23 दिस॰ 2025·8 मिनट
ग्राहक सेगमेंटेशन और कोहोर्ट विश्लेषण के लिए वेब ऐप कैसे बनाएं
ग्राहक सेगमेंटेशन और कोहोर्ट विश्लेषण के लिए वेब ऐप बनाने का व्यावहारिक कदम‑दर‑कदम मार्गदर्शक: डेटा मॉडल, पाइपलाइन्स, UI, मैट्रिक्स और तैनाती।
ग्राहक सेगमेंटेशन और कोहोर्ट विश्लेषण के लिए वेब ऐप बनाने का व्यावहारिक कदम‑दर‑कदम मार्गदर्शक: डेटा मॉडल, पाइपलाइन्स, UI, मैट्रिक्स और तैनाती।
टेबल डिजाइन करने या टूल चुनने से पहले यह स्पष्ट करें कि ऐप किन सवालों के जवाब देनी चाहिए। “सेगमेंटेशन और कोहोर्ट” कई अर्थ रखता है; स्पष्ट उपयोग‑मामले आपको ऐसा प्रोडक्ट बनाने से बचाते हैं जो फीचर-रिच है पर निर्णय लेने में मदद नहीं करता।
शुरू करें कि लोग कौन‑से सटीक निर्णय लेना चाहते हैं और वे किन नंबरों पर भरोसा करते हैं। सामान्य प्रश्न:
प्रत्येक प्रश्न के लिए समय विंडो (daily/weekly/monthly) और ग्रैन्यूलैरिटी (user, account, subscription) नोट करें। यह बाकी बिल्ड को संरेखित रखता है।
प्राथमिक उपयोगकर्ताओं और उनके वर्कफ़्लो पहचानें:
व्यवहारिक जरूरतें भी कैप्चर करें: वह कितनी बार डैशबोर्ड देखते हैं, उनके लिए “one click” का अर्थ क्या है, और कौन सा डेटा वे अधिकारिक मानते हैं।
एक न्यूनतम व्यवहार्य संस्करण परिभाषित करें जो टॉप 2–3 प्रश्नों का विश्वसनीय उत्तर दे। सामान्य MVP स्कोप: कोर सेगमेंट, कुछ कोहोर्ट व्यू (रिटेंशन, राजस्व), और शेयर करने योग्य डैशबोर्ड।
"नाइस‑टू‑हैव" आइटम बाद के लिए रखें, जैसे scheduled exports, alerts, automations, या जटिल मल्टी‑स्टेप सेगमेंट लॉजिक।
यदि फर्स्ट‑वर्जन की स्पीड महत्वपूर्ण है, तो MVP के लिए किसी वाइब‑कोडिंग प्लेटफ़ॉर्म जैसे Koder.ai से स्कैफ़ोल्ड करना विचार करें। आप चैट में सेगमेंट बिल्डर, कोहोर्ट हीटमैप और बेसिक ETL आवश्यकताओं का वर्णन कर सकते हैं और एक कार्यशील React फ्रंटेंड साथ ही Go + PostgreSQL बैकएंड जेनरेट कर सकते हैं—फिर stakeholders के परिभाषाएँ फ़ाइन‑ट्यून करने पर planning mode, snapshots और rollback के साथ iterate कर सकते हैं।
सफलता मापनीय होनी चाहिए। उदाहरण:
जब ट्रेड‑ऑफ़ आएं तो ये मैट्रिक्स आपका नॉर्थ‑स्टार होंगे।
स्क्रीन डिजाइन करने या ETL जॉब लिखने से पहले तय करें कि आपकी प्रणाली में “एक ग्राहक” और “एक क्रिया” क्या मतलब रखती है। कोहोर्ट और सेगमेंटेशन के परिणाम उन्हीं परिभाषाओं जितने भरोसेमंद होंगे।
एक प्राथमिक पहचानकर्ता चुनें और दस्तावेज़ करें कि बाकी कैसे मैप होते हैं:
पहचान स्टिचिंग के बारे में स्पष्ट रहें: आप anonymous और known प्रोफाइल्स कब मर्ज करते हैं, और यदि कोई उपयोगकर्ता कई खातों से जुड़ा हो तो क्या होता है।
पहले उन स्रोतों के साथ शुरू करें जो आपके उपयोग‑मामलों का उत्तर देते हैं, फिर आवश्यकता अनुसार और जोड़ें:
प्रत्येक स्रोत के लिए रिकॉर्ड का सिस्टम और रिफ्रेश कैडेंस (real‑time, hourly, daily) नोट करें ताकि बाद में “क्यों नंबर मैच नहीं करते?” विवाद न हों।
रिपोर्टिंग के लिए एक एकल टाइमज़ोन सेट करें (अक्सर बिज़नेस टाइमज़ोन या UTC) और परिभाषित करें कि “दिन”, “सप्ताह” और “महीना” का क्या अर्थ है (ISO वीक बनाम रविवार‑स्टार्ट वीक)। यदि आप राजस्व संभालते हैं, तो करेंसी नियम चुनें: स्टोर्ड करेंसी, रिपोर्टिंग करेंसी, और एक्सचेंज‑रेट का समय।
सादा भाषा में परिभाषाएँ लिखें और हर जगह पुनः उपयोग करें:
इस ग्लॉसरी को एक प्रोडक्ट रिक्वायरमेंट की तरह ट्रीट करें: यह UI में दिखाई दे और रिपोर्ट्स में संदर्भित हो।
एक सेगमेंटेशन ऐप अपनी डेटा मॉडल पर जीवित रहता है या मरता है। अगर एनालिस्ट सामान्य प्रश्न सरल क्वेरी से उत्तर नहीं दे सकते, तो हर नया सेगमेंट कस्टम इंजीनियरिंग काम बन जाएगा।
ट्रैक किए जाने वाले हर इवेंट के लिए एक सुसंगत इवेंट संरचना उपयोग करें। एक व्यावहारिक बेसलाइन:
event_name (उदा., signup, trial_started, invoice_paid)timestamp (UTC में स्टोर करें)user_id (कृत्यकर्ता)properties (JSON लचीले विवरणों के लिए जैसे utm_source, device, feature_name)event_name को नियंत्रित रखें (एक परिभाषित सूची), और properties को लचीला रखें—पर अपेक्षित कीज़ दस्तावेज़ करें। इससे रिपोर्टिंग के लिए स्थिरता मिलती है बिना प्रोडक्ट बदलावों को अवरुद्ध किए।
सेगमेंटेशन ज्यादातर "उपयोगकर्ताओं/खातों को एट्रिब्यूट्स से फिल्टर करना" है। उन एट्रिब्यूट्स को समर्पित तालिकाओं में रखें बजाय केवल इवेंट प्रॉपर्टीज में डालने के।
सामान्य एट्रिब्यूट्स:
यह गैर‑विशेषज्ञों को ऐसे सेगमेंट बनाने देता है जैसे “SMB users in EU on Pro acquired via partner” बिना कच्चे इवेंट्स में खोज किए।
कई एट्रिब्यूट समय के साथ बदलते हैं—खासतौर पर प्लान। यदि आप केवल user/account रिकॉर्ड पर वर्तमान प्लान स्टोर करते हैं, तो ऐतिहासिक कोहोर्ट परिणाम drift करेंगे।
दो सामान्य पैटर्न:
account_plan_history(account_id, plan, valid_from, valid_to)क्वेरी स्पीड बनाम स्टोरेज और जटिलता के आधार पर जानबूझकर चुनें।
एक सरल, क्वेरी‑फ्रेंडली कोर मॉडल है:
user_id, account_id, event_name, timestamp, properties)user_id, created_at, region, आदि)account_id, plan, industry, आदि)यह संरचना ग्राहक सेगमेंटेशन और कोहोर्ट/रिटेंशन विश्लेषण दोनों के लिए साफ़‑साफ़ मैप होती है, और जैसे‑जैसे आप और उत्पाद, टीमें और रिपोर्टिंग जोड़ते हैं, स्केल कर सकती है।
कोहोर्ट विश्लेषण केवल उतना ही भरोसेमंद है जितनी इसकी नियमावली। UI बनाना या क्वेरी ऑप्टिमाइज़ करने से पहले उन सटीक परिभाषाओं को लिख दें जिनका ऐप उपयोग करेगा ताकि हर चार्ट और एक्सपोर्ट अपेक्षित परिणाम दे।
शुरू में यह तय करें कि आपके प्रोडक्ट को कौन‑से कोहोर्ट प्रकार चाहिए। सामान्य विकल्प:
प्रत्येक प्रकार को एक स्पष्ट anchor event (और कभी‑कभी एक property) से मैप करें, क्योंकि वही एंकर कोहोर्ट सदस्यता तय करता है। तय करें कि मेंबरशिप immutable है (एक बार असाइन होने पर कभी न बदले) या इतिहास सही होने पर बदल सकती है।
फिर तय करें कि आप कोहोर्ट इंडेक्स कैसे गणना करेंगे (जैसे कॉलम: week 0, week 1 …)। ये नियम स्पष्ट करें:
छोटी‑छोटी चॉइसेज़ भी संख्याओं को इस तरह हिला सकती हैं कि "क्यों मेल नहीं खा रहा" जैसी चर्चाएँ शुरू हो जाती हैं।
परिभाषित करें कि प्रत्येक कोहोर्ट तालिका का सेल क्या दर्शाता है। सामान्य मैट्रिक्स:
रेट मैट्रिक्स के लिए डिनॉमिनेटर भी निर्दिष्ट करें (उदा., retention rate = week N में सक्रिय उपयोगकर्ता ÷ cohort size at week 0)।
कोहोर्ट किनारों पर जटिल हो जाते हैं। नियम तय करें:
इन फैसलों को सादा भाषा में दस्तावेज़ करें; भविष्य की आप और आपके उपयोगकर्ता धन्यवाद कहेंगे।
आपका सेगमेंटेशन और कोहोर्ट विश्लेषण केवल उतना भरोसेमंद है जितना इनपुट डेटा। एक अच्छी पाइपलाइन डेटा को पहचान योग्य बनाती है: हर दिन समान अर्थ, समान आकार, और सही स्तर की डिटेल।
अधिकांश उत्पाद कई स्रोतों का मिश्रण उपयोग करते हैं ताकि एक इंटीग्रेशन पर टीम्स ब्लॉक न हों:
एक व्यावहारिक नियम: उन "मस्ट‑हैव" इवेंट्स की एक छोटी सेट पर परिभाषा करें जो कोर कोहोर्ट्स को पॉवर करते हैं (उदा., signup, first value action, purchase), फिर विस्तार करें।
इंजेस्ट के जितना करीब संभव वेलिडेशन जोड़ें ताकि खराब डेटा फैल न पाए।
केंद्रित रहें:
जब आप रिकॉर्ड रिजेक्ट या ठीक करें, निर्णय को ऑडिट लॉग में लिखें ताकि आप समझा सकें "क्यों नंबर बदले"।
कच्चा डेटा असंगत होता है। इसे साफ़, संगत एनालिटिक्स तालिकाओं में बदलें:
जॉब्स को शेड्यूल (या स्ट्रीमिंग) पर चलाएं और ऑपरेशनल गार्डरेल्स रखें:
पाइपलाइन को एक उत्पाद की तरह ट्रीट करें: इंस्ट्रूमेंट करें, देखें और इसे बोरिंग‑स्ट्रॉन्ग रखें।
जहाँ आप एनालिटिक्स डेटा स्टोर करते हैं वह तय करेगा कि आपका कोहोर्ट डैशबोर्ड त्वरित महसूस करेगा या धीमा। सही विकल्प डेटा वॉल्यूम, क्वेरी पैटर्न और आवश्यक रिज़ल्ट‑स्पीड पर निर्भर करता है।
कई शुरुआती चरण के उत्पादों के लिए PostgreSQL पर्याप्त होता है: यह परिचित, सस्ता और SQL‑सपोर्टेड है। यह तब बेहतर काम करता है जब आपका इवेंट वॉल्यूम मध्यम हो और आप इंडेक्सिंग व पार्टिशनिंग में सावधान हों।
यदि आप बहुत बड़े इवेंट स्ट्रीम्स (सैंकड़ों मिलियन से अरबों रो) या कई समवर्ती डैशबोर्ड उपयोगकर्ताओं की उम्मीद करते हैं, तो स्केलेबल एनालिटिक्स के लिए डेटा वेयरहाउस (BigQuery, Snowflake, Redshift) या अत्यंत तेज़ आग्रीगेशन के लिए OLAP स्टोर (ClickHouse, Druid) पर विचार करें।
एक व्यावहारिक नियम: यदि "सप्ताह द्वारा रिटेंशन, सेगमेंट से फ़िल्टर" क्वेरी पोस्टग्रेस में ट्यूनिंग के बाद भी सेकंड ले रही है, तो आप वेयरहाउस/OLAP क्षेत्र के करीब हैं।
कच्चे इवेंट्स रखें, लेकिन कुछ एनालिटिक्स‑फ्रेंडली संरचनाएँ जोड़ें:
यह अलगाव आपको कोहोर्ट/सेगमेंट फिर से गणना करने देता है बिना पूरी events तालिका को दोबारा लिखे।
अधिकांश कोहोर्ट क्वेरीज समय, एंटिटी और इवेंट प्रकार से फ़िल्टर करती हैं। प्राथमिकता दें:
(event_name, event_time))\डैशबोर्ड वही आग्रीगेशन बार‑बार करते हैं: कोहोर्ट द्वारा रिटेंशन, सप्ताहवार काउंट्स, सेगमेंट के अनुसार कन्वर्ज़न। इन्हें शेड्यूल पर प्रीकम्प्यूट करें (घंटेवार/दैनिक) ताकि UI कुछ हजार पंक्तियाँ पढ़े—न कि अरबों।
ड्रिल‑डाउन के लिए कच्चा डेटा उपलब्ध रखें, पर आपका डिफ़ॉल्ट अनुभव तेज़ सारांशों पर निर्भर होना चाहिए। यह “आज़़ाद ढंग से एक्सप्लोर करें” और “स्पिनर का इंतज़ार करें” के बीच का फर्क है।
सेगमेंट बिल्डर वहीं है जहाँ सेगमेंटेशन सफल होती है या विफल। अगर वह SQL लिखने जैसा लगेगा, तो ज़्यादातर टीमें इसका उपयोग नहीं करेंगी। आपका लक्ष्य एक “प्रश्न बिल्डर” है जो किसी को यह बताने दे कि वे "कौन" माने बिना यह जाने कि डेटा कैसे स्टोर है।
छोटे नियम सेट से शुरू करें जो वास्तविक प्रश्नों से मेल खाते हों:
हर नियम को dropdowns और फ्रेंडली फ़ील्ड‑नेम्स के साथ एक वाक्य के रूप में रेंडर करें (इंटरनल कॉलम नेम्स छिपाएँ)। जहाँ संभव हो, उदाहरण दिखाएँ (उदा., “Tenure = days since first sign‑in”)।
गैर‑विशेषज्ञ समूहों में सोचते हैं: “US AND Pro AND used Feature X”, और अपवाद जैसे “(US or Canada) and not churned”。इसे पहुंचनीय रखें:
उपयोगकर्ताओं को save segments करने दें जिसमें नाम, विवरण और वैकल्पिक owner/team हो। सेव्ड सेगमेंट्स डैशबोर्ड और कोहोर्ट व्यू में पुनः उपयोग योग्य हों और संस्करणित हों ताकि बदलाव पुराने रिपोर्टों को silently बदल न दें।
हमेशा बिल्डर में ही एक अनुमानित या सटीक segment size दिखाएँ, जो नियम बदलते ही अपडेट हो। यदि आप गति के लिए सैंपलिंग उपयोग करते हैं, तो स्पष्ट रहें:
यह भी दिखाएँ कि क्या शामिल है: “Users counted once” बनाम “events counted”, और बिहेवियरल नियमों के लिए उपयोग की गई समय विंडो।
तुलनाओं को एक फ़र्स्ट‑क्लास विकल्प बनाएं: उसी व्यू में Segment A vs Segment B चुनें (रिटेंशन, कन्वर्ज़न, राजस्व)। उपयोगकर्ताओं को चार्ट डुप्लिकेट करने पर मजबूर न करें।
सरल पैटर्न: एक “Compare to…” सिलेक्टर जो दूसरे सेव्ड सेगमेंट या एक एड‑हॉक सेगमेंट को एक्सेप्ट करे, स्पष्ट लेबल और UI में सुसंगत रंग।
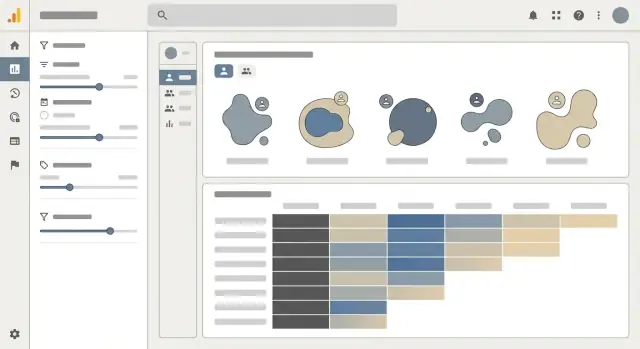
एक कोहोर्ट डैशबोर्ड तब सफल होता है जब वह एक सवाल जल्दी हल कर दे: “क्या हम लोगों को रख रहे हैं (या खो रहे हैं), और क्यों?” UI पैटर्न्स को पैटर्न्स स्पष्ट कर देने चाहिए, फिर रीडर्स को विवरण में ड्रिल‑डाउन करने दें बिना SQL जाने।
कोहोर्ट हीटमैप को मुख्य व्यू के रूप में उपयोग करें, पर इसे रिपोर्ट की तरह लेबल करें—पहेली की तरह नहीं। हर पंक्ति में कोहोर्ट परिभाषा और आकार स्पष्ट रूप से दिखाएँ (उदा., “Week of Oct 7 — 3,214 users”)। हर सेल में retention % और absolute counts के बीच स्विच करने का विकल्प रखें, क्योंकि प्रतिशत पैमाने को छिपाते हैं और काउंट्स दर को छिपाते हैं।
कॉलम हेडर्स सुसंगत रखें (“Week 0, Week 1, Week 2…” या वास्तविक तिथियाँ), और पंक्ति लेबल के पास कोहोर्ट आकार दिखाएँ ताकि रीडर कॉन्फिडेंस जज कर सके।
हर मेर्टिक लेबल पर टूलटिप्स जोड़ें (Retention, Churn, Revenue, Active users) जो बताएं:
एक छोटा टूलटिप एक लंबी हेल्प पेज से बेहतर है; यह निर्णय के क्षण में गलत व्याख्या रोकता है।
हीटमैप के ऊपर सबसे सामान्य फ़िल्टर रखें और उन्हें reversible बनाएं:
सक्रिय फ़िल्टर को चिप्स के रूप में दिखाएँ और एक‑क्लिक “Reset” दें ताकि लोग बेझिझक खोज कर सकें।
वर्तमान व्यू (फ़िल्टर और %/counts सहित) के लिए CSV export दें। शेयर करने योग्य लिंक दें जो कॉन्फ़िगरेशन को संरक्षित करें। शेयरिंग करते समय परमीशन्स लागू करें: लिंक कभी भी दर्शक के अधिकार से अधिक एक्सेस न बढ़ाये।
यदि आप “Copy link” देंगे, तो एक संक्षिप्त कन्फ़र्मेशन और /settings/access का लिंक दिखाएँ जहाँ एक्सेस मैनेज होता है।
सेगमेंटेशन और कोहोर्ट टूल्स अक्सर ग्राहक डेटा को छूते हैं; इसलिए seguridad और प्राइवेसी बाद में सोचने की बात नहीं हैं। इन्हें प्रोडक्ट फीचर्स की तरह ट्रीट करें: यह उपयोगकर्ताओं को सुरक्षित रखता है, सपोर्ट बोझ घटाता है, और स्केल होने पर कंप्लायंस बनाए रखता है।
अपनी ऑडियंस के अनुरूप ऑथेंटिकेशन से शुरू करें (B2B के लिए SSO, SMB के लिए ईमेल/पासवर्ड, या दोनों)। फिर सरल, पूर्वानुमेय रोल लागू करें:
UI और API दोनों पर परमीशन को सुसंगत रखें। अगर कोई endpoint कोहोर्ट डेटा एक्सपोर्ट कर सकता है, तो केवल UI परमीशन पर्याप्त नहीं है—सर्वर‑साइड चेक अनिवार्य हैं।
यदि आपका ऐप कई वर्कस्पेस/क्लाइंट्स सपोर्ट करता है, तो मान लें "कोई दूसरे वर्कस्पेस का डेटा देखना आज़माएगा" और आइसोलेशन के लिए डिज़ाइन करें:
यह आकस्मिक क्रॉस‑टेनेंट लीकेज रोकता है, खासकर जब एनालिस्ट कस्टम फ़िल्टर बनाते हैं।
अधिकांश सेगमेंटेशन और रिटेंशन विश्लेषण बिना कच्चे व्यक्तिगत डेटा के काम करता है। क्या इकट्ठा करना है इसे न्यूनतम रखें:
डेटा को रेस्ट और ट्रांज़िट में एन्क्रिप्ट करें, और सीक्रेट्स (API कीज़, DB क्रेडेंशियल्स) को उचित सीक्रेट्स मैनेजर में रखें।
प्रत्येक वर्कस्पेस के लिए रिटेंशन पॉलिसीज़ परिभाषित करें: कच्चे इवेंट्स, व्युत्पन्न तालिकाएँ और एक्सपोर्ट कितने समय तक रखें। डिलीशन वर्कफ़्लोज़ सुनिश्चित करें कि डेटा वास्तव में हटे:
रिटेंशन और उपयोगकर्ता डिलीशन अनुरोधों के लिए स्पष्ट, दस्तावेजीकृत वर्कफ़्लो कोहोर्ट चार्ट से भी ज़्यादा महत्वपूर्ण है।
एनालिटिक्स ऐप का परीक्षण केवल "पेज लोड होता है या नहीं" नहीं है। आप निर्णय भेज रहे हैं। कोहोर्ट रिटेंशन में एक छोटा सा गणितीय गलती या सेगमेंटेशन में सूक्ष्म फ़िल्टरिंग बग पूरी टीम को गुमराह कर सकता है।
यूनिट टेस्ट्स से शुरू करें जो आपकी कोहोर्ट गणनाएँ और सेगमेंट लॉजिक छोटे, ज्ञात फ़िक्सचर के साथ सत्यापित करें। एक छोटा डेटासेट बनाएं जहाँ "सही उत्तर" स्पष्ट हो (उदा., 10 उपयोगकर्ता सप्ताह 1 में साइन अप, 4 सप्ताह 2 में लौटे → 40% रिटेंशन)। फिर टेस्ट करें:
ये टेस्ट CI में चलने चाहिए ताकि क्वेरी लॉजिक या आग्रीगेशन में हर बदलाव स्वतः जाँच हो।
अधिकांश एनालिटिक्स विफलताएँ डेटा विफलताएँ होती हैं। हर लोड पर या कम से कम दैनिक ऑटोमेटेड चेक जोड़ें:
जब कोई चेक फेल हो, पर्याप्त संदर्भ के साथ अलर्ट करें: कौन सा इवेंट, कौन सा टाइम विंडो, और यह बेसलाइन से कितना विचलित हुआ।
प्रदर्शन टेस्ट चलाएँ जो असली उपयोग के समान हों: बड़े डेट‑रेंज, मल्टीपल फ़िल्टर्स, हाई‑कार्डिनैलिटी प्रॉपर्टीज़ और नेस्टेड सेगमेंट्स। p95/p99 क्वेरी‑टाइम्स ट्रैक करें और बजट लागू करें (उदा., सेगमेंट प्रीव्यू 2s के अंदर, डैशबोर्ड 5s के अंदर)। यदि टेस्ट रिग्रेस करते हैं, तो अगली रिलीज़ से पहले पता चल जाएगा।
अंत में, प्रोडक्ट और मार्केटिंग टीम के साथ यूजर‑एक्सेप्टेंस टेस्टिंग करें। उन "असली प्रश्नों" का सेट इकट्ठा करें जो वे आज पूछते हैं और अपेक्षित उत्तर परिभाषित करें। अगर ऐप भरोसेमंद परिणाम दोहराए बिना या अंतर का कारण बताए बिना भरोसेमंद परिणाम नहीं दे सकता, तो शिप करने के लिए तैयार नहीं है।
आपका सेगमेंटेशन और कोहोर्ट एनालिसिस ऐप लॉन्च एक “बड़ा शुभारंभ” नहीं है, बल्कि एक सुरक्षित लूप सेटअप करने के बारे में है: रिलीज़, ऑब्जर्व, सीखें और सुधारें।
वह रास्ता चुने जो आपकी टीम की स्किल्स और ऐप की ज़रूरतों से मेल खाता हो।
मैनेज्ड होस्टिंग (उदा., प्लेटफ़ॉर्म जो Git से डिप्लॉय करता है) अक्सर तेज़ तरीका है विश्वसनीय HTTPS, रोलबैक और ऑटोसकेलिंग के साथ कम ऑप्स काम के लिए।
कंटेनर तब अच्छा है जब आपको एनवायरनमेंट्स में सुसंगत रनटाइम चाहिए या आप क्लाउड प्रदाताओं के बीच जाना चाहते हैं।
Serverless स्पाइकी उपयोग (उदा., डैशबोर्ड जो मुख्यतः बिज़नेस घंटे में प्रयोग होते हैं) के लिए अच्छा हो सकता है, पर कोल्ड‑स्टार्ट और लंबे ETL जॉब्स का ध्यान रखें।
यदि आप प्रोटोटाइप से प्रोडक्शन तक बिना स्टैक फिर से बनाये जाना चाहते हैं, तो Koder.ai ऐसे प्लेटफ़ॉर्म्स में शामिल है जो ऐप (React + Go + PostgreSQL) जेनरेट करने, डिप्लॉय और होस्ट करने, कस्टम डोमेन अटैच करने और snapshots/rollback का उपयोग कर के iterations के जोखिम को घटाने का रास्ता देते हैं।
dev, staging और production तीन एनवायरनमेंट रखें।
dev और staging में कच्चे ग्राहक डेटा उपयोग करने से बचें। प्रोडक्शन के समान आकार के सेफ़ सैंपल डाटासेट लोड करें (फिल्ड्स, इवेंट प्रकार, एज‑केसेज़ समान) ताकि टेस्टिंग वास्तविक लगे पर प्राइवेसी समस्याएँ न हों।
staging को आपका “ड्रेस रिहर्सल” बनाएं: प्रोडक्शन‑जैसी इंफ्रास्ट्रक्चर, पर अलग क्रेडेंशियल्स, अलग DBs और फीचर फ्लैग्स ताकि नए कोहोर्ट नियम टेस्ट हों।
ट्रैक करें कि क्या टूट रहा है और क्या धीमा हो रहा है:
ETL फेल होने पर, rising error rates या क्वेरी टाइमआउट्स में अचानक स्पाइक पर सिम्पल अलर्ट (ईमेल/Slack) जोड़ें।
नॉन‑एक्सपर्ट उपयोगकर्ताओं से फ़ीडबैक के आधार पर मासिक (या द्वि‑साप्ताहिक) रिलीज़ प्लान करें: भ्रमित करने वाले फ़िल्टर, गुम परिभाषाएँ, या “क्यों यह यूजर इस कोहोर्ट में है?” जैसे प्रश्न।
ऐसे जोड़ों को प्राथमिकता दें जो नए निर्णय अनलॉक करें—नए कोहोर्ट प्रकार, बेहतर UX डिफ़ॉल्ट, और स्पष्ट व्याख्याएँ—बगैर मौजूदा रिपोर्ट्स तोड़े। फीचर फ्लैग्स और वर्ज़न्ड गणनाएँ आपको सुरक्षित तरीके से विकसित करने में मदद करेंगी।
यदि आपकी टीम सार्वजनिक रूप से सीख साझा करती है, तो ध्यान रखें कि कुछ प्लेटफ़ॉर्म (किसी में Koder.ai शामिल) ऐसे प्रोग्राम ऑफर करते हैं जहाँ आप क्रेडिट कमा सकते हैं अपनी बिल्ड के बारे में कंटेंट बनाने या रेफर करने पर—यह उपयोगी है अगर आप तेज़ी से iterate कर रहे हैं और एक्सपेरिमेंटेशन लागत कम रखना चाहते हैं।
शुरुआत उन 2–3 स्पष्ट निर्णयों से करें जिनके लिए ऐप आवश्यक है (उदा., चैनल के हिसाब से सप्ताह-1 रिटेंशन, प्लान के हिसाब से चर्न जोखिम), फिर तय करें:
पहले MVP को उन सवालों का विश्वसनीय उत्तर देने के लिए बनाएं, फिर अलर्ट, ऑटोमेशन या जटिल लॉजिक जोड़ें।
साफ़ भाषा में परिभाषाएँ लिखें और हर जगह पुनः उपयोग करें (UI टूलटिप्स, एक्सपोर्ट, डॉक्स)। कम से कम परिभाषित करें:
फिर टाइमज़ोन, सप्ताह/महीना नियम और करेंसी नियम को стандар्ड करें ताकि चार्ट और CSV मेल खाएं।
एक प्राथमिक पहचानकर्ता चुनें और स्पष्ट रूप से डॉक्यूमेंट करें कि बाकी कैसे मैप होते हैं:
user_id व्यक्ति-स्तर रिटेंशन/यूसेज के लिएaccount_id B2B रोल-अप और सब्सक्रिप्शन मैट्रिक्स के लिएanonymous_id प्री-साइनअप व्यवहार के लिएपहचान स्टिचिंग कब होती है (उदा., लॉगिन पर) और किन किन किन एज केसों में क्या होता है (एक यूजर कई अकाउंट में हो, मर्ज, डुप्लिकेट) बताएं।
एक व्यावहारिक बेसलाइन है events + users + accounts मॉडल:
events: event_name, (UTC), , , (JSON)यदि प्लान या लाइफसाइकल स्टेटस जैसे एट्रिब्यूट समय के साथ बदलते हैं, तो केवल वर्तमान मान रखने से ऐतिहासिक कोहोर्ट्स बदल जाते हैं। सामान्य तरीके:
plan_history(account_id, plan, valid_from, valid_to)आप क्वेरी गति बनाम स्टोरेज/ETL जटिलता के आधार पर चुनें।
कोहोर्ट प्रकार उन एंकर इवेंट्स से मैप होने चाहिए जो अनाम विवाद न छोड़ें (signup, पहली खरीद, किसी मुख्य फ़ीचर का पहला उपयोग)। फिर निर्दिष्ट करें:
यह भी तय करें कि कोहोर्ट मेंबरशिप अपरिवर्तनीय है या देर से आए/सही किए गए डेटा पर बदल सकती है।
पहले से तय करें कि आप कैसे हैंडल करेंगे:
इन नियमों को टूलटिप्स और एक्सपोर्ट मेटाडेटा में शामिल करें ताकि हितधारक लगातार व्याख्या कर सकें।
इंजेस्ट पाथs को स्रोत-सत्य के अनुसार चुनें:
इंजेस्ट के पास वेलिडेशन जोड़ें (ज़रूरी फ़ील्ड, टाइमस्टैम्प सैनीटी, डुप्लिकेशन), और रीकॉर्ड्स रिजेक्ट/फ़िक्स करने पर ऑडिट लॉग रखें ताकि आप संख्या बदलाव समझा सकें।
मध्यम वॉल्यूम के लिए PostgreSQL पर्याप्त हो सकता है: परिचित, सस्ता और SQL-फ्रेंडली। बहुत बड़े इवेंट स्ट्रीम्स या भारी समवर्ती डैशबोर्ड उपयोग के लिए डेटा वेयरहाउस (BigQuery/Snowflake/Redshift) या OLAP स्टोर (ClickHouse/Druid) पर विचार करें।
डैशबोर्ड तेज रखने के लिए प्रीकम्प्यूट करें:
segment_membership (यदि मेंबरशिप बदलती है तो validity विंडो सहित)ड्रिल-डाउन के लिए कच्चे इवेंट रखें, लेकिन डिफ़ॉल्ट अनुभव तेज़ सारांशों पर निर्भर करे।
सरल, अनुमानित RBAC लागू करें और इसे सर्वर-साइड लागू करना न भूलें:
मल्टी-टेनेंट ऐप्स के लिए हर जगह workspace_id शामिल करें और row-level scoping (RLS) लागू करें। PII कम से कम लें, UI में डिफ़ॉल्ट रूप से मास्क करें, और डिलीशन वर्कफ़्लोज़ लागू करें जो कच्चे और व्युत्पन्न दोनों डेटा को हटाएँ।
timestampuser_idaccount_idpropertiesusers/accounts: फ़िल्टरिंग के लिए स्थिर एट्रिब्यूटevent_name को नियंत्रित सूची रखें और properties को लचीला पर डॉक्यूमेंटेड रखें। यह संयोजन कोहोर्ट गणित और नॉन-एक्सपर्ट सेगमेंटेशन दोनों का समर्थन करता है।