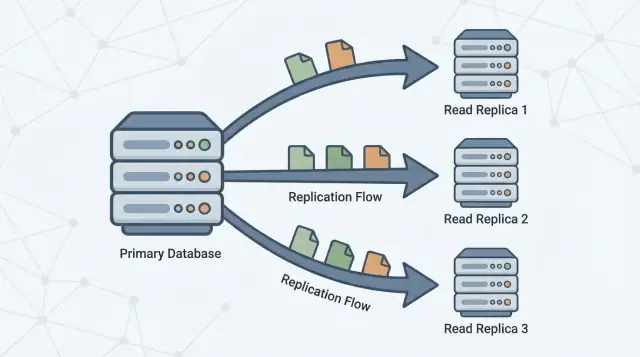
रीड रेप्लिका क्या है (और क्या नहीं)
एक रीड रेप्लिका आपके मुख्य डेटाबेस (अक्सर प्राइमरी कहा जाता है) की एक कॉपी है जो उससे लगातार परिवर्तन प्राप्त करके अपडेट रहती है। आपका ऐप रेप्लिका को सिर्फ पढ़ने वाले प्रश्न (जैसे SELECT) भेज सकता है, जबकि प्राथमिक सभी लिखने वाले कामों (जैसे INSERT, UPDATE, और DELETE) को संभालता रहता है।
बुनियादी वादा
वादा सरल है: अधिक पढ़ने की क्षमता बिना प्राथमिक पर अधिक दबाव डाले।
यदि आपके ऐप पर बहुत सारी “फ़ेच” ट्रैफिक है—होमपेज, प्रोडक्ट पेज, यूज़र प्रोफाइल, डैशबोर्ड—तो उन पढ़ाइयों का कुछ हिस्सा एक या अधिक रेप्लिकास पर ले जाना प्राथमिक को लिखने पर ध्यान देने के लिए मुक्त कर सकता है। कई सेटअप में, यह एप्लिकेशन में न्यूनतम बदलाव के साथ किया जा सकता है: आप एक डेटाबेस को सत्य का स्रोत रखते हैं और रेप्लिकास को अतिरिक्त क्वेरी करने की जगह के रूप में जोड़ते हैं।
रीड रेप्लिका क्या नहीं है
रीड रेप्लिकास उपयोगी हैं, लेकिन ये जादू की बटन नहीं हैं। वे नहीं करते:
- लिखने की क्षमता बढ़ाना। सारे लिखे फिर भी प्राथमिक पर ही आते हैं।
- धीमी क्वेरियों को ठीक करना। अगर क्वेरी अक्षरशः खराब है (इंडेक्स गायब, बड़े टेबल स्कैन, खराब जोइन पैटर्न), तो वह रेप्लिका पर भी धीमी रहेगी—सिर्फ़ कहीं और।
- अच्छे स्कीमा और डेटा डिज़ाइन की जगह लेना। रेप्लिकास हॉट‑स्पॉट्स, ओवरसाइज़्ड रो या “सब कुछ” टेबल जैसी समस्याओं को हल नहीं करते।
- निगरानी की ज़रूरत खत्म करना। रेप्लिकास नए मूविंग पार्ट्स जोड़ते हैं: लैग, कनेक्शन सीमाएँ, और फ़ेलओवर व्यवहार।
बाकी गाइड के लिए अपेक्षाएँ
रीड रेप्लिकास को एक रीड‑स्केलिंग टूल जिसमें ट्रेड‑ऑफ हैं के रूप में सोचें। इस लेख के बाकी हिस्से में बताया गया है कि वे कब वास्तव में मदद करते हैं, आम तरह से वे कैसे उल्टा असर कर सकते हैं, और कैसे अवधारणाएँ जैसे रिप्लिकेशन लैग और इवेंटुअल कंसिस्टेंसी यह प्रभावित करती हैं कि उपयोगकर्ता क्या देखते हैं जब आप किसी कॉपी से पढ़ना शुरू करते हैं बजाय प्राथमिक के।
रीड रेप्लिकास क्यों मौजूद हैं
एक अकेला प्राथमिक डेटाबेस सर्वर अक्सर शुरुआत में “काफ़ी बड़ा” लगता है। वह लिखे (इन्सर्ट, अपडेट, डिलीट) संभालता है और आपके ऐप, डैशबोर्ड और आंतरिक टूल्स की हर पढ़ने की रिक्वेस्ट का भी जवाब देता है।
जैसे‑जैसे उपयोग बढ़ता है, पढ़ाइयाँ आम तौर पर लिखने से तेज़ी से बढ़ती हैं: हर पेज व्यू कई क्वेरियों को ट्रिगर कर सकता है, खोज स्क्रीन कई लुकअप्स कर सकती हैं, और एनालिटिक्स‑शैली की क्वेरियाँ बहुत सारे रो स्कैन कर सकती हैं। भले ही आपका लिखने का वॉल्यूम मध्यम हो, प्राथमिक फिर भी बोतल‑नेक बन सकता है क्योंकि उसे दो काम एक साथ करने होते हैं: परिवर्तन सुरक्षित और तेज़ी से स्वीकार करना, और बढ़ती पढ़ने वाली ट्रैफ़िक को कम लेटेंसी के साथ सर्व करना।
पढ़ाइयों को लिखनों से अलग करना
रीड रेप्लिकास उस वर्कलोड को विभाजित करने के लिए मौजूद हैं। प्राथमिक लिखने पर केन्द्रित रहता है और “स्रोत‑सत्य” बनाए रखता है, जबकि एक या अधिक रेप्लिकास पढ़ने‑केवल क्वेरियों को संभालते हैं। जब आपका ऐप कुछ क्वेरियों को रेप्लिकास की ओर रूट कर सकता है, तो आप प्राथमिक पर CPU, मेमोरी और I/O प्रेशर को घटाते हैं। इससे आम तौर पर समग्र प्रतिसाद‑क्षमता बेहतर होती है और लिखने के पिक्स के लिए और हेडरूम बनता है।
एक वाक्य में रिप्लिकेशन
रिप्लिकेशन वह तंत्र है जो प्राथमिक से दूसरे सर्वरों तक परिवर्तन कॉपी करके रेप्लिकास को अपडेट रखता है। प्राथमिक परिवर्तन रिकॉर्ड करता है, और रेप्लिकास उन परिवर्तनों को लागू करते हैं ताकि वे लगभग वही डेटा उपयोग करके प्रश्नों का उत्तर दे सकें।
यह पैटर्न कई डेटाबेस सिस्टम और मैनेज्ड सर्विसेज़ (जैसे PostgreSQL, MySQL, और क्लाउड‑होस्टेड वेरिएंट) में आम है। सटीक इम्प्लीमेंटेशन अलग हो सकता है, पर लक्ष्य वही रहता है: प्राथमिक को अनंत तक वर्टिकली स्केल करने के बजाय रीड क्षमता बढ़ाना।
रिप्लिकेशन कैसे काम करता है (सरल मानसिक मॉडल)
प्राइमरी डेटाबेस को “स्रोत‑सत्य” की तरह सोचें। यह हर लिखे को स्वीकार करता है—ऑर्डर बनाना, प्रोफाइल अपडेट करना, भुगतान रिकॉर्ड करना—और उन परिवर्तनों को निश्चित ऑर्डर देता है।
एक या अधिक रीड रेप्लिकास तब प्राथमिक का अनुगमन करते हैं, उन परिवर्तनों को कॉपी करते हैं ताकि वे पढ़ने वाले प्रश्न (जैसे “मेरा ऑर्डर इतिहास दिखाओ”) को प्राथमिक पर अतिरिक्त लोड डाले बिना जवाब दे सकें।
बुनियादी फ्लो
- प्राइमरी लिखे स्वीकार करता है और उन्हें एक दृढ़ लॉग में रिकॉर्ड करता है (नाम डेटाबेस पर निर्भर करता है)।
- रेप्लिकास उन लॉग एंट्रीज़ को स्ट्रीम या फ़ेच करते हैं प्राथमिक से।
- रेप्लिकास वही परिवर्तन उसी क्रम में फिर से चलाते हैं, धीरे‑धीरे पकड़ते हुए।
पढ़ाइयाँ रेप्लिकास से सर्व की जा सकती हैं, पर लिखे फिर भी प्राथमिक पर ही जाते हैं।
सिंक्रोनस बनाम असिंक्रोनस रिप्लिकेशन (ऊपर से)
रिप्लिकेशन दो व्यापक मोड में हो सकता है:
- सिंक्रोनस: प्राथमिक तब तक इंतज़ार करता है जब तक कि कोई रेप्लिका (या क्वोरम) परिवर्तन प्राप्त होने की पुष्टिकरण नहीं देता। इससे स्टेल पढ़ाइयाँ कम होती हैं, पर लिखने की लेटेंसी बढ़ सकती है और लिखने को रेप्लिका/नेटवर्क मुद्दों के प्रति संवेदनशील बना देता है।
- असिंक्रोनस: प्राथमिक तुरंत लिखे को कमिट कर देता है, और रेप्लिकास बाद में पकड़ते हैं। इससे लिखना तेज़ और ज़्यादा रेज़िलिएंट रहता है, पर रेप्लिकास अस्थायी रूप से पीछे रह सकते हैं।
रिप्लिकेशन लैग और “इवेंटुअल कंसिस्टेंसी”
यह देरी—रेप्लिकास का प्राथमिक से पीछे रह जाना—को रिप्लिकेशन लैग कहा जाता है। यह स्वचालित रूप से विफलता नहीं है; अक्सर यह वह सामान्य ट्रेड‑ऑफ होता है जिसे आप पढ़ने को स्केल करने के लिए स्वीकार करते हैं।
उपयोगकर्ताओं के लिए, लैग इवेंटुअल कंसिस्टेंसी के रूप में दिखता है: आप कुछ बदलते हैं और सिस्टम अंततः हर जगह सुसंगत हो जाएगा, पर तुरंत नहीं।
उदाहरण: आप अपना ईमेल पता अपडेट करते हैं और प्रोफ़ाइल पेज रीफ्रेश करते हैं। अगर पेज किसी रेप्लिका से सर्व हो रहा है जो कुछ सेकंड पीछे है, तो आप थोड़ी देर के लिए पुराना ईमेल देख सकते हैं—जब तक रेप्लिका अपडेट लागू कर के "क catch up" नहीं हो जाती।
रीड रेप्लिकास कब सच में मदद करते हैं
रीड रेप्लिकास तब मदद करते हैं जब आपका प्राइमरी डेटाबेस लिखने के लिए स्वस्थ है पर पढ़ने वाला ट्रैफ़िक उसे ओवरवेल्म कर रहा हो। वे सबसे प्रभावी होते हैं जब आप बिना लेखन‑तरीकों को बदले एक महत्वपूर्ण हिस्सा SELECT लोड ऑफ़लोड कर सकते हैं।
संकेत कि आप रीड‑बाउंड हैं (न कि राइट‑बाउंड)
ऐसे पैटर्न देखें:
- ट्रैफ़िक पीक्स पर प्राथमिक पर उच्च CPU जबकि लिखने की थ्रूपुट असामान्य रूप से ऊँची नहीं
SELECT क्वेरियों का INSERT/UPDATE/DELETE के मुकाबले बहुत अधिक अनुपात- पीक्स के दौरान पढ़ने की क्वेरीज़ धीमी हो रही हैं जबकि लिखे स्थिर हैं
- रीड‑हेवी एंडपॉइंट्स (प्रोडक्ट पेज, फीड, सर्च) द्वारा कनेक्शन पूल सैचुरेशन
पढ़ाइयाँ समस्या हैं यह कैसे सत्यापित करें (मेट्रिक्स)
रेप्लिकास जोड़ने से पहले कुछ ठोस संकेतों से वैलिडेट करें:
- CPU बनाम I/O: क्या प्राथमिक का CPU तब पिक पर है जब पढ़ने की लेटेंसी बढ़ती है? या डिस्क पढ़ने का I/O बॉटलनेक है?
- क्वेरी मिक्स:
SELECT स्टेटमेंट्स में बिताया गया प्रतिशत समय (आपके स्लो क्वेरी लॉग/APM से)।
- p95/p99 रीड लेटेंसी: रीड एंडपॉइंट्स और डेटाबेस क्वेरी लेटेंसी को अलग ट्रैक करें।
- बफ़र/कैश हिट रेट: कम हिट‑रेट का मतलब पढ़ाइयाँ डिस्क एक्सेस फोर्स कर रही हैं।
- टॉप क्वेरियाँ बाय टोटल टाइम: एक महँगी क्वेरी पूरे "रीड लोड" का बड़ा हिस्सा ले सकती है।
सस्ते फिक्स छोड़ें मत
अक्सर सबसे अच्छा पहला कदम ट्यूनिंग होता है: सही इंडेक्स जोड़ना, एक क्वेरी को फिर से लिखना, N+1 कॉल कम करना, या हॉट पढ़ाइयों को कैश करना। ये परिवर्तन रेप्लिकास ऑपरेट करने से तेज़ और सस्ते हो सकते हैं।
तत्काल चेकलिस्ट: रेप्लिकास बनाम ट्यूनिंग
रेप्लिकास चुनें अगर:
- अधिकतर लोड पढ़ने की ट्रैफ़िक है, और पढ़ाइयाँ पहले से ठीक‑ठाक ऑप्टिमाइज़्ड हैं
- आप ऑफ़लोड किए गए क्वेरियों के लिए कभी‑कभी स्टेल पढ़ने सहन कर सकते हैं
- आपको बिना रिस्की स्कीमा/क्वेरी बदलाव के जल्दी अतिरिक्त क्षमता चाहिए
पहले ट्यूनिंग चुनें अगर:
- कुछ क्वेरियाँ कुल पढ़ने के समय का वर्चस्व कर रही हैं
- इंडेक्स गायब हैं या जोइन स्पष्ट रूप से अप्रभावी हैं
- कम ट्रैफ़िक में भी पढ़ाइयाँ धीमी हैं (क्वेरी डिज़ाइन की समस्या का संकेत)
सबसे उपयुक्त उपयोग‑केसेस
रीड रेप्लिकास तब सबसे ज़्यादा मूल्यवान होते हैं जब प्राथमिक डेटाबेस लिखने (चेकआउट, साइन‑अप, अपडेट) संभाल रहा हो, पर ट्रैफ़िक का बड़ा हिस्सा पढ़‑हेवी हो। प्राइमरी–रेप्लिका आर्किटेक्चर में, सही क्वेरियों को रेप्लिकास पर धकेलना डेटाबेस प्रदर्शन को बिना एप्लिकेशन फीचर बदले बेहतर बनाता है।
1) डैशबोर्ड और एनालिटिक्स जो ट्रांज़ैक्शन्स को धीमा नहीं करना चाहिए
डैशबोर्ड अक्सर लंबी क्वेरियाँ चलाते हैं: ग्रुपिंग, बड़े डेट‑रेंज पर फ़िल्टरिंग, या मल्टीपल टेबल्स जोइन करना। ये क्वेरियाँ CPU, मेमोरी और कैश के लिए ट्रांज़ैक्शनल काम से प्रतिस्पर्धा कर सकती हैं।
एक रीड रेप्लिका अच्छा स्थान है:
- आंतरिक रिपोर्टिंग वर्कलोड्स के लिए
- एडमिन डैशबोर्ड्स के लिए
- "डेली/वीकली मैट्रिक्स" व्यूज़ के लिए
आप प्राथमिक को तेज़, पूर्वानुमानित ट्रांज़ैक्शन्स पर केंद्रित रखते हुए एनालिटिक्स पढ़ाइयों को स्वतंत्र रूप से स्केल कर सकते हैं।
2) खोज और ब्राउज़ पेज जिनपर भारी रीड वॉल्यूम हो
कैटलॉग ब्राउज़िंग, यूज़र प्रोफाइल और कंटेंट फीड्स अक्सर उच्च मात्रा में समान पढ़ने वाली क्वेरियाँ पैदा करते हैं। जब यह रीड‑स्केलिंग प्रेशर बाधा बनता है, तो रेप्लिकास ट्रैफ़िक को सोख सकते हैं और लेटेंसी स्पाइक्स को कम कर सकते हैं।
यह विशेष रूप से प्रभावी है जब पढ़ाइयाँ कैश‑मिस‑भारी हों (कई यूनिक क्वेरियाँ) या जब आप केवल एप्लिकेशन कैश पर भरोसा नहीं कर सकते।
3) बैकग्राउंड जॉब्स जो बहुत डेटा स्कैन करते हैं
एक्सपोर्ट्स, बैकफिल्स, समरीज़ री‑कम्प्यूट करना और "हर रिकॉर्ड जो X से मेल खाता है" वाले जॉब्स प्राथमिक को थ्रैश कर सकते हैं। ऐसे स्कैन अक्सर रेप्लिकास पर चलाना सुरक्षित रहता है।
बस यह सुनिश्चित करें कि जॉब इवेंटुअल कंसिस्टेंसी सहन कर सके: रिप्लिकेशन लैग के कारण उसे नवीनतम अपडेट नहीं दिख सकते।
4) कम‑लेटेंसी के लिए मल्टी‑रीजन पढ़ाइयाँ (स्टेलेनेस‑केविट्स के साथ)
यदि आप ग्लोबली उपयोगकर्ता सर्व करते हैं, तो रेप्लिकास को उनके नज़दीक रखना राउंड‑ट्रिप टाइम घटा सकता है। ट्रेड‑ऑफ लैग या नेटवर्क मुद्दों के दौरान अधिक स्टेल पढ़ाइयों का जोखिम है, इसलिए यह उन पेजों के लिए बेहतर है जहाँ "लगभग ताज़ा" स्वीकार्य है (ब्राउज़, सिफारिशें, सार्वजनिक सामग्री)।
जहाँ रेप्लिकास उल्टा असर कर सकते हैं
Go और Postgres से शुरू करें
Go + PostgreSQL बैकएंड जनरेट करें और पढ़ने व लिखने के रास्तों को जल्द ही आकार देना शुरू करें।
रीड रेप्लिकास उन स्थितियों में बढ़िया होते हैं जहां "काफ़ी नज़दीक" ठीक है। वे तब उल्टा असर करते हैं जब आपका प्रोडक्ट चुपचाप मान ले कि हर पढ़ाई नवीनतम लिखाई दर्शाती है।
क्लासिक लक्षण: “मैंने अभी अपडेट किया, तो क्यों नहीं बदला?”
यूज़र अपना प्रोफ़ाइल एडिट करता है, फॉर्म सबमिट करता है, या अकाउंट सेटिंग बदलता है—और अगला पेज किसी रेप्लिका से सर्व होने पर कुछ सेकंड पीछे दिखाई देता है। अपडेट सफल हुआ था, पर उपयोगकर्ता पुराना डेटा देखता है और दोबारा सबमिट कर सकता है, दोहरी क्रियाएँ कर सकता है, या भरोसा खो सकता है।
यह विशेष रूप से परेशानी‑देह है उन फ्लोज़ में जहाँ उपयोगकर्ता तुरंत पुष्टि की उम्मीद करता है: ईमेल बदलना, प्रेफरेंस टॉगल करना, डॉक्युमेंट अपलोड करना, या कमेंट पोस्ट करके फिर रिडायरेक्ट होना।
"ताज़ा होना जरूरी" स्क्रीन (यहाँ जुआ मत खेलें)
कुछ पढ़ाइयाँ थोड़ी भी देर के लिए स्टेल सहन नहीं कर सकतीं:
- शॉपिंग कार्ट और चेकआउट टोटल्स
- वॉलेट बैलेंस, लॉयल्टी पॉइंट्स, इन्वेंटरी काउंट्स
- "क्या मेरी पेमेंट हुई?" जैसी स्थिति स्क्रीन
अगर कोई रेप्लिका पीछे है, तो आप गलत कार्ट टोटल दिखा सकते हैं, स्टॉक ओवरसेल कर सकते हैं, या पुराना बैलेंस दिखा सकते हैं। भले ही सिस्टम बाद में खुद को ठीक कर ले, उपयोगकर्ता अनुभव (और सपोर्ट वॉल्यूम) को नुकसान होता है।
एडमिन और ऑप्स टूल्स को सबसे ताज़ा सत्य चाहिए
आंतरिक डैशबोर्ड अक्सर वास्तविक निर्णय चलाते हैं: फ्रॉड समीक्षा, कस्टमर सपोर्ट, ऑर्डर फुलफिलमेंट, मॉडरेशन, और घटना प्रतिक्रिया। अगर कोई एडमिन टूल रेप्लिकास से पढ़ता है, तो आप अपूर्ण डेटा पर कार्रवाई करने का जोखिम उठाते हैं—उदा., पहले से रिफंड किए गए ऑर्डर को रिफंड कर देना, या नवीनतम स्टेटस चेंज मिस कर देना।
व्यावहारिक फ़िक्स: "राइट‑योर‑राइट्स" को प्राथमिक पर रूट करें
एक सामान्य पैटर्न है कंडीशनल रूटिंग:
- उपयोगकर्ता के लिखने के बाद उनकी फ़ॉलो‑अप पुष्टिकरण पढ़ाइयों को कुछ समय के लिए प्राथमिक पर भेजें (सेकंड से मिनट)।
- बैकग्राउंड, एनोनिमस, या नॉन‑क्रिटिकल पढ़ाइयाँ रेप्लिकास पर रखें।
यह रेप्लिकास के लाभ बचाए रखता है बिना कंसिस्टेंसी का अनुमान लगाने के जोखिम के।
रिप्लिकेशन लैग और स्टेल पढ़ाइयों को समझना
रिप्लिकेशन लैग वह देरी है जो किसी लिखे के प्राथमिक पर कमिट होने और वही परिवर्तन रेप्लिका पर दिखने के बीच होती है। अगर आपका ऐप उस देरी के दौरान रेप्लिका से पढ़ता है, तो यह "स्टेल" परिणाम दे सकता है—ऐसा डेटा जो कुछ पलों पहले सच था, पर अब नहीं।
लैग क्यों होता है
लैग सामान्य है, और अक्सर तनाव के समय बढ़ता है। आम कारणों में शामिल हैं:
- प्राथमिक पर लोड स्पाइक्स: ज्यादा लिखने का मतलब अधिक परिवर्तनों को भेजना और लागू करना।
- रेप्लिका का कमज़ोर या बिज़ी होना: रेप्लिका परिवर्तनों को उतनी तेज़ी से लागू नहीं कर पाती (CPU, डिस्क I/O)।
- नेटवर्क लेटेंसी या जिटर: प्रतिकृति स्ट्रीम को स्थानांतरित करने में देरी।
- बड़े ट्रांज़ैक्शन्स / बल्क अपडेट: एक बड़ा परिवर्तन सीरियलाइज़, ट्रांसफर और रीप्ले होने में समय ले सकता है।
स्टेल पढ़ाइयाँ प्रोडक्ट व्यवहार में कैसे दिखती हैं
लैग सिर्फ "ताज़गी" को नहीं, बल्कि उपयोगकर्ता‑नज़रिये से सहीपन को प्रभावित करता है:
- उपयोगकर्ता अपना प्रोफ़ाइल अपडेट करता है, फिर रीफ्रेश करने पर पुराना वैल्यू दिखता है।
- "अनराड संदेश" या नोटिफ़िकेशन बैज काउंट्स डिफ्ट करते हैं क्योंकि गिनती थोड़े पुराने रो पर आधारित है।
- एडमिन/रिपोर्टिंग स्क्रीन नवीनतम ऑर्डर्स, रिफंड्स, या स्टेटस चेंज मिस कर सकती हैं।
व्यावहारिक तरीके इसे संभालने के
शुरू करें यह तय करके कि आपकी फीचर क्या सहन कर सकती है:
- टॉलरेंस विंडो जोड़ें: कई डैशबोर्ड्स के लिए "डेटा 30 सेकंड तक पुराना हो सकता है" स्वीकार्य है।
- राइट‑आफ्टर‑राइट को प्राथमिक पर रूट करें: उपयोगकर्ता कुछ बदलने के बाद उस एंटिटी को थोड़ी देर प्राथमिक से पढ़ें।
- UI संदेश: उपयोगकर्ता को अपेक्षा सेट करें ("अपडेट हो रहा है…", "दिखने में कुछ सेकंड लग सकते हैं")।
- रीट्राइ लॉजिक: अगर किसी महत्वपूर्ण पढ़ाई में अभी‑ही लिखा रिकॉर्ड नहीं दिखता, तो प्राथमिक के विरुद्ध रीट्राइ करें या थोड़ी देरी के बाद पुनः प्रयास करें।
क्या मॉनिटर और अलर्ट करें
रेप्लिका लैग (समय/बाइट्स पीछे), रेप्लिका apply रेट, रिप्लिकेशन त्रुटियाँ, और रेप्लिका CPU/डिस्क I/O ट्रैक करें। लैग जब आपकी सहनशीलता से ऊपर जाए तब अलर्ट करें (उदा., 5s, 30s, 2m) और जब लैग लगातार बढ़ता रहे तब भी अलर्ट करें (इशारा कि बिना हस्तक्षेप के रेप्लिका पकड़ नहीं पाएगा)।
रीड स्केलिंग बनाम राइट स्केलिंग (मुख्य ट्रेड‑ऑफ)
रिपोर्टिंग को ट्रांज़ैक्शन्स से अलग करें
महत्वपूर्ण राइट पथों में भारी पढ़ाई मिलाए बिना आंतरिक रिपोर्टिंग स्क्रीन चालू करें।
रीड रेप्लिकास एक उपकरण हैं रीड स्केलिंग के लिए: SELECT क्वेरियों को सर्व करने के और स्थान जोड़ना। वे राइट स्केलिंग के लिए नहीं हैं: कितने INSERT/UPDATE/DELETE ऑपरेशन्स सिस्टम स्वीकार कर सकता है यह बढ़ाने के लिए।
रीड्स स्केल करना: रेप्लिकास किस में अच्छे हैं
जब आप रेप्लिकास जोड़ते हैं, आप रीड क्षमता जोड़ते हैं। अगर आपका ऐप रीड‑हेवी एंडपॉइंट्स (प्रोडक्ट पेज, फीड्स, लुकअप्स) पर बाधित है, तो आप उन क्वेरियों को कई मशीनों पर फैला सकते हैं।
यह अक्सर बेहतर करता है:
- लोड के दौरान क्वेरी लेटेंसी (प्राथमिक पर कम टकराव)
- रीड्स के लिए थ्रूपुट (ज़्यादा CPU/मेमोरी/I/O उपलब्ध)
- भारी पढ़ाइयों का आइसोलेशन, जैसे रिपोर्टिंग वर्कलोड्स, ताकि वे ट्रांज़ैक्शनल ट्रैफ़िक को प्रभावित न करें
राइटस् स्केल करना: रेप्लिकास क्या नहीं करते
एक सामान्य गलतफ़हमी है कि “ज़्यादा रेप्लिकास = ज़्यादा राइट थ्रूपुट।” सामान्य प्राथमिक‑रेप्लिका सेटअप में, सारे लिखे अभी भी प्राथमिक पर ही जाते हैं। वास्तव में, ज़्यादा रेप्लिकास प्राथमिक के लिए थोड़ा अधिक काम भी बढ़ा सकते हैं क्योंकि उसे हर रेप्लिका के लिए रिप्लिकेशन डेटा जनरेट और भेजना पड़ता है।
अगर आपकी समस्या लिखने की थ्रूपुट है, तो रेप्लिकास इसे नहीं ठीक करेंगे। आप आम तौर पर अलग उपाय देख रहे होंगे (क्वेरी/इंडेक्स ट्यूनिंग, बैचिंग, पार्टिशनिंग/शार्डिंग, या डेटा मॉडल बदलना)।
कनेक्शन सीमाएँ और पूलिंग: छिपा हुआ बॉटलनेक
भले ही रेप्लिकास आपको और रीड CPU दें, आप फिर भी कनेक्शन सीमाओं पर ठोकर खा सकते हैं। हर डेटाबेस नोड की अधिकतम समवर्ती कनेक्शन्स होती हैं, और रेप्लिकास जोड़ने से यह संभावित कनेक्शन्स बढ़ जाते हैं—बिना कुल मांग घटाए।
व्यावहारिक नियम: कनेक्शन पूलिंग (या एक पूलर) का उपयोग करें और प्रति‑सर्विस कनेक्शन गणनाएँ जानबूझकर रखें। वरना, रेप्लिकास बस “अधिक डेटाबेस जिन्हें ओवरलोड करना है” बन सकते हैं।
लागत‑व्यापी ट्रेड‑ऑफ: क्षमता मुफ्त नहीं है
रेप्लिकास वास्तविक लागत जोड़ते हैं:
- ज़्यादा नोड्स (कम्प्यूट खर्च)
- ज़्यादा स्टोरेज (प्रत्येक रेप्लिका आम तौर पर पूरी कॉपी स्टोर करती है)
- ज़्यादा ऑपरेशन्स प्रयास (मॉनिटरिंग लैग, बैकअप/रीस्टोर रणनीति, स्कीमा बदलाव, इन्सिडेंट रिस्पॉन्स)
ट्रेड‑ऑफ सरल है: रेप्लिकास आपको रीड हेडरूम और आइसोलेशन खरीदा देता है, पर वे जटिलता जोड़ते हैं और लिखने की सीमा नहीं बढ़ाते।
हाई अवेलेबिलिटी और फ़ेलओवर: रेप्लिकास क्या कर सकते हैं
रीड रेप्लिकास रीड उपलब्धता सुधार सकते हैं: यदि आपका प्राथमिक ओवरलोड या थोड़ी देर के लिए अनुपलब्ध हो, तो आप कुछ पढ़ने वाली ट्रैफ़िक रेप्लिकास से सर्व कर सकते हैं। इससे ग्राहक‑सामने वाले पेज प्रतिक्रियाशील रह सकते हैं (उन सामग्रियों के लिए जो थोड़ी स्टेलनेस सहन कर सकती हैं) और प्राथमिक दुर्घटना के ब्लास्ट‑रेडियस को कम किया जा सकता है।
क्या रेप्लिकास अकेले पूरी हाई‑अवेलेबिलिटी योजना प्रदान नहीं करते। एक रेप्लिका आम तौर पर स्वतः लेखन स्वीकार करने के लिए तैयार नहीं होती, और "एक पढ़ने योग्य कॉपी मौजूद है" का मतलब यह नहीं है कि "सिस्टम जल्दी और सुरक्षित रूप से फिर से लिखना शुरू कर सकता है।"
प्रमोशन और फ़ेलओवर (सैद्धांतिक रूप से)
फ़ेलओवर आम तौर पर मतलब होता है: प्राथमिक विफलता का पता लगाना → एक रेप्लिका चुनना → उसे नया प्राथमिक बनाना (promote) → लिखों को उस नोड पर रीडायरेक्ट करना।
कुछ मैनेज्ड डेटाबेस अधिकतर प्रक्रिया को स्वचालित करते हैं, पर मूल विचार वही रहता है: आप यह बदल रहे होते हैं कि कौन लिखने की अनुमति रखता है।
योजनाबद्ध जोखिम जिनका ध्यान रखें
- स्टेल डेटा: रेप्लिका पीछे हो सकती है। अगर आप उसे प्रमोट करते हैं, तो शायद नवीनतम लिखे खो सकते हैं जो कभी रेप्लिकेट नहीं हुए।
- स्प्लिट‑ब्रेन से बचाव: आपको दो नोड्स को एक साथ लिखने से रोकना चाहिए। इसलिए प्रमोशन आम तौर पर एक केंद्रित अथॉरिटी (मैनेज्ड कंट्रोल प्लेन, क्वोरम सिस्टम, या कड़े ऑपरेशनल प्रक्रियाएँ) द्वारा नियंत्रित होता है।
- रूटिंग और कैशेस: आपका ऐप टार्गेट बदलने का एक भरोसेमंद तरीका चाहिए—कनेक्शन स्ट्रिंग्स, DNS, प्रॉक्सी, या डेटाबेस राउटर। लिखने वाला ट्रैफ़िक पुराने प्राथमिक पर गलती से न जा पाए।
इसे फीचर की तरह टेस्ट करें
फ़ेलओवर को अभ्यास की तरह लें। स्टेजिंग में (और सावधानी से प्रोडक्शन में निम्न‑जोखिम विंडो में) गेम‑डे टेस्ट चलाएँ: प्राथमिक लॉस का सिमुलेशन करें, रिकवरी‑टाइम मापें, रूटिंग वेरिफाई करें, और पुष्टि करें कि आपका ऐप रीड‑ओनली अवधियों और रीकनेक्शन्स को सहजता से संभालता है।
व्यावहारिक रूटिंग पैटर्न (रीड/राइट स्प्लिटिंग)
रीड रेप्लिकास तभी मदद करेंगे जब आपकी ट्रैफ़िक असल में उन तक पहुँचे। "रीड/राइट स्प्लिटिंग" नियमों का सेट है जो लिखों को प्राथमिक और योग्य पढ़ाइयों को रेप्लिकास पर भेजता है—बिना सठीकता तोड़े।
पैटर्न 1: एप्लिकेशन में विभाजन
सबसे सरल तरीका आपके डेटा‑एक्सेस लेयर में स्पष्ट रूटिंग है:
- सारे लिखे (
INSERT/UPDATE/DELETE, स्कीमा बदलाव) प्राथमिक पर जाएं।
- केवल चुनी हुई पढ़ाइयाँ रेप्लिका उपयोग कर सकें।
यह समझने में आसान और रोलबैक करने में आसान है। आप यहां व्यापार नियम भी एन्कोड कर सकते हैं जैसे "चेकआउट के बाद, कुछ समय तक ऑर्डर स्टेटस प्राथमिक से पढ़ो।"
पैटर्न 2: प्रॉक्सी या ड्राइवर के जरिए विभाजन
कुछ टीमें डेटाबेस प्रॉक्सी या स्मार्ट ड्राइवर पसंद करती हैं जो "प्राइमरी बनाम रेप्लिका" एंडपॉइंट्स को समझते हैं और क्वेरी प्रकार या कनेक्शन सेटिंग्स के आधार पर रूट करते हैं। इससे एप्लिकेशन को बदलने की ज़रूरत कम होती है, पर सावधान रहें: प्रॉक्सी यह भरोसे के साथ नहीं जान सकता कि कौन‑सी पढ़ाइयाँ प्रोडक्ट परिप्रेक्ष्य से "सुरक्षित" हैं।
किन क्वेरियों को रेप्लिकास पर भेजना सुरक्षित है
अच्छे उम्मीदवार:
- एनालिटिक्स, रिपोर्टिंग वर्कलोड्स, डैशबोर्ड्स
- सर्च/ब्राउज़ पेज जहाँ थोड़ी स्टेलनेस स्वीकार्य है
- बैकग्राउंड जॉब्स जो रीट्राइ करते हैं और नवीनतम वैल्यू की ज़रूरत नहीं है
उन पढ़ाइयों को रेप्लिकास पर मत भेजें जो तुरंत किसी उपयोगकर्ता लिखाई के बाद होती हैं (उदा., "प्रोफ़ाइल अपडेट → रीलोड प्रोफ़ाइल"), जब तक कि आपके पास कंसिस्टेंसी रणनीति न हो।
ट्रांज़ैक्शन्स और सेशन कंसिस्टेंसी
एक ट्रांज़ैक्शन के भीतर, सभी पढ़ाइयाँ प्राथमिक पर रखें।
ट्रांज़ैक्शन के बाहर, "राइट‑योर‑राइट्स" सेशंस पर विचार करें: लिखने के बाद उपयोगकर्ता/सेशन को थोड़े TTL के लिए प्राथमिक से पिन करें, या विशिष्ट फॉलो‑अप क्वेरियों को प्राथमिक पर रूट करें।
छोटा शुरू करें और मापें
एक रेप्लिका जोड़ें, सीमित एंडपॉइंट/क्वेरियों का रूट करें, और पहले/बाद तुलना करें:
- प्राथमिक CPU और रीड IOPS
- रेप्लिका उपयोगिता
- एरर रेट और लेटेंसी पर्सेंटाइल्स
- स्टेल पढ़ाइयों से जुड़ी घटनाएँ
सिर्फ़ तब रूटिंग बढ़ाएँ जब प्रभाव स्पष्ट और सुरक्षित हो।
मॉनिटरिंग और ऑपरेशन्स बेसिक्स
रीड-हैवी फीचर्स तेज़ बनाएं
रीड-हैवी पेज और डैशबोर्ड तेज़ी से प्रोटोटाइप करें, फिर तय करें क्या स्टेल रीड स्वीकार्य है।
रीड रेप्लिकास "सेट और भूलो" नहीं होते। वे अतिरिक्त डेटाबेस सर्वर्स हैं जिनकी अपनी प्रदर्शन सीमाएँ, विफलता मोड और ऑपरेशनल जिम्मेदारियाँ होती हैं। थोड़ी निगरानी अनुशासन अक्सर "रेप्लिकास ने मदद की" और "रेप्लिकास ने उलझन बढ़ाई" के बीच का अंतर है।
क्या देखें (कुछ मैट्रिक्स जो मायने रखते हैं)
उपयोगकर्ता‑मुखी लक्षणों की व्याख्या करने वाले संकेतकों पर ध्यान दें:
- रेप्लिका लैग: रेप्लिका प्राथमिक से कितना पीछे है (सेकंड, बाइट्स, या WAL/LSN स्थिति)। यह स्टेल पढ़ाइयों की शुरुआती चेतावनी है।
- रिप्लिकेशन त्रुटियाँ: टूटे कनेक्शन्स, ऑथ फेल्योर, डिस्क‑फुल, या रिप्लिकेशन स्लॉट समस्याएँ। इन्हें शोर न समझें—इन्हें घटनाओं की तरह ट्रीट करें।
- क्वेरी लेटेंसी (p50/p95) रेप्लिका vs प्राथमिक पर: रेप्लिकास भी धीमे हो सकते हैं भले ही प्राथमिक ठीक हो (अलग कैश स्टेट, अलग हार्डवेयर, लंबी रिपोर्ट्स)।
- कैश हिट रेट: एक रेप्लिका जो लगातार मिस कर रही है, रीस्टार्ट या ट्रैफ़िक शिफ्ट के बाद उच्च लेटेंसी दिखा सकती है।
क्षमता योजना: कितनी रेप्लिकास चाहिए?
रीड्स ऑफ़लोड करने के लिए एक रेप्लिका से शुरू करें। तभी और जोड़ें जब आपको स्पष्ट सीमा मिले:
- रीड थ्रूपुट: एक रेप्लिका पीक QPS या भारी एनालिटिकल क्वेरियों को हैंडल नहीं कर सकती।
- आइसोलेशन: रिपोर्टिंग वर्कलोड के लिए एक समर्पित रेप्लिका रखें ताकि डैशबोर्ड्स यूज़र ट्रैफिक से संसाधन न चुराएँ।
- भूगोल: प्रति‑रीजन एक रेप्लिका रीड लेटेंसी घटा सकती है, पर ऑपरेशनल ओवरहेड बढ़ा देती है।
व्यावहारिक नियम: केवल तब रेप्लिकास स्केल करें जब आपने पुष्टि कर ली हो कि पढ़ाइयाँ ही बाधा हैं (न कि इंडेक्स, धीमी क्वेरियाँ, या ऐप कैशिंग)।
सामान्य ऑपरेशनल कार्य
- बैकअप्स: निर्णय लें कि बैकअप कहाँ चलेंगे। रेप्लिका से बैकअप लेना प्राथमिक पर लोड कम कर सकता है, पर कंसिस्टेंसी आवश्यकताओं और रेप्लिका की सेहत की जाँच करें।
- स्कीमा बदलाव: रिप्लिकेशन के परिप्रेक्ष्य में माइग्रेशन्स का परीक्षण करें (लंबे‑समय के DDL लैग बढ़ा सकते हैं)। रोलनाउट्स का समन्वय करें ताकि ऐप और स्कीमा परिवर्तन propagation के दौरान संगत रहें।
- रख‑रखाव विंडोज़: रेप्लिकास को पैच या रिस्टार्ट करने से अस्थायी रूप से पढ़ने की क्षमता घटती है। रोटेशन की योजना बनाएं ताकि आवश्यक रीड हेडरूम गिर न जाए।
ट्रबलशूटिंग चेकलिस्ट: "रेप्लिकास धीमे हैं"
- रेप्लिका लैग जाँचें: अगर यह उच्च है, तो उपयोगकर्ता रीट्राइ कर रहे हों या स्टेल डेटा देख रहे हों।
- रेप्लिका बनाम प्राथमिक पर स्लो क्वेरी लॉग की तुलना करें: रिपोर्टिंग क्वेरियाँ अक्सर यहाँ दिखती हैं।
- रेप्लिका होस्ट पर CPU, मेमोरी, डिस्क I/O, और नेटवर्क की जाँच करें।
- उन लंबे‑संचालित ट्रांज़ैक्शन्स के लिए जांचें जो प्राथमिक पर लॉक कंटेंशन पैदा कर रहे हों और रिप्लिकेशन को देर कर रहे हों।
- सुनिश्चित करें कि आपका रीड रूटिंग किसी एक रेप्लिका को ओवरलोड नहीं कर रहा (असमान लोड‑बैलेंसिंग)।
- पुष्टि करें कि रेप्लिकास पर इंडेक्स प्राथमिक की तरह मौजूद हैं और सांख्यिकियाँ अद्यतित हैं।
विकल्प और सरल निर्णय फ्रेमवर्क
रीड रेप्लिकास रीड स्केलिंग के लिए एक उपकरण हैं, पर अक्सर वे पहली लीवर नहीं होते। ऑपरेशनल जटिलता जोड़ने से पहले देखें कि क्या एक सरल समाधान वही परिणाम दे देता है।
पहले आज़माने के विकल्प
कैशिंग कई पढ़ाइयों को डेटाबेस से हटा सकता है। "रीड‑मोस्टली" पेजों (प्रोडक्ट डिटेल्स, सार्वजनिक प्रोफाइल, कॉन्फ़िग) के लिए एप्लिकेशन कैश या CDN लोड को नाटकीय रूप से घटा सकता है—बिना रिप्लिकेशन लैग जोड़ने के।
इंडेक्स और क्वेरी ऑप्टिमाइज़ेशन आम तौर पर अधिकांश मामलों में रेप्लिकास से बेहतर काम करते हैं: कुछ महँगी क्वेरियाँ CPU जला रही हों तो सही इंडेक्स जोड़ना, SELECT कॉलम घटाना, N+1 क्वेरियों को रोकना और खराब जोइन ठीक करना अक्सर सबसे बड़ा फायदा देता है।
मैटीरियलाइज़्ड व्यूज़ / प्री‑एग्रीगेशन उन वर्कलोड्स के लिए सहायक हैं जो स्वभाव से भारी हैं (एनालिटिक्स, डैशबोर्ड)। जटिल क्वेरियों को बार‑बार नहीं चलाकर आप कैलकुलेटेड नतीजे स्टोर कर सकते हैं और शेड्यूल पर रिफ्रेश कर सकते हैं।
कब शार्डिंग/पार्टिशनिंग पर विचार करें
अगर आपकी लिखने की समस्या है (हॉट रो, लॉक कंटेंशन, लिखने के I/O सीमा), तो रेप्लिकास मदद नहीं करेंगे। तब तालिकाओं को समय/टेनेंट के हिसाब से पार्टिशन करना, या ग्राहक‑आईडी के अनुसार शार्डिंग लिखने का लोड फैलाने और कंटेंशन कम करने का व्यावहारिक कदम होता है। यह बड़ा आर्किटेक्चरल कदम है, पर यह असली बाधा का समाधान देता है।
एक सरल निर्णय फ्रेमवर्क
चार सवाल पूछें:
- लक्ष्य क्या है? रीड लेटेंसी घटाना, रिपोर्टिंग वर्कलोड ऑफ़लोड करना, या हाई अवेलेबिलिटी सुधारना?
- कितनी ताज़गी चाहिए? अगर आप स्टेल पढ़ाई सहन नहीं कर सकते, तो रेप्लिकास उपयोगकर्ता‑दिखने वाली समस्याएँ ला सकते हैं।
- बजट क्या है? रेप्लिकास इंफ्रास्ट्रक्चर लागत और स्थायी मॉनिटरिंग/ऑपरेशन्स खर्च जोड़ते हैं।
- कितनी जटिलता सहन कर सकते हैं? रीड/राइट स्प्लिटिंग, इवेंटुअल कंसिस्टेंसी संभालना, और फ़ेलओवर टेस्टिंग गैर‑तुच्छ हैं।
अगर आप किसी नए प्रोडक्ट का प्रोटोटाइप बना रहे हैं या जल्दी सेवा खड़ी कर रहे हैं, तो पहले इन सीमाओं को आर्किटेक्चर में शामिल करना मददगार होता है। उदाहरण के लिए, Koder.ai पर बनने वाली टीमें अक्सर शुरुआत में सरलता के लिए एक ही प्राथमिक रखती हैं, और जैसे‑जैसे डैशबोर्ड्स, फीड्स, या आंतरिक रिपोर्टिंग ट्रांज़ैक्शनल ट्रैफ़िक से प्रतिस्पर्धा करने लगते हैं, वे रेप्लिकास की ओर बढ़ती हैं। प्लानिंग‑फ़र्स्ट वर्कफ़्लो यह तय करना आसान बनाता है कि कौन‑से एंडपॉइंट्स इवेंटुअल कंसिस्टेंसी सहेंगे और कौन‑से “राइट‑योर‑राइट्स” प्राथमिक से पढ़ने चाहिए।
यदि आप मार्ग चुनने में मदद चाहते हैं, तो /pricing देखें, या संबंधित मार्गदर्शिकाएँ /blog में ब्राउज़ करें।