11 मार्च 2025·8 मिनट
ऑपरेशनल जोखिम ट्रैकिंग के लिए वेब ऐप कैसे बनाएं
ऑपरेशनल जोखिम ट्रैकिंग वेब ऐप डिज़ाइन, बनाने और लॉन्च करने के चरण-दर-चरण योजना: आवश्यकताएँ, डेटा मॉडल, वर्कफ़्लो, कंट्रोल्स, रिपोर्टिंग और सुरक्षा।
ऑपरेशनल जोखिम ट्रैकिंग वेब ऐप डिज़ाइन, बनाने और लॉन्च करने के चरण-दर-चरण योजना: आवश्यकताएँ, डेटा मॉडल, वर्कफ़्लो, कंट्रोल्स, रिपोर्टिंग और सुरक्षा।
स्क्रीन डिज़ाइन या टेक स्टैक चुनने से पहले यह स्पष्ट कर लें कि आपकी संस्था में “ऑपरेशनल जोखिम” का क्या मतलब है। कुछ टीमें इसे प्रक्रिया विफलताओं और मानव त्रुटि तक सीमित रखती हैं; अन्य इसमें आईटी आउटेज, विक्रेता समस्याएँ, धोखाधड़ी या बाहरी घटनाएँ भी शामिल करती हैं। यदि परिभाषा धुंधली है, तो आपका ऐप एक डम्पिंग ग्राउंड बन जाएगा—और रिपोर्टिंग अविश्वसनीय हो जाएगी।
लिखित स्पष्ट बयान लिखें कि क्या ऑपरेशनल जोखिम माना जाएगा और क्या नहीं। आप इसे चार बकेट (प्रक्रिया, लोग, सिस्टम, बाहरी घटनाएँ) के रूप में फ्रेम कर सकते हैं और हर एक के लिए 3–5 उदाहरण जोड़ सकते हैं। यह बाद में बहसों को कम करता है और डेटा को सुसंगत रखता है।
विशिष्ट रूप से बताएं कि ऐप को क्या हासिल करना चाहिए। आम लक्ष्यों में शामिल हैं:
यदि आप परिणाम वर्णन नहीं कर सकते, तो संभवतः वह सुविधानुरोध (feature request) है—जरूरत नहीं।
उन रोल्स की सूची बनाएं जो ऐप का उपयोग करेंगे और उन्हें क्या सबसे ज़रूरी है:
यह “हर किसी” के लिए बनाने और किसी को संतुष्ट न करने से रोकता है।
ऑपरेशनल जोखिम ट्रैकिंग के लिए एक व्यावहारिक v1 आम तौर पर इन पर केंद्रित होता है: एक रिस्क रजिस्टर, बेसिक रिस्क स्कोरिंग, एक्शन ट्रैकिंग, और सरल रिपोर्टिंग। गहरी क्षमताएँ (उन्नत इंटीग्रेशन, जटिल टैक्सोनोमी मैनेजमेंट, कस्टम वर्कफ़्लो बिल्डर) बाद के चरणों के लिए रखें।
मापने योग्य संकेत चुनें जैसे: मालिक वाले जोखिम का प्रतिशत, रिस्क रजिस्टर की पूर्णता, कार्रवाइयों को बंद करने का समय, ओवरड्यू एक्शन रेट, और समय पर समीक्षा पूर्णता। ये मीट्रिक यह आकलन करना आसान बनाती हैं कि ऐप काम कर रहा है—और अगला सुधार क्या होना चाहिए।
एक रिस्क रजिस्टर वेब ऐप तभी काम करता है जब यह उसी तरीके से मेल खाता है जिस तरह लोग वास्तव में ऑपरेशनल जोखिम की पहचान, आकलन और फॉलो-अप करते हैं। फीचर्स की बात करने से पहले उन लोगों से बात करें जो इसे इस्तेमाल करेंगे (या जिनका आकलन आउटपुट से होगा)।
एक छोटा, प्रतिनिधि समूह से शुरू करें:
वर्कशॉप में वास्तविक वर्कफ़्लो को चरण-दर-चरण मैप करें: risk identification → assessment → treatment → monitoring → review। वहां जहाँ निर्णय होते हैं (कौन क्या मंजूर करता है), “डन” क्या दिखता है, और क्या ट्रिगर करता है रिव्यू (समय-आधारित, घटना-आधारित, या थ्रेशोल्ड-आधारित) यह कैप्चर करें।
स्टेकहोल्डर्स से वर्तमान स्प्रेडशीट या ईमेल ट्रेल दिखाने को कहें। ठोस मुद्दों का दस्तावेज़ बनाएं जैसे:
न्यूनतम वर्कफ़्लोज़ लिखें जो ऐप को सपोर्ट करना चाहिए:
देर होने से रोकने के लिए प्रारंभ में आउटपुट पर सहमति बनाएं। सामान्य जरूरतों में शामिल हैं बोर्ड सारांश, बिज़नेस-यूनिट व्यू, ओवरड्यू एक्शन्स, और ऊपर के जोखिम स्कोर या ट्रेंड द्वारा।
किसी भी नियम को सूचीबद्ध करें जो आवश्यकताओं को आकार देता है—उदा., डेटा रिटेंशन पीरियड, घटना डेटा के लिए गोपनीयता प्रतिबंध, कर्तव्यों का पृथक्करण, अनुमोदन साक्ष्य, और क्षेत्र या इकाई द्वारा एक्सेस प्रतिबंध। तथ्य पर केंद्रित रहें: आप बाध्यताओं को इकट्ठा कर रहे हैं, स्वतः ही अनुपालन का दावा नहीं कर रहे।
स्क्रीन या वर्कफ़्लो बनाने से पहले उस शब्दावली पर सहमति बनाएं जिसे आपका ऑपरेशनल रिस्क ट्रैकिंग ऐप लागू करेगा। स्पष्ट शब्दावली “एक ही जोखिम, अलग शब्द” जैसी समस्याओं को रोकती है और रिपोर्टिंग भरोसेमंद बनाती है।
परिभाषित करें कि जोखिम कैसे समूहित और फ़िल्टर होंगे। इसे रोज़मर्रा के स्वामित्व के साथ-साथ डैशबोर्ड और रिपोर्ट्स के लिए उपयोगी रखें।
सामान्य टैक्सोनॉमी लेवल में category → subcategory शामिल होते हैं, जिन्हें बिज़नेस यूनिट्स और जहाँ मददगार हो प्रक्रियाएँ/प्रोडक्ट/लोकेशन से मैप करें। बहुत विस्तृत टैक्सोनॉमी से बचें जिससे उपयोगकर्ता लगातार चुन न सकें; पैटर्न उभरने पर आप बाद में परिष्कृत कर सकते हैं।
एक संगत रिस्क स्टेटमेंट फ़ॉर्मैट पर सहमति बनाएं (उदा., “Due to cause, event may occur, leading to impact”) और फिर तय करें क्या अनिवार्य होगा:
यह संरचना कंट्रोल और घटनाओं को एकल कथा से जोड़ती है बजाय बिखरे नोट्स के।
निर्धारित करें कि आप किन आकलन आयामों का समर्थन करेंगे। न्यूनतम के रूप में Likelihood और Impact रखें; Velocity और Detectability तब जोड़ें जब टीमें उन्हें नियमित रूप से सुसंगत रूप से रेट कर सकें।
इनेरेंट बनाम रेसिडुअल रिस्क कैसे हैंडल करेंगे यह तय करें। एक सामान्य दृष्टिकोण: कंट्रोल्स से पहले का स्कोर inherent, और कंट्रोल्स के बाद का स्कोर residual; कंट्रोल्स को स्पष्ट रूप से लिंक करें ताकि लॉजिक रिव्यू और ऑडिट में समझने योग्य रहे।
अंत में, सरल रेटिंग स्केल (अक्सर 1–5) पर सहमति बनाएं और हर स्तर के लिए सामान्य भाषा में परिभाषाएँ लिखें। अगर “3 = मध्यम” का हर टीम के लिए अलग मतलब है तो आपका आकलन शोर पैदा करेगा न कि जानकारी।
एक स्पष्ट डेटा मॉडल ही स्प्रेडशीट-शैली रजिस्टर को भरोसेमंद सिस्टम में बदलता है। छोटे कोर रिकॉर्ड्स, साफ़ रिश्ते, और सुसंगत रेफ़रेंस सूचियाँ रखें ताकि रिपोर्टिंग उपयोग बढ़ने पर भी विश्वसनीय रहे।
कुछ तालिकाओं से शुरू करें जो सीधे काम के तरीके से मैप हों:
मुख्य many-to-many लिंक स्पष्ट रूप से मॉडल करें:
यह संरचना ऐसे प्रश्नों का समर्थन करती है जैसे “कौन से कंट्रोल हमारे शीर्ष जोखिमों को कम करते हैं?” और “कौन सी घटनाओं ने रिस्क रेटिंग बदलवाई?”
ऑपरेशनल रिस्क ट्रैकिंग में अक्सर डिफेन्सिबल चेंज हिस्ट्री की ज़रूरत होती है। Risks, Controls, Assessments, Incidents, और Actions के लिए हिस्ट्री/ऑडिट टेबल जोड़ें जिनमें:
यदि अनुमोदन और ऑडिट अपेक्षित हैं तो केवल “last updated” स्टोर करने से बचें।
रेपोर्टिंग टूटने से रोकने के लिए रेफ़रेंस टेबल्स (हार्ड-कोड्ड स्ट्रिंग्स नहीं) का उपयोग करें: टैक्सोनॉमी, स्टेटस, सेवेरिटी/लाइकलीहुड स्केल, कंट्रोल टाइप्स, और एक्शन स्टेट्स। यह टाइपो (“High” बनाम “HIGH”) से रिपोर्टिंग टूटने को रोकेगा।
साक्ष्य को फर्स्ट-क्लास डेटा समझें: एक Attachments टेबल जिसमें फ़ाइल मेटाडेटा (नाम, प्रकार, साइज, अपलोडर, लिंक्ड रिकॉर्ड, अपलोड तारीख) और रिटेंशन/डिलीशन डेट और एक्सेस क्लासिफिकेशन के फ़ील्ड हों। फ़ाइलों को ऑब्जेक्ट स्टोरेज में रखें, पर गवर्नेंस नियम डेटाबेस में रखें।
जब “कौन क्या करता है” अस्पष्ट होता है तो रिस्क ऐप जल्दी विफल हो जाता है। स्क्रीन बनाने से पहले वर्कफ़्लो स्टेट्स, कौन आइटमों को किन स्टेट्स में ले जा सकता है, और हर स्टेप पर क्या कैप्चर किया जाना चाहिए यह परिभाषित करें।
छोटे रोल सेट से शुरू करें और तभी बढ़ाएँ जब ज़रूरत हो:
परमिशन ऑब्जेक्ट टाइप (risk, control, action) और क्षमता (create, edit, approve, close, reopen) के अनुसार स्पष्ट रखें।
एक स्पष्ट लाइफसाइकल उपयोग करें जिसमें अनुमानित गेट्स हों:
रिव्यू साइकिल, कंट्रोल टेस्टिंग, और एक्शन ड्यू डेट्स पर SLA लगाएं। ड्यू डेट से पहले रिमाइंडर भेजें, SLA मिस होने पर एस्केलेट करें, और ओवरड्यू आइटमों को प्रमुखता से दिखाएँ (ओनर्स और उनके मैनेजरों के लिए)।
हर आइटम का एक जिम्मेदार ओनर होना चाहिए और वैकल्पिक कोलैबोरेटर्स हो सकते हैं। डेलिगेशन और रीअसाइनमेंट को सपोर्ट करें, पर कारण आवश्यक रखें (और वैकल्पिक रूप से प्रभावी तिथि) ताकि पाठक समझ सकें कि जिम्मेदारी कब और क्यों ट्रांसफर हुई।
एक रिस्क ऐप तब सफल होता है जब लोग वास्तव में इसका उपयोग करें। गैर-टेक उपयोगकर्ताओं के लिए सर्वश्रेष्ठ UX पूर्वानुमेय, कम घर्षण वाला और सुसंगत होता है: स्पष्ट लेबल, न्यूनतम जार्गन, और इतना मार्गदर्शन कि “miscellaneous” प्रविष्टियों से बचा जा सके।
आपका इनटेक फ़ॉर्म एक निर्देशित वार्तालाप जैसा होना चाहिए। फ़ील्ड के नीचे छोटे हेल्पर टेक्स्ट जोड़ें (लंबे निर्देश नहीं) और वास्तव में आवश्यक फ़ील्ड्स को required मार्क करें।
आवश्यक आइटमों में शामिल करें: टाइटल, कैटेगरी, प्रक्रिया/एरिया, ओनर, करंट स्टेटस, प्रारंभिक स्कोर, और “क्यों यह महत्वपूर्ण है” (इम्पैक्ट नैरेटिव)। यदि आप स्कोरिंग उपयोग करते हैं, तो हर फैक्टर के पास टूलटिप्स एम्बेड करें ताकि उपयोगकर्ता बिना पेज छोड़े परिभाषा समझ सकें।
अधिकांश उपयोगकर्ता लिस्ट व्यू में रहते हैं—इसलिए इसे तेज़ बनाएं ताकि प्रश्न “किसे ध्यान देने की ज़रूरत है?” का उत्तर मिल सके।
स्टेटस, ओनर, कैटेगरी, स्कोर, अंतिम समीक्षा तिथि, और ओवरड्यू एक्शन के लिए फ़िल्टर और सॉर्टिंग दें। अपवादों (ओवरड्यू रिव्यू, पस्ट-ड्यू एक्शन्स) को सूक्ष्म बैज के साथ हाइलाइट करें—हर जगह अलार्म रंगों से बचें—ताकि ध्यान सही आइटमों पर जाए।
डिटेल स्क्रीन को पहले सारांश की तरह पढ़ने योग्य बनाएं, फिर सहायक विवरण। शीर्ष क्षेत्र पर ध्यान रखें: विवरण, करंट स्कोर, अंतिम समीक्षा, अगली समीक्षा तिथि, और ओनर।
नीचे लिंक्ड कंट्रोल्स, घटनाएँ, और एक्शन्स अलग सेक्शन के रूप में दिखाएँ। संदर्भ के लिए टिप्पणियाँ और साक्ष्य के लिए अटैचमेंट्स जोड़ें (“क्यों हमने स्कोर बदला”)।
एक्शन्स को असाइनमेंट, ड्यू डेट, प्रोग्रेस, साक्ष्य अपलोड, और स्पष्ट बंद होने के मापदंड चाहिए। समापन स्पष्ट बनाएं: कौन क्लोज़र को मंजूर करता है और क्या प्रमाण चाहिए।
यदि आप रेफरेंस लेआउट चाहते हैं तो नेविगेशन को सरल और सुसंगत रखें (उदा., /risks, /risks/new, /risks/{id}, /actions)।
रिस्क स्कोरिंग वह जगह है जहाँ आपका ऐप कार्रवाई योग्य बनता है। लक्ष्य टीमें “ग्रेड” करना नहीं है, बल्कि यह मानकीकृत करना है कि किस जोखिम की तुलना कैसे की जाए, क्या पहले ध्यान देना चाहिए, और आइटम पुराने न होने पाएँ।
पहले सरल, समझने योग्य मॉडल से शुरू करें जो अधिकांश टीमों पर काम करे। एक सामान्य डिफ़ॉल्ट 1–5 स्केल है Likelihood और Impact के लिए, और निकाला गया स्कोर:
हर मान के लिए स्पष्ट परिभाषाएँ लिखें ("3" क्या मतलब है)। यह डॉक्यूमेंटेशन UI के पास रखें (टूलटिप्स या “How scoring works” ड्रॉअर) ताकि उपयोगकर्ताओं को इसे खोजने की ज़रूरत न पड़े।
सिर्फ़ नंबर व्यवहार को नहीं चलाते—थ्रेशोल्ड्स करते हैं। Low / Medium / High (और वैकल्पिक रूप से Critical) के लिए सीमाएँ परिभाषित करें और तय करें कि हर स्तर क्या ट्रिगर करता है।
उदाहरण:
थ्रेशोल्ड्स कॉन्फ़िगरेबल रखें, क्योंकि “High” का मतलब बिज़नेस यूनिट के अनुसार अलग हो सकता है।
ऑपरेशनल जोखिम की चर्चाएँ अक्सर फंस जाती हैं जब लोग एक-दूसरे की बात नहीं समझते। इसे अलग करके हल करें:
UI में दोनों स्कोर साइड-बाय-साइड दिखाएँ और स्पष्ट करें कि कंट्रोल्स कैसे रेसिडुअल रिस्क को प्रभावित करते हैं (उदा., एक कंट्रोल Likelihood को 1 से घटा सकता है)। लॉजिक को ऑटोमैटेड समायोजन के पीछे छिपाने से बचें जिसे उपयोगकर्ता समझ न पाएं।
ऐसे टाइम-आधारित रिव्यू लॉजिक जोड़ें ताकि जोखिम पुराने न हो जाएँ। एक व्यावहारिक बेसलाइन:
रिव्यू आवृत्ति को बिज़नेस यूनिट के अनुसार कॉन्फ़िगर करने दें और हर जोखिम पर ओवरराइड की अनुमति दें। फिर ऑटोमेटेड रिमाइंडर और “review overdue” स्टेटस को पिछले रिव्यू डेट के आधार पर लागू करें।
कैलकुलेशन को विज़िबल रखें: Likelihood, Impact, किसी भी कंट्रोल समायोजन, और अंतिम रेसिडुअल स्कोर दिखाएँ। उपयोगकर्ता को “यह High क्यों है?” का उत्तर एक नज़र में मिलना चाहिए।
एक ऑपरेशनल रिस्क टूल तभी विश्वसनीय है जब उसकी हिस्ट्री पुख्ता हो। यदि स्कोर बदला, एक कंट्रोल “tested” चिह्नित हुआ, या एक घटना पुनःश्रेणीबद्ध हुई—तो आपको यह रिकॉर्ड चाहिए कि किसने क्या, कब और क्यों किया।
ऐसा प्रारंभिक इवेंट सूची बनाएं ताकि आप महत्वपूर्ण क्रियाओं को न छोड़ें और लॉग को शोर से भर न दें। सामान्य ऑडिट इवेंट्स:
कम से कम, एक्टिंग उपयोगकर्ता, टाइमस्टैम्प, ऑब्जेक्ट टाइप/ID, और बदले गए फ़ील्ड्स (पुराना → नया) स्टोर करें। एक वैकल्पिक “परिवर्तन का कारण” नोट जोड़ें—यह बाद के उलझनों को रोकेगा (“त्रैमासिक समीक्षा के बाद रेसिडुअल स्कोर बदला”)।
ऑडिट लॉग को एपेंड-ओनली रखें। एडिट की अनुमति देने से बचें; यदि सुधार आवश्यक है तो एक नया इवेंट बनाएं जो पिछली इवेंट का संदर्भ दे।
ऑडिटर्स और एडमिन को आमतौर पर एक समर्पित, फ़िल्टर करने योग्य व्यू चाहिए: तारीख़ रेंज, ऑब्जेक्ट, उपयोगकर्ता, और इवेंट टाइप के अनुसार। इस स्क्रीन से एक्सपोर्ट करना आसान बनाएं पर एक्सपोर्ट इवेंट को भी लॉग करें। यदि आपका एडमिन क्षेत्र है तो उसे /admin/audit-log से लिंक करें।
साक्ष्य फ़ाइलों (स्क्रीनशॉट, टेस्ट रिज़ल्ट, नीतियाँ) को वर्शन करें। हर अपलोड को नई वर्शन मानें और पूर्व फ़ाइलें संरक्षित रखें। यदि प्रतिस्थापन की अनुमति है तो कारण नोट आवश्यक करें और दोनों वर्शन रखें।
रिटेंशन नियम तय करें (उदा., ऑडिट इवेंट X वर्षों के लिए रखें; साक्ष्य Y के बाद हटाएँ जब तक कि लीगल होल न हो)। साक्ष्य को उन मामलों में अधिक कड़ा परमिशन दें जहाँ वह पर्सनल डेटा या सुरक्षा विवरण रखता है।
सुरक्षा और गोपनीयता ऑपरेशनल रिस्क ट्रैकिंग ऐप के लिए “अतिरिक्त” नहीं हैं—वे तय करते हैं कि लोग घटनाएँ लॉग करने, साक्ष्य जोड़ने, और स्वामित्व असाइन करने में कितने सहज हैं। पहले यह मैप करें कि किसे एक्सेस चाहिए, उन्हें क्या दिखना चाहिए, और क्या प्रतिबंधित होना चाहिए।
यदि आपकी संस्था पहले से किसी आईडेंटिटी प्रोवाइडर (Okta, Azure AD, Google Workspace) का उपयोग करती है तो SAML या OIDC के जरिए Single Sign-On प्राथमिकता दें। यह पासवर्ड रिस्क घटाता है, ऑनबोर्डिंग/ऑफ़बोर्डिंग सरल बनाता है, और कॉर्पोरेट नीतियों के अनुरूप है।
छोटे टीमों या बाहरी उपयोगकर्ताओं के लिए ईमेल/पासवर्ड काम कर सकता है—पर इसे मजबूत पासवर्ड नियम, सुरक्षित अकाउंट रिकवरी, और (जहाँ समर्थित) MFA के साथ पेयर करें।
ऐसी भूमिकाएँ परिभाषित करें जो वास्तविक जिम्मेदारियों को दर्शाएँ: admin, risk owner, reviewer/approver, contributor, read-only, auditor।
ऑपरेशनल रिस्क अक्सर सामान्य अंदरूनी टूल से ज़्यादा कड़ाई मांगता है। विचार करें RBAC जो सीमित करे:
परमिशन समझने योग्य रखें—लोगों को जल्दी पता होना चाहिए कि वे किसी रिकॉर्ड को क्यों देख पा रहे हैं या नहीं।
हर जगह इन-ट्रांज़िट एन्क्रिप्शन (HTTPS/TLS) का उपयोग करें और ऐप सर्विसेज़ व डेटाबेस के लिए लीस्ट प्रिविलेज का पालन करें। सेशंस को सुरक्षित कुकीज़, छोटे आइडल टाइमआउट, और लॉगआउट पर सर्वर-साइड इनवैलिडेशन से सुरक्षित रखें।
हर फ़ील्ड का समान जोखिम नहीं होता। घटना नैरेटिव, ग्राहक प्रभाव नोट्स, या कर्मचारी विवरण कड़ी नियंत्रण माँग सकते हैं। फ़ील्ड-लेवल विजिबिलिटी (या कम से कम रेडैक्शन) का समर्थन करें ताकि उपयोगकर्ता सहकार्य कर सकें बिना संवेदनशील सामग्री व्यापक रूप से उजागर किए।
कुछ व्यावहारिक गार्डरेल जोड़ें:
ये नियंत्रण डेटा की रक्षा करते हुए रिपोर्टिंग और रेमेडिएशन वर्कफ़्लोज़ को सुचारू रखते हैं।
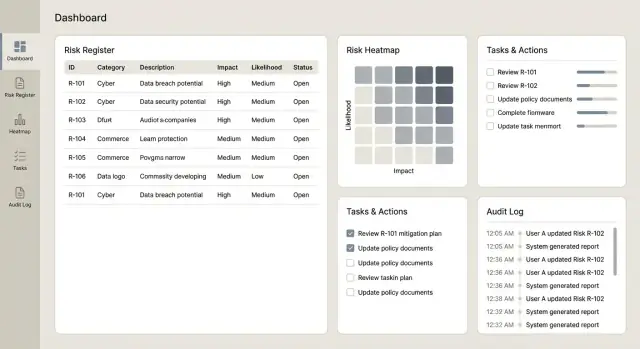
डैशबोर्ड और रिपोर्ट्स वही जगह हैं जहां एक ऑपरेशनल रिस्क ट्रैकिंग ऐप अपनी वैल्यू सिद्ध करता है: वे एक लंबे रजिस्टर को स्पष्ट निर्णयों में बदलते हैं। कुंजी यह है कि संख्याएँ अंतर्निहित स्कोरिंग नियमों और रिकॉर्ड्स के साथ ट्रेसेबल हों।
छोटे सेट से शुरू करें जो सामान्य प्रश्नों के तेज़ जवाब दें:
हर टाइल को क्लिक करने योग्य बनाएं ताकि उपयोगकर्ता चार्ट के पीछे के सटीक रिस्क, कंट्रोल, घटना, और कार्यों तक ड्रिल डाउन कर सकें।
निर्णय लेने वाले डैशबोर्ड अलग होते हैं—दैनिक प्रबंधन के लिए स्क्रीन जोड़ें जो इस सप्ताह क्या ध्यान देने योग्य है:
ये व्यू रिमाइंडर्स और टास्क ओनरशिप के साथ अच्छी तरह काम करते हैं ताकि ऐप सिर्फ़ डेटाबेस न बने बल्कि एक वर्कफ़्लो टूल भी बने।
शुरू में एक्सपोर्ट्स की योजना बनाएं क्योंकि समितियाँ अक्सर ऑफ़लाइन पैक्स पर निर्भर करती हैं। CSV विश्लेषण के लिए और PDF रीड-ओनली वितरण के लिए समर्थन दें, साथ में:
यदि आपके पास पहले से गवर्नेंस पैक टेम्पलेट है, तो उसका प्रतिबिंब करें ताकि अपनाना आसान हो।
यह सुनिश्चित करें कि हर रिपोर्ट परिभाषा आपके स्कोरिंग नियमों से मेल खाती हो। उदा., यदि डैशबोर्ड “टॉप रिस्क” को रेसिडुअल स्कोर के अनुसार रैंक करता है, तो वही कैलकुलेशन रिकॉर्ड और एक्सपोर्ट में भी उपयोग हो।
बड़े रजिस्टर के लिए प्रदर्शन के लिए डिज़ाइन करें: लिस्ट पर पैजिनेशन, सामान्य एग्रीगेट्स के लिए कैशिंग, और ऐसिंक रिपोर्ट जेनरेशन (बैकग्राउंड में जनरेट करें और रेडी होने पर नोटिफाई करें)। बाद में यदि आप शेड्यूल्ड रिपोर्ट जोड़ते हैं तो इंटरनल लिंक रखें (उदा., /reports पर रिपोर्ट कॉन्फ़िगरेशन सेव करें)।
इंटीग्रेशन और माइग्रेशन यह तय करते हैं कि आपका ऐप सिस्टम ऑफ़ रिकॉर्ड बनेगा—या बस एक और ऐसी जगह जिसे लोग भूल जाते हैं। इन्हें जल्दी योजना में रखें, पर लागू क्रमिक रूप से करें ताकि मूल प्रोडक्ट स्थिर रहे।
अधिकांश टीमें “एक और टास्क सूची” नहीं चाहतीं। वे चाहती हैं कि ऐप उस जगह से जुड़े जहाँ काम होता है:
व्यावहारिक दृष्टिकोण यह रखें कि रिस्क ऐप जोखिम डेटा का ओनर बने, जबकि बाहरी टूल एक्सेक्यूशन विवरण (टिकट, असाइन, ड्यू डेट) मैनेज करें और प्रोग्रेस अपडेट वापस फीड करें।
कई संगठन Excel से शुरू करते हैं। एक इम्पोर्ट प्रदान करें जो सामान्य फ़ॉर्मैट स्वीकार करे पर गार्ड्रेल्स जोड़ें:
जो बनेगा उसका प्रीव्यू दिखाएँ—क्या क्रिएट होगा, क्या रिजेक्ट होगा, और क्यों। वह एक स्क्रीन घंटे के बैक-एंड संचार को बचा सकती है।
भले ही आप केवल एक इंटीग्रेशन से शुरू करें, API को इस सोच के साथ डिज़ाइन करें कि कई इंटीग्रेशन होंगे:
इंटीग्रेशन सामान्य कारणों से फेल होते हैं: परमिशन बदलाव, नेटवर्क टाइमआउट, हटाए गए टिकट। इसके लिए बनाएं:
यह भरोसा बनाए रखता है और रजिस्टर व एक्सेक्यूशन टूल के बीच मौन विचलन को रोकता है।
एक रिस्क ट्रैकिंग ऐप तब मूल्यवान बनता है जब लोग उस पर भरोसा करते हैं और नियमित उपयोग करते हैं। टेस्टिंग और रोलआउट को उत्पाद का हिस्सा समझें, न कि अंतिम चेकबॉक्स।
उन हिस्सों के लिए ऑटोमेटेड टेस्ट्स से शुरू करें जो हर बार समान व्यवहार करने चाहिए—ख़ासकर स्कोरिंग और परमिशन्स:
UAT तब सबसे अच्छा काम करता है जब यह वास्तविक काम की नकल करे। हर बिज़नेस यूनिट से कुछ नमूना जोखिम, कंट्रोल, घटनाएँ, और एक्शन्स माँगें, फिर सामान्य परिदृश्य चलाएँ:
बग्स के साथ-साथ भ्रमित कर देने वाले लेबल, गायब स्टेटस, और फ़ील्ड जो टीमों की भाषा से मेल नहीं खाते—इनको कैप्चर करें।
पहले एक टीम (या एक क्षेत्र) पर 2–4 हफ्ते के लिए रोलआउट करें। स्कोप नियंत्रित रखें: एक वर्कफ़्लो, कुछ फ़ील्ड, और एक स्पष्ट सफलता मीट्रिक (उदा., % रिस्क समय पर रिव्यू हुए)। फीडबैक का उपयोग कर समायोजन करें:
छोटे हाउ-टू गाइड और एक पन्ने का ग्लॉसरी प्रदान करें: हर स्कोर का क्या अर्थ है, कब कौन सा स्टेटस उपयोग करें, और साक्ष्य कैसे अटैच करें। 30 मिनट की लाइव सेशन और रिकॉर्डेड क्लिप्स अक्सर लंबे मैनुअल से बेहतर असर देती हैं।
यदि आप एक विश्वसनीय v1 जल्दी बनाना चाहते हैं तो Koder.ai जैसे vibe-coding प्लेटफ़ॉर्म से आप प्रोटोटाइप और वर्कफ़्लोज़ पर जल्दी इटरेट कर सकते हैं। आप स्क्रीन और नियम (रिस्क इनटेक, अनुमोदन, स्कोरिंग, रिमाइंडर, ऑडिट लॉग व्यू) चैट में वर्णित कर सकते हैं, फिर वास्तविक UI पर स्टेकहोल्डर्स की प्रतिक्रिया के अनुसार जनरेट ऐप को परिष्कृत कर सकते हैं।
Koder.ai एंड-टू-एंड डिलीवरी के लिए बनाया गया है: यह वेब ऐप्स (अक्सर React), बैकएंड सर्विसेज़ (Go + PostgreSQL) बनाना सपोर्ट करता है, और स्रोत-कोड एक्सपोर्ट, डिप्लॉयमेंट/होस्टिंग, कस्टम डोमेन्स, और स्नैपशॉट्स/रोलबैक जैसी व्यावहारिक सुविधाएँ देता है—जब आप टैक्सोनॉमी, स्कोरिंग स्केल, या अनुमोदन फ्लोज़ बदल रहे हों तब सुरक्षित इटरेशन के लिए उपयोगी। टीमें एक फ्री टियर से शुरू कर सकती हैं और प्रॉ, बिज़नेस, या एंटरप्राइज़ की ओर बढ़ सकती हैं क्योंकि गवर्नेंस और स्केल की ज़रूरतें बढ़ती हैं।
ऑटोमेटेड बैकअप, बेसिक अपटाइम/एरर मॉनिटरिंग, और टैक्सोनॉमी व स्कोरिंग स्केल के लिए एक हल्का चेंज प्रोसेस पहले से योजना बनाएं ताकि अपडेट्स समय के साथ सुसंगत और ऑडिटेबल रहें।
एक स्पष्ट संगठनात्मक परिभाषा लिख कर शुरू करें कि “ऑपरेशनल जोखिम” में क्या आता है और क्या नहीं।
एक व्यावहारिक तरीका चार बकेट में विभाजित करना है—प्रक्रिया, लोग, सिस्टम, बाहरी घटनाएँ—और प्रत्येक के लिए कुछ उदाहरण जोड़ें ताकि उपयोगकर्ता लगातार तरीके से आइटम को वर्गीकृत कर सकें।
v1 को उन न्यूनतम वर्कफ़्लोज़ पर केंद्रित रखें जो भरोसेमंद डेटा बनाते हैं:
जटिल टैक्सोनोमी मैनेजमेंट, कस्टम वर्कफ़्लो बिल्डर और गहरी इंटीग्रेशन को तब टालें जब तक उपयोग स्थिर न हो।
एक छोटा पर प्रतिनिधि स्टेकहोल्डर समूह शामिल करें:
यह वास्तविक वर्कफ़्लो के लिए डिज़ाइन करने में मदद करेगा बजाए कि काल्पनिक फीचर्स के।
वर्तमान वर्कफ़्लो को एंड-टू-एंड मैप करें (भले ही यह ईमेल + स्प्रेडशीट हो): identify → assess → treat → monitor → review.
प्रत्येक स्टेप के लिए दस्तावेज़ करें:
इनको स्पष्ट स्टेट्स और ट्रांज़िशन नियमों में बदल दें।
एक सुसंगत रिस्क स्टेटमेंट फ़ॉर्मैट स्टैंडर्ड करें (जैसे, “Due to कारण, घटना हो सकती है, जिससे प्रभाव होगा”) और अनिवार्य फ़ील्ड तय करें।
कम से कम आवश्यक होनी चाहिए:
यह अस्पष्ट प्रविष्टियों को रोकेगा और रिपोर्टिंग की गुणवत्ता बेहतर करेगा।
पहले सरल, समझने योग्य मॉडल चुनें (आम तौर पर 1–5 Likelihood और 1–5 Impact, जहाँ Score = L × I)।
इसे सुसंगत बनाने के लिए:
यदि टीमें लगातार स्कोर नहीं कर पातीं, तो और आयाम जोड़ने से पहले मार्गदर्शन दें।
पॉइंट-इन-टाइम असेसमेंट को “करंट” रिस्क रिकॉर्ड से अलग रखें।
एक न्यूनतम स्कीमा में आमतौर पर शामिल हैं:
यह संरचना यह सवाल उत्तर देने में मदद करती है—“किस घटना ने रेटिंग बदलाव को प्रेरित किया?”—बिना हिस्ट्री ओवरराइट किए।
एक एपेंड-ओनली ऑडिट लॉग रखें मुख्य इवेंट्स के लिए (create/update/delete, approvals, ownership changes, exports, permission changes)।
कॅप्चर करें:
फिल्टर करने योग्य, रीड-ओनली ऑडिट लॉग व्यू दें और उससे एक्सपोर्ट करने पर भी उस इवेंट को लॉग करें।
साक्ष्य को फर्स्ट-क्लास डेटा की तरह ट्रीट करें—सिर्फ़ फाइल न समझें।
सुझावी अभ्यास:
यह ऑडिट्स के लिए मददगार है और संवेदनशील सामग्री के आकस्मिक एक्सपोज़र को घटाता है।
यदि आपकी संस्था पहले से किसी पहचान प्रदाता (Okta, Azure AD, Google Workspace) का उपयोग करती है तो SSO (SAML/OIDC) प्राथमिकता दें। यह पासवर्ड रिस्क घटाता है और ऑनबोर्डिंग/ऑफ़बोर्डिंग को सरल बनाता है।
प्रायोगिक सुरक्षा आवश्यकताएँ:
अनुमति नियम समझने में आसान रखें ताकि लोग जान सकें कि उन्हें क्यों एक्सेस दिया गया या नहीं।