12 सित॰ 2025·8 मिनट
डे़‑वन मॉनिटरिंग के लिए प्रोडक्शन ऑब्ज़र्वेबिलिटी स्टार्टर पैक
डे़‑वन के लिए प्रोडक्शन ऑब्ज़र्वेबिलिटी स्टार्टर पैक: जोड़ने के लिए न्यूनतम लॉग्स, मेट्रिक्स और ट्रेसेस, साथ ही “धीमा है” रिपोर्ट के लिए एक सरल ट्रायएज फ्लो।
डे़‑वन के लिए प्रोडक्शन ऑब्ज़र्वेबिलिटी स्टार्टर पैक: जोड़ने के लिए न्यूनतम लॉग्स, मेट्रिक्स और ट्रेसेस, साथ ही “धीमा है” रिपोर्ट के लिए एक सरल ट्रायएज फ्लो।
पूरा ऐप अक्सर ही नहीं टूटता। अक्सर एक ही कदम अचानक व्यस्त हो जाता है, कोई क्वेरी जो टेस्ट में ठीक थी, या कोई निर्भरता जो टाइमआउट देना शुरू कर देती है। असली उपयोगकर्ता असली विविधता लाते हैं: धीमे फोन, flaky नेटवर्क, अजीब इनपुट, और ट्रैफ़िक स्पाइक्स बुरा समय चुनकर आते हैं।
जब कोई कहता है “धीमा है”, तो उसकी मंशा अलग-अलग हो सकती है। पेज लोड होने में देर हो सकती है, इंटरैक्शन लैग कर रहे हों, कोई API कॉल टाइमआउट हो रही हो, बैकग्राउंड जॉब जमा हो रहे हों, या कोई थर्ड‑पार्टी सर्विस सब कुछ धीमा कर रही हो।
इसीलिए आपको डैशबोर्ड से पहले सिग्नल चाहिए। पहले दिन पर, आपको हर एंडपॉइंट के लिए परफेक्ट चार्ट्स नहीं चाहिए। आपको इतने लॉग, मेट्रिक्स और ट्रेसेस चाहिए कि एक सवाल जल्दी से हल हो सके: समय कहाँ जा रहा है?
जल्दी-जल्दी बहुत ज़्यादा इंस्ट्रूमेंट करने का भी जोखिम है। बहुत सारे इवेंट शोर पैदा करते हैं, पैसा खर्च करते हैं, और ऐप को भी धीमा कर सकते हैं। और बुरा यह कि टीमों का टेलीमेट्री पर भरोसा घट जाता है क्योंकि वह अव्यवस्थित और असंगत लगता है।
एक वास्तविक दिन-एक लक्ष्य सादा है: जब आपको “धीमा है” रिपोर्ट मिले, आप 15 मिनट से कम में धीमे कदम का पता लगा सकें। आपको बताना चाहिए कि बोतलनीक क्लाइंट रेंडरिंग में है, API हैंडलर/निर्भरता में है, डेटाबेस या कैश में है, या बैकग्राउंड वर्कर या बाहरी सर्विस में।
उदाहरण: नया चेकआउट फ्लो धीमा लग रहा है। भले ही आपके पास बहुत सारे टूल न हों, फिर भी आप यह कह पाना चाहेंगे, “95% समय payment provider कॉल में जा रहा है,” या “cart क्वेरी बहुत सारी रोज़ स्कैन कर रही है।” अगर आप Koder.ai जैसे टूल से तेज़ी से ऐप बनाते हैं, तो यह दिन‑एक बेसलाइन और भी ज़्यादा मायने रखती है, क्योंकि तेज शिपिंग तब ही काम आती है जब आप जल्दी से डिबग भी कर सकें।
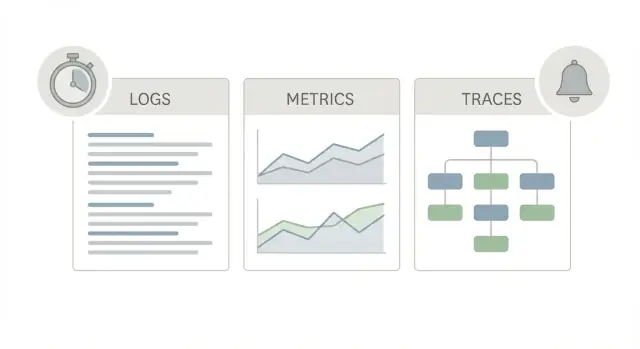
एक अच्छा प्रोडक्शन ऑब्ज़र्वेबिलिटी स्टार्टर पैक ऐप के तीन अलग‑अलग “व्यू” इस्तेमाल करता है, क्योंकि हर एक अलग सवाल का जवाब देता है।
लॉग्स कहानी बताते हैं। वे बताते हैं कि एक रिक्वेस्ट, एक यूज़र, या एक बैकग्राउंड जॉब के लिए क्या हुआ। एक लॉग लाइन कह सकती है “payment failed for order 123” या “DB timeout after 2s,” साथ में request ID, user ID और error message जैसी डिटेल्स। जब कोई अजीब वन‑ऑफ समस्या रिपोर्ट करता है, तो लॉग अक्सर सबसे तेज़ तरीका होते हैं यह कन्फर्म करने का कि यह हुआ और किसे प्रभावित किया।
मेट्रिक्स स्कोरबोर्ड हैं। ये वे नंबर हैं जिन्हें आप ट्रेंड और अलर्ट कर सकते हैं: request rate, error rate, latency percentiles, CPU, queue depth। मेट्रिक्स बताते हैं कि कोई चीज़ दुर्लभ है या व्यापक, और क्या यह बिगड़ रही है। अगर latency सबके लिए 10:05 पर बढ़ी, तो मेट्रिक्स इसे दिखाएंगे।
ट्रेसेस नक्शा हैं। एक ट्रेस एक ही रिक्वेस्ट का पीछा करता है जब वह आपके सिस्टम में चलता है (web -> API -> database -> third‑party)। यह दिखाता है कि समय कहाँ खर्च हुआ, कदम दर कदम। क्योंकि “धीमा है” लगभग कभी एक बड़ा रहस्य नहीं होता — यह अक्सर एक धीमा हॉप होता है।
एक घटना के दौरान व्यावहारिक फ्लो कुछ इस तरह दिखता है:
एक सरल नियम: अगर कुछ मिनटों के बाद आप एक बोतलनीक नहीं बता पा रहे, तो आपको और अलर्ट नहीं चाहिए। आपको बेहतर ट्रेसेस चाहिए, और ऐसी कंसिस्टेंट IDs चाहिए जो ट्रेस को लॉग से जोड़ दें।
ज़्यादातर “हम इसे नहीं ढूंढ पा रहे” घटनाएँ गुम डेटा की वजह से नहीं होतीं। वे इसलिए होती हैं क्योंकि वही चीज़ सेवाओं में अलग‑अलग तरीके से रिकॉर्ड होती है। दिन‑एक पर कुछ साझा सम्मेलन लॉग्स, मेट्रिक्स और ट्रेसेस को तभी लाइन में लाते हैं जब आपको तेज़ी से जवाब चाहिए।
शुरूआत में, हर deployable यूनिट के लिए एक सर्विस नाम चुनें और उसे स्थिर रखें। अगर “checkout-api” आपके आधे डैशबोर्ड में “checkout” बन जाता है, तो आप इतिहास खो देते हैं और अलर्ट टूट जाते हैं। एनवायरनमेंट लेबल्स के साथ भी यही करें। छोटे सेट जैसे prod और staging चुनें और हर जगह उनका उपयोग करें।
अगला, हर रिक्वेस्ट को फॉलो करना आसान बनाएं। एज पर (API gateway, web server, या पहला हैंडलर) request ID जेनरेट करें और उसे HTTP कॉल्स, मैसेज क्यूज़ और बैकग्राउंड जॉब्स में पास करें। अगर सपोर्ट टिकेट कहता है “10:42 पर धीमा था,” तो एक single ID आपको एक्सैक्ट लॉग्स और ट्रेस बिना अनुमान के निकालने देगा।
दिन‑एक के लिए एक काम करने वाला कॉन्वेंशन सेट:
जल्दी निर्णय लें कि किस टाइम यूनिट का उपयोग होगा। API latency के लिए milliseconds और लंबे जॉब्स के लिए seconds चुनें, और उसी पर टिके रहें। मिक्स्ड यूनिट्स ऐसे चार्ट बनाते हैं जो ठीक दिखते हैं पर गलत कहानी कहते हैं।
एक ठोस उदाहरण: अगर हर API duration_ms, route, status और request_id लॉग करे, तो रिपोर्ट जैसे “tenant 418 के लिए checkout धीमा है” एक त्वरित फ़िल्टर बन जाती है, बहस नहीं।
अगर आप सिर्फ एक काम करेंगे, तो लॉग्स को सर्च करना आसान बनाइए। इसकी शुरुआत structured logs (आम तौर पर JSON) और हर सेवा में एक ही फील्ड्स से होती है। लोकल डेवलपमेंट के लिए plain text ठीक है, पर रियल ट्रैफ़िक, retries और मल्टीपल इंस्टेंसेज़ होने पर वे शोर बन जाते हैं।
एक अच्छा नियम: वही लॉग करें जो आप असल में किसी घटना में इस्तेमाल करेंगे। ज़्यादातर टीमों को यह जवाब देना होता है: यह किस रिक्वेस्ट का था? किसने किया? कहाँ फेल हुआ? उसने क्या छुआ? अगर किसी लॉग लाइन से इनमें से कोई मदद नहीं मिलती, तो शायद उसे लॉग नहीं करना चाहिए।
दिन‑एक के लिए एक छोटा, सुसंगत फील्ड सेट रखें ताकि आप सेवाओं के बीच फ़िल्टर और जुड़ाव कर सकें:
जब कोई एरर हो, तो उसे एक बार लॉग करें, संदर्भ के साथ। एक एरर टाइप (या कोड), एक छोटा संदेश, सर्वर एरर्स के लिए stack trace, और उपस्ट्रीम निर्भरता शामिल करें (उदाहरण: postgres, payment provider, cache)। हर retry पर वही stack trace दोहराने से बचें। इसके बजाय request_id संलग्न करें ताकि आप चेन फॉलो कर सकें।
उदाहरण: एक यूज़र रिपोर्ट करता है कि वह settings सेव नहीं कर पा रहा। request_id से एक सर्च करने पर PATCH /settings पर 500 मिलता है, और नीचे Postgres का timeout था जिसमें duration_ms लिखा था। आपको पूरे पेलोड्स की ज़रूरत नहीं थी, सिर्फ route, user/session और dependency नाम काफी थे।
प्राइवसी लॉगिंग का हिस्सा है, बाद का काम नहीं। पासवर्ड, टोकन, ऑथ हेडर्स, पूरा रिक्वेस्ट बॉडी या संवेदनशील PII लॉग न करें। अगर आपको यूज़र पहचानने की ज़रूरत है, तो एक स्थिर ID (या हैश्ड वैल्यू) लॉग करें, ईमेल या फोन नंबर नहीं।
अगर आप Koder.ai (React, Go, Flutter) पर ऐप बनाते हैं, तो इन फील्ड्स को हर जनरेट की गई सर्विस में शुरू से ही शामिल करना अच्छा है ताकि आपकी पहली घटना के दौरान "लॉगिंग ठीक करना" न करना पड़े।
एक अच्छा स्टार्टर पैक छोटे सेट के मेट्रिक्स से शुरू होता है जो एक सवाल जल्दी से जवाब दे: सिस्टम अभी हेल्दी है या नहीं, और अगर नहीं तो कहाँ दर्द हो रहा है?
ज़्यादातर प्रोडक्शन मुद्दे चार “गोल्डन सिग्नल्स” में दिखते हैं: latency (responses slow), traffic (load बदल गया), errors (failures), और saturation (कोई साझा रिसोर्स मैक्स पर पहुँच गया)। अगर आप इन चार सिग्नलों को अपने ऐप के हर बड़े हिस्से के लिए देख सकते हैं, तो आप बिना अनुमान के अधिकांश घटनाओं का ट्रायएज कर सकते हैं।
Latency औसतन नहीं, percentiles में देखनी चाहिए। p50, p95, p99 ट्रैक करें ताकि आप देख सकें कि एक छोटे समूह के यूज़र्स बुरा अनुभव कर रहे हैं। ट्रैफ़िक के लिए requests per second से शुरू करें (या workers के लिए jobs per minute)। एरर्स के लिए 4xx और 5xx अलग रखें: 4xx बढ़ना अक्सर क्लाइंट बिहेवियर या वैलिडेशन बदलाव बताता है; 5xx बढ़ना आपके ऐप या उसकी निर्भरताओं की ओर इशारा करता है। Saturation वह सिग्नल है जो बताता है कि "हम किसी चीज़ से बाहर हो रहे हैं" (CPU, memory, DB connections, queue backlog)।
अधिकतर ऐप्स के लिए न्यूनतम सेट:
ठोस उदाहरण: अगर यूज़र कहते हैं “धीमा है” और API p95 latency spike हो रहा है जबकि ट्रैफ़िक फिक्स्ड है, तो अगला कदम saturation चेक करना है। अगर DB pool usage max के नज़दीक पिन है और timeouts बढ़ रहे हैं, तो आपने संभावित बोतलनीक पाया। अगर DB ठीक दिखता है पर queue depth तेजी से बढ़ रहा है, तो बैकग्राउंड वर्क साझा संसाधनों को स्टार्व कर रहे होंगे।
अगर आप Koder.ai पर ऐप बनाते हैं, तो इस चेकलिस्ट को दिन‑एक की definition of done का हिस्सा मानें। ऐप छोटा होने पर ये मेट्रिक्स जोड़ना आसान है बजाए पहले असली घटना के दौरान जोड़ने के।
जब कोई कहे "धीमा है", लॉग अक्सर बताते हैं कि क्या हुआ और मेट्रिक्स बताते हैं कि यह कितनी बार हुआ। ट्रेसेस बताते हैं कि एक रिक्वेस्ट के अंदर समय कहाँ गया। वही समय‑रेखा एक अस्पष्ट शिकायत को स्पष्ट फ़िक्स में बदल देती है।
सर्वर साइड से शुरू करें। अपने ऐप के एज पर (पहला हैंडलर जो रिक्वेस्ट लेता है) इनबाउंड रिक्वेस्ट्स इंस्ट्रूमेंट करें ताकि हर रिक्वेस्ट एक ट्रेस उत्पन्न कर सके। क्लाइंट‑साइड ट्रेसिंग बाद में कर सकते हैं।
एक अच्छा दिन‑एक ट्रेस उन स्पैन्स को रखता है जो आमतौर पर स्लो होने वाले हिस्सों से मेल खाते हैं:
ट्रेसेस को searchable और comparable बनाने के लिए कुछ की‑ऐट्रिब्यूट्स कैप्चर करें और सेवाओं के बीच उन्हें कॉन्सिस्टेंट रखें।
इनबाउंड request span के लिए route (템्पलेट जैसे /orders/:id, पूरा URL नहीं), HTTP method, status code, और latency रिकॉर्ड करें। डेटाबेस स्पैन्स के लिए DB system (PostgreSQL, MySQL), ऑपरेशन टाइप (select, update), और अगर जोड़ना आसान हो तो table name रिकॉर्ड करें। External calls के लिए dependency name (payments, email, maps), target host, और status रिकॉर्ड करें।
सैंपलिंग दिन‑एक पर मायने रखती है, वरना लागत और शोर तेज़ी से बढ़ते हैं। एक सरल head‑based नियम अपनाएँ: errors और slow requests (अगर SDK सपोर्ट करता है) का 100% ट्रेस करें, और सामान्य ट्रैफ़िक का छोटा प्रतिशत सैंपल लें (1–10%)। ट्रैफ़िक कम होने पर शुरुआत में अधिक रखें, फिर जैसे ही वॉल्यूम बढ़े घटाएँ।
“अच्छा” क्या दिखता है: एक ट्रेस जहाँ आप ऊपर से नीचे कहानी पढ़ सकें। उदाहरण: GET /checkout 2.4s लिया, DB ने 120ms लिया, cache 10ms, और external payment कॉल ने 2.1s लिया जिसमें retry भी था। अब आप जानते हैं कि समस्या निर्भरता में है, आपके कोड में नहीं। यही प्रोडक्शन ऑब्ज़र्वेबिलिटी स्टार्टर पैक का मूल है।
जब कोई कहे “धीमा है”, सबसे तेज़ जीत वह है कि उस अस्पष्ट भावना को कुछ ठोस सवालों में बदल दें। यह स्टार्टर पैक ट्रायएज फ्लो तब भी काम करता है जब आपका ऐप बिल्कुल नया हो।
पहले समस्या को संकुचित करें, फिर साक्ष्य के क्रम में आगे बढ़ें। सीधा डेटाबेस पर कूदें मत।
स्थिर करने के बाद, एक छोटा सुधार करें: क्या हुआ लिखें और एक गायब सिग्नल जोड़ें। उदाहरण के लिए, अगर आप यह नहीं बता पाए कि slowdown केवल एक रीजन में था, तो latency मेट्रिक्स में region tag जोड़ें। अगर लंबे डेटाबेस स्पैन में यह स्पष्ट नहीं था कि कौन‑सी query थी, तो सावधानी से query labels जोड़ें, या एक "query name" फील्ड।
एक त्वरित उदाहरण: अगर checkout p95 400ms से 3s पर कूदता है और ट्रेसेस में payment call में 2.4s दिखता है, तो आप बहस बंद कर के provider, retries और timeouts पर ध्यान दे सकते हैं।
जब कोई कहे “धीमा है”, तब आप केवल यह समझने में एक घंटा बर्बाद कर सकते हैं कि वे क्या कहना चाहते हैं। एक स्टार्टर पैक तभी काम का है जब वह समस्या को तेज़ी से संकुचित करने में मदद करे।
तीन स्पष्ट सवालों से शुरू करें:
फिर कुछ नंबर देखें जो आमतौर पर बताते हैं कि आगे कहाँ जाना है। परफेक्ट डैशबोर्ड की तलाश मत करें। आप सिर्फ “सामान्य से बुरा” सिग्नल चाह रहे हैं।
अगर p95 बढ़ा लेकिन errors स्थिर हैं, तो पिछले 15 मिनट के सबसे slow route के लिए एक trace खोलें। एक ट्रेस अक्सर दिखा देता है कि समय DB, external API कॉल, या locks पर जा रहा है।
फिर एक लॉग सर्च करें। अगर आपके पास specific user report है, तो उनके request_id (या correlation ID) से सर्च करें और टाइमलाइन पढ़ें। अगर नहीं, तो उसी टाइम विंडो में सबसे आम error message के लिए सर्च करें और देखें क्या यह slowdown के साथ मेल खाता है।
अंत में निर्णय लें: अभी mitigate करें या गहराई से जांच करें। अगर यूज़र्स ब्लॉक्ड हैं और saturation हाई है, तो तेज mitigation (scale up, rollback, या गैर‑जरूरी feature flag बंद करना) समय खरीद सकता है। अगर प्रभाव छोटा है और सिस्टम स्थिर है, तो ट्रेसेस और slow query logs के साथ और जांच करें।
रिलीज़ के कुछ घंटे बाद, सपोर्ट टिकेट आते हैं: “Checkout 20–30 सेकंड लेता है।” कोई भी अपने लैपटॉप पर reproduce नहीं कर पा रहा, तो अनुमान लगना शुरू हो जाता है। यहीं पर एक स्टार्टर पैक पैसे वक़्त बचाता है।
सबसे पहले, मेट्रिक्स देखें और लक्षण कन्फर्म करें। HTTP requests के लिए p95 latency चार्ट एक स्पष्ट spike दिखाता है, पर सिर्फ POST /checkout के लिए। दूसरे रूट्स सामान्य दिखते हैं और error rate फ्लैट है। इससे समस्या "पूरे साइट धीमी" से घटकर "एक endpoint धीमा" हो जाती है।
अगला, slow POST /checkout रिक्वेस्ट के लिए एक ट्रेस खोलें। ट्रेस वाटरफॉल दोषी को स्पष्ट कर देती है। अक्सर दो नतीजे मिलते हैं:
PaymentProvider.charge स्पैन 18 सेकंड ले रहा है, जिसमें अधिकांश समय wait पर जा रहा है।DB: insert order स्पैन धीमा है, क्वेरी के लौटने से पहले लंबा wait दिखा रहा है।अब ट्रेस से मिलते हुए लॉग्स कन्फर्म करें, उसी request ID (या अगर आप लॉग में store करते हैं तो trace ID) का उपयोग करके। उस रिक्वेस्ट के लॉग्स में बार‑बार warning दिखती है जैसे “payment timeout reached” या “context deadline exceeded”, और नई रिलीज़ में जो retries जोड़े गए थे वे भी दिखते हैं। अगर डेटाबेस पथ है तो लॉग्स lock wait संदेश या slow query स्टेटमेंट दिखा सकते हैं।
तीनों सिग्नल एक साथ हों तो फिक्स स्पष्ट हो जाते हैं:
कुंजी यही है कि आपने शिकार नहीं किया। मेट्रिक्स ने endpoint दिखाया, ट्रेसेस ने slow step दिखाया, और लॉग्स ने failure mode request‑level पर कन्फर्म किया।
अधिकांश घटना समय टालने योग्य गैप्स पर बर्बाद होता है: डेटा है पर वह शोर, जोखिम भरा, या उस एक डिटेल की कमी में है जो लक्षणों को कारण से जोड़ता है। एक स्टार्टर पैक तभी मदद करता है जब वह तनाव के समय में भी इस्तेमाल योग्य रहे।
एक आम जाल बहुत ज़्यादा लॉग करना है, खासकर raw request bodies। यह उपयोगी लगता है जब तक आप विशाल स्टोरेज के लिए भुगतान न करने लगें, सर्च स्लो न हो जाए, और गलती से पासवर्ड, टोकन, या पर्सनल डेटा कैप्चर न हो जाए। संरचित फील्ड्स (route, status code, latency, request_id) पसंद करें और केवल छोटे, स्पष्ट रूप से अनुमति दिए गए इनपुट के हिस्से लॉग करें।
एक और समय नष्ट करने वाली बात है मेट्रिक्स जो दिखने में डिटेल्ड हैं पर एग्रीगेट करना असम्भव बन जाते हैं। हाई‑कार्डिनैलिटी लेबल्स जैसे पूरा user ID, emails, या यूनिक order नंबर आपके मेट्रिक सीरीज की संख्या फूला देते हैं और डैशबोर्ड को अविश्वसनीय बना देते हैं। उसके बजाय coarse labels (route name, HTTP method, status class, dependency name) प्रयोग करें, और किसी भी यूज़र‑स्पेसिफिक चीज़ को लॉग्स में रखें जहाँ वह है।
बार‑बार फास्ट डायग्नोसिस में रुकावट डालने वाली गलतियाँ:
एक छोटा व्यावहारिक उदाहरण: अगर checkout p95 800ms से 4s पर कूदता है, आप दो मिनट में यह दो सवाल चाहेंगे: क्या यह ठीक deploy के बाद शुरू हुआ, और क्या समय आपके ऐप में है या किसी निर्भरता में (database, payment provider, cache)? पर्सेंटाइल्स, एक रिलीज टैग, और route + dependency नामों वाले ट्रेसेस के साथ आप जल्दी जवाब पा लेंगे। उनके बिना, आप घटना विंडो जला रहे होंगे अनुमान लगाकर।
असल जीत स्थिरता है। एक स्टार्टर पैक तभी काम करता है जब हर नई सर्विस वही बेसिक्स लेकर शिप हो, एक ही नामकरण के साथ, और कुछ भी टूटने पर आसानी से मिल सके।
अपने दिन‑एक के निर्णयों को एक छोटा टेम्पलेट बनाकर टीम फिर से इस्तेमाल करे। छोटा रखें, पर विशिष्ट रहें।
एक "home" view बनाएं जो कोई भी घटना के दौरान खोल सके। एक स्क्रीन पर requests per minute, error rate, p95 latency, और आपका मुख्य saturation metric दिखाएँ, environment और version के लिए फ़िल्टर के साथ।
शुरुआत में अलर्टिंग न्यून रखें। दो अलर्ट बहुत कुछ कवर करते हैं: एक मुख्य route पर error rate spike, और उसी route पर p95 latency spike। अगर और जोड़ते हैं, तो हर एक का स्पष्ट एक्शन होना चाहिए।
अंत में, मासिक समीक्षा तय करें। noisy alerts हटाएं, नामकरण कसें, और पिछली घटना में बचाने वाला एक missing सिग्नल जोड़ें।
इसे अपने बिल्ड प्रोसेस में डालने के लिए, अपनी रिलीज चेकलिस्ट में एक “observability gate” जोड़ें: request IDs, version tags, home view, और दो बेसलाइन अलर्ट के बिना कोई deploy न करें। अगर आप Koder.ai के साथ शिप करते हैं, तो आप planning mode में ये day‑one सिग्नल परिभाषित कर सकते हैं, फिर snapshots और rollback का इस्तेमाल करके सुरक्षित तरीके से iterate कर सकते हैं।
Start with the first place users enter your system: the web server, API gateway, or your first handler.
request_id and pass it through every internal call.route, method, status, and duration_ms for every request.That alone usually gets you to a specific endpoint and a specific time window fast.
Aim for this default: you can identify the slow step in under 15 minutes.
You don’t need perfect dashboards on day one. You need enough signal to answer:
Use them together, because each answers a different question:
During an incident: confirm impact with metrics, find the bottleneck with traces, explain it with logs.
Pick a small set of conventions and apply them everywhere:
Default to structured logs (often JSON) with the same keys everywhere.
Minimum fields that pay off immediately:
Start with the four “golden signals” per major component:
Then add a tiny component checklist:
Instrument server-side first so every inbound request can create a trace.
A useful day-one trace includes spans for:
Make spans searchable with consistent attributes like (template form), , and a clear dependency name (for example , , ).
A simple, safe default is:
Start higher when traffic is low, then reduce as volume grows.
The goal is to keep traces useful without exploding cost or noise, and still have enough examples of the slow path to diagnose it.
Use a repeatable flow that follows evidence:
These mistakes burn time (and sometimes money):
service_name, environment (like prod/staging), and versionrequest_id generated at the edge and propagated across calls and jobsroute, method, status_code, and tenant_id (if multi-tenant)duration_ms)The goal is that one filter works across services instead of starting over each time.
timestamp, level, service_name, environment, versionrequest_id (and trace_id if available)route, method, status_code, duration_msuser_id or session_id (a stable ID, not an email)Log errors once with context (error type/code + message + dependency name). Avoid repeating the same stack trace on every retry.
routestatus_codepaymentspostgrescacheWrite down the one missing signal that would have made this faster, and add it next.
Keep it simple: stable IDs, percentiles, clear dependency names, and version tags everywhere.