैं। "परिवार" को समझना मदद करता है यह अनुमान लगाने में कि क्या तेज़ होगा, क्या दर्ददायक होगा, और क्यों।
की-वैल्यू डेटाबेस एक अद्वितीय कुंजी के पीछे एक वैल्यू स्टोर करते हैं, जैसे एक विशाल वितरित हैशमैप। क्योंकि एक्सेस पैटर्न सामान्यतः "कुंजी से प्राप्त करें" / "कुंजी द्वारा सेट करें" होता है, वे अत्यंत तेज़ और हॉरिजॉन्टली स्केलेबल हो सकते हैं।
ये उन मामलों में बेहतरीन हैं जहां आप पहले से lookup key जानते हैं (sessions, caching, feature flags), पर एड-हॉक क्वेरी के लिए सीमाएँ होती हैं।
डॉक्यूमेंट डेटाबेस JSON-समान डॉक्यूमेंट्स स्टोर करते हैं (अक्सर कलेक्शन्स में समूहित)। हर डॉक्यूमेंट की संरचना थोड़ी अलग हो सकती है, जो प्रोडक्ट के विकसित होने पर स्कीमा लचीलापन देता है।
वे पूरे डॉक्यूमेंट पढ़ने/लिखने और उनके अंदर फ़ील्ड्स के आधार पर क्वेरी करने के लिए अनुकूलित होते हैं—बिना सख्त टेबलों के। ट्रेडऑफ: रिश्तों का मॉडलिंग पेचीदा हो सकता है, और जॉइन्स (यदि समर्थित हों) रिलेशनल सिस्टम जितने सीमलेस नहीं होते।
वाइड-कोलम डेटाबेस (Bigtable से प्रेरित) डेटा को रो कीज़ के अनुसार व्यवस्थित करते हैं, जिनमें कई कॉलम हो सकते हैं जो रो के अनुसार भिन्न होते हैं। ये भारी लिखने की दरों और वितरित स्टोरेज में चमकते हैं, और टाइम-सीरीज़, इवेंट और लॉग वर्कलोड्स के लिए उपयुक्त हैं।
ये आमतौर पर एक्सेस पैटर्न के आसपास सावधान डिज़ाइन को पुरस्कृत करते हैं: आप प्राथमिक कुंजी और क्लस्टरिंग नियमों से कुशलतापूर्वक क्वेरी करते हैं, न कि मनमाने फ़िल्टर से।
ग्राफ डेटाबेस रिश्तों को प्राथमिक डेटा मानते हैं। बार-बार टेबल्स को जॉइन करने की बजाय वे नोड्स के बीच एजेज़ को ट्रैवर्स करते हैं, जिससे "ये चीज़ें कैसे जुड़ी हैं?" जैसे प्रश्न स्वाभाविक और तेज़ी से हल होते हैं (fraud rings, recommendations, dependency graphs)।
रिलेशनल डेटाबेस normalization को प्रोत्साहित करते हैं: डेटा को कई टेबल्स में बाँटकर क्वेरी समय पर जॉइन से फिर से बनाना। कई NoSQL सिस्टम्स आपको उन सबसे महत्वपूर्ण एक्सेस पैटर्न्स के आसपास डिज़ाइन करने के लिए प्रेरित करते हैं—कभी-कभी नकल के दाम पर—ताकि नोड्स पर लेटेंसी पूर्वानुमानित रहे।
वितरित डेटाबेस में, एक जॉइन को कई पार्टिशन्स या मशीनों से डेटा खींचने की जरूरत हो सकती है। इससे नेटवर्क हॉप्स, समन्वय, और अनप्रिडिक्टेबल लेटेंसी बढ़ती है। डेनॉर्मलाइजेशन (संबंधित डेटा को साथ में स्टोर करना) राउंड-ट्रिप्स घटाता है और पढ़ को अक्सर "लोकल" रखता है।
एक व्यावहारिक परिणाम: आप orders में वही customer नाम स्टोर कर सकते हैं भले ही वह customers में भी मौजूद हो, क्योंकि "last 20 orders" एक कोर क्वेरी है।
कई NoSQL डेटाबेस सीमित जॉइन्स (या कोई नहीं) सपोर्ट करते हैं, इसलिए एप्लिकेशन पर अधिक जिम्मेदारी आती है:\n
इसीलिए NoSQL मॉडलिंग अक्सर इस सवाल से शुरू होती है: "हमें कौन-कौन सी स्क्रीन लोड करनी हैं?" और "कौन से शीर्ष क्वेरीज हमें तेज़ करने हैं?"
सेकंडरी इंडेक्स नई क्वेरीज सक्षम कर सकते हैं ("ईमेल से यूज़र्स खोजो"), पर वे मुफ्त नहीं होते। वितरित प्रणालियों में, हर लिखाई कई इंडेक्स संरचनाओं को अपडेट कर सकती है, जिसके कारण:\n
user_profile_summary रिकॉर्ड बनाएँ ताकि पोस्ट्स, लाइक्स और फॉलोज़ को स्कैन न करना पड़ेNoSQL इसलिए अपनाया गया कि यह हर मामले में "बेहतर" था—बल्कि इसलिए कि टीमें कुछ रिलेशनल सुविधाओं के बदले स्पीड, स्केल और वेब-स्केल दबाव के तहत लचीलापन स्वीकार करने को तैयार थीं।
डिज़ाइन के अनुसार स्केल-आउट। कई NoSQL सिस्टम्स ने मशीनें जोड़ना व्यावहारिक बनाया। शार्डिंग और रेप्लिकेशन को मूल क्षमताएँ बनाया गया, न कि बाद की व्यवस्था।
लचीले स्कीमा। डॉक्यूमेंट और की-वैल्यू सिस्टम्स ने एप्लिकेशन को बिना हर फ़ील्ड परिवर्तन को सख्त टेबल पर जाने के विकास की इजाज़त दी, जिससे बार-बार बदलती आवश्यकताओं पर रुकावट कम हुई।
उच्च उपलब्धता पैटर्न। नोड्स और रीजन में रेप्लिकेशन से हार्डवेयर फेल्योर या मेंटेनेंस के दौरान सर्विसेज़ चलती रहीं।
डेटा नकल और डेनॉर्मलाइजेशन। जॉइन्स से बचने के लिए अक्सर डेटा की नकल करनी पड़ती है। इससे पढ़ प्रदर्शन बेहतर होता है पर स्टोरेज बढ़ता है और "इसे हर जगह अपडेट रखें" जटिलता आती है।
कंसिस्टेंसी के आश्चर्य। परिणामी संगति तब तक स्वीकार्य है—जब तक कि वह समस्या न बनाए। उपयोगकर्ता stale डेटा देखें तो भ्रम पैदा हो सकता है जब तक एप्लिकेशन को उन किनारों को सहन करने के लिए डिज़ाइन न किया गया हो।
एनालिटिक्स कठिन हो सकती है। कुछ NoSQL स्टोर्स ऑपरेशनल रीड/राइट में उत्कृष्ट हैं पर एड-हॉक क्वेरींग, रिपोर्टिंग, या जटिल एग्रीगेशन SQL-प्रथम सिस्टम्स से अधिक कठिन बना सकते हैं।
प्रारंभिक NoSQL अपनाने ने अक्सर प्रयास डेटाबेस सुविधाओं से इंजीनियरिंग अनुशासन की ओर शिफ्ट कर दिया: रेप्लिकेशन मॉनिटर करना, पार्टिशन्स का प्रबंधन, कम्पैक्शन चलाना, बैकअप/रिस्टोर योजना बनाना, और फेल्योर सीनारियोज़ का लोड-टेस्ट करना। मजबूत ऑपरेशनल परिपक्वता वाली टीमें सबसे अधिक लाभान्वित हुईं।
वर्कलोड वास्तविकताओं के आधार पर चुनें: अपेक्षित लेटेंसी, पीक थ्रूपुट, प्रमुख क्वेरी पैटर्न, stale रीड्स के लिए सहनशीलता, और रिकवरी अपेक्षाएँ (RPO/RTO)। "सही" NoSQL विकल्प आमतौर पर वही होता है जो आपके एप्लिकेशन के विफल होने, स्केल करने और क्वेरी करने के तरीके से मेल खाता हो—न कि जो सबसे प्रभावशाली चेकलिस्ट दिखाता हो।
NoSQL चुनना डेटाबेस ब्रांड या हैप से शुरू नहीं होना चाहिए—यह आपके एप्लिकेशन को क्या करना है, यह कैसे बढ़ेगा, और आपके उपयोगकर्ताओं के लिए "सही" का क्या अर्थ है, से शुरू होना चाहिए।
डेटास्टोर चुनने से पहले लिखें:\n
अगर आप अपने एक्सेस पैटर्न्स स्पष्ट रूप से नहीं बता सकते, तो कोई भी चुनाव अनुमान होगा—खासकर NoSQL के साथ, जहाँ मॉडलिंग अक्सर पढ़ने और लिखने के तरीके के चारों ओर आकार लेती है।
व्यावहारिक संकेत: अगर आपका "कोर ट्रूथ" (orders, payments, inventory) हर समय सही होना चाहिए, उसे SQL या किसी अन्य मजबूती-प्रदान करने वाले स्टोर में रखें। अगर आप हाई-वॉल्यूम कंटेंट, सेशन्स, कैशिंग, एक्टिविटी फीड्स, या लचीले उपयोगकर्ता-जनित डेटा सर्व कर रहे हैं, तो NoSQL अच्छी तरह फिट हो सकता है।
कई टीमें कई स्टोर्स के साथ सफल होती हैं: उदाहरण के लिए, ट्रांज़ैक्शंस के लिए SQL, प्रोफाइल/कंटेंट के लिए डॉक्यूमेंट डेटाबेस, और सेशन्स के लिए की-वैल्यू स्टोर। लक्ष्य जटिलता के लिए नहीं है—बल्कि हर वर्कलोड को उस टूल से मैच करना है जो उसे साफ़-सुथरे तरीके से संभाले।
यहाँ डेवलपर वर्कफ़्लो भी मायने रखता है। अगर आप आर्किटेक्चर पर इटरेट कर रहे हैं, तो एक वर्किंग प्रोटोटाइप (API, डेटा मॉडल, UI) जल्दी से स्पिन अप कर पाना निर्णयों के जोखिम को कम कर सकता है। प्लेटफ़ॉर्म जैसे Koder.ai टीमों को चैट से पूरा-स्टैक एप्प जनरेट कर प्रोटोटाइपिंग में मदद करते हैं—आमतौर पर React फ्रंटेंड और Go + PostgreSQL बैकेंड के साथ—और फिर आपको सोर्स कोड एक्सपोर्ट करने देते हैं। भले ही आप बाद में कुछ वर्कलोड्स के लिए NoSQL स्टोर जोड़ें, एक मजबूत SQL "सिस्टम ऑफ़ रिकॉर्ड" के साथ तेज़ प्रोटोटाइपिंग, स्नैपशॉट्स और रोलबैक प्रयोगों को सुरक्षित और तेज़ बना सकते हैं।
जो कुछ भी आप चुनें, उसे साबित करें:\n
अगर आप इन परिदृश्यों का परीक्षण नहीं कर सकते, तो आपका डेटाबेस निर्णय सैद्धांतिक ही रहेगा—और प्रोडक्शन अंततः आपके लिए परीक्षण कर देगा।
NoSQL ने दो सामान्य दबावों का सामना करने के लिए जन्म लिया:
यह SQL को “खराब” साबित करने के बारे में नहीं था, बल्कि विभिन्न वर्कलोड्स अलग trade-off को प्राथमिकता देने लगे थे।
परंपरागत “scale up” रणनीति व्यवहार में सीमाओं से टकराई:
NoSQL प्रणालियाँ नोड्स जोड़कर यानी स्केल आउट करके समाधान देती हैं, बजाय बार-बार बड़े बॉक्स खरीदने के।
रिलेशनल स्कीमा जानबूझकर कठोर होते हैं—यह स्थिरता के लिए अच्छा है लेकिन तेज़ी से बदलते माहौल में दर्दनाक हो सकता है। बड़े टेबल्स पर साधारण बदलाव भी अक्सर मांगते हैं:
डॉक्यूमेंट-स्टाइल मॉडल अक्सर वैकल्पिक और विकसित होती फ़ील्ड्स को बिना भारी माइग्रेशन के संभालने में मदद करते हैं।
ज़रूरी नहीं। कई SQL डेटाबेस आउट-ऑफ़--द-बॉक्स स्केल आउट कर सकते हैं, लेकिन यह ऑपरेशनल रूप से जटिल हो सकता है (शार्डिंग, क्रॉस-शार्ड जॉइन, वितरित ट्रांज़ैक्शन)।
NoSQL प्रणालियाँ अक्सर वितरण (partitioning + replication) को एक पहली श्रेणी की डिजाइन बनाती हैं, और बड़े स्केल पर सरल, पूर्वानुमानित एक्सेस पैटर्न के लिए अनुकूलित होती हैं।
डेनॉर्मलाइजेशन डेटा को उसी आकार में स्टोर करता है जिस रूप में आप उसे पढ़ते हैं, अक्सर फ़ील्ड्स की नकल करके जॉइन्स से बचने के लिए।
उदाहरण: orders रिकॉर्ड में ग्राहक का नाम रखना ताकि “last 20 orders” एक तेज़ पढ़ाई हो सके।
ट्रेडऑफ है अपडेट जटिलता: आपको डुप्लीकेट डेटा को कहीं भी अपडेट रखना होता है—या तो एप्लिकेशन लॉजिक से या पाइपलाइनों के ज़रिए।
CAP सिद्धांत का मतलब यह है कि नेटवर्क विभाजन के समय डेटाबेस को निर्णय लेना पड़ता है:
CAP सिर्फ़ यह याद दिलाता है कि विभाजन के दौरान पूर्ण संगति और पूर्ण उपलब्धता दोनों की गारंटी नहीं दी जा सकती।
स्ट्रॉंग कंसिस्टेंसी का मतलब है कि एक बार write की पुष्टि हो जाने पर सभी readers उसे तुरंत देखेंगे; यह अक्सर नोड्स के बीच समन्वय माँगता है।
इवेंटुअल कंसिस्टेंसी का मतलब है कि प्रतियाँ थोड़ी देर तक अलग जवाब दे सकती हैं, पर समय के साथ वे समरूप हो जाती हैं। यह फीड्स, काउंटर्स और हाई-अपटाइम यूजर एक्सपीरियंस के लिए उपयुक्त हो सकता है—अगर एप्लिकेशन थोड़ी स्टेलनेस सह ले।
कॉनफ्लिक्ट तब होता है जब अलग-अलग रेप्लिकास लगभग एक ही समय में अपडेट स्वीकार कर लेते हैं। सामान्य रणनीतियाँ:
चयन इस बात पर निर्भर करता है कि उस डाटा के लिए मध्यवर्ती अपडेट खोना स्वीकार्य है या नहीं।
एक त्वरित मिलान गाइड:
अपने प्रमुख एक्सेस पैटर्न के आधार पर चुनें, लोकप्रियता पर नहीं।
शुरू करें आवश्यकताओं से और उन्हें परीक्षणों से साबित करें:
कई सिस्टम्स हाइब्रिड होते हैं: लेनदेन के लिए SQL, हाई-वॉल्यूम/लचीले डाटा के लिए NoSQL।