क्यों प्रोडक्शन फेलियर जल्दी पकड़ना मुश्किल होता है
प्रोडक्शन अक्सर एक नाटकीय “टूटने” की तरह नहीं होता। ज़्यादातर मामलों में ये धीरे-धीरे बिगड़ता है: कुछ रिक्वेस्ट टाइमआउट होने लगती हैं, बैकग्राउंड जॉब पीछे रह जाता है, CPU बढ़ता है, और ग्राहक पहले महसूस कर लेते हैं—क्योंकि आपका मॉनिटरिंग अभी भी “ग्रीन” दिखा रहा होता है।
फ़ेलियर लक्षण के रूप में दिखते हैं, कारण के रूप में नहीं
यूज़र रिपोर्ट आम तौर पर धुंधली होती है: “यह धीमा लग रहा है।” यह लक्षण दर्जनों मूल कारणों से साझा हो सकता है—डेटाबेस लॉक कंटेंशन, नया क्वेरी प्लान, मिसिंग इंडेक्स, noisy neighbor, retry storm, या कोई बाहरी डिपेंडेंसी जो इंटरमिटेंट फेल कर रही हो।
अच्छी विजिबिलिटी के बिना टीम अनुमान लगाने लगती है:
- क्या slowdown ग्लोबल है या सिर्फ एक एंडपॉइंट पर है?
- क्या यह किसी डिप्लॉय के बाद, config बदलने के बाद, या ट्रैफिक स्पाइक के बाद शुरू हुआ?
- क्या यह एप्लिकेशन है, डेटाबेस है, या उनके बीच का नेटवर्क?
आपके डैशबोर्ड वो नहीं देखते जो यूज़र महसूस करते हैं
कई टीमें एवरेज (औसत) ट्रैक करती हैं (औसत लेटेंसी, औसत CPU)। औसत दर्द छुपा देते हैं। कुछ प्रतिशत बहुत धीमी रिक्वेस्ट पूरे एक्सपीरियंस को बर्बाद कर सकती है जबकि कुल मिलाकर मैट्रिक्स ठीक दिखते हैं। और अगर आप सिर्फ "अप/डाउन" मॉनिटर करते हैं, तो आप उस लंबे समय को मिस कर देंगे जब सिस्टम टेक्निकली अप है पर प्रैक्टिकली उपयोग-योग्य नहीं है।
ऑब्ज़रवेबिलिटी + स्लो क्वेरी लॉग्स: पूरक संकेत
ऑब्ज़रवेबिलिटी मदद करती है यह पता करने में कहाँ सिस्टम बिगड़ रहा है (कौन सा सर्विस, एंडपॉइंट, या डिपेंडेंसी)। स्लो क्वेरी लॉग्स मदद करते हैं यह साबित करने में क्या डेटाबेस कर रहा था जब रिक्वेस्ट अटक गई (कौन सी क्वेरी, कितना समय लिया, और अक्सर किस तरह का काम हुआ)।
यह गाइड व्यावहारिक है: पहले चेतावनी कैसे पाएं, यूज़र-फेसिंग लेटेंसी को विशेष डेटाबेस काम से कैसे जोड़ें, और बिना वेंडर-विशिष्ट वादों पर निर्भर रहे बिना मामले को कैसे ठीक करें।
ऑब्ज़रवेबिलिटी बेसिक्स: मैट्रिक्स, लॉग्स, और ट्रेसेस
ऑब्ज़रवेबिलिटी का मतलब है सिस्टम क्या कर रहा है यह समझने के लिए उसके द्वारा बनाए गए सिग्नल्स को देख पाना—बिना अनुमान लगाए या “लोकल में रिप्रोड्यूस” करने की ज़रूरत के। यह फर्क है जानने और पिनपॉइंट करने के बीच कि लेटेंसी कहाँ हो रही है और क्यों शुरू हुई।
तीन स्तंभ (और हर एक किसके लिए अच्छा है)
मैट्रिक्स समय के साथ नंबर होते हैं (CPU %, request rate, error rate, database latency)। ये तेज़ होते हैं क्वेरी करने में और ट्रेंड्स व सडेन स्पाइक्स पकड़ने के लिए बढ़िया हैं।
लॉग्स इवेंट रिकॉर्ड होते हैं जिनमें डिटेल्स होते हैं (एक एरर मैसेज, SQL टेक्स्ट, यूज़र ID, टाइमआउट)। ये सबसे अच्छे होते हैं यह समझाने के लिए कि क्या हुआ—इंसानी पढ़ने योग्य रूप में।
ट्रेसिस एक ही रिक्वेस्ट का पीछा करते हैं जब वह सर्विसेज और डिपेंडेंसीज़ के माध्यम से चलता है (API → app → database → cache)। ये आदर्श होते हैं यह बताने के लिए कि कहाँ समय बिताया गया और किस स्टेप ने स्लोडाउन किया।
एक उपयोगी माइंडसेट: मैट्रिक्स बताते हैं कुछ गलत है, ट्रेसेस दिखाते हैं कहाँ, और लॉग्स बताते हैं बिल्कुल क्या।
अच्छी ऑब्ज़रवेबिलिटी किन सवालों के जवाब देनी चाहिए
एक स्वस्थ सेटअप आपको incidents के जवाब में स्पष्ट उत्तर देता है:
- क्या टूटा? (एरर, टाइमआउट, सैचुरेशन)
- कहाँ? (कौन सा एंडपॉइंट, सर्विस, डिपेंडेंसी, या क्वेरी)
- क्यों अभी? (डिप्लॉय, ट्रैफिक चेंज, फीचर फ्लैग, डेटा ग्रोथ)
मॉनिटरिंग बनाम ऑब्ज़रवेबिलिटी (एक आम भ्रम)
मॉनिटरिंग आमतौर पर प्री-डेफ़ाइंड चेक्स और अलर्ट्स के बारे में होती है (“CPU > 90%”)। ऑब्ज़रवेबिलिटी उससे आगे जाती है: यह आपको नए, अनपेक्षित फेलियर मोड्स की जाँच करने देती है सिग्नल्स को स्लाइस और कोर्रिलेट करके (उदाहरण: केवल एक कस्टमर सेगमेंट slow चेकआउट एक्सपीरियंस कर रहा है, जो एक विशिष्ट डेटाबेस कॉल से जुड़ा है)।
इंसिडेंट के दौरान नए सवाल पूछने की क्षमता ही कच्चे टेलीमेट्री को तेज़, शांत ट्रबलशूटिंग में बदल देती है।
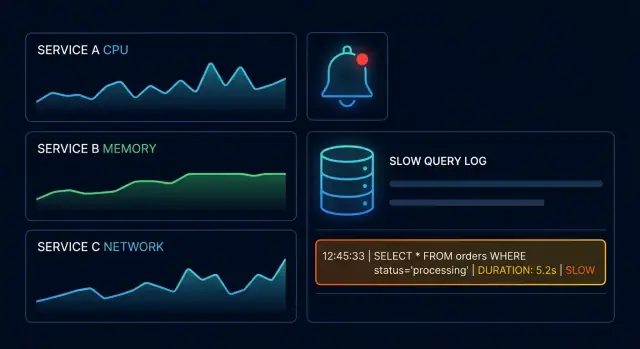
स्लो क्वेरी लॉग्स क्या होते हैं और वे क्या उजागर करते हैं
स्लो क्वेरी लॉग एक केन्द्रित रिकॉर्ड होता है उन डेटाबेस ऑपरेशन्स का जो किसी “धीमी” थ्रेशहोल्ड से ऊपर चले गए। सामान्य क्वेरी लॉगिंग (जो बेहद भारी हो सकती है) के विपरीत, यह उन स्टेटमेंट्स को हाइलाइट करता है जो यूज़र-विजिबल लेटेंसी और प्रोडक्शन incidents का कारण बनने की सबसे अधिक संभावना रखते हैं।
एक स्लो क्वेरी लॉग आमतौर पर क्या रिकॉर्ड करता है
अधिकांश डेटाबेस एक समान कोर फील्ड्स कैप्चर कर सकते हैं:
- क्वेरी (अक्सर normalised SQL टेक्स्ट)
- ड्यूरेशन (टोटल समय, कभी-कभी ब्रेकडाउन के साथ)
- टाइमस्टैम्प्स (कब शुरू और कब खत्म हुआ)
- संदर्भ जैसे डेटाबेस/यूज़र, होस्ट, एप्लिकेशन नाम, rows examined/returned, और कभी-कभी क्वेरी प्लान या प्लान हैश
यह संदर्भ ही बनाता है “यह क्वेरी धीमी थी” को “यह क्वेरी इस सर्विस के लिए, इस कनेक्शन पूल से, इस समय पर धीमी थी” में बदल देने के लिए, जो तब महत्वपूर्ण है जब एक से अधिक एप्स एक ही डेटाबेस शेयर करते हैं।
स्लो क्वेरियाँ क्यों दिखती हैं
स्लो क्वेरी लॉग्स अकेले “खराब SQL” के बारे में कम होते हैं। ये संकेत हैं कि डेटाबेस को अतिरिक्त काम करना पड़ा या वह कुछ का इंतज़ार कर रहा था। सामान्य कारणों में शामिल हैं:
- मिसिंग या अप्रभावी इंडेक्स, जिससे फुल स्कैन या महंगे जोइन होते हैं
- खराब एक्सिक्यूशन प्लान्स (अकसर पैरामीटर वैल्यूज़, outdated statistics, या प्लान कैश व्यवहार से ट्रिगर)
- लॉक वेट्स और कंटेंशन, जहाँ क्वेरी जब चलती है तो तेज़ होती है पर जब वह वेट करती है तो धीमी बन जाती है
- लोड स्पाइक्स, जहाँ एक क्वेरी जो आमतौर पर ठीक रहती है, concurrency या I/O प्रेशर में धीमी पड़ जाती है
एक सहायक माइंडसेट: स्लो क्वेरी लॉग्स दोनों को कैप्चर करते हैं—वर्क (CPU/I/O हेवी क्वेरियाँ) और वेटिंग (लॉक्स, सैचुरेटेड रिसोर्सेज)।
“धीमा” कैसे परिभाषित करें: थ्रेशहोल्ड और परसेंटाइल
एक सिंगल थ्रेशहोल्ड (उदाहरण: “500ms से ऊपर कुछ भी लॉग करो”) सरल है, पर यह तब दर्द मिस कर सकता है जब सामान्य लेटेंसी बहुत कम हो। विचार करें:
- एक फिक्स्ड थ्रेशहोल्ड ताकि सच में खराब आउट्लायर्स पकड़े जाएं
- एक परसेंटाइल-आधारित व्यू (p95/p99) अपने मॉनिटरिंग में ताकि आप regressions नोटिस कर सकें भले ही absolute times “ठीक” दिखें
यह स्लो क्वेरी लॉग को actionable रखता है जबकि आपके मैट्रिक्स ट्रेंड्स को उभारते हैं।
गोपनीयता नोट: संवेदनशील मान लॉग करने से बचें
स्लो क्वेरी लॉग्स अनजाने में व्यक्तिगत डेटा कैप्चर कर सकते हैं अगर पैरामीटर इनलाइन होते हैं (ईमेल, टोकन, IDs)। पैरामीटराइज़्ड क्वेरियाँ पसंद करें और ऐसे सेटिंग्स जो क्वेरी शेप्स को लॉग करती हों बजाय रॉ वैल्यूज़ के। जब नहीं टाला जा सके, तो अपने लॉग पाइपलाइन में मास्किंग/रेडैक्शन जोड़ें इससे पहले कि आप लॉग स्टोर या शेयर करें।
स्लो क्वेरियाँ कैसे आउटेज और यूज़र-विजिबल लेटेंसी बन जाती हैं
एक स्लो क्वेरी शायद ही "सिर्फ धीमी" बनी रहती है। सामान्य चेन कुछ इस तरह दिखती है: यूज़र लेटेंसी → API लेटेंसी → डेटाबेस प्रेशर → टाइमआउट। यूज़र इसे सबसे पहले पेज हैंग या मोबाइल स्क्रीन स्पिन के रूप में महसूस करता है। थोड़ी देर बाद, आपकी API मैट्रिक्स में response times बढ़ते हैं, भले ही एप्लिकेशन कोड नहीं बदला हो।
क्यों डेटाबेस की परेशानी ऐप समस्या लगती है
बाहरी दृष्टि से, एक धीमा डेटाबेस अक्सर “एप्लिकेशन स्लो है” के रूप में दिखाई देता है क्योंकि API थ्रेड क्वेरी के लिए ब्लॉक होता है। ऐप सर्वर्स पर CPU और मेमोरी सामान्य दिख सकती है, फिर भी p95 और p99 लेटेंसी बढ़ सकते हैं। अगर आप केवल एप-लेवल मैट्रिक्स देखते हैं, तो आप गलत संदिग्ध का पीछा कर सकते हैं—HTTP हैंडलर्स, कैशेज़, या डिप्लॉयमेंट्स—जबकि असली बॉटलनेक एक सिंगल क्वेरी प्लान हो सकता है जिसने regress किया हो।
स्लो क्वेरियाँ कैसे आउटेज में बदल जाती हैं
एक बार एक क्वेरी दगा देने लगी, सिस्टम कॉप करने की कोशिश करते हैं—और ये कॉपिंग मैकेनिज़्म फेलियर को बढ़ा सकते हैं:
- रिट्राइज़ क्लाइंट्स या इंटरनल सर्विसेज से ट्रैफ़िक को गुणा कर देते हैं, DB लोड बढ़ता है।
- कनेक्शन पूल एक्सॉस्टन होता है क्योंकि रिक्वेस्ट्स कनेक्शंस लंबे समय तक होल्ड करते हैं, नए रिक्वेस्ट्स को वेट करना पड़ता है।
- क्यू बिल्डअप जॉब वर्कर्स और मेसेज कंज्यूमर्स में बनता है क्योंकि थ्रूपुट गिरता है।
- टाइमआउट्स आ जाते हैं जो आंशिक फेल्यर्स ट्रिगर करते हैं, जो और अधिक रिट्राइज़ और duplicate work पैदा करते हैं।
एक सादा परिदृश्य
कल्पना करें एक checkout एंडपॉइंट है जो कॉल करता है SELECT ... FROM orders WHERE user_id = ? ORDER BY created_at DESC LIMIT 1. डेटा ग्रोथ की एक सीमा के बाद, इंडेक्स पर्याप्त नहीं रहा, और क्वेरी का समय 20ms से बढ़कर 800ms हो गया। सामान्य ट्रैफ़िक के तहत यह परेशान करने वाला है। पीक ट्रैफ़िक में, API रिक्वेस्ट्स DB कनेक्शंस का इंतजार करते हुए पाइल अप हो जाती हैं, 2 सेकंड पर टाइमआउट हो जाते हैं, और क्लाइंट्स रिट्राइ करने लगते हैं। मिनटों में, एक “छोटी” स्लो क्वेरी यूज़र-वीज़िबल एरर और पूरा प्रोडक्शन इनसिडेंट बन जाती है।
वे मैट्रिक्स जो जल्दी डेटाबेस दर्द की ओर इशारा करते हैं
जब डेटाबेस संघर्ष करने लगता है, पहले संकेत आमतौर पर कुछ ही मैट्रिक्स में दिखाई देते हैं। लक्ष्य सब कुछ ट्रैक करना नहीं है—यह तेजी से बदलाव पकड़ना और फिर विस्तृत जगह की तरफ़ पिवट करना है।
गोल्डन सिग्नल्स से शुरू करें
ये चार संकेत मदद करते हैं बताने में कि आप डेटाबेस इश्यू देख रहे हैं, एप्लिकेशन इश्यू देख रहे हैं, या दोनों:
- लेटेंसी: बढ़ता हुआ p95/p99 रिक्वेस्ट टाइम अक्सर सबसे जल्दी ग्राहक-देखने वाला लक्षण है।
- ट्रैफ़िक: एक ट्रैफ़िक स्पाइक कारण हो सकता है (ज़्यादा लोड) या परिणाम (रिट्राइज़ और थंडरिंग हर्ड्स)।
- एरर्स: टाइमआउट्स, 5xx, और डेटाबेस एरर कोड्स देखें।
- सैचुरेशन: एक DB “अप” हो सकता है पर सैचुरेटेड—CPU, I/O, कनेक्शन स्लॉट्स, या लॉक कंटेंशन।
कोर डेटाबेस मैट्रिक्स जो देखने चाहिए
कुछ DB-विशिष्ट चार्ट आपको बता सकते हैं क्या बॉटलनेक क्वेरी एक्सिक्यूशन का है, concurrency का है, या स्टोरेज का:
- क्वेरी लेटेंसी डिस्ट्रीब्यूशन (सिर्फ एवरेज नहीं): भारी टेल (p95/p99) और बढ़ती variance देखें।
- कनेक्शंस और पूल यूटिलाइज़ेशन: बढ़ती “एक्टिव” कनेक्शंस, पूल में कतारबंदी, या बार-बार पूल exhaustion।
- लॉक्स और वेट टाइम: लॉक वेट ड्यूरेशन और डेडलॉक्स; ये अकसर अचानक लेटेंसी जंप से कोरिलेट करते हैं।
- कैश हिट रेट / बफ़र कैश एफिशिएंसी: ड्रॉप का मतलब हो सकता है कि आपका वर्किंग सेट अब फिट नहीं हो रहा, जिससे अधिक डिस्क रीड्स होते हैं।
सर्विस-लेवल मैट्रिक्स जो DB को इम्प्लिकेट करते हैं
DB मैट्रिक्स को सर्विस के एक्सपीरियंस के साथ पेयर करें:
- रिक्वेस्ट रेट और टाइमआउट्स (अपस्ट्रीम टाइमआउट्स सहित)।
- p95/p99 लेटेंसी बाय एंडपॉइंट: एक ही एंडपॉइंट का degrade होना एक क्वेरी पैटर्न की ओर इशारा कर सकता है।
- रिट्राइ रेट: रिट्राइज़ लोड को बढ़ा सकते हैं और वास्तविक ट्रिगर को छुपा सकते हैं।
ऐसे डैशबोर्ड बनाएं जो सही सवालों का जवाब दें
डैशबोर्ड इस तरह डिजाइन करें कि जल्दी जवाब मिलें:
- क्या यह नया है? कल/पिछले हफ्ते के समान समय से तुलना करें।
- क्या यह अलग है? एक एंडपॉइंट, एक टेनेंट, एक नोड, एक AZ?
- क्या यह बढ़ रहा है? क्या सैचुरेशन ऊपर जा रहा है और क्या कतारें बन रही हैं?
जब ये मैट्रिक्स लाइन अप होते हैं—टेल लेटेंसी बढ़ना, टाइमआउट्स बढ़ना, सैचुरेशन चढ़ना—तो आपके पास स्लो क्वेरी लॉग्स और ट्रेसिंग की ओर पिवट करने का मजबूत संकेत होता है ताकि सटीक ऑपरेशन का पता लगाया जा सके।
सटीक स्लो ऑपरेशन तक रिक्वेस्ट पाथ ट्रेस करना
इन‑बिल्ट विज़िबिलिटी के साथ शिप करें
React, Go, और PostgreSQL ऐप जल्दी बनाएं और पहले दिन से ट्रेसिंग व स्लो‑क्वेरी लॉगिंग जोड़ें।
स्लो क्वेरी लॉग्स आपको डेटाबेस में क्या धीमा था बताते हैं। डिस्ट्रिब्यूटेड ट्रेसिंग बताती है किसने मांगा था, कहाँ से, और क्यों यह मायने रखता था।
हंच के बजाय रिक्वेस्ट का पालन करें
ट्रेसिंग होने पर, “डेटाबेस स्लो है” अलर्ट एक ठोस कहानी बन जाता है: एक विशिष्ट एंडपॉइंट (या बैकग्राउंड जॉब) ने कॉल्स की एक श्रृंखला ट्रिगर की, जिनमें से एक ने अपने अधिकांश समय को डेटाबेस ऑपरेशन पर बिताया।
APM UI में, उच्च-लेटेंसी ट्रेस से शुरू करें और देखें:
- उसने कौन सा रूट या जॉब नाम इनिशिएट किया (जैसे
GET /checkout या billing_reconcile_worker)।
- एक डेटाबेस स्पैन जिसमें असामान्य रूप से उच्च ड्यूरेशन या टाइम-टु-फर्स्ट-रो हो।
- क्या स्लोनेस एक रिक्वेस्ट टाइप तक सीमित है या कई तरह के अनुरोधों में फैली है।
स्पैन्स को सुरक्षित तरीके से टैग करें (बिना SQL लीक किए)
ट्रेसिस में पूरा SQL जोखिम भरा हो सकता है (PII, सीक्रेट्स, बड़े पेलोड)। एक व्यावहारिक तरीका है स्पैन्स को क्वेरी नाम / ऑपरेशन से टैग करना बजाय पूरे स्टेटमेंट के:
db.operation=SELECT और db.table=ordersapp.query_name=orders_by_customer_v2feature_flag=checkout_upsell
यह ट्रेसेस को सर्चेबल और सुरक्षित रखता है जबकि आपको कोड पाथ की ओर इशारा भी करता है।
सब कुछ IDs से कोरिलेट करें
“ट्रेस” → “ऐप लॉग्स” → “स्लो क्वेरी एंट्री” को जोड़ने का तेज़ तरीका है एक साझा पहचानकर्ता:
- एक trace ID को एप्लिकेशन लॉग्स में प्रोपेगेट करें।
- यदि संभव हो, तो स्लो क्वेरी लॉग संदर्भ में (या सुरक्षित और समर्थित होने पर क्वेरी में एक कमेंट के रूप में) trace ID (या request ID) जोड़ें।
अब आप जल्दी से उच्च-मूल्य वाले सवालों का उत्तर दे सकते हैं:
- कौन सा रूट या वर्कर स्लो कॉल ट्रिगर कर रहा था?
- क्या यह किसी विशिष्ट टेनेंट/कस्टमर, रिजन, या प्लान से जुड़ा था?
- क्या यह किसी रिलीज़ या कन्फ़िग चेंज के बाद शुरू हुआ?
- क्या यह एक महंगी क्वेरी है, या कई छोटी क्वेरियों की बर्स्ट (N+1)?
स्लो क्वेरी लॉगिंग सेटअप कैसे करें बिना डेटा में डूबे
स्लो क्वेरी लॉग्स तभी उपयोगी होते हैं जब वे पठनीय और actionable बने रहें। लक्ष्य यह नहीं है कि “हर चीज लॉग करो हमेशा”—बल्कि इतना विवरण कैप्चर करें कि यह समझा जा सके क्यों क्वेरियाँ धीमी हैं, बिना अधिक ओवरहेड या लागत की समस्या पैदा किए।
अपनी ऐप की अनुभूति के अनुसार थ्रेशहोल्ड चुनें
एक एब्सोल्यूट थ्रेशहोल्ड से शुरू करें जो यूज़र एक्सपेक्शंस और आपके DB की भूमिका को दर्शाता हो।
- एब्सोल्यूट उदाहरण: OLTP-हेवी एप्स के लिए
>200ms, मिक्सड वर्कलोड के लिए >500ms
फिर एक रिलेटिव व्यू जोड़ें ताकि आप तब भी समस्याएँ देखें जब सारा सिस्टम धीरे-धीरे स्लो हो रहा हो (और कम क्वेरियाँ हार्ड लाइन को पार कर रही हों)।
- रिलेटिव उदाहरण: “हर मिनट टॉप 100 सबसे स्लो” या “टॉप 1% सबसे स्लो स्टेटमेंट्स”
दोनों का उपयोग अंधे धब्बों से बचाता है: एब्सोल्यूट थ्रेशहोल्ड हमेशा-बुरी क्वेरियों को पकड़ेगा, जबकि रिलेटिव थ्रेशहोल्ड भी busy periods में regressions पकड़ेंगे।
समझदारी से सैंपल लें और वह संदर्भ कैप्चर करें जो वास्तव में उपयोगी होगा
पीक ट्रैफिक पर हर स्लो स्टेटमेंट लॉग करना प्रदर्शन को प्रभावित कर सकता है और शोर पैदा कर सकता है। सैंपलिंग पसंद करें (उदा., स्लो इवेंट्स का 10–20% लॉग करें) और किसी incident के दौरान अस्थायी रूप से सैंप्लिंग बढ़ाएं।
सुनिश्चित करें कि हर इवेंट में वह संदर्भ हो जिस पर आप कार्रवाई कर सकें: ड्यूरेशन, rows examined/returned, database/user, application name, और संभव हो तो request या trace ID।
क्वेरियों को नॉर्मलाइज़ करें ताकि पैटर्न स्पष्ट हों
रॉ SQL स्ट्रिंग्स गंदी होती हैं: अलग IDs और timestamps एक जैसी क्वेरी को यूनिक दिखाते हैं। क्वेरी फिंगरप्रिंटिंग (नॉर्मलाइज़ेशन) का उपयोग करें ताकि समान स्टेटमेंट्स ग्रुप हो सकें, जैसे WHERE user_id = ?।
यह आपको सवाल पूछने देता है: “किस shape की क्वेरी सबसे अधिक लेटेंसी पैदा कर रही है?” बजाय एक-ऑफ उदाहरणों के पीछे भागने के।
इन्सिडेंट्स के आसपास प्लान रिटेंशन (और लागत) व्यवस्थित करें
डिटेल्ड स्लो क्वेरी लॉग्स को पर्याप्त समय तक रखें ताकि आप "पहले बनाम बाद" की तुलना कर सकें—अक्सर 7–30 दिन एक व्यवहारिक शुरुआती बिंदु है।
यदि स्टोरेज चिंता है, तो पुराने डेटा को डाउनसैम्पल करें (एग्रेगेट्स और टॉप फिंगरप्रिंट्स रखें) जबकि हाल का फुल-फिडेलिटी लॉग कुछ समय के लिए रखें।
अलर्ट्स जो ग्राहकों की शिकायत से पहले स्लोडाउन्स पकड़ते हैं
सीखे हुए सबक को क्रेडिट में बदलें
Koder.ai के साथ बनाते हुए जो आपने सीखा वो शेयर करें और कंटेंट के लिए क्रेडिट कमाएँ।
अलर्ट्स को यह संकेत देना चाहिए "यूज़र इसे महसूस करने वाले हैं" और यह बताना चाहिए कि सबसे पहले कहाँ देखना है। सबसे आसान तरीका है कि आप उन संकेतों पर अलर्ट करें जो लक्षण (यूज़र अनुभव) और कारण (क्या इसे चला रहा है) दोनों को कवर करते हैं, साथ में नॉइज़ कंट्रोल जिससे ऑन-कॉल को लगातार बेकार पेजिंग न मिले।
लक्षणों पर अलर्ट करें (यूज़र इम्पैक्ट)
एक छोटे से हाई-सिग्नल इंडिकेटर्स से शुरू करें जो ग्राहक दर्द से कोरिलेट करते हैं:
- बढ़ता हुआ p95/p99 रिक्वेस्ट लेटेंसी महत्वपूर्ण एंडपॉइंट्स के लिए (सिर्फ एवरेज नहीं)
- टाइमआउट रेट (एप टाइमआउट्स और अपस्ट्रीम टाइमआउट्स) और रिट्राइ रेट
- क्यू डेप्थ / वर्कर सैचुरेशन (थ्रेड पूल, कनेक्शन पूल)
- डेटाबेस लॉक वेट्स और ब्लॉक्ड ट्रांज़ैक्शंस (एक आम “सब कुछ धीमा” पूर्वाग्रह)
यदि संभव हो, तो अलर्ट्स को "गोल्डन पाथ्स" (checkout, login, search) तक सीमित करें ताकि आप कम-प्राथमिकता रूट्स पर पेजिंग न करें।
कारणों पर अलर्ट करें (जांच को तेज करने वाले)
लक्षण अलर्ट के साथ कारण-उन्मुख अलर्ट पेयर करें जो निदान का समय कम करें:
- टॉप स्लो क्वेरी फिंगरप्रिंट्स किसी थ्रेशहोल्ड को पार करने पर (उदा., p95 ड्यूरेशन या कुल समय)
- प्लान चेंज्स (अचानक rows examined में वृद्धि, नए फुल टेबल स्कैन, इंडेक्स न यूज़ होना)
- डेटाबेस लेयर्स से एरर स्पाइक्स (डेडलॉक्स, बहुत अधिक कनेक्शंस, क्वेरी कैंसलेशंस)
ये कारण-अलर्ट ideally क्वेरी फिंगरप्रिंट, sanitized example parameters, और संबंधित डैशबोर्ड या ट्रेस व्यू के सीधे लिंक शामिल करें।
असली incidents मिस किए बिना नॉइज़ घटाएं
इस्तेमाल करें:
- Burn-rate अलर्ट्स SLOs के खिलाफ (तेज़ पेज तेज regressions के लिए, धीमा पेज लंबे ख़र्च के लिए)
- मल्टी-विंडो चेक्स (उदा., 5मिन और 30मिन) ताकि फ्लैपिंग से बचा जा सके
- डेडुपिंग और ग्रुपिंग (प्रति सर्विस/DB + क्वेरी फिंगरप्रिंट एक incident)
हर पेज में "अब क्या करें?" शामिल होना चाहिए—ऐसा रनबुक लिंक करें जैसे /blog/incident-runbooks और पहले तीन चेक्स निर्दिष्ट करें (लेटेंसी पैनल, स्लो क्वेरी लिस्ट, लॉक/कनेक्शन ग्राफ)।
एक व्यावहारिक इन्सिडेंट वर्कफ़्लो: स्पाइक से रूट कारण तक
जब लेटेंसी स्पाइक करे, तो तेज़ रिकवरी और लंबे आउटेज के बीच फर्क एक दोहराने योग्य वर्कफ़्लो होने से आता है। लक्ष्य है "कुछ धीमा है" से आगे बढ़कर एक विशिष्ट क्वेरी, एंडपॉइंट, और परिवर्तन तक पहुँचना जिसने उसे किया।
1) डिटेक्ट → पुष्टि करें कि यह असली है
यूज़र लक्षण से शुरू करें: उच्च रिक्वेस्ट लेटेंसी, टाइमआउट, या एरर रेट।
कई हाई-सिग्नल इंडिकेटर्स से पुष्टि करें: p95/p99 लेटेंसी, थ्रूपुट, और डेटाबेस हेल्थ (CPU, कनेक्शंस, क्यू/वेट टाइम)। सिंगल-होस्ट अनोमलीज़ का पीछा करने से बचें—सर्विस में पैटर्न की तलाश करें।
2) स्कोप → कौन और क्या प्रभावित है
ब्लास्ट रेडियस संकुचित करें:
- कौन से एंडपॉइंट्स धीमे हैं (p95 द्वारा टॉप रूट्स)?
- क्या यह सभी कस्टमर्स है या एक उपसमूह (टेनेंट, रिजन, प्लान)?
- क्या यह किसी स्पष्ट समय सीमा (डिप्लॉय, बैच जॉब, ट्रैफिक शिफ्ट) के साथ शुरू हुआ?
यह स्कोपिंग चरण आपको गलत चीज़ ऑप्टिमाइज़ करने से रोकता है।
3) आइसोलेट → स्लो ऑपरेशन खोजने के लिए ट्रेसेस का उपयोग करें
स्लो एंडपॉइंट्स के लिए डिस्ट्रिब्यूटेड ट्रेसेस खोलें और सबसे लंबी ड्यूरेशन वाले से सॉर्ट करें।
ऐसा स्पैन देखें जो रिक्वेस्ट का डोमिनेट कर रहा हो: डेटाबेस कॉल, लॉक वेट, या रिपीटेड क्वेरियाँ (N+1 व्यवहार)। ट्रेसेस को रिलीज़ वर्ज़न, टेनेंट ID, और एंडपॉइंट नाम जैसे कॉन्टेक्स्ट टैग्स से कोरिलेट करें ताकि यह दिखे कि क्या स्लोनेस किसी डिप्लॉय या खास वर्कलोड से मेल खाती है।
4) पुष्टि करें → ट्रेसेस को स्लो क्वेरी लॉग्स से जोड़ें
अब संदिग्ध क्वेरी को स्लो क्वेरी लॉग्स में मान्य करें।
"फिंगरप्रिंट्स" (नॉर्मलाइज़्ड क्वेरियाँ) पर ध्यान दें ताकि कुल समय और काउंट के आधार पर सबसे खराब अपराधियों को खोज सकें। फिर प्रभावित टेबल्स और प्रेडिकेट्स देखें (उदा., फ़िल्टर्स और जोइन्स)। यहीं अक्सर आप एक मिसिंग इंडेक्स, नया जोइन, या क्वेरी प्लान चेंज पाते हैं।
5) मिटीगेट → यूज़र इम्पैक्ट को सुरक्षित रूप से कम करें
सबसे कम जोखिम वाली मिटीगेशन पहले चुनें: रिलीज़ को रोलबैक करें, फीचर फ्लैग डिसेबल करें, लोड शेड करें, या कनेक्शन पूल लिमिट्स बढ़ाएं केवल तब जब आपको यकीन हो कि यह कंटेंशन नहीं बढ़ाएगा। अगर आपको क्वेरी बदलनी ही है तो छोटा और मापनीय बदलाव रखें।
एक व्यवहारिक टिप: अगर आपका डिलिवरी पाइपलाइन इसे सपोर्ट करता है, तो "रोलबैक" को एक फ़र्स्ट-क्लास बटन समझें, न कि हीरो मूव। प्लेटफॉर्म जैसे Koder.ai स्नैपशॉट्स और रोलबैक वर्कफ़्लोज़ के साथ इस पर ज़ोर देते हैं, जो तभी मदद करते हैं जब एक रिलीज़ ने गलती से स्लो क्वेरी पैटर्न इंट्रोड्यूस किया हो।
6) डोक्युमेंट करें → अगली बार का समय घटाएं
कैप्चर करें: क्या बदला, आपने कैसे पता लगाया, सटीक फिंगरप्रिंट, प्रभावित एंडपॉइंट्स/टेनेंट्स, और क्या फिक्स किया। इसे फॉलो-अप में बदलें: एक अलर्ट जोड़ें, एक डैशबोर्ड पैनल, और एक परफॉर्मेंस गार्ड्रेल (उदा., “कोई क्वेरी फिंगरप्रिंट p95 पर X ms से ऊपर नहीं”)।
प्रोडक्शन में स्लो क्वेरियों को सुरक्षित रूप से ठीक करना
जब एक स्लो क्वेरी पहले से ही यूज़र्स को प्रभावित कर रही हो, लक्ष्य होता है पहले इम्पैक्ट को कम करना, फिर परफॉर्मेंस सुधारना—बिना इन्सिडेंट को और बिगाड़े। ऑब्ज़रवेबिलिटी डेटा (स्लो क्वेरी सैंपल्स, ट्रेसेस, और प्रमुख DB मैट्रिक्स) बताता है कौन सा लीवर सबसे सुरक्षित है खींचने के लिए।
1) कम-जोखिम मिटीगेशंस से स्टेबलाइज़ करें
ऐसे बदलाव करें जो लोड कम करें पर डेटा व्यवहार न बदलें:
- फीचर फ्लैग्स: अस्थायी रूप से महंगे एंडपॉइंट्स, रिपोर्ट्स, सर्च फ़िल्टर्स, या “रीसेंट एक्टिविटी” पैनल जो भारी क्वेरियाँ ट्रिगर करते हैं, डिसेबल करें।
- रेट लिमिट्स / कोटा: ट्रेस में दिख रहे विशिष्ट रूट या कस्टमर सेगमेंट को थ्रॉटल करें।
- कैशिंग: रीड-हेवी एंडपॉइंट्स के लिए शॉर्ट-लाइव्ड कैशिंग जोड़ें (यहाँ तक कि 30–120 सेकेंड भी DB लोड को काफी घटा सकता है)। एप्लिकेशन-स्तरीय कैशिंग को डेटाबेस-स्तरीय बदलाव से पहले प्राथमिकता दें।
- महंगे पाथ्स डिसेबल करें: वैकल्पिक JOINs, “order by relevance”, या डीप पेजिनेशन को फ्लैग के पीछे हटाएं।
ये मिटीगेशंस समय खरीदते हैं और p95 लेटेंसी व DB CPU/IO मैट्रिक्स में तुरंत सुधार दिखाना चाहिए।
2) डेटाबेस फिक्सेस: लक्षित और टेस्टेबल
स्थिर होने पर, वास्तविक क्वेरी पैटर्न को ठीक करें:
- एक इंडेक्स जोड़ें जो क्वेरी के फ़िल्टर + sort से मेल खाता हो।
EXPLAIN के साथ वैलिडेट करें और स्कैन किए गए रो में कमी की पुष्टि करें।
- क्वेरी को फिर से लिखें ताकि स्कैन किए जाने वाले डेटा को सीमित किया जा सके (कम कॉलम चुनें,
SELECT * से बचें, सलेक्टिव प्रेडिकेट्स जोड़ें, correlated subqueries को बदलें)।
- N+1 पैटर्न घटाएँ आईडी बैचिंग करके, प्रीफेच जोड़कर, या सावधानीपूर्वक JOINs के साथ एकल क्वेरी का उपयोग करके।
बदलाव को धीरे-धीरे लागू करें और वही ट्रेस/स्पैन और स्लो क्वेरी सिग्नेचर इस्तेमाल करके सुधारों की पुष्टि करें।
3) ऑपरेशनल मिटीगेशंस जब कोड बदलना तुरंत संभव न हो
- कैपेसिटी बढ़ाएँ (रीड रेप्लिकाज़, बड़ा इंस्टेंस) ताकि रक्तस्राव रुके।
- कनेक्शन पूल ट्यून करें ताकि कतारबंदी और थ्रेड exhaustion न हो।
- टाइमआउट्स एडजस्ट करें ताकि सिस्टम तेजी से फेल करे बजाय ब्लॉक होने के।
रोलबैक: रिवर्ट बनाम हॉटफिक्स
जब चेंज एरर्स, लॉक कंटेंशन, या लोड शिफ्ट अनप्रेडिक्टेबल बढ़ाता है तो रोलबैक करें। हॉटफिक्स तब करें जब आप बदलाव को आइसोलेट कर सकें (एक क्वेरी, एक एंडपॉइंट) और आपके पास स्पष्ट पहले/बाद टेलीमेट्री हो ताकि सुरक्षित सुधार को वैलिडेट किया जा सके।
SLOs और परफॉर्मेंस गार्ड्रेल्स के साथ पुनरावृत्तियों को रोकना
खतरे वाली क्वेरीज का जल्दी प्रोटोटाइप बनाएं
एंडपॉइंट, क्वेरी और स्कीमा जेनरेट करने के लिए चैट का उपयोग करें, फिर डेटा बढ़ने पर सुरक्षित रूप से इटरेट करें।
एक बार आपने प्रोडक्शन में स्लो क्वेरी ठीक कर दी, असली जीत है यह सुनिश्चित करना कि वही पैटर्न थोड़े अलग रूप में वापस न आए। साफ़ SLOs और कुछ हल्के गार्ड्रेल्स एक इन्सिडेंट को दीर्घकालिक विश्वसनीयता में बदल देते हैं।
SLOs को उस पर बाँधें जो यूज़र महसूस करते हैं
ऐसे SLIs से शुरू करें जो सीधे ग्राहक अनुभव से जुड़ते हों:
- p95 (और p99) एंडपॉइंट लेटेंसी, प्रमुख रूट्स और टेनेंट्स के अनुसार विभाजित
- एरर रेट (टाइमआउट, 5xx, और “सॉफ्ट एरर्स” जैसे कैंसलेशंस से खाली परिणाम)
- सैचुरेशन सिग्नल्स जो स्लोडाउन्स से कोरिलेट करते हैं (DB CPU, कनेक्शन पूल वेट टाइम)
एक SLO सेट करें जो स्वीकार्य परफॉर्मेंस दर्शाता हो, न कि परफ़ेक्ट परफॉर्मेंस। उदाहरण: “p95 checkout लेटेंसी 600ms से कम रहे 99.9% मिनट्स के लिए।” जब SLO खतरे में हो, तो आपके पास जोखिम भरे डिप्लॉय रोकने और परफॉर्मेंस पर ध्यान केंद्रित करने का ऑब्जेक्टिव कारण होगा।
रिलीज़ के अनुसार रिग्रेशन को ट्रैक करें, "भावनाओं" से नहीं
अधिकांश दोहराई जाने वाली घटनाएँ रिग्रेशन होती हैं। उन्हें आसान बनाइए देखने के लिए कि कब हुआ—हर रिलीज़ के लिए पहले/बाद की तुलना करें:
- उसी एंडपॉइंट के ट्रेसेस की तुलना करें और देखें क्या कोई नया स्पैन कुल समय में हावी हो गया।
- स्लो क्वेरी फिंगरप्रिंट्स की तुलना करें (नॉर्मलाइज़्ड पैटर्न्स) ताकि नया क्वेरी शेप, मिसिंग इंडेक्स, या अचानक rows scanned में उछाल पकड़ा जा सके।
कुंजी है वितरण (p95/p99) में परिवर्तन देखना, सिर्फ एवरेज में नहीं।
क्रिटिकल पाथ्स के लिए परफॉर्मेंस टेस्ट जोड़ें
एक छोटे सेट को चुनें “जो धीमा नहीं होना चाहिए” जैसे एंडपॉइंट्स और उनके महत्वपूर्ण क्वेरीज। CI में परफॉर्मेंस चेक जोड़ें जो विफल हों जब लेटेंसी या क्वेरी कॉस्ट किसी थ्रेशहोल्ड को पार करे (एक साधारण बेसलाइन + अनुमत ड्रिफ्ट भी काम करता है)। यह N+1 बग्स, आकस्मिक फुल टेबल स्कैन, और अनबाउंडेड पेजिनेशन को शिप होने से पहले पकड़ता है।
अगर आपकी टीम जल्दी सर्विसेज बनाती है (उदाहरण के लिए, चैट-ड्रिवन ऐप बिल्डर जैसे Koder.ai, जहाँ React फ्रंटेंड्स, Go बैकएंड्स, और PostgreSQL स्कीमैस जल्दी जेनरेट और इटेरेट होते हैं), तो ये गार्ड्रेल्स और भी ज़्यादा मायने रखते हैं: स्पीड एक फीचर है, पर तभी जब आप पहले से ही टेलीमेट्री (trace IDs, query fingerprinting, और safe logging) वीड में जोड़ दें।
जिम्मेदारी और समीक्षा कैडेंस बनाएं
स्लो-क्वेरी रिव्यू किसी का काम बनाइए, न कि बाद की बात:
- हर सर्विस/डेटाबेस के लिए एक owner असाइन करें।
- साप्ताहिक कैडेंस पर स्लो क्वेरी रिपोर्ट्स रिव्यू करें (कई टीमों के लिए हफ्ते में एक बार काफी है)।
- एक छोटा बैकलॉग रखें: क्वेरी फिंगरप्रिंट, संदिग्ध कारण, अगला कार्य, और अपेक्षित प्रभाव।
SLOs यह परिभाषित करते हैं कि "अच्छा कैसा दिखता है" और गार्ड्रेल्स ड्रिफ्ट पकड़ते हैं—इस तरह परफॉर्मेंस आवर्ती आपातकाल नहीं रह जाता बल्कि डिलिवरी का प्रबंधित हिस्सा बन जाता है।
डेटाबेस के लिए ऑब्ज़रवेबिलिटी सेटअप में क्या देखें
डेटाबेस-फोकस्ड ऑब्ज़रवेबिलिटी सेटअप आपको जल्दी दो सवालों का उत्तर दे सके: "क्या डेटाबेस बॉटलनेक है?" और "किस क्वेरी (और किस कॉलर) ने इसे किया?" सबसे अच्छे सेटअप यह उत्तर स्पष्ट कर देते हैं बिना इंजीनियरों को घंटे भर के लिए कच्चे लॉग्स grep करने के लिए मजबूर किए।
एक व्यावहारिक चेकलिस्ट
आवश्यक मैट्रिक्स (आदर्श रूप से इंस्टेंस, क्लस्टर, और रोल/रिप्लिका के अनुसार ब्रोकन):
- क्वेरी लेटेंसी (p50/p95/p99), थ्रूपुट (QPS), और एरर रेट
- कनेक्शन पूल उपयोग, एक्टिव/आइडल कनेक्शंस, वेट टाइम
- लॉक्स: लॉक वेट टाइम, डेडलॉक्स, रो लॉक कंटेंशन
- रिसोर्स सिग्नल्स: CPU, मेमोरी, डिस्क I/O, कैश हिट रेश्यो
- रेप्लिकेशन लैग (यदि लागू हो)
स्लो क्वेरी लॉग्स के लिए आवश्यक लॉग फील्ड्स:
- Timestamp, duration, database/schema, user/role, client/app identifier
- Normalized query or fingerprint, plus a safe way to view the full text when permitted
- Rows examined/returned, query plan hash (if available)
ट्रेіс टैग्स जो रिक्वेस्ट को क्वेरियों से कोरिलेट करें:
- service.name, endpoint/route, environment, version
- db.system, db.name, db.statement fingerprint, db.operation
- request_id / trace_id surfaced into logs
आप जो डैशबोर्ड्स और अलर्ट्स की उम्मीद करें:
- “DB pain” ओवरव्यू: p95 लेटेंसी + QPS + कनेक्शन वेट्स + लॉक वेट्स
- टॉप N क्वेरी फिंगरप्रिंट्स बाय टोटल टाइम और बाय p95
- सतत p95/p99 वृद्धि, बढ़ते लॉक वेट्स, और पूल सैचुरेशन पर अलर्ट (सिर्फ CPU नहीं)
टूल या वेंडर से पूछने वाले सवाल
क्या यह एंडपॉइंट लेटेंसी स्पाइक को एक विशिष्ट क्वेरी फिंगरप्रिंट और रिलीज़ वर्ज़न से कोरिलेट कर सकता है? यह सैंपलिंग कैसे हैंडल करता है ताकि दुर्लभ, महंगी क्वेरियाँ आप खो न दें? क्या यह शोर वाले स्टेटमेंट्स को डेडुप्लिकेट (फिंगरप्रिंटिंग) करता है और समय के साथ regressions को हाईलाइट करता है?
डेटा हैंडलिंग जिन पर आपको समझौता नहीं करना चाहिए
इन-बिल्ट रेडैक्शन (PII और लिटरेल्स), RBAC, और लॉग्स व ट्रेसेस के लिए स्पष्ट रिटेंशन लिमिट्स देखें। सुनिश्चित करें कि डेटा को आपके वेयरहाउस/SIEM में एक्सपोर्ट करना उन नियंत्रणों को बायपास न करे।
यदि आपकी टीम विकल्पों का मूल्यांकन कर रही है, तो प्रारम्भिक रूप से आवश्यकताओं को संरेखित करना मदद करता है—इन्टर्नली एक शॉर्टलिस्ट साझा करें, फिर वेंडर्स को शामिल करें। अगर आप चाहते हैं, तो एक त्वरित तुलना या मार्गदर्शन के लिए /pricing देखें या /contact के जरिए संपर्क करें।