15 जुल॰ 2025·8 मिनट
प्रयोग-आधारित मूल्य कार्यान्वयन: मीटरिंग और सामंजस्य
प्रयोग-आधारित मूल्य कार्यान्वयन: क्या मीटर करें, कुल कहाँ कैलकुलेट करें, और वो reconciliation जांचें जो इनवॉइस भेजने से पहले बिलिंग बग्स पकड़ती हैं।
प्रयोग-आधारित मूल्य कार्यान्वयन: क्या मीटर करें, कुल कहाँ कैलकुलेट करें, और वो reconciliation जांचें जो इनवॉइस भेजने से पहले बिलिंग बग्स पकड़ती हैं।
Usage billing तब टूटता है जब इनवॉइस पर जो नंबर है वह आपके प्रोडक्ट ने जो दिया उसके साथ मेल नहीं खाता। शुरुआती अंतर बहुत छोटा (कई गुमशुदा API कॉल्स) हो सकता है, फिर वह रिफंड्स, नाराज़ टिकट और उस वित्त टीम तक बढ़ जाता है जो डैशबोर्ड्स पर भरोसा करना बंद कर देती है।
कारण आम तौर पर अनुमान लगाने योग्य होते हैं। घटनाएँ गायब हो जाती हैं क्योंकि एक सर्विस क्रैश हो गई जो उपयोग रिपोर्ट करने से पहले थी, कोई कतार डाउन थी, या कोई क्लाइंट ऑफ़लाइन चला गया। घटनाएँ दो बार गिनी जाती हैं क्योंकि रिट्राई हुए, वर्कर्स ने एक ही संदेश को फिर से प्रोसेस किया, या कोई इम्पोर्ट जॉब फिर चला। समय अपने खुद के मुद्दे लाता है: सर्वरों के बीच क्लॉक ड्रिफ्ट, टाइमज़ोन, डे लाईट सेविंग्स, और लेट-आगमन इवेंट्स उपयोग को गलत बिलिंग अवधि में धकेल सकते हैं।
एक त्वरित उदाहरण: एक चैट प्रोडक्ट जो प्रति AI जनरेशन चार्ज करता है, एक इवेंट तब भेज सकता है जब अनुरोध शुरू होता है, और दूसरा जब यह समाप्त होता है। अगर आप स्टार्ट इवेंट से बिल करते हैं, तो आप फेल्यर्स के लिए चार्ज कर सकते हैं। अगर आप फिनिश इवेंट से बिल करते हैं, तो आप उन मामलों को मिस कर सकते हैं जहाँ अंतिम कॉलबैक कभी नहीं आया। अगर दोनों बिल होते हैं, तो डबल चार्ज हो जाएगा।
कई लोगों को एक ही नंबर पर भरोसा करने की ज़रूरत होती है:
लक्ष्य केवल सटीक टोटल नहीं है। यह समझने योग्य इनवॉइस और तेज़ विवाद निपटान भी है। अगर आप किसी लाइन आइटम को कच्चे उपयोग तक ट्रेस नहीं कर सकते, तो एक आउटेज आपका बिलिंग अनुमान पर बदल सकता है, और तभी बिलिंग बग बिलिंग इन्सिडेंट बनते हैं।
एक सरल सवाल से शुरू करें: आप बिल्कुल किस चीज़ के लिए चार्ज कर रहे हैं? अगर आप यूनिट और नियम एक मिनट में समझा नहीं पा रहे, तो सिस्टम अंदाज़ा लगाने लगेगा और ग्राहक नोटिस करेंगे।
एक मीटर पर एक प्राथमिक बिल योग्य यूनिट चुनें। सामान्य विकल्प हैं: API कॉल्स, रिक्वेस्ट्स, टोकन, compute मिनट्स, GB स्टोर्ड, GB ट्रांसफर, या सीट्स। ब्लेंडेड यूनिट्स (जैसे “सक्रिय उपयोगकर्ता मिनट”) से बचें जब तक वास्तव में ज़रूरत न हो—वे ऑडिट और समझाने में कठिन होते हैं।
उपयोग की सीमाएँ परिभाषित करें। यह स्पष्ट करें कि उपयोग कब शुरू और कब बंद होता है: क्या ट्रायल में मेटर्ड ओवरेज शामिल हैं, या एक कैप तक मुफ्त है? अगर आप ग्रेस पीरियड देते हैं, तो क्या ग्रेस के दौरान उपयोग बाद में बिल होगा या माफ़ किया जाएगा? प्लान परिवर्तन वहीं होते हैं जहाँ भ्रम बढ़ता है। तय करें कि क्या आप प्रोरेट करेंगे, अलाउंसेज तुरंत रीसेट करेंगे, या परिवर्तन अगले बिलिंग चक्र पर लागू करेंगे।
राउंडिंग और मिनिमम्स लिखकर रखें बजाय उन्हें निहित रहने दें। उदाहरण के लिए: निकटतम सेकंड, मिनट, या 1,000 टोकन तक राउंड अप करें; दैनिक न्यूनतम शुल्क लागू करें; या 1 MB जैसे न्यूनतम बिलेबल इंक्रीमेंट को लागू करें। ऐसे छोटे नियम बड़े “मैंसे क्यों चार्ज हुआ?” टिकट बनाते हैं।
जल्दी पिन करने योग्य नियम:
उदाहरण: एक टीम प्रो पर है, फिर मध्य-महीने अपग्रेड करती है। अगर आप अपग्रेड पर अलाउंसेज रीसेट करते हैं, तो उन्हें एक महीने में प्रभावी रूप से दो मुफ्त अलाउंसेज मिल सकते हैं। अगर आप रीसेट नहीं करते, तो उन्हें अपग्रेड करने पर दंडित महसूस हो सकता है। दोनों विकल्प वैध हो सकते हैं, पर यह सुसंगत, दस्तावेजीकृत और टेस्टेबल होना चाहिए।
निर्धारित करें कि क्या एक बिल योग्य इवेंट माना जाएगा और उसे डेटा के रूप में लिखें। अगर आप केवल इवेंट्स से “क्या हुआ” की कहानी फिर से नहीं चला सकते, तो विवादों के समय आप अनुमान लगाने लगेंगे।
“उपयोग हुआ” से अधिक ट्रैक करें। आपको वे इवेंट्स भी चाहिए जो ग्राहक को क्या भुगतान करना चाहिए बदलते हैं:
अधिकांश बिलिंग बग्स संदर्भ की कमी से आते हैं। अब ही उबाऊ फील्ड्स कैप्चर करें ताकि सपोर्ट, वित्त और इंजीनियरिंग बाद में सवालों का जवाब दे सकें।
सपोर्ट-ग्रेड मेटाडेटा भी लाभ देता है: request ID या trace ID, रीजन, ऐप वर्शन, और लागू प्राइसिंग रुल्स वर्शन। जब कोई ग्राहक कहे “मुझे 2:03 PM पर दो बार क्यों चार्ज किया गया,” ये फील्ड्स वही हैं जो आपको साबित करने, सुरक्षित रूप से रिवर्स करने, और दोहराव रोकने देती हैं।
पहला नियम सरल है: बिल योग्य इवेंट्स उसी सिस्टम से इमिट करें जिसे वाकई पता हो कि काम हुआ। ज्यादातर मामलों में वह आपका सर्वर होता है, न कि ब्राउज़र या मोबाइल ऐप।
क्लाइंट-साइड काउंटर्स स्पूफ करना आसान और खोना आसान होते हैं। उपयोगकर्ता अनुरोध ब्लॉक कर सकते हैं, उन्हें रिप्ले कर सकते हैं, या पुराना कोड चला सकते हैं। खराब इरादे न भी हों, मोबाइल ऐप क्रैश होते हैं, क्लॉक्स ड्रिफ्ट करते हैं, और रिट्राई होते हैं। अगर आपको क्लाइंट संकेत पढ़ना ही है, तो उसे एक हिंट मानकर रखें, इनवॉइस न मानें।
एक व्यावहारिक तरीका यह है कि आप उपयोग तब इमिट करें जब आपका बैकएंड किसी अपरिवर्तनीय बिंदु को पार करे, जैसे जब आपने एक रिकॉर्ड परस्थायी रूप से स्टोर कर लिया, एक जॉब पूरा हुआ, या आपने एक ऐसी रिस्पॉन्स डिलीवर की जिसे आप प्रमाणित कर सकें। भरोसेमंद इमिशन पॉइंट्स में शामिल हैं:
ऑफलाइन मोबाइल मुख्य अपवाद है। अगर कोई Flutter ऐप कनेक्शन के बिना काम करना चाहिए, तो यह स्थानीय रूप से उपयोग ट्रैक कर सकता है और बाद में अपलोड कर सकता है। गार्डरेल्स डालें: एक यूनिक इवेंट ID, डिवाइस ID, और मोनोटोनिक सीक्वेंस नंबर शामिल करें, और सर्वर जितना हो सके वैलिडेट करे (अकाउंट स्टेटस, प्लान लिमिट्स, डुप्लिकेट IDs, असंभव टाइमस्टैम्प)। जब ऐप reconnect करे, तो सर्वर को इवेंट्स idempotently स्वीकार करना चाहिए ताकि retries डबल चार्ज न करें।
इवेंट टाइमिंग इस बात पर निर्भर करती है कि उपयोगकर्ता क्या देखने की उम्मीद करते हैं। रीयल-टाइम API कॉल्स के लिए काम करता है जहाँ ग्राहक डैशबोर्ड में उपयोग देखते हैं। नियर-रीयल-टाइम (कुछ मिनटों में) अक्सर काफी होता है और सस्ता भी। बैच हाई-वॉल्यूम सिग्नल्स के लिए काम कर सकता है (जैसे storage scans), पर देरी के बारे में स्पष्ट रहें और वही source-of-truth नियम अपनाएँ ताकि लेट डेटा पुराने इनवॉइस को चुपचाप न बदल दे।
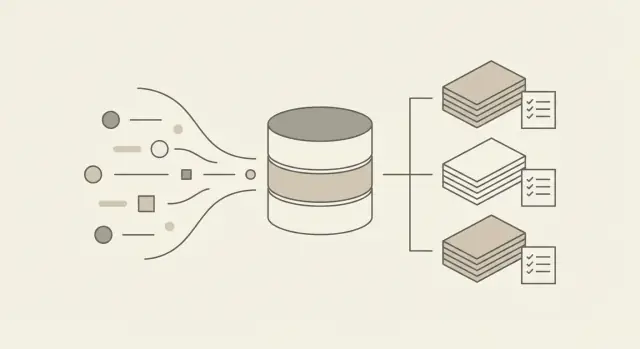
आपको दो चीज़ें चाहिए जो अनावश्यक लग सकती हैं पर बाद में बचाती हैं: अपरिवर्तनीय कच्चे इवेंट्स (जो हुआ) और व्युत्पन्न टोटल्स (जो आप बिल करते हैं)। Raw events आपका स्रोत-प्रमाण हैं। Aggregated usage वही है जिसे आप जल्दी क्वेरी कर सकते हैं, ग्राहकों को समझा सकते हैं, और इनवॉइस में बदल सकते हैं।
आप दो सामान्य स्थानों पर टोटल्स कैलकुलेट कर सकते हैं। डेटाबेस में करना (SQL जॉब्स, materialized tables, शेड्यूल्ड क्वेरीज़) शुरुआती दौर में ऑपरेट करने में सरल है और लॉजिक को डेटा के पास रखता है। एक समर्पित aggregator सेवा (एक छोटा वर्कर जो इवेंट्स पढ़कर रोलअप लिखता है) वर्शनिंग, टेस्टिंग और स्केल करने में आसान है, और यह उत्पादों के बीच सुसंगत नियम लागू कर सकता है।
Raw events आपको बग्स, रिफंड और विवादों से बचाते हैं। Aggregates आपको धीमे इनवॉइस और महंगे क्वेरीज़ से बचाते हैं। अगर आप केवल aggregates स्टोर करते हैं, तो एक गलत नियम इतिहास को स्थायी रूप से करप्ट कर सकता है।
एक व्यावहारिक सेटअप:
एग्रीगेशन विंडो को स्पष्ट रखें। एक बिलिंग टाइमज़ोन चुनें (अक्सर ग्राहक का, या सभी के लिए UTC) और उसी पर टिके रहें। “दिन” की सीमाएँ टाइमज़ोन के साथ बदलती हैं, और जब उपयोग दिनों के बीच शिफ्ट होता है तो ग्राहक नोटिस करते हैं।
लेट और आउट-ऑफ-ऑर्डर इवेंट्स सामान्य हैं (मोबाइल ऑफ़लाइन, रिट्राई, कतार देरी)। पिछले इनवॉइस को चुपचाप न बदलें क्योंकि एक लेट इवेंट आया। एक क्लोज-एंड-फ्रीज़ नियम रखें: एक बार जब एक बिलिंग अवधि इनवॉइस हो गई, तो सुधारों को अगले इनवॉइस में समायोजन के रूप में लिखें और स्पष्ट कारण दें।
उदाहरण: अगर API कॉल्स मासिक बिल किए जाते हैं, तो आप डैशबोर्ड के लिए घंटा-वार काउंट, अलर्ट्स के लिए दैनिक काउंट, और इनवॉइसिंग के लिए एक मासिक फ्रीज़ टोटल बना सकते हैं। अगर 200 कॉल्स दो दिन बाद आते हैं, तो उन्हें रिकॉर्ड करें, पर अगले महीने एक +200 समायोजन के रूप में बिल करें, पिछले महीने का इनवॉइस पुनर्लेखन करके नहीं।
एक काम करने वाला उपयोग पाइपलाइन ज्यादातर डेटा फ्लो है जिसमें सख्त गार्डरेल्स होते हैं। क्रम सही रखें और आप मूल्य निर्धारण बाद में बिना सब कुछ हाथ से फिर से प्रोसेस किए बदल सकेंगे।
जब एक इवेंट आता है, तो उसे वैलिडेट और नार्मलाइज़ तुरंत करें। आवश्यक फील्ड्स चेक करें, यूनिट्स कन्वर्ट करें (bytes से GB, सेकंड्स से मिनट्स), और टाइमस्टैम्प्स को एक स्पष्ट नियम के मुताबिक क्लैंप करें (इवेंट समय बनाम रिसीव्ड समय)। अगर कुछ invalid है, तो उसे quietly ड्रॉप करने के बजाय rejected के रूप में कारण के साथ स्टोर करें।
नार्मलाइज़ेशन के बाद, append-only मानसिकता बनाए रखें और इतिहास को जगह पर “ठीक” न करें। Raw events आपका स्रोत-प्रमाण हैं।
यह फ्लो अधिकांश उत्पादों के लिए काम करता है:
फिर इनवॉइस वर्शन को फ्रीज़ करें। “फ्रीज़” का मतलब है एक ऑडिट ट्रेल रखना जो जवाब दे: किन raw events ने, किस dedupe नियम ने, किस aggregation कोड वर्शन ने, और किस प्राइसिंग रुल्स ने ये लाइन आइटम बनाए। अगर बाद में आप कोई कीमत बदलते हैं या बग फिक्स करते हैं, तो नया इनवॉइस संशोधन बनाएं, न कि चुपके से एडिट।
डबल चार्जिंग और मिसिंग उपयोग आमतौर पर उसी मूल समस्या से आते हैं: आपका सिस्टम तय नहीं कर पाता कि कोई इवेंट नया है, डुप्लिकेट है, या खो गया है। यह चालाक बिलिंग लॉजिक से कम और इवेंट आइडेंटिटी और वैलिडेशन के आसपास सख्त नियंत्रण के बारे में अधिक है।
Idempotency कीज़ पहली रक्षा पंक्ति हैं। एक ऐसी की बनाएं जो वास्तविक-विश्व कार्रवाई के लिए स्थिर हो, ना कि HTTP रिक्वेस्ट के लिए। एक अच्छी की deterministic और बिल योग्य यूनिट के लिए यूनिक होनी चाहिए, उदाहरण के लिए: tenant_id + billable_action + source_record_id + time_bucket (जब यूनिट टाइम-आधारित हो तब ही टाइम बकेट का उपयोग करें)। इसे पहले durable write पर लागू करें, आमतौर पर आपका ingestion डेटाबेस या इवेंट लॉग, एक unique constraint के साथ ताकि डुप्लिकेट्स आ ही न सकें।
रिट्राइज़ और टाइमआउट सामान्य हैं, तो इनके लिए डिजाइन करें। एक क्लाइंट वही इवेंट 504 के बाद दोबारा भेज सकता है भले ही आपने उसे पहले ही प्राप्त कर लिया हो। आपका नियम होना चाहिए: रिपीट्स स्वीकार करें, पर उन्हें दो बार गिनें नहीं। रिसीविंग को काउंटिंग से अलग रखें: एक बार ingest करें (idempotent), फिर स्टोर किए गए इवेंट्स से aggregate करें।
वैलिडेशन “असंभव उपयोग” को टोटल्स को करप्ट करने से रोकता है। ingest पर और फिर aggregation पर फिर से वैलिडेट करें, क्योंकि दोनों जगह बग हो सकते हैं।
मिसिंग उपयोग को नोटिस करना सबसे कठिन है, इसलिए ingestion त्रुटियों को first-class डेटा मानें। फेल्ड इवेंट्स को सफल इवेंट्स से अलग रखें और उन्हीं फील्ड्स के साथ स्टोर करें (idempotency की सहित), साथ में एक त्रुटि कारण और retry काउंट।
Reconciliation checks वे उबाऊ गार्डरेल हैं जो “हमने ज्यादा चार्ज किया” और “हमने उपयोग मिस किया” को ग्राहकों के नोटिस में आने से पहले पकड़ते हैं।
शुरूआत एक ही समय विंडो को दो जगहों पर reconcile करके करें: raw events और aggregated usage। एक निश्चित विंडो चुनें (उदा.: कल UTC में), फिर काउंट्स, सम्स, और यूनिक IDs की तुलना करें। छोटे अंतर होते हैं (लेट इवेंट्स, रिट्राइज़), पर उन्हें ज्ञात नियमों द्वारा समझाया जाना चाहिए, रहस्य द्वारा नहीं।
फिर वह जो आपने बिल किया उसके विरुद्ध आपने जो प्राइस किया उसकी reconciliation करें। एक इनवॉइस को एक प्राइस किए गए उपयोग स्नैपशॉट से पुनरुत्पादन योग्य होना चाहिए: सटीक उपयोग टोटल्स, सटीक प्राइस नियम, सटीक करेंसी, और सटीक राउंडिंग। अगर इनवॉइस बाद में फिर से चलाने पर बदलता है, तो आपके पास इनवॉइस नहीं, अनुमान है।
डेली सैनीटी चेक्स उन मुद्दों को पकड़ते हैं जो “गलत मैथ” नहीं पर “अजीब वास्तविकता” हैं:
जब आप समस्या पाते हैं, तो आपको एक बैकफिल प्रक्रिया की ज़रूरत होगी। बैकफिल्स इरादतन और लॉग किए जाने चाहिए। रिकॉर्ड करें कि क्या बदला, कौन-सा विंडो, कौन-से ग्राहक, किसने ट्रिगर किया, और कारण क्या था। समायोजन को अकाउंटिंग एंट्री की तरह ट्रीट करें, चुपके से किए गए एडिट की तरह नहीं।
एक सरल विवाद वर्कफ़्लो सपोर्ट को शांत रखता है। जब कोई ग्राहक चार्ज पर सवाल उठाता है, तो आपको कच्चे इवेंट्स से उसी स्नैपशॉट और प्राइसिंग वर्शन का उपयोग करके उनका इनवॉइस पुनरुत्पादन करने में सक्षम होना चाहिए। इससे एक अस्पष्ट शिकायत एक ठीक करने योग्य बग में बदल जाती है।
सबसे ज़्यादा बिलिंग की आगें जटिल गणित से नहीं होतीं। वे छोटे अनुमानों से आती हैं जो केवल सबसे बुरे समय पर टूटते हैं: महीने के अंत में, अपग्रेड के बाद, या एक रिट्राई स्फीयर के दौरान। सावधान रहना ज्यादातर समय के लिए, पहचान और नियमों के लिए एक सच पकड़ने और उसे नहीं मोड़ने के बारे में है।
ये बार-बार दिखाई देते हैं, यहां तक कि परिपक्व टीमों में भी:
उदाहरण: एक ग्राहक 20 तारीख को अपग्रेड करता है और आपका इवेंट प्रोसेसर 19 की एक दिन की डेटा timeout के बाद फिर से ट्राई करता है। बिना idempotency कीज़ और नियम वर्शनिंग के, आप 19 को डुप्लिकेट कर सकते हैं और 1-19 को नए दर पर प्राइस कर सकते हैं।
यहाँ एक सरल उदाहरण है एक ग्राहक, Acme Co, के लिए, जिसे तीन मीटरों पर बिल किया जाता है: API कॉल्स, storage (GB-days), और प्रीमियम फीचर रन।
ये वे इवेंट्स हैं जो आपका ऐप एक दिन (5 जनवरी) में इमिट करता है। ध्यान दें वे फील्ड्स जो बाद में कहानी को फिर से बनाना आसान बनाते हैं: event_id, customer_id, occurred_at, meter, quantity, और एक idempotency key।
{"event_id":"evt_1001","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1002","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1003","customer_id":"cust_acme","occurred_at":"2026-01-05T10:00:00Z","meter":"storage_gb_days","quantity":42.0,"idempotency_key":"daily_storage_2026-01-05"}
{"event_id":"evt_1004","customer_id":"cust_acme","occurred_at":"2026-01-05T15:40:10Z","meter":"premium_runs","quantity":3,"idempotency_key":"run_batch_991"}
महीने के अंत में, आपका aggregation जॉब raw events को customer_id, meter, और बिलिंग अवधि द्वारा समूहित करता है। जनवरी के टोटल्स पूरे महीने के योग होते हैं: API कॉल्स का योग 1,240,500; storage GB-days का योग 1,310.0; premium runs का योग 68।
अब एक लेट इवेंट 2 फरवरी को आता है, पर वह 31 जनवरी का है (मोबाइल क्लाइंट ऑफ़लाइन था)। क्योंकि आप aggregate occurred_at (इंगेस्ट टाइम नहीं) द्वारा करते हैं, जनवरी के टोटल बदल जाते हैं। आप या तो (a) अगले इनवॉइस पर एक समायोजन लाइन जेनरेट करते हैं या (b) अपनी पॉलिसी द्वारा अनुमति हो तो जनवरी को फिर से जारी करते हैं।
Reconciliation यहाँ एक बग पकड़ता है: evt_1001 और evt_1002 में वही idempotency_key (req_7f2) है। आपकी जांच "एक अनुरोध के लिए दो बिल योग्य इवेंट्स" को फ्लैग करती है और इनवॉइसिंग से पहले एक को डुप्लिकेट के रूप में चिह्नित कर देती है।
सपोर्ट इसे सरलता से समझा सकता है: "हमने同一 API अनुरोध को retry के कारण दो बार रिपोर्ट होते देखा। हमने डुप्लिकेट उपयोग इवेंट हटा दिया, इसलिए आपको एक बार चार्ज किया गया। आपके इनवॉइस में समायोजन शामिल है जो सुधरे हुए टोटल को दर्शाता है।"
बिलिंग चालू करने से पहले, अपने उपयोग सिस्टम को एक छोटे वित्तीय लेजर की तरह ट्रीट करें। अगर आप वही कच्चे डेटा फिर से चला कर वही टोटल नहीं पा सकते, तो आप "असंभव" चार्ज ढूँढने में रातें बिताएँगे।
इस चेकलिस्ट को अंतिम गेट के रूप में इस्तेमाल करें:
एक व्यावहारिक परीक्षण: एक ग्राहक चुनें, पिछले 7 दिनों के raw events को एक क्लीन डेटाबेस में replay करें, फिर उपयोग और एक इनवॉइस जेनरेट करें। अगर परिणाम प्रोडक्शन से अलग है, तो आपकी समस्या गणित नहीं बल्कि निर्धारकता (determinism) है।
पहला रिलीज़ पायलट की तरह ट्रीट करें। एक बिलेबल यूनिट चुनें (उदा.: "API कॉल्स" या "GB स्टोर्ड") और एक reconciliation रिपोर्ट जो आपने जो बिल करने की उम्मीद की थी बनाम असल में जो बिल हुआ, उसकी तुलना करे। एक पूरे चक्र तक वह स्थिर रहने पर अगला यूनिट जोड़ें।
पहले दिन से सपोर्ट और वित्त को सफल बनाएं—उन्हें एक सरल इंटरनल पेज दें जो दोनों पक्ष दिखाए: कच्चे इवेंट्स और वे समेकित टोटल जो इनवॉइस पर जाते हैं। जब ग्राहक पूछे "मुझे क्यों चार्ज किया गया?", तो आप चाहते हैं कि एक ही स्क्रीन मिनटों में इसका जवाब दे दे।
असली पैसा चार्ज करने से पहले, रीयलिटी को रीप्ले करें। स्टेजिंग डेटा का उपयोग करके एक पूरा महीना सिमुलेट करें, अपनी aggregation चलाएँ, इनवॉइस जेनरेट करें, और छोटे नमूना खातों के लिए मैन्युअली गिने गए अपेक्षित परिणामों से तुलना करें। कुछ ग्राहकों को चुनें जिनके पैटर्न अलग हों (कम, स्पाइकी, स्थिर) और सुनिश्चित करें कि उनके टोटल raw events, daily aggregates, और invoice lines में सुसंगत हैं।
अगर आप मीटरिंग सेवा खुद बना रहे हैं, तो Koder.ai (koder.ai) जैसे प्लेटफॉर्म का उपयोग एक अंदरूनी एडमिन UI और एक Go + PostgreSQL बैकएंड प्रोटोटाइप करने के लिए तेज़ रास्ता हो सकता है, फिर लॉजिक स्थिर होने पर स्रोत कोड एक्सपोर्ट करें।
जब बिलिंग नियम बदलते हैं, जोखिम कम करने के लिए एक रिलीज़ रूटीन अपनाएँ:
Usage billing तब टूटता है जब इनवॉइस का कुल आपके प्रोडक्ट की वास्तविक डिलीवरी से नहीं मिलता।
आम कारण:
समाधान “बेहतर गणित” से कम और घटनाओं को भरोसेमंद, डुप्लिकेट-रहित और एंड-टू-एंड समझने योग्य बनाने से ज्यादा संबंधित है।
प्रति मीटर एक स्पष्ट यूनिट चुनें और उसे एक वाक्य में परिभाषित करें (उदा.: “एक सफल API अनुरोध” या “एक पूरा AI जनरेशन”)।
फिर उन नियमों को लिखें जिन पर ग्राहक बहस कर सकते हैं:
अगर आप यूनिट और नियम को जल्दी समझाकर नहीं बता पाते, तो बाद में ऑडिट और सपोर्ट में मुश्किल होगी।
केवल खपत नहीं—“पैसे से जुड़ी” घटनाएँ भी ट्रैक करें।
कम से कम:
यह सुनिश्चित करता है कि प्लान बदलने या सुधार होने पर इनवॉइस पुनरुत्पादन योग्य रहे।
वो संदर्भ कैप्चर करें जिसकी आपको “मैं क्यों चार्ज हुआ?” का जवाब बिना अंदाज़े के देने के लिए ज़रूरत होगी:
occurred_at UTC में और एक ingest timestampसपोर्ट-ग्रेड एक्स्ट्रा (request/trace ID, region, app version, pricing-rule version) विवादों के निपटान को तेज बनाते हैं।
बिल योग्य घटनाएँ उस सिस्टम से इमिट करें जिसे वाकई पता है कि काम हुआ—आम तौर पर आपका बैकएंड, ना कि ब्राउज़र या मोबाइल ऐप।
अच्छे इमिशन पॉइंट्स वे हैं जो “अपरिवर्तनीय” हैं, जैसे:
क्लाइंट-साइड सिग्नल आसानी से खो सकते हैं और स्पूफ हो सकते हैं—इन्हें केवल संकेत के रूप में लें जब तक आप उन्हें अच्छे से वैलिडेट न कर सकें।
दोनों का उपयोग करें:
अगर आप केवल aggregates स्टोर करते हैं, तो एक गलत नियम इतिहास को स्थायी रूप से भ्रष्ट कर सकता है। अगर केवल raw events हैं, तो इनवॉइस और डैशबोर्ड धीमे और महंगे हो सकते हैं।
डुप्लिकेट्स को गिनना असंभव बनाएं:
इस तरह एक timeout-and-retry दोहरे चार्ज में नहीं बदलता।
एक स्पष्ट नीति चुनें और उसे ऑटोमेट करें.
व्यवहारिक डिफ़ॉल्ट:
occurred_at (इवेंट समय) के आधार पर aggregate करें, ingestion time नहींयह अकाउंटिंग साफ़ रखता है और अतीत के इनवॉइस अचानक बदलने से बचाता है।
छोटे, रोज़मर्रा के चेक लगाकर बड़े खर्चों से पहले त्रुटियाँ पकड़ें।
उपयोगी reconciliation:
अंतर लेट इवेंट्स या डेडूप द्वारा समझाए जाने चाहिए, किसी रहस्यमयी विभेद द्वारा नहीं।
इनवॉइस को समझने योग्य बनाएं और एक संगत “पेपर ट्रेल” रखें:
जब टिकट आए, तो सपोर्ट को यह बताने में सक्षम होना चाहिए:
यह विवाद को त्वरित लुकअप में बदल देता है, मैनुअल जांच में नहीं।