18 दिस॰ 2025·8 मिनट
Postgres स्कीमा डिज़ाइन — प्लानिंग मोड: चरण-दर-चरण तरीका
Postgres स्कीमा प्लानिंग मोड आपको एंटिटीज़, constraints, इंडेक्स और माइग्रेशन्स पहले से तय करने में मदद करता है ताकि बाद में कोड दोबारा लिखने से बचा जा सके।
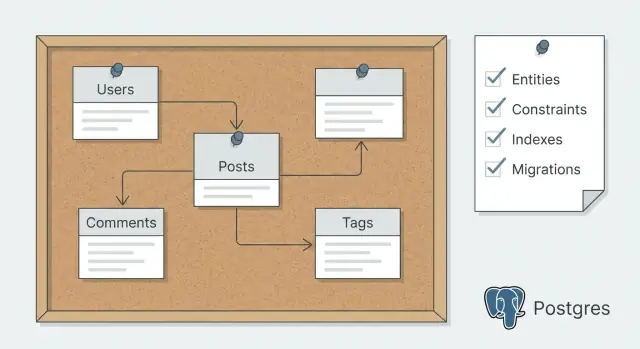
Postgres स्कीमा प्लानिंग मोड आपको एंटिटीज़, constraints, इंडेक्स और माइग्रेशन्स पहले से तय करने में मदद करता है ताकि बाद में कोड दोबारा लिखने से बचा जा सके।
अगर आप तब एंडपॉइंट्स और मॉडल बनाते हैं जब डेटाबेस का आकार स्पष्ट नहीं है, तो अक्सर वही फीचर दोबारा लिखने पड़ते हैं। ऐप डेमो के लिए काम कर लेता है, फिर असली डेटा और एज केस आते हैं और सब कुछ नाजुक लगने लगता है।
ज़्यादातर री-राइट तीन अनुमानित समस्याओं से आते हैं:
इनमें से हर एक बदलाव कोड, टेस्ट और क्लाइंट ऐप्स में लहरों की तरह फैलाता है।
Postgres स्कीमा प्लान करने का मतलब है पहले डेटा कॉन्ट्रैक्ट तय करना, फिर उस पर मेल खाता कोड जेनरेट करना। व्यवहार में इसका मतलब है एंटिटीज़, रिश्ते और कुछ अहम क्वेरीज लिखना, फिर constraints, इंडेक्स और माइग्रेशन तरीका चुनना इससे पहले कि कोई टूल टेबल्स और CRUD स्कैफोल्ड करे।
यह और भी ज़्यादा मायने रखता है जब आप Koder.ai जैसे vibe-coding प्लेटफ़ॉर्म का उपयोग करते हैं, जहां आप बहुत सा कोड तेज़ी से जेनरेट कर सकते हैं। तेज़ जेनरेशन शानदार है, लेकिन स्कीमा तय होने पर ही यह भरोसेमंद बनता है। आपके जनरेट हुए मॉडल और एंडपॉइंट्स को बाद में कम संपादन की ज़रूरत पड़ेगी।
जब आप प्लानिंग छोड़ देते हैं तो आमतौर पर ये परेशानियाँ आती हैं:
एक अच्छा स्कीमा प्लान सरल है: आपकी एंटिटीज़ का साधारण भाषा में विवरण, तालिकाओं और कॉलम्स का ड्राफ्ट, मुख्य constraints और इंडेक्स, और एक माइग्रेशन रणनीति जो प्रोडक्ट बढ़ने पर सुरक्षित रूप से बदलाव करने दे।
स्कीमा प्लानिंग तब सबसे अच्छा काम करती है जब आप पहले यह तय करें कि ऐप को क्या याद रखना है और लोग उस डेटा के साथ क्या कर पाएँ। लक्ष्य को 2–3 सामान्य वाक्यों में लिखें। अगर आप इसे सरल रूप से नहीं समझा सकते, तो आप शायद अनावश्यक तालिकाएँ बना देंगे।
फिर उन क्रियाओं पर ध्यान दें जो डेटा बनाती या बदलती हैं। ये क्रियाएँ असल में आपके rows की उत्पत्ति हैं, और ये बताती हैं कि क्या validate करना ज़रूरी है। संज्ञाओं के बजाय क्रियाओं (verbs) में सोचें।
उदाहरण के लिए, एक बुकिंग ऐप को बुकिंग बनानी होगी, उसे reschedule करना होगा, रद्द करना होगा, refund करना होगा और ग्राहक को संदेश भेजना होगा। ये क्रियाएँ जल्दी ही दिखाती हैं कि क्या स्टोर करना है (time slots, status changes, money amounts) इससे पहले कि आप किसी टेबल का नाम रखें।
अपने पढ़ने के रास्ते (read paths) भी कैप्चर करें, क्योंकि पढ़ने स्ट्रक्चर और इंडेक्सिंग को आगे चलकर ड्राइव करते हैं। उन स्क्रीन या रिपोर्ट्स की सूची बनाएं जो लोग वास्तव में उपयोग करेंगे और वे डेटा को कैसे स्लाइस करते हैं: “My bookings” तारीख के अनुसार sort और status से filter, admin द्वारा ग्राहक नाम या बुकिंग रेफ़रेंस से search, स्थानवार दैनिक राजस्व, और किसने क्या कब बदला इसका audit view।
अंत में, गैर-फंक्शनल ज़रूरतें नोट करें जो स्कीमा विकल्प बदलती हैं—जैसे audit history, soft deletes, multi-tenant separation, या प्राइवेसी नियम (उदा., संपर्क विवरण कौन देख सकता है इसकी सीमाएँ)।
यदि आप इसके बाद कोड जेनरेट करने की योजना बना रहे हैं, तो ये नोट्स मजबूत प्रॉम्प्ट बन जाते हैं। वे बताते हैं क्या ज़रूरी है, क्या बदल सकता है, और क्या searchable होना चाहिए। अगर आप Koder.ai इस्तेमाल कर रहे हैं, तो कुछ भी जनरेट करने से पहले यह लिखना Planning Mode को बहुत अधिक प्रभावी बनाता है क्योंकि प्लेटफ़ॉर्म अनुमान के बजाय असली आवश्यकताओं से काम कर रहा होता है।
तालिकाओं को छूने से पहले, लिखें कि आपका ऐप क्या स्टोर करता है। बार-बार आने वाली संज्ञाओं की सूची बनाकर शुरू करें: user, project, message, invoice, subscription, file, comment। हर noun एक संभावित एंटिटी है।
फिर हर एंटिटी के लिए एक वाक्य जोड़ें जो बताये: यह क्या है और यह क्यों मौजूद है। उदाहरण: “A Project is a workspace a user creates to group work and invite others.” इससे data, items, या misc जैसे vague टेबल्स बनने से बचाव होता है।
Ownership अगला बड़ा फैसला है और यह लगभग हर क्वेरी को प्रभावित करता है। हर एंटिटी के लिए तय करें:
अब तय करें कि आप रिकॉर्ड्स की पहचान कैसे करेंगे। UUIDs तब अच्छे हैं जब रिकॉर्ड कई स्थानों से बन सकते हों (web, mobile, background jobs) या जब आप अनुमानित IDs नहीं चाहते। Bigint IDs छोटे और तेज़ होते हैं। अगर आपको मानव-फ्रेंडली पहचान चाहिए, तो उसे अलग रखें (उदा., एक छोटा project_code जो account के अंदर unique हो) बजाय इसे primary key बनाने के।
अंत में, रिश्तों को शब्दों में लिखें इससे पहले कि आप कुछ डायग्राम करें: एक user के कई projects हैं, एक project के कई messages हैं, और users कई projects में हो सकते हैं। हर लिंक को required या optional के रूप में चिह्नित करें, जैसे “a message must belong to a project” बनाम “an invoice may belong to a project.” ये वाक्य बाद में कोड जेनरेशन के लिए स्रोत सत्य बन जाते हैं।
जब एंटिटीज़ स्पष्ट भाषा में पढ़ने योग्य हों, तब हर एक को एक तालिका में बदलें जिसमें कॉलम्स वास्तविक तथ्यों से मेल खाते हों जिन्हें आपको स्टोर करना है।
नाम और प्रकार चुनें जिन्हें आप बनाए रख सकें। सुसंगत पैटर्न चुनें: snake_case कॉलम नाम, एक ही विचार के लिए एक ही प्रकार, और predictable primary keys। टाइमस्टैम्प के लिए timestamptz पसंद करें ताकि टाइम ज़ोन बाद में चौंकाने न करें। पैसे के लिए numeric(12,2) (या सेंट में integer रखें) फ़्लोट्स के बजाय।
status फ़ील्ड्स के लिए या तो Postgres enum का उपयोग करें या text कॉलम के साथ CHECK constraint ताकि allowed values नियंत्रित रहें।
जो ज़रूरी है बनाम वैकल्पिक तय करने के लिए नियमों को NOT NULL में ट्रांसलेट करें। अगर किसी मान के बिना row का अर्थ नहीं बनता तो इसे required बनाएं। अगर यह वास्तव में अज्ञात या अप्रासंगिक है तो nulls की अनुमति दें।
एक व्यावहारिक डिफ़ॉल्ट कॉलम सेट:
id (uuid या bigint, एक तरीका चुनें और सुसंगत रहें)created_at और updated_atdeleted_at केवल यदि आपको वाकई सॉफ्ट डिलीट चाहिएcreated_by जब आपको यह जानना ज़रूरी हो कि किसने क्या कियाMany-to-many रिश्ते लगभग हमेशा join तालिकाओं बननी चाहिए। उदाहरण के लिए, यदि कई users सहयोग कर सकते हैं तो app_members बनाएं जिसमें app_id और user_id हों, फिर जोड़ी पर uniqueness लागू करें ताकि duplicates न हों।
इतिहास के बारे में पहले सोचें। अगर आपको versioning चाहिए तो एक immutable तालिका योजना बनाएं जैसे app_snapshots, जहाँ हर row एक सेव्ड वर्शन हो और apps से app_id द्वारा जुड़ा और created_at से stamp किया गया हो।
Constraints आपके स्कीमा के गार्डरेल्स हैं। तय करें कौन से नियम हर हालत में सच होने चाहिए चाहे कोई भी सेवा, स्क्रिप्ट, या admin टूल डेटाबेस को छू रहा हो।
पहले identity और रिश्तों से शुरू करें। हर तालिका को primary key चाहिए, और कोई भी “belongs to” फ़ील्ड असली foreign key होनी चाहिए, केवल एक integer नहीं जिसे आप उम्मीद कर रहे हों कि मेल खाएगा।
फिर उन जगहों पर uniqueness जोड़ें जहाँ duplicates सच में नुकसान पहुँचाएंगे, जैसे एक ही ईमेल वाले दो अकाउंट्स या दो लाइन आइटम्स जिनका (order_id, product_id) एक जैसा है।
जल्दी से लागू किए जाने योग्य उच्च-मूल्य वाले constraints:
amount >= 0, status IN ('draft','paid','canceled'), या rating BETWEEN 1 AND 5।Cascade व्यवहार वह जगह है जहाँ योजना आपको बाद में बचाती है। पूछें कि लोग वास्तव में क्या उम्मीद करते हैं। अगर एक ग्राहक हटाया जाता है, तो उसके ऑर्डर्स आमतौर पर गायब नहीं होने चाहिए। यह restrict deletes और इतिहास रखने का इशारा करता है। ऑर्डर लाइनों जैसे निर्भर डेटा के लिए order → items पर cascading समझ में आता है क्योंकि items का माता-पिता के बिना कोई मायना नहीं रहता।
जब आप बाद में मॉडल और एंडपॉइंट जेनरेट करेंगे, तो ये constraints स्पष्ट आवश्यकताएँ बन जाती हैं: किन errors को हैंडल करना है, कौन से फ़ील्ड ज़रूरी हैं, और कौन से एज केस डिज़ाइन द्वारा असंभव हैं।
इंडेक्स एक सवाल का उत्तर होने चाहिए: असली उपयोगकर्ताओं के लिए क्या तेज़ चाहिए।
पहले उन स्क्रीन और API कॉल्स से शुरू करें जिन्हें आप पहले शिप करने की उम्मीद करते हैं। एक लिस्ट पेज जो status से filter करता और newest के अनुसार sort करता है, उसकी ज़रूरतें एक detail पेज से अलग होंगी जो संबंधित रिकॉर्ड लोड करता है।
किसी भी इंडेक्स चुनने से पहले 5–10 क्वेरी पैटर्न साधारण शब्दों में लिखें। उदाहरण: “पिछले 30 दिनों के मेरे इनवॉइस दिखाओ, paid/unpaid से filter करो, created_at से sort करो,” या “एक प्रोजेक्ट खोलो और उसकी tasks due_date के अनुसार सूचीबद्ध करो।” यह इंडेक्स विकल्पों को वास्तविक उपयोग पर आधार देता है।
एक अच्छा शुरुआती इंडेक्स सेट अक्सर foreign key कॉलम (joins के लिए), सामान्य filter कॉलम (जैसे status, user_id, created_at) और कुछ composite इंडेक्स शामिल करता है जो स्थिर multi-filter क्वेरीज के लिए उपयोगी होते हैं, जैसे (account_id, created_at) जब आप हमेशा account_id से filter कर के समय के अनुसार sort करते हैं।
Composite इंडेक्स का क्रम मायने रखता है। पहले वह कॉलम रखें जिस पर आप सबसे अधिक filter करते हैं (और जो सबसे ज्यादा selective है)। अगर आप हर अनुरोध पर tenant_id फ़िल्टर करते हैं, तो अक्सर वह कई इंडेक्सों के आगे होना चाहिए।
हर चीज़ पर इंडेक्स डालने से बचें “शायद बाद में” के बहाने। हर इंडेक्स INSERT और UPDATE पर अतिरिक्त काम जोड़ता है, और यह एक दुर्लभ क्वेरी की थोड़ी धीमी होने से ज़्यादा नुकसान कर सकता है।
टेक्स्ट सर्च की योजना अलग बनाएं। अगर आपको केवल साधारण “contains” मैचिंग चाहिए तो शुरू में ILIKE ही काफी हो सकता है। अगर सर्च केंद्र है, तो जल्दी ही full-text search (tsvector) की योजना बनाएं ताकि बाद में redesign न करना पड़े।
एक स्कीमा "पूर्ण" नहीं होता जब आप पहली बार टेबल्स बनाते हैं। हर बार जब आप कोई फीचर जोड़ते हैं, गलती सुधारते हैं, या अपने डेटा के बारे में अधिक सीखते हैं तो यह बदलता है। अगर आप अग्रिम में अपनी माइग्रेशन रणनीति तय कर लेते हैं तो कोड जेनरेशन के बाद दर्दनाक री-राइट से बचते हैं।
सरल नियम रखें: डेटाबेस में छोटे-छोटे कदमों में बदलाव करें, एक बार में एक फीचर। हर माइग्रेशन को रिव्यू करने में आसान और हर वातावरण में सुरक्षित चलने योग्य बनाएं।
ज़्यादातर ब्रेकेज़ कॉलम का नाम बदलने, हटाने, या प्रकार बदलने से आते हैं। सब कुछ एक ही बार में करने के बजाय एक सुरक्षित रास्ता प्लान करें:
यह ज़्यादा स्टेप्स लेता है, पर वास्तविक दुनिया में यह तेज़ है क्योंकि आउटेज और इमरजेंसी पैच कम होते हैं।
Seed डेटा भी माइग्रेशन्स का हिस्सा हैं। तय करें कौन सी reference तालिकाएँ "हमेशा वहाँ" रहेंगी (roles, statuses, countries, plan types) और उन्हें predictable बनाएं। इन तालिकाओं के inserts और updates को समर्पित माइग्रेशन्स में रखें ताकि हर डेवलपर और हर डिप्लॉय पर एक जैसा परिणाम आये।
शुरुआत में अपेक्षाएँ सेट करें:
रोलबैक हमेशा पूरा "down migration" नहीं होता। कभी-कभी सबसे अच्छा रोलबैक बैकअप रिस्टोर है। अगर आप Koder.ai इस्तेमाल कर रहे हैं, तो यह भी तय करने लायक है कि जोखिम भरे बदलावों से पहले snapshots और rollback पर कब निर्भर रहना है, खासकर त्वरित recovery के लिए।
एक छोटी SaaS ऐप कल्पना करें जहाँ लोग टीमों में जुड़ते हैं, प्रोजेक्ट बनाते हैं, और tasks ट्रैक करते हैं।
दिन एक पर केवल जिन फील्ड्स की ज़रूरत हो उनकी सूची बनाकर शुरू करें:
रिश्ते सीधे-साधे हैं: एक team के कई projects हैं, एक project के कई tasks हैं, और users टीमों में team_members के जरिए जुड़ते हैं। Tasks किसी project से संबंधित होते हैं और किसी यूज़र को असाइन हो सकते हैं।
अब कुछ constraints जोड़ें जो आम गलतियों को रोकेँ:
इंडेक्स वास्तविक स्क्रीन से मेल खाने चाहिए। उदाहरण के लिए, अगर task लिस्ट project और state से filter करती और newest से sort करती है, तो tasks (project_id, state, created_at DESC) जैसा इंडेक्स प्लान करें। अगर “My tasks” प्रमुख view है तो tasks (assignee_user_id, state, due_date) जैसा इंडेक्स मददगार होगा।
माइग्रेशन्स के लिए, पहले सेट को सुरक्षित और साधारण रखें: टेबल्स बनाएं, primary keys, foreign keys, और मूल unique constraints। एक अच्छा follow-up परिवर्तन उपयोग के बाद जोड़ा जाना चाहिए, जैसे tasks पर soft delete (deleted_at) जोड़ना और “active tasks” इंडेक्स को deleted rows को इग्नोर करने के लिए समायोजित करना।
ज़्यादातर री-राइट्स इसलिए होते हैं क्योंकि पहले स्कीमा में नियम और वास्तविक उपयोग विवरण नहीं होते। एक अच्छा प्लानिंग पास परफेक्ट डायग्राम बनाने के बारे में नहीं है। यह जल्दी ही traps पहचानने के बारे में है।
एक सामान्य त्रुटि महत्वपूर्ण नियमों को केवल एप्लिकेशन कोड में रखना है। अगर किसी मान का unique होना, मौजूद होना या सीमा में होना आवश्यक है, तो डेटाबेस को भी इसे enforce करना चाहिए। अन्यथा कोई बैकग्राउंड जॉब, नया एंडपॉइंट या मैन्युअल इम्पोर्ट आपकी लॉजिक को बायपास कर सकता है।
एक और सामान्य चूक यह है कि इंडेक्स को बाद की समस्या समझना। लॉन्च के बाद उन्हें जोड़ना अक्सर अंदाज पर आधारित बन जाता है, और आप गलत चीज़ इंडेक्स कर सकते हैं जबकि असली धीमी क्वेरी join या status फ़ील्टर पर हो।
Many-to-many टेबल भी चुपचाप बग्स का स्रोत हैं। अगर आपकी join टेबल duplicates रोकती नहीं तो आप एक ही रिश्ता दो बार स्टोर कर सकते हैं और घंटों लगा दें “क्यों यह यूज़र दो रोल दिखा रहा है?”
यह भी आसान है कि आप पहले तालिकाएँ बनाते हैं और बाद में महसूस करते हैं कि आपको audit logs, soft deletes, या event history चाहिए। ये बदलाव एंडपॉइंट्स और रिपोर्ट्स में फैलते हैं।
अंत में, JSON कॉलम्स लचीलेपन के लिए tempting होते हैं, पर वे चेक्स हटाते और इंडेक्सिंग मुश्किल बनाते हैं। JSON को केवल वास्तव में वैरिएबल payloads के लिए रखें, न कि मुख्य बिज़नेस फ़ील्ड्स के लिए।
कोड जेनरेट करने से पहले यह त्वरित फिक्स सूची चलाएँ:
यहाँ रुककर सुनिश्चित करें कि योजना इतनी पूरी है कि आप बिना लगातार आश्चर्य के कोड जेनरेट कर सकें। लक्ष्य परफेक्ट होना नहीं है। लक्ष्य उन गैप्स को पकड़ना है जो बाद में री-राइट्स का कारण बनते हैं: गायब रिश्ते, अस्पष्ट नियम, और ऐसे इंडेक्स जो ऐप के उपयोग के तरीके से मेल नहीं खाते।
तेज़ प्री-फ़्लाइट चेक:
amount >= 0 या allowed statuses)।एक सरल सैनीटि टेस्ट: कल्पना करें कि कल एक टीममेट जुड़ रहा है। क्या वे बिना हर घंटे “क्या यह null हो सकता है?” या “डिलीट होने पर क्या होता है?” पूछे पहले एंडपॉइंट्स बना पाएँगे?
जब योजना स्पष्ट पढ़ती है और मुख्य फ्लोज़ कागज पर समझ में आते हैं, तो इसे कार्यान्वित करने के लिए कुछ बनाएं: एक असली स्कीमा और माइग्रेशन्स।
पहली माइग्रेशन से शुरू करें जो टेबल्स, types (यदि आप enums इस्तेमाल करते हैं) और आवश्यक constraints बनाये। पहला पास छोटा पर सही रखें। थोड़ा सा seed डेटा लोड करें और वे क्वेरीज चलाएँ जिनकी आपकी ऐप को ज़रूरत होगी। अगर कोई फ्लो अजीब लगे, तो माइग्रेशन इतिहास अभी छोटा होने पर स्कीमा ठीक करें।
जब आप कुछ end-to-end क्रियाओं (create, update, list, delete, और एक असली बिज़नेस एक्शन) को स्कीमा के साथ टेस्ट कर सकें तब ही मॉडल और एंडपॉइंट जेनरेट करें। कोड जेनरेशन तेज़ तब होता है जब टेबल्स, कीज़ और नामकरण इतने स्थिर हों कि आप अगले दिन सब कुछ rename न कर रहे हों।
एक व्यवहारिक लूप जो री-राइट्स कम रखे:
पहले तय करें कि आप क्या डेटाबेस में वेरिफाई करेंगे बनाम API लेयर में। डेटाबेस में स्थायी नियम रखें (foreign keys, unique constraints, check constraints)। सॉफ्ट नियम API में रखें (feature flags, अस्थायी सीमाएँ, और जटिल cross-table लॉजिक जो अक्सर बदलता है)।
अगर आप Koder.ai इस्तेमाल कर रहे हैं, तो एक समझदारी भरा तरीका यह है कि पहले Planning Mode में एंटिटीज़ और माइग्रेशन्स पर सहमति बनाएं, फिर अपना Go plus PostgreSQL बैकएंड जेनरेट करें। जब कोई बदलाव ग़लत हो जाए, स्नैपशॉट्स और रोलबैक आपको तेज़ी से एक ज्ञात-सही वर्शन पर लौटने में मदद कर सकते हैं जबकि आप स्कीमा योजना समायोजित करते हैं।
पहले स्कीमा प्लान करें। यह एक स्थिर डेटा कॉन्ट्रैक्ट (तालिकाएँ, कीज़, constraints) तय करता है ताकि जनरेट किए गए मॉडल और एंडपॉइंट्स बार-बार नाम बदलने और पुनर्लेखन की ज़रूरत न पड़े।
व्यवहार में: अपनी एंटिटीज़, रिश्ते और टॉप क्वेरीज़ लिखें, फिर constraints, इंडेक्स और माइग्रेशन फाइनल करें इससे पहले कि आप कोड जेनरेट करें।
ऐप को किन चीज़ों को याद रखना है और यूज़र्स क्या कर पाएँ—इन्हें 2–3 वाक्यों में लिखें ताकि आप डायग्राम पर अटकें नहीं।
फिर सूची बनाएं:
यह तालिकाएँ डिजाइन करने के लिए पर्याप्त स्पष्टता देगा बिना ओवरबिल्ड किए।
उन संज्ञाओं (nouns) की सूची बनाकर शुरू करें जो बार-बार आ रही हैं (user, project, invoice, task)। हर एक के लिए एक वाक्य जोड़ें: यह क्या है और क्यों मौजूद है।
अगर आप इसे स्पष्ट रूप से नहीं बता पाएँगे, तो आमतौर पर vague तालिकाएँ बनेंगी जैसे items या misc और बाद में पछतावा होगा।
अपने स्कीमा में एक सुसंगत ID रणनीति अपनाएँ:
मानव-फ्रेंडली आईडी चाहिए तो primary key अलग रखें और एक अलग unique कॉलम दें (जैसे project_code)।
रिश्ते के अनुसार फैसला लें और उपयोगकर्ता की उम्मीद के अनुसार चुनें:
RESTRICT/NO ACTION बेहतर है (जैसे customers → orders)CASCADE समझ में आता है (जैसे order → line items)यह निर्णय जल्दी करें क्योंकि यह API व्यवहार और एज केस प्रभावित करता है।
डेटाबेस में स्थायी नियम रखें ताकि हर तरह का राइटर (API, स्क्रिप्ट, इम्पोर्ट, admin टूल) समान रूप से बाध्य हो।
पहले प्राथमिकता दें:
रियल क्वेरी पैटर्न से शुरू करें, अनुमान से नहीं।
5–10 साधारण-इंग्लिश क्वेरी लिखें (filters + sort) और उनके लिए इंडेक्स चुनें:
status, user_id, created_atएक join टेबल बनाएं जिसमें दो foreign keys हों और एक composite unique constraint।
उदाहरण पैटर्न:
team_members(team_id, user_id, role, joined_at)UNIQUE (team_id, user_id) डुप्लिकेट्स रोकता हैयह ऐसे चुपचाप आने वाले बग्स रोकता है जैसे “क्यों यह यूज़र दो बार दिख रहा है?” और आपकी क्वेरीज साफ़ रखता है।
डिफ़ॉल्ट रूप से:
timestamptz समय स्टैम्प के लिए (time zone आश्चर्य कम होते हैं)numeric(12,2) या सेंट्स को integer में रखें (floats से बचें)CHECK constraintsसमान कॉन्सेप्ट के लिए समान टाइप रखें ताकि joins और validations predictable रहें।
छोटे, रिव्यूएबल माइग्रेशन रखें और एक ही कदम में ब्रेकिंग चेंज से बचें।
सुरक्षित रास्ता:
यह चरणबद्ध तरीका आउटेज और इमरजेंसी पैच कम करता है।
PRIMARY KEYFOREIGN KEYUNIQUE (email, (team_id, user_id))CHECK (non-negative amounts, allowed statuses)NOT NULL(account_id, created_at))हर चीज़ पर इंडेक्स न डालें; हर इंडेक्स INSERT/UPDATE को धीमा करता है।