18 मई 2025·8 मिनट
स्कीमा डिज़ाइन पहले: प्रारम्भिक क्वेरी ट्यूनिंग से तेज़ ऐप्स
प्रारम्भिक प्रदर्शन सुधार अक्सर बेहतर स्कीमा डिज़ाइन से मिलते हैं: सही तालिकाएँ, कुंजियाँ और प्रतिबंध धीमी क्वेरियों और बाद की महंगी पुनर्लेखनों को रोकते हैं।
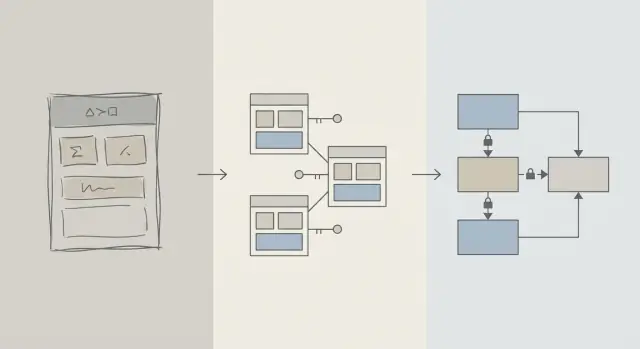
स्कीमा बनाम क्वेरी अनुकूलन: हम क्या मानते हैं
जब कोई ऐप धीमा महसूस होता है, तो पहली प्रवृत्ति अक्सर “SQL ठीक करो” होती है। यह समझ में आता है: एक अकेली क्वेरी दिखाई देती है, मापी जा सकती है और दोषी ठहराना आसान होता है। आप EXPLAIN चला सकते हैं, एक इंडेक्स जोड़ सकते हैं, किसी JOIN को समायोजित कर सकते हैं, और कभी-कभी तुरंत सुधार देख लेते हैं.
लेकिन उत्पाद के शुरुआती चरणों में, गति की समस्याएँ विशिष्ट क्वेरी टेक्स्ट के बजाय डेटा के आकार/रूप से भी उतनी ही संभावना होती हैं। अगर स्कीमा आपको डेटाबेस से लड़ने पर मजबूर करता है, तो क्वेरी ट्यूनिंग व्हैक-ए-मोल बन सकती है।
स्कीमा डिज़ाइन (साधारण भाषा)
स्कीमा डिज़ाइन वह तरीका है जिससे आप अपना डेटा व्यवस्थित करते हैं: तालिकाएँ, कॉलम, रिश्ते और नियम। इसमें ऐसे निर्णय शामिल होते हैं जैसे:
- किन “चीज़ों” को अपनी अलग तालिका चाहिए (users, orders, events)
- तालिकाएँ कैसे जुड़ी हैं (one-to-many, many-to-many)
- क्या कोई यूनिक या अनिवार्य होना चाहिए (प्रतिबंध)
- आप अवस्थाएँ और इतिहास कैसे दर्शाते हैं (timestamps, status फ़ील्ड, audit रिकॉर्ड)
अच्छा स्कीमा डिज़ाइन उस तरह के प्रश्नों को भी तेज़ बनाता है जो स्वाभाविक रूप से पूछे जाते हैं।
क्वेरी अनुकूलन (साधारण भाषा)
क्वेरी अनुकूलन डेटा प्राप्त/अपडेट करने के तरीके को बेहतर बनाना है: क्वेरियों को फिर से लिखना, इंडेक्स जोड़ना, अनावश्यक काम कम करना, और उन पैटर्नों से बचना जो बड़े स्कैन ट्रिगर करते हैं।
दोनों महत्वपूर्ण हैं—समय अधिक मायने रखता है
यह लेख "स्कीमा अच्छा है, क्वेरियाँ बुरी हैं" नहीं कहता। यह ऑपरेशन्स के क्रम के बारे में है: पहले डेटाबेस स्कीमा के बुनियादी सिद्धांत सही करें, फिर उन क्वेरियों को ट्यून करें जिन्हें वास्तव में ज़रूरत है।
आप सीखेंगे कि शुरुआती प्रदर्शन में स्कीमा निर्णय क्यों प्रमुख होते हैं, कैसे पहचानें कि असली बाधा स्कीमा है, और आपकी ऐप बढ़ने पर इसे सुरक्षित रूप से कैसे विकसित करें। यह उत्पाद टीमों, संस्थापकों और वास्तविक दुनिया की ऐप्स बनाने वाले डेवलपर्स के लिए लिखा गया है—न कि केवल डेटाबेस विशेषज्ञों के लिए।
क्यों स्कीमा डिज़ाइन सबसे पहले प्रदर्शन तय करता है
प्रारम्भिक प्रदर्शन आमतौर पर चालाक SQL के बारे में नहीं होता—यह इस बारे में होता है कि डेटाबेस को कितना डेटा छानना/छूना पड़ता है।
संरचना तय करती है कि आपको कितना स्कैन करना होगा
एक क्वेरी केवल उतनी ही चयनशील हो सकती है जितना डेटा मॉडल अनुमति देता है। यदि आप "status", "type" या "owner" जैसे फील्ड को ढीले ढंग से स्टोर करते हैं (या असंगत तालिकाओं में फैलाते हैं), तो डेटाबेस अक्सर यह पता लगाने के लिए बहुत अधिक पंक्तियों को स्कैन करना पड़ता है कि क्या मैच करता है।
एक अच्छा स्कीमा खोज स्थान को स्वाभाविक रूप से संकुचित कर देता है: स्पष्ट कॉलम, संगत डेटा प्रकार, और अच्छी तरह परिभाषित तालिकाएँ क्वेरियों को पहले फ़िल्टर करने और डिस्क/मेमोरी से कम पेज पढ़ने में मदद करते हैं।
गुम हुए कीज़ महँगा काम बनाती हैं
जब प्राथमिक कुंजियाँ और विदेशी कुंजियाँ मौजूद नहीं होतीं (या लागू नहीं की जातीं), तो रिश्ते अनुमान बन जाते हैं। यह काम को क्वेरी परत में धकेल देता है:
- Joins बड़े हो जाते हैं क्योंकि कोई विश्वसनीय, इंडेक्स्ड जॉइन पाथ नहीं होता।
- फ़िल्टर जटिल हो जाते हैं क्योंकि आप डुप्लिकेट, nulls, और "लगभग मेल खाने वाले" मानों के लिए क्षतिपूर्ति कर रहे होते हैं।
प्रतिबंधों के बिना, खराब डेटा जमा होता है—इसलिए पंक्तियों के बढ़ने के साथ क्वेरियाँ धीमी होती जाती हैं।
इंडेक्स स्कीमा का अनुसरण करते हैं (और सब कुछ ठीक नहीं कर सकते)
इंडेक्स सबसे उपयोगी होते हैं जब वे अनुमानित पहुँच पाथ से मेल खाते हैं: foreign keys से जॉइन करना, स्पष्ट कॉलम द्वारा फ़िल्टर करना, सामान्य फ़ील्ड पर सॉर्ट करना। अगर स्कीमा महत्वपूर्ण एट्रिब्यूट्स को गलत तालिका में स्टोर करता है, एक कॉलम में मायने मिलाता है, या टेक्स्ट पार्सिंग पर निर्भर करता है, तो इंडेक्स आपकी मदद नहीं कर पाएंगे—आप अभी भी बहुत स्कैन और ट्रांसफ़ॉर्म कर रहे होंगे।
डिफ़ॉल्ट रूप से तेज़
साफ़ रिश्ते, स्थिर पहचानकर्ता, और समझदारी वाली तालिका सीमाओं के साथ, कई रोज़मर्रा की क्वेरियाँ "डिफ़ॉल्ट रूप से तेज़" बन जाती हैं क्योंकि वे कम डेटा छूती हैं और सरल, इंडेक्स-अनुकूल प्रेडिकेट्स का उपयोग करती हैं। तब क्वेरी ट्यूनिंग अंतिम चरण बन जाती है—ना कि लगातार लड़ाई।
शुरुआती चरण की वास्तविकता: परिवर्तन लगातार रहता है
शुरुआती उत्पादों के पास "स्थिर आवश्यकताएँ" नहीं होतीं—उनके पास प्रयोग होते हैं। सुविधाएँ शिप होती हैं, फिर बदली जाती हैं, या गायब हो जाती हैं। एक छोटी टीम रोडमैप दबाव, सपोर्ट और इन्फ्रास्ट्रक्चर संभाल रही होती है और पुरानी निर्णयों पर फिर से जाने के लिए सीमित समय होता है।
सबसे अधिक क्या बदलता है
आमतौर पर सबसे पहले SQL टेक्स्ट नहीं बदलता। डेटा का मतलब बदलता है: नए स्टेट्स, नए रिश्ते, "ओह, हमें यह भी ट्रैक करना है..." फ़ील्ड, और पूरे वर्कफ़्लो जो लॉन्च पर कल्पना नहीं किए गए थे। यह बदलाव सामान्य है—और यही वजह है कि शुरुआती चरण में स्कीमा निर्णय इतने मायने रखते हैं।
बाद में स्कीमा ठीक करना क्यों कठिन है बनाम क्वेरी ठीक करना
एक क्वेरी को फिर से लिखना आमतौर पर उलटने योग्य और स्थानीय होता है: आप एक सुधार शिप कर सकते हैं, उसे माप सकते हैं, और यदि ज़रूरत हो तो रोलबैक कर सकते हैं।
स्कीमा को फिर से लिखना अलग है। एक बार जब आपने वास्तविक ग्राहक डेटा स्टोर कर दिया, तो हर संरचनात्मक परिवर्तन एक प्रोजेक्ट बन जाता है:
- माइग्रेशन जो तालिकाओं को लॉक कर देते हैं या पीक समय पर लिखने को धीमा कर देते हैं
- बैकफिल्स नए कॉलम भरने या व्युत्पन्न डेटा को पुनर्निर्मित करने के लिए
- डुअल-राइट या शैडो तालिकाएँ संक्रमण के दौरान ऐप को चलाने के लिए
- डाउनटाइम का जोखिम यदि बदलाव ऑनलाइन नहीं किया जा सके
अच्छे टूलिंग के साथ भी, स्कीमा परिवर्तनों में समन्वय लागत आती है: ऐप कोड अपडेट, डिप्लॉयमेंट अनुक्रम, और डेटा सत्यापन।
शुरुआती निर्णय कैसे यौगिक बनते हैं
जब डेटाबेस छोटा होता है, एक अपुष्ट स्कीमा "ठीक" दिख सकता है। जैसे-ही पंक्तियाँ हजारों से लाखों तक बढ़ती हैं, वही डिज़ाइन बड़े स्कैन, भारी इंडेक्स और महंगे जॉइन्स पैदा करती है—फिर हर नई सुविधा उसी आधार पर बनती है।
इसलिए शुरुआती लक्ष्य पूर्णता नहीं है। यह ऐसा स्कीमा चुनना है जो बदलाव को अवशोषित कर सके बिना हर बार जोखिम भरे माइग्रेशन को मजबूर किए।
डिज़ाइन के मूल सिद्धांत जो धीमी क्वेरियों को रोकते हैं
शुरुआत में अधिकांश "धीमी क्वेरी" समस्याएँ SQL चालाकियों के बारे में नहीं—वे डेटा मॉडल में अस्पष्टता के बारे में हैं। यदि स्कीमा यह अस्पष्ट बनाता है कि कोई रिकॉर्ड क्या दर्शाता है, या रिकॉर्ड कैसे संबंधित हैं, तो हर क्वेरी लिखने, चलाने और बनाए रखने के लिए महँगी हो जाती है।
कुछ मूल एंटिटीज़ के छोटे सेट से शुरू करें
सबसे पहले उन कुछ चीज़ों को नाम दें जिनके बिना आपका उत्पाद काम नहीं कर सकता: users, accounts, orders, subscriptions, events, invoices—जो भी वास्तव में केंद्रिय है। फिर रिश्तों को स्पष्ट रूप से परिभाषित करें: one-to-many, many-to-many (अक्सर एक join टेबल के साथ), और ownership (कौन क्या "रखता" है)।
एक व्यावहारिक चेक: हर तालिका के लिए, आप वाक्य पूरा कर सकें "इस तालिका की एक पंक्ति दर्शाती है ___." अगर आप नहीं कर पाते, तो तालिका संभवतः अवधारणाओं को मिला रही है, जो बाद में जटिल फ़िल्टरिंग और जॉइन्स को मजबूर करेगी।
नामकरण और ownership को उबाऊ रूप से सुसंगत रखें
संगति आकस्मिक जॉइन्स और भ्रमित API व्यवहार को रोकती है। कन्वेंशंस चुनें (snake_case बनाम camelCase, *_id, created_at/updated_at) और उन पर टिके रहें।
यह भी तय करें कि एक फ़ील्ड किसका है। उदाहरण के लिए, "billing_address" किसी order का (समय का स्नैपशॉट) है या किसी user का (वर्तमान डिफ़ॉल्ट)? दोनों वैध हो सकते हैं—लेकिन बिना स्पष्ट इरादे के मिश्रण धीमी, त्रुटिपूर्ण क्वेरियों की ओर ले जाता है ताकि "सत्य" पता किया जा सके।
वास्तविकता से मेल खाते डेटा प्रकार चुनें
ऐसे प्रकार उपयोग करें जो रनटाइम रूपांतरण से बचाएँ:
- समय के साथ तालमेल रखने के लिए timezone वाले timestamps का उपयोग करें जिन्हें आप समझते हैं।
- पैसे के लिए decimals का उपयोग करें (floats नहीं)।
- ज्ञात श्रेणियों के लिए enums/reference तालिकाएँ उपयोग करें।
जब प्रकार गलत होते हैं, डेटाबेस कुशलतापूर्वक तुलना नहीं कर पाता, इंडेक्स कम उपयोगी हो जाते हैं, और क्वेरियों को अक्सर casting की ज़रूरत पड़ती है।
बिना योजना के तथ्यों की नकल न करें
एक ही तथ्य को कई जगहों पर स्टोर करना (उदाहरण: order_total और sum(line_items)) ड्रिफ्ट पैदा करता है। यदि आप व्युत्पन्न मान कैश करते हैं, तो उसे दस्तावेज़ित करें, सत्य की स्रोत परिभाषित करें, और अपडेट्स को सुसंगत रूप से लागू करें (अक्सर एप्लिकेशन लॉजिक प्लस प्रतिबंध के साथ)।
कुंजियाँ और प्रतिबंध: गति डेटा इंटेग्रिटी से शुरू होती है
एक तेज़ डेटाबेस आमतौर पर एक पूर्वानुमान योग्य डेटाबेस होता है। कुंजियाँ और प्रतिबंध आपका डेटा पूर्वानुमान योग्य बनाते हैं क्योंकि वे "असंभव" अवस्थाओं—मिसिंग रिश्ते, डुप्लिकेट पहचान, या वे मान जो ऐप सोचता है वैसा नहीं—को रोकते हैं। वह सफाई सीधे प्रदर्शन को प्रभावित करती है क्योंकि क्वेरी प्लानर बेहतर अनुमान लगा सकता है।
प्राथमिक कुंजियाँ: हर तालिका को एक स्थिर पहचानकर्ता चाहिए
हर तालिका में एक प्राथमिक कुंजी (PK) होना चाहिए: एक कॉलम (या छोटे सेट) जो एक पंक्ति को अनन्य रूप से पहचानता है और कभी नहीं बदलता। यह केवल डेटाबेस सिद्धांत नहीं है—यह आपको तालिकाओं को कुशलतापूर्वक जोड़ने, सुरक्षित कैश करने, और रिकॉर्ड्स को बिना अनुमान के संदर्भित करने देता है।
एक स्थिर PK महँगी वर्कअराउंड से भी बचाता है। अगर तालिका में सच्चा पहचानकर्ता नहीं है, तो एप्लिकेशन पंक्तियों की "पहचान" ईमेल, नाम, timestamp, या कॉलम के बंडल से करने लगता है—जिससे चौड़े इंडेक्स, धीमे जॉइन्स, और किन्हीं मानों के बदलने पर एज केस पैदा होते हैं।
विदेशी कुंजियाँ: उन्टेग्रिटी जो ऑप्टिमाइज़र की मदद करती हैं
FKs रिश्तों को लागू करते हैं: orders.user_id को मौजूदा users.id की ओर इशारा करना चाहिए। FKs के बिना, अवैध रेफरेंस घुस जाते हैं (हटाए गए उपयोगकर्ताओं के लिए ऑर्डर, गायब पोस्ट के लिए कमेंट्स), और तब हर क्वेरी को रक्षात्मक रूप से फ़िल्टर, left-join और nulls को संभालना पड़ता है।
FKs होने पर, क्वेरी प्लानर अक्सर जॉइन्स को अधिक आत्मविश्वास के साथ अनुकूलित कर सकता है क्योंकि रिश्ता स्पष्ट और गारंटीकृत होता है। आप अनऑर्डिनलाइज़्ड रोज़ के संचय से भी बचेंगे जो समय के साथ तालिकाओं और इंडेक्स को भारी बना देते हैं।
साफ़, तेज़ डेटा के लिए प्रतिबंध मार्गदर्शक होते हैं
प्रतिबंध नौकरशाही नहीं हैं—वे मार्गदर्शक हैं:
- UNIQUE डुप्लिकेट्स रोकता है जो ऐप को अतिरिक्त लुकअप्स और सफाई करने के लिए मजबूर करते हैं। उदाहरण: एक canonical
users.email। - NOT NULL तिहरे-राज्य लॉजिक और क्वेरियों में अचानक null-हैंडलिंग शाखाओं से बचाता है।
- CHECK मानों को ज्ञात सेट के भीतर रखता है (उदा.,
status IN ('pending','paid','canceled')).
साफ़ डेटा का मतलब सरल क्वेरियाँ, कम fallback शर्तें, और कम "बस स्थिति के लिए" जॉइन्स है।
सामान्य एंटी-पैटर्न जो आपको धीमा करते हैं
- कोई foreign keys नहीं: बाद में orphan क्लीनअप जॉब्स और जटिल क्वेरी लॉजिक का भुगतान करना पड़ेगा।
- डुप्लिकेट "email" फ़ील्ड्स (जैसे
users.emailऔरcustomers.email): विरोधी पहचान और डुप्लिकेट इंडेक्स मिलते हैं। - फ्री-फॉर्म status strings: "Cancelled" बनाम "canceled" जैसी टाइपो छिपे विभाजनों का कारण बनती हैं जो फ़िल्टर्स और रिपोर्टिंग को तोड़ देती हैं।
यदि आप शुरुआती दौर में गति चाहते हैं, तो खराब डेटा स्टोर करना मुश्किल बनाइए। डेटाबेस आपको सरल योजनाओं, छोटे इंडेक्स और कम प्रदर्शन आश्चर्यों के साथ इनाम देगा।
नॉर्मलाइज़ेशन बनाम डीनॉर्मलाइज़ेशन: एक व्यावहारिक संतुलन
होस्टिंग समेत डिप्लॉय करें
पहले इन्फ्रास्ट्रक्चर सेट किए बिना अपना ऐप डिप्लॉय और होस्ट करें।
नॉर्मलाइज़ेशन एक सरल विचार है: प्रत्येक "तथ्य" को एक ही जगह पर रखें ताकि डेटा आपके डेटाबेस में तशरीह न फैले। जब वही मान कई तालिकाओं/कॉलम में कॉपी किया जाता है, अपडेट्स जोखिम भरे हो जाते हैं—एक कॉपी बदलती है और दूसरी नहीं, और आपकी ऐप विरोधाभासी उत्तर दिखाने लगती है।
नॉर्मलाइज़ेशन (डिफ़ॉल्ट): एक तथ्य, एक घर
व्यावहारिक रूप से, नॉर्मलाइज़ेशन का मतलब है एंटिटीज़ को अलग करना ताकि अपडेट साफ़ और पूर्वानुमानित हों। उदाहरण के लिए, एक उत्पाद का नाम और कीमत products तालिका में होना चाहिए, हर ऑर्डर रो में दोहराया नहीं। एक category नाम categories में होना चाहिए, और ID के जरिए संदर्भित होना चाहिए।
यह कम करता है:
- डुप्लिकेट डेटा (कम स्टोरेज, कम असंगतियाँ)
- अपडेट त्रुटियाँ (एक बार बदलो, सब जगह दिखेगा)
- भ्रमित "कौन सा मान सही है?" बग
जब अतिनॉर्मलाइज़ेशन नुकसान पहुंचाता है
नॉर्मलाइज़ेशन तब ज्यादा हो सकता है जब आप डेटा को बहुत छोटी तालिकाओं में बाँट देते हैं जिन्हें रोज़ के स्क्रीन के लिए लगातार जोड़ा जाना चाहिए। डेटाबेस सही परिणाम दे सकता है, पर सामान्य रीड्स धीमी और जटिल हो सकती हैं क्योंकि हर रिक्वेस्ट को कई जॉइन्स की ज़रूरत होती है।
एक आम शुरुआती-चरण लक्षण: एक "सरल" पेज (जैसे ऑर्डर हिस्ट्री सूची) के लिए 6–10 तालिकाएँ जॉइन करनी पड़ती हैं, और प्रदर्शन ट्रैफ़िक और कैश वार्मथ पर निर्भर करता है।
व्यावहारिक तरीका: कोर फैक्ट्स नॉर्मलाइज़ करें, सबसे हॉट रीड के लिए डीनॉर्मलाइज़ करें
एक समझदार संतुलन है:
- कोर फैक्ट्स और ownership को नॉर्मलाइज़ करें (source of truth)। उत्पाद गुण
productsमें रखें, category नामcategoriesमें और रिश्ते foreign keys के जरिए। - सबसे अधिक उपयोग होने वाली रीड्स के लिए सावधानीपूर्वक डीनॉर्मलाइज़ करें—पर केवल जब आप लाभ और इसे कैसे सही रखा जाएगा समझा सकें।
डीनॉर्मलाइज़ेशन का मतलब बार-बार छोटी मात्रा में डेटा को नकल करना है ताकि एक सामान्य क्वेरी सस्ती हो (कम जॉइन्स, तेज़ सूचियाँ)। मुख्य शब्द "सावधानीपूर्वक" है: हर डुप्लिकेट फ़ील्ड के पास इसे अपडेट रखने की योजना होनी चाहिए।
उदाहरण: products, categories, और order items
एक नॉर्मलाइज़्ड सेटअप इस तरह दिख सकता है:
products(id, name, price, category_id)categories(id, name)orders(id, customer_id, created_at)order_items(id, order_id, product_id, quantity, unit_price_at_purchase)
नोट करें एक सूक्ष्म जीत: order_items unit_price_at_purchase रखता है (डीनॉर्मलाइज़ेशन का एक रूप) क्योंकि आपको ऐतिहासिक सटीकता चाहिए भले ही बाद में product price बदल जाए। वह डुप्लीकेशन जानबूझकर और स्थिर है।
यदि आपकी सबसे सामान्य स्क्रीन "item summaries के साथ orders" है, तो आप order_items में product_name भी डीनॉर्मलाइज़ कर सकते हैं ताकि हर सूची पर products को जॉइन न करना पड़े—पर केवल तब जब आप इसे सिंक रखने के लिए तैयार हों (या मान लें कि यह खरीद के समय का स्नैपशॉट है)।
इंडेक्स रणनीति स्कीमा का अनुसरण करती है, न कि विपरीत
इंडेक्स को अक्सर एक जादुई "स्पीड बटन" माना जाता है, पर वे केवल तब अच्छी तरह काम करते हैं जब underlying तालिका संरचना समझदारी से बने हो। अगर आप अभी भी कॉलम का नाम बदल रहे हैं, तालिकाएँ बाँट रहे हैं, या रिकॉर्ड कैसे संबंधित हैं बदल रहे हैं, तो आपका इंडेक्स सेट भी बार-बार बदलता रहेगा। इंडेक्स सबसे अच्छा तब काम करते हैं जब कॉलम और एप्लिकेशन द्वारा उन पर फ़िल्टर/सॉर्ट करने के तरीके स्थिर हों ताकि आप उन्हें हर सप्ताह फिर से न बना रहे हों।
अपने ऐप के सबसे सामान्य प्रश्नों से शुरू करें
आपको परफेक्ट भविष्यवाणी की ज़रूरत नहीं, पर आपको उन क्वेरियों की छोटी सूची चाहिए जो सबसे ज़्यादा मायने रखती हैं:
- “Find a user by email.”
- “Show recent orders for a customer.”
- “List invoices by status, newest first.”
ये बयान सीधे बताते हैं कि किन कॉलमों को इंडेक्स चाहिए। अगर आप इन्हें ज़ुबान पर नहीं कह सकते, तो आमतौर पर यह स्कीमा स्पष्टता की समस्या होती है—इंडेक्स की नहीं।
कंपोजिट इंडेक्स, सरल भाषा में
एक कंपोजिट इंडेक्स एक से अधिक कॉलम को कवर करता है। कॉलमों का क्रम मायने रखता है क्योंकि डेटाबेस इंडेक्स को बाएँ से दाएँ प्रभावी तरीके से उपयोग कर सकता है।
उदाहरण के लिए, अगर आप अक्सर customer_id द्वारा फ़िल्टर करते हैं और फिर created_at द्वारा सॉर्ट करते हैं, तो (customer_id, created_at) पर इंडेक्स आमतौर पर उपयोगी होगा। उल्टा (created_at, customer_id) वही क्वेरी उतना मददगार नहीं होगा।
सब कुछ इंडेक्स न करें
हर अतिरिक्त इंडेक्स की कीमत होती है:
- धीमी writes: inserts/updates हर इंडेक्स को भी अपडेट करना होगा।
- अधिक स्टोरेज: इंडेक्स डेटाबेस आकार का बड़ा हिस्सा बन सकते हैं।
- अधिक जटिलता: अतिरिक्त इंडेक्स मेंटेनेंस और ट्यूनिंग को कठिन बनाते हैं।
एक साफ़, संगत स्कीमा "सही" इंडेक्सों को एक छोटे सेट तक सीमित करता है जो वास्तविक एक्सेस पैटर्न से मेल खाते हैं—बिना लगातार write और स्टोरेज टैक्स दिए।
लिखने का प्रदर्शन: एक गंदे स्कीमा की छिपी लागत
प्रतिबंध सुरक्षित तरीके से जोड़ें
धीमी क्वेरीज को रोकने के लिए पहले से PKs, FKs और चेक्स मॉडल करें।
धीमी ऐप्स हमेशा रीड्स से धीमी नहीं होतें। कई शुरुआती प्रदर्शन समस्याएँ inserts और updates के दौरान नजर आती हैं—user signups, checkout फ्लोज़, background jobs—क्योंकि एक गन्दा स्कीमा हर लिखावट को अतिरिक्त काम करवा देता है।
क्यों लिखना महँगा होता है
कुछ स्कीमा विकल्प हर परिवर्तन की लागत को गुप्त रूप से गुणा कर देते हैं:
- वाइड रोज़: एक तालिका में दर्जनों (या सैकड़ों) कॉलम ठूँस देना अक्सर बड़ी पंक्तियाँ, अधिक I/O, और अधिक कैश चर्न का कारण बनता है—भले ही अधिकांश कॉलम शायद ही कभी उपयोग हों।
- बहुत सारे इंडेक्स: इंडेक्स रीड्स को तेज़ करते हैं, पर हर insert/update को भी हर इंडेक्स अपडेट करना पड़ता है।
- Triggers और cascades: triggers एक सरल
INSERTके पीछे अतिरिक्त काम छिपा सकते हैं। Cascading foreign keys सही और मददगार हो सकते हैं, पर वे भी लिखने के समय काम बढ़ा देते हैं जो संबंधित डेटा के साथ बढ़ता है।
read-heavy बनाम write-heavy: अपना दर्द जानकर चुनें
यदि आपका वर्कलोड read-heavy है (feeds, search पेज), तो आप अधिक इंडेक्सिंग और कभी-कभार चयनात्मक डीनॉर्मलाइज़ेशन बर्दाश्त कर सकते हैं। यदि यह write-heavy है (event ingestion, telemetry, high-volume orders), तो ऐसा स्कीमा प्राथमिकता दें जो लिखवाइयों को सरल और पूर्वानुमानित रखे, फिर ज़रूरत पर रीड ऑप्टिमाइजेशन जोड़ें।
शुरुआती-चरण के सामान्य पैटर्न जो लिखनों को नुकसान पहुंचाते हैं
- ऑडिट लॉग्स: अनुपालन के लिए बढ़िया, पर हर अपडेट पर बड़े स्नैपशॉट लॉग करने से बचें।
- इवेंट टेबल्स: append-only तालिकाएँ अच्छी तरह स्केल करती हैं, पर अगर आप अनावश्यक payloads स्टोर करें तो वे फुल हो सकती हैं।
- सॉफ्ट डिलीट्स: सुविधाजनक, पर वे इंडेक्स साइज बढ़ाते हैं और अपडेट/क्वेरीज़ धीमी कर सकते हैं जब तक सावधानी से योजनाबद्ध न हों।
इतिहास बनाए रखते हुए लिखतें सरल रखें
एक व्यावहारिक तरीका:
- "वर्तमान स्थिति" को एक तालिका में रखें, और इतिहास को एक अलग append-only तालिका में रखें।
- इतिहास की पंक्तियाँ संकरी रखें (केवल जो वास्तव में चाहिए: किसने/कब/क्या बदला)।
- इतिहास पर इंडेक्स वास्तविक एक्सेस पैटर्न के आधार पर रखें (आमतौर पर
entity_id,created_at)। - शुरुआत में ऑडिटिंग के लिए triggers से बचें; स्पष्ट एप्लिकेशन लिखें ताकि लागत दिखाई दे और परीक्षण योग्य हो।
साफ़ लिखने के रास्ते आपको हेडरूम देते हैं—और वे बाद में क्वेरी अनुकूलन को आसान बनाते हैं।
ORMs और APIs कैसे स्कीमा निर्णयों को बढ़ा देते हैं
ORMs डेटाबेस काम को आसानी से महसूस कराते हैं: आप मॉडल परिभाषित करते हैं, मेथड कॉल करते हैं, और डेटा दिख जाता है। लेकिन एक ORM महँगी SQL को तब तक छिपा भी सकता है जब तक कि यह चोट न पहुंचाने लगे।
ORMs: सुविधा जो धीमे पैटर्न छिपा सकती है
दो सामान्य जाल:
- अप्रभावी जॉइन्स: एक दिखने में सरल
.include()या नेस्टेड सीरियलाइज़र चौड़े जॉइन्स, डुप्लिकेट पंक्तियाँ, या बड़े सॉर्ट्स में बदल सकता है—खासकर अगर रिश्ते स्पष्ट रूप से परिभाषित न हों। - N+1 क्वेरियाँ: आप 50 रिकॉर्ड ला रहे हैं, और फिर ORM चुपचाप संबंधित डेटा लाने के लिए 50 और क्वेरियाँ चला देता है। यह विकास में काम कर सकता है पर वास्तविक ट्रैफ़िक में ढह जाता है।
एक अच्छी तरह डिज़ाइन किया गया स्कीमा इन पैटर्न्स के उभरने की संभावना कम करता है और जब वे होते हैं तो उन्हें पहचानना आसान बनाता है।
स्पष्ट रिश्ते ORM उपयोग को सुरक्षित बनाते हैं
जब तालिकाओं में स्पष्ट foreign keys, unique constraints, और not-null नियम होते हैं, तो ORM सुरक्षित क्वेरियाँ जेनरेट कर सकता है और आपका कोड सुसंगत अनुमान पर निर्भर कर सकता है।
उदाहरण के लिए, यह सुनिश्चित करना कि orders.user_id मौजूद हो (FK) और users.email यूनिक हो, उन एज केस वर्गों को रोकता है जो अन्यथा एप्लिकेशन-स्तरीय जाँचों और अतिरिक्त क्वेरी काम में बदल जाते।
APIs स्कीमा चयन को उत्पाद व्यवहार में बदल देते हैं
आपकी API डिज़ाइन आपके स्कीमा की डाउनस्ट्रीम है:
- स्थिर IDs (और संगत कुंजी प्रकार) URLs, कैशिंग, और क्लाइंट-साइड स्टेट को सरल बनाते हैं।
- पैजिनेशन तब सबसे अच्छा काम करती है जब आप एक इंडेक्स्ड, मोनोटोनिक कॉलम द्वारा ऑर्डर कर सकें (अक्सर
created_at+id)। - फिल्टरिंग तब voorsग्य हे जब कॉलम वास्तविक एट्रिब्यूट्स का प्रतिनिधित्व करें (ना कि ओवरलोडेड स्ट्रिंग्स या JSON ब्लॉब्स) और प्रतिबंध मानों को साफ़ रखें।
इसे एक वर्कफ़्लो बनाएं, बचाव अभियान नहीं
स्कीमा निर्णयों को प्रथम श्रेणी इंजीनियरिंग माना जाए:
- हर परिवर्तन के लिए माइग्रेशन का उपयोग करें, कोड की तरह समीक्षा कीजिए (/blog/migrations).
- नए एंडपॉइंट के लिए हल्की "स्कीमा समीक्षा" जोड़ें: कौन सी तालिकाएँ, कौन सी कुंजियाँ, कौन से प्रतिबंध, और क्वेरी का स्वरूप।
- स्टेजिंग में ORM क्वेरियों को लॉग करें और N+1 पैटर्न्स को प्रोडक्शन से पहले फ़्लैग करें (/blog/orm-performance-checks).
अगर आप तेज़ी से बना रहे हैं जैसे चैट-ड्रिवन वर्कफ़्लो के साथ (उदा., React ऐप और Go/PostgreSQL बैकएंड को जेनरेट करना Koder.ai में), तो early में "स्कीमा समीक्षा" को बातचीत का हिस्सा बनाना मददगार होता है। आप तेज़ी से इटेरेट कर सकते हैं, पर फिर भी प्रतिबंध, कुंजियाँ, और माइग्रेशन प्लान जानबूझकर रखें—खासकर ट्रैफ़िक आने से पहले।
शुरुआती चेतावनी संकेत कि आपका स्कीमा बाधा है
कुछ प्रदर्शन समस्याएँ इतनी "खराब SQL" नहीं होतीं जितनी कि डेटाबेस का आपके डेटा के रूप से लड़ना। यदि आप कई endpoints और रिपोर्ट्स में समान समस्याएँ देखते हैं, तो यह अक्सर स्कीमा संकेत है, न कि क्वेरी-ट्यूनिंग का मौका।
देखने के लिए सामान्य लक्षण
धीमे फ़िल्टर क्लासिक संकेत हैं। यदि सरल शर्तें जैसे "कस्टमर द्वारा ऑर्डर ढूँढो" या "निर्माण तिथि से फ़िल्टर करें" लगातार सुस्त हैं, तो समस्या गुम हुए रिश्तों, mismatched types, या ऐसे कॉलम हो सकते हैं जिन्हें प्रभावी रूप से इंडेक्स नहीं किया जा सकता।
एक और लाल झंडी है बढ़ती जॉइन संख्या: एक क्वेरी जो 2–3 तालिकाएँ जोड़कर उत्तर देता दिखना चाहिए, बेसिक प्रश्न का उत्तर देने के लिए 6–10 तालिकाएँ जॉइन करने लगती है (अक्सर अतिनॉर्मलाइज़्ड लुकअप्स, polymorphic पैटर्न, या "सब कुछ एक तालिका में" डिज़ाइनों के कारण)।
इसके अलावा उन कॉलमों में असंगत मानों के लिए देखें जो enums की तरह व्यवहार करते हैं—खासतौर पर status फ़ील्ड्स ("active", "ACTIVE", "enabled", "on")। असंगति रक्षात्मक क्वेरियाँ (LOWER(), COALESCE(), OR-चेन) को मजबूर करती है जो चाहे कितनी भी ट्यूनिंग हो हमेशा धीमी रहती हैं।
स्कीमा चेकलिस्ट (त्वरित सत्यापित करने के लिए)
- foreign keys पर गुम हुए इंडेक्स (जैसाโตबिलें बढ़ती हैं तो जॉइन्स full scans बन जाते हैं)।
- गलत डेटा प्रकार (उदा., IDs स्ट्रिंग के रूप में स्टोर, dates टेक्स्ट के रूप में, पैसे float में)।
- EAV तालिकाएँ (Entity–Attribute–Value) को कोर डेटा के लिए उपयोग करना: पहले लचीला, पर फ़िल्टर/सॉर्ट्स कई जॉइन्स और मुश्किल-इंडेक्स योग्य प्रेडिकेट में बदल जाते हैं।
सरल, टूल-एग्नोस्टिक डायग्नोस्टिक्स
रियलिटी चेक से शुरू करें: तालिका के अनुसार पंक्तियों की गिनती, और प्रमुख कॉलमों के लिए कार्डिनैलिटी (कितने विशिष्ट मान)। यदि एक "status" कॉलम में 4 अपेक्षित मान होने चाहिए पर आप 40 पाते हैं, तो स्कीमा पहले ही जटिलता लीक कर रहा है।
फिर अपने स्लो एंडपॉइंट्स के क्वेरी प्लांस देखें। अगर आप बार-बार जॉइन कॉलमों पर sequential scans या बड़े intermediate result sets देखते हैं, तो स्कीमा और इंडेक्सिंग संभवतः मूल कारण हैं।
अंत में, slow query logs सक्षम करें और समीक्षा करें। जब बहुत सारी अलग-अलग क्वेरियाँ समान तरीकों से धीमी हों (उसी तालिकाएँ, वही प्रेडिकेट्स), तो यह आमतौर पर एक संरचनात्मक मुद्दा होता है जिसे मॉडल स्तर पर ठीक करना चाहिए।
बढ़ने पर स्कीमा को सुरक्षित रूप से कैसे विकसित करें
पूरे टीम के साथ काम करें
अकेले बिल्ड करने वालों से लेकर बिज़नेस और एंटरप्राइज टीमों तक के लिए उपयुक्त प्लान चुनें।
शुरुआती स्कीमा निर्णय शायद ही कभी वास्तविक उपयोगकर्ताओं से मिलने के बाद बचते हैं। लक्ष्य "इसे परफेक्ट बनाना" नहीं है—बल्कि इसे बदलना है बिना प्रोडक्शन तोड़े, डेटा खोए, या टीम को एक हफ्ते के लिए फ्रीज़ किए।
हल्का, दोहराव योग्य परिवर्तन प्रक्रिया
एक व्यावहारिक वर्कफ़्लो जो एक-व्यक्ति की ऐप से बड़ी टीम तक स्केल करता है:
- मॉडल करें: नई आकृति लिखें (तालिकाएँ/कॉलम, रिश्ते, और क्या स्रोत-ऐक्यता बनेगी)। उदाहरण रिकॉर्ड और एज केस शामिल करें।
- माइग्रेट करें: नए संरचनाएँ बैकवर्ड-कम्पैटिबल तरीके से जोड़ें (नए कॉलम/तालिकाएँ पहले जोड़ें; तुरंत हटाएं या नाम न बदलें)।
- बैकफिल: बैच में मौजूदा डेटा से नए फ़ील्ड भरें। प्रगति को ट्रैक करें ताकि आप पुनः आरंभ कर सकें।
- वैध करें: डेटा साफ़ होने के बाद ही प्रतिबंध जोड़ें (उदा., NOT NULL, foreign keys)। पुराने बनाम नए आउटपुट की तुलना करने वाले चेक चलाएँ।
फीचर फ़्लैग्स और डुअल-राइट्स (संयमित उपयोग)
अधिकांश स्कीमा परिवर्तनों को जटिल रोलआउट पैटर्न की ज़रूरत नहीं होती। "विस्तार और संकुचन" को प्राथमिकता दें: कोड लिखें जो दोनों पुरानी और नई संरचनाएँ पढ़ सके, फिर लेखन तब स्विच करें जब आप आश्वस्त हों।
फीचर फ़्लैग्स या डुअल राइट्स केवल तभी उपयोग करें जब आपको वास्तव में क्रमिक कटओवर की जरूरत हो (उच्च ट्रैफ़िक, लंबी बैकफिल्स, या कई सर्विसेज)। यदि आप डुअल-राइट करते हैं, तो ड्रिफ्ट का पता लगाने के लिए मॉनिटरिंग जोड़ें और संघर्ष पर कौन जीतेगा यह परिभाषित करें।
रोलबैक और माइग्रेशन परीक्षण जो वास्तविकता को दर्शाए
सुरक्षित रोलबैक माइग्रेशन्स से शुरू होते हैं जो उल्टे हो सकें। "अनडू" पथ का अभ्यास करें: एक नया कॉलम ड्रॉप करना आसान है; ओवरराइट किए गए डेटा को पुनर्प्राप्त करना नहीं है।
माइग्रेशन्स को वास्तविक डेटा वॉल्यूम पर टेस्ट करें। एक माइग्रेशन जो लैपटॉप पर 2 सेकंड में खत्म होता है, प्रोडक्शन में मिनटों तक तालिकाओं को लॉक कर सकता है। प्रोडक्शन जैसे पंक्ति गण, इंडेक्स, और रनटाइम को मापें।
यह वह जगह है जहाँ प्लेटफ़ॉर्म टूलिंग जोखिम कम कर सकती है: भरोसेमंद डिप्लॉयमेंट्स, स्नैपशॉट/रोलबैक, और कोड को एक्सपोर्ट करने की क्षमता। यदि आप Koder.ai का उपयोग कर रहे हैं, तो उन माइग्रेशन्स को पेश करने से पहले स्नैपशॉट्स और प्लानिंग मोड पर भरोसा करें जो सावधानीपूर्वक अनुक्रम की ज़रूरत पड़ सकती हैं।
अगले व्यक्ति (भविष्य के आप सहित) के लिए निर्णय दस्तावेज़ करें
एक छोटा स्कीमा लॉग रखें: क्या बदला, क्यों, और कौन से ट्रेडऑफ स्वीकार किए गए। इसे /docs या आपके रेपो README से लिंक करें। नोट्स शामिल करें जैसे "यह कॉलम जानबूझकर डीनॉर्मलाइज़्ड है" या "foreign key 2025-01-10 को बैकफिल के बाद जोड़ा गया" ताकि भविष्य के परिवर्तन पुराने गलतियों को दोहराएँ नहीं।
कब क्वेरियों का अनुकूलन करें (और एक संवेदनशील कार्यवाही क्रम)
क्वेरी अनुकूलन मायने रखता है—पर यह तब सबसे अधिक लाभदायक होता है जब आपका स्कीमा आपके खिलाफ न हो। अगर तालिकाओं में स्पष्ट कुंजियाँ नहीं हैं, रिश्ते असंगत हैं, या "एक पंक्ति प्रति चीज़" का उल्लंघन हो रहा है, तो आप सप्ताह भर क्वेरी ट्यूनिंग पर समय व्यतीत कर सकते हैं जिसे अगली हफ्ते फिर से लिखा जाना है।
एक व्यावहारिक प्राथमिकता क्रम
-
पहले स्कीमा ब्लॉकर्स ठीक करें। उन बातों से शुरू करें जो सही क्वेरी करना मुश्किल बनाती हैं: गुम प्राथमिक कुंजियाँ, असंगत विदेशी कुंजियाँ, ऐसे कॉलम जो कई मायने रखते हैं, सत्य का कई स्रोत, या प्रकार जो वास्तविकता से मेल नहीं खाते (उदा., स्ट्रिंग के रूप में स्टोर किए गए तारीख)।
-
एक्सेस पैटर्न को स्थिर करें। एक बार जब डेटा मॉडल उस तरीके को प्रतिबिंबित करे जिस पर ऐप व्यवहार करता है (और अगले कुछ स्प्रिंट्स के लिए वही रहने की संभावना है), तब क्वेरी ट्यूनिंग टिकाऊ बनती है।
-
शीर्ष क्वेरियों को अनुकूलित करें—सभी क्वेरियों को नहीं। लॉग्स/APM का उपयोग करके सबसे धीमी और सबसे बार-बार चलने वाली क्वेरियाँ पहचानें। एक ऐसा एंडपॉइंट जो दिन में 10,000 बार हिट होता है आमतौर पर एक विरले admin रिपोर्ट से अधिक प्रभावी है।
शुरुआती क्वेरी ट्यूनिंग का 80/20
अधिकांश शुरुआती जीत कुछ ही कदमों से आती हैं:
- अपने सबसे सामान्य फ़िल्टर और जॉइन्स के लिए सही इंडेक्स जोड़ें (और सत्यापित करें कि यह वास्तव में उपयोग हो रहा है)।
- कम कॉलम वापस भेजें (wide tables पर
SELECT *से बचें)। - अनावश्यक जॉइन्स से बचें—कभी-कभी एक जॉइन केवल इसलिए होता है क्योंकि स्कीमा आपको "बुनियादी एट्रिब्यूट खोजने" के लिए मजबूर करता है।
अपेक्षाएँ सेट करें: यह लगातार चलने वाला काम है, पर नींव पहले आता है
प्रदर्शन का काम कभी खत्म नहीं होता, पर लक्ष्य इसे पूर्वानुमानित बनाना है। एक साफ़ स्कीमा के साथ, हर नई सुविधा परोक्ष लोड जोड़ती है; एक गंदे स्कीमा के साथ, हर नई सुविधा यौगिक भ्रम जोड़ती है।
इस सप्ताह का चेकलिस्ट
- सबसे धीमी 5 और सबसे बार-बार 5 क्वेरियों की सूची बनाएं।
- प्रत्येक के लिए पुष्टि करें: primary key मौजूद, जॉइन्स key-to-key हैं, और प्रकार सही हैं।
- उस डॉमिनेंट फिल्टर/ऑर्डर को मैच करने वाला एक इंडेक्स जोड़ें।
- एक हॉट पाथ में
SELECT *को बदलें। - फिर से मापें और अगले स्प्रिंट के लिए एक सरल "पहले/बाद" नोट रखें।