14 जुल॰ 2025·8 मिनट
मेमोरी मैनेजमेंट रणनीतियाँ: भाषाओं में प्रदर्शन बनाम सुरक्षा
जानिए गार्बेज कलेक्शन, स्वामित्व (ownership), और रेफ़रेंस काउंटिंग स्पीड, लेटेंसी और सुरक्षा को कैसे प्रभावित करते हैं—और किस लक्ष्य के लिए कौन‑सी भाषा चुनें।
जानिए गार्बेज कलेक्शन, स्वामित्व (ownership), और रेफ़रेंस काउंटिंग स्पीड, लेटेंसी और सुरक्षा को कैसे प्रभावित करते हैं—और किस लक्ष्य के लिए कौन‑सी भाषा चुनें।
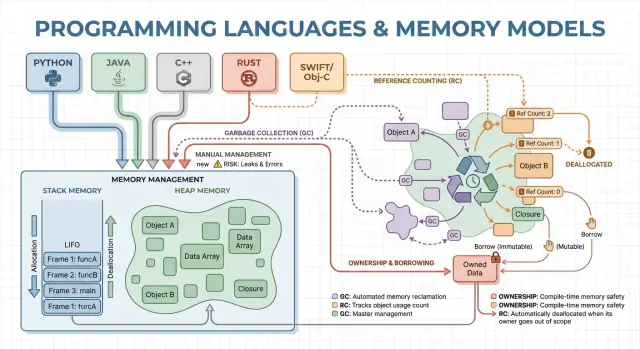
मेमोरी मैनेजमेंट वे नियम और तंत्र हैं जो एक प्रोग्राम मेमोरी का अनुरोध करने, उसे उपयोग करने और वापस करने के लिए इस्तेमाल करता है। हर चल रहा प्रोग्राम को वेरिएबल्स, यूज़र डेटा, नेटवर्क बफर्स, इमेजेज़ और मध्यवर्ती परिणामों जैसी चीज़ों के लिए मेमोरी चाहिए। चूँकि मेमोरी सीमित होती है और ऑपरेटिंग सिस्टम तथा अन्य एप्लिकेशंस के साथ साझा होती है, भाषाओं को यह तय करना होता है कि कौन मेमोरी को फ़्री करने का ज़िम्मेदार है और कब वह होता है।
ये निर्णय उन दो परिणामों को आकार देते हैं जिनकी ज्यादातर लोग परवाह करते हैं: प्रोग्राम कितना तेज़ लगता है, और दबाव में यह कितना विश्वसनीय व्यवहार करता है।
प्रदर्शन एक अकेला नंबर नहीं है। मेमोरी मैनेजमेंट निम्न चीज़ों को प्रभावित कर सकता है:
एक भाषा जो तेज़ी से अलोकेट करती है पर कभी-कभी क्लीनअप के लिए रुकती है, बेंचमार्क में शानदार दिख सकती है पर इंटरैक्टिव ऐप्स में झटकेदार महसूस हो सकती है। दूसरी मॉडल जो पॉज़ से बचती है, वह लीक और लाइफटाइम गलतियों को रोकने के लिए सतर्क डिज़ाइन की माँग कर सकती है।
सुरक्षा का मतलब है मेमोरी-संबंधी विफलताओं को रोकना, जैसे:
कई हाई-प्रोफ़ाइल सुरक्षा मुद्दे मेमोरी गलतियों जैसे use-after-free या बफ़र ओवरफ़्लो से जुड़े होते हैं।
यह गाइड लोकप्रिय भाषाओं में उपयोग किए जाने वाले मुख्य मेमोरी मॉडल का गैर-टेक्निकल परिचय है, वे किस चीज़ को ऑप्टिमाइज़ करते हैं, और जब आप किसी एक को चुनते हैं तो आप किन टेªड‑ऑफ को स्वीकार कर रहे हैं।
मेमोरी वह जगह है जहाँ आपका प्रोग्राम डेटा रखता है जब यह रन कर रहा होता है। अधिकांश भाषाएँ इसे दो मुख्य क्षेत्रों के इर्द-गिर्द व्यवस्थित करती हैं: स्टैक और हीप।
स्टैक को ऐसे सोचें जैसे मौजूदा काम के लिए चिपकने वाले नोट्स का एक साफ ढेर। जब कोई फ़ंक्शन शुरू होता है, उसे स्टैक पर उसके लोकल वेरिएबल्स के लिए एक छोटा “फ़्रेम” मिलता है। जब फ़ंक्शन समाप्त होता है, उस पूरे फ़्रेम को एक बार में हटा दिया जाता है।
यह तेज़ और पूर्वानुमानिक है—पर यह केवल उन वैल्यूज़ के लिए काम करता है जिनका साइज ज्ञात है और जिनका लाइफटाइम फ़ंक्शन कॉल के साथ समाप्त हो जाता है।
हीप अधिक एक स्टोरेज रूम जैसा है जहाँ आप ऑब्जेक्ट्स को तब तक रख सकते हैं जब तक आपको उनकी ज़रूरत हो। यह डायनामिक साइज की लिस्ट्स, स्ट्रिंग्स, या प्रोग्राम के विभिन्न हिस्सों में साझा ऑब्जेक्ट्स के लिए अच्छा है।
क्योंकि हीप ऑब्जेक्ट्स एक फ़ंक्शन से अधिक समय तक जीवित रह सकते हैं, प्रमुख सवाल बन जाता है: कौन उन्हें फ़्री करने का ज़िम्मेदार है, और कब? यही जिम्मेदारी एक भाषा का “मेमोरी मैनेजमेंट मॉडल” है।
एक पॉइंटर या रेफ़रेंस किसी ऑब्जेक्ट तक अप्रत्यक्ष पहुँच का तरीका है—जैसे स्टोरेज रूम में किसी बॉक्स की शेल्फ़ नंबर। अगर बॉक्स फेंक दिया गया लेकिन आपके पास शेल्फ़ नंबर बचा है, तो आप कचरा पढ़ सकते हैं या क्रैश कर सकते हैं (ये क्लासिक use-after-free बग हैं)।
कल्पना कीजिए एक लूप जो एक ग्राहक रिकॉर्ड बनाता है, एक संदेश फ़ॉर्मेट करता है, और फिर उसे छोड़ देता है:
कुछ भाषाएँ इन विवरणों को छिपाती हैं (स्वचालित क्लीनअप), जबकि अन्य इन्हें उजागर करती हैं (आप स्पष्ट रूप से मेमोरी फ़्री करते हैं, या आपको किसी ऑब्जेक्ट का मालिक कौन है यह नियमों के अनुसार रखना होता है)। इस लेख का शेष भाग इन विकल्पों के प्रभावों, स्पीड, पॉज़ और सुरक्षा के बारे में बताता है।
मैनुअल मेमोरी मैनेजमेंट का मतलब है कि प्रोग्राम (और इसलिए डेवलपर) स्पष्ट रूप से मेमोरी मांगता है और बाद में उसे रिलीज़ करता है। व्यवहार में यह C में malloc/free, या C++ में new/delete जैसा दिखता है। सिस्टम प्रोग्रामिंग में यह अभी भी आम है जहाँ आपको यह सटीक नियंत्रण चाहिए कि मेमोरी कब ली और लौटाई जाए।
आप आमतौर पर मेमोरी तब अलोकेट करते हैं जब कोई ऑब्जेक्ट वर्तमान फ़ंक्शन कॉल से अधिक समय तक रहना चाहिए, डायनामिक रूप से बढ़ता है (उदा., रिसाइज़ेबल बफ़र), या हार्डवेयर/OS/नेटवर्क प्रोटोकॉल के साथ इंटरऑप के लिए खास लेआउट की आवश्यकता होती है।
बैकग्राउंड में कोई गार्बेज कलेक्टर न होने से आश्चर्यजनक पॉज़ कम होते हैं। अलोकेशन और डीअलोकेशन को अत्यधिक पूर्वानुमानिक बनाया जा सकता है, विशेषकर जब कस्टम अलोकेटर्स, पूल्स, या फिक्स्ड-साइज़ बफ़र्स के साथ जोड़ा जाए।
मैनुअल नियंत्रण ओवरहेड भी घटा सकता है: कोई ट्रेसिंग फेज़ नहीं, कोई राइट बैरियर्स नहीं, और अक्सर ऑब्जेक्ट पर कम मेटाडेटा। जब कोड सावधानीपूर्वक डिज़ाइन किया जाता है, आप कड़े लेटेंसी लक्ष्यों को पकड़ सकते हैं और मेमोरी उपयोग को सख्त सीमाओं के भीतर रख सकते हैं।
व्यापारिक सौदा यह है कि रनटाइम स्वचालित रूप से गलतियों को रोकने वाला नहीं है:
ये बग्स क्रैश, डेटा करप्शन, और सुरक्षा समस्याएँ पैदा कर सकते हैं।
टीमें रिस्क कम करने के लिए रॉ अलोकेशन को सीमित करती हैं और पैटर्न्स पर भरोसा रखती हैं जैसे:
std::unique_ptr) ओनरशिप को एन्कोड करने के लिएमैनुअल मेमोरी मैनेजमेंट अक्सर एम्बेडेड सॉफ़्टवेयर, रियल-टाइम सिस्टम, OS घटक, और प्रदर्शन-क्रिटिकल लाइब्रेरीज़ के लिए मजबूत चुनाव होता है—ऐसी जगहें जहाँ सटीक नियंत्रण और पूर्वानुमानिक लेटेंसी डेवलपर सुविधा से ज़्यादा मायने रखती हैं।
गार्बेज कलेक्शन (GC) स्वचालित मेमोरी क्लीनअप है: रनटाइम ऑब्जेक्ट्स को ट्रैक करता है और उन ऑब्जेक्ट्स को रिक्लेम कर लेता है जो अब प्रोग्राम द्वारा पहुंच योग्य नहीं हैं। व्यवहार में इसका मतलब है कि आप व्यवहार और डेटा फ़्लो पर ध्यान दे सकते हैं जबकि सिस्टम अधिकांश अलोकेशन और डीअलोकेशन निर्णय संभालता है।
ज़्यादातर कलेक्टर्स पहले लाइव ऑब्जेक्ट्स की पहचान करते हैं, फिर बचे हुए को रिक्लेम करते हैं।
Tracing GC रूट्स (जैसे स्टैक वेरिएबल्स, ग्लोबल रेफ़रेंसेज़, रजिस्टर) से शुरू होकर रेफ़रेंस का पालन करता है, सब कुछ मार्क करता है जो पहुंच योग्य है, और फिर हीप को स्वीप करके अनमार्क्ड ऑब्जेक्ट्स को फ़्री कर देता है। यदि किसी ऑब्जेक्ट की ओर कुछ भी इशारा नहीं कर रहा है, तो वह कलेक्शन के लिए योग्य हो जाता है।
Generational GC इस अवलोकन पर आधारित है कि कई ऑब्जेक्ट्स जल्दी मरते हैं। यह हीप को जनरेशन में बाँटता है और युवा क्षेत्र को अक्सर कलेक्ट करता है, जो आमतौर पर सस्ता और अधिक कुशल होता है।
Concurrent GC कलेक्शन के हिस्सों को एप्लिकेशन थ्रेड्स के साथ-साथ चलाता है, ताकि लंबे पॉज़ को कम किया जा सके। यह मेमोरी का निरंतर दृश्य बनाए रखने के लिए अधिक बुककीपिंग कर सकता है।
GC आमतौर पर मैनुअल नियंत्रण के बदले रनटाइम काम लेता है। कुछ सिस्टम स्थिर थ्रूपुट को प्राथमिकता देते हैं (प्रति सेकंड बहुत सारा काम पूरा करना) पर स्टॉप-दे-वर्ल्ड पॉज़ पेश कर सकते हैं। अन्य लेटेंसी-संवेदी ऐप्स के लिए पॉज़ को न्यूनतम करने की कोशिश करते हैं पर सामान्य निष्पादन के दौरान अतिरिक्त ओवरहेड जोड़ सकते हैं।
GC जीवनकाल वाली एक पूरी श्रेणी की गलतियों को हटा देता है (खासकर use-after-free), क्योंकि ऑब्जेक्ट्स तब तक रिक्लेम नहीं होते जब तक कि वे पहुँच योग्य न हों। यह मिस्ड डीलोकेशन्स से होने वाले लीक को भी घटाता है (हालाँकि आप अभी भी रेफ़रेंसेज़ को अनायास लंबे समय तक रखकर “लीक” कर सकते हैं)। बड़े कोडबेस में जहाँ ओनरशिप मैन्युअली ट्रैक करना कठिन होता है, यह अक्सर इंटरेशन को तेज करता है।
गार्बेज-कलेक्टेड रनटाइम्स JVM (Java, Kotlin), .NET (C#, F#), Go, और ब्राउज़र तथा Node.js के JavaScript इंजिन में सामान्य हैं।
रेफ़रेंस काउंटिंग वह रणनीति है जहाँ हर ऑब्जेक्ट ट्रैक करता है कि उस पर कितने “ओनर्स” (रेफ़रेंस) हैं। जब काउंट शून्य पर पहुँचता है, ऑब्जेक्ट तुरंत फ़्री हो जाता है। यह तत्क्षणीयता सहज लग सकती है: जैसे ही कुछ भी किसी ऑब्जेक्ट तक नहीं पहुँच सकता, उसकी मेमोरी रिक्लेम हो जाती है।
हर बार जब आप किसी ऑब्जेक्ट की रेफ़रेंस कॉपी करते हैं या स्टोर करते हैं, रनटाइम उसका काउंटर बढ़ाता है; जब रेफ़रेंस चला जाता है, वह घटता है। शून्य होने पर तुरंत क्लीनअप ट्रिगर होता है।
इससे रिसोर्स मैनेजमेंट सीधा हो जाता है: ऑब्जेक्ट्स अक्सर उस समय के करीब रिलीज़ होते हैं जब आप उनका उपयोग बंद कर देते हैं, जिससे पीक मेमोरी उपयोग घट सकता है और विलंबित रिक्लेम से बचा जा सकता है।
रेफ़रेंस काउंटिंग के साथ आमतौर पर स्थिर, निरंतर ओवरहेड मिलता है: इनक्रिमेंट/डीक्रिमेंट ऑपरेशन कई असाइनमेंट्स और फ़ंक्शन कॉल्स पर होते हैं। यह ओवरहेड आमतौर पर छोटा होता है, पर यह हर जगह होता है।
फायदा यह है कि आपको आमतौर पर उन बड़े स्टॉप-दे-वर्ल्ड पॉज़ का सामना नहीं करना पड़ता जो कुछ ट्रेसिंग GC कराते हैं। लेटेंसी अक्सर स्मूद होती है, हालांकि बड़े ऑब्जेक्ट ग्राफ़ के एक साथ डीअलोकेशन होने पर अभी भी बर्स्ट हो सकते हैं।
रेफ़रेंस काउंटिंग उन ऑब्जेक्ट्स को रिक्लेम नहीं कर सकती जो साईकल में हैं। यदि A B को रेफ़र करता है और B A को रेफ़र करता है, तो दोनों काउंट शून्य से ऊपर बने रहते हैं भले ही बाकी कुछ भी उन्हें न पहुंचा रहा हो—इससे मेमोरी लीक बनता है।
इकोसिस्टम इसे कुछ तरीकों से संभालते हैं:
स्वामित्व और बरोइंग का मॉडल सबसे नज़दीकी रूप से Rust से जुड़ा है। आइडिया सरल है: कंपाइलर ऐसे नियम लागू करता है कि dangling pointers, डबल-फ्री, और कई डेटा-रेस बनना मुश्किल हो जाता है—और यह सब रनटाइम GC पर निर्भर किए बिना।
हर वैल्यू का एक ही "ओनर" होता है। जब ओनर स्कोप से बाहर हो जाता है, वैल्यू तुरंत और पूर्वानुमानिक रूप से क्लीनअप हो जाती है। इससे आपको मैनुअल क्लीनअप जैसी निश्चित रिसोर्स मैनेजमेंट मिलती है, पर बहुत कम गलतियों की गुंजाइश होती है।
ओनरशिप मूव भी कर सकती है: किसी वैरिएबल को नई वैरिएबल में असाइन करने या फ़ंक्शन में पास करने पर जिम्मेदारी ट्रांसफर हो सकती है। मूव के बाद पुराना बाइंडिंग उपयोग नहीं किया जा सकता, जिससे use-after-free स्वाभाविक रूप से रोका जाता है।
बरोइंग आपको किसी वैल्यू का उपयोग करने देता है बिना उसका ओनर बनें।
एक शेयर्ड बॉरो पढ़ने के लिए अनुमति देता है और स्वतंत्र रूप से कॉपी किया जा सकता है।
एक म्यूटेबल बॉरो अपडेट की अनुमति देता है, पर उसे विशेष होना चाहिए: जब यह मौजूद है, तब उसी वैल्यू को न पढ़ने न लिखने देने की शर्त होती है। यह "एक लेखक या कई रीडर्स" का नियम कंपाइल‑टाइम पर चेक होता है।
क्योंकि लाइफटाइम्स ट्रैक होते हैं, कंपाइलर ऐसे कोड को अस्वीकार कर सकता है जो उस डेटा से ज़्यादा समय जीवित रह जाएगा जिसका वह रेफ़रेंस कर रहा है—इससे कई dangling-reference बग ख़त्म हो जाते हैं। यही नियम समवर्ती कोड में कई रेस कंडीशंस को भी रोकते हैं।
ट्रेड‑ऑफ सीखने की कर्व और कुछ डिज़ाइन पाबंदियाँ हैं। आपको डेटा फ़्लो को पुनर्गठित करना पड़ सकता है, स्पष्ट ओनरशिप सीमाएँ तय करनी पड़ सकती हैं, या साझा म्यूटेबल स्टेट के लिए विशेष प्रकारों का उपयोग करना पड़ सकता है।
यह मॉडल सिस्टम कोड—सर्विसेज, एम्बेडेड, नेटवर्किंग, और प्रदर्शन‑संवेदी घटकों—के लिए उपयुक्त है जहाँ आप GC पॉज़ के बिना पूर्वानुमानिक क्लीनअप और कम लेटेंसी चाहते हैं।
जब आप बहुत सारी छोटी‑उम्र की ऑब्जेक्ट्स बनाते हैं—पार्सर में AST नोड्स, गेम फ़्रेम में एंटिटीज़, वेब रिक्वेस्ट के दौरान अस्थायी डेटा—तो प्रत्येक ऑब्जेक्ट को अलग से अलोकेट और फ़्री करने का ओवरहेड रनटाइम को डोमिनेट कर सकता है। एरीनाज़ (रीजन) और पूल्स ऐसे पैटर्न हैं जो फाइन‑ग्रैन्ड फ्रीज़ के बदले तेज़ बल्क मैनेजमेंट के लिए ट्रेड करते हैं।
एरीना एक मेमोरी "ज़ोन" है जहाँ आप समय के साथ कई ऑब्जेक्ट्स अलोकेट करते हैं, फिर सभी को एक साथ रिलीज़ कर देते हैं जब आप एरीना को ड्रॉप या रीसेट करते हैं।
पर‑ऑब्जेक्ट लाइफटाइम को व्यक्तिगत तौर पर ट्रैक करने की बजाय आप लाइफटाइम को एक स्पष्ट सीमा से जोड़ देते हैं: "इस रिक्वेस्ट के लिए अलोकेट की गई सब चीज़ें", या "इस फ़ंक्शन की कंपाइलेशन के दौरान अलोकेट की गई सब चीज़ें"।
एरीनाज़ अक्सर तेज़ होती हैं क्योंकि वे:
यह थ्रूपुट सुधार सकता है, और बार-बार फ्रीज़ या अलोकेटर कंटेंशन से होने वाले लेटेंसी स्पाइक्स को कम कर सकता है।
एरीनाज़ और पूल्स निम्न जगहों पर मिलते हैं:
मुख्य नियम सरल है: किसी रीजन में अलोकेट की गई चीज़ों की रेफ़रेंस को उस रीजन की लाइफटाइम से बाहर न जाने दें। अगर कोई चीज़ ग्लोबली स्टोर हो जाती है या रीजन के जीवनकाल के बाद रिटर्न कर दी जाती है, तो आप use-after-free बग का जोखिम उठाते हैं।
भिन्न भाषाएँ और लाइब्रेरीज़ इसे अलग‑अलग संभालती हैं: कुछ अनुशासन और API पर भरोसा करती हैं, अन्य प्रकारों के माध्यम से रीजन बॉर्डर को एन्कोड कर सकती हैं।
एरीनाज़ और पूल्स GC या स्वामित्व के विकल्प नहीं हैं—ये अक्सर पूरक होते हैं। GC भाषाएँ अक्सर हॉट पाथ्स के लिए ऑब्जेक्ट पूल्स का उपयोग करती हैं; स्वामित्व‑आधारित भाषाएँ एरीनाज़ का उपयोग करके अलोकेशंस को समूहित कर सकती हैं और लाइफटाइम्स को स्पष्ट कर सकती हैं। सावधानी से उपयोग करने पर ये "डिफ़ॉल्ट रूप से तेज़" अलोकेशन प्रदान करते हैं बिना यह खोए कि मेमोरी कब रिलीज़ होगी।
किसी भाषा का मेमोरी मॉडल प्रदर्शन और सुरक्षा की कहानी का केवल एक हिस्सा है। आधुनिक कंपाइलर और रनटाइम आपके प्रोग्राम को इस तरह से पुनर्लेखन करते हैं कि कम अलोकेट किया जाए, जल्दी फ़्री किया जाए, और अतिरिक्त बुककीपिंग से बचा जा सके। इसलिए "GC धीमा है" या "मैनुअल मेमोरी सबसे तेज़ है" जैसे नियम‑कानून वास्तविक अनुप्रयोगों में अक्सर टूट जाते हैं।
कई अलोकेशन केवल फ़ंक्शन्स के बीच डेटा पास करने के लिए होते हैं। Escape analysis के साथ, कंपाइलर यह साबित कर सकता है कि कोई ऑब्जेक्ट वर्तमान स्कोप से बाहर नहीं निकलता और उसे हीप के बजाय स्टैक पर रखा जा सकता है।
यह एक हीप अलोकेशन और उससे जुड़ी लागतें (GC ट्रैकिंग, रेफ़रेंस काउंट अपडेट, अलोकेटर लॉक) पूरी तरह हटा सकता है। मैनेज्ड भाषाओं में यह मुख्य कारण है कि छोटे ऑब्जेक्ट्स अपेक्षित से सस्ते हो सकते हैं।
जब कंपाइलर कोई फ़ंक्शन इनलाइन करता है (कॉल को फ़ंक्शन बॉडी से बदल देता है), तो वह अब परतों के पार देख सकता है। उस दृश्यता से निम्न जैसी ऑप्टिमाइज़ेशन संभव होती हैं:
अच्छी तरह डिज़ाइन किए गए API ऑप्टिमाइज़ेशन के बाद “ज़ीरो‑कॉस्ट” बन सकते हैं, भले ही स्रोत कोड में वे भारी दिखाई दें।
JIT रनटाइम वास्तविक प्रोडक्शन डेटा (हॉट कोड पाथ्स, सामान्य ऑब्जेक्ट साइज़, अलोकेशन पैटर्न) के आधार पर ऑप्टिमाइज़ कर सकता है। इससे अक्सर थ्रूपुट बेहतर होता है, पर यह वार्म‑अप समय और कभी‑कभी री‑कम्पाइल या GC के लिए पॉज़ जोड़ सकता है।
AOT कंपाइलर्स को पहले अनुमान लगाना पड़ता है, पर वे पूर्वानुमानिक स्टार्टअप और स्थिर लेटेन्सी देते हैं।
GC‑आधारित रनटाइम्स हीप साइज़िंग, पॉज़‑टाइम लक्ष्यों, और जनरेशन थ्रेशोल्ड जैसी सेटिंग्स उजागर करते हैं। इन्हें तब छुएँ जब आपके पास मापी गई वजह हो (उदा., लेटेंसी स्पाइक्स या मेमोरी प्रेशर), न कि पहले कदम के रूप में।
एक ही एल्गोरिथम के दो इम्प्लीमेंटेशन छिपे हुए अलोकेशन काउंट्स, अस्थायी ऑब्जेक्ट्स, और पॉइंटर‑चेजिंग में भिन्न हो सकते हैं। ये भिन्नताएँ ऑप्टिमाइज़र, अलोकेटर, और कैश व्यवहार के साथ इंटरैक्ट करती हैं—इसलिए प्रदर्शन तुलना के लिए प्रोफाइलिंग ज़रूरी है, अनुमान नहीं।
मेमोरी मैनेजमेंट विकल्प सिर्फ यह नहीं बदलते कि आप कैसे कोड लिखते हैं—ये यह भी बदलते हैं कि काम कब होता है, आपको कितनी मेमोरी रिज़र्व करनी पड़ती है, और उपयोगकर्ताओं के लिए प्रदर्शन कितना सुसंगत महसूस होता है।
थ्रूपुट है “एक यूनिट समय में कितना काम।” कल्पना कीजिए एक रातभर चलने वाली बैच जॉब जो 10 मिलियन रिकॉर्ड प्रोसेस करती है: अगर GC या रेफ़रेंस काउंटिंग थोड़ा बहुत ओवरहेड जोड़ता है पर डेवलपर उत्पादकता तेज़ रखता है, तो कुल मिलाकर आप अभी भी तेज़ी से खत्म कर सकते हैं।
लेटेंसी है “एक ऑपरेशन का एंड‑टू‑एंड कितना समय लेता है।” एक वेब रिक्वेस्ट के लिए, एक धीमा जवाब उपयोगकर्ता अनुभव को नुकसान पहुँचाता है भले ही औसत थ्रूपुट उच्च हो। एक रनटाइम जो कभी‑कभी मेमोरी रिक्लेम के लिए रुकता है बैच प्रोसेसिंग के लिए ठीक हो सकता है, पर इंटरैक्टिव ऐप्स में यह नोटिसेबल हो सकता है।
बड़ी मेमोरी फ़ुटप्रिंट क्लाउड लागत बढ़ाती है और प्रोग्रामों को धीमा कर सकती है। जब आपका वर्किंग सेट CPU कैश में ठीक से नहीं बैठता, CPU अक्सर RAM से डेटा का इंतज़ार करता है। कुछ रणनीतियाँ गति के लिए अतिरिक्त मेमोरी का व्यापार करती हैं (उदा., फ्री किए गए ऑब्जेक्ट्स को पूल में रखना), जबकि अन्य मेमोरी घटाने के लिए बुककीपिंग ओवरहेड जोड़ती हैं।
फ्रैगमेंटेशन तब होती है जब खाली मेमोरी कई छोटे‑छोटे गैप्स में बँट जाती है—जैसे एक पार्किंग लॉट में बिखरे छोटे‑छोटे स्पॉट्स में वैन पार्क करने की कोशिश करना। अलोकेटर्स को स्थान खोजने में अधिक समय लग सकता है, और मेमोरी बढ़ सकती है भले ही "काफ़ी" तकनीकी रूप से उपलब्ध हो।
कैश लोकैलिटी का मतलब है संबंधित डेटा पास‑पास बैठा हो। पूल/एरीना अलोकेशन अक्सर लोकैलिटी सुधारता है (एक साथ अलोकेट हुए ऑब्जेक्ट्स पास‑पास रहने की संभावना), जबकि मिश्रित साइज़ वाले लंबे‑जीव हीप धीरे‑धीरे कैश‑अनुकूल लेआउट से दूर हो सकते हैं।
यदि आपको सुसंगत रिस्पॉन्स‑टाइम चाहिए—गेम्स, ऑडियो ऐप्स, ट्रेडिंग सिस्टम्स, एम्बेडेड या रियल‑टाइम कंट्रोलर—तो "अधिकतर तेज़ पर कभी‑कभार धीमा" अक्सर "थोड़ा धीमा पर सुसंगत" से बदतर होता है। ऐसे मामलों में पूर्वानुमानिक डीअलोकेशन पैटर्न और अलोकेशंस पर सख्त नियंत्रण मायने रखता है।
मेमोरी त्रुटियाँ केवल "डेवलपर की गलती" नहीं हैं। कई वास्तविक सिस्टमों में वे सुरक्षा समस्याओं में बदल जाती हैं: अचानक क्रैश (डेनियल‑ऑफ़‑सर्विस), आकस्मिक डेटा उजागर होना (फ़्री या अनइनिशियलाइज़्ड मेमोरी पढ़ना), या ऐसे हालात जहाँ हमलावर प्रोग्राम को अनपेक्षित कोड चलाने के लिए मोड़ देते हैं।
विभिन्न मेमोरी‑मैनेजमेंट रणनीतियाँ अलग‑अलग तरीके से फेल होती हैं:
समवर्तीता खतरे के मॉडल को बदल देती है: एक थ्रेड में "ठीक" लगने वाली मेमोरी दूसरी थ्रेड द्वारा फ्री या म्यूटेट होने पर खतरनाक बन सकती है। जो मॉडल शेयरिंग के नियम लागू करते हैं (या स्पष्ट सिंक्रोनाइज़ेशन की आवश्यकता रखते हैं) वे उन रेस कंडीशंस के अवसर घटाते हैं जो करप्टेड स्टेट, डेटा लीक, और इंटरमिटेंट क्रैश का कारण बनते हैं।
कोई भी मेमोरी मॉडल सब जोखिम नहीं हटाता—लॉजिक बग्स (ऑथ गलतियाँ, असुरक्षित डिफॉल्ट्स, खराब वैलिडेशन) अभी भी होते हैं। मजबूत टीमें कई सुरक्षात्मक परतें लगाती हैं: परीक्षण में सैनिटाइज़र्स, सुरक्षित स्टैण्डर्ड लाइब्रेरीज़, कड़ाई से कोड रिव्यू, फ़ज़िंग, और अनसेफ़/FFI कोड के आसपास सख्त सीमाएँ। मेमोरी सुरक्षा हमला सतह को भारी हद तक घटाती है, पर यह कोई पूर्ण गारंटी नहीं है।
मेमोरी समस्याएँ उस परिवर्तन के नज़दीक पकड़ी जाएँ तो आसानी से ठीक होती हैं जिसने उन्हें जन्म दिया। कुंजी है पहले मापना, फिर समस्या को सही टूल के साथ संकुचित करना।
पहले तय करें कि आप स्पीड या मेमोरी ग्रोथ का पीछा कर रहे हैं।
परफॉर्मेंस के लिए वॉल‑क्लॉक टाइम, CPU टाइम, अलोकेशन रेट (bytes/sec), और GC या अलोकेटर में बिताया गया समय मापें। मेमोरी के लिए पीक RSS, स्टेडी‑स्टेट RSS, और समय के साथ ऑब्जेक्ट काउंट ट्रैक करें। समान इनपुट के साथ वही वर्कलोड चलाएँ; छोटे‑बदलाव अलोकेशन चर्न को छिपा सकते हैं।
साझा संकेत: एक रिक्वेस्ट अपेक्षा से अधिक अलोकेट कर रहा है, या ट्रैफ़िक के साथ मेमोरी बढ़ रही है भले ही थ्रूपुट स्थिर हो। फिक्सेस में अक्सर बफ़र्स को पुन: उपयोग करना, शॉर्ट‑लाइव ऑब्जेक्ट्स के लिए एरीना/पूल का उपयोग करना, और ऑब्जेक्ट ग्राफ़ को सरल बनाकर कम ऑब्जेक्ट्स को साइकिल्स पार कराना शामिल है।
एक न्यूनतम इनपुट के साथ पुनरुत्पादन करें, सबसे कड़े रनटाइम चेक (सैनिटाइज़र्स/GC सत्यापन) सक्षम करें, फिर कैप्चर करें:
पहली फिक्स को एक प्रयोग मानकर चलाएँ; माप फिर से करें कि बदलाव ने अलोकेशन्स घटाए या मेमोरी को स्थिर किया—बिना समस्या को कहीं और धकेले। और ट्रेड‑ऑफ की व्याख्या के लिए देखें /blog/performance-trade-offs-throughput-latency-memory-use।
भाषा चुनना सिर्फ़ सिनटैक्स या इकोसिस्टम के बारे में नहीं है—उसका मेमोरी मॉडल रोज़मर्रा के विकास की गति, परिचालन जोखिम, और वास्तविक ट्रैफ़िक के तहत प्रदर्शन की पूर्वानुमानिकता को आकार देता है।
अपने प्रॉडक्ट की आवश्यकताओं को मेमोरी रणनीति से मैप करें इन व्यावहारिक सवालों का उत्तर देकर:
यदि आप मॉडल बदल रहे हैं, तो घर्षण की योजना बनाएं: मौजूदा लाइब्रेरीज़ (FFI) को कॉल करना, मिश्रित मेमोरी कन्वेंशन्स, टूलिंग, और हायरिंग मार्केट। प्रोटोटाइप छिपे हुए लागतों (पॉज़, मेमोरी ग्रोथ, CPU ओवरहेड) को जल्दी उजागर करने में मदद करते हैं।
एक व्यावहारिक तरीका यह है कि आप जिन एनवायरनमेंट्स पर विचार कर रहे हैं उनमें उसी फीचर का छोटा‑प्रोटोटाइप बनाएं और प्रतिनिधि लोड पर अलोकेशन रेट, टेल लेटेंसी, और पीक मेमोरी की तुलना करें। टीमें कभी‑कभी इस तरह का “सेब्स‑टू‑सेब्स” मूल्यांकन करती हैं: Koder.ai जैसी सर्विस में आप जल्दी से एक छोटा React फ्रंट‑एंड प्लस Go + PostgreSQL बैकएंड स्कैफ़ोल्ड कर सकते हैं, फिर रिक्वेस्ट शेप्स और डेटा स्ट्रक्चर्स पर इटरेट करके देख सकते हैं कि GC‑आधारित सर्विस किस तरह व्यवहार करती है (और जब आप आगे बढ़ने के लिए तैयार हों तो स्रोत कोड एक्सपोर्ट कर सकते हैं)।
शीर्ष 3–5 बाधाओं को परिभाषित करें, एक पतला प्रोटोटाइप बनाएं, और मापें: मेमोरी उपयोग, टेल लेटेंसी, और फेल्योर मोड्स।
| मॉडल | डिफ़ॉल्ट रूप से सुरक्षा | लेटेंसी की पूर्वानुमानिकता | डेवलपर स्पीड | सामान्य समस्याएँ |
|---|---|---|---|---|
| मैनुअल | कम–मध्यम | उच्च | मध्यम | लीक, use-after-free |
| GC | उच्च | मध्यम | उच्च | पॉज़, हीप ग्रोथ |
| RC | मध्यम–उच्च | उच्च | मध्यम | साइकल्स, ओवरहेड |
| स्वामित्व | उच्च | उच्च | मध्यम | सीखने की कर्व |
मेमोरी मैनेजमेंट यह बताता है कि कोई प्रोग्राम डेटा (ऑब्जेक्ट, स्ट्रिंग, बफर आदि) के लिए मेमोरी कैसे आवंटित करता है और जब वह जरूरत नहीं रहती तो उसे कैसे रिलीज़ करता है।
यह प्रभावित करता है:
स्टैक तेज़, स्वतः और फ़ंक्शन कॉल्स से जुड़ा होता है: जब एक फ़ंक्शन लौटता है, उसका पूरा स्टैक फ़्रेम एक बार में हट जाता है।
हीप डायनामिक और लंबी-उम्र के डेटा के लिए लचीला है, लेकिन इसे यह तय करने की ज़रूरत होती है कि कब और कौन उसे फ़्री करेगा।
एक सामान्य नियम: स्टैक छोटे-जीवन और निश्चित-आकार लोकल्स के लिए बढ़िया है; हीप उन चीज़ों के लिए उपयोग होता है जिनकी लाइफटाइम या साइज अनिश्चित हों।
एक रिफ़रेंस/पॉइंटर कोड को किसी ऑब्जेक्ट तक अप्रत्यक्ष पहुँच देने देता है। ख़तरा तब आता है जब ऑब्जेक्ट की मेमोरी रिलीज़ हो गई हो लेकिन रिफ़रेंस अभी भी इस्तेमाल हो रहा हो।
इससे हो सकता है:
आप स्पष्ट रूप से मेमोरी आवंटित और रिलीज़ करते हैं (उदा., malloc/free, new/delete)।
यह उपयोगी है जब आपको चाहिए:
कीमत: यदि ओनरशिप और लाइफटाइम्स सही तरीके से नहीं संभाले गए तो बग्स आने का खतरा ज़्यादा होता है।
यदि प्रोग्राम अच्छी तरह से डिज़ाइन किया गया है तो मैनुअल मैनेजमेंट बहुत ही पूर्वानुमानिक लेटेंसी दे सकता है, क्योंकि बैकग्राउंड में कोई GC साइकिल नहीं चलती।
आप इसे ऑप्टिमाइज़ कर सकते हैं:
परन्तु गलती से महंगे पैटर्न बनाना भी आसान है (फ्रैगमेंटेशन, अलोकेटर कंटेंशन, बहुत सी छोटी अलोकेशन/फ्री कॉल्स)।
गार्बेज कलेक्शन स्वचालित मेमोरी क्लीनअप है: रनटाइम ट्रैक करता है कि कौन-से ऑब्जेक्ट्स पहुंच योग्य हैं और जिन तक पहुँचा नहीं जा सकता उन्हें वापस ले लेता है।
ज़्यादातर ट्रेसिंग GC इस तरह काम करता है:
यह आमतौर पर सुरक्षा बढ़ाता है (कम use-after-free), पर रनटाइम में काम जोड़ेगा और कलेक्टर के डिज़ाइन के हिसाब से पॉज़ आ सकती हैं।
रेफ़रेंस काउंटिंग तब काम करता है जब हर ऑब्जेक्ट ट्रैक करता है कि उस पर कितने “ओनर्स” (रिफ़रेंसेज़) हैं। काउंट ज़ीरो होने पर ऑब्जेक्ट तुरंत फ़्री हो जाता है।
फायदे:
नुकसान:
स्वामित्व और उधारी (ownership और borrowing) वह मॉडल है जो मुख्यतः Rust से जुड़ा है। कंपाइलर ऐसे नियम लागू करता है जो dangling pointers, डबल-फ्री और कई डेटा-रेस को रोकते हैं—बाकी सब बिना रनटाइम GC पर निर्भर हुए।
मुख्य विचार:
यह GC के बिना पूर्वानुमानित क्लीनअप देता है, पर इसके लिये सीखने की कर्व और कुछ डिज़ाइन समायोजन की आवश्यकता होती है।
एक एरीना/रीजन बहुत सारी ऑब्जेक्ट्स को एक “ज़ोन” में अलोकेट करता है, और फिर सबको एक साथ छोड़ दिया जाता है या रीसेट किया जाता है।
यह तब प्रभावी है जब आपके पास एक स्पष्ट लाइफटाइम सीमा हो, जैसे:
मुख्य सुरक्षा नियम: एरीना की लाइफटाइम से कहीं बाहर रेफ़रेंस न निकलें।
रियल लोड पर मापें:
फिर टार्गेटेड टूल्स का उपयोग करें:
कई ईकोसिस्टम्स कमजोर रेफ़रेंस या साइकल डिटेक्टर का उपयोग करके इसे कम करते हैं।
रनटाइम सेटिंग (जैसे GC पैरामीटर) तब ही ट्यून करें जब मापा हुआ समस्या सामने हो।