02 सित॰ 2025·8 मिनट
API के लिए Protobuf बनाम JSON: गति, आकार और अनुकूलता
Protobuf और JSON को APIs के लिए तुलना करें: पेलोड साइज, गति, पढ़ने‑लायकता, टूलिंग, स्कीमा इवोल्यूशन और यह तय करें कि वास्तविक प्रोडक्ट्स में कौन‑सा फॉर्मेट कब बेहतर बैठता है।
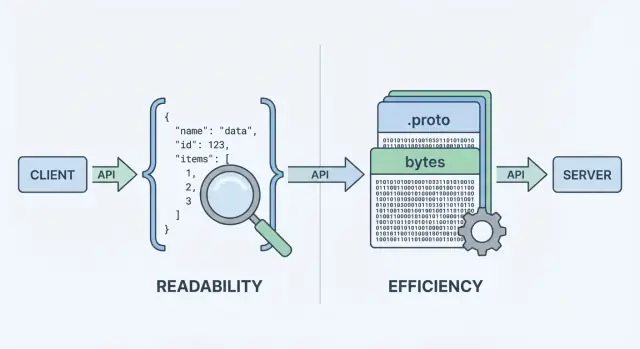
Protobuf और JSON क्या हैं (और क्यों मायने रखते हैं)
जब आपका API डेटा भेजता या प्राप्त करता है, तो उसे एक डेटा फ़ॉर्मेट चाहिए—एक मानकीकृत तरीका जिससे इनफार्मेशन को रिक्वेस्ट और रिस्पॉन्स बॉडीज़ में प्रस्तुत किया जाता है। वह फ़ॉर्मेट फिर नेटवर्क पर भेजने के लिए सीरियलाइज़ (बाइट्स में बदलना) होता है, और क्लाइंट/सर्वर पर वापस उपयोगी ऑब्जेक्ट्स में डिसीरियलाइज़ किया जाता है।
दो आम विकल्प हैं JSON और Protocol Buffers (Protobuf)। ये एक ही बिजनेस डेटा (यूज़र्स, ऑर्डर्स, टाइमस्टैम्प, आइटम्स की सूचियाँ) को मॉडल कर सकते हैं, पर प्रदर्शन, पेलोड साइज और डेवलपर वर्कफ़्लो के मामले में अलग ट्रेड‑ऑफ़ करते हैं।
JSON: मानव-पठनीय टेक्स्ट
JSON (JavaScript Object Notation) एक टेक्स्ट-आधारित फॉर्मेट है जो ऑब्जेक्ट और ऐरे जैसे साधारण स्ट्रक्चर से बना है। यह REST APIs के लिए लोकप्रिय है क्योंकि इसे पढ़ना आसान है, लॉग करना आसान है, और curl या ब्राउज़र DevTools जैसे टूल्स से तुरंत निरीक्षण किया जा सकता है।
एक बड़ा कारण कि JSON हर जगह है: अधिकतर भाषाओं में इसका बेहतरीन समर्थन है, और आप एक रिस्पॉन्स देखकर तुरंत समझ सकते हैं।
Protobuf: स्कीमा-आधारित कॉम्पैक्ट बाइनरी
Protobuf Google द्वारा बनाया गया एक बाइनरी सीरियलाइज़ेशन फॉर्मेट है। टेक्स्ट भेजने के बजाय यह .proto स्कीमा द्वारा परिभाषित कॉम्पैक्ट बाइनरी रिप्रेजेंटेशन भेजता है। स्कीमा फील्ड्स, उनके प्रकार और उनके न्यूमेरिक टैग्स बताता है।
बाइनरी और स्कीमा-ड्रिवन होने के कारण, Protobuf आमतौर पर छोटे पेलोड और तेज़ पार्सिंग देता है—जो हाई-रिक्वेस्ट वॉल्यूम, मोबाइल नेटवर्क या लेटेंसी‑संवेदनशील सर्विसेज में मायने रखता है (अकसर gRPC के साथ, पर केवल gRPC तक सीमित नहीं)।
एक ही डेटा, अलग‑अलग ट्रेड‑ऑफ़
यह अलग करना महत्वपूर्ण है कि आप "क्या" भेज रहे हैं और "कैसे" उसे एन्कोड किया जा रहा है। एक “user” जिसमें id, name और email हो सकता है, उसे JSON और Protobuf दोनों में मॉडल किया जा सकता है। अंतर वह लागत है जो आपको चुकानी पड़ती है:
- पेलोड आकार (टेक्स्ट बनाम कॉम्पैक्ट बाइनरी)
- सीपीयू समय सीरियलाइज़/डिसीरियलाइज़ करने में
- डिबगिंग और ऑब्ज़रवेबिलिटी (पठनीय लॉग बनाम बाइनरी टूलिंग)
- कम्पैटिबिलिटी और इवोल्यूशन (अनौपचारिक JSON कन्वेंशंस बनाम लागू स्कीमा)
एक‑साइज़‑फिट‑ऑल उत्तर नहीं है। कई पब्लिक‑फेसिंग APIs के लिए JSON अभी भी डिफ़ॉल्ट रहता है क्योंकि यह एक्सेसिबल और फ्लेक्सिबल है। आंतरिक सर्विस‑टू‑सर्विस कम्युनिकेशन, प्रदर्शन‑सेंसिटिव सिस्टम, या कड़ा अनुबंध होने पर Protobuf बेहतर बैठ सकता है। इस गाइड का लक्ष्य है कि आप प्रतिबंधों के आधार पर चुनें—न कि विचारधारा के।
API डेटा कैसे सीरियलाइज़ और भेजा जाता है
जब एक API डेटा रिटर्न करता है, वह सीधे "ऑब्जेक्ट्स" नेटवर्क पर नहीं भेज सकता। पहले उन्हें बाइट्स की स्ट्रीम में बदलना पड़ता है—इसे सीरियलाइज़ेशन कहते हैं—सोचिए कि यह डेटा को पैक करने जैसा है। दूसरी तरफ, क्लाइंट उन बाइट्स को फिर से खोल कर उपयोगी डेटा स्ट्रक्चर बनाता है (डिसीरियलाइज़ेशन)।
सर्वर से क्लाइंट तक एक त्वरित यात्रा
एक सामान्य request/response फ्लो इस तरह दिखता है:
- सर्वर एक रिस्पॉन्स बनाता है अपने इन‑मेमरी टाइप्स में (objects/structs/classes)।
- Serializer उसे एन्कोड करके एक पेलोड बनाता है (JSON टेक्स्ट या Protobuf बाइनरी)।
- पेलोड को HTTP/1.1, HTTP/2, या HTTP/3 पर बाइट्स के रूप में भेजा जाता है।
- क्लाइंट बाइट्स प्राप्त करता है, फिर उन्हें अपने इन‑मेमरी टाइप्स में डिकोड करता है।
यह “एन्कोडिंग स्टेप” ही वह जगह है जहाँ फॉर्मेट का प्रभाव पड़ता है। JSON एन्कोडिंग पठनीय टेक्स्ट बनाती है जैसे {"id":123,"name":"Ava"}. Protobuf एन्कोडिंग कॉम्पैक्ट बाइनरी बाइट्स बनाती है जो बिना टूलिंग के मानवार्थी नहीं होते।
फॉर्मेट क्यों प्रदर्शन और वर्कफ़्लो बदलता है
हर रिस्पॉन्स को पैक और अनपैक करना पड़ता है, इसलिए फॉर्मेट प्रभावित करता है:
- बैंडविड्थ (पेलोड साइज): छोटे पेलोड ट्रांसफर लागत घटाते हैं, मोबाइल नेटवर्क और हाई‑ट्रैफ़िक APIs के लिए मददगार।
- लेटेंसी: कम डेटा ट्रांसमिट मतलब तेज़ रिस्पॉन्स; तेज़ एन्कोड/डिकोड CPU समय भी बचाता है।
- डेवलपर वर्कफ़्लो: JSON DevTools और लॉग में आसान; Protobuf अक्सर जनरेटेड टाइप्स और विशिष्ट डिकोडिंग टूल्स मांगता है।
API स्टाइल आपको एक दिशा में धकेल सकता है
आपका API स्टाइल अक्सर निर्णय को प्रभावित करता है:
- REST‑स्टाइल JSON APIs आमतौर पर JSON यूज़ करते हैं क्योंकि यह व्यापक रूप से समर्थित,
curlसे टेस्ट करने में आसान, और लॉग/इंस्पेक्शन में सरल है। - gRPC प्रायः Protobuf के साथ डिज़ाइन किया गया है। यह HTTP/2 और कोड जेनरेशन का उपयोग करता है, जो strongly typed Protobuf संदेशों के साथ सहजता से जुड़ता है।
आप JSON को gRPC के साथ (transcoding के माध्यम से) या Protobuf को साधारण HTTP पर इस्तेमाल कर सकते हैं, पर आपकी स्टैक की डिफ़ॉल्ट एर्गोनॉमिक्स—फ्रेमवर्क, गेटवे, क्लाइंट लाइब्रेरी, और डिबगिंग आदतें—यह अक्सर तय कर देती हैं कि रोज़‑मर्रा में क्या चलना आसान है।
पेलोड साइज और स्पीड: आम तौर पर क्या मिलता/हारता है
जब लोग protobuf बनाम json की तुलना करते हैं, वे आमतौर पर दो मेट्रिक्स से शुरू करते हैं: पेलोड कितना बड़ा है और encode/decode में कितना समय लगता है। हेडलाइन सरल है: JSON टेक्स्ट है और अक्सर verbose होता है; Protobuf बाइनरी है और कॉम्पैक्ट रहता है।
पेलोड साइज: कॉम्पैक्ट बाइनरी बनाम पठनीय टेक्स्ट
JSON में फील्ड नाम दोहराए जाते हैं और नंबर/बूलियन/स्ट्रक्चर टेक्स्ट में होते हैं, इसलिए यह अक्सर अधिक बाइट्स भेजता है। Protobuf फील्ड नामों की जगह न्यूमेरिक टैग्स का उपयोग करता है और मानों को प्रभावी ढंग से पैक करता है, इसलिए यह बड़े ऑब्जेक्ट्स, रिपीटेड फील्ड्स और गहरे नेस्टेड डेटा में खासकर छोटा रहता है।
फिर भी, कम्प्रेशन गैप को कम कर सकता है। gzip या brotli के साथ, JSON की रिपीटेड कुंजियाँ बहुत अच्छी तरह कंप्रेस होती हैं, इसलिए वास्तविक परिनियोजन में अंतर घट सकता है। Protobuf भी कंप्रेस हो सकता है, पर सापेक्ष लाभ अक्सर छोटे होते हैं।
CPU लागत: टेक्स्ट पार्स करना बनाम बाइनरी डीकोड करना
JSON पार्सर्स को टेक्स्ट टोकनाइज़ करना पड़ता है, वैलिडेट करना पड़ता है, स्ट्रिंग से नंबर में बदलना पड़ता है, और edge‑cases (escaping, whitespace, unicode) संभालने होते हैं। Protobuf डिसीरियलाइज़ेशन अधिक डायरेक्ट है: टैग पढ़ो → टाइप्ड वैल्यू पढ़ो। कई सर्विसेज़ में Protobuf CPU समय और गार्बेज सृजन कम करता है, जिससे लोड के तहत टेल‑लेटेंसी में सुधार हो सकता है।
नेटवर्क प्रभावित क्षेत्र: मोबाइल और हाई‑लेटेंसी कनेक्शंस
मोबाइल नेटवर्क या हाई‑लेटेंसी लिंक पर, कम बाइट्स का मतलब तेज़ ट्रांसफ़र और कम रेडियो‑टाइम (जो बैटरी भी बचा सकता है) होता है। पर अगर आपके रिस्पॉन्स पहले से ही छोटे हैं, तो हैंडशेक ओवरहेड, TLS और सर्वर प्रोसेसिंग हावी हो सकते हैं—जिससे फॉर्मेट का प्रभाव कम नज़र आएगा।
अपने सिस्टम में बेंचमार्क कैसे करें
अपने वास्तविक पेलोड्स के साथ मापें:
- प्रतिनिधि requests/responses चुनें (छोटे, सामान्य, worst‑case)।
- तुलना करें: raw साइज, compressed साइज (gzip/brotli), encode/decode समय, और end‑to‑end लेटेंसी।
- वास्तविक concurrency पर टेस्ट चलाएँ और p50/p95/p99 रिकॉर्ड करें।
इस तरह "API serialization" बहस को आप अपने API के लिए भरोसेमंद डेटा में बदल देते हैं।
डेवलपर अनुभव: पठनीयता, डिबगिंग और लॉगिंग
डेवलपर अनुभव में JSON अक्सर डिफ़ॉल्ट रूप से जीतता है। आप JSON रिक्वेस्ट या रिस्पॉन्स को लगभग कहीं भी निरीक्षण कर सकते हैं: ब्राउज़र DevTools, curl आउटपुट, Postman, रिवर्स प्रॉक्सी, और प्लेन‑टेक्स्ट लॉग्स। जब कुछ टूटता है, तो "हमने असल में क्या भेजा?" पता लगाने के लिए अक्सर बस कॉपी/पेस्ट काफी होता है।
Protobuf अलग है: यह कॉम्पैक्ट और सख्त है, पर मानव‑पठनीय नहीं। अगर आप कच्चे Protobuf बाइट्स लॉग करते हैं तो आपको base64 blobs या पढ़ने लायक न होने वाला बाइनरी दिखेगा। पेलोड समझने के लिए आपको सही .proto स्कीमा और एक डिकोडर चाहिए (उदा. protoc, भाषा‑विशिष्ट टूलिंग, या आपकी सर्विस का जेनरेटेड टाइप)।
व्यावहारिक डिबगिंग वर्कफ़्लो
JSON के साथ, मुद्दों को दोहराना सीधा है: एक लॉग्ड पेलोड लें, सीक्रेट्स हटाएँ, उसे curl से रीप्ले करें, और आप एक न्यूनतम टेस्ट केस के पास होते हैं।
Protobuf के साथ, आप आमतौर पर डिबग इस तरह करते हैं:
- बाइनरी पेलोड कैप्चर करें (अक्सर base64‑encoded),
- उसे सही स्कीमा वर्ज़न से डिकोड करें,
- री‑एन्कोड करके रिक्वेस्ट को रीप्ले करें।
यह अतिरिक्त स्टेप मैनेज करने लायक है—पर केवल तब जब टीम के पास एक दोहराने योग्य वर्कफ़्लो हो।
Protobuf (और JSON) को डिबग करना आसान बनाने के सुझाव
स्ट्रक्चर्ड लॉगिंग दोनों फॉर्मैट के लिए मददगार है। request IDs, method नाम, user/account identifiers, और प्रमुख फील्ड्स लॉग करें बजाय पूरे बॉडी के—जहाँ सुरक्षित हो।
Protobuf के लिए विशेष सुझाव:
- एक decoded, redacted “debug view” (उदा. JSON रिप्रेजेंटेशन) बाइनरी पेलोड के साथ लॉग करें जब सुरक्षित हो।
- लॉग में स्कीमा वर्ज़न या संदेश प्रकार रखें ताकि "कौन सा
.protoइस्तेमाल हुआ?" की उलझन न हो। - एक छोटा internal स्क्रिप्ट/Make टार्गेट रखें जो "इस base64 पेलोड को सही स्कीमा से डिकोड कर सके"—ऑन‑कॉल के लिए उपयोगी।
JSON के लिए, canonicalized JSON (स्थिर कुंजी क्रम) लॉग करने पर विचार करें ताकि diffs और इंसीडेंट टाइमलाइन पढ़ना आसान हो।
स्कीमा और टाइप सुरक्षा: लचीलापन बनाम गार्डरैइल
APIs सिर्फ डेटा नहीं भेजते—वे अर्थ भेजते हैं। JSON और Protobuf के बीच सबसे बड़ा फर्क यह है कि अर्थ कितनी स्पष्टता से परिभाषित और लागू होता है।
JSON: लचीला आकार, लचीली व्याख्याएँ
JSON डिफ़ॉल्ट रूप से "schema‑less" है: आप कोई भी ऑब्जेक्ट किसी भी फील्ड के साथ भेज सकते हैं, और कई क्लाइंट तब तक स्वीकार कर लेंगे जब तक यह "ठीक‑ठीक" दिखता है।
यह शुरुआती दौर में सुविधाजनक है, पर यह गलतियों को छिपा भी सकता है। आम झमेलों में शामिल हैं:
- असंगत फील्ड्स:
userIdएक जगह,user_idदूसरी जगह, या अलग कोड पाथ पर फील्ड गायब होना। - Stringly‑typed डेटा: नंबर, बूलियन या तारीखें स्ट्रिंग के रूप में भेजना जैसे
"42","true", या"2025-12-23"—उत्पादन में आसान, पढ़ने में मज़ेदार। - अस्पष्ट nulls:
nullका अर्थ “अज्ञात”, “सेट नहीं”, या “जानबूझकर खाली” हो सकता है और विभिन्न क्लाइंट इसे अलग तरह से हैंडल कर सकते हैं।
आप JSON Schema या OpenAPI जोड़ सकते हैं, पर JSON खुद उपभोक्ताओं को उसका पालन करने की आवश्यकता नहीं देता।
Protobuf: .proto के जरिए स्पष्ट अनुबंध
Protobuf .proto फ़ाइल में स्कीमा की मांग करता है। स्कीमा बताता है:
- कौन‑से फील्ड मौजूद हैं,
- उनका प्रकार क्या है (string, integer, enum, message, आदि),
- और कौन‑सा फील्ड नंबर वायर पर प्रत्येक फील्ड की पहचान करता है।
यह अनुबंध आकस्मिक बदलावों—जैसे integer को string में बदल देना—को रोकने में मदद करता है क्योंकि जनरेटेड कोड विशिष्ट प्रकारों की अपेक्षा करता है।
टाइप सुरक्षा के विवरण जो मायने रखते हैं
Protobuf के साथ, नंबर्स नंबर्स रहते हैं, enums ज्ञात मानों तक सीमित रहते हैं, और timestamps अक्सर well‑known types के रूप में मॉडल होते हैं (बजाय किसी ad‑hoc स्ट्रिंग के)। proto3 में, अनुपस्थिति optional फील्ड्स या wrapper types के साथ default values से अलग दिखाई देती है।
यदि आपका API सटीक प्रकारों और उम्मीद के मुताबिक पार्सिंग पर निर्भर करता है, तो Protobuf उन गार्डरैइल्स को देता है जिन्हें JSON आमतौर पर कन्वेंशन के जरिए प्राप्त करने की कोशिश करता है।
बदलती स्कीमा और क्लाइंट ब्रेक हुए बिना वर्ज़निंग
Endpoints और उनके विकास की योजना बनाएं
इम्प्लीमेंटेशन कोड जनरेट करने से पहले endpoints, फील्ड्स, डिफ़ॉल्ट्स और वर्जनिंग नियम मैप करें।
APIs विकास के साथ बदलते हैं: आप फील्ड जोड़ते हैं, बिहेवियर में बदलाव करते हैं, और पुरानी चीज़ें हटाते हैं। लक्ष्य होता है कि अनुबंध को बिना कंज्यूमर्स को हैरान किए बदलना।
बैकवर्ड बनाम फॉरवर्ड कंपैटिबिलिटी (साफ भाषा में)
- Backward compatible: नए सर्वर पुराने क्लाइंट से बात कर सकते हैं। पुराना क्लाइंट जो नहीं समझता उसे इग्नोर कर देता है और फिर भी काम करता है।
- Forward compatible: नए क्लाइंट पुराने सर्वर से बात कर सकते हैं। नए क्लाइंट मिसिंग फील्ड्स को हैंडल कर सकते हैं और defaults पर fallback कर लेते हैं।
अच्छी इवोल्यूशन रणनीति दोनों के लिए लक्ष्य रखती है, पर बैकवर्ड कंपैटिबिलिटी अक्सर कम से कम इच्छा‑मानक होती है।
Protobuf: फील्ड नंबर सबसे महत्वपूर्ण होते हैं
Protobuf में हर फील्ड का नंबर (उदा. email = 3) होता है—नाम मानव के लिए हैं; वायर पर पहचान नंबर है। इसलिए:
-
सुरक्षित बदलाव (आम तौर पर)
- नए optional फील्ड जोड़ें और नए, कभी इस्तेमाल न किए गए नंबर चुनें।
- नए enum मान जोड़ें (मौजूदा को reorder न करें)।
- किसी फील्ड को deprecated घोषित करें पर उसका नंबर reserve करें।
-
जो जोखिम भरा है (अक्सर ब्रेकिंग)
- किसी पुराने नंबर का पुन: उपयोग कर के अलग मतलब देना या प्रकार बदलना।
- असंगत तरीके से प्रकार बदलना (string → int)।
- किसी फील्ड को हटाकर उसका नंबर रिलीज़ कर देना—आगे जाकर नंबर की reuse अर्थ को खराब कर सकती है।
सर्वोत्तम अभ्यास: पुराने नंबर/नाम के लिए reserved इस्तेमाल करें और चेंजलॉग रखें।
JSON: कन्वेंशंस और अनुशासन द्वारा वर्ज़निंग
JSON में बिल्ट‑इन स्कीमा नहीं है, इसलिए कम्पैटिबिलिटी आपके पैटर्न पर निर्भर करती है:
- additive परिवर्तन प्राथमिकता दें: नए फील्ड जोड़ें बजाय मौजूदा को बदलने के।
- unknown फील्ड्स को इग्नोर करने का सिद्धांत रखें, और missing फील्ड्स को sensible default मानें।
- प्रकार बदलने से बचें; अगर ज़रूरी हो तो नया फील्ड नाम जोड़ें।
डिप्रीकेशन्स और स्पष्ट पॉलिसी
डिप्रीकेशन को पहले से document करें: कोई फील्ड कब डिप्रीकेट होगा, कितना समय सपोर्ट रहेगा, और क्या उसकी जगह क्या है। एक सरल वर्ज़निंग पॉलिसी (उदा. “additive changes non‑breaking; removals new major version मांगेंगे”) प्रकाशित करें और उसका पालन करें।
प्लेटफ़ॉर्म‑विशेष टूलिंग और इकोसिस्टम सपोर्ट
JSON और Protobuf के बीच चयन अक्सर इस बात पर निर्भर करता है कि आपका API कहाँ चलना है—और आपकी टीम क्या मैनेज करना चाहती है।
ब्राउज़र्स बनाम सर्वर: JSON का "डिफ़ॉल्ट" लाभ
JSON लगभग सार्वभौमिक है: हर ब्राउज़र और बैकएंड रनटाइम इसे बिना अतिरिक्त डिपेंडेंसीज़ के पार्स कर सकता है। वेब ऐप में fetch() + JSON.parse() आम रास्ता है, और प्रॉक्सी, API गेटवे और ऑब्ज़रवेबिलिटी टूल्स अक्सर JSON को आउट‑ऑफ‑द‑बॉक्स समझते हैं।
Protobuf ब्राउज़र में भी चल सकता है, पर यह zero‑cost डिफ़ॉल्ट नहीं है। आप आमतौर पर Protobuf लाइब्रेरी (या generated JS/TS कोड) जोड़ेंगे, बंडल साइज मैनेज करेंगे, और तय करेंगे कि क्या आप HTTP पर Protobuf भेज कर ब्राउज़र टूलिंग से आसानी से निरीक्षण कर पाएँगे।
मोबाइल और बैकएंड SDKs: जहाँ Protobuf चमकता है
iOS/Android और बैकएंड भाषाओं (Go, Java, Kotlin, C#, Python, आदि) पर Protobuf का समर्थन परिपक्व है। बड़े फायदे तब मिलते हैं जब आप प्लेटफ़ॉर्म‑विशिष्ट लाइब्रेरीज़ का उपयोग करते हैं और आम तौर पर .proto से कोड जनरेट करते हैं।
कोड जेनरेशन के फायदे:
- टाइपेड मॉडल और enums, जिससे क्लाइंट‑साइड पर जल्दी एरर पकड़ती है
- तेज़ सीरियलाइज़ेशन लाइब्रेरीज़ और सर्विसेज़ में सुसंगत डेटा शेप
लागतें भी हैं:
- बिल्ड स्टेप्स (CI में कोड जेनरेट करना, generated artifacts को सिंक में रखना)
- रिपो/प्रोसेस कॉम्प्लेक्सिटी (shared
.protoपैकेज प्रकाशित करना, वर्शन पिनिंग)
gRPC: मजबूत इकोसिस्टम, आकार देने वाला प्रतिबंध
Protobuf अक्सर gRPC के साथ जुड़ा होता है, जो आपको सर्विस डिफ़िनिशन, क्लाइंट स्टब्स, स्ट्रीमिंग और इंटरसेप्टर्स का पूरा टूलिंग स्टोरी देता है। अगर आप gRPC पर विचार कर रहे हैं, तो Protobuf नैचुरल फिट है।
यदि आप पारंपरिक JSON REST API बना रहे हैं, तो JSON की टूलिंग इकोसिस्टम (ब्राउज़र DevTools, curl‑फ़्रेंडली डिबगिंग, generic gateways) सरल बनी रहती है—खासकर पब्लिक APIs और तेज़ इंटीग्रेशन के लिए।
जल्दी प्रोटोटाइप दोनों विकल्पों का बिना जल्दी प्रतिबद्ध हुए
अगर आप अभी भी API सतह खोज रहे हैं, तो दोनों स्टाइल्स में प्रोटोटाइप बनाना मददगार हो सकता है। उदाहरण के लिए, कई टीमें जल्दी एक JSON REST API बनाती हैं और प्रदर्शन संवेदनशील आंतरिक सर्विस के लिए gRPC/Protobuf रखती हैं, फिर असली पेलोड्स पर बेंचमार्क करके तय करती हैं कि क्या डिफ़ॉल्ट बने।
(Koder.ai का उदाहरण: प्लेटफ़ॉर्म फुल‑स्टैक ऐप्स जेनरेट कर सकता है और प्लानिंग/स्नैपशॉट/रोलबैक समर्थन के साथ कॉन्ट्रैक्ट पर तेजी से इटरे이트 करना आसान बनाता है।)
ऑपरेशनल फिट: कैशिंग, गेटवेज़ और ऑब्ज़रवेबिलिटी
अपने वास्तविक पेलोड का बेंचमार्क लें
एक ही API के दो वर्शन चलाकर वास्तविक डेटा के साथ पेलोड साइज और लेटेंसी मापें।
JSON बनाम Protobuf चुनने का असर सिर्फ पेलोड साइज या स्पीड तक सीमित नहीं है। यह इस बात को भी प्रभावित करता है कि आपका API कैशिंग लेयर्स, गेटवेज़ और टीम के इंसिडेंट‑टूल्स के साथ कितना अच्छा फ़िट बैठता है।
कैशिंग और CDNs
अधिकांश HTTP कैशिंग इंफ्रास्ट्रक्चर (ब्राउज़र कैश, रिवर्स प्रॉक्सी, CDN) HTTP सेमांटिक्स के आसपास ऑप्टिमाइज़्ड हैं, किसी विशेष बॉडी फॉर्मैट के लिए नहीं। CDN किसी भी बाइट्स को कैश कर सकता है जब तक रिस्पॉन्स cacheable हो।
फिर भी, कई टीमें एज पर HTTP/JSON की अपेक्षा करती हैं क्योंकि निरीक्षण और ट्रबलशूटिंग आसान है। Protobuf के साथ कैशिंग काम करती है, पर आपको deliberate होना होगा:
- कैश कुंजियाँ (URL, query params, और खासकर
Vary) साफ रखें - स्पष्ट cacheability हेडर्स (
Cache-Control,ETag,Last-Modified) सेट करें - कई फॉर्मैट सपोर्ट करते समय अनजाने कैश fragmentation से बचें
कंटेंट‑नेगोशिएशन (Content-Type और Accept)
अगर आप JSON और Protobuf दोनों सपोर्ट करते हैं, तो कंटेंट‑नेगोशिएशन यूज़ करें:
- क्लाइंट भेजे
Accept: application/jsonयाAccept: application/x-protobuf - सर्वर मैचिंग
Content-Typeके साथ जवाब दे
कैश्स को यह समझाने के लिए Vary: Accept सेट करें, वरना कैश किसी JSON रिस्पॉन्स को Protobuf क्लाइंट को सर्व कर सकता है (या उल्टा)।
गेटवेज़, प्रॉक्सी और ऑब्ज़रवेबिलिटी
API गेटवेज़, WAFs, request/response transformers और ऑब्ज़रवेबिलिटी टूल्स अक्सर JSON बॉडीज़ को मानते हैं:
- रिक्वेस्ट वैलिडेशन और स्कीमा चेक्स
- फील्ड‑लेवल लॉगिंग और रिडैक्शन
- पेलोड फ़ील्ड्स से निकाले जाने वाले मेट्रिक्स
- डैशबोर्ड और ट्रेस व्यूज़ में डिबगिंग
बाइनरी Protobuf इन फीचर्स को सीमित कर सकता है जब तक कि आपका टूलिंग Protobuf‑aware न हो या आप डिकोडिंग स्टेप जोड़ें।
मिश्रित वातावरण के लिए व्यावहारिक मार्गदर्शन
आम पैटर्न है बाहरी सतह पर JSON, अंदर Protobuf:
- पब्लिक REST एंडपॉइंट्स: JSON संगतता और आसान ऑपरेशन्स के लिए
- आंतरिक सर्विस‑टू‑सर्विस कॉल्स: Protobuf (अकसर gRPC के माध्यम से) दक्षता के लिए
यह बाहरी इंटीग्रेशन को सरल रखता है जबकि आप उन स्थानों पर Protobuf के प्रदर्शन लाभ कैप्चर करते हैं जहाँ आप दोनों सिरों को नियंत्रित करते हैं।
सुरक्षा और विश्वसनीयता के विचार
JSON या Protobuf चुनने से डेटा एन्कोड और पार्स होने का तरीका बदलता है—पर यह प्रमाणीकरण, एन्क्रिप्शन, अधिकृत और सर्वर‑साइड वैलिडेशन जैसे मूल सुरक्षा आवश्यकताओं की जगह नहीं लेता। एक तेज़ सीरियलाइज़र उस API को नहीं बचाएगा जो अनट्रस्टेड इनपुट बिना सीमाओं के स्वीकार करता है।
फॉर्मेट विकल्प सुरक्षा पर परत नहीं है
Protobuf को "ज़्यादा सुरक्षित" मानने की प्रवृत्ति हो सकती है क्योंकि यह बाइनरी और कम पठनीय है। पर यह सुरक्षा रणनीति नहीं है। हमला करने वालों को payload मानव‑पठनीय चाहिए ही नहीं—उन्हें केवल आपका एंडपॉइंट चाहिए। अगर API संवेदनशील फील्ड लीक कर रहा है, इनपुट सीमाएँ नहीं लगा रहा, या कमजोर auth है, तो फॉर्मेट बदलना इसे ठीक नहीं करेगा।
ट्रांसपोर्ट एन्क्रिप्ट करें (TLS), authz चेक लागू करें, इनपुट वैलिडेट करें, और सुरक्षित रूप से लॉग करें—चाहे आप JSON REST API यूज़ कर रहे हों या grpc protobuf।
हमला सतह: पेलोड, पार्सर्स और वैलिडेशन
दोनों फॉर्मैट साझा जोखिम रखते हैं:
- अत्यधिक बड़े पेलोड्स: बड़े JSON दस्तावेज़ या विशाल Protobuf संदेश मेमोरी‑प्रेशर, धीमी पार्सिंग, या DoS ट्रिगर कर सकते हैं।
- पार्सर बग्स: हर पार्सर कोड है, और कोड में कमजोरियाँ हो सकती हैं। जोखिम यह नहीं है कि "JSON बनाम Protobuf", बल्कि आप कौन‑सी लाइब्रेरी इस्तेमाल कर रहे हैं और क्या वे अपडेट हैं।
- स्कीमा वैलिडेशन गैप्स: JSON फ्लेक्सिबल है, जिससे अनपेक्षित फील्ड्स या प्रकार स्वीकार किए जा सकते हैं जब तक आप JSON Schema से वैलिडेशन नहीं करते। Protobuf टाइप constraints देता है, पर फिर भी सेमांटिक रूप से अमान्य डेटा (उदा. नकारात्मक मात्रा) तब भी पास हो सकता है जब तक आप बिजनेस वैलिडेशन न करें।
विश्वसनीयता: सीमाएँ, टाइमआउट और सख्ती
API को लोड और दुरुपयोग के तहत भरोसेमंद रखने के लिए दोनों फॉर्मैट पर समान गार्डरेइल लागू करें:
- अधिकतम रिक्वेस्ट साइज और अधिकतम संदेश साइज सेट करें (कम्प्रेशन होने पर डिकंप्रेस्ड साइज भी शामिल करें)।
- स्लो‑क्लाइंट और स्लो‑पार्सर रिसोर्स ड्रेन से बचने के लिए टाइमआउट और cancellation रखें।
- सख्त वैलिडेशन अपनाएँ: अनिवार्य बिजनेस फील्ड्स, वैध रेंज, और unknown enum मानों को ठुकराएँ जहाँ उपयुक्त।
- लॉगिंग के साथ सावधान रहें: JSON पढ़ने में आसान है, पर दोनों फॉर्मैट्स में कच्चे पेलोड्स गलती से सीक्रेट्स उजागर कर सकते हैं।
निचोड़: “बाइनरी बनाम टेक्स्ट” मुख्यतः प्रदर्शन और एर्गोनॉमिक्स को प्रभावित करता है। सुरक्षा और विश्वसनीयता सुसंगत सीमाओं, अपडेटेड डिपेंडेंसियों, और स्पष्ट वैलिडेशन से आती है—चाहे आप कोई भी सीरियलाइज़र चुनें।
कब JSON चुनें और कब Protobuf चुनें
JSON और Protobuf के बीच चुनना इस बात से ज़्यादा संबंधित है कि आपका API किस बात के लिए ऑप्टिमाइज़ करना चाहता है: मानव‑मित्रता और पहुँच, या दक्षता और सख्त अनुबंध।
कब JSON सामान्यतः डिफ़ॉल्ट है
JSON आमतौर पर सबसे सुरक्षित डिफ़ॉल्ट है जब आपको व्यापक संगतता और आसान ट्रबलशूटिंग चाहिए।
सामान्य परिदृश्य:
- पब्लिक APIs जहाँ आप क्लाइंट्स को नियंत्रित नहीं करते (partners, third parties)
- ब्राउज़र और वेब क्लाइंट्स (नेटिव JSON सपोर्ट, DevTools में आसान निरीक्षण)
- प्रारंभिक उत्पाद चरणों में तेज़ इटरेशन (कम श्रीम, सरल पेलोड्स)
- डिबगिंग‑प्रथम वर्कफ़्लो (कॉपी/पेस्ट रिक्वेस्ट, पठनीय लॉग, तेज cURL टेस्टिंग)
- REST‑स्टाइल एंडपॉइंट्स जो व्यापक रूप से कैश या प्रॉक्सी किए जाएंगे
कब Protobuf चमकता है
Protobuf तब जीतती है जब प्रदर्शन और सुसंगतता मानव‑पठनीयता से ज़्यादा महत्वपूर्ण हों।
सामान्य परिदृश्य:
- हाई थ्रूपुट APIs जहाँ आप बैंडविड्थ का भुगतान करते हैं या बड़े पैमाने पर ऑपरेट करते हैं
- कई छोटे कॉल्स (chatty services) जहाँ सीरियलाइज़ेशन ओवरहेड जुड़ जाता है
- आंतरिक माइक्रोसर्विसेज़ जहाँ आप दोनों सिरों को नियंत्रित करते हैं और स्कीमा लागू कर सकते हैं
- gRPC‑आधारित सिस्टम (Protobuf नैचुरल फिट है और मजबूत टूलिंग देता है)
- मोबाइल/एज एन्वायरनमेंट जहाँ छोटे पेलोड्स लेटेंसी और बैटरी के लिहाज़ से मददगार होते हैं
निर्णय के लिए सवाल
इन सवालों से तेज़ी से चयन संकुचित करें:
- कौन API को consume करेगा? बाहरी/पब्लिक क्लाइंट्स → JSON।
- क्या आप सभी क्लाइंट्स और डिप्लॉयमेंट्स नियंत्रित करते हैं? यदि हाँ, Protobuf अपनाना आसान है।
- क्या प्रदर्शन वास्तविक बाधा है? मापें: p95 लेटेंसी, CPU, और egress लागत।
- कितनी जरूरी है सख्त टाइपिंग और स्कीमा अनुबंध? Protobuf गार्डरैइल देता है।
- क्या आपकी टूलिंग पर्याप्त परिपक्व है? कोड जनरेशन, CI चेक और डेवलपर ऑनबोर्डिंग पर विचार करें।
यदि आप अभी भी उलझन में हैं, तो "एज पर JSON, अंदर Protobuf" का तरीका प्रायोगिक रूप से व्यावहारिक समझौता है।
माइग्रेशन रणनीतियाँ: JSON और Protobuf के बीच जाना
अपने जनरेट किए गए कोड के मालिक बनें
पूरा सोर्स एक्सपोर्ट करें ताकि आपका API कॉन्ट्रैक्ट और जनरेटेड टाइप्स आपके repo में रहें।
फॉर्मेट माइग्रेट करना सब कुछ फिर से लिखने जैसा नहीं है; यह उपभोक्ताओं के लिए जोखिम कम करने के बारे में है। सबसे सुरक्षित कदम वह है जो संक्रमण के दौरान API उपयोग करने योग्य रहे और रोलबैक आसान हो।
1) छोटे से शुरू करें: एक एंडपॉइंट या एक आंतरिक सर्विस
कम‑जोखिम एरिया चुनें—अक्सर एक आंतरिक सर्विस‑टू‑सर्विस कॉल या एक single read‑only endpoint। इससे आप Protobuf स्कीमा, जेनरेटेड क्लाइंट्स और ऑब्ज़रवेबिलिटी चेंजेस को बिना बड़े‑बंग बदलाव के मान्य कर पाएँगे।
एक व्यावहारिक पहला कदम है कि मौजूदा रिसोर्स के लिए Protobuf रिप्रेजेंटेशन जोड़ें और JSON शेप को अपरिवर्तित रखें। इससे आपको जल्दी पता चल जाएगा कि आपका डेटा मॉडल कहाँ ambiguous है (null vs missing, नंबर vs string, date formats) और आप स्कीमा में उसे स्पष्ट कर सकेंगे।
2) अस्थायी तौर पर JSON और Protobuf साथ चलाएँ
बाहरी APIs के लिए dual support आम तौर पर सबसे स्मूद पथ है:
Content-TypeऔरAcceptहेडर्स के ज़रिए फॉर्मैट negotiate करें।- यदि नेगोशिएशन टूलिंग से मुश्किल है तो अलग endpoint (उदा.
/v2/...) एक्सपोज़ करें।
इस अवधि के दौरान, सुनिश्चित करें कि दोनों फॉर्मैट्स एक ही source‑of‑truth मॉडल से उत्पादित हों ताकि subtle drift न हो।
3) फॉर्मेट परिवर्तन को एक प्रोडक्ट बदलाव की तरह टेस्ट करें
योजना बनाएँ:
- Compatibility tests: पुराने क्लाइंट्स नए सर्वर पर और नए क्लाइंट्स पुराने सर्वर पर चलाएँ।
- Contract tests: अनिवार्य फील्ड्स, default व्यवहार और एरर रिस्पॉन्सेस वैलिडेट करें।
- Benchmarks: पेलोड साइज, CPU, और लेटेंसी मापें (कम्प्रेशन और TLS सहित)।
4) स्कीमा डॉक्युमेंट करें और उदाहरण भेजें
.proto फाइलें, फील्ड टिप्पणियाँ, और ठोस request/response उदाहरण (JSON और Protobuf दोनों) प्रकाशित करें ताकि कंज्यूमार यह सत्यापित कर सकें कि वे डेटा को सही तरीके से समझ रहे हैं। एक छोटा "migration guide" और चेंजलॉग सपोर्ट लोड घटाते हैं और अपनाने का समय छोटा करते हैं।
व्यावहारिक सर्वश्रेष्ठ अभ्यास और त्वरित चेकलिस्ट
JSON बनाम Protobuf चुनना अक्सर विचारधारा से कम और आपके ट्रैफ़िक, क्लाइंट्स और ऑपरेशनल प्रतिबंधों की वास्तविकता से ज़्यादा जुड़ा होता है। सबसे भरोसेमंद रास्ता है मापें, निर्णय दस्तावेज़ करें, और API चेंज को नीरस (boring) रखें।
अनुकूलित करने से पहले मापें
प्रतिनिधि endpoints पर छोटा प्रयोग चलाएँ।
ट्रैक करें:
- पेलोड साइज (median और p95)
- end‑to‑end लेटेंसी (client → server → client)
- सीरियलाइज़/डिसीरियलाइज़िंग पर सर्विसेज़ का CPU और मेमोरी उपयोग
- एरर रेट और टाइमआउट
इसको staging में production‑like डेटा के साथ करें, फिर production में छोटे ट्रैफ़िक स्लाइस पर सत्यापित करें।
स्कीमा और अनुबंध को voorspelbaar रखें
चाहे आप JSON Schema/OpenAPI या .proto फ़ाइलें इस्तेमाल करें:
- endpoints और फील्ड्स में सुसंगत नामकरण बनाएँ।
- स्पष्ट defaults परिभाषित और डॉक्यूमेंट करें। “Missing” बनाम “empty” क्लाइंट्स के लिए अप्रत्याशित नहीं होना चाहिए।
- additive changes प्राथमिकता दें; अर्थ बदलने के बजाय नए optional फील्ड जोड़ें।
- डिप्रेकेटेड फील्ड्स के साथ स्पष्ट नोट्स और timelines दें, और क्लाइंट्स माइग्रेट होने तक deprecated फील्ड्स काम करते रहें।
डेवलपर अनुभव को प्राथमिकता दें
भले ही आप प्रदर्शन के लिए Protobuf चुनें, अपने डॉक्स को मित्रवत रखें:
- उदाहरण requests/responses शामिल करें ("happy path" और सामान्य एरर)।
- सबसे सामान्य भाषाओं के लिए कॉपी‑पेस्ट करने योग्य क्लाइंट स्निपेट दें।
- पेलोड्स को लॉग/टूलिंग में कैसे निरीक्षण करें, यह दस्तावेज़ करें।
यदि आप डॉक्यूम्स या SDK गाइड में बदलाव करते हैं, तो उन्हें स्पष्ट लिंक दें (उदा. /docs और /blog)। यदि प्राइसिंग या उपयोग‑सीमाएँ फॉर्मैट चुनाव को प्रभावित करती हैं, तो वह भी दिखाएँ (/pricing)।
त्वरित चेकलिस्ट
- प्रमुख endpoints के लिए पेलोड साइज + p95 लेटेंसी + एरर रेट मापें
- सुसंगत फील्ड नामकरण और स्पष्ट default व्यवहार डॉक्यूमेंट किए गए हों
- केवल additive changes; डिप्रेकेशन्स की तारीख और माइग्रेशन नोट्स हों
- डॉक्युमेंटेशन में उदाहरण शामिल हों; क्लाइंट स्निपेट उपलब्ध हों
- ऑब्ज़रवेबिलिटी प्लान: चुने गए फॉर्मैट के लिए लॉगिंग/ट्रेसबिलिटी काम करती हो
अक्सर पूछे जाने वाले प्रश्न
API में JSON और Protobuf का व्यावहारिक अंतर क्या है?
JSON एक टेक्स्ट-आधारित फॉर्मेट है जिसे पढ़ना, लॉग करना और आम टूल्स से टेस्ट करना आसान है। Protobuf एक .proto स्कीमा द्वारा परिभाषित कॉम्पैक्ट बाइनरी फॉर्मेट है, जो अक्सर छोटे पेलोड और तेज पार्सिंग देता है।
निर्णय आपकी ज़रूरतों पर निर्भर करता है: पहुंच और डिबग करने की सुविधा (JSON) बनाम दक्षता और सख्त अनुबंध (Protobuf)।
request/response फ्लो में “serialization” और “deserialization” का क्या मतलब है?
API बाइट्स भेजते हैं, इन-मेमोरी ऑब्जेक्ट्स नहीं। Serialization आपके सर्वर ऑब्जेक्ट्स को ट्रांसपोर्ट के लिए एक पेलोड (JSON टेक्स्ट या Protobuf बाइनरी) में एन्कोड करता है; deserialization उन बाइट्स को वापस क्लाइंट/सर्वर ऑब्जेक्ट्स में डीकोड करता है।
आपका फॉर्मेट विकल्प बैंडविड्थ, लेटेंसी और (डि)सीरियलाइज़ेशन में लगने वाले CPU समय को प्रभावित करता है।
क्या Protobuf हमेशा JSON से वायर पर छोटा होता है?
अक्सर हाँ—खासकर बड़े या नेस्टेड ऑब्जेक्ट्स और रिपीटेड फील्ड्स के मामले में, क्योंकि Protobuf न्यूमेरिक टैग और कुशल बाइनरी एन्कोडिंग का उपयोग करता है।
हालाँकि, यदि आप gzip/brotli सक्षम करते हैं तो JSON में रिपीटेड कुंजियाँ अच्छी तरह कंप्रेस हो जाती हैं, इसलिए वास्तविक दुनिया में साइज का अंतर कम हो सकता है। हमेशा raw और compressed साइज दोनों मापें।
क्या Protobuf encode/decode और लेटेंसी में हमेशा JSON से तेज़ है?
यह संभव है। JSON पार्सिंग में टेक्स्ट टोकनाइज़ेशन, एस्केपिंग/यूनिकोड हैंडलिंग और स्ट्रिंग→नंबर कन्वर्ज़न शामिल है। Protobuf डीकोडिंग अधिक डायरेक्ट होती है (tag → typed value), जिससे अक्सर CPU समय और GC कम होता है।
फिर भी, अगर पेलोड बहुत छोटे हैं तो लेटेंसी पर TLS, नेटवर्क RTT और एप्लिकेशन वर्क का ज्यादा प्रभाव पड़ सकता है।
Protobuf को debug और log करना JSON से कठिन क्यों है?
डिफ़ॉल्ट रूप से हाँ—JSON इंस्पेक्शन और DevTools, curl, Postman जैसे टूल्स में आसान है। Protobuf बाइनरी होने के कारण पढ़ने में कठिन होता है और सही .proto स्कीमा और डिकोडिंग टूल की ज़रूरत होती है।
बेहतर वर्कफ़्लो के लिए अक्सर एक decoded, redacted debug view (अक्सर JSON में) को बाइनरी पेलोड के साथ लॉग किया जाता है।
JSON और Protobuf के बीच स्कीमा और टाइप सुरक्षा कैसे अलग होती है?
JSON मूलतः schema-less है जब तक कि आप JSON Schema/OpenAPI लागू न करें। यह फ्लेक्सिबिलिटी शुरुआत में सुविधाजनक है पर गलतियों को छिपा सकती है—जैसे inconsistent field names, “stringly-typed” values, या ambiguous null semantics。
Protobuf .proto फ़ाइल के जरिए टाइप-सेफ़्टी और स्पष्ट अनुबंध प्रदान करता है, जिससे मल्टी-टीम और मल्टी-लैंग्वेज वातावरण में parsing उम्मीद के अनुसार रहती है।
JSON बनाम Protobuf में क्लाइंट ब्रेक किए बिना API को कैसे विकसित करें?
Protobuf में हर फील्ड का एक फील्ड नंबर (टैग) होता है, और वही वायर पर पहचान है। सुरक्षित बदलाव आम तौर पर additive होते हैं: नए optional फील्ड जोड़ें और नए नंबर इस्तेमाल करें।
जो चीजें अक्सर ब्रेक करती हैं: किसी पुराने नंबर का पुन: उपयोग करना, प्रकार बदलना (string → int), या किसी फील्ड को हटाकर उसका नंबर वापस लेना।
JSON में कम्पैटिबिलिटी पैटर्न और अनुशासन पर निर्भर करती है—आम आचरण additive बदलाव करना और unknown fields को इग्नोर करना है।
क्या एक API एक साथ JSON और Protobuf दोनों सपोर्ट कर सकता है?
हाँ। कंटेंट-नेगोशिएशन का उपयोग करें:
- क्लाइंट भेजे
Accept: application/jsonयाAccept: application/x-protobuf - सर्वर जवाब दे उपयुक्त
Content-Typeके साथ Vary: Acceptजोड़ें ताकि कैश्स फॉर्मैट मिश्रित न कर दें
अगर आपका टूलिंग negotiation कठिन बनाती है, तो अस्थायी रूप से अलग endpoint/version (उदा. ) एक्सपोज़ करना भी बेहतरीन हो सकता है।
कौन से टूलिंग और प्लेटफ़ॉर्म प्रतिबंध चुनाव को प्रभावित करना चाहिए?
यह आपके वातावरण पर निर्भर है:
- ब्राउज़र/पब्लिक APIs: JSON कम से कम फ़्रिक्शन के साथ आता है और डिफ़ॉल्ट टूलिंग बेहतर होती है।
- मोबाइल/बैकएंड/इंटरनल: Protobuf मजबूत लाइब्रेरीज़ और code generation के साथ लाभ देता है।
- gRPC सिस्टम: Protobuf नैचुरल मैच है और generated stubs/streaming के साथ घुलमिल जाता है।
Protobuf चुनने पर codegen, CI और स्कीमा वर्शनिंग की मेंटेनेंस लागत को ध्यान में रखें।
Protobuf चुनना सुरक्षा या विश्वसनीयता में सुधार करता है?
फॉर्मेट परिवर्तन स्वयं सुरक्षा नहीं है। दोनों पर समान सुरक्षा आवश्यकताएँ लागू होती हैं—TLS, authz, इनपुट वैलिडेशन, और लॉगिंग में redaction।
दोनों के लिए प्रैक्टिकल गार्डरेड्स:
- अधिकतम request/message साइज सेट करें (डिकंप्रेस्ड साइज सहित)
- टाइमआउट और cancellation लागू करें
- बिजनेस-रूल वैलिडेशन करें (टाइप-चेक पर्याप्त नहीं)
- संवेदनशील फ़ील्ड्स को लॉग न करें; संरचित लॉग और redaction अपनाएँ
पार्सर लाइब्रेरीज़ को अपडेट रखना भी महत्वपूर्ण है।