12 नव॰ 2025·8 मिनट
गैर‑लाभकारी लैब से AI नेतृत्व तक: OpenAI का इतिहास
OpenAI के इतिहास का अन्वेषण: 2015 के गैर‑लाभकारी आरंभ से लेकर GPT‑3, GPT‑4, ChatGPT के लॉन्च और संगठनात्मक, रणनीतिक व सुरक्षा‑संबंधी विकास तक की प्रमुख मील‑पत्थर।
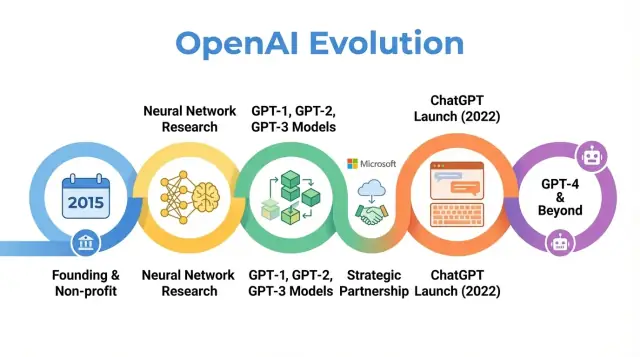
अवलोकन: OpenAI का इतिहास क्यों मायने रखता है
OpenAI एक AI अनुसंधान और परिनियोजन कंपनी है जिसकी गतिविधियाँ शुरुआती शोध पत्रों से लेकर ChatGPT जैसे उत्पादों तक इस बात को प्रभावित करती हैं कि लोग कृत्रिम बुद्धिमत्ता के बारे में कैसे सोचते हैं। यह समझना कि OpenAI कैसे विकसित हुआ—2015 की एक छोटी गैर‑लाभकारी लैब से लेकर AI के एक केंद्रीय खिलाड़ी बनने तक—इस बात को स्पष्ट करता है कि आधुनिक AI आज क्यों और किस तरह दिखाई देता है।
OpenAI की कहानी केवल मॉडलों के रिलीज़ का क्रम नहीं है। यह मिशन, प्रोत्साहन, तकनीकी सफलता और सार्वजनिक दबाव किस तरह परस्पर क्रिया करते हैं इसका अध्ययन भी है। संगठन ने शुरुआती दिनों में खुला शोध और व्यापक लाभ पर जोर दिया, फिर पूँजी आकर्षित करने के लिए पुनर्गठन किया, Microsoft के साथ गहन साझेदारी बनाई, और सैकड़ों मिलियन उपयोगकर्ताओं वाले उत्पाद लॉन्च किए।
यह इतिहास क्यों महत्वपूर्ण है
OpenAI का इतिहास निम्न व्यापक रुझानों को उजागर करता है:
-
मिशन और मूल्य: OpenAI की शुरुआत का लक्ष्य यह सुनिश्चित करना था कि AGI सभी मानवता के लिए लाभकारी हो। समय के साथ इस मिशन की व्याख्या और संशोधन इस बात को दिखाते हैं कि आदर्शवादी लक्ष्यों और व्यावसायिक वास्तविकताओं के बीच तनाव कैसे बनते हैं।
-
अनुसंधान सफलता: प्रारम्भिक परियोजनाओं से लेकर GPT‑3, GPT‑4, DALL·E और Codex जैसे सिस्टमों तक का विकास बड़े‑पैमाने के फाउंडेशन मॉडलों की ओर एक व्यापक शिफ्ट को दर्शाता है जो आज कई AI अनुप्रयोगों को शक्ति देते हैं।
-
शासन एवं संरचना: शुद्ध गैर‑लाभकारी से सीमित‑लाभ इकाई में परिवर्तन और जटिल शासन तंत्रों का निर्माण इस बात को दिखाता है कि शक्तिशाली तकनीकों का प्रबंधन करने के लिए नए संगठनात्मक रूपों का प्रयोग हो रहा है।
-
सार्वजनिक प्रभाव और जांच: ChatGPT और अन्य रिलीज़ के साथ OpenAI एक ऐसे नाम में बदल गया जो शोध‑वृत के बाहर भी घर‑घर में जाना जाता है, जिससे सुरक्षा, संरेखण और नियमन की बहसें तीव्र हुईं जो अब वैश्विक नीतिगत चर्चाओं को आकार देती हैं।
यह लेख 2015 से लेकर हालिया विकास तक OpenAI की यात्रा का पालन करता है, दिखाते हुए कि हर चरण AI अनुसंधान, अर्थशास्त्र और शासन में व्यापक बदलावों को कैसे प्रतिबिंबित करता है—और इससे क्षेत्र के भविष्य के लिए क्या अर्थ निकलते हैं।
OpenAI की स्थापना: मिशन और शुरुआती टीम
2015 का AI क्षण
OpenAI की स्थापना दिसंबर 2015 में हुई, उस समय मशीन लर्निंग—विशेषकर डीप लर्निंग—तेजी से सुधर रहा था पर अभी भी सामान्य बुद्धिमत्ता तक दूर था। छवि मान्यता बेंचमार्क गिर रहे थे, स्पीच सिस्टम बेहतर हो रहे थे, और Google, Facebook, Baidu जैसे कंपनियाँ AI में भारी निवेश कर रही थीं।
शोधकर्ताओं और टेक नेताओं के बीच एक बढ़ती चिंता थी कि उन्नत AI कुछ शक्तिशाली निगमों या सरकारों के नियंत्रण में सीमित रह सकता है। OpenAI को एक प्रतिरोधक के रूप में सोचा गया: एक ऐसा अनुसंधान संगठन जो संकुचित व्यावसायिक लाभ के बजाय दीर्घकालिक सुरक्षा और AI के लाभों के व्यापक वितरण पर केन्द्रित हो।
मिशन: सभी के लाभ के लिए AGI
शुरू से ही OpenAI ने अपना मिशन आर्टिफिशियल जनरल इंटेलिजेंस (AGI) के संदर्भ में परिभाषित किया, न कि केवल मशीन लर्निंग की क्रमिक प्रगति तक सीमित। मुख्य कथन यह था कि OpenAI यह सुनिश्चित करने के लिए काम करेगा कि यदि AGI बनाई जाए तो वह “पूरी मानवता के लिए लाभकारी” हो।
इस मिशन के कुछ ठोस निहितार्थ थे:
- सुरक्षा अनुसंधान और दीर्घकालिक संरेखण प्रश्नों को प्राथमिकता देना
- जहाँ संभव हो शोध, कोड और अंतर्दृष्टियाँ व्यापक रूप से साझा करने की प्रतिबद्धता
- जीत‑लेने‑वाला प्रतिस्पर्धात्मक ढांचे से बचने के लिए अन्य संस्थाओं के साथ सहयोग करना
प्रारम्भिक सार्वजनिक ब्लॉग पोस्ट और संस्थापकीय चार्टर दोनों ने खुलापन और सावधानी दोनों पर ज़ोर दिया: OpenAI अपने काम का बहुत कुछ प्रकाशित करेगा, पर शक्तिशाली क्षमताओं के जारी करने के सामाजिक प्रभाव पर विचार करेगा।
संस्थापक, शुरुआती नेतृत्व और संरचना
OpenAI की शुरुआत एक गैर‑लाभकारी अनुसंधान लैब के रूप में हुई। आरंभिक वित्तीय प्रतिबद्धताओं को लगभग $1 बिलियन के वादे के रूप में घोषित किया गया था, हालांकि यह एक दीर्घकालिक वादा था न कि अग्रिम नकदी। प्रमुख प्रारम्भिक समर्थकों में Elon Musk, Sam Altman, Reid Hoffman, Peter Thiel, Jessica Livingston, और YC Research शामिल थे, साथ ही Amazon Web Services और Infosys जैसी कंपनियों का समर्थन भी रहा।
शुरुआती नेतृत्व टीम में स्टार्टअप, शोध और संचालन का मिश्रण था:
- Sam Altman – सह‑संस्थापक और प्रारम्भिक बोर्ड चेयर (बाद में CEO)
- Elon Musk – सह‑संस्थापक और प्रारम्भिक दौर में दाता एवं बोर्ड सदस्य
- Greg Brockman – पूर्व Stripe CTO, CTO और सह‑संस्थापक के रूप में शामिल
- Ilya Sutskever – प्रमुख डीप लर्निंग शोधकर्ता, मुख्य वैज्ञानिक के रूप में
- Wojciech Zaremba और John Schulman – सह‑संस्थापक और मुख्य शोध नेता
यह सिलिकॉन वैली उद्यमिता और शीर्ष‑स्तरीय AI शोध का मिश्रण OpenAI की शुरुआती संस्कृति को आकार देता था: AI क्षमताओं को आगे बढ़ाने के लिए बहुत महत्त्वाकांक्षी, पर दीर्घकालिक वैश्विक प्रभाव पर केंद्रित गैर‑लाभकारी रूप में आयोजित।
गैर‑लाभकारी युग: शुरुआती शोध और खुला विज्ञान
2015 में OpenAI के एक गैर‑लाभकारी अनुसंधान लैब के रूप में लॉन्च होने पर सार्वजनिक वादा सरल पर महत्वाकांक्षी था: कृत्रिम बुद्धिमत्ता को आगे बढ़ाना और जहां तक संभव हो व्यापक समुदाय के साथ साझा करना।
डिफ़ॉल्ट रूप से खुलापन
प्रारम्भिक वर्षों को “डिफ़ॉल्ट रूप से खुला” दर्शन पर परिभाषित किया गया। शोध पत्र जल्दी पोस्ट किए जाते थे, कोड आमतौर पर जारी किया जाता था, और आंतरिक टूल सार्वजनिक परियोजनाओं में बदल दिए जाते थे। विचार यह था कि व्यापक वैज्ञानिक प्रगति और जांच को तेज़ करना एक ही कंपनी के भीतर क्षमताओं के केंद्रीकरण से अधिक सुरक्षित और लाभकारी होगा।
Saath hi, सुरक्षा पहले से ही बातचीत का हिस्सा थी। टीम ने चर्चा की कि कब खुलापन दुरुपयोग जोखिम बढ़ा सकता है और चरणबद्ध रिलीज़ तथा नीति समीक्षा के विचार बनाना शुरू किए—हालाँकि वे विचार बाद में विकसित होने वाले शासन प्रक्रियाओं की तुलना में अभी तक अनौपचारिक थे।
प्रमुख शोध क्षेत्र
OpenAI का प्रारम्भिक वैज्ञानिक फोकस कई कोर क्षेत्रों में फैला था:
- रिइन्फोर्समेंट लर्निंग (RL): Dota 2 जैसे खेलों में एजेंटों की महारत और जटिल नियंत्रण कार्यों पर काम ने RL एल्गोरिदम, अन्वेषण विधियों और स्केलेबिलिटी को आगे बढ़ाया।
- रोबोटिक्स: रोबोट हाथों पर प्रयोगों ने प्रदर्शित किया कि कैसे RL और सिमुलेशन को भौतिक दुनिया में ट्रांसफ़र किया जा सकता है।
- अनसुपरवाइज़्ड और सेल्फ‑सुपरवाइज़्ड लर्निंग: शोधकर्ताओं ने बड़े, अनलेबल्ड डेटासेट्स से मॉडल कैसे सीख सकते हैं, इस पर काम किया, जो बाद के फाउंडेशन मॉडलों का मार्ग प्रशस्त कर गया।
ये परियोजनाएँ परिष्कृत उत्पादों से ज़्यादा इस पर केन्द्रित थीं कि डीप लर्निंग, कंप्यूट और चतुर प्रशिक्षण रेजीम के साथ क्या संभव है।
समुदाय को आकार देने वाले टूल
इस युग के दो सबसे प्रभावशाली आउटपुट थे OpenAI Gym और Universe।
- OpenAI Gym ने RL परिवेशों और बेंचमार्क का एक सामान्य सेट प्रदान किया। इससे शोधकर्ताओं के लिए एल्गोरिदम की तुलना करना मानकीकृत हुआ और नए लैबों और छात्रों के लिए बाधा कम हुई।
- Universe का उद्देश्य एजेंटों को मौजूदा सॉफ़्टवेयर परिवेशों पर प्रशिक्षित और आकलित करना था, खेलों से लेकर वेब ऐप्स तक। हालांकि Universe अंततः सेवानिवृत्त हुआ, उसने सामान्य‑उद्देश्य एजेंटों में उत्साह को सघन किया।
दोनों परियोजनाएँ साझा अवसंरचना के प्रति प्रतिबद्धता को दर्शाती हैं, न कि स्वामित्व‑आधारित लाभ को।
सहकर्मियों और मीडिया की दृष्टि
नॉन‑प्रॉफिट अवधि के दौरान, OpenAI को अक्सर बड़े तकनीकी फर्मों के AI लैबों के मुकाबले एक मिशन‑चालित प्रतिरोधक के रूप में चित्रित किया जाता था। सहकर्मियों ने इसके शोध की गुणवत्ता, कोड और परिवेशों की उपलब्धता, और सुरक्षा चर्चाओं में भागीदारी की सराहना की।
मीडिया कवरेज ने उच्च‑प्रोफ़ाइल फंडर्स, गैर‑वाणिज्यिक संरचना और खुले प्रकाशन के वादे के असामान्य संयोजन को उजागर किया। इस प्रतिष्ठा—एक प्रभावशाली, खुले शोध लैब के रूप में जो दीर्घकालिक परिणामों के प्रति चिंतित है—ने बाद के हर रणनीतिक बदलाव पर प्रतिक्रियाओं को आकार दिया।
शक्तिशाली मॉडल बनाना: GPT‑1 से GPT‑3 तक
OpenAI के इतिहास में निर्णायक मोड़ तब आया जब संगठन ने बड़े ट्रांसफॉर्मर‑आधारित भाषा मॉडलों पर ध्यान केंद्रित करने का निर्णय लिया। इस शिफ्ट ने OpenAI को एक मूलभूत मॉडल प्रदाता के रूप में बदल दिया जिस पर अन्य लोग निर्माण करते हैं।
GPT‑1: ट्रांसफॉर्मर विचार का प्रमाण (2018)
GPT‑1 बाद के मानकों से छोटे पैमाने का था—117 मिलियन पैरामीटर, BookCorpus पर प्रशिक्षित—पर यह एक महत्वपूर्ण प्रमाण‑अवधार था।
विविध NLP कार्यों के लिए अलग‑अलग मॉडल प्रशिक्षण की बजाय GPT‑1 ने दिखाया कि एक ही ट्रांसफॉर्मर मॉडल, एक साधारण उद्देश्य (अगला शब्द भविष्यवाणी) के साथ प्रशिक्षित होकर, न्यूनतम फाइन‑ट्यूनिंग के साथ प्रश्न उत्तर, सेंटिमेंट विश्लेषण और टेक्स्चुअल एंटेलमेंट जैसे कार्यों में अनुकूल किया जा सकता है।
OpenAI के आंतरिक रोडमैप के लिए, GPT‑1 ने तीन विचार मान्य किए:
- पैमाना मायने रखता है: बड़े मॉडल और अधिक डेटा अप्रत्याशित रूप से बेहतर प्रदर्शन करते हैं।
- प्री‑ट्रेनिंग + फाइन‑ट्यूनिंग कार्य‑विशिष्ट प्रणालियों को मात दे सकते हैं।
- ट्रांसफॉर्मर्स भाषा के लिए शक्तिशाली आर्किटेक्चर हैं।
GPT‑2: क्षमताएँ और दुरुपयोग चिंताएँ (2019)
GPT‑2 ने उसी मूल विधि को बहुत आगे बढ़ाया: 1.5 बिलियन पैरामीटर और वेब‑आधारित बड़े डेटासेट पर प्रशिक्षण। इसके आउटपुट अक्सर आश्चर्यजनक रूप से सुसंगत होते थे: बहु‑पैराग्राफ़ लेख, काल्पनिक कहानियाँ, और सारांश जो देखने में मानवीय लेखन जैसे लगते थे।
इन क्षमताओं ने दुरुपयोग के संभावित खतरे उठाए: स्वचालित प्रचार, स्पैम, उत्पीड़न और बड़े पैमाने पर फेक न्यूज़। OpenAI ने पूर्ण मॉडल तुरंत जारी न करके चरणबद्ध रिलीज़ नीति अपनाई:
- प्रारम्भिक छोटे मॉडल का रिलीज, साथ में तकनीकी पेपर और उदाहरण
- दुरुपयोग की खोज के लिए आंतरिक और बाह्य रेड‑टीमिंग जारी रखना
- OpenAI जोखिमों का आकलन करने के बाद बड़े संस्करणों को क्रमशः जारी करना
यह OpenAI का पहली बार स्पष्ट उदाहरण था कि परिनियोजन निर्णयों को सुरक्षा और सामाजिक प्रभाव से जोड़ा जा रहा है, और इसने संगठन के खुलापन और जिम्मेदारी के बारे में सोचने के तरीके को आकार दिया।
GPT‑3: पैमाना, सामान्यता और API (2020)
GPT‑3 ने फिर से पैमाने को बढ़ाया—इस बार 175 बिलियन पैरामीटर तक। यह मुख्य रूप से फाइन‑ट्यूनिंग पर निर्भर रहने की बजाय “फ्यू‑शॉट” और यहाँ तक कि “ज़ीरो‑शॉट” सीखने को प्रदर्शित करता था: मॉडल अक्सर केवल प्रॉम्प्ट में निर्देशों और कुछ उदाहरणों से ही एक नया कार्य कर सकता था।
उस स्तर की सामान्यता ने OpenAI और व्यापक उद्योग के सोचने के तरीके को बदल दिया। कई संकीर्ण मॉडलों के निर्माण के बजाय, एक बड़ा मॉडल कई उपयोग‑केसों का सामान्य‑उद्देश्य इंजन बन सकता था:
- कॉपीराइटिंग और सामग्री निर्माण
- कोड स्निपेट और ऑटोकम्प्लीट
- प्रश्न‑उत्तर, चैट और खोज समर्थन
निश्चित रूप से, OpenAI ने GPT‑3 को ओपन‑सोर्स न करके वाणिज्यिक API के माध्यम से पहुंच प्रदान की। इस निर्णय ने रणनीतिक मोड़ को चिह्नित किया:
- मॉडलों को प्रकाशित करने से उन्हें एक प्रबंधित सेवा के रूप में चलाने की ओर
- शुद्ध अनुसंधान लैब से प्लेटफ़ॉर्म प्रदाता में परिवर्तन
- OpenAI के मॉडलों पर बनने वाले डेवलपर इकोसिस्टम की नींव रखना
GPT‑1, GPT‑2 और GPT‑3 ने OpenAI के इतिहास में एक स्पष्ट मार्ग रेखांकित किया: ट्रांसफॉर्मर्स का स्केलिंग, उभरती क्षमताओं की खोज, सुरक्षा और दुरुपयोग से जुड़ी जद्दोजहद, और ChatGPT तथा GPT‑4 जैसी सेवाओं के लिए व्यावसायिक बुनियाद रखना।
संगठन का पुनर्गठन: OpenAI LP और सीमित‑लाभ मॉडल
2018 तक OpenAI के नेताओं का विश्वास मजबूत हो गया था कि छोटी दान‑निधि वाली लैब बने रहना बहुत बड़े AI सिस्टमों का निर्माण और सुरक्षित मार्गदर्शन करने के लिए पर्याप्त नहीं होगा। फ्रंटियर मॉडल्स का प्रशिक्षण पहले से ही दसियों मिलियन डॉलर के कंप्यूट और प्रतिभा की मांग कर रहा था, और लागत घात स्पष्ट रूप से और भी ऊँचा जाने की ओर इशारा कर रहा था। शीर्ष शोधकर्ताओं को आकर्षित करने, बड़े प्रयोग करने और क्लाउड अवसंरचना तक दीर्घकालिक पहुंच सुनिश्चित करने के लिए OpenAI को ऐसी संरचना की जरूरत थी जो निवेश आकर्षित कर सके बिना मूल मिशन को त्यागे।
OpenAI LP क्यों बनाया गया
2019 में OpenAI ने OpenAI LP, एक नया "सीमित‑लाभ" लिमिटेड पार्टनरशिप लॉन्च की। लक्ष्य बड़ा बाहरी निवेश अनलॉक करना था, जबकि गैर‑लाभकारी के मिशन—यह सुनिश्चित करना कि AGI पूरी मानवता के लिए लाभकारी हो—निर्णय‑प्रक्रिया में शीर्ष रहे।
पारंपरिक वेंचर‑बैक्ड स्टार्टअप अंततः शेयरधारकों के प्रति जवाबदेह होते हैं जो अनकट रिटर्न चाहते हैं। OpenAI के संस्थापकों को चिंता थी कि ऐसा दबाव सुरक्षा, खुलापन या सावधान परिनियोजन की तुलना में मुनाफ़े को प्राथमिकता दे सकता है। LP संरचना एक समझौता थी: यह इक्विटी‑समान हित जारी कर सकती थी और बड़े पैमाने पर धन जुटा सकती थी, पर अलग नियमों के तहत।
सीमित‑लाभ मॉडल कैसे काम करता है
सीमित‑लाभ मॉडल में, निवेशक और कर्मचारी OpenAI LP में अपनी हिस्सेदारी पर रिटर्न कमा सकते हैं, पर केवल उनके मूल निवेश के एक निर्धारित गुणक तक (प्रारम्भिक निवेशकों के लिए अक्सर 100x तक, बाद के ट्रैंच में कम कैप के साथ)। एक बार वह कैप पार हो जाने पर, अतिरिक्त अधिक‑मूल्य nonprofit माता‑संस्था की ओर जाना माना गया ताकि उसे उसके मिशन के अनुरूप उपयोग किया जा सके।
यह पारंपरिक स्टार्टअप्स से काफी अलग है, जहाँ इक्विटी का मूल्य सैद्धांतिक रूप से अनसीमित बढ़ सकता है और शेयरधारक मूल्य बढ़ाना कानूनी व सांस्कृतिक प्राथमिकता होती है।
गैर‑लाभकारी और LP के बीच संबंध
OpenAI Nonprofit नियंत्रणकारी संस्था बनी रही। इसका बोर्ड OpenAI LP की देखरेख करता है और मिशन को किसी विशेष समूह के हितों पर प्राथमिकता देने के लिए चार्टर्ड है।
औपचारिक रूप से:
- गैर‑लाभकारी OpenAI LP में नियंत्रणकारी हिस्सेदारी रखती है।
- गैर‑लाभकारी बोर्ड प्रमुख नेतृत्व नियुक्त करता है और सिद्धांततः उन निर्णयों को ओवरराइड कर सकता है जो मिशन के प्रति टकराव करते हैं।
- फिड्यूशियरी कर्तव्य nonprofit चार्टर के इर्द‑गिर्द फ्रेम किया गया है, न कि शुद्ध वित्तीय अनुकूलन के इर्द‑गिर्द।
यह शासन डिज़ाइन OpenAI को वाणिज्यिक संगठन की तरह धन जुटाने और भर्ती की लचीलापन देने के लिए बनाया गया था जबकि मिशन‑पहले नियंत्रण बनाए रखने का दावा भी करता है।
बहसें और धन तथा भर्ती पर प्रभाव
पुनर्गठन ने संगठन के भीतर और बाहर बहस को जन्म दिया। समर्थकों ने कहा कि यह सीमित‑लाभ संरचना अवसरहीन थी ताकि कटिंग‑एज AI शोध के लिए आवश्यक अरबों की पूँजी सुरक्षित की जा सके जबकि मुनाफ़ा‑ प्रेरित दवाबों को सीमित रखा जा सके। आलोचकों ने पूछा कि क्या कोई भी ऐसी संरचना जो बड़े रिटर्न की पेशकश करती है, वाकई में वाणिज्यिक दबाव का विरोध कर पाएगी, और क्या कैप पर्याप्त रूप से कम हैं या उनका स्पष्ट रूप से पालन होगा।
व्यवहारिक रूप से, OpenAI LP ने बड़े रणनीतिक निवेशों के द्वार खोल दिए, सबसे उल्लेखनीय Microsoft का निवेश, और प्रतिस्पर्धात्मक वेतन पैकेज देने की क्षमता दी। इससे OpenAI ने शोध टीमों का पैमाना बढ़ाया, GPT‑3 और GPT‑4 जैसे मॉडलों के लिए प्रशिक्षण रन विस्तारित किए, और ChatGPT जैसे सिस्टमों को वैश्विक पैमाने पर परिनियोजित करने के लिए आवश्यक अवसंरचना बनाई—सभी जबकि औपचारिक रूप से गैर‑लाभकारी जड़ों के साथ शासन संबंध बनाए रखा।
Microsoft के साथ रणनीतिक साझेदारी
रेफर करके क्रेडिट पाएं
टीममेट्स या दोस्तों को इनवाइट करें और रेफरल के ज़रिए क्रेडिट कमाएँ।
2019 का निवेश और दीर्घकालिक समझौता
2019 में OpenAI और Microsoft ने एक बहु‑वर्षीय साझेदारी की घोषणा की जिसने दोनों कंपनियों की AI भूमिकाओं को नया आकार दिया। Microsoft ने अनुमानित $1 बिलियन का निवेश किया, जिसमें नकद और Azure क्लाउड क्रेडिट शामिल थे, जिसके बदले में वह OpenAI का पसंदीदा वाणिज्यिक साझेदार बन गया।
यह सौदा OpenAI की बढ़ती मॉडलों को प्रशिक्षित करने के लिए विशाल कंप्यूट संसाधनों की जरूरत और Microsoft को उन्नत AI तक पहुँच प्रदान करने की दोनों आवश्यकताओं के साथ मेल खाता था। अगले वर्षों में यह संबंध अतिरिक्त वित्तपोषण और तकनीकी सहयोग के माध्यम से और गहरा हुआ।
Azure को OpenAI का क्लाउड बैकबोन बनाना
OpenAI ने Microsoft Azure को अपना प्राथमिक क्लाउड प्लेटफ़ॉर्म चुना, कुछ कारणों से:
- पैमाना और कस्टम हार्डवेयर: Azure ने हजारों GPUs (और बाद में कस्टम एक्सेलेरेटर) वाले विशेष क्लस्टर्स बनाने का वादा किया जो बड़े‑पैमाने के प्रशिक्षण के लिए अनुकूलित थे।
- को‑इंजीनियरिंग: OpenAI के इंजीनियर Azure टीमों के साथ मिलकर नेटवर्किंग, स्टोरेज और ऑर्केस्ट्रेशन को बड़े भाषा मॉडलों के लिए अनुकूलित करते रहे।
- वित्तीय संरचना: निवेश और क्लाउड क्रेडिट ने उन प्रयोगों की प्रारम्भिक लागत घटाई जो अन्यथा महंगे होते।
इसने Azure को GPT‑3, Codex और बाद के GPT‑4 जैसे मॉडल को प्रशिक्षित करने और सर्व करने के लिए डिफ़ॉल्ट वातावरण बना दिया।
सुपरकम्प्यूटिंग अवसंरचना का सह‑विकास
साझेदारी ने OpenAI के वर्कलोड्स के लिए Azure पर दुनिया की एक बड़ी AI सुपरकम्प्यूटिंग प्रणाली बनाने में मदद की। Microsoft ने इन क्लस्टर्स को Azure की AI क्षमताओं के प्रमुख उदाहरण के रूप में उजागर किया, जबकि OpenAI ने उन्हें मॉडल के पैमाने और प्रयोगों को आगे बढ़ाने के लिए भरोसा किया।
यह संयुक्त अवसंरचना ग्राहक और साझेदार के बीच की रेखा को धुंधला कर गई: OpenAI ने प्रभावी रूप से Azure की AI रोडमैप पर प्रभाव डाला, और Azure OpenAI की आवश्यकताओं के अनुरूप ट्यून किया गया।
लाइसेंसिंग, उत्पाद और सार्वजनिक धारणा
Microsoft ने कुछ OpenAI तकनीकों के विशिष्ट लाइसेंस प्राप्त किए, विशेषकर GPT‑3। इससे Microsoft इन मॉडलों को अपने उत्पादों—Bing, Office, GitHub Copilot, Azure OpenAI Service—में एम्बेड कर सका, जबकि अन्य कंपनियाँ OpenAI की अपनी API के माध्यम से इनसे जुड़ीं।
यह विशिष्टता बहस का विषय बनी: समर्थकों का तर्क था कि इससे शक्तिशाली AI को सुरक्षित रूप से स्केल करने के लिए आवश्यक फंडिंग और वितरण मिला; आलोचकों का कहना था कि इससे सीमांत मॉडल पर एक बड़ी टेक कंपनी का प्रभाव केंद्रीकृत हो गया।
साथ ही, साझेदारी ने OpenAI को मुख्यधारा की दृश्यता दी। Microsoft के ब्रांडिंग, उत्पाद एकीकरण और एंटरप्राइज़ सेल्स चैनल ने OpenAI सिस्टमों को शोध डेमो से रोज़मर्रा के उपकरणों में बदलने में मदद की, जिससे सार्वजनिक धारणा में OpenAI को एक स्वतंत्र लैब और Microsoft के मुख्य AI साझेदार दोनों के रूप में देखा गया।
टेक्स्ट से परे ब्रेकथ्रू: DALL·E, CLIP और Codex
जैसे‑जैसे OpenAI के मॉडल भाषा को समझने और जनरेट करने में बेहतर हुए, टीम ने नई मोडॅलिटीज़—इमेज और कोड—में भी कदम रखा। इस शिफ्ट ने OpenAI के कार्य को लेखन और संवाद से दृश्य रचनात्मकता और सॉफ़्टवेयर विकास तक फैला दिया।
CLIP: छवि और भाषा को जोड़ना
CLIP (Contrastive Language–Image Pretraining), जिसे पहली बार 2021 में घोषित किया गया, उन मॉडलों की ओर एक बड़ा कदम था जो मनुष्यों की तरह दुनिया को समझने का प्रयास करते हैं।
CLIP ने केवल लेबल वाली छवियों पर प्रशिक्षण लेने के बजाय सार्वजनिक वेब से सैकड़ों मिलियन इमेज‑कैप्शन जोड़ों से सीखा। इसे यह सिखाया गया कि छवियों को उनके सबसे संभावित टेक्स्ट विवरणों के साथ मेल करना है और उन्हें गलत विवरणों से अलग करना है।
इसने CLIP को आश्चर्यजनक रूप से सामान्य क्षमताएँ दीं:
- बिना कार्य‑विशिष्ट प्रशिक्षण के ऑब्जेक्ट और शैलियों को पहचानना
- प्राकृतिक‑भाषा प्रॉम्प्ट का पालन करके वर्गीकृत करना (उदा., “एक टैबी बिल्ली की फोटो”)
- अन्य सिस्टमों के लिए एक लचीला विज़ुअल बैकबोन के रूप में काम करना
CLIP बाद की जेनरेटिव इमेज वर्क का आधार बन गया।
DALL·E और DALL·E 2: टेक्स्ट‑टू‑इमेज रचनात्मकता
DALL·E (2021) ने GPT‑शैली आर्किटेक्चर को छवियों पर लागू किया, टेक्स्ट प्रॉम्प्ट से सीधे तस्वीरें जनरेट कीं: “एवोकाडो के आकार की आर्मचेयर” या “एक स्टोरफ्रंट साइन जिस पर ‘openai’ लिखा है” जैसे निर्देशों पर। यह दिखा कि भाषा मॉडल को इमेज जनरेशन के लिए भी बढ़ाया जा सकता है।
DALL·E 2 (2022) ने रिज़ॉल्यूशन, यथार्थवाद और नियंत्रण में काफी सुधार किया। इसमें ऐसी क्षमताएँ आईं जैसे:
- इनपेंटिंग: टेक्स्ट से किसी मौजूदा छवि के हिस्से को संपादित करना
- आउटपेंटिंग: एक छवि को उसके मूल बॉर्डर्स के बाहर विस्तारित करना
- शैली और संरचना नियंत्रण: विस्तृत प्रॉम्प्ट से आउटपुट को निर्देशित करना
इन प्रणालियों ने डिजाइनरों, विपणक, कलाकारों और शौकिया उपयोगकर्ताओं के लिए विचारों का प्रोटोटाइप बनाना बदल दिया, रचनात्मक कार्य का कुछ हिस्सा मैन्युअल ड्राफ्टिंग से प्रॉम्प्ट‑चालित अनुक्रमिक खोज में बदल गया।
Codex और सॉफ़्टवेयर विकास का भविष्य
Codex (2021) ने GPT‑3 परिवार को स्रोत कोड के लिए अनुकूलित किया, बड़े सार्वजनिक कोडबेस पर प्रशिक्षण लेकर। यह प्राकृतिक भाषा को कार्यशील स्निपेट में परिवर्तित कर सकता है—Python, JavaScript और अन्य भाषाओं के लिए।
GitHub Copilot, जो Codex पर बना है, ने इसे रोज़मर्रा के विकास उपकरणों तक पहुंचाया। प्रोग्रामर अब पूरा फंक्शन, टेस्ट और बायलरप्लेट सुझाव के रूप में प्राप्त करने लगे, और प्राकृतिक‑भाषा टिप्पणियों का उपयोग कर रहे थे।
सॉफ़्टवेयर विकास के लिए Codex ने एक क्रमिक शिफ्ट की झलक दिखाई:
- हर पंक्ति हाथ से लिखने से हटकर AI‑जनित ड्राफ्ट की निगरानी और परिष्करण की तरफ़
- सिंटैक्स याद रखने की बजाय वास्तुकला, इरादा और समीक्षा पर अधिक ध्यान
CLIP, DALL·E और Codex ने दिखाया कि OpenAI का दृष्टिकोण पाठ से परे छवि और कोड तक प्रसारित किया जा सकता है, और इसके अनुसंधान का प्रभाव कला, डिजाइन और इंजीनियरिंग में विस्तृत हुआ।
ChatGPT और सार्वजनिक ध्यान
अपने ब्रांड के नाम से प्रकाशित करें
जब आप साझा करने के लिए तैयार हों तो अपने प्रोजेक्ट को कस्टम डोमेन पर पब्लिश करें।
लॉन्च और तेज़ अपनापन
OpenAI ने ChatGPT को 30 नवंबर 2022 को एक मुफ्त "रिसर्च प्रीव्यू" के रूप में लॉन्च किया, जिसे एक बड़े उत्पाद अभियान की बजाय एक छोटे ब्लॉग पोस्ट और ट्वीट में घोषित किया गया। यह मॉडल GPT‑3.5 पर आधारित था और संवाद के लिए अनुकूलित था, साथ ही कुछ हानिकारक या असुरक्षित अनुरोधों को अस्वीकार करने के गार्ड्रिल्स थे।
उपयोग तीव्र रूप से वृद्धि करने लगा। दिनों के भीतर लाखों लोगों ने साइन‑अप किया, और ChatGPT सबसे तेज़ी से बढ़ने वाले उपभोक्ता अनुप्रयोगों में से एक बन गया। उपयोगकर्ता इसकी क्षमता का परीक्षण करके निपुणता से निबंध लिखवाना, कोड डिबग करना, ईमेल ड्राफ्ट करना और जटिल विषयों को सरल भाषा में समझवाना आरंभ कर दिया।
काम, स्कूल और घर में रोज़मर्रा उपयोग
ChatGPT की अपील किसी एक संकुचित उपयोग‑मामले की बजाय इसकी बहुमुखी प्रतिभा में थी।
शिक्षा में, छात्र इसका उपयोग पाठों का सारांश करने, अभ्यास प्रश्न बनाने, अकादमिक लेखों का अनुवाद या सरलीकरण करने और गणित या विज्ञान समस्याओं के कदम‑दर‑कदम समाधान पाने के लिए करते थे। शिक्षक सिलेबस डिजाइन करने, रूबरिक्स ड्राफ्ट करने और विभक्त सीखने सामग्री बनाने के लिए इसका प्रयोग कर रहे थे, जबकि स्कूल नीतियों के बारे में बहस भी चल रही थी।
कार्यस्थल में, पेशेवर लोग ChatGPT से ईमेल, मार्केटिंग कॉपी और रिपोर्ट ड्राफ्ट करवा रहे थे, प्रस्तुति का आउटलाइन बना रहे थे, कोड स्निपेट जनरेट करवा रहे थे और उत्पाद विचारों के लिए मंथन कर रहे थे। स्वतंत्र पेशेवर और छोटे व्यवसाय विशेष रूप से इसे सामग्री और विश्लेषण के लिए सस्ते सहायक के रूप में उपयोग करने लगे।
दैनिक समस्या‑सुलझाव के लिए, लोग ChatGPT से यात्रा योजनाएँ, फ्रिज में उपलब्ध सामग्री से रेसिपी, और बुनियादी कानूनी व चिकित्सा व्याख्याएँ ले रहे थे (अक्सर पेशेवर सलाह लेने की चेतावनी के साथ), और नई क्षमताएँ सीखने में मदद ले रहे थे।
मुफ्त प्रीव्यू से भुगतान‑आधारित ऑफ़र तक
प्रारम्भिक रिसर्च प्रीव्यू मुफ्त था ताकि फेलियर, दुरुपयोग और कमी के बारे में प्रतिपुष्टि इकट्ठी की जा सके। जैसे‑जैसे उपयोग बढ़ा, OpenAI को उच्च अवसंरचना लागत का सामना करना पड़ा और उपयोगकर्ताओं ने अधिक विश्वसनीय पहुँच की माँग की।
फरवरी 2023 में OpenAI ने ChatGPT Plus पेश किया, एक सब्सक्रिप्शन जो तेज़ प्रतिक्रियाएँ, पीक समय में प्राथमिकता और GPT‑4 जैसे नए मॉडलों तथा फीचर्स तक प्रारम्भिक पहुँच देता था। इससे आवर्ती राजस्व का मार्ग खुला जबकि मुफ्त स्तर व्यापक पहुँच बनाए रखा गया।
समय के साथ, OpenAI ने और व्यापार‑उन्मुख विकल्प जोड़े: वही संवादात्मक मॉडलों के लिए API पहुंच, उत्पादों और वर्कफ़्लोज़ में एकीकरण के टूल, और ChatGPT Enterprise व टीम योजनाएँ जिनमें उच्च सुरक्षा, एडमिन कंट्रोल और अनुपालन सुविधाएँ शामिल थीं।
बहस, नियमन और नैतिक चिंताएँ
ChatGPT की अचानक दृश्यता ने लंबे समय से चल रही बहसों को तीव्र कर दिया।
नियामक और नीति निर्माता गोपनीयता, डेटा सुरक्षा और मौजूदा कानूनों के अनुपालन के बारे में चिंतित हुए, विशेषकर यूरोपीय संघ जैसे क्षेत्रों में। कुछ अधिकारियों ने ChatGPT पर अस्थायी प्रतिबंध या जांच शुरू की कि डेटा संग्रह और प्रसंस्करण कानूनी मानदंडों को पूरा करता है या नहीं।
शिक्षकों ने नकल और शैक्षणिक ईमानदारी की चिंताओं का सामना किया क्योंकि छात्र ऐसे निबंध और गृहकार्य उत्पन्न कर सकते थे जिन्हें पहचानना मुश्किल था। कुछ स्कूलों ने प्रतिबंध लगाए या कड़े नियम बनाए, जबकि अन्य ने प्रक्रियाओं, मौखिक परीक्षाओं या कक्षा‑आधारित कार्यों को प्राथमिकता देने के लिए असाइनमेंट रूपरेखा बदली।
नैतिकता विज्ञानी और शोधकर्ता गलत जानकारी, महत्वपूर्ण निर्णयों पर अत्यधिक निर्भरता, प्रतिक्रियाओं में पक्षपात और रचनात्मक व ज्ञान‑काज नौकरियों पर संभावित प्रभाव जैसी चिंताओं को उठा रहे थे। प्रशिक्षण डेटा, कॉपीराइट और कलाकारों/लेखकों के अधिकारों के बारे में भी प्रश्न उठे कि किस प्रकार उनके काम ने मॉडल के व्यवहार को प्रभावित किया होगा।
OpenAI के लिए ChatGPT एक मोड़ था: इसने संगठन को एक शोध‑केंद्रित लैब से वैश्विक चर्चा के केंद्र में बदल दिया कि शक्तिशाली भाषा मॉडलों को कैसे परिनियोजित, शासित और रोज़मर्रा के जीवन में शामिल किया जाना चाहिए।
GPT‑4 और AI क्षमताओं में उन्नति
GPT‑3.5 से GPT‑4 तक
OpenAI ने मार्च 2023 में GPT‑4 जारी किया जो GPT‑3.5 से बड़ा उन्नयन था—वह मॉडल जिसने प्रारम्भ में ChatGPT को संचालित किया था। GPT‑4 ने तर्क, जटिल निर्देशों का पालन और लंबे संवादों में सामंजस्य बनाए रखने में सुधार किया। यह कानूनी धाराओं की व्याख्या, तकनीकी पेपरों का सारांश बनाना, या अस्पष्ट आवश्यकताओं से कोड ड्राफ्ट करना जैसे सूक्ष्म प्रॉम्प्ट्स को संभालने में बेहतर हुआ।
GPT‑3.5 की तुलना में, GPT‑4 ने कई स्पष्ट विफलता मोड्स को कम किया: यह उद्धरण माँगने पर स्रोत बनावट की संभावना कम करने लगा, गणित और तर्क की किनारों पर बेहतर प्रदर्शन करने लगा, और दोहराए गए प्रश्नों पर अधिक सुसंगत आउटपुट देता था।
मल्टीमॉडल और बेंचमार्क प्रदर्शन
GPT‑4 ने मल्टीमॉडल क्षमताएँ पेश कीं: कुछ कॉन्फ़िगरेशन में यह टेक्स्ट के अलावा इमेज भी इनपुट के रूप में स्वीकार कर सकता है। इससे चार्ट का वर्णन, हस्तलिखित नोट्स पढ़ना, UI स्क्रीनशॉट समझना या फ़ोटो से संरचित जानकारी निकालने जैसे उपयोग‑मामले संभव हुए।
मानकीकृत बेंचमार्क्स पर GPT‑4 ने पिछले मॉडलों की तुलना में काफी बेहतर प्रदर्शन किया। इसने बार परीक्षा, SAT और विभिन्न उन्नत प्लेसमेंट परीक्षण जैसे सिम्युलेटेड पेशेवर परीक्षाओं पर पास‑टॉप परिशताएँ प्राप्त कीं। कोडिंग और तर्क बेंचमार्क्स पर भी सुधार दिखाई दिया, जो भाषा‑समझ और समस्या‑समाधान दोनों में मजबूत क्षमताएँ दर्शाता है।
पारिस्थितिकी तंत्र पर प्रभाव और शेष चुनौतियाँ
GPT‑4 जल्दी ही OpenAI के API का केंद्र बन गया और उत्पादन में AI कोपायलट्स, कोडिंग असिस्टेंट, ग्राहक समर्थन टूल्स, शिक्षा प्लेटफ़ॉर्म और कानून, वित्त व स्वास्थ्य जैसे क्षेत्रों में वर्टिकल‑विशिष्ट अनुप्रयोगों की नई लहर का आधार बना।
इन प्रगति के बावजूद, GPT‑4 अभी भी हॉलुसिनेट करता है, असुरक्षित या पक्षपाती आउटपुट के लिए प्रेरित किया जा सकता है, और वास्तविक समझ या अद्यतित तथ्यात्मक ज्ञान की कमी रखता है। OpenAI ने GPT‑4 के लिए संरेखण अनुसंधान पर भारी जोर दिया— RLHF, रेड‑टीमिंग और सिस्टम‑स्तरीय सुरक्षा नियमों जैसी तकनीकों का उपयोग करते हुए—पर यह भी रेखांकित किया कि जोखिमों और दुरुपयोग को प्रबंधित करने के लिए सावधान परिनियोजन, निगरानी और सतत शोध की आवश्यकता बनी हुई है।
OpenAI में सुरक्षा, संरेखण और शासन
शुरू से ही OpenAI ने सुरक्षा और संरेखण को अपने मिशन का केंद्रीय हिस्सा बताया है, न कि उत्पाद लॉन्च के बाद की बात। संगठन ने बार‑बार कहा है कि उसका उद्देश्य उच्च‑क्षमतावाले AI सिस्टम बनाना है जो मानव मूल्यों के अनुरूप हों और ऐसे तरीके से परिनियोजित हों कि वे केवल शेयरधारकों या शुरुआती साझेदारों के लिए नहीं बल्कि सबके लिए फ़ायदे बनायें।
OpenAI चार्टर और घोषित प्राथमिकताएँ
2018 में OpenAI ने OpenAI चार्टर प्रकाशित किया, जिसने उसकी प्राथमिकताओं को औपचारिक रूप दिया:
- व्यापक रूप से लाभकारी AGI बनाना, और उन उपयोगों को रोकना जो मानवता के लिए हानिकारक हो सकते हैं।
- सुरक्षा पर सहयोग करना और अन्य शोध तथा नीति संस्थाओं के साथ समन्वय करना।
- यदि कोई अन्य परियोजना सुरक्षित AGI के निकट हो तो उसकी मदद करने की तैयार रहना।
चार्टर प्रभावी रूप से एक शासन कम्पास के रूप में कार्य करता है, जो शोध दिशाओं, परिनियोजन‑गति और बाहरी साझेदारियों के बारे में निर्णयों को आकार देता है।
सुरक्षा, नीति और रेड‑टीमिंग संरचनाएँ
जैसे‑जैसे मॉडल अधिक सक्षम हुए, OpenAI ने अपने मूल शोध टीमों के साथ समर्पित सुरक्षा और शासन कार्यक्षमताएँ भी बनाई:
- संरेखण व सुरक्षा अनुसंधान समूह यह पता लगाते हैं कि कैसे मॉडल दबाव या प्रतिकूल‑प्रॉम्प्टिंग में भी मानवीय इरादों के अनुरूप व्यवहार करें।
- नीति और शासन टीमें सामाजिक प्रभावों का विश्लेषण करती हैं, जिम्मेदार परिनियोजन नीतियाँ प्रबंधित करती हैं, और सरकारों व मानक‑संस्थाओं के साथ संवाद करती हैं।
- रेड‑टीमिंग प्रोग्राम्स आंतरिक विशेषज्ञों और बाहरी शोधकर्ताओं को आमंत्रित करते हैं ताकि रिलीज़ से पहले मॉडल के दुरुपयोग, पक्षपात और सुरक्षा कमजोरियों का परीक्षण किया जा सके।
ये समूह GPT‑4 और DALL·E जैसे मॉडलों के लॉन्च निर्णयों, पहुँच‑टियरों और उपयोग‑नीतियों को प्रभावित करते हैं।
तकनीकें: RLHF और आगे
एक प्रमुख तकनीकी दृष्टिकोण रहा है रीइन्फोर्समेंट लर्निंग फ्रॉम ह्यूमन फीडबैक (RLHF)। मानव लेबलर मॉडल आउटपुट की समीक्षा करते हैं, उन्हें रैंक करते हैं और एक रिवॉर्ड मॉडल प्रशिक्षित करते हैं। मुख्य मॉडल को फिर ऐसे उत्तर देने के लिए अनुकूलित किया जाता है जो मानव‑पसंदीदा व्यवहार के करीब हों, जिससे विषाक्त, पक्षपाती या असुरक्षित आउटपुट कम होते हैं।
समय के साथ, OpenAI ने RLHF पर अतिरिक्त परतें लगाईं: सिस्टम‑स्तरीय सुरक्षा नीतियाँ, कंटेंट फ़िल्टर, डोमेन‑विशिष्ट फाइन‑ट्यूनिंग और ऐसे निगरानी उपकरण जो उच्च‑जोखिम उपयोग को प्रतिबंधित या फ़्लैग कर सकते हैं।
बाह्य सहयोग और सार्वजनिक फ्रेमवर्क
OpenAI ने सार्वजनिक सुरक्षा फ़्रेमवर्क्स में भाग लिया है, जैसे सरकारों के साथ स्वैच्छिक प्रतिबद्धताएँ, मॉडल रिपोर्टिंग प्रथाएँ, और फ्रंटियर मॉडल सुरक्षा मानकों पर काम। इसने शैक्षणिक व नागरिक‑समाज संगठनों के साथ आकलनों, रेड‑टीमिंग और ऑडिट्स में सहयोग किया है।
ये सहयोग, चार्टर और विकासशील उपयोग‑नीतियाँ OpenAI के बढ़ती क्षमताव वाली AI प्रणालियों के शासन का आधार बनाते हैं।
विवाद, आलोचना और आंतरिक तनाव
बिना अतिरिक्त सेटअप के लॉन्च करें
बिल्ट-इन डिप्लॉयमेंट और होस्टिंग विकल्पों के साथ अपने बनाए हुए प्रोजेक्ट को लॉन्च करें।
OpenAI की तेज़ी से उभरती प्रसिद्धि आलोचना और आंतरिक तनाव के साथ रही है, जिनमें से अधिकांश इस बात पर केंद्रित रहे हैं कि संगठन अब भी कितनी निष्ठा से अपने मूल मिशन—विस्तृत, सुरक्षित लाभ—से मेल खाता है।
“ओपन” साइंस से बंद मॉडलों तक
शुरू में OpenAI ने खुला प्रकाशन और साझाकरण पर जोर दिया। समय के साथ, GPT‑2, GPT‑3 और GPT‑4 जैसे शक्तिशाली मॉडलों के साथ कंपनी ने सीमित रिलीज़, केवल API‑आधारित पहुंच और कम तकनीकी विवरण साझा करने की ओर रुख किया।
आलोचकों ने कहा कि यह कदम नाम “OpenAI” द्वारा निहित वादे से टकराता है। कंपनी के भीतर के समर्थक तर्क देते रहे कि पूर्ण मॉडल वेट्स और प्रशिक्षण विवरण छुपाना दुरुपयोग जोखिम और सुरक्षा कारणों से आवश्यक है।
OpenAI ने सुरक्षा मूल्यांकन, सिस्टम‑कार्ड और नीति दस्तावेज़ प्रकाशित करके प्रतिक्रिया दी है, पर मुख्य मॉडल वेट्स अभी भी गोपनीय रखे जाते हैं। इसे कंपनी खुलेपन, सुरक्षा और प्रतिस्पर्धी दबाव के बीच संतुलन बताती है।
शक्ति, डेटा और वाणिज्यिकरण
जैसे‑जैसे OpenAI ने Microsoft के साथ साझेदारी गहरी की—Azure और Copilot जैसी उत्पादों में मॉडल के एकीकरण के साथ—दर्शकों ने कंप्यूट, डेटा और निर्णय‑शक्ति के केंद्रीकरण की चिंता जताई।
आलोचक कहते हैं कि अब कुछ कंपनियाँ सबसे उन्नत सामान्य‑उद्देश्य मॉडलों और उनके पीछे की विशाल अवसंरचना को नियंत्रित करती हैं। अन्य लोगों का तर्क है कि ChatGPT Plus, एंटरप्राइज़ ऑफ़र और विशिष्ट लाइसेंसिंग जैसी वाणिज्यिक पहलें मूल गैर‑लाभकारी उद्देश्य—विस्तृत लाभ—से भटका सकती हैं।
OpenAI का नेतृत्व राजस्व को महंगा शोध फंड करने के लिए आवश्यक बताता है और कहता है कि सीमित‑लाभ संरचना और चार्टर मानवता के हितों को प्राथमिकता देने का औपचारिक ढांचा देता है। साथ ही यह मुफ्त पहुँच, शोध साझेदारियाँ और कुछ ओपन‑सोर्स टूल्स के माध्यम से सार्वजनिक लाभ दिखाने की कोशिश भी करता है।
नेतृत्व तनाव और हाई‑प्रोफ़ाइल प्रस्थान
तेज़ चाल के चलते, कितनी तेज़ी से आगे बढ़ना चाहिए, कितना खुला रहना चाहिए, और सुरक्षा को कैसे प्राथमिकता देनी चाहिए—इन बातों पर आंतरिक मतभेद समय‑समय पर उभरते रहे।
Dario Amodei और अन्य 2020 में Anthropic की स्थापना करने के लिए निकले, यह कहते हुए कि सुरक्षा और शासन पर दृष्टिकोण भिन्न था। बाद में, प्रमुख सुरक्षा शोधकर्ताओं के त्याग ने, जैसे Jan Leike का 2024 में निकलना, सार्वजनिक रूप से यह संकेत दिया कि अल्पकालिक उत्पाद लक्ष्यों ने दीर्घकालिक सुरक्षा कार्य को पीछे छोड़ा है।
सबसे दिखाई देने वाला विभाजन नवंबर 2023 में हुआ जब बोर्ड ने संक्षेप में CEO Sam Altman को हटाया, भरोसे की हानि का हवाला दिया गया। कर्मचारियों के तीव्र विरोध और Microsoft सहित अन्य हितधारकों के मध्यस्थता के बाद, Altman लौटा, बोर्ड में परिवर्तन हुए और OpenAI ने गवर्नेंस सुधारों का वादा किया, जिसमें एक नया सुरक्षा और सुरक्षा समिति भी शामिल था।
ये घटनाएँ दिखाती हैं कि संगठन तेजी से परिनियोजन, वाणिज्यिक सफलता और सुरक्षा व व्यापक लाभ के ज़िम्मेदारियों के बीच संतुलन कैसे स्थापित करे—यह अभी भी एक विकासशील चुनौती बनी हुई है।
OpenAI की भविष्य में बदलती भूमिका
OpenAI एक छोटे, अनुसंधान‑केंद्रित गैर‑लाभकारी से एक केंद्रीय अवसंरचना प्रदाता में बदल गया है, जो यह प्रभावित करता है कि नए उपकरण कैसे बनाए जाते हैं, विनियम कैसे बनते हैं, और वे कैसे समझे जाते हैं।
लैब से प्लेटफ़ॉर्म तक
मॉडल प्रकाशित करने के बजाय, OpenAI अब एक पूरा प्लेटफ़ॉर्म चलाता है जिसका उपयोग स्टार्टअप्स, उद्यम और स्वतंत्र डेवलपर करते हैं। GPT‑4, DALL·E और भविष्य के सिस्टम्स के लिए APIs के माध्यम से यह बन गया है:
- स्वास्थ्य, शिक्षा, डेवलपर टूल्स और रचनात्मक उद्योगों में उत्पादों के लिए एक तकनीकी आधार
- बेंचमार्क, सर्वोत्तम प्रथाओं और सुरक्षा फीचर्स के लिए एक संदर्भ बिंदु जिसे अन्य लैब अपनाते या आलोचना करते हैं
यह प्लेटफ़ॉर्म रोल मतलब है कि OpenAI केवल शोध को आगे नहीं बढ़ा रहा—यह लाखों लोगों के लिए शक्तिशाली AI का पहला अनुभव कैसे होता है, उसके डिफ़ॉल्ट भी सेट कर रहा है।
शोध, उद्योग और नीति को आकार देना
OpenAI का काम प्रतिस्पर्धियों और ओपन‑सोर्स समुदायों को नए मॉडलों, प्रशिक्षण विधियों और सुरक्षा दृष्टिकोणों के साथ जवाब देने के लिए मजबूर करता है। वह प्रतिस्पर्धा प्रगति को तेज करती है और खुलापन, केंद्रीकरण और वाणिज्यिकरण पर बहसें तेज करती है।
सरकारें और नियामक OpenAI की प्रथाओं, पारदर्शिता रिपोर्टों और संरेखण अनुसंधान को AI परिनियोजन, सुरक्षा मूल्यांकन और जिम्मेदार उपयोग के नियम लिखते समय देख रहे हैं। सार्वजनिक बातचीत ChatGPT, GPT‑4 और भविष्य के सिस्टम्स के बारे में यह तय करती है कि समाज AI के जोखिम और लाभों को कैसे कल्पना करता है।
खुले प्रश्न: शक्ति, समानता, जवाबदेही
जैसे‑जैसे मॉडेल अधिक सक्षम होते जाते हैं, OpenAI की भूमिका से जुड़े अकल्पित मुद्दे और भी महत्वपूर्ण होते जा रहे हैं:
- फ्रंटियर मॉडलों पर नियंत्रण कितना केंद्रीकृत होना चाहिए?
- किसे प्राथमिक या शुरुआती पहुँच मिलनी चाहिए—और किन शर्तों पर?
- प्रशिक्षण डेटा, पर्यावरणीय प्रभाव और बाहरी सुरक्षा ऑडिट कैसे शासित होते हैं?
- उन लोगों और देशों के प्रति OpenAI की क्या जिम्मेदारियाँ हैं जो ग्राहक नहीं हैं पर उसके तकनीकों से प्रभावित होते हैं?
ये प्रश्न तय करेंगे कि भविष्य के AI सिस्टम मौजूदा असमानताओं को बढ़ाएंगे या उन्हें घटाने में मदद करेंगे।
आज OpenAI से जुड़ने के तरीके
डेवलपर्स और व्यवसाय कर सकते हैं:
- OpenAI के APIs पर निर्माण करें, साथ‑ही स्वतंत्र सुरक्षा जाँच, रेड‑टीमिंग और निगरानी अपनाएँ
- ओपन‑सोर्स टूल्स के साथ संयोजन करके किसी एक प्रदाता पर निर्भरता कम करें
- जहाँ संभव हो फीडबैक प्रोग्रामों, नीति परामर्शों और शोध सहयोगों में भाग लें
व्यक्ति कर सकते हैं:
- मॉडल कैसे काम करते हैं, उनकी सीमाएँ क्या हैं और डेटा कैसे उपयोग होता है यह सीखें
- AI टूल्स का आलोचनात्मक उपयोग करें—आउटपुट की जाँच करें, अधिक निर्भरता से बचें, और हानिकारक व्यवहार रिपोर्ट करें
OpenAI का भावी प्रभाव केवल उसके आंतरिक निर्णयों पर निर्भर नहीं करेगा, बल्कि इस पर भी कि सरकारें, प्रतियोगी, नागरिक‑समाज और रोज़मर्रा के उपयोगकर्ता इन प्रणालियों के साथ कैसे जुड़ते, आलोचना करते और जवाबदेही की माँग करते हैं।
अक्सर पूछे जाने वाले प्रश्न
OpenAI की स्थापना क्यों की गई थी?
OpenAI की स्थापना 2015 में एक गैर‑लाभकारी अनुसंधान लैब के रूप में इस मिशन के साथ की गई थी कि अगर आर्टिफिशियल जनरल इंटेलिजेंस (AGI) बनती है तो वह पूरी मानवता के लिए लाभकारी हो।
इसके पीछे कई कारण थे:
- शक्तिशाली AI कुछ ही कंपनियों या सरकारों के नियंत्रण में चले जाने की चिंता
- अल्पकालिक मुनाफ़े से पहले दीर्घकालिक सुरक्षा और संरेखण को प्राथमिकता देने की इच्छा
- बंद, स्वामित्व‑आधारित प्रणालियों के बजाय खुला और सहयोगी शोध तेज़ करने की अभिलाषा
यह प्रारम्भिक कहानी आज भी OpenAI की संरचना, साझेदारियों और सार्वजनिक प्रतिबद्धताओं को प्रभावित करती है।
OpenAI AGI से क्या मतलब रखता है और इसका मिशन क्या है?
AGI (artificial general intelligence) ऐसे AI सिस्टम को कहते हैं जो केवल एक विशिष्ट काम तक सिमित नहीं रहते बल्कि मानवीय स्तर पर कई संज्ञानात्मक कार्य कर सकते हैं।
OpenAI का मिशन है:
- ऐसी AGI बनाना जो व्यापक रूप से लाभकारी हो और किसी छोटी समूह द्वारा नियंत्रित न हो
- सुरक्षा और संरेखण पर ध्यान देकर शक्तिशाली सिस्टमों को मानवीय मूल्यों के अनुरूप बनाना
- शोध, साझेदारियों और पहुंच कार्यक्रमों के माध्यम से लाभों को व्यापक रूप से साझा करना
यह मिशन OpenAI चार्टर में औपचारिक रूप से दर्ज है और शोध तथा परिनियोजन से जुड़े बड़े निर्णयों को आकार देता है।
OpenAI ने गैर‑लाभकारी से सीमित‑लाभ संरचना में क्यों बदलाव किया?
OpenAI ने शुद्ध गैर‑लाभकारी संस्थान से हटकर 2019 में एक "सीमित‑लाभ" (capped‑profit) लिमिटेड पार्टनरशिप, OpenAI LP, बनाई ताकि कटिंग‑एज AI शोध के लिए आवश्यक बड़े निवेश जुटाए जा सकें जबकि मिशन को शीर्ष पर रखा जा सके।
मुख्य बिंदु:
- निवेशक और कर्मचारी अपनी हिस्सेदारी पर रिटर्न कमा सकते हैं, पर एक तय सीमा तक ही
- गैर‑लाभकारी माता‑संस्था OpenAI LP को नियंत्रित करती है और मानवता के हितों को प्राथमिकता देनी चाहिए
- यह संरचना धन और प्रतिभा तक पहुंच और शुद्ध लाभ‑अधिग्रहण के बीच संतुलन करने का एक प्रयोग है
इसकी प्रभावशीलता लगातार बहस का विषय बनी हुई है।
Microsoft को OpenAI साझेदारी से क्या लाभ होता है?
Microsoft ने OpenAI को विशाल क्लाउड कंप्यूट संसाधन (Azure) दिए और अरबों डॉलर के निवेश प्रदान किए। इसके बदले में Microsoft को खुले लाभ हुए:
- GPT‑3 जैसे कुछ तकनीकों का विशिष्ट लाइसेंस, जिससे Microsoft अपने उत्पादों में इन्हें जोड़ सका
- GitHub Copilot, Bing और Microsoft 365 जैसे टूल्स में उन्नत AI क्षमताओं का एकीकृत उपयोग
- Azure पर कस्टम सुपरकम्प्यूटिंग क्लस्टर्स जिनसे बड़े मॉडल प्रशिक्षित किए गए
OpenAI को इसके बदले प्रशिक्षण और परिनियोजन के लिए अत्यधिक आवश्यक संसाधन मिले, जबकि Microsoft को अपने इकोसिस्टम में भिन्न AI क्षमताएँ मिलीं।
GPT‑1, GPT‑2, GPT‑3, और GPT‑4 ने OpenAI के मार्ग को कैसे बदला?
GPT श्रृंखला ने पैमाने, क्षमताओं और परिनियोजन रणनीति में क्रमिक बदलाव दिखाया:
- GPT‑1 (2018): आज के मानकों पर छोटा था, पर यह सिद्ध कर गया कि एक ट्रांसफॉर्मर मॉडल अगला शब्द भविष्यवाणी करके कई NLP कार्यों में सामान्यीकरण कर सकता है।
- GPT‑2 (2019): काफी बड़ा और सुसंगत टेक्स्ट जनरेट करने में सक्षम; दुरुपयोग की चिंताओं के कारण चरणबद्ध रिलीज़ का रास्ता अपनाया गया।
- 175 अरब पैरामीटर तक का बड़ा उछाल; फ्यू‑शॉट और ज़ीरो‑शॉट क्षमताओं ने इसे वाणिज्यिक API के रूप में उपलब्ध कराया।
OpenAI आज पहले जितना "खुला" क्यों नहीं है?
शुरूआत में OpenAI “डिफ़ॉल्ट रूप से खुला” था—कागज़ प्रकाशित करना, कोड साझा करना और Gym जैसे टूल जारी करना। जैसे‑जैसे मॉडल अधिक शक्तिशाली हुए, नीति बदली:
- पूर्ण मॉडल वेट्स सीमित या देरी से जारी किए जाने लगे
- डाउनलोड करने योग्य मॉडल की बजाय API‑आधारित पहुंच दी गई
- कच्चे प्रशिक्षण विवरण से ज़्यादा सुरक्षा मूल्यांकन और सिस्टम‑कार्ड्स पर जोर दिया गया
OpenAI का तर्क है कि यह दुरुपयोग और सुरक्षा जोखिम घटाने के लिए जरूरी था; आलोचक मानते हैं कि इससे “OpenAI” नाम द्वारा दिए गए प्रारम्भिक खुलापन का उल्लंघन होता है और शक्ति एक जगह केंद्रित होती है।
OpenAI अपने AI सिस्टमों को सुरक्षित और संरेखित कैसे रखने की कोशिश करता है?
OpenAI सुरक्षा और संरेखण को संस्थागत और तकनीकी तौर पर मैनेज करने के कई तरीकों का उपयोग करता है:
- broadly beneficial AGI की प्रतिबद्धता वाला औपचारिक चार्टर
- समर्पित सुरक्षा, संरेखण, नीति और रेड‑टीमिंग टीमें जो लॉन्च और पहुंच निर्णयों को प्रभावित करती हैं
- मानव प्रतिक्रिया से प्रशिक्षण (RLHF), कंटेंट फ़िल्टर और निगरानी उपकरण जैसी तकनीकें
- उच्च‑जोखिम क्षमताओं के लिए चरणबद्ध रोल‑आउट और अलग‑अलग एक्सेस‑टियर
ये उपाय जोखिम घटाते हैं पर हॉलुसिनेशन, पक्षपात और दुरुपयोग जैसी समस्याएँ पूरी तरह समाप्त नहीं कर पाते—ये निरंतर शोध और शासन चुनौतियाँ बनी रहती हैं।
ChatGPT का रिलीज़ क्यों एक निर्णायक मोड़ था?
ChatGPT (देर 2022) ने बड़े भाषा मॉडलों को सरल चैट इंटरफ़ेस के माध्यम से आम जनता के लिए सुलभ बना दिया।
यह बदलाव इसलिए अहम था:
- शोध तकनीक को रोज़मर्रा के लिखने, कोडिंग और सीखने के उपकरण में बदल दिया
- लाखों लोगों को संवादात्मक AI से तुरंत परिचित कराया
- स्कूलों, कंपनियों और नियामकों को नीतिगत और नैतिक प्रश्नों का सामना कराना पड़ा (जैसे नकल, गोपनीयता, गलत जानकारी)
इसने OpenAI पर बाहरी निगरानी और सुरक्षा‑प्रथाओं के लिए भी तीव्र ध्यान केंद्रित कर दिया।
OpenAI की टेक्नोलॉजी नौकरी और रचनात्मक काम को कैसे प्रभावित कर सकती है?
Codex और GPT‑4 जैसे मॉडल कुछ ज्ञान‑कामों और रचनात्मक कार्यों को बदल रहे हैं:
लाभ:
- दोहराए जाने वाले लेखन और कोडिंग कार्यों का स्वचालन
- ड्राफ्टिंग, विचार‑उद्यापन और अनुवाद में सहायता
- संवादात्मक शिक्षण सहायकों के जरिए शिक्षा तक पहुंच बढ़ना
जोखिम:
व्यक्ति और संगठन आज OpenAI के साथ जिम्मेदारी से कैसे जुड़ सकते हैं?
OpenAI के इकोसिस्टम के साथ जिम्मेदारी से जुड़ने के कुछ तरीके:
- उपयोगकर्ता के रूप में: ChatGPT और अन्य टूल आज़माएँ, उनकी सीमाएँ समझें और आउटपुट को अंतिम सत्य मानने की बजाय मसौदे के रूप में समीक्षा करें।
- डेवलपर/व्यवसाय के रूप में: API का उपयोग करते समय अपनी सुरक्षा जाँच, लॉगिंग और डोमेन‑विशिष्ट गार्ड्रेल्स जोड़ें।
- नागरिक/शोधकर्ता के रूप में: दस्तावेज़ों, सुरक्षा रिपोर्टों और OpenAI चार्टर का पालन करें; जहाँ संभव हो सार्वजनिक परामर्शों, ऑडिट्स और आलोचनात्मक शोध में भाग लें।
इनमें पारदर्शिता, जवाबदेही और समान पहुंच के लिए दबाव बनाना भी शामिल है, क्योंकि इन प्रणालियों की क्षमताएँ बढ़ती जा रही हैं।