25 जुल॰ 2025·8 मिनट
LLM कैसे साधारण अंग्रेज़ी विचारों को फुल‑स्टैक ऐप में बदलते हैं
LLM साधारण अंग्रेज़ी प्रोडक्ट आइडियाज़ को वेब, मोबाइल और बैकएंड ऐप्स में कैसे बदलते हैं: आवश्यकताएँ, UI फ्लोज़, डेटा मॉडल, APIs, परीक्षण और डिप्लॉयमेंट।
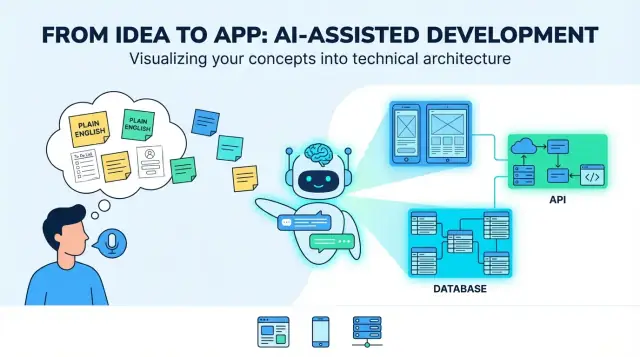
LLM साधारण अंग्रेज़ी प्रोडक्ट आइडियाज़ को वेब, मोबाइल और बैकएंड ऐप्स में कैसे बदलते हैं: आवश्यकताएँ, UI फ्लोज़, डेटा मॉडल, APIs, परीक्षण और डिप्लॉयमेंट।
एक "साधारण अंग्रेज़ी प्रोडक्ट आइडिया" अक्सर इरादे और आशा का मिश्रण होता है: किसके लिए है, कौन सी समस्या हल करता है, और सफलता कैसी दिखेगी। यह कुछ वाक्य हो सकते हैं (“कुत्ते निकलवाने वालों के लिए शेड्यूलिंग ऐप”), एक मोटा वर्कफ़्लो (“ग्राहक अनुरोध → वॉकर स्वीकार करता है → भुगतान”), और कुछ अनिवार्यताएँ (“पुश नोटिफिकेशन, रेटिंग्स”)। यह आइडिया की बातचीत के लिए पर्याप्त है—लेकिन लगातार बनाने के लिए काफी नहीं।
जब लोग कहते हैं कि एक LLM किसी आइडिया को "अनुवाद" कर सकता है, तो उपयोगी मतलब यह है: धुंधले लक्ष्य को ठोस, परखने योग्य निर्णयों में बदलना। "अनुवाद" सिर्फ री‑राइट नहीं है—यह संरचना जोड़ना है ताकि आप समीक्षा, चुनौती और कार्यान्वयन कर सकें।
LLM कोर बिल्डिंग ब्लॉक्स के पहले ड्राफ्ट में तेज़ होते हैं:
आम तौर पर “अंतिम परिणाम” एक फुल‑स्टैक प्रोडक्ट के ब्लूप्रिंट जैसा दिखता है: वेब UI, मोबाइल UI, बैकएंड सर्विसेज (ऑथ, बिज़नेस लॉजिक, नोटिफिकेशन) और डेटा स्टोरेज (डाटाबेस + फाइल/मीडिया स्टोरेज)।
LLM आपके प्रोडक्ट के ट्रेड‑ऑफ का भरोसेमंद चुनाव नहीं कर सकता, क्योंकि सही उत्तर उस संदर्भ पर निर्भर करते हैं जो आपने शायद नहीं लिखा:
मॉडल को विकल्प और डिफ़ॉल्ट्स प्रस्तावित करने वाला समझें—अंतिम सत्य नहीं।
सबसे बड़े फेल्योर मोड अनुमानित हैं:
"अनुवाद" का असली लक्ष्य मान्यताओं को दिखाई देने योग्य बनाना है—ताकि आप उन्हें कोड में बढ़ने से पहले पुष्टि, संशोधित या खारिज कर सकें।
LLM को "मुझसे X के लिए ऐप बनाओ" से स्क्रीन, APIs और डेटा मॉडल में बदलने से पहले आपको एक पर्याप्त विशिष्ट प्रोडक्ट ब्रिफ चाहिए। यह चरण धुंधले इरादे को साझा लक्ष्य में बदलने के बारे में है।
समस्या बयान एक या दो वाक्य में लिखें: कौन संघर्ष कर रहा है, किसके साथ, और क्यों यह मायने रखता है। फिर प्रेक्षणीय सफलता मेट्रिक्स जोड़ें।
उदाहरण: “क्लिनिक के लिए फ़ॉलो‑अप अपॉइंटमेंट शेड्यूल करने का समय कम करें।” मेट्रिक्स हो सकते हैं औसत शेड्यूलिंग समय, नॉ‑शो दर, या % मरीज जो सेल्फ‑सर्व से बुक करते हैं।
मुख्य उपयोगकर्ता प्रकार सूचीबद्ध करें (न कि हर कोई जो सिस्टम छू सकता है)। प्रत्येक के लिए एक शीर्ष कार्य और छोटा परिदृश्य दें।
एक उपयोगी प्रॉम्प्ट टेम्पलेट: “As a [role], I want to [do something] so that [benefit].” लक्ष्य 3–7 कोर उपयोग‑केसेस के लिए रखें जो MVP को परिभाषित करें।
प्रतिबंध एक साफ‑प्रोटोटाइप और शिपेबल प्रोडक्ट के बीच का फर्क होते हैं। शामिल करें:
पहली रिलीज़ में क्या है और क्या टाला गया है, इसे स्पष्ट करें। एक सरल नियम: MVP फीचर को प्राथमिक उपयोग‑केसेस को एंड‑टू‑एंड सपोर्ट करना चाहिए बिना मैन्युअल वर्कअराउंड के।
यदि चाहें, इसे एक पेज के ब्रिफ के रूप में कैप्चर करें और अगले चरणों (आवश्यकताएँ, UI फ्लोज़, आर्किटेक्चर) के लिए इसे "सोर्स ऑफ़ ट्रुथ" रखें।
एक साधारण‑अंग्रेज़ी आइडिया आम तौर पर लक्ष्य (“लोगों को क्लास बुक करने में मदद करें”), मान्यताएँ (“उपयोगकर्ता लॉग इन करेंगे”), और अस्पष्ट स्कोप (“इसे सरल बनाओ”) का मिश्रण होता है। LLM यहां उपयोगी है क्योंकि यह गंदे इनपुट को समीक्ष्य आवश्यकताओं में बदल सकता है जिन्हें आप सुधार और मंज़ूरी दे सकें।
प्रत्येक वाक्य को युज़र स्टोरी के रूप में लिखना शुरू करें। इससे स्पष्ट होता है कौन क्या चाहता है और क्यों:
यदि कोई स्टोरी उपयोगकर्ता प्रकार या लाभ नहीं बताती, तो वह शायद अभी भी बहुत अस्पष्ट है।
फिर स्टोरीज़ को फीचर्स में समूहित करें, और हर एक को must‑have या nice‑to‑have लेबल दें। इससे डिज़ाइन और इंजीनियरिंग शुरू होने से पहले स्कोप ड्रिफ्ट रोका जाता है।
उदाहरण: “पुश नोटिफिकेशन” आमतौर पर nice‑to‑have हो सकता है, जबकि “बुकिंग रद्द करना” अक्सर must‑have होता है।
हर स्टोरी के नीचे सरल, परखने योग्य नियम जोड़ें। अच्छे स्वीकृति मानदंड विशिष्ट और प्रेक्षणीय होते हैं:
LLM अक्सर “हैप्पी पाथ” पर डिफ़ॉल्ट होता है, इसलिए स्पष्ट रूप से एज‑केस माँगे जैसे:
यह आवश्यकताओं का बंडल वह सोर्स ऑफ़ ट्रुथ बनता है जिसका उपयोग आप बाद के आउटपुट (UI फ्लोज़, APIs और टेस्ट) को आंकने के लिए करेंगे।
एक साधारण‑अंग्रेज़ी आइडिया तब बिल्डेबल बनता है जब वह उपयोगकर्ता यात्राएँ और स्क्रीन जिन्हें स्पष्ट नेविगेशन जोड़ता है में बदल जाता है। इस चरण में आप रंग नहीं चुन रहे—आप यह परिभाषित कर रहे हैं कि लोग क्या कर सकते हैं, किस क्रम में, और सफलता कैसी दिखती है।
सबसे पहले उन पाथ्स की सूची बनाएं जो सबसे ज़्यादा मायने रखते हैं। कई प्रोडक्ट्स के लिए आप इन्हें इस तरह संरचित कर सकते हैं:
मॉडल इन फ्लोज़ को स्टेप‑बाय‑स्टेप सिक्वेंस के रूप में ड्राफ्ट कर सकता है। आपकी जिम्मेदारी यह पुष्टि करना है कि क्या वैकल्पिक है, क्या आवश्यक है, और उपयोगकर्ता कहां सुरक्षित रूप से बाहर निकल और फिर से शुरू कर सकते हैं।
दो आउटपुट माँगे: एक स्क्रीन इन्वेंटरी और एक नेविगेशन मैप।
एक अच्छा आउटपुट स्क्रीन के नाम सुसंगत रखता है (उदा. “Order Details” बनाम “Order Detail”), एंट्री‑पॉइंट्स बताता है, और खाली‑राज्यों (no results, no saved items) को शामिल करता है।
आवश्यकताओं को फ़ॉर्म फ़ील्ड्स में बदलें: आवश्यक/वैकल्पिक, फ़ॉर्मैट, सीमाएँ, और उपयोगकर्ता‑मित्र त्रुटि संदेश। उदाहरण: पासवर्ड नियम, पेमेंट ऐड्रेस फ़ॉर्मैट, या “तारीख भविष्य में होनी चाहिए”। सुनिश्चित करें कि वैलिडेशन इनलाइन (टाइप करते समय) और सबमिट पर दोनों जगह हो।
रिडेबल टेक्स्ट साइज़, स्पष्ट कंट्रास्ट, वेब पर फुल कीबोर्ड सपोर्ट, और त्रुटि संदेश जो बताते हैं कि समस्या कैसे ठीक करें (सिर्फ़ “Invalid input” नहीं)। हर फ़ॉर्म फ़ील्ड का लेबल और फ़ोकस ऑर्डर तार्किक होना चाहिए।
एक "आर्किटेक्चर" ऐप का ब्लूप्रिंट है: कौन‑कौन से भाग हैं, हर भाग की ज़िम्मेदारी क्या है, और वे कैसे संवाद करते हैं। जब LLM आर्किटेक्चर प्रस्ताव करता है, तो आपकी जॉब यह सुनिश्चित करना है कि वह वर्तमान में बनाना आसान और बाद में विकसित करने के लिए स्पष्ट हो।
अधिकांश नए प्रोडक्ट्स के लिए एकल बैकएंड (मोनोलिथ) सही शुरुआती विकल्प है: एक कोडबेस, एक डिप्लॉयमेंट, एक डेटाबेस। इसे बनाना तेज़ है, डिबग करना आसान है, और ऑपरेट करना सस्ता है।
एक मॉड्यूलर मोनोलिथ अक्सर मधुर संतुलन होता है: अभी भी एक डिप्लॉय, लेकिन मॉड्यूल (Auth, Billing, Projects इत्यादि) से व्यवस्थित और स्पष्ट सीमाएँ। तब सेवा विभाजन तब करें जब असली दबाव हो—जैसे भारी ट्रैफिक, अलग‑अलग टीमों की स्वतंत्र डिप्लॉय की ज़रूरत, या कोई हिस्सा अलग पैमाने पर स्केल करना।
यदि मॉडल तुरंत “माइक्रोसर्विसेज” सुझाता है, तो उससे ठोस जरूरतों के साथ जस्टिफिकेशन माँगे, न कि भविष्य‑अनुमानों के साथ।
एक अच्छा आर्किटेक्चर आउटलाइन अनिवार्य चीज़ों को नाम देता है:
मॉडल को यह भी निर्दिष्ट करना चाहिए कि हर हिस्सा कहाँ रहता है (बैकएंड बनाम मोबाइल बनाम वेब) और क्लाइंट्स बैकएंड से कैसे इंटरैक्ट करेंगे (आम तौर पर REST या GraphQL)।
आर्किटेक्चर अस्पष्ट बने रहता है जब तक आप बेसिक्स पिन नहीं करते: बैकएंड फ्रेमवर्क, डेटाबेस, होस्टिंग, और मोबाइल दृष्टिकोण (नेटिव बनाम क्रॉस‑प्लैटफ़ॉर्म)। मॉडल से इन्हें “मान्यताएँ” के रूप में लिखवाएँ ताकि सभी जानते कि किस पर डिज़ाइन किया जा रहा है।
बड़े री‑राइट्स के जगह छोटे "एस्केप हैचेज" पसंद करें: हॉट रीड्स के लिए कैशिंग, बैकग्राउंड जॉब्स के लिए कतार, और स्टेटलेस ऐप सर्वर ताकि आप बाद में और इंस्टेन्स जोड़ सकें। सर्वश्रेष्ठ आर्किटेक्चर प्रस्ताव सरल v1 रखते हुए विकल्पों की व्याख्या करते हैं।
एक प्रोडक्ट आइडिया अक्सर संज्ञाओं से भरा होता है: “users,” “projects,” “tasks,” “payments,” “messages.” डेटा मॉडलिंग वह चरण है जहाँ LLM उन संज्ञाओं को साझा तस्वीर में बदलता है कि ऐप क्या स्टोर करेगा—और अलग‑अलग चीज़ें कैसे जुड़ेंगी।
कुंजी इकाइयों की सूची से शुरू करें और पूछें: किसका क्या है?
उदाहरण:
फिर रिश्तों और प्रतिबंधों को परिभाषित करें: क्या टास्क किसी प्रोजेक्ट के बिना मौजूद रह सकता है, क्या टिप्पणियाँ संपादित हो सकती हैं, क्या प्रोजेक्ट आर्काइव हो सकता है, और प्रोजेक्ट डिलीट होने पर टास्क के साथ क्या होता है।
अगला कदम मॉडल से पहला‑पास स्कीमा पूछना है (SQL टेबल या NoSQL कलेक्शन्स)। इसे सरल रखें और उन निर्णयों पर ध्यान दें जो व्यवहार प्रभावित करते हैं।
एक सामान्य ड्राफ्ट में शामिल हो सकता है:
महत्वपूर्ण: “status” फ़ील्ड्स, टाइमस्टैम्प और यूनिक प्रतिबंध जल्दी पकड़ लें (जैसे यूनिक ईमेल)। ये विवरण UI फ़िल्टर, नोटिफिकेशन और रिपोर्टिंग को आगे चलकर प्रभावित करते हैं।
अधिकांश असली ऐप्स को स्पष्ट नियम चाहिए कि कौन क्या देख सकता है। LLM को स्वामित्व स्पष्ट करना चाहिए (owner_user_id) और एक्सेस मॉडल (memberships/roles) को मॉडल करना चाहिए। मल्टी‑टेनेंट प्रोडक्ट्स के लिए एक tenant/organization इकाई और tenant_id जोड़ें जहाँ आवश्यक हो।
साथ ही परिभाषित करें कि अनुमतियाँ कैसे लागू की जाएँगी: रोल द्वारा (admin/member/viewer), स्वामित्व द्वारा, या दोनों द्वारा।
अंत में निर्णय लें कि क्या लॉग किया जाना चाहिए और क्या हटाया जाना चाहिए। उदाहरण:
ये चुनाव अनुपालन, सपोर्ट या बिलिंग प्रश्नों के आने पर अप्रिय आश्चर्य से बचाते हैं।
बैकएंड APIs वे जगह हैं जहाँ आपका ऐप वादों को वास्तविक क्रियाओं में बदलता है: “मेरी प्रोफ़ाइल सेव करो”, “मे ऑर्डर्स दिखाओ”, “लिस्टिंग खोजो”। एक अच्छा आउटपुट उपयोगकर्ता क्रियाओं से शुरू होकर स्पष्ट एंड‑पॉइंट्स का सेट बनाता है।
मुख्य चीज़ें सूचीबद्ध करें जिनसे उपयोगकर्ता इंटरैक्ट करते हैं (उदा. Projects, Tasks, Messages)। हर एक के लिए परिभाषित करें कि उपयोगकर्ता क्या कर सकते हैं:
यह आमतौर पर एंड‑पॉइंट्स जैसे मैप होता है:
POST /api/v1/tasks (create)GET /api/v1/tasks?status=open&q=invoice (list/search)GET /api/v1/tasks/{taskId} (read)PATCH /api/v1/tasks/{taskId} (update)DELETE /api/v1/tasks/{taskId} (delete)एक टास्क बनाएँ: उपयोगकर्ता शीर्षक और नियत तारीख सबमिट करता है।
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
रिस्पॉन्स सहेजे गए रिकॉर्ड को लौटाता है (सर्वर‑जनरेटेड फ़ील्ड्स सहित):
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
(ऊपर के कोड ब्लॉक्स को जैसा दिया गया है वैसे ही रखें — इन्हें अनुवादित न करें।)
मॉडल को सुसंगत एरर्स उत्पन्न करने के लिए कहें:
रिट्राई के लिए, POST पर idempotency keys पसंद करें और स्पष्ट गाइड दें जैसे “retry after 5 seconds.”
मोबाइल क्लाइंट धीरे‑धीरे अपडेट होते हैं। एक वर्जन्ड बेस पाथ (/api/v1/...) इस्तेमाल करें और ब्रेकिंग बदलाव से बचें:
GET /api/version)सुरक्षा "बाद में" का काम नहीं है। जब LLM आपके आइडिया को ऐप स्पेक्स में बदल रहा है, तो आप चाहते हैं कि सुरक्षित डिफ़ॉल्ट स्पष्ट हों—ताकि पहली जनरेटेड वर्ज़न गलती से दुरुपयोग के लिए खुला न हो।
मॉडल से प्राथमिक लॉगिन तरीका और एक बैकअप सुझवाएँ, साथ में क्या होगा जब चीज़ें गलत हों (एक्सेस खोना, संदिग्ध लॉगिन)। सामान्य विकल्प:
सत्र हैंडलिंग निर्दिष्ट कराएँ (शॉर्ट‑लाइव्ड एक्सेस टोकन, रिफ्रेश टोकन, डिवाइस लॉगआउट) और यह बताएं कि आप MFA सपोर्ट करना चाहते हैं या नहीं।
ऑथेंटिकेशन उपयोगकर्ता की पहचान बताता है; ऑरॉराइज़ेशन पहुंच को सीमित करता है। मॉडल को एक स्पष्ट पैटर्न चुनने के लिए कहें:
project:edit, invoice:export) फ्लेक्सिबल प्रोडक्ट्स के लिएएक अच्छा आउटपुट उदाहरण नियम देगा जैसे: “केवल प्रोजेक्ट ओनर प्रोजेक्ट डिलीट कर सकते हैं; collaborators संपादित कर सकते हैं; viewers टिप्पणी कर सकते हैं।”
मॉडल से ठोस सुरक्षा उपायों की सूची माँगें, न कि सामान्य वादे:
और बेसलाइन थ्रेट चेकलिस्ट माँगें: CSRF/XSS सुरक्षा, सिक्योर कुकीज, और सुरक्षित फ़ाइल अपलोड्स यदि लागू हों।
मूल रूप से न्यूनतम डेटा कलेक्शन रखें: सिर्फ़ वही जो फीचर के लिए सचमुच चाहिए, और जितना कम समय ज़रूरी हो उतना रखें।
मॉडल से साधारण भाषा में पॉलिसी ड्राफ्ट करवाएँ:
अगर आप एनालिटिक्स जोड़ते हैं, तो ऑप्ट‑आउट (या आवश्यक होने पर ऑप्ट‑इन) सुनिश्चित करें और इसे सेटिंग्स और पॉलिसी पेजों में स्पष्ट रूप से डॉक्यूमेंट करें।
एक अच्छा LLM आपकी आवश्यकताओं को टेस्ट प्लान में बदल सकता है जो चौंका देने kadar उपयोगी हो सकता है—बशर्ते आप इसे हर चीज़ को Acceptance Criteria से जोड़ने के लिए मजबूर करें।
मॉडल को अपनी फीचर लिस्ट और स्वीकृति मानदंड दें, फिर उससे हर मानदंड के लिए टेस्ट जनरेट करने के लिए कहें। एक ठोस आउटपुट में शामिल होना चाहिए:
यदि कोई टेस्ट किसी विशिष्ट मानदंड से नहीं जुड़ता, तो वह शायद शोर है।
LLM फेर भी ऐसे फिक्सचर सुझा सकता है जो असली उपयोग के मामलों को प्रतिबिंबित करते हैं: गन्दा नाम, गायब फ़ील्ड, टाइमज़ोन, लंबा टेक्स्ट, और “लगभग डुप्लिकेट” रिकॉर्ड।
माँगे:
मॉडल से डेडिकेटेड मोबाइल चेकलिस्ट जोड़वाएँ:
LLM टेस्ट स्केलेटन लिखने में तेज़ है, पर आप समीक्षा करें:
मॉडल को फास्ट टेस्ट लेखक मानें—not अंतिम QA साइन‑ऑफ।
मॉडल बहुत सारा कोड जेनरेट कर सकता है, पर उपयोगकर्ताओं को तब ही लाभ होगा जब वह सुरक्षित रूप से शिप हो और आप लाँच के बाद क्या हो रहा है देख सकें। यह चरण रेपेटेबल रिलीज़ के बारे में है: हर बार वही स्टेप्स, कम से कम सरप्राइज के साथ।
एक साधारण CI पाइपलाइन सेट करें जो हर пул रिक्वेस्ट पर और मेन ब्रांच पर मर्ज पर चले:
भले ही LLM ने कोड लिखा हो, CI आपको बताता है कि परिवर्तन के बाद क्या चीजें अभी भी काम करती हैं।
तीन वातावरण उपयोग करें और स्पष्ट उद्देश्यों के साथ:
कन्फ़िगरेशन एनवायरनमेंट वेरिएबल्स और सीक्रेट्स के माध्यम से होनी चाहिए (हार्ड‑कोड न करें)। नियम: यदि किसी मान को बदलने के लिए कोड बदलना पड़ता है, तो वह शायद गलत तरह से कॉन्फ़िगर किया गया है।
एक सामान्य फुल‑स्टैक ऐप के लिए:
तीन सिग्नल की योजना बनाएं:
यहाँ AI‑सहायता वाले विकास का ऑपरेशनल पक्ष आता है: आप सिर्फ़ कोड जेनरेट नहीं कर रहे—आप एक प्रोडक्ट चला रहे हैं।
LLM एक अस्पष्ट विचार को ऐसा कुछ बना सकता है जो एक पूर्ण योजना जैसा दिखता है—लेकिन पॉलिश्ड प्रॉज़ अक्सर गैप छिपा सकते हैं। सबसे आम फेल्योर अनुमानित हैं, और आप कुछ दोहराने‑योग्य आदतों से उन्हें रोक सकते हैं।
कमज़ोर आउटपुट अक्सर चार मुद्दों से होते हैं:
मॉडल को काम करने के लिए ठोस सामग्री दें:
प्रत्येक डिलीवेरेबल के लिए चेकलिस्ट माँगे। उदाहरण के लिए, आवश्यकताएँ तब "डन" मानी जाएँ जब उनमें स्वीकृति मानदंड, एरर स्टेट्स, रोल्स/परमिशन, और मापनीय सफलता मेट्रिक्स शामिल हों।
LLM आउटपुट तब भटकते हैं जब स्पेक्स, API नोट्स, और UI आइडियाज़ अलग-अलग थ्रेड्स में होते हैं। एक जीवित डॉक (साधारण markdown फ़ाइल) रखें जो लिंक करे:
जब आप फिर से प्रॉम्प्ट करें, तो लेटेस्ट अंश पेस्ट करें और कहें: “केवल सेक्शन्स X और Y अपडेट करो; बाकी सब वही रखें।”
यदि आप इम्प्लिमेंट कर रहे हैं, तो ऐसा वर्कफ़्लो इस्तेमाल करें जो क्विक इटरेशन का समर्थन करता हो बिना ट्रेसबिलिटी खोए। उदाहरण के लिए, Koder.ai का “planning mode” यहां फिट हो सकता है: आप स्पेक लॉक कर सकते हैं (मान्यताएँ, खुले प्रश्न, स्वीकृति मानदंड), वेब/मोबाइल/बैकएंड स्कैफोल्डिंग एक ही चैट थ्रेड से जनरेट कर सकते हैं, और स्नैपशॉट/रोलबैक पर भरोसा कर सकते हैं यदि किसी बदलाव ने रिग्रेशन भीज दिया। स्रोत कोड एक्सपोर्ट तब ख़ास उपयोगी होता है जब आप चाहते हैं कि जेनरेटेड आर्किटेक्चर और आपका रेपो सुसंगत रहें।
यहाँ "LLM अनुवाद" का एक एंड‑टू‑एंड उदाहरण है—साथ ही चेकपॉइंट्स जहाँ इंसान को धीमा होना चाहिए और वास्तविक निर्णय लेने चाहिए।
साधारण‑अंग्रेज़ी आइडिया: “एक पेट‑सिटिंग मार्केटप्लेस जहाँ मालिक पोस्ट करते हैं, सिटर आवेदन करते हैं, और भुगतान नौकरी के पूरा होने के बाद रिलीज़ होता है।”
एक LLM इसे पहले ड्राफ्ट में बदल सकता है जैसे:
POST /requests, GET /requests/{id}, POST /requests/{id}/apply, GET /requests/{id}/applications, POST /messages, POST /checkout/session, POST /jobs/{id}/complete, POST /reviews.यह उपयोगी है—पर यह "डन" नहीं है। यह एक संरचित प्रस्ताव है जिसे मान्य करने की ज़रूरत है।
प्रोडक्ट निर्णय: "एक आवेदन" को कौन वैध मानता है? क्या मालिक सीधे किसी सिटर को निमंत्रण दे सकता है? कब एक रिक्वेस्ट को "filled" माना जाता है? ये नियम हर स्क्रीन और API को प्रभावित करते हैं।
सुरक्षा और गोपनीयता समीक्षा: रोल‑आधारित एक्सेस कन्फर्म करें (मालिक दूसरे मालिकों की चैट नहीं पढ़ सकते), पेमेंट्स सुरक्षित करें, और डेटा रिटेंशन परिभाषित करें (उदा. चैट X महीनों बाद हटाएँ)। दुरुपयोग नियंत्रण जोड़े: रेट‑लिमिट्स, स्पैम रोकथाम, ऑडिट लॉग्स।
परफ़ॉर्मेंस ट्रेड‑ऑफ: तय करें क्या तेज़ और स्केलेबल होना चाहिए (सर्च/फिल्टर, चैट)। यह कैशिंग, पेजिनेशन, इंडेक्सिंग और बैकग्राउंड जॉब्स को प्रभावित करता है।
पायलट के बाद, उपयोगकर्ता कह सकते हैं “रिक्वेस्ट दोहराएँ” या “आंशिक रिफंड के साथ रद्द करें” जैसी माँगें। उसे अपडेटेड आवश्यकताओं के रूप में फीड करें, प्रभावित फ्लोज़ को री‑जनरेट या पैच करें, फिर टेस्ट और सुरक्षा चेक्स दोबारा चलाएँ।
“क्यों” कैप्चर करें, सिर्फ़ “क्या” नहीं: मुख्य बिज़नेस नियम, परमिशन मैट्रिक्स, API कॉन्ट्रैक्ट्स, एरर कोड्स, DB माइग्रेशंस, और रिलीज़/इंसिडेंट‑रिस्पॉन्स का शॉर्ट रनबुक। यही चीज़ जेनरेटेड कोड को छह महीने बाद समझने योग्य रखती है।
इस संदर्भ में “अनुवाद” का मतलब है एक अस्पष्ट विचार को विशिष्ट, परखने योग्य निर्णयों में बदलना: रोल, उपयोगकर्ता यात्राएँ, आवश्यकताएँ, डेटा, APIs, और सफलता के मानदंड।
यह सिर्फ पैराफ्रेज़ करना नहीं है—यह मान्यताओं को स्पष्ट करना है ताकि आप उन्हें बनाने से पहले स्वीकृत या अस्वीकार कर सकें।
एक व्यावहारिक प्रथम पास में शामिल होता है:
इसे एक ड्राफ्ट ब्लूप्रिंट समझें जिसे आप समीक्षा करेंगे—यह अंतिम स्पेक नहीं है।
क्योंकि LLM आपके वास्तविक दुनिया के प्रतिबंधों और ट्रेड‑ऑफ को बिना बताए भरोसेमंद रूप से नहीं जान सकता, इसलिए कुछ निर्णयों के लिए इंसान ज़रूर चाहिए। उदाहरण:
मॉडल विकल्प और डिफ़ॉल्ट प्रस्ताव कर सकता है—फैसला इंसान को लेना चाहिए।
ऐसा प्रॉडक्ट ब्रिफ बनाएं जिसे डिजाइन के लिए पर्याप्त संदर्भ मिल सके:
अगर आप इसे किसी सहकर्मी को नहीं दे सकते जिसपर वही व्याख्या निकले, तो ब्रिफ अभी तैयार नहीं है।
लक्ष्यों को युज़र स्टोरीज़ + स्वीकृति मानदंड में बदलकर रखें। एक मजबूत पैकेज में आम तौर पर शामिल हैं:
यह UI, API और टेस्ट के लिए आपका “सोर्स ऑफ़ ट्रथ” बन जाता है।
दो डिलिवरेबल माँगे:
फिर सत्यापित करें:
अधिकांश v1 उत्पादों के लिए डिफ़ॉल्ट शुरुआत: मोनोलिथ या मॉड्यूलर मोनोलिथ।
यदि मॉडल तुरंत “माइक्रोसर्विसेज” सुझाव दे, तो उसकी वजह माँगें (यानी ट्रैफिक, स्वतंत्र डिप्लॉय की ज़रूरत)। वर्जित ओवर‑इंजीनियरिंग की जगह "एस्केप हैचेज" पसंद करें:
v1 को जल्दी शिप करने योग्य और डिबग करने में आसान रखें।
मॉडल से यह स्पष्ट कराएँ कि वह क्या निर्देश मानकर डेटा मॉडल बना रहा है:
डेटा निर्णय UI फिल्टर, नोटिफिकेशन, रिपोर्टिंग और सुरक्षा को प्रभावित करते हैं।
उपयोगकर्ताओं की क्रियाओं से शुरू करें → CRUD + सर्च
प्रत्येक मुख्य ऑब्जेक्ट (Projects, Tasks, Messages इत्यादि) के लिए परिभाषित करें कि उपयोगकर्ता क्या कर सकते हैं और फिर उसे एंडपॉइंट्स में मैप करें, उदाहरण:
मॉडल को Acceptance Criteria के हिसाब से टेस्ट प्लान बनवाएँ:
और री‑यूज़ेबल फिक्सचर, टाइमज़ोन, लंबा टेक्स्ट, प्रायः मेल खाने वाले रिकॉर्ड और अनिश्चित नेटवर्क जैसी परिस्थितियाँ शामिल करें। जनरेट किए गए टेस्टों को शुरुआती बिंदु मानें, अंतिम QA नहीं।
आप व्यवहार डिजाइन कर रहे हैं, दृश्य नहीं।
POST /api/v1/tasks (create)GET /api/v1/tasks?status=open&q=invoice (list/search)GET /api/v1/tasks/{taskId} (read)PATCH /api/v1/tasks/{taskId} (update)DELETE /api/v1/tasks/{taskId} (delete)सुनिश्चित करें कि अनुरोध/प्रतिक्रिया के उदाहरण, त्रुटि स्वरूप और idempotency की सिफारिशें हों।