10 अक्टू॰ 2025·8 मिनट
आपके अनुप्रयोगों के लिए Redis: पैटर्न, समस्याएँ और सुझाव
Redis को अपने ऐप्स में व्यवहारिक तरीके से इस्तेमाल करना सीखें: कैशिंग, सेशन्स, कतारें, pub/sub, रेट‑लिमिटिंग — साथ ही स्केलिंग, परसिस्टेंस, मॉनिटरिंग और सामान्य समस्याएँ।
Redis को अपने ऐप्स में व्यवहारिक तरीके से इस्तेमाल करना सीखें: कैशिंग, सेशन्स, कतारें, pub/sub, रेट‑लिमिटिंग — साथ ही स्केलिंग, परसिस्टेंस, मॉनिटरिंग और सामान्य समस्याएँ।
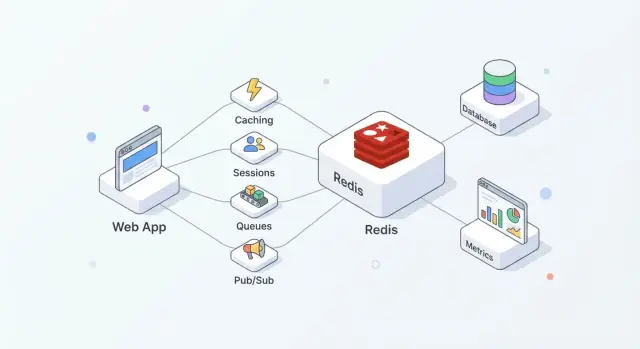
Redis एक इन‑मेमोरी डेटा स्टोर है जिसे अक्सर एप्लिकेशनों के बीच एक साझा “फास्ट लेयर” के रूप में इस्तेमाल किया जाता है। टीमें इसे इसलिए पसंद करती हैं क्योंकि इसे अपनाना सरल है, सामान्य ऑपरेशनों के लिए बहुत तेज़ है, और यह एक से अधिक काम (कैश, सेशन, काउंटर, कतार, pub/sub) संभालने के लिए पर्याप्त लचीला है बिना हर काम के लिए नया सिस्टम जोड़ने की जरूरत के।
व्यवहार में, Redis सबसे अच्छा तब काम करता है जब आप इसे स्पीड + समन्वय के रूप में देखें, जबकि आपकी प्राथमिक डेटाबेस स्रोत‑सत्य बनी रहती है।
एक आम सेटअप इस तरह दिखता है:
यह विभाजन आपके डेटाबेस को सटीकता और टिकाऊपन पर केंद्रित रखता है, जबकि Redis उच्च‑फ्रीक्वेंसी पढ़/लिख लिख को संभालता है जो अन्यथा लेटेंसी या लोड बढ़ाता।
शुरू में सही उपयोग पर, Redis कुछ व्यावहारिक नतीजे देता है:
Redis प्राथमिक डेटाबेस का विकल्प नहीं है। अगर आपको जटिल क्वेरीज, दीर्घकालिक स्टोरेज गारंटियाँ, या एनालिटिक्स‑शैली रिपोर्टिंग चाहिए, तो आपका डेटाबेस अभी भी सही जगह है।
साथ ही, यह मानकर न चलें कि Redis "डिफ़ॉल्ट रूप से टिकाऊ" है। यदि कुछ सेकण्ड का डेटा भी खोना अस्वीकार्य है, तो आपको सावधानीपूर्वक परसिस्टेंस सेटिंग्स—या किसी अलग सिस्टम—की आवश्यकता होगी जो आपकी रिकवरी ज़रूरतों के अनुरूप हो।
Redis को अक्सर “की‑वैल्यू स्टोर” के रूप में वर्णित किया जाता है, पर इसे ऐसे तेज़ सर्वर के रूप में सोचना ज़्यादा उपयोगी है जो नाम (की) के द्वारा छोटे डेटा टुकड़े रखें और उनमें परिवर्तन कर सके। यह मॉडल प्रत्याशित एक्सेस पैटर्न को प्रोत्साहित करता है: आप आमतौर पर जानते हैं कि आपको क्या चाहिए (एक सेशन, एक कैश्ड पेज, एक काउंटर), और Redis उसे एक ही राउंड‑ट्रिप में ला सकता है।
Redis डेटा को RAM में रखता है, इसलिए यह माइक्रोसेकंड से लेकर लो मिलिसेकंड में जवाब दे सकता है। ट्रेड‑ऑफ यह है कि RAM सीमित और डिस्क से महँगा है।
जल्दी निर्णय लें कि Redis क्या है:
Redis डेटा को डिस्क पर परसिस्ट कर सकता है (RDB स्नैपशॉट और/या AOF एपेंड‑ओनली लॉग), पर परसिस्टेंस लिखने पर ओवरहेड जोड़ता है और टिकाऊपन विकल्पों की ज़रूरत डालता है (उदाहरण के लिए, “तेज़ पर कभी‑कभी कुछ सेकंड खो सकता है” बनाम “धीमा पर सुरक्षित”)। परसिस्टेंस को एक डायल समझकर सेट करें जो व्यावसायिक प्रभाव पर आधारित हो, न कि एक बॉक्स जिसे आप स्वतः ही टिक कर दें।
Redis अधिकतर कमांड्स को एकल थ्रेड में निष्पादित करता है, जो सीमित सुनाई देता है जब तक आप यह न याद रखें कि दो बातें हैं: ऑपरेशंस आम तौर पर छोटे होते हैं, और कई वर्कर थ्रेड्स के बीच लॉकिंग ओवरहेड नहीं होता। जब तक आप महँगे कमांड और ओवरसाइज़्ड पेलोड से बचते हैं, यह मॉडल उच्च समवर्तीता के तहत बेहद कुशल हो सकता है।
आपकी ऐप Redis से TCP पर क्लाइंट लाइब्रेरीज़ के ज़रिये बात करती है। कनेक्शन पूलिंग का उपयोग करें, रिक्वेस्ट्स छोटे रखें, और जब कई ऑपरेशंस की ज़रूरत हो तो बैचिंग/पाइपलाइनिंग प्राथमिकता दें।
टाइमआउट और रेट्राइज़ की योजना बनाएं: Redis तेज़ है, पर नेटवर्क तेज़ नहीं होते, और आपकी एप्लिकेशन को gracefully degrade करना चाहिए जब Redis व्यस्त या अस्थायी रूप से अनुपलब्ध हो।
यदि आप नया सर्विस बना रहे हैं और जल्दी इन बेसिक्स को स्टैंडर्डाइज़ करना चाहते हैं, तो एक प्लेटफ़ॉर्म जैसे Koder.ai आपकी मदद कर सकता है React + Go + PostgreSQL एप्लिकेशन स्कैफोल्ड करने में और फिर Redis‑बैक्ड फीचर्स (कैशिंग, सेशन्स, रेट लिमिटिंग) चैट‑ड्रिवन वर्कफ़्लो के ज़रिये जोड़ने में—वह भी तब जब आप स्रोत कोड एक्सपोर्ट कर के कहीं भी चलाना चाहें।
कैशिंग तभी मददगार है जब उसकी स्पष्ट जिम्मेदारी हो: कौन भरता है, कौन इनवैलिडेट करता है, और “पर्याप्त ताज़ा” का क्या मतलब है।
Cache‑aside का मतलब है कि आपकी एप्लिकेशन—Redis नहीं—रीड्स और राइट्स को नियंत्रित करती है।
आम फ़्लो:
Redis एक तेज़ की‑वैल्यू स्टोर है; आपकी ऐप तय करती है कि कैसे सीरियलाईज़, वर्ज़न और एग्ज़पायर एंट्रीज़ को संभालना है।
TTL एक प्रोडक्ट निर्णय भी है जितना कि तकनीकी। छोटी TTLs stale‑ness कम करती हैं पर डेटाबेस लोड बढ़ाती हैं; लंबी TTLs काम बचाती हैं पर आउटडेटेड परिणामों का जोखिम बढ़ाती हैं।
व्यवहारिक टिप्स:
user:v3:123) ताकि पुराने कैश्ड शेप नए कोड को ब्रेक न करें।जब कोई हॉट की एक्सपायरी होती है, कई रिक्वेस्ट्स एक साथ मिस कर सकती हैं।
आम रक्षा उपाय:
अच्छे उम्मीदवारों में शामिल हैं API प्रतिक्रियाएँ, महँगी क्वेरी परिणाम, और कम्प्यूटेड ऑब्जेक्ट्स (रकोमेंडेशन्स, एग्रीगेशन)। पूरे HTML पेज का कैश करना काम कर सकता है, पर पर्सनलाइज़ेशन और अनुमतियों के साथ सावधान रहें—जब यूज़र‑विशिष्ट लॉजिक हो तो फ्रैगमेंट कैशिंग बेहतर है।
Redis छोटे‑समय के लॉगिन स्टेट के लिए व्यावहारिक जगह है: सेशन IDs, रिफ्रेश‑टोकन मेटाडेटा, और "इस डिवाइस को याद रखें" फ़्लैग्स। लक्ष्य है ऑथेंटिकेशन को तेज़ बनाना जबकि सेशन लाइफटाइम और रिवोकेशन पर कड़ा नियंत्रण रखना।
आम पैटर्न यह है: आपकी ऐप एक रैंडम सेशन ID जारी करती है, Redis में एक संक्षिप्त रिकॉर्ड स्टोर करती है, और ID को ब्राउज़र में HTTP‑only कुकी के रूप में लौटाती है। हर अनुरोध पर आप सेशन की-अप को देखकर यूज़र आइडेंटिटी और परमिशन्स को रिक्वेस्ट कंटेक्स्ट में जोड़ते हैं।
Redis यहां अच्छा काम करता है क्योंकि सेशन रीड अक्सर होते हैं, और सेशन एक्सपाइरी इन‑बिल्ट होती है।
कीज़ को इस तरह डिज़ाइन करें कि स्कैन और रिवोक करना आसान हो:
sess:{sessionId} → सेशन पेलोड (userId, issuedAt, deviceId)user:sessions:{userId} → सक्रिय session IDs का Set (वैकल्पिक, “सब जगह लॉगआउट” के लिए)sess:{sessionId} पर TTL का उपयोग करें जो आपकी सेशन लाइफटाइम से मेल खाता हो। यदि आप सेशन्स रोटेट करते हैं (सिफारिश की जाती है), तो नया सेशन ID बनाएं और पुराना तुरंत डिलीट कर दें।
"स्लाइडिंग एक्सपायरेशन" (हर अनुरोध पर TTL बढ़ाना) सावधानी से इस्तेमाल करें: यह भारी उपयोगकर्ताओं के लिए सेशन्स को अनंतकाल तक जिंदा रख सकता है। एक सुरक्षित समझौता है कि केवल तब TTL बढ़ायें जब वह निकटता पर हो।
एक डिवाइस पर लॉगआउट करने के लिए, sess:{sessionId} को डिलीट कर दें।
सभी डिवाइसेज़ पर लॉगआउट करने के लिए, या तो:
user:sessions:{userId} में पाए गए सभी session IDs डिलीट करें, याuser:revoked_after:{userId} टाइमस्टैम्प रखें और किसी भी सेशन को अमान्य मानें जो इससे पहले जारी हुआ होटाइमस्टैम्प विधि बड़े‑फैन‑आउट डिलीट्स से बचाती है।
Redis में न्यूनतम आवश्यक डेटा ही स्टोर करें—IDs को प्राथमिकता दें न कि व्यक्तिगत डेटा। कच्चे पासवर्ड या लंबे‑अवधि के सीक्रेट कभी न रखें। अगर आपको टोकन-संबंधी डेटा स्टोर करना ही है, तो हैश रखें और तंग TTLs का प्रयोग करें।
किसे Redis से कनेक्ट करने की अनुमति है, उसे सीमित करें, ऑथेंटिकेशन आवश्यक बनायें, और सेशन IDs को उच्च‑एंट्रॉपी रखें ताकि अनुमान लगाने के हमलों से बचा जा सके।
रेट‑लिमिटिंग वह जगह है जहाँ Redis चमकता है: यह तेज़ है, आपकी सभी ऐप इंस्टेंसों के बीच साझा होता है, और परम‑ऑमिक ऑपरेशंस प्रदान करता है जो भारी ट्रैफ़िक के तहत काउंटरों को सुसंगत रखते हैं। यह लॉगिन एण्डपॉइंट्स, महँगी सर्चेस, पासवर्ड रीसेट फ्लो और किसी भी API के लिए उपयोगी है जिसे स्क्रैप या ब्रूट‑फोर्स किया जा सकता है।
Fixed window सबसे सरल है: "एक मिनट में 100 अनुरोध"। आप वर्तमान मिनट बकेट में अनुरोधों की गिनती करते हैं। यह आसान है, पर बॉउंडरी पर बर्स्ट की अनुमति दे सकता है (उदा., 12:00:59 पर 100 और 12:01:00 पर फिर 100)।
Sliding window बाउंडरी को स्मूद बनाता है क्योंकि यह पिछले N सेकंड/मिनट्स को देखता है न कि सिर्फ़ वर्तमान बकेट। यह अधिक न्यायसंगत है, पर आमतौर पर महंगा होता है (आपको sorted sets या अधिक बुककीपिंग की ज़रूरत पड़ सकती है)।
Token bucket बर्स्ट हैंडलिंग के लिए शानदार है। यूज़र्स समय के साथ टोकन "कमाते" हैं एक कैप तक; हर अनुरोध एक टोकन खर्च करता है। यह छोटे बर्स्ट्स की अनुमति देता है जबकि औसत दर को लागू रखता है।
एक आम फिक्स्ड‑विंडो पैटर्न है:
INCR key से काउंटर बढ़ाएँEXPIRE key window_seconds से TTL सेट/रीसेट करेंचाल यह है कि इसे सुरक्षित तरीक़े से करें। अगर आप INCR और EXPIRE को अलग कॉल्स के रूप में चलाते हैं, तो उनके बीच क्रैश होने पर ऐसी कीज़ बन सकती हैं जो कभी एक्सपायर न हों।
सुरक्षित विकल्पों में शामिल हैं:
INCR करने और केवल पहली बार की‑निर्माण पर EXPIRE सेट करने के लिए एक Lua स्क्रिप्ट का उपयोग।SET key 1 EX <ttl> NX का उपयोग आरंभिककरण के लिए, फिर बाद में INCR (अक्सर फिर भी स्क्रिप्ट में रैप किया जाता है ताकि रेस से बचा जा सके)।एटॉमिक ऑपरेशंस तब सबसे ज़रूरी होते हैं जब ट्रैफ़िक स्पाइक्स हों: इनके बिना, दो अनुरोध एक ही अवशिष्ट कोटा देख सकते हैं और दोनों पास हो सकते हैं।
अधिकतर ऐप्स को कई परतों की ज़रूरत होती है:
rl:user:{userId}:{route})बर्स्टी एण्डपॉइंट्स के लिए, token bucket (या उदार fixed window साथ ही एक छोटा "burst" विंडो) वैध स्पाइक्स जैसे पेज लोड या मोबाइल री‑कनेक्ट्स को दंडित करने से बचाता है।
पहले तय करें कि “सुरक्षित” का क्या मतलब है:
आम समझौता यह है कि कम‑जोखिम रूट्स के लिए fail-open और संवेदनशील रूट्स (login, password reset, OTP) के लिए fail-closed रखें, और मॉनिटरिंग रखें ताकि रेट‑लिमिटिंग बंद होते ही आप नोटिस कर सकें।
जब आपको ईमेल भेजना, इमेज रिसाइज़ करना, डेटा सिंक करना, या आवधिक टास्क चलाने के लिए हल्की कतार चाहिए होती है, तब Redis बैकग्राउंड जॉब्स चला सकता है। कुंजी होती है सही डेटा स्ट्रक्चर चुनना और retries तथा failure हैंडलिंग के स्पष्ट नियम तय करना।
Lists सबसे सरल कतार हैं: producers LPUSH, workers BRPOP करते हैं। ये आसान हैं, पर आपको "in‑flight" जॉब्स, retries, और visibility timeouts के लिए अतिरिक्त लॉजिक बनानी पड़ेगी।
Sorted sets तब ज़बरदस्त होते हैं जब शेड्यूलिंग मायने रखती है। स्कोर को टाइमस्टैम्प (या प्राथमिकता) के रूप में इस्तेमाल करें, और workers अगला due जॉब फेच करें। यह देरी वाले जॉब्स और प्राथमिकता कतारों के लिए उपयुक्त है।
Streams अक्सर ड्यूरेबल वर्क वितरण के लिए बेहतर डिफॉल्ट होते हैं। वे consumer groups को सपोर्ट करते हैं, हिस्टरी रखते हैं, और कई वर्कर्स को बिना अपना "प्रोसेसिंग लिस्ट" बनाये समन्वय करने देते हैं।
Streams consumer groups में, एक worker मैसेज पढ़ता है और बाद में ACK करता है। अगर worker क्रैश हो जाता है, तो मैसेज pending रहता है और किसी अन्य worker द्वारा claim किया जा सकता है।
Retries के लिए, प्रयास‑गणना ट्रैक करें (मैसेज पेलोड में या साइड कीज़ में) और एक्सपोनेंशियल बैकऑफ लागू करें (अक्सर एक sorted set "retry schedule" के माध्यम से)। मैक्स प्रयास सीमा के बाद, जॉब को मैनुअल रिव्यू के लिए dead-letter queue (दूसरा stream या list) में भेजें।
मान लें कि जॉब्स दो बार चल सकते हैं। हैंडलर्स को idempotent बनायें:
job:{id}:done) का उपयोग करते हुए SET ... NX से साइड इफेक्ट्स से पहले चेक करेंपेलोड छोटे रखें (बड़ा डेटा कहीं और स्टोर करें और रेफरेंस पास करें)। बैक‑प्रेशर जोड़ें—कतार की लंबाई सीमित करके, लेगर बढ़ने पर प्रोड्यूसर्स को धीमा करके, और pending depth और प्रोसेसिंग समय के आधार पर वर्कर्स को स्केल करके।
Redis Pub/Sub सबसे सरल तरीका है ईवेंट्स को ब्रॉडकास्ट करने का: पब्लिशर्स चैनल पर मैसेज भेजते हैं, और हर कनेक्टेड सब्सक्राइबर उसे तुरंत पाता है। यहां कोई पोलिंग नहीं—सिर्फ़ लाइटवेट “पुश” जो रियल‑टाइम अपडेट्स के लिए अच्छी तरह काम करता है।
Pub/Sub तब अच्छा है जब आपको गति और फैन‑आउट चाहिए और गारंटीबद्ध डिलीवरी की परवाह कम हो:
एक उपयोगी मानसिक मॉडल: Pub/Sub रेडियो स्टेशन जैसा है—जो भी ट्यून है वह ब्रॉडकास्ट सुनता है, पर किसी के पास रिकॉर्डिंग अपने आप नहीं रह जाती।
Pub/Sub के महत्वपूर्ण ट्रेड‑ऑफ़ हैं:
इसीलिए Pub/Sub उन वर्कफ़्लोज़ के लिए खराब फिट है जहाँ हर ईवेंट को प्रोसेस करना अनिवार्य हो (चाहे एक‑बार भी)।
यदि आपको टिकाऊपन, रिट्राइज, कन्श्यूमर ग्रुप्स, या बैक‑प्रेशर हैंडलिंग चाहिए तो आमतौर पर Redis Streams बेहतर विकल्प होते हैं। Streams घटनाओं को स्टोर करते हैं, acknowledgements के साथ प्रोसेसिंग करते हैं, और रिस्टार्ट के बाद रिकवर करने देते हैं—यह एक हल्का‑फुल्का मैसेज क्यू की तरह व्यवहार करते हैं।
वास्तविक डिप्लॉयमेंट्स में कई ऐप इंस्टेंस सब्सक्राइब करते हैं। कुछ व्यावहारिक टिप्स:
app:{env}:{domain}:{event} (उदा., shop:prod:orders:created).notifications:global पर ब्रॉडकास्ट करें, और यूज़र्स को लक्ष्य करने के लिए notifications:user:{id} का उपयोग करें।ऐसी उपयोगिता में Pub/Sub एक तेज़ ईवेंट "सिग्नल" है, जबकि Streams (या कोई अन्य कतार) उन ईवेंट्स को संभालता है जिन्हें आप खोने afford नहीं कर सकते।
Redis डेटा स्ट्रक्चर चुनना केवल "क्या काम करता है" का सवाल नहीं है—यह मेमोरी उपयोग, क्वेरी गति, और कोड की सादगी को भी प्रभावित करता है। एक अच्छा नियम है कि उस स्ट्रक्चर को चुनें जो उन प्रश्नों से मेल खाता है जिन्हें आप बाद में पूछेंगे (रीड पैटर्न), न कि केवल आज के स्टोर करने के तरीके से।
INCR/DECR)।SISMEMBER और आसान सेट ऑपरेशंस।Redis ऑपरेशंस कमांड‑स्तर पर एटॉमिक होते हैं, तो आप रेस कंडीशन्स के बिना काउंटर सुरक्षित रूप से इनक्रिमेंट कर सकते हैं। पेज व्यूज़ और रेट‑लिमिट काउंटर आमतौर पर INCR के साथ strings और expiry के साथ होते हैं।
लीडरबोर्ड्स में sorted sets बेहतरीन हैं: आप स्कोर अपडेट कर सकते हैं (ZINCRBY) और टॉप खिलाड़ियों को प्रभावी ढंग से ला सकते हैं (ZREVRANGE) बिना सभी एंट्रीज़ को स्कैन किये।
अगर आप कई कीज़ बनाते हैं जैसे user:123:name, user:123:email, user:123:plan तो आप प्रति‑की ओवरहेड बढ़ाते हैं और की मैनेजमेंट मुश्किल करते हैं।
एक हैश जैसे user:123 जिसमें फील्ड्स (name, email, plan) हों, संबंधित डेटा को एक साथ रखता है और आमतौर पर की‑काउंट को घटाता है। यह आंशिक अपडेट को भी आसान बनाता है (एक फील्ड अपडेट करें बजाय संपूर्ण JSON वापस लिखने के)।
संशय हो तो एक छोटा नमूना मॉडल करें और उच्च‑वॉल्यूम डेटा के लिए स्ट्रक्चर तय करने से पहले मेमोरी उपयोग मापें।
Redis को अक्सर “इन‑मेमोरी” कहा जाता है, पर उसके पास यह चुनाव होते हैं कि नोड रिस्टार्ट पर क्या होता है, डिस्क भर जाने पर क्या होता है, या सर्वर गायब होने पर क्या होता है। सही सेटअप इस बात पर निर्भर करता है कि आप कितना डेटा खोने की स्थिति स्वीकार कर सकते हैं और कितनी जल्दी आपको रिकवर होना चाहिए।
RDB snapshots आपके डेटासेट का प्वाइंट‑इन‑टाइम डंप सेव करते हैं। ये संकुचित और स्टार्टअप पर तेज़ लोड होते हैं, जिससे रिस्टार्ट तेज़ हो सकता है। ट्रेड‑ऑफ यह है कि आप अंतिम स्नैपशॉट के बाद लिखे गए हालिया बदलाव खो सकते हैं।
AOF (append-only file) लिखे गए ऑपरेशंस को जैसे‑जैसे होते हैं लॉग करता है। इससे सामान्यतः संभावित डेटा लॉस कम होता है क्योंकि चेंजेज अधिक लगातार रिकॉर्ड होते हैं। AOF फाइलें बड़ी हो सकती हैं, और स्टार्टअप पर रीप्ले लंबा लग सकता है—हालाँकि Redis AOF को rewrite/compact कर सकता है ताकि वह प्रबंधनीय रहे।
कई टीमें दोनों चलाती हैं: तेज़ रिस्टार्ट के लिए स्नैपशॉट और बेहतर लिखने की टिकाऊपन के लिए AOF।
परसिस्टेंस मुफ़्त नहीं है। डिस्क लिखाइयाँ, AOF fsync नीतियाँ, और बैकग्राउंड rewrite ऑपरेशंस लेटेंसी स्पाइक्स जोड़ सकते हैं अगर आपकी स्टोरेज धीमी या संतृप्त हो। दूसरी ओर, परसिस्टेंस रिस्टार्ट को कम डरावना बनाती है: बिना परसिस्टेंस के अनपेक्षित रिस्टार्ट का मतलब खाली Redis होगा।
रेप्लिकेशन डेटा की नकल (या नकलें) रखता है ताकि प्राथमिक डाउन होने पर आप फेलओवर कर सकें। लक्ष्य आम तौर पर उपलब्धता पहले होता है, न कि परफेक्ट कंसिस्टेंसी। विफलता में, रेप्लिकाज थोड़ा पीछे हो सकते हैं, और फेलओवर कुछ हालिया लिखे गए डेटा को खो सकता है।
किसी भी ट्यूनिंग से पहले दो संख्याएँ लिखें:
इन लक्ष्यों का उपयोग करके RDB आवृत्ति, AOF सेटिंग्स, और क्या आपको रेप्लिक्स/ऑटोमेटेड फेलओवर चाहिए—इन निर्णयों को तय करें कि Redis को आप किस भूमिका (cache, session store, queue, या primary data store) में उपयोग कर रहे हैं।
एक सिंगल Redis नोड आपको काफी दूर तक ले जा सकता है: यह ऑपरेट करने में सरल है, समझने में आसान है, और कई कैशिंग, सेशन, या कतार वर्कलोड्स के लिए अक्सर तेज़ी से काफी होता है।
स्केलिंग तब आवश्यक होती है जब आप हार्ड लिमिट्स पर पहुँचते हैं—आमतौर पर मेमोरी सीमा, CPU संतृप्ति, या एकल नोड एकल‑बिंदु‑असफलता बन जाता है जिसे आप स्वीकार नहीं कर सकते।
इनमें से कोई भी सच होने पर नोड जोड़ने पर विचार करें:
एक व्यावहारिक पहला कदम अक्सर वर्कलोड्स को अलग करना (दो स्वतंत्र Redis इंस्टेंसेस) होता है क्लस्टर में जाने से पहले।
शार्डिंग का मतलब है आपकी कीज़ को कई Redis नोड्स में विभाजित करना ताकि हर नोड केवल डेटा का एक हिस्सा रखे। Redis Cluster Redis का बिल्ट‑इन तरीका है यह स्वचालित रूप से करने का: की‑स्पेस को स्लॉट्स में बाँटा जाता है, और हर नोड कुछ स्लॉट्स का मालिक होता है।
इससे कुल मेमोरी और कुल थ्रूपुट बढ़ता है। ट्रेड‑ऑफ है जटिलता: मल्टी‑की ऑपरेशंस पर प्रतिबंध आते हैं (कीज़ को एक ही शार्ड पर होना चाहिए), और ट्रबलशूटिंग में अधिक हिस्से शामिल होते हैं।
"समान" शार्डिंग के बावजूद भी वास्तविक ट्रैफ़िक तिरछा हो सकता है। एक लोकप्रिय की ("हॉट की") एक नोड को ओवरलोड कर सकती है जबकि दूसरे खाली बैठे हों।
निवारण में शामिल हैं: छोटे TTLs के साथ जिटर जोड़ना, वैल्यू को कई कीज़ में बाँटना (की हैशिंग), या एक्सेस पैटर्न को फिर से डिज़ाइन करना ताकि पढ़ें फैल जाएं।
एक Redis Cluster को एक क्लस्टर‑अवेयर क्लाइंट चाहिए जो टोपोलॉजी खोज सके, सही नोड पर अनुरोध रूट कर सके, और स्लॉट्स मूव होने पर redirections का पालन कर सके।
माइग्रेट करने से पहले पुष्टि करें:
स्केलिंग तब सबसे अच्छा काम करती है जब यह योजनाबद्ध विकास हो: लोड टेस्ट करें, की लेटेंसी को इंस्ट्रुमेंट करें, और धीरे‑धीरे ट्रैफ़िक माइग्रेट करें बजाय सब कुछ एक ही बार में बदलने के।
Redis को अक्सर “आंतरिक पाइपलाइन” माना जाता है, और यही कारण है कि यह अक्सर लक्षित होता है: एक खुला पोर्ट पूरा डेटा लीकेज या एक आक्रमणकारी‑नियंत्रित कैश में बदल सकता है। मान लें कि Redis संवेदनशील इंफ्रास्ट्रक्चर है, भले ही आप केवल "अस्थायी" डेटा ही स्टोर कर रहे हों।
शुरू करें ऑथेंटिकेशन चालू करके और ACLs (Redis 6+) का उपयोग करके। ACLs आपको यह करने देती हैं:
हर कंपोनेंट के लिए एक ही पासवर्ड साझा करने से बचें। इसके बजाय प्रति‑सर्विस क्रेडेंशियल जारी करें और अनुमतियाँ संकीर्ण रखें।
सबसे प्रभावी नियंत्रण यह है कि Redis पहुँच योग्य ही न हो। Redis को एक प्राइवेट इंटरफ़ेस पर बाइंड करें, इसे प्राइवेट सबनेट पर रखें, और केवल उन सर्विसेस के लिए इनबाउंड ट्रैफ़िक को सुरक्षा समूह/फ़ायरवॉल से सीमित करें जिन्हें इसकी ज़रूरत है।
जब Redis ट्रैफ़िक होस्ट‑बाउंडरी पार करे जिन्हें आप पूरी तरह नियंत्रित नहीं करते (मल्टी‑AZ, साझा नेटवर्क, Kubernetes नोड्स, या हाइब्रिड एनवायरनमेंट), तो TLS का उपयोग करें। TLS स्निफ़िंग और क्रेडेंशियल चोरी को रोकता है, और सेशन्स, टोकन्स, या किसी भी यूज़र‑संबंधी डेटा के लिए थोड़े ओवरहेड के लायक है।
ऐसे कमांड्स को लॉक करें जो दुर्व्यवहार होने पर भारी नुकसान कर सकते हैं। सामान्य उदाहरण जिन्हें ACLs के ज़रिये नकारना या सीमित करना चाहिए: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG, और EVAL (या कम से कम स्क्रिप्टिंग को सावधानी से नियंत्रित करें)। rename-command दृष्टिकोण का उपयोग सावधानी से करें—ACLs आम तौर पर स्पष्ट और ऑडिट करने में आसान होते हैं।
Redis क्रेडेंशियल्स को अपने सीक्रेट्स मैनेजर में रखें (कोड या कंटेनर इमेज में नहीं), और रोटेशन की योजना बनायें। रोटेशन तब आसान होता है जब क्लाइंट्स बिना redeploy किए क्रेडेंशियल्स रीलोड कर सकें, या आप ट्रांज़िशन विंडो के दौरान दो मान्य क्रेडेंशियल्स का समर्थन करें।
यदि आप एक व्यावहारिक चेकलिस्ट चाहते हैं, तो अपनी रनबुक में इसे रखें साथ ही /blog/monitoring-troubleshooting-redis नोट्स भी।
Redis अक्सर "ठीक लगता है"…जब तक ट्रैफ़िक शिफ्ट न हो, मेमोरी धीरे‑धीरे न बढ़े, या कोई धीमा कमांड सब कुछ स्टॉल न कर दे। एक हल्का मॉनिटरिंग रूटीन और एक स्पष्ट इंसिडेंट चेकलिस्ट अधिकतर आकस्मिकताओं को रोक देती है।
एक छोटे सेट से शुरू करें जिसे आपकी टीम किसी को भी समझा सके:
जब कुछ "धीमा" लगे, तो Redis के अपने टूल्स से पुष्टि करें:
KEYS, SMEMBERS, या बड़े LRANGE कॉल्स में उछाल आम रेड फ़्लैग हैं।अगर लेटेंसी बढ़ती है जबकि CPU सामान्य दिखता है, तो नेटवर्क संतृप्ति, ओवरसाइज़्ड पेलोड्स, या ब्लॉक किए गए क्लाइंट्स पर विचार करें।
विकास के लिए योजना बनाते समय हेडरूम रखें (आम तौर पर 20–30% खाली मेमोरी) और लॉन्च या फीचर‑फ्लैग के बाद धारणाओं की पुनरावृत्ति करें। "निरन्तर evictions" को चेतावनी न समझें—इसे आउटेज मानें।
इंसिडेंट के दौरान (क्रम में) जाँचें: memory/evictions, latency, client connections, slowlog, replication lag, और हाल के deploys। बार‑बार होने वाले कारणों को लिखें और उन्हें स्थायी रूप से ठीक करें—केवल अलर्ट पर्याप्त नहीं होंगे।
यदि आपकी टीम तेजी से इटरेट कर रही है, तो इन ऑपरेशनल अपेक्षाओं को अपने डेवलपमेंट वर्कफ़्लो में भी शामिल करना मददगार हो सकता है। उदाहरण के लिए, Koder.ai के planning mode और snapshots/rollback के साथ, आप Redis‑बैक्ड फीचर्स (जैसे कैशिंग या रेट‑लिमिटिंग) को प्रोटोटाइप कर सकते हैं, लोड के तहत उनका परीक्षण कर सकते हैं, और सुरक्षित रूप से बदलाव वापस ले सकते हैं—साथ ही इम्प्लिमेंटेशन को स्रोत‑कोड के रूप में एक्सपोर्ट भी रख सकते हैं।
Redis सर्व-साझा, इन‑मेमोरी “फास्ट लेयर” के रूप में सबसे अच्छा है, जैसे:
स्थायी, प्राधिकृत डेटा और जटिल प्रश्नों के लिए अपनी प्राथमिक डेटाबेस का उपयोग करें। Redis को एक एक्सेलरेटर और समन्वयक समझें — सिस्टम ऑफ़ रिकॉर्ड नहीं।
नहीं। Redis परसिस्ट कर सकता है, लेकिन यह "डिफ़ॉल्ट रूप से टिकाऊ" नहीं माना जाना चाहिए। अगर आपको जटिल क्वेरीज, मजबूत टिकाऊपन गारंटी, या विश्लेषण/रिपोर्टिंग चाहिए तो वह डेटा प्राथमिक डेटाबेस में रखें。
अगर कुछ सेकंड का डेटा खो जाना अस्वीकार्य है, तो Redis की परसिस्टेंस सेटिंग्स अकेले काफी नहीं होंगी—बिना सावधानी के। ऐसे वर्कलोड के लिए या तो सावधानीपूर्वक कॉन्फ़िगरेशन करें या अलग सिस्टम चुनें।
अपने स्वीकार्य डेटा लॉस और रिकवरी व्यवहार के आधार पर निर्णय लें:
पहले अपने RPO/RTO लक्ष्य लिखें, फिर परसिस्टेंस को उसी के अनुरूप ट्यून करें।
Cache-aside में आपकी ऐप ज़िम्मेदार होती है:
यह तब अच्छा काम करता है जब आपकी एप्लिकेशन कभी‑कभार मिस सह सकती है और आपके पास एक्सपाइरेशन/इनवैलिडेशन की स्पष्ट पॉलिसी है।
TTL चुनते समय उपयोगकर्ता प्रभाव और बैकएंड लोड को आधार बनाइए:
user:v3:123) का प्रयोग करें।अगर अनिश्चित हों तो पहले छोटी TTL रखें, डेटाबेस लोड मापें और फिर समायोजित करें।
इनमें से एक या अधिक अपनाएँ:
ये पैटर्न सिंक्रोनाइज़्ड कैश मिस से डेटाबेस पर अति-लोड को रोकते हैं।
एक सामान्य तरीका:
sess:{sessionId} के तहत सेशन डेटा स्टोर करें और TTL को सेशन लाइफटाइम से मिलाएँ।user:sessions:{userId} को सक्रिय सेशन IDs की एक Set के रूप में रखें, ताकि “सभी जगह लॉगआउट” संभव हो।"स्लाइडिंग एक्सपाइरेशन" (हर अनुरोध पर TTL बढ़ाना) से सावधान रहें—यह भारी उपयोगकर्ताओं के लिए सेशन को अनिश्चितकाल तक जिंदा रख सकता है।
ऐटोमिक अपडेट्स का उपयोग करें ताकि काउंटर फंसें या रेस न करें:
INCR और EXPIRE को अलग, बिना सुरक्षा वाले कॉल के रूप में न चलाएँ।कीज़ को विचारपूर्वक स्कोप करें (per-user, per-IP, per-route), और पहले से तय करें कि Redis अनुपलब्ध होने पर fail-open करें या fail-closed—खासकर संवेदनशील एण्डपॉइंट्स के लिए।
निर्भरता और ऑपरेशनल ज़रूरतों के आधार पर चुनें:
LPUSH/BRPOP): सरल, पर retries, इन‑फ्लाइट ट्रैकिंग और टाइमआउट स्वयं बनानी पड़ती है।Pub/Sub तेज़, रियल‑टाइम ब्रॉडकास्ट के लिए उपयोग करें जहाँ संदेश खो जाना स्वीकार्य हो (presence, लाइव डैशबोर्ड)। इसकी सीमाएँ:
अगर हर ईवेंट को प्रोसेस करना ज़रूरी है, तो टिकाऊपन, consumer groups, retries और बैक‑प्रेशर हैंडलिंग के लिए Redis Streams चुनें। ऑपरेशनल हाइजीन के लिए Redis को ACLs और नेटवर्क इन्सोलेशन से लॉक करें, और latency/evictions को ट्रैक करें; एक रनबुक भी रखें जैसे /blog/monitoring-troubleshooting-redis।
जॉब पेलोड छोटे रखें; बड़े ब्लॉब्स कहीं और रखें और सिर्फ रेफरेंस पास करें।