05 अक्टू॰ 2025·8 मिनट
आपकी एप्लिकेशन के लिए RabbitMQ: पैटर्न, सेटअप और ऑप्स
अपने ऐप्स में RabbitMQ कैसे उपयोग करें: कोर कॉन्सेप्ट्स, सामान्य पैटर्न, भरोसेमंदता टिप्स, स्केलिंग, सिक्योरिटी, और प्रोडक्शन मॉनिटरिंग।
अपने ऐप्स में RabbitMQ कैसे उपयोग करें: कोर कॉन्सेप्ट्स, सामान्य पैटर्न, भरोसेमंदता टिप्स, स्केलिंग, सिक्योरिटी, और प्रोडक्शन मॉनिटरिंग।
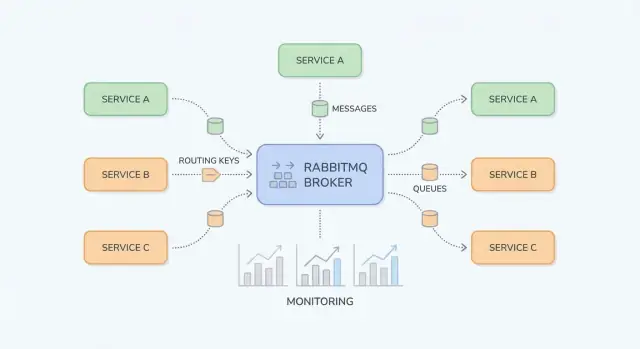
RabbitMQ एक मैसेज ब्रॉकर है: यह आपके सिस्टम के हिस्सों के बीच बैठता है और निर्मित ढंग से "वर्क" (संदेश) को प्रोड्यूसर्स से कंज्यूमर्स तक पहुँचाता है। एप्लिकेशन टीमें अक्सर तब इसे अपनाती हैं जब डायरेक्ट, सिंक्रोनस कॉल्स (सर्विस-टू-सर्विस HTTP, साझा डेटाबेस, क्रॉन जॉब्स) नाजुक निर्भरताएँ, असमान लोड, और डिबग करने में कठिन फेल्योर चेन बना रहे होते हैं।
ट्रैफिक स्पाइक्स और असमान वर्कलोड। अगर आपकी ऐप जल्दी में 10× ज़्यादा साइनअप्स या ऑर्डर्स पाती है, सब कुछ तुरंत प्रोसेस करने से डाउनस्ट्रीम सर्विसेज़ ओवरवेल्म हो सकती हैं। RabbitMQ के साथ, प्रोड्यूसर्स तेजी से टास्क कतार में डालते हैं और कंज्यूमर्स नियंत्रित गति से उन्हें प्रोसेस करते हैं।
सर्विसेज़ के बीच कड़ाई से कपल होना। जब सर्विस A को सर्विस B को कॉल करके इंतज़ार करना पड़ता है, तो फेल्यर और लेटेंसी फैलते हैं। मैसेजिंग उन्हें डिस्कूपल करती है: A मैसेज प्रकाशित करता है और आगे बढ़ता है; B उपलब्ध होने पर उसे प्रोसेस करता है।
सुरक्षित फेल्यर हैंडलिंग। हर फेल्यर यूजर को दिखने वाला एरर नहीं होना चाहिए। RabbitMQ बैकग्राउंड में रिट्राई करने, “पॉइज़न” संदेशों को अलग करने और अस्थायी आउटेज के दौरान काम खोने से बचाने में मदद करता है।
टीमें आमतौर पर स्मूथर वर्कलोड (पीक्स बफ़र), डिस्कूपल्ड सर्विसेज़ (कम रनटाइम निर्भरताएँ), और नियंत्रित रिट्राइज़ हासिल करती हैं। उतना ही महत्वपूर्ण, यह समझना आसान हो जाता है कि काम "कहाँ" अटका है—प्रोड्यूसर पर, कतार में, या कंज्यूमर में।
यह गाइड एप्लिकेशन टीम्स के लिए व्यावहारिक RabbitMQ पर केंद्रित है: कोर कॉन्सेप्ट्स, सामान्य पैटर्न (pub/sub, work queues, रिट्राइज़ और DLQ), और ऑपरेशनल चिंताएँ (सिक्योरिटी, स्केलिंग, ऑब्ज़रवेबिलिटी, ट्रबलशूटिंग)।
यह AMQP स्पेसिफिकेशन का पूर्ण चलाखी से अवलोकन या हर RabbitMQ प्लगइन की गहरी व्याख्या करने का लक्ष्य नहीं रखता। लक्ष्य यह है कि आप ऐसे मैसेज फ्लोज़ डिज़ाइन करें जो असल सिस्टम्स में मेंटेनेबल बने रहें।
RabbitMQ एक मैसेज ब्रॉकर है जो आपके सिस्टम के हिस्सों के बीच संदेशों को रूट करता है, ताकि प्रोड्यूसर्स काम सौंप सकें और कंज्यूमर्स उसे तब प्रोसेस कर सकें जब वे तैयार हों।
डायरेक्ट HTTP कॉल में, सर्विस A सर्विस B को अनुरोध भेजती है और आम तौर पर रिस्पॉन्स का इंतज़ार करती है। अगर सर्विस B धीमी या डाउन है, तो सर्विस A फेल या अटक सकती है, और आपको हर कॉलर में टाइमआउट, रिट्राई और बैकप्रेशर हैंडल करना पड़ता है।
RabbitMQ के साथ (आम तौर पर AMQP के माध्यम से), सर्विस A ब्रोकऱ को मैसेज प्रकाशित करती है। RabbitMQ उसे स्टोर और रूट कर देता है और उपयुक्त कतार(ओं) को भेजता है; सर्विस B असिंक्रोनस तरीके से उसे कंज्यूम करती है। मुख्य बदलाव यह है कि आप एक ड्यूरेबल मिडल लेयर के ज़रिए संवाद कर रहे हैं जो स्पाइक्स को बफ़र करता है और असमान वर्कलोड को स्मूथ करता है।
मैसेजिंग उपयुक्त है जब आप:
मैसेजिंग खराब फिट है जब आप:
सिंक्रोनस (HTTP):
एक चेकआउट सर्विस इनवॉइसिंग सर्विस को HTTP से कॉल करती है: "Create invoice." यूज़र तब तक इंतज़ार करता है जब तक इनवॉइसिंग चलती है। अगर इनवॉइसिंग धीमा है, तो चेकआउट की लेटेंसी बढ़ती है; अगर यह डाउन है, तो चेकआउट फेल कर जाएगा।
असिंक्रोनस (RabbitMQ):
चेकआउट invoice.requested के साथ ऑर्डर आईडी प्रकाशित करता है। यूज़र को तुरंत पुष्टि मिल जाती है कि ऑर्डर रिसीव हुआ। इनवॉइसिंग संदेश कंज्यूम करती है, इनवॉइस बनाती है, फिर invoice.created प्रकाशित करती है जिसे ईमेल/नोटिफिकेशन उठाते हैं। हर कदम स्वतंत्र रूप से रिट्राई कर सकता है, और अस्थायी आउटेज पूरे फ़्लो को अपने आप नहीं तोड़ते।
RabbitMQ को समझना आसान है अगर आप "जहाँ संदेश प्रकाशित होते हैं" और "जहाँ संदेश स्टोर होते हैं" को अलग कर दें। प्रोड्यूसर्स exchanges पर प्रकाशित करते हैं; एक्सचेंज संदेशों को queues में रूट करते हैं; कंज्यूमर्स कतारों से पढ़ते हैं।
एक exchange संदेशों को स्टोर नहीं करता। यह नियमों का आकलन करता है और संदेशों को एक या अधिक कतारों तक फॉरवर्ड करता है।
billing या email) तो उपयोग करें।region=eu AND tier=premium), पर इसे विशेष मामलों तक सीमित रखें क्योंकि यह समझने में कठिन हो सकता है।एक queue वह जगह है जहाँ संदेश तब तक रहते हैं जब तक कोई कंज्यूमर उन्हें प्रोसेस न कर ले। एक कतार के एक या कई कंज्यूमर हो सकते हैं (competing consumers), और संदेश सामान्यतः एक समय में एक कंज्यूमर को डिलीवर होते हैं।
एक binding एक एक्सचेंज को कतार से जोड़ता है और रूटिंग नियम को परिभाषित करता है। सोचें: “जब एक्सचेंज X पर रूटिंग की Y के साथ कोई संदेश आए, तो उसे कतार Q पर भेजो।” आप एक ही एक्सचेंज से कई कतारें बाँध सकते हैं (pub/sub) या एक ही कतार को विभिन्न रूटिंग कीज़ के लिए बाँध सकते हैं।
Direct exchanges में रूटिंग सटीक होती है। Topic exchanges में, रूटिंग कीज़ डॉट-सेपरेटेड शब्दों जैसी दिखती हैं, उदाहरण:
orders.createdorders.eu.refundedBindings वाइल्डकार्ड्स शामिल कर सकते हैं:
* ठीक एक शब्द से मेल खाता है (उदा., orders.* orders.created से मेल खाएगा)# शून्य या अधिक शब्दों से मेल खाता है (उदा., orders.# orders.created और orders.eu.refunded दोनों से मेल खाएगा)यह आपको प्रोसेसर्स जोड़ने का साफ़ तरीका देता है बिना प्रोड्यूसर्स को बदलने के—नई कतार बनाइए और उसे आप जिस पैटर्न से चाहते हैं उस पर बाँध दीजिए।
RabbitMQ संदेश देने के बाद कंज्यूमर से रिपोर्ट करता है कि क्या हुआ:
Requeue के साथ सावधान रहें: जो संदेश हमेशा फेल होता है वह अनंत पर लूप कर सकता है और कतार को ब्लॉक कर सकता है। कई टीमें nack को एक रिट्राई स्ट्रेटजी और एक dead-letter कतार के साथ जोड़ती हैं ताकि फेल्यर्स प्रेडिक्टेबल ढंग से हैंडल हों।
RabbitMQ तब चमकता है जब आपको अपने सिस्टम के हिस्सों के बीच काम या सूचनाएं मूव करनी हों बिना सब कुछ धीमे कदम पर रोककर। नीचे कुछ व्यावहारिक पैटर्न दिए गए हैं जो रोज़मर्रा के प्रोडक्ट्स में दिखते हैं।
जब कई कंज्यूमर्स को एक ही इवेंट पर प्रतिक्रिया देनी हो—बिना पब्लिशर को यह जानने की ज़रूरत कि वे कौन हैं—तो publish/subscribe अच्छा फिट है।
उदाहरण: जब कोई यूज़र अपनी प्रोफ़ाइल अपडेट करे, आप सर्च इंडेक्सिंग, एनालिटिक्स, और CRM सिंक को समानांतर में नोटिफाई कर सकते हैं। fanout एक्सचेंज के साथ आप सभी बाइंडेड कतारों में ब्रॉडकास्ट कर सकते हैं; topic एक्सचेंज के साथ आप चयनात्मक रूप से रूट कर सकते हैं (उदा., user.updated, user.deleted)। यह सेवाओं को कड़ाई से कपल होने से बचाता है और टीमें बाद में नए सब्सक्राइबर जोड़ सकती हैं बिना पब्लिशर बदलने के।
अगर एक टास्क समय लेता है, उसे कतार में डालिए और वर्कर्स असिंक्रोनस तरीके से प्रोसेस करें:
यह वेब रिक्वेस्ट्स को तेज़ रखता है और वर्कर्स को स्वतंत्र रूप से स्केल करने देता है। यह समकक्षता को नियंत्रित करने का एक स्वाभाविक तरीका भी है: कतार आपका "करने का काम" बन जाती है, और वर्कर काउंट आपकी "थ्रूपुट नॉब"।
कई वर्कफ़्लो सर्विस बॉर्डर्स को पार करते हैं: order → billing → shipping क्लासिक उदाहरण है। एक सर्विस अगली को कॉल करके ब्लॉक करने के बजाय, हर सर्विस अपनी स्टेप पूरी करने पर इवेंट प्रकाशित कर सकती है। डाउनस्ट्रीम सर्विसेज़ उन इवेंट्स को कंज्यूम कर के वर्कफ़्लो जारी रखती हैं।
यह रेज़िलिएंस सुधारता है (shipping में अस्थायी आउटेज चेकआउट को नहीं तोड़ता) और ओनरशिप को साफ़ करता है: प्रत्येक सर्विस उन इवेंट्स पर प्रतिक्रिया करती है जिनकी उसे परवाह है।
RabbitMQ आपके ऐप और धीमे/फ्लेकी डिपेंडेंसियों (थर्ड-पार्टी APIs, लेगसी सिस्टम, बैच DBs) के बीच एक बफ़र भी हो सकता है। आप अनुरोध जल्दी कतार में डालते हैं, फिर नियंत्रित रिट्राइज़ के साथ प्रोसेस करते हैं। अगर डिपेंडेंसी डाउन है, तो काम सुरक्षित रूप से जमा होता है और बाद में ड्रेन हो जाता है—बजाय इसके कि आपके पूरे ऐप में टाइमआउट हों।
यदि आप धीरे-धीरे कतारें इंट्रोड्यूस कर रहे हैं, तो एक छोटा “async outbox” या सिंगल बैकग्राउंड-जॉब कतार एक अच्छा पहला कदम होता है (देखें /blog/next-steps-rollout-plan)।
एक RabbitMQ सेटअप तभी काम करने योग्य रहता है जब रूट्स अनुमानित हों, नामकंसीस्टेंट हों, और पेलोड्स पुराने कंज्यूमर्स को तोड़े बिना विकसित हों। किसी और कतार को जोड़ने से पहले सुनिश्चित करें कि संदेश की "कहानी" स्पष्ट हो: यह कहाँ उत्पन्न हुआ, कैसे रूट हो रहा है, और एक साथ काम करते हुए टीम मेंबर इसे एंड-टू-एंड कैसे डिबग कर सकता है।
सही एक्सचेंज चुनना पहले से अनपेक्षित बाइंडिंग्स और सरप्राइस फैन-आउट को घटाता है:
billing.invoice.created)।billing.*.created, *.invoice.*)—यह आम तौर पर इवेंट-स्टाइल रूटिंग के लिए सबसे उपयुक्त विकल्प है।एक अच्छा नियम: अगर आप कोड में जटिल रूटिंग लॉजिक "इजाद" कर रहे हैं, तो वह अक्सर topic exchange पैटर्न में रखना चाहिए।
मैसेज बॉडीज़ को सार्वजनिक API की तरह ट्रीट करें। स्पष्ट वर्शनिंग का उपयोग करें (उदा., टॉप-लेवल फ़ील्ड schema_version: 2) और बैकवर्ड कंपैटिबिलिटी का लक्ष्य रखें:
इससे पुरानी कंज्यूमर बिना तुरन्त अपडेट हुए काम करती रहेंगी और नई कंज्यूमर अपनी गति से नए स्कीमा को अपनाएंगी।
ट्रबलशूटिंग सस्ती बनाइए: मेटाडेटा को मानकीकृत कर के:
correlation_id: एक ही बिजनेस एक्शन से जुड़े कमांड/इवेंट्स को जोड़ता है।trace_id (या W3C traceparent): संदेशों को HTTP और असिंक्रोनस फ़्लोज़ में डिस्ट्रिब्यूटेड ट्रेस के साथ लिंक करता है।जब हर पब्लिशर इन्हें लगातार सेट करता है, तो आप बिना अनुमान के एक ट्रांज़ैक्शन को कई सर्विसेज़ में फॉलो कर सकते हैं।
पैटर्नशुदा, सर्चेबल नामों का उपयोग करें। एक सामान्य पैटर्न:
<domain>.<type> (उदा., billing.events)<domain>.<entity>.<verb> (उदा., billing.invoice.created)<service>.<purpose> (उदा., reporting.invoice_created.worker)कंसिस्टेंसी क्लेवरनेस से बेहतर है: भविष्य का आप (और आपकी ऑन-कॉल टीम) आपका शुक्रगुज़ार रहेगी।
विश्वसनीय मैसेजिंग ज़्यादातर फेल्यर की योजना बनाने के बारे में है: कंज्यूमर क्रैश होंगे, डाउनस्ट्रीम APIs टाइमआउट देंगे, और कुछ इवेंट बस मालफॉर्म्ड होंगे। RabbitMQ आपको टूल देता है, पर आपका एप्लिकेशन कोड सहयोग करना होगा।
एक आम सेटअप at-least-once delivery होता है: एक संदेश खोने की बजाय कई बार डिलीवर हो सकता है। यह तब होता है जब कंज्यूमर संदेश पाकर काम शुरू करता है और फिर ack भेजने से पहले फेल हो जाता है—RabbitMQ उसे फिर से डिलीवर करेगा।
व्यवहारिक नतीजा: डुप्लिकेट सामान्य हैं, इसलिए आपका हैंडलर कई बार चलने पर सुरक्षित होना चाहिए।
आइडेम्पोटेंसी का अर्थ है “एक ही संदेश का दो बार प्रोसेस होना एक बार प्रोसेस होने जैसा ही है।” उपयोगी तरीके:
message_id शामिल करें (या बिजनेस की जैसे order_id + event_type + version) और उसे TTL के साथ "processed" टेबल/कैश में स्टोर करें।PENDING हो) या DB uniqueness constraints से डबल-क्रिएट को रोकेँ।रिट्राइज़ को उपभोक्ता के टाइट लूप के रूप में नहीं बल्कि अलग फ़्लो के रूप में ट्रीट करना बेहतर है।
एक सामान्य पैटर्न:
यह बिना messages को "unacked" पर फंसा रहने दिए बैकऑफ़ बनाता है।
कुछ संदेश कभी सफल नहीं होंगे (खराब स्कीमा, गायब संदर्भीय डेटा, कोड बग)। इन्हें ऐसे पहचानें:
इन्हें DLQ में क्वारंटीन करें। DLQ को एक ऑपरेशनल इनबॉक्स की तरह ट्रीट करें: पेलोड्स का निरीक्षण करें, मूल समस्या ठीक करें, फिर चुनिंदा संदेशों को मैन्युअली रीप्ले करें (आदर्श रूप से एक नियंत्रित टूल/स्क्रिप्ट के माध्यम से) बजाय इसके कि सब कुछ वापस मुख्य कतार में डाल दिया जाए।
RabbitMQ प्रदर्शन आम तौर पर कुछ व्यावहारिक कारकों द्वारा सीमित होता है: आप कनेक्शनों का प्रबंधन कैसे करते हैं, कंज्यूमर कितनी तेज़ी से सुरक्षित रूप से काम कर सकते हैं, और क्या कतारों का उपयोग "स्टोरेज" की तरह किया जा रहा है। लक्ष्य स्थिर थ्रूपुट है बिना बढ़ते बैकलॉग के।
आम गलती यह है कि हर पब्लिशर या कंज्यूमर के लिए नया TCP कनेक्शन खोला जाए। कनेक्शंस अपेक्षाकृत भारी होते हैं (हैंडशेक, हार्टबीट, TLS), इसलिए इन्हें लंबी अवधि के लिए रखें और रीयूज़ करें।
Channels का उपयोग छोटे नंबर के कनेक्शंस पर मल्टिप्लेक्स करने के लिए करें। एक नियम: थोड़े कनेक्शंस, कई चैनल। फिर भी, हजारों चैनल अंधाधुंध न बनाएं—प्रत्येक चैनल का ओवरहेड होता है और आपके क्लाइंट लाइब्रेरी की अपनी सीमाएँ हो सकती हैं। सर्विस प्रति एक छोटा चैनल पूल रखें और पब्लिशिंग के लिए चैनलों को रीयूज़ करें।
अगर कंज्यूमर बहुत सारे संदेश एक साथ खींचते हैं, तो आपको मेमोरी स्पाइक्स, लंबे प्रोसेसिंग समय, और असमान लेटेंसी देखने को मिल सकती है। हर कंज्यूमर को नियंत्रित संख्या में unacked संदेश रखने के लिए prefetch सेट करें।
व्यवहारिक मार्गदर्शन:
बड़े संदेश थ्रूपुट कम करते हैं और मेमोरी दबाव बढ़ाते हैं (पब्लिशर्स, ब्रोकऱ और कंज्यूमर्स पर)। अगर आपका पेलोड बड़ा है (डॉक्यूमेंट्स, इमेजेज़, बड़े JSON), तो उसे कहीं और (ऑब्जेक्ट स्टोरेज या DB) में स्टोर करने पर विचार करें और केवल ID + मेटाडेटा भेजें।
एक अच्छा ह्यूरिस्टिक: संदेश KB रेंज में रखें, MB नहीं।
क्यू वृद्धि एक लक्षण है, रणनीति नहीं। ऐसे बैकप्रेशर जोड़ें कि प्रोड्यूसर्स धीमे जब कंज्यूमर्स पकड़ न सकें:
संशोधन करते समय एक-एक करके एक नॉब बदलें और मापें: पब्लिश रेट, ack रेट, कतार लंबाई, और एंड-टू-एंड लेटेंसी।
RabbitMQ की सुरक्षा ज़्यादातर "एजेस" को कड़ा करने के बारे में है: क्लाइंट्स कैसे कनेक्ट करते हैं, कौन क्या कर सकता है, और क्रेडेंशियल्स को गलत जगहों से कैसे दूर रखा जाए। इसे एक बेसलाइन के रूप में उपयोग करें और अपनी अनुपालन आवश्यकताओं के अनुसार अनुकूलित करें।
RabbitMQ परमीशन्स शक्तिशाली हैं जब आप उन्हें निरंतर उपयोग करते हैं।
ऑपरेशनल हार्डनिंग (पोर्ट्स, फ़ायरवॉल्स, और ऑडिटिंग) के लिए एक छोटा आंतरिक रनबुक रखें और उसे /docs/security से लिंक करें ताकि टीमें एक मानक का पालन करें।
जब RabbitMQ गलत व्यवहार करता है, तो लक्षण पहले आपके एप्लिकेशन में दिखते हैं: धीमे एंडपॉइंट्स, टाइमआउट, गायब अपडेट, या जॉब्स जो "कभी खत्म नहीं होते"। अच्छी ऑब्ज़रवेबिलिटी आपको पुष्टि करने देती है कि ब्रोकऱ कारण है, बॉटलनेक कहाँ है (पब्लिशर, ब्रोकऱ, या कंज्यूमर), और उपयोगकर्ताओं के नोटिस से पहले कार्रवाई करने देती है।
एक छोटे सेट से शुरू करें जो बताता है कि संदेश बह रहे हैं या नहीं:
ट्रेंड्स पर अलर्ट सेट करें, सिर्फ़ सख्त थ्रेशोल्ड्स पर नहीं:
ब्रोकऱ लॉग्स यह अलग करने में मदद करते हैं कि "RabbitMQ डाउन है" या "क्लाइंट्स इसका ग़लत उपयोग कर रहे हैं"। ऑथेंटिकेशन फेल्यर्स, blocked connections (resource alarms), और बार-बार चैनल एरर्स देखें। एप्लिकेशन साइड पर, सुनिश्चित करें कि हर प्रोसेसिंग प्रयास लॉग में correlation ID, कतार का नाम और परिणाम (acked, rejected, retried) शामिल करे।
यदि आप डिस्ट्रिब्यूटेड ट्रेसिंग उपयोग करते हैं, तो मैसेज प्रॉपर्टीज़ के जरिए trace headers पास करें ताकि आप “API request → published message → consumer work” को जोड़ सकें।
प्रत्येक क्रिटिकल फ्लो के लिए एक डैशबोर्ड बनाएं: publish rate, ack rate, depth, unacked, requeues, और consumer count। अपने डैशबोर्ड में सीधे /docs/monitoring जैसे आंतरिक रनबुक के लिंक जोड़ें और ऑन-कॉल रिस्पॉन्डर्स के लिए "पहले क्या जांचें" चेकलिस्ट रखें।
जब कुछ भी "सिर्फ हिलना बंद" कर देता है, तो पहले रिस्टार्ट करने के लालच से बचें। अधिकांश समस्याएँ स्पष्ट हो जाती हैं अगर आप (1) बाइंडिंग और रूटिंग, (2) कंज्यूमर हेल्थ, और (3) रिसोर्स अलार्म्स देखेंगे।
यदि पब्लिशर्स "सफलतापूर्वक भेज दिया" रिपोर्ट करते हैं पर कतारें खाली हैं (या गलत कतार भर रही है), तो कोड से पहले रूटिंग जांचें।
मैनेजमेंट UI में शुरू करें:
topic में)।यदि कतार में संदेश हैं पर कुछ कंज्यूम नहीं कर रहा, तो जाँचें:
डुप्लिकेट्स आमतौर पर रिट्राइज़ (कंज्यूमर क्रैश के बाद प्रोसेस हुआ पर ack से पहले), नेटवर्क बाधाएँ, या मैन्युअल रीक्यूज़िंग से आते हैं। हैंडलर्स को आइडेम्पोटेंट बनाकर mitigiate करें (उदा., DB में message ID से डेडुप)।
आउट-ऑफ-ऑर्डर डिलीवरी अपेक्षित है जब आप कई कंज्यूमर्स या रीक्यूज़ का उपयोग करते हैं। यदि ऑर्डर महत्वपूर्ण है, तो उस कतार के लिए एकल कंज्यूमर का उपयोग करें, या कुंजी द्वारा partition करके कई कतारें बनाएँ।
अलार्म्स का मतलब है कि RabbitMQ खुद को सुरक्षा दे रहा है।
रीप्ले करने से पहले मूल कारण ठीक करें और "पॉइज़न मैसेज" लूप बंद करें। छोटे बैचों में रीक्यू करें, एक retry cap जोड़ें, और फेल्यर्स को मेटाडेटा (attempt count, last error) के साथ स्टैम्प करें। रीप्ले किए गए संदेशों को सबसे पहले एक अलग कतार में भेजने पर विचार करें ताकि वही त्रुटि दोहराए जाने पर आप जल्दी रोक सकें।
मेसजिसिंग टूल चुनना "सबसे अच्छा" के बारे में कम और आपके ट्रैफ़िक पैटर्न, फेल्योर सहनशीलता, और ऑपरेशनल कम्फर्ट के मिलान के बारे में ज़्यादा है।
RabbitMQ तब बढ़िया है जब आपको विश्वसनीय संदेश डिलीवरी और फ्लेक्सिबल रूटिंग चाहिए। यह क्लासिक असिंक्रोनस वर्कफ़्लोज़—कमान्ड्स, बैकग्राउंड जॉब्स, फैन्-आउट नोटिफ़िकेशन्स, और request/response पैटर्न—के लिए मज़बूत विकल्प है, विशेषकर जब आप चाहें:
यदि आपका उद्देश्य इवेंट-ड्रिवन है पर प्राथमिक लक्ष्य काम मूव करना है बजाय लंबी इवेंट हिस्ट्री रखने के, तो RabbitMQ अक्सर एक आरामदायक डिफ़ॉल्ट होता है।
Kafka और समान प्लेटफ़ॉर्म हाई-थ्रूपुट स्ट्रीमिंग और लॉंग-लिव्ड इवेंट लॉग के लिए बनाए गए हैं। Kafka-लाइक सिस्टम चुनें जब आपको चाहिए:
ट्रेड-ऑफ: Kafka-स्टाइल सिस्टम का ऑपरेशनल ओवरहेड ज़्यादा हो सकता है और ये आपको थ्रूपुट-उन्मुख डिज़ाइन (बैचिंग, partition strategy) की ओर धकेल सकते हैं। RabbitMQ आम तौर पर कम-से-मध्यम थ्रूपुट में कम एंड-टू-एंड लेटेंसी और जटिल रूटिंग के लिए आसान रहता है।
अगर आपके पास एक ऐप है जो जॉब्स पैदा करता है और एक वर्कर पूल उन्हें खा जाता है—और आप सादे semantics से ठीक हैं—तो Redis-आधारित कतार (या मैनेज्ड टास्क सर्विस) पर्याप्त हो सकती है। टीमें आमतौर पर तब इससे बाहर निकलती हैं जब उन्हें मजबूत डिलीवरी गारंटी, डेड-लेटरिंग, बहु-रूटिंग पैटर्न, या स्पष्ट प्रोड्यूसर/कंज्यूमर पृथक्करण चाहिए।
अपने मैसेज कॉन्ट्रैक्ट्स इस तरह डिज़ाइन करें कि आप बाद में मूव कर सकें:
अगर बाद में आपको रीप्लेबल स्ट्रीम्स चाहिए, तो आप अक्सर RabbitMQ इवेंट्स को एक लॉग-आधारित सिस्टम में ब्रिज कर सकते हैं जबकि ऑपरेशनल वर्कफ़्लोज़ के लिए RabbitMQ को रखेंगे। व्यावहारिक रोलआउट योजना के लिए देखें /blog/rabbitmq-rollout-plan-and-checklist।
RabbitMQ रोलआउट तब सबसे अच्छा काम करता है जब आप इसे एक प्रोडक्ट की तरह ट्रीट करें: छोटे से शुरू करें, ओनरशिप परिभाषित करें, और अधिक सेवाओं तक विस्तार करने से पहले विश्वसनीयता साबित करें।
एक ऐसा वर्कफ़्लो चुनें जो असिंक्रोनस प्रोसेसिंग से लाभान्वित हो (उदा., ईमेल भेजना, रिपोर्ट जनरेट करना, थर्ड-पार्टी API सिंक)।
यदि आपको नामकरण, रिट्राइ टियर्स, और बेसिक नीतियों के लिए संदर्भ टेम्पलेट चाहिए, तो उसे /docs में केंद्रीकृत रखें।
जैसे-जैसे आप इन पैटर्न्स को लागू करते हैं, सोचें कि स्कैफ़ोल्डिंग को टीम्स के बीच स्टैण्डर्ड किया जाए। उदाहरण के लिए, Koder.ai का उपयोग करने वाली टीमें अक्सर एक छोटा प्रोड्यूसर/कंज्यूमर सर्विस स्केलेटन जनरेट करती हैं (नामकरण कन्वेंशन, retry/DLQ वायरिंग, और trace/correlation हेडर सहित), फिर सोर्स को एक्सपोर्ट कर समीक्षा करती हैं और रोलआउट से पहले प्लानिंग मोड में इटरेट करती हैं।
RabbitMQ तब सफल होता है जब "कोई न कोई कतार का मालिक" हो। प्रोडक्शन से पहले यह तय करें:
यदि आप समर्थन औपचारिक कर रहे हैं या मैनेज्ड होस्टिंग कर रहे हैं, तो शुरुआती चरण में अपेक्षाओं को संरेखित करें (देखें /pricing) और onboarding/इन्सिडेंट के लिए संपर्क मार्ग /contact सेट करें।
छोटी, टाइम-बॉक्स्ड एक्सरसाइज़ चलाएँ ताकि विश्वास बने:
एक सेवा कुछ हफ्तों तक स्थिर रहने पर, उसी पैटर्न को दोहराएँ—टीम के अनुसार फिर से नया डिज़ाइन न बनाएं।
RabbitMQ का उपयोग तब करें जब आप सेवाओं को डिस्कूपल (decouple) करना चाहते हों, ट्रैफिक स्पाइक्स को सहन करना चाहते हों, या धीमे काम को रिक्वेस्ट पाथ से हटाना चाहते हों.
अच्छे उपयोग के मामले: बैकग्राउंड जॉब्स (ईमेल, PDF जनरेशन), कई कंज्यूमर को सूचनाएं भेजना, और वर्कफ्लो जो अस्थायी डाउनस्ट्रीम आउटेज के दौरान भी चलना चाहिए.
बचें जब आपको तुरंत उत्तर चाहिए (सिंपल रीड/वैलिडेशन) या जब आप वर्शनिंग, रिट्राई और मॉनिटरिंग के लिए प्रतिबद्ध नहीं हो सकते — ये प्रोडक्शन में अनिवार्य पहलू हैं।
एक्सचेंज पर प्रकाशित करें और कतारों में रूट करें:
orders.* या orders.# जैसे फ्लेक्सिबल पैटर्न चाहते हों।अधिकांश टीमें मेंटेन करने योग्य इवेंट-स्टाइल रूटिंग के लिए topic एक्सचेंज को डिफ़ॉल्ट चुनती हैं।
कतार (queue) संदेशों को तब तक रखती है जब तक कोई कंज्यूमर उन्हें न प्रोसेस कर ले; बाइंडिंग वह नियम है जो एक्सचेंज को कतार से जोड़ता है।
रूटिंग समस्याओं को डिबग करने के लिए:
ये तीन चेक सबसे ज़्यादा “पब्लिश हुआ पर कंज्यूम नहीं हुआ” मामलों का कारण होते हैं।
वर्क कतार तब उपयोग करें जब आप चाहते हैं कि कई वर्कर्स में से कोई एक हर टास्क को प्रोसेस करे.
व्यवहारिक सेटअप टिप्स:
prefetch सेट करें ताकि वर्कर्स बहुत सारे unacked संदेश न पकड़ें।At-least-once delivery का मतलब है कि एक संदेश कई बार डिलीवर हो सकता है (उदा., कंज्यूमर ने काम किया लेकिन ack भेजने से पहले क्रैश हो गया)।
डुप्लिकेट हैंडल करने के तरीके:
message_id (या बिजनेस की) का उपयोग करें और प्रोसेस्ड IDs को TTL के साथ स्टोर करें।डुप्लिकेट सामान्य मानकर डिज़ाइन करें।
तंग requeue लूप्स से बचें। एक सामान्य दृष्टिकोण है “रिट्राई कतारें” + DLQ:
DLQ से रीक्वप केवल मूल कारण ठीक करने के बाद, छोटे बैचों में करें।
संदेशों को सार्वजनिक APIs की तरह ट्रीट करें:
schema_version जोड़ें।मेटाडेटा भी मानकीकृत करें:
कुछ संकेत जिनपर ध्यान दें:
अलर्टिंग ट्रेंड्स पर रखें (उदा., “10 मिनट में बैकलॉग बढ़ रहा है”) और लॉग्स में queue name, correlation_id और outcome (acked/retried/rejected) शामिल करें।
मूल सुरक्षा नियम लागू करें:
एक छोटा आंतरिक रनबुक रखें ताकि टीमें एक मानक अपनाएं (उदा., /docs/security)।
फ्लो कहाँ रुक रहा है यह खोज कर शुरू करें:
रीस्टार्ट करना अक्सर पहला या सर्वोत्तम कदम नहीं होता।
correlation_id ताकि एक ही बिजनेस एक्शन से जुड़े कमांड/इवेंट्स को जोड़ा जा सके।trace_id (या W3C traceparent) ताकि असिंक्रोनस और HTTP फ़्लो में डिस्ट्रिब्यूटेड ट्रेसिंग जुड़ी रहे।ये नियम ऑनबोर्डिंग और हादसों के वक्त बहुत मददगार होते हैं।