क्यों Roy Fielding का REST आज भी महत्वपूर्ण है
Roy Fielding सिर्फ़ एक नाम नहीं है जो API शब्दजाल से जुड़ा हो। वे HTTP और URI स्पेसिफिकेशन्स के प्रमुख लेखकों में से एक थे और अपनी PhD थीसिस में उन्होंने एक आर्किटेक्चरल स्टाइल REST (Representational State Transfer) के रूप में वर्णित किया, जिससे यह समझाया गया कि वेब इतना कुशलता से क्यों काम करता है।
इस उत्पत्ति का महत्व इसलिए है क्योंकि REST "सुंदर एंडपॉइंट्स" बनाने के लिए नहीं बनाया गया था। यह उन प्रतिबंधों को समझाने का तरीका था जो एक वैश्विक, असंगठित नेटवर्क को अभी भी स्केल करने लायक बनाते हैं: बहुत सारे क्लाइंट, बहुत सारे सर्वर, इंटरमीडियरीज, कैशिंग, आंशिक विफलताएँ, और सतत परिवर्तन।
इस पोस्ट से आप क्या पाएँगे
यदि आपने कभी सोचा है कि दो "REST APIs" पूरी तरह अलग क्यों महसूस करते हैं—या क्यों एक छोटा डिजाइन निर्णय बाद में पेजिनेशन दर्द, कैशिंग उलझन, या ब्रेकिंग चेंजिस में बदल जाता है—तो यह गाइड उन आश्चर्यों को घटाने के लिए है।
आपको मिलेगा:
- API डिजाइन या मूल्यांकन करते समय स्पष्ट निर्णय लेने की क्षमता
- अपनी टीम के साथ ट्रेड-ऑफ पर चर्चा करने के लिए बेहतर शब्दावली
- वास्तविक प्रोजेक्ट्स में किन REST विचारों का सबसे अधिक महत्व है इसका व्यावहारिक अनुुभव
एक पेज में REST: स्टाइल, स्टैंडर्ड नहीं
REST कोई चेकलिस्ट, प्रोटोकॉल या सर्टिफिकेशन नहीं है। Fielding ने इसे एक architectural style कहा: प्रतिबंधों का एक सेट जो मिलकर ऐसी प्रणालियाँ बनाते हैं जो वेब की तरह स्केल करें—उपयोग में सरल, समय के साथ विकसित होने योग्य, और इंटरमीडियरीज (प्रॉक्सी, कैश, गेटवे) के अनुकूल बिना निरंतर समन्वय के।
REST किस समस्या का समाधान कर रहा था
प्रारम्भिक वेब को कई संगठनों, सर्वरों, नेटवर्क और क्लाइंट प्रकारों में काम करना था। इसे बिना केंद्रीय नियंत्रण के बढ़ना था, आंशिक विफलताओं का सामना करना था, और नई सुविधाओं को बिना पुराने को तोड़े प्रकट होने देना था। REST यह प्राथमिकता देता है कि कुछ व्यापक रूप से साझा की गई अवधारणाएँ (पहचानकर्ता, रिप्रज़ेंटेशन्स, स्टैंडर्ड ऑपरेशन्स) कस्टम, कड़े जुड़े कॉन्ट्रैक्ट्स के ऊपर हों।
"आर्किटेक्चरल प्रतिबंध" सरल शब्दों में
एक प्रतिबंध एक नियम है जो डिज़ाइन की स्वतंत्रता को सीमित करता है ताकि लाभ मिलें। उदाहरण के लिए, आप सर्वर-साइड सेशन स्टेट छोड़ सकते हैं ताकि किसी भी सर्वर नोड द्वारा अनुरोध को संभाला जा सके—जो विश्वसनीयता और स्केलिंग सुधारता है। हर REST प्रतिबंध ऐसे ही व्यापार-ऑफ़ बनाता है: कम एड-हॉक लचीलापन, अधिक पूर्वानुमानयोग्यता और विकासशीलता।
REST बनाम “REST-जैसा” APIs
कई HTTP APIs REST विचारों को उधार लेते हैं (HTTP पर JSON, URL एन्डपॉइंट्स, शायद स्टेटस कोड्स) पर पूरा प्रतिबंध सेट लागू नहीं करते। यह "गलत" नहीं है—अक्सर यह प्रोडक्ट डेडलाइन या अंदरूनी उपयोग की जरूरतों को दर्शाता है। फर्क का नाम रखना उपयोगी होता है: एक API resource-oriented हो सकता है बिना पूरी तरह REST होने के।
एक पैराग्राफ में मानसिक मॉडल
REST सिस्टम को ऐसे सोचें: resources (ऐसी चीजें जिनका URL से नामकरण हो सकता है) जिनसे क्लाइंट representations (resource का वर्तमान दृश्य, जैसे JSON या HTML) के माध्यम से इंटरैक्ट करते हैं, और जिन्हें links मार्गदर्शित करते हैं (अगले कदम और संबंधित संसाधन)। क्लाइंट को गोपनीय बाह्य-नियमों की ज़रूरत नहीं; वह स्टैण्डर्ड अर्थ समझकर links का पालन करता है, ठीक उसी तरह जैसे ब्राउज़र वेब पर नेविगेट करता है।
Resources और Representations: मूल शब्दावली
प्रतिबंधों और HTTP विवरणों में खोने से पहले, REST एक सरल शब्दावली बदलाव से शुरू होता है: resources के बारे में सोचें, न कि actions के बारे में।
Resource = एक संज्ञा जिसे आप पहचान सकते हैं
एक resource आपकी प्रणाली का पता योग्य "चीज" है: एक user, एक invoice, एक product category, एक shopping cart। महत्वपूर्ण यह है कि यह एक noun है जिसकी एक पहचान है।
इसीलिए /users/123 स्वाभाविक लगता है: यह ID 123 वाला user पहचानता है। इसके विपरीत, action-shaped URLs जैसे /getUser या /updateUserPassword verbs—operations—को दर्शाते हैं, न कि उस चीज़ को जिसकी आप पहचान कर रहे हैं।
REST यह नहीं कहता कि आप क्रियाएँ नहीं कर सकते। यह कहता है कि क्रियाएँ uniform interface के माध्यम से व्यक्त की जानी चाहिए (HTTP APIs में यह आमतौर पर GET/POST/PUT/PATCH/DELETE जैसी विधियाँ होती हैं) जो resource identifiers पर कार्य करें।
Representation = resource का एक दृश्य
एक representation वह है जो आप वायर पर भेजते हैं—किसी समय पर resource का स्नैपशॉट या दृश्य। वही resource कई representations में हो सकता है।
उदाहरण के लिए, resource /users/123 JSON के रूप में एप्प के लिए, या HTML के रूप में ब्राउज़र के लिए प्रदर्शित किया जा सकता है.
GET /users/123
Accept: application/json
यह वापस कर सकता है:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
जबकि:
GET /users/123
Accept: text/html
एक HTML पेज लौटा सकता है जो वही यूजर विवरण प्रदर्शित करता है।
मुख्य विचार: resource JSON नहीं है और न ही वह HTML है। वे केवल उसे रिप्रज़ेंट करने के फॉर्मैट हैं।
यह फ्रेमिंग API डिज़ाइन कैसे बदलती है
एक बार जब आप अपने API को resources और representations के चारों ओर मॉडल करते हैं, तो कई व्यावहारिक फैसले आसान हो जाते हैं:
- नाम स्थिर रहते हैं।
/users/123 वैध रहेगा भले ही आपका UI, वर्कफ़्लो, या डेटा मॉडल बदल जाए।
- एन्डपॉइंट्स सरल होते हैं। हर ऑपरेशन के लिए नया URL बनाने की बजाय आप resource URLs को पुन: उपयोग करते हैं और मेथड या रिप्रज़ेंटेशन बदलते हैं।
- क्लाइंट कोड कम कप्ल्ड होता है। क्लाइंट "यूजर लाओ" या "यूजर पर फील्ड अपडेट करो" पर ध्यान देता है न कि एक्शन वाले एंडपॉइंट्स की सूची याद रखने पर।
यह resource-फर्स्ट माइंडसेट वह आधार है जिस पर REST प्रतिबंध बनते हैं। इसके बिना, "REST" अक्सर "HTTP पर JSON और कुछ अच्छे URL पैटर्न" में गिरकर रह जाता है।
प्रतिबंध 1: क्लाइंट–सर्वर पृथक्करण
क्लाइंट–सर्वर पृथक्करण REST का एक तरीका है जिम्मेदारियों का साफ़ विभाजन लागू करने का। क्लाइंट उपयोगकर्ता अनुभव (जो लोग देखते और करते हैं) पर केंद्रित है, जबकि सर्वर डेटा, नियम और पर्सिस्टेंस (जो सत्य है और क्या अनुमति है) पर केंद्रित है। जब आप उन चिंताओं को अलग रखते हैं, तो प्रत्येक पक्ष बिना दूसरे की री-राइट के बदल सकता है।
क्लाइंट बनाम सर्वर पर क्या रहता है?
दैनिक शब्दों में, क्लाइंट "प्रेज़ेंटेशन लेयर" है: स्क्रीन, नेविगेशन, त्वरित फीडबैक के लिए फॉर्म वैलिडेशन, और ऑप्टिमिस्टिक UI व्यवहार (जैसे नया कमेंट तुरंत दिखाना)। सर्वर "सोर्स ऑफ ट्रूथ" है: ऑथेंटिकेशन, ऑथराइज़ेशन, बिजनेस नियम, डेटा स्टोरेज, ऑडिटिंग, और जो भी चीज़ डिवाइसेज़ में सार्थक रूप से सुसंगत रहनी चाहिए।
एक व्यावहारिक नियम: यदि निर्णय सुरक्षा, पैसा, परमिशन, या साझा डेटा कंसिस्टेंसी को प्रभावित करता है, तो वह सर्वर पर होना चाहिए। यदि निर्णय केवल अनुभव को प्रभावित करता है (लेआउट, लोकल इनपुट हिन्ट, लोडिंग स्टेट्स), तो वह क्लाइंट पर होना चाहिए।
यह आधुनिक ऐप पैटर्न्स से कैसे मेल खाता है
यह प्रतिबंध सीधे सामान्य सेटअप्स से मेल खाता है:
- SPA + API: एक वेब ऐप (React/Vue आदि) UI पर जल्दी iterate कर सकता है जबकि API resources पर सेवा देता रहता है।
- मोबाइल ऐप्स: iOS और Android क्लाइंट एक ही सर्वर नियम और एंडपॉइंट साझा कर सकते हैं।
- थर्ड-पार्टी इंटीग्रेशन: पार्टनर्स को वही सर्वर क्षमताएँ मिलती हैं बिना आपके UI की ज़रूरत के।
क्लाइंट–सर्वर पृथक्करण वह चीज़ है जो "एक बैकएंड, कई फ्रंटएंड" को वास्तविक बनाती है।
आम गलती: UI स्टेट को सर्वर सत्र में लीक करना
एक सामान्य ग़लती UI वर्कफ़्लो स्टेट को सर्वर पर संग्रहीत करना है (उदा.: "यूजर चेकआउट के किस स्टेप पर है")—यह बैकएंड को एक विशेष स्क्रीन फ्लो से जोड़ता है और स्केलिंग को मुश्किल बनाता है।
पसंदीदा तरीका यह है कि आवश्यक संदर्भ हर रिक्वेस्ट के साथ भेजें (या संग्रहित संसाधनों से व्युत्पन्न करें), ताकि सर्वर resources और नियमों पर बना रहे—किसी विशेष UI के प्रगति को याद रखने पर नहीं।
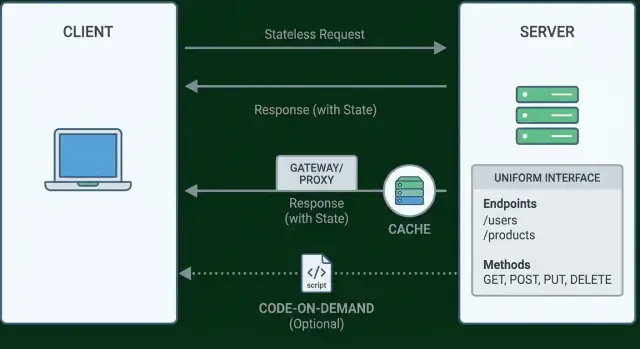
प्रतिबंध 2: स्टेटलेस इंटरैक्शन्स
स्टेटलेस का अर्थ है कि सर्वर को क्लाइंट के बारे में अनुरोधों के बीच किसी भी चीज़ को याद रखने की ज़रूरत नहीं। प्रत्येक अनुरोध में वह सारी जानकारी होती है जो उसे समझने और सही प्रतिक्रिया देने के लिए चाहिए—कॉलर कौन है, वे क्या चाहते हैं, और प्रोसेस करने के लिए जो भी संदर्भ चाहिए।
यह क्यों महत्वपूर्ण है
जब अनुरोध स्वतंत्र होते हैं, तो आप लोड बैलेंसर के पीछे सर्वरों को जोड़ या हटाएँ बिना यह चिंता किए कि "कौन सा सर्वर मेरी सेशन जानता है"। इससे स्केलिंग और लचीलापन बढ़ता है: कोई भी इंस्टेंस किसी भी अनुरोध को संभाल सकता है।
यह ऑपरेशन्स को भी सरल बनाता है। डिबगिंग अक्सर आसान हो जाता है क्योंकि पूरा संदर्भ अनुरोध (और लॉग) में दिखाई देता है, न कि सर्वर-साइड सेशन मेमोरी में छिपा हुआ।
वास्तविक APIs में आप जो ट्रेड-ऑफ महसूस करते हैं
स्टेटलेस APIs आमतौर पर हर कॉल पर थोड़ा अधिक डेटा भेजते हैं। सर्वर सत्र पर भरोसा करने की बजाय, क्लाइंट हर बार क्रेडेंशियल और संदर्भ शामिल करते हैं।
आपको "stateful" यूज़र फ्लोज़ (जैसे पेजिनेशन या बहु-चरण चेकआउट) के बारे में स्पष्ट होना पड़ेगा। REST इन्हें मना नहीं करता—बस यह स्टेट को क्लाइंट पर या सर्वर-साइड उन संसाधनों पर रखने को प्रोत्साहित करता है जिनकी पहचान और पुनःप्राप्ति संभव है।
व्यावहारिक पैटर्न (और वे क्या हल करते हैं)
- ऑथ टोकन्स (जैसे Bearer JWTs): प्रत्येक अनुरोध में
Authorization: Bearer … हेडर होता है ताकि कोई भी सर्वर इसे authenticate कर सके।
- Idempotency keys: "payment create" जैसे ऑपरेशन्स के लिए क्लाइंट
Idempotency-Key भेजते हैं ताकि retries काम को दोबारा न कर दें।
- Correlation IDs:
X-Correlation-Id जैसा हेडर आपको वितरण प्रणाली में एक उपयोगकर्ता कार्रवाई को ट्रेस करने देता है।
पेजिनेशन के लिए, "सर्वर page 3 याद रखता है" से बचें। स्पष्ट पैरामीटर जैसे ?cursor=abc या प्रतिक्रिया में next लिंक पसंद करें, ताकि नेविगेशन स्टेट प्रतिक्रियाओं में रहे न कि सर्वर मेमोरी में।
प्रतिबंध 3: कैशेबल रिस्पॉन्सेस
कैशिंग का मतलब है एक पिछले उत्तर को सुरक्षित रूप से पुन: उपयोग करना ताकि क्लाइंट (या बीच की कोई चीज़) को आपका सर्वर वही काम बार-बार न कराना पड़े। अच्छा किया जाए तो यह उपयोगकर्ताओं के लिए लेटेंसी घटाता है और आपके लिए लोड कम करता है—बिना API के अर्थ को बदले।
व्यवहार में "कैशेबल" का अर्थ
एक रिस्पॉन्स कैशेबल तब होता है जब यह सुरक्षित है कि किसी अन्य अनुरोध को कुछ समय के लिए वही पेलोड मिल जाए। HTTP में आप यह इरादा कैशिंग हेडर्स के साथ संचारित करते हैं:
Cache-Control: मुख्य नियंत्रक (कितनी देर रखना है, साझा कैशों द्वारा संग्रहीत हो सकता है या नहीं)ETag और Last-Modified: वैलिडेटर जो क्लाइंट को पूछने देते हैं "क्या यह बदल गया?" और एक सस्ता "not modified" उत्तर देते हैंExpires: ताज़गी व्यक्त करने का एक पुराना तरीका, फिर भी कहीं-कहीं मिलता है
यह केवल "ब्राउज़र कैशिंग" से बड़ा है। प्रॉक्सी, CDN, API गेटवे और यहाँ तक कि मोबाइल ऐप्स भी उत्तरों को नियमों के स्पष्ट होने पर पुन: उपयोग कर सकते हैं।
आम तौर पर क्या कैश करना सुरक्षित है (और क्या नहीं)
अच्छे उम्मीदवार:
- सार्वजनिक, सभी के लिए एक समान डेटा (product catalogs, documentation, फीचर फ्लैग्स जो user-specific नहीं हैं)
- कम बार बदलने वाले read-only resources (स्टैटिक कॉन्फ़िग, रेफरेंस डेटा)
- GET प्रतिक्रियाएँ जो कुकीज़ या ऑथORIZATION पर निर्भर नहीं करतीं
आमतौर पर नकारात्मक उम्मीदवार:
- खाता-आधारित व्यक्तिगत डेटा (प्रोफाइल, ऑर्डर, संदेश)
- ऑथ-संबंधी प्रतिक्रियाएँ (टोकन एक्सचेंज, सेशन स्टेट)
- वह सब जो प्रति-यूजर बदलता है जब तक आप स्पष्ट रूप से हैंडल न करें (उदा.,
private कैशिंग नियम)
व्यवहारिक परिणाम जो आप नोटिस करेंगे
- तेज़ पेज और अधिक प्रतिक्रियाशील ऐप्स (नेटवर्क पर कम इंतज़ार)
- कम सर्वर और DB लागत (दोहराए गए कंप्यूटेशन्स कम)
- कम "rate limit" घटनाएँ (कैश्ड रीड्स से अनुरोध मात्रा घटती है)
मुख्य विचार: कैशिंग कोई बाद की बात नहीं है। यह एक REST प्रतिबंध है जो उन APIs को इनाम देता है जो ताजगी और वैलिडेशन स्पष्ट रूप से बताते हैं।
प्रतिबंध 4: समान इंटरफ़ेस (वास्तव में क्या मतलब है)
समान इंटरफ़ेस को अक्सर "GET पढ़ने के लिए और POST बनाने के लिए उपयोग करें" समझ लिया जाता है। यह केवल एक छोटा हिस्सा है। Fielding का विचार बड़ा है: APIs इतने सहज होने चाहिए कि क्लाइंट को हर एंडपॉइंट के लिए विशेष ज्ञान की ज़रूरत न हो।
समान इंटरफ़ेस के चार भाग
-
संसाधनों की पहचान: आप चीज़ों (resources) को स्थिर पहचानकर्ताओं (URLs) से नामित करते हैं, न कि क्रियाओं से। सोचें /orders/123, न कि /createOrder।
-
प्रतिनिधित्व के माध्यम से मैनिप्यूलेशन: क्लाइंट resource बदलता है एक representation भेजकर (JSON, HTML, आदि)। सर्वर resource नियंत्रित करता है; क्लाइंट उसके representations का आदान-प्रदान करता है।
-
स्व-वर्णन संदेश: हर रिक्वेस्ट/रिस्पॉन्स में इसे प्रोसेस करने के तरीके के बारे में पर्याप्त जानकारी होनी चाहिए—मेथड, स्टेटस कोड, हेडर्स, मीडिया टाइप, और स्पष्ट बॉडी। यदि अर्थ बाहरी दस्तावेज़ों में छिपा है तो क्लाइंट टाइटली कप्ल्ड हो जाएंगे।
-
हाइपरमीडिया (HATEOAS): प्रतिक्रियाएँ लिंक और अनुमति प्राप्त क्रियाएँ शामिल करें ताकि क्लाइंट वर्कफ़्लो का पालन कर सके बिना हर URL पैटर्न को हार्ड-कोड किए।
यह कप्लिंग कैसे घटाता है
एक सुसंगत इंटरफ़ेस क्लाइंट को आंतरिक सर्वर विवरणों पर कम निर्भर बनाता है। समय के साथ इसका मतलब है कम ब्रेकिंग चेंजिस, कम "स्पेशल केसेज़," और जब टीमें एंडपॉइंट बदलें तो कम रीवर्क।
व्यावहारिक नियम
- स्टेटस कोड्स का सुसंगत उपयोग करें: जैसे
200 सफल रीड के लिए, 201 क्रिएटेड (साथ में Location), 400 वैलिडेशन, 401/403 auth संबंधी, 404 जब resource मौजूद न हो।
- अपनी एरर फ़ॉर्मैट को स्टैण्डर्ड करें पूरे API में। उदाहरण फ़ील्ड्स:
code, message, details, requestId।
- मीडिया टाइप्स और हेडर्स अर्थपूर्ण रखें (
Content-Type, कैशिंग हेडर्स), ताकि संदेश अपने आप को समझाएँ।
समान इंटरफ़ेस का उद्देश्य पूर्वानुमेयता और विकासशीलता है, सिर्फ़ "सही वर्ब्स" नहीं।
स्व-वर्णन संदेश: समझ के लिए डिज़ाइन करना
एक "स्व-वर्णन" संदेश वह है जो रिसीवर को बिना बाहरी ट्राइबल नॉलेज के यह बता दे कि उसे कैसे इंटरप्रेट करना है। यदि क्लाइंट (या इंटरमीडियरी) यह नहीं समझ सकता कि एक रिस्पॉन्स "कیا مطلب है" सिर्फ HTTP हेडर्स और बॉडी देखकर, तो आपने HTTP पर एक निजी प्रोटोकॉल बना दिया है।
पेलोड समझाने के लिए मीडिया टाइप्स का उपयोग करें
सबसे आसान जीत Content-Type (आप क्या भेज रहे हैं) और अक्सर Accept (आप क्या वापस चाहते हैं) के साथ स्पष्ट होना है। Content-Type: application/json बताता है कि बेसिक पार्सिंग नियम क्या हैं, पर आप जब अर्थ महत्वपूर्ण हो तो vendor या profile-based media types के साथ और आगे जा सकते हैं।
रुचिकर दृष्टिकोण:
- Generic media type + स्थिर फ़ील्ड्स:
application/json के साथ सावधानीपूर्वक बनाए रखा schema। अधिकांश टीमों के लिए सबसे आसान।
- Vendor media types:
application/vnd.acme.invoice+json ताकि एक विशिष्ट रिप्रज़ेंटेशन का संकेत मिले।
- Profiles:
application/json रखें और semantics को परिभाषित करने वाला profile पैरामीटर या लिंक जोड़ें।
वर्जनिंग और अनुकूलता (बिना क्लाइंट तोड़े)
वर्जनिंग को मौजूदा क्लाइंट्स की रक्षा करनी चाहिए। लोकप्रिय विकल्प:
- URL वर्जनिंग (
/v1/orders): स्पष्ट, पर प्रतिनिधित्वों को विकसित करने की बजाय उनके फोर्क होने को बढ़ावा दे सकती है।
- हेडर या मीडिया टाइप वर्जनिंग (
Accept के जरिए): URLs को स्थिर रखता है और संदेश का भाग बनाता है कि "यह क्या मतलब रखता है"।
- एडिटिव एवोल्यूशन: नए फ़ील्ड जोड़ना पसंद करें और पुराने काम करते रहें; धीरे-धीरे डिप्रिकेट करें।
जो भी चुनें, बैकवर्ड कम्पैटिबिलिटी को डिफ़ॉल्ट रखें: फ़ील्ड्स का नाम बदलकर न रखें, अर्थ चुपचाप न बदलें, और हटाना ब्रेकिंग परिवर्तन समझें।
सुसंगत त्रुटियाँ और स्पष्ट नामकरण
क्लाइंट तेजी से सीखते हैं जब त्रुटियाँ हर जगह एक जैसी दिखती हैं। एक एरर शेप चुनें (उदा., code, message, details, traceId) और endpoints में प्रयोग करें। स्पष्ट, अनुमान्य फील्ड नाम चुनें (createdAt बनाम created_at) और एक कन्वेंशन का पालन करें।
दस्तावेज़ीकरण मदद करता है—पर स्पष्टता संदेश में होनी चाहिए
अच्छी डॉक्यूमेंटेशन अपनाने में तेजी लाती है, पर यह अकेला स्थान नहीं होना चाहिए जहाँ अर्थ मौजूद हो। यदि किसी क्लाइंट को यह जानने के लिए विकी पढ़नी पड़े कि status: 2 का मतलब "paid" है या "pending", तो संदेश स्व-वर्णन नहीं है। अच्छी तरह डिज़ाइन किए गए हेडर्स, मीडिया टाइप्स, और पठनीय पेलोड से वह निर्भरता कम होती है और सिस्टम्स को विकसित करना आसान होता है।
हाइपरमीडिया (HATEOAS): REST विचारों में सबसे अधिक छोड़ा गया
हाइपरमीडिया (अक्सर HATEOAS: Hypermedia As The Engine Of Application State) का मतलब है कि क्लाइंट को API के अगले URLs पहले से जानने की ज़रूरत नहीं है। प्रत्येक रिस्पॉन्स में डिस्कवर करने योग्य अगले कदम लिंक के रूप में शामिल होते हैं: कहाँ जाना है, कौन से एक्शन्स संभव हैं, और कभी-कभी कौन सा HTTP मेथड उपयोग करना चाहिए।
व्यावहारिक में यह कैसा दिखता है
हार्ड-कोडेड रास्तों जैसे /orders/{id}/cancel की बजाय क्लाइंट सर्वर द्वारा दिए गए लिंक का पालन करता है। सर्वर प्रभावी रूप से कह रहा है: "वर्तमान resource की स्थिति को देखते हुए, यहाँ वैध मूव्स हैं।"
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
यदि ऑर्डर बाद में paid हो जाता है, तो सर्वर cancel लिंक हटाकर refund जोड़ सकता है—बिना एक अच्छी तरह व्यवहार करने वाले क्लाइंट को तोड़े।
हाइपरमीडिया किस समय सबसे अधिक मदद करता है
हाइपरमीडिया तब चमकता है जब फ्लोज़ विकसित होते हैं: ऑनबोर्डिंग स्टेप्स, चेकआउट, अनुमोदन, सब्सक्रिप्शन्स, या कोई भी प्रोसेस जहाँ "अगला क्या allowed है" स्थिति, परमिशन या बिजनेस रूल्स पर निर्भर करता है।
यह हार्ड-कोडेड URLs और नाज़ुक क्लाइंट अनुमान घटाता है। आप रूट्स को पुन: व्यवस्थित कर सकते हैं, नई क्रियाएँ जोड़ सकते हैं, या पुराने को डिप्रिकेट कर सकते हैं बशर्ते आप लिंक रिलेशन्स का अर्थ बनाए रखें।
टीमें इसे क्यों छोड़ देती हैं (और क्या खोती हैं)
टीमें अक्सर HATEOAS छोड़ देती हैं क्योंकि यह अतिरिक्त मेहनत जैसा लगता है: लिंक फॉर्मैट्स पर परिभाषा, रिलेशन नामों पर सहमति, और क्लाइंट डेवलपर्स को यह सिखाना कि वे यूआरएल्स बनाकर नहीं बल्कि लिंक का पालन करें।
जो आप खोते हैं वह है एक मुख्य REST लाभ: ढीली कप्लिंग। बिना हाइपरमीडिया के, कई APIs "HTTP पर RPC" बन जाते हैं—वे HTTP का उपयोग करते हैं, पर क्लाइंट अब भी बाहरी डॉक्यूमेंटेशन और फिक्स्ड URL टेम्पलेट्स पर बहुत निर्भर रहते हैं।
प्रतिबंध 5: स्तरीकृत प्रणाली
स्तरीकृत प्रणाली का अर्थ है कि क्लाइंट को यह जानने की ज़रूरत नहीं है (और अक्सर यह पता नहीं चलता) कि वह असल में ओरिजिन सर्वर से बात कर रहा है या रास्ते में किसी इंटरमीडियरी से। ये लेयर्स API गेटवे, रिवर्स प्रॉक्सी, CDN, ऑथ सर्विसेस, WAFs, सर्विस मेष, और माइक्रोसर्विसेस के बीच रूटिंग को शामिल कर सकती हैं।
लेयर्स उपयोगी क्यों हैं
लेयर्स साफ़ सीमाएँ बनाती हैं। सुरक्षा टीमें TLS, रेट लिमिट्स, ऑथेंटिकेशन और रिक्वेस्ट वैलिडेशन ऐज पर लागू कर सकती हैं बिना हर बैकएंड सेवा में बदलाव किए। ऑपरेशन्स टीमें गेटवे के पीछे हॉराइज़ॉन्टली स्केल कर सकती हैं, CDN में कैश लगा सकती हैं, या घटना के दौरान ट्रैफ़िक शिफ्ट कर सकती हैं। क्लाइंट्स के लिए यह सरल हो सकता है: एक स्थिर API एंडपॉइंट, सुसंगत हेडर्स, और अनुमान्य एरर फॉर्मैट।
व्यवहार में महसूस होने वाले ट्रेड-ऑफ़
इंटरमीडियरीज छिपी हुई लैटेन्सी ला सकती हैं (अतिरिक्त हॉप्स, अतिरिक्त हैंडशेक) और डिबगिंग कठिन बना सकती हैं: बग गेटवे नियमों, CDN cache, या ओरिजिन कोड में कहीं भी हो सकता है। कैशिंग उलझन तब होती है जब विभिन्न लेयर्स अलग-अलग तरीके से कैश करती हैं, या जब कोई गेटवे हेडर्स रीराइट करता है जो कैश कीज़ को प्रभावित करते हैं।
लेयर्स को नुकसान पहुंचाने से रोकने के व्यावहारिक सुझाव
- ट्रेसिंग IDs एंड-टू-एंड उपयोग करें: रिक्वेस्ट ID स्वीकार करें (या जनरेट करें) और हर हॉप में उसे आगे बढ़ाएँ; उसे रिस्पॉन्स और लॉग में शामिल करें।
- एरर प्रोप्रेगेशन स्पष्ट रखें: स्टैंडर्ड एरर बॉडी रखें और अपस्ट्रीम फेलियर्स को स्पष्ट रूप से मैप करें (हर समस्या को generic 500 में बदलें नहीं)।
- प्रति हॉप टाइमआउट सेट करें: गेटवे टाइमआउट, अपस्ट्रीम टाइमआउट, और क्लाइंट टाइमआउट को संरेखित रखें ताकि “रहस्यमय” डिस्कनेक्ट्स से बचा जा सके।
- कैशिंग व्यवहार डॉक्यूमेंट करें: स्पष्ट करें कौन सी प्रतिक्रियाएँ कैशेबल हैं और किन हेडर्स को इंटरमीडियरीज को संरक्षित रखना चाहिए।
लेयर्स शक्तिशाली हैं—जब सिस्टम देखकरने योग्य और अनुमान्य रहता है।
प्रतिबंध 6 (ऐच्छिक): कोड-ऑन-डिमांड
कोड-ऑन-डिमांड वह REST प्रतिबंध है जो स्पष्ट रूप से ऐच्छिक है। इसका अर्थ है कि सर्वर क्लाइंट का विस्तार करके उसे निष्पाद्य कोड भेज सकता है जो क्लाइंट साइड पर चलता है। हर व्यवहार क्लाइंट में पहले से न भेजकर, क्लाइंट ज़रूरत के अनुसार नया लॉजिक डाउनलोड कर सकता है।
वेब का परिचित उदाहरण: JavaScript
यदि आपने कभी ऐसा वेबपेज लोड किया है जो फिर इंटरैक्टिव बन जाता है—फॉर्म वैलिडेट करना, चार्ट रेंडर करना, टेबल फिल्टर करना—तो आपने कोड-ऑन-डिमांड का उपयोग किया है। सर्वर HTML और डेटा देता है, साथ में JavaScript जो ब्राउज़र में रन होकर व्यवहार देता है।
यह एक बड़ा कारण है कि वेब जल्दी विकसित हो सकता है: एक ब्राउज़र सामान्य-उद्देश्य क्लाइंट रह सकता है, जबकि साइटें नई क्षमताएँ भेजती हैं बिना उपयोगकर्ता को नया ऐप इंस्टॉल कराए।
यह ऐच्छिक क्यों है (और कई APIs इसे क्यों छोड़ते हैं)
REST बिना कोड-ऑन-डिमांड के भी "काम" करता है क्योंकि बाकी प्रतिबंध पहले से ही स्केलेबिलिटी, सरलता और इंटरऑपरेबिलिटी सक्षम करते हैं। एक API पूरी तरह से resource-oriented हो सकता है—कहीं JSON जैसी representations सर्व कर रहा हो—जबकि क्लाइंट अपना व्यवहार स्वयं लागू करता है।
वास्तव में, कई आधुनिक वेब APIs जानबूझकर executable code भेजने से बचते हैं क्योंकि यह जटिलता बढ़ाता है:
- सुरक्षा: निष्पाद्य कोड का बड़ा अटैक सरफेस होता है (इंजेक्शन, सप्लाई-चेन मुद्दे, मैलिशियस स्क्रिप्ट)
- कंटेंट नीतियाँ: ब्राउज़र्स Content Security Policy (CSP) जैसे प्रतिबंध लागू करते हैं, और संगठन इनलाइन स्क्रिप्ट या अज्ञात मूलों को ब्लॉक कर सकते हैं
- ऑडिटिंग और अनुपालन: यह साबित करना मुश्किल हो जाता है कि किसी समय पर क्लाइंट पर कौन सा कोड चला, विशेषकर यदि वह डायनेमिकली फेच किया गया हो
कोड-ऑन-डिमांड कब समझ में आता है
कोड-ऑन-डिमांड उपयोगी हो सकता है जब आप क्लाइंट वातावरण को नियंत्रित करते हैं और UI व्यवहार जल्दी रोलआउट करना चाहते हैं, या जब आप एक पतला क्लाइंट चाहते हैं जो सर्वर से "प्लगइन्स" या नियम डाउनलोड करता है। पर इसे एक अतिरिक्त टूल की तरह treat करें, न कि संसाधन-आधारित इंटरैक्शन की ज़रूरत।
मुख्य निष्कर्ष: आप REST को बिना कोड-ऑन-डिमांड के भी पूरी तरह से फॉलो कर सकते हैं—और कई प्रोडक्शन APIs ऐसा करते हैं—क्योंकि यह प्रतिबंध वैकल्पिक एक्सटेंसिबिलिटी के बारे में है, न कि resource-based इंटरैक्शन की नींव के बारे में।
आज REST लागू करना: व्यावहारिक विकल्प और सामान्य गलतियाँ
अधिकांश टीमें REST को बाहर नहीं करती—वे एक "REST-जैसा" स्टाइल अपनाती हैं जो HTTP को ट्रांसपोर्ट के रूप में रखता है जबकि कुछ प्रमुख प्रतिबंध धीरे-धीरे छोड़ दिए जाते हैं। यह ठीक हो सकता है, बशर्ते यह सचेत ट्रेड-ऑफ हो न कि बाद में नाजुक क्लाइंट और महंगी री-राइट के रूप में दिखाई देने वाली गलती।
सामान्य REST-जैसे शॉर्टकट्स (और क्यों होते हैं)
कुछ पैटर्न बार-बार दिखाई देते हैं:
- RPC endpoints:
/doThing, /runReport, /users/activate—नाम देना आसान, वायरअप करना आसान।
- Verb-heavy URLs:
/createOrder, /updateProfile, /deleteItem—HTTP मेथड्स गौण बन जाते हैं।
- छिपी हुई सेशन्स: "स्टेटलेस" APIs जो फिर भी sticky sessions, सर्वर मेमोरी, या इम्प्लिसिट वर्कफ़्लो स्टेट पर निर्भर करते हैं।
ये विकल्प शुरुआती रूप में उत्पादक लगते हैं क्योंकि वे आंतरिक फ़ंक्शन नामों और बिजनेस ऑपरेशन्स का प्रतिबिंब देते हैं।
बाद में आप क्या परिणाम देखेंगें
- नाज़ुक क्लाइंट्स: यदि क्लाइंट विशिष्ट एंडपॉइंट आकृतियों और एड-हॉक व्यवहारों पर निर्भर करते हैं, तो छोटे सर्वर रिफैक्टर्स भी ब्रेकिंग परिवर्तन बन सकते हैं।
- कठिन वर्जनिंग: जब URLs व्यवहारों को एन्कोड करते हैं बजाय स्थिर संसाधनों को, तो आप व्यवहार वर्जनिंग करने लगते हैं बजाय प्रतिनिधित्वों को विकसित करने के।
- कैश मिस (और उच्च लेटेंसी): कैशिंग हेडर्स की अनदेखी या सब कुछ के लिए POST उपयोग करने से इंटरमीडियरीज आपकी मदद नहीं कर पातीं।
- स्केलिंग समस्याएँ: छिपे सर्वर-साइड सेशन स्टेट हॉराइज़ॉन्टल स्केलिंग को जटिल बनाते हैं और विफलताओं से रिकवरी कठिन करते हैं।
एक व्यावहारिक संरेखण चेकलिस्ट
इसे "हम कितने REST हैं, वास्तव में?" रिव्यू के रूप में उपयोग करें:
- संसाधनों को नाम दें, क्रियाओं को नहीं:
/orders/{id} को प्राथमिकता दें बजाय /createOrder के।
- HTTP मेथड्स का इरादतन उपयोग करें: GET retrieval के लिए, POST creation के लिए, PUT/PATCH updates के लिए, DELETE removal के लिए।
- रिक्वेस्ट्स स्वतंत्र बनाएँ: कोई सर्वर मेमोरी जरूरी न हो—किसी क्लाइंट स्टेप को समझने के लिए।
- जहाँ सुरक्षित हो कैशिंग का लाभ उठाएँ: GET प्रतिक्रियाओं के लिए
Cache-Control, ETag, और Vary निर्धारित करें।
- एरर्स और मीडिया टाइप्स को स्टैण्डर्ड करें: सुसंगत स्टेटस कोड्स और रिस्पॉन्स शेप स्पेशल केसेज़ कम करते हैं।
यह निर्माण करते समय कहाँ दिखता है
REST प्रतिबंध सिर्फ़ सिद्धांत नहीं हैं—ये गार्डरेल हैं जिन्हें आप शिप करते समय महसूस करते हैं। जब आप तेज़ी से API जेनरेट कर रहे होते हैं (उदा., एक React फ्रंटेंड स्कैफोल्डिंग के साथ Go + PostgreSQL बैकएंड), सबसे आसान गलती यह है कि "सबसे तेज़ वायरअप" आपकी इंटरफ़ेस को नियंत्रित कर दे।
यदि आप Koder.ai जैसे vibe-coding प्लेटफ़ॉर्म का उपयोग करके चैट से वेब ऐप बना रहे हैं, तो इन REST प्रतिबंधों को बातचीत में जल्दी लाना मदद करता है—पहले resources नामकरण करें, स्टेटलेस रहें, सुसंगत एरर शेप्स पर निर्णय लें, और तय करें कि कहाँ कैश सुरक्षित है। इस तरह, तेज़ iteration के बावजूद भी APIs ग्राहकों के लिए अनुमान्य और विकसित करने में आसान बने रहते हैं। (और क्योंकि Koder.ai सोर्स कोड एक्सपोर्ट सपोर्ट करता है, आप जरूरत बढ़ने पर API कॉन्ट्रैक्ट और इम्प्लीमेंटेशन को परिष्कृत कर सकते हैं।)
API और वेब ऐप टीमों के लिए निष्कर्ष
पहले अपने प्रमुख संसाधन परिभाषित करें, फिर प्रतिबंधों को सचेत रूप से चुनें: यदि आप कैशिंग या हाइपरमीडिया छोड़ रहे हैं तो कारण और विकल्प दस्तावेज़ करें। लक्ष्य पवित्रता नहीं—स्पष्टता है: स्थिर resource identifiers, पूर्वानुमेय semantics, और स्पष्ट ट्रेड-ऑफ जो आपके सिस्टम के विकसित होने पर क्लाइंट को लचीला बनाए रखें।