यह पोस्ट क्या कवर करती है (और क्यों मायने रखता है)
Snowflake ने क्लाउड डेटा वेयरहाउसिंग में एक सरल परंतु दूरगामी विचार लोकप्रिय बनाया: डेटा स्टोरेज और क्वेरी कंप्यूट को अलग रखें। यह विभाजन डेटा टीमों के दो सामान्य दर्द-बिंदुओं को बदल देता है—वेयरहाउस कैसे स्केल होता है और आप उन्हें कैसे भुगतान करते हैं।
एक ही “बॉक्स” की तरह वेयरहाउस को देखने के बजाय (जहां अधिक यूज़र्स, अधिक डेटा, या जटिल क्वेरी सब एक ही संसाधनों के लिए लड़ते हैं), Snowflake का मॉडल आपको डेटा एक बार स्टोर करने और आवश्यकता के समय सही मात्रा में कंप्यूट स्पिन-अप करने देता है। नतीजा अक्सर तेज़ उत्तर-समय, पीक उपयोग के दौरान कम बॉटलनेक्स और इस बात पर स्पष्ट नियंत्रण है कि किस चीज़ के लिए कब भुगतान होता है।
थीम #1: सामान्य ट्रेड-ऑफ़ के बिना प्रदर्शन और स्केलिंग
यह पोस्ट सामान्य भाषा में समझाती है कि स्टोरेज और कंप्यूट को अलग करने का असल मतलब क्या है—और इसका असर किस तरह होता है:
- कॉनकरेंसी (एक ही समय में कई लोग क्वेरी चला रहे हों)
- इलास्टिक स्केलिंग (कंप्यूट को ऊपर-नीचे करना)
- लागत व्यवहार (केवल तब कंप्यूट का भुगतान जब वह चल रहा हो, साथ ही सतत स्टोरेज)
हम यह भी बताएँगे कि यह मॉडल हर समस्या का जादुई हल नहीं है—क्योंकि कुछ प्रदर्शन और लागत की झटके उस तरीके से आते हैं जिस तरह वर्कलोड्स डिज़ाइन किए जाते हैं, ना कि प्लेटफ़ॉर्म से ही।
थीम #2: इकोसिस्टम कच्ची गति जितना ही महत्वपूर्ण क्यों हो सकता है
एक तेज़ प्लेटफ़ॉर्म पूरी कहानी नहीं है। कई टीमों के लिए टाइम-टू-वैल्यू इस पर निर्भर करता है कि क्या आप आसानी से वेयरहाउस को उन्हीं टूल्स से जोड़ सकते हैं जिनका आप पहले से उपयोग करते हैं—ETL/ELT पाइपलाइंस, BI डैशबोर्ड, कैटलॉग/गवर्नेंस टूल्स, सुरक्षा नियंत्रण, और पार्टनर डेटा स्रोत।
Snowflake का इकोसिस्टम (डेटा शेयरिंग पैटर्न और मार्केटप्लेस-शैली वितरण सहित) कार्यान्वयन टाइमलाइन को छोटा कर सकता है और कस्टम इंजीनियरिंग कम कर सकता है। यह पोस्ट बताती है कि व्यवहार में “इकोसिस्टम की गहराई” कैसी दिखती है और आपकी संस्था के लिए इसे कैसे आंके।
यह किसके लिए है
यह गाइड डेटा लीडर्स, एनालिस्ट्स और गैर-विशेषज्ञ निर्णयकर्ताओं के लिए लिखा गया है—वे लोग जिन्हें Snowflake आर्किटेक्चर, स्केलिंग, लागत और इंटीग्रेशन विकल्पों के पीछे के ट्रेड‑ऑफ़ समझने होते हैं बिना विक्रेता के जार्गन में खोए।
अलग करने से पहले: पारंपरिक वेयरहाउस क्यों सीमित हो जाते थे
पारंपरिक डेटा वेयरहाउस एक सरल अनुमान के आसपास बनाए गए थे: आप एक निश्चित मात्रा में हार्डवेयर खरीदते/किराए पर लेते हैं, फिर सब कुछ उसी बॉक्स या क्लस्टर पर चलाते हैं। जब वर्कलोड पूर्वानुमेय और वृद्धि धीरे-धीरे थी तो यह ठीक काम करता था—लेकिन जैसे ही डेटा वॉल्यूम और यूज़र काउंट तेज़ी से बढ़े, यह संरचनात्मक सीमाएँ पैदा करने लगा।
क्लासिक मॉडल: फिक्स्ड क्लस्टर्स और सावधान कैपेसिटी प्लानिंग
ऑन‑प्रेम सिस्टम (और शुरुआती क्लाउड "लिफ्ट‑और‑शिफ्ट" डिप्लॉयमेंट) आमतौर पर इस तरह दिखते थे:
- एक सिंगल MPP (massively parallel processing) क्लस्टर स्टोरेज, CPU, और मेमोरी को साथ में संभालता था।
- आप पीक डिमांड के लिए क्लस्टर का साइज तय करते थे, क्योंकि रिसाइज़िंग धीमा, जोखिम भरा, या डाउनटाइम मांगता था।
- कैपेसिटी प्लानिंग एक बार‑बार होने वाला प्रोजेक्ट बन जाता था: वृद्धि का अनुमान, बजट का औचित्य, हार्डवेयर ऑर्डर, इंस्टाल, माइग्रेट।
यहाँ तक कि जब विक्रेताओं ने "नोड्स" दिया भी, मूल पैटर्न वही रहा: स्केल करने का मतलब आमतौर पर एक साझा वातावरण में बड़ा या अधिक नोड जोड़ना होता था।
दर्द-बिंदु: धीमा स्केलिंग, बर्बाद खर्च, और कतार लगना
यह डिज़ाइन कुछ सामान्य सिरदर्द पैदा करती है:
- धीमा स्केलिंग: अगर तिमाही रिपोर्टिंग के समय अचानक अधिक पौ्फरशर (horsepower) चाहिए, तो आप उसे हमेशा जल्दी नहीं जोड़ पाते। या तो आप इंतज़ार करते हैं, या "सुरक्षा के लिए" ओवरप्रोविजन करते हैं।
- निष्क्रिय क्षमता: पीक के लिए साइज किए गए क्लस्टर अधिकांश समय अंडर-यूज़्ड रहते हैं—फिर भी आपको उनके लिए भुगतान करना पड़ता है (हार्डवेयर लागत, लाइसेंस, ऑप्स समय)।
- लोड के दौरान कतार: जब कई टीमें एक साथ क्वेरी चलाती हैं, तो वे समान संसाधनों के लिए भिड़ती हैं। भारी जॉब्स इंटरैक्टिव डैशबोर्ड्स को ब्लॉक कर सकते हैं, जिससे टाइमआउट, नाराज़ स्टेकहोल्डर्स और नियम जैसे "बिज़नेस घंटे के दौरान वह क्वेरी मत चलाओ" बन जाते हैं।
टूलिंग और इंटीग्रेशन: पावरफुल पर अक्सर नाज़ुक
क्योंकि ये वेयरहाउस अपने वातावरण से कड़ी तरह जुड़े होते थे, इंटीग्रेशन अक्सर ऑर्गेनिकली बढ़ते गए: कस्टम ETL स्क्रिप्ट्स, हैंड‑बिल्ट कनेक्टर्स, और वन‑ऑफ पाइपलाइंस। ये तब तक काम करते रहे—जब तक कोई स्कीमा बदल न जाए, अपस्ट्रीम सिस्टम मूव न हो, या कोई नया टूल आ न जाए। सब कुछ चलाए रखना लगातार मेंटेनेंस जैसा लग सकता था बजाए स्थिर प्रगति के।
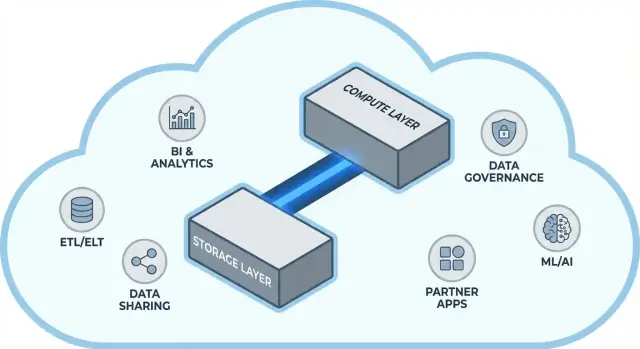
मूल विचार: स्टोरेज और कंप्यूट को अलग करना
पारंपरिक डेटा वेयरहाउस अक्सर दो बहुत अलग कामों को जोड़ देते थे: स्टोरेज (जहाँ आपका डेटा रहता है) और कंप्यूट (वह हॉर्सपावर जो डेटा पढ़ता, जॉइन/एग्रीगेट और लिखता है)।
स्टोरेज बनाम कंप्यूट (सादा शब्दों में)
स्टोरेज एक लॉन्ग‑टर्म पैंट्री जैसा है: टेबल्स, फ़ाइलें और मेटाडेटा सुरक्षित और सस्ते तरीके से रखे जाते हैं, टिकाऊ और हमेशा उपलब्ध रहने के लिए डिज़ाइन किए जाते हैं।
कंप्यूट किचन स्टाफ जैसा है: यह CPU और मेमोरी का सेट है जो असल में आपकी क्वेरीज़ "पकाता" है—SQL चलाना, सॉर्टिंग, स्कैनिंग, रिज़ल्ट बनाना, और एक साथ कई यूज़र्स को संभालना।
मुख्य बदलाव: उन्हें स्वतंत्र रूप से स्केल करना
Snowflake इन दोनों को अलग करता है ताकि आप एक को बदलें बिना दूसरे को मजबूर करने के।
- अगर डेटा वॉल्यूम बढ़ता है, तो आप अधिक स्टोरेज जोड़ते हैं (आम तौर पर इन्क्रीमेंटल और अपेक्षाकृत प्रेडिक्टेबल)।
- अगर रिपोर्ट ट्रैफ़िक अचानक बढ़ता है, तो आप अधिक कंप्यूट जोड़ते हैं (वर्चुअल वेयरहाउस का आकार बदलकर या जोड़कर) बिना आधार डेटा को मूव या डुप्लिकेट किए।
व्यवहार में, यह दिन‑प्रतिदिन के संचालन को बदल देता है: आपको स्टोरेज बढ़ने के कारण कंप्यूट "ओवरबाय" करने की ज़रूरत नहीं पड़ती, और आप वर्कलोड्स को अलग कर सकते हैं (उदा., एनालिस्ट्स बनाम ETL) ताकि वे एक-दूसरे को धीमा न करें।
यह क्या नहीं है
यह अलगाव शक्तिशाली है, पर जादू नहीं:
- यह मुफ्त स्केलिंग नहीं है। बड़े या अधिक वेयरहाउस आम तौर पर अधिक कंप्यूट खर्च का मतलब हैं।
- यह हर बार स्वचालित बचत भी नहीं करता। खराब लिखी गई क्वेरीज़, अनावश्यक रिफ्रेश शेड्यूल, या हमेशा‑ऑन वेयरहाउस अभी भी लागत बढ़ा सकते हैं।
- यह योजना को अनदेखा करने का बहाना नहीं है। आपको अभी भी वेयरहाउस साइज चुनना होगा, ऑटो‑सस्पेंड नियम सेट करने होंगे, और कंप्यूट को बिज़नेस उपयोग पैटर्न से मिलाना होगा।
मूल मूल्य नियंत्रण है: स्टोरेज और कंप्यूट के लिए अलग-अलग भुगतान करना, और उन्हें आपकी टीमों की वास्तविक ज़रूरतों के अनुरूप मिलाना।
Snowflake की आर्किटेक्चर साधारण शब्दों में
Snowflake को समझना सबसे आसान है तीन परतों के रूप में जो साथ काम करती हैं, पर स्वतंत्र रूप से स्केल कर सकती हैं।
1) स्टोरेज: क्लाउड ऑब्जेक्ट स्टोरेज
आपकी टेबल्स अंततः क्लाउड प्रदाता के ऑब्जेक्ट स्टोरेज में डेटा फ़ाइलों के रूप में रहती हैं (जैसे S3, Azure Blob, या GCS)। Snowflake आपके लिए फ़ाइल फॉर्मैट, कंप्रेशन और संगठन का प्रबंधन करता है। आप "डिस्क संलग्न" नहीं करते या स्टोरेज वॉल्यूम साइज नहीं करते—स्टोरेज डेटा के साथ बढ़ता है।
2) कंप्यूट: वर्चुअल वेयरहाउस
कंप्यूट को वर्चुअल वेयरहाउस के रूप में पैकेज किया जाता है: CPU/मेमोरी के स्वतंत्र क्लस्टर जो क्वेरीज़ को निष्पादित करते हैं। आप एक ही डेटा पर एक साथ कई वेयरहाउस चला सकते हैं। यही पुरानी प्रणालियों से मुख्य फर्क है जहाँ भारी वर्कलोड्स अक्सर एक ही संसाधन पूल पर भिड़ते थे।
3) क्लाउड सर्विसेज: मेटाडेटा और समन्वय
एक अलग सर्विस लेयर सिस्टम का "ब्रेन" संभालता है: ऑथेंटिकेशन, क्वेरी पार्सिंग और ऑप्टिमाइज़ेशन, ट्रांज़ैक्शन/मेटाडेटा प्रबंधन, और समन्वय। यह लेयर यह तय करती है कि क्वेरी को कुशलता से कैसे चलाया जाए इससे पहले कि कंप्यूट डेटा तक पहुँचे।
एक क्वेरी कैसे बहती है
जब आप SQL सबमिट करते हैं, Snowflake की सर्विसेज लेयर उसे पार्स करती है, एक एक्ज़ीक्यूशन प्लान बनाती है, और फिर उस प्लान को चुने गए वर्चुअल वेयरहाउस को सौंप देती है। वेयरहाउस केवल आवश्यक डेटा फ़ाइलों को ऑब्जेक्ट स्टोरेज से पढ़ता है (और जहाँ संभव हो कैशिंग का लाभ उठाता है), उन्हें प्रोसेस करता है, और परिणाम लौटाता है—बिना आपके बेस डेटा को स्थायी रूप से वेयरहाउस में मूव किए।
कॉनकरेंसी और अलगाव (जार्गन के बिना)
अगर कई लोग एक साथ क्वेरी चलाते हैं, तो आप या तो:
- अलग‑अलग टीम/वर्कलोड के लिए अलग वेयरहाउस का उपयोग कर सकते हैं (वर्कलोड आईसोलेशन), या
- मल्टि‑क्लस्टर वेयरहाउस सक्षम कर सकते हैं ताकि Snowflake आवश्यकता के समय और कंप्यूट क्लस्टर जोड़ सके, फिर वापस कम कर दे।
यही Snowflake के प्रदर्शन और “नोइज़ी नेबर” नियंत्रण के पीछे का आर्किटेक्चरल आधार है।
स्केलिंग और कॉनकरेंसी: असल में क्या बदलता है
Snowflake का बड़ा व्यावहारिक बदलाव यह है कि आप कंप्यूट को स्वतंत्र रूप से स्केल करते हैं, न कि डेटा को। "वेयरहाउस बड़ा हो रहा है" की जगह, आपके पास प्रत्येक वर्कलोड के लिए संसाधन ऊपर/नीचे करने की क्षमता है—बिना टेबल्स कॉपी किए, डिस्क्स को रिसी-परटिशनिंग किए, या डाउनटाइम शेड्यूल किए।
इलास्टिसिटी: डेटा बिना हिलाए कंप्यूट का आकार बदलना
Snowflake में, एक वर्चुअल वेयरहाउस वह कंप्यूट इंजन है जो क्वेरीज़ चलाता है। आप इसे सेकंडों में रिसाइज़ कर सकते हैं (उदा., Small से Large), और डेटा वहीं रहता है। इसका मतलब यह है कि परफ़ॉर्मेंस ट्यूनिंग अक्सर एक सरल सवाल बन जाती है: “क्या इस वर्कलोड को अभी अधिक हॉर्सपावर चाहिए?”
यह अस्थायी बर्स्ट को भी सक्षम करता है: माह-अंत क्लोज़ के लिए ऊपर स्केल करें, फिर स्पाइक के खत्म होने पर वापस नीचे आ जाएँ।
कॉनकरेंसी: कतारों में कम लड़ाई
पारंपरिक सिस्टम अक्सर विभिन्न टीमों को एक ही कंप्यूट शेयर करने पर मजबूर करते हैं, जिससे व्यस्त घंटों में कतार लग जाती है।
Snowflake आपको विभिन्न टीमों/वर्कलोड्स के लिए अलग वर्चुअल वेयरहाउस चलाने देता है—उदा., एक एनालिस्ट्स के लिए, एक डैशबोर्ड्स के लिए, और एक ETL के लिए। चूंकि ये वेयरहाउस एक ही अंतर्निहित डेटा पढ़ते हैं, आप “तुम्हारी डैशबोर्ड ने मेरी रिपोर्ट धीमी कर दी” वाली समस्या घटा देते हैं और परफ़ॉर्मेंस को अधिक अनुमाननीय बनाते हैं।
आप जिन ट्रेडऑफ़्स का सामना करेंगे
इलास्टिक कंप्यूट अपने आप सफलता नहीं लाता। सामान्य गोट्चास में शामिल हैं:
- कोल्ड स्टार्ट्स: सस्पेंड किए गए वेयरहाउस को फिर से चालू होने में थोड़ा समय लग सकता है, जो अनियमित जॉब्स के लिए लेटेंसी जोड़ता है।
- सही‑साइज़िंग के चुनाव: ओवरसाइज़िंग पैसे बर्बाद करती है; अंडरसाइज़िंग धीमी क्वेरीज़ और निराशा पैदा करती है।
- गार्ड्रेल्स जरूरी हैं: ऑटो‑सस्पेंड/ऑटो‑रिस्यूम, रिसोर्स मॉनिटर और स्पष्ट ओनरशिप का उपयोग करें ताकि वेयरहाउस निष्क्रिय न चलें या अनियंत्रित रूप से फैलें।
कुल मिलाकर परिवर्तन यह है कि स्केलिंग और कॉनकरेंसी अब इन्फ्रास्ट्रक्चर प्रोजेक्ट्स से दिन‑प्रतिदिन के ऑपरेटिंग निर्णय बन जाते हैं।
लागत मॉडल: कहाँ बचत होती है (और कहाँ नहीं)
अपने सोर्स कोड का मालिक बनें
एक कार्यशील वेब ऐप बनाएं और जब आप इसका मालिक बनने के लिए तैयार हों तो सोर्स कोड एक्सपोर्ट करें।
Snowflake बिलिंग असल में कैसे काम करती है
Snowflake की “पे फ़ॉर व्हाट यू यूज़” मूलतः दो मीटर एक साथ चलाने जैसा है:
- Compute: आपका वर्चुअल वेयरहाउस जब चल रहा होता है तब क्रेडिट्स के लिए बिल किया जाता है (यदि यह ऑन है तो मीटर टिकल कर रहा है)।
- Storage: स्टोर किए गए डेटा की मात्रा के लिए बिल।
यह विभाजन वही जगह है जहाँ बचत हो सकती है: आप बहुत सारा डेटा अपेक्षाकृत सस्ते में रख सकते हैं जबकि कंप्यूट केवल आवश्यकता पर चालू रखें।
लागत कहां चढ़ती है
अधिकांश "अनअपेक्षित" खर्च कंप्यूट व्यवहारों से आते हैं बजाय रॉ स्टोरेज के। आम ड्राइवरों में शामिल हैं:
- ओवरसाइज़्ड वेयरहाउस (वर्कलोड की ज़रूरत से बड़ा साइज चुनना)
- हमेशा‑ऑन वर्कलोड्स (रात में या वीकेंड पर छोड़े गए वेयरहाउस)
- अकुशल क्वेरीज़ (अनफ़िल्टरड स्कैन, अनावश्यक जॉइन, बार‑बार चलने वाले भारी ट्रांसफ़ॉर्मेशन)
- ऊँची‑कॉनकरेंसी पैटर्न (कई छोटे डैशबोर्ड लगातार रिफ्रेश होते हैं)
स्टोरेज और कंप्यूट को अलग करने से क्वेरीज़ स्वचालित रूप से प्रभावी नहीं बनतीं—खराब SQL अभी भी क्रेडिट्स जल्दी जला सकता है।
वास्तविक दुनिया में काम करने वाले व्यावहारिक नियंत्रण
आपको फाइनेंस विभाग की ज़रूरत नहीं है—सिर्फ कुछ गार्डरेल:
- Auto-suspend / auto-resume ताकि निष्क्रिय समय के लिए भुगतान न करें
- Resource monitors ताकि किसी वेयरहाउस/टीम के क्रेडिट उपयोग पर अलर्ट या कट लगाया जा सके
- Scheduling (बैच जॉब्स को निर्धारित विंडो में चलाएँ; DEV/TEST को वर्किंग घंटे के बाहर पॉज़ करें)
- Right-sizing: बड़ा करने से पहले छोटे वेयरहाउस स परखें
सही उपयोग से, मॉडल अनुशासन को इनाम देता है: छोटे‑समय के, सही‑साइज़्ड कंप्यूट के साथ पूर्वानुमेय स्टोरेज वृद्धि।
डेटा शेयरिंग और सहयोग को फर्स्ट‑क्लास फीचर के रूप में रखना
Snowflake शेयरिंग को प्लेटफ़ॉर्म में डिज़ाइन किए गए रूप में मानता है—यह एक्सपोर्ट्स, फ़ाइल ड्रॉप्स और वन‑ऑफ ETL पर बाद में जोड़ा गया फीचर नहीं है।
बिना कॉपी किए शेयरिंग (कई मामलों में)
एक्स्ट्रैक्ट्स भेजने की बजाय, Snowflake किसी अन्य अकाउंट को सुरक्षित “शेयर” के माध्यम से वही अंतर्निहित डेटा क्वेरी करने दे सकता है। कई परिदृश्यों में, डेटा को दूसरी वेयरहाउस में डुप्लिकेट करने या डाउनलोड के लिए ऑब्जेक्ट स्टोरेज में पुश करने की ज़रूरत नहीं पड़ती। कंज़्यूमर साझा डेटाबेस/टेबल को स्थानीय ही जैसा देखता है, जबकि प्रदाता यह नियंत्रित रखता है कि क्या एक्सपोज़ किया गया है।
यह "डिकपल्ड" दृष्टिकोण डेटा स्प्रॉल कम करता है, एक्सेस तेज़ करता है, और उन पाइपलाइनों की संख्या घटाता है जिन्हें आपको बनाना और मेंटेन करना पड़ता है।
सामान्य सहयोग पैटर्न
पार्टनर और कस्टमर शेयरिंग: एक विक्रेता क्यूरेटेड datasets ग्राहकों को प्रकाशित कर सकता है (उदा., उपयोग विश्लेषिकी या संदर्भ डेटा) स्पष्ट सीमाओं के साथ—केवल अनुमत स्कीमास, टेबल्स या व्यूज़।
आंतरिक डोमेन शेयरिंग: केंद्रीय टीमें प्रमाणित datasets को प्रोडक्ट, फाइनेंस और ऑपरेशंस को एक्सपोज़ कर सकती हैं बिना हर टीम को अपनी कॉपी बनानी पड़े। यह "एक संख्याओं का सेट" संस्कृति को समर्थन देता है जबकि टीमों को अपना कंप्यूट चलाने देता है।
शासित सहयोग: संयुक्त परियोजनाएँ (उदा., एजेंसी, सप्लायर, या सब्सिडियरी के साथ) साझा dataset पर काम कर सकती हैं जबकि संवेदनशील कॉलम मास्क किए गए और एक्सेस लॉग किए गए हों।
योजना के लिए सीमाएँ
शेयरिंग "सेट इट एंड फॉरगेट इट" नहीं है। आपको अभी भी चाहिए:
- गवर्नेंस: स्पष्ट ओनरशिप, एक्सेस रिव्यूज़, और PII/रेगुलेटेड डेटा के लिए नीतियाँ।
- कॉन्ट्रैक्ट्स और अपेक्षाएँ: कौन कंप्यूट का भुगतान करेगा, SLA, रिटेंशन, और परिभाषाएँ बदलने पर क्या होगा।
- डिस्कवरबिलिटी: बिना कैटलॉग और अच्छे नामकरण के लोग सही साझा डेटा नहीं पाएंगे या उस पर भरोसा नहीं करेंगे। शेयर को दस्तावेज़ीकरण और आपके डेटा कैटलॉग के साथ संरेखित करें यदि आपके पास है।
क्यों इकोसिस्टम प्रदर्शन जितना ही मायने रख सकता है
एक तेज़ वेयरहाउस मूल्यवान है, पर केवल गति ही यह तय नहीं करती कि कोई प्रोजेक्ट समय पर शिप होगा। जो अक्सर फर्क डालता है वह प्लेटफ़ॉर्म के आस‑पास का इकोसिस्टम है: तैयार‑बनाए कनेक्शन्स, टूल्स और जानकारियाँ जो कस्टम काम को घटाती हैं।
डेटा प्लेटफ़ॉर्म के लिए “इकोसिस्टम” का अर्थ
व्यवहार में, एक इकोसिस्टम में शामिल हैं:
- कनेक्टर्स डेटा स्रोतों और गंतव्यों (SaaS ऐप्स, डेटाबेस, स्ट्रीमिंग टूल्स) के लिए
- पार्टनर टूल्स इन्गेस्ट, ट्रांसफॉर्मेशन, BI, डेटा क्वालिटी, और ऑब्ज़रवेबिलिटी के लिए
- ऐप्स और नेटिव इंटीग्रेशन जो डेटा के पास चलते हैं
- टेम्पलेट्स और रेफ़रेंस आर्किटेक्चर्स (कॉमन मॉडल, पैटर्न, डिप्लॉयमेंट गाइड)
- कम्युनिटी ज्ञान: उदाहरण, फोरम, मिट‑अप्स, और हायरिंग उपलब्धता
डिलीवरी स्पीड के लिए इकोसिस्टम क्यों बेंचमार्क से बेहतर हो सकता है
बेंचमार्क नियंत्रण परिस्थितियों में प्रदर्शन का एक सीमित हिस्सा मापते हैं। असली प्रोजेक्ट्स का अधिकतर समय नीचे खर्च होता है:
- डेटा को विश्वसनीय और इनक्रिमेंटल रूप से लाना
- datasets को मॉडल करना, टेस्ट करना, और डॉक्यूमेंट करना
- ऑपरेशनल टास्क (मॉनिटरिंग, अलर्टिंग, लागत नियंत्रण)
- सुरक्षा रिव्यूज़, एक्सेस कंट्रोल्स, और ऑडिट
यदि आपका प्लेटफ़ॉर्म इन चरणों के लिए परिपक्व इंटीग्रेशन रखता है, तो आप गोंद‑कोड बनाने और मेंटेन करने से बचते हैं। इससे आमतौर पर कार्यान्वयन समय घटता है, विश्वसनीयता बढ़ती है, और टीम/वेंडर बदलने पर सब कुछ फिर से लिखने की जरूरत कम होती है।
मूल्यांकन के लिए सरल लेंस: कवरेज, गुणवत्ता, मेंटेनबिलिटी
इकोसिस्टम का आकलन करते समय देखें:
- कवरेज: क्या यह आपके प्रमुख स्रोतों, BI टूल्स, ऑर्केस्ट्रेशन, और गवर्नेंस जरूरतों का समर्थन करता है?
- गुणवत्ता: क्या कनेक्टर्स सक्रिय रूप से मेंटेन किए जा रहे हैं, अच्छी तरह दस्तावेजीकृत हैं, और आपके पैमाने पर सिद्ध हैं?
- मेंटेनबिलिटी: कितना ongoing प्रयास चाहिए—अपग्रेड्स, ब्रेकिंग चेंज, डिबगिंग, और सपोर्ट?
परफ़ॉर्मेंस आपको क्षमता देती है; इकोसिस्टम अक्सर यह तय करता है कि आप उस क्षमता को व्यवसायी परिणामों में कितनी जल्दी बदल सकते हैं।
इंटीग्रेशन इकोसिस्टम: डेटा को इन, आउट और उपयोग में लाना
डेमो से डिप्लॉय तक जाएँ
अपने प्रोटोटाइप को डिप्लॉय करें और आवश्यकताओं के बदलने पर स्नैपशॉट्स और रोलबैक के साथ पुनरावृत्ति करें।
Snowflake तेज़ क्वेरी चला सकता है, पर वैल्यू तब दिखती है जब डेटा आपके स्टैक के माध्यम से विश्वसनीय रूप से चलता है: स्रोतों से Snowflake में, और वापस उन टूल्स में जहाँ लोग रोज़ाना उपयोग करते हैं। “लास्ट माइल” आम तौर पर यही तय करती है कि प्लेटफ़ॉर्म सहज लगेगा या लगातार नाज़ुक।
योजना के लिए मुख्य इंटीग्रेशन श्रेणियाँ
अधिकांश टीमों को मिश्रण की ज़रूरत होती है:
- ELT/ETL डेटाबेस, SaaS ऐप्स, फ़ाइलों, और ऑब्जेक्ट स्टोरेज से इन्गेस्ट के लिए।
- BI और एनालिटिक्स डैशबोर्ड, सेल्फ‑सर्व एक्सप्लोरेशन, और सिमेंटिक लेयर के लिए।
- रिवर्स ETL क्यूरेटेड डेटा को CRM, मार्केटिंग, और सपोर्ट सिस्टम्स में पुश करने के लिए।
- ऑर्केस्ट्रेशन शेड्यूलिंग, निर्भरताएँ, बैकफिल्स, और एनवायरनमेंट प्रमोशन के लिए।
- स्ट्रीमिंग नियर‑रियल‑टाइम इवेंट्स और चेंज डेटा कैप्चर के लिए।
- ML टूल्स फीचर पाइपलाइंस, ट्रेनिंग वर्कफ़्लोज़, और मॉडल मॉनिटरिंग के लिए।
कनेक्टर्स चुनते समय पूछने वाले प्रश्न
सभी "Snowflake‑संगत" टूल्स समान व्यवहार नहीं करते। मूल्यांकन के दौरान व्यावहारिक विवरणों पर ध्यान दें:
- क्या कनेक्टर सर्टिफ़ाइड/सपोर्टेड है (और किसके द्वारा)? एस्केलेशन पाथ क्या है?
- क्या यह इन्क्रिमेंटल लोड्स संभाल सकता है (CDC, टाइमस्टैम्प, हाई‑वॉटर मार्क)?
- स्कीमा ड्रिफ्ट—नए कॉलम, टाइप चेंज, डिलीट किए गए फील्ड्स—को यह कैसे हैंडल करता है?
- रिट्राइज, डुप्लिकेशन, और एक्सैक्टली‑वन बनाम एट‑लिस्ट‑वन पर गारंटी क्या हैं?
ऑपरेशंस को अनदेखा न करें
इंटीग्रेशन को डे‑2 रेडीनेस भी चाहिए: मॉनिटरिंग और अलर्टिंग, लाइनिएज/कैटलॉग हुक्स, और इंसिडेंट रिस्पांस वर्कफ़्लो (टिकटिंग, ऑन‑कॉल, रनबुक)। एक मजबूत इकोसिस्टम केवल अधिक लोगो नहीं—बल्कि कम आश्चर्य है जब पाइपलाइंस 2 बजे सुबह फेल हों।
गवर्नेंस, सुरक्षा, और बड़े पैमाने पर भरोसा
टीमें बढ़ने पर, एनालिटिक्स का सबसे कठिन हिस्सा अक्सर गति नहीं—बल्कि यह सुनिश्चित करना है कि सही लोग सही कारण से सही डेटा तक पहुँचें, और यह साबित करने के लिए साधन हों कि नियंत्रण काम कर रहे हैं। Snowflake की गवर्नेंस फीचर्स इस वास्तविकता के लिए डिज़ाइन की गई हैं: बहुत सारे यूज़र्स, बहुत सारे डेटा प्रोडक्ट, और बार‑बार शेयरिंग।
वह गवर्नेंस बेसिक्स जो सच में टिकते हैं
स्पष्ट रोल्स और least‑privilege मानसिकता से शुरुआत करें। व्यक्तियों को सीधे एक्सेस देने की बजाय, ANALYST_FINANCE या ETL_MARKETING जैसे रोल परिभाषित करें, फिर उन रोल्स को विशिष्ट डेटाबेस, स्कीमास, टेबल्स, और (ज़रूरत पड़ने पर) व्यूज़ का एक्सेस दें।
संवेदनशील फील्ड्स (PII, वित्तीय पहचानकर्ता) के लिए masking policies का उपयोग करें ताकि लोग datasets को क्वेरी कर सकें बिना कच्ची वैल्यू देखे—जब तक उनकी भूमिका इसे अनुमति न देती हो। इसे ऑडिटिंग के साथ जोड़ें: किसने कब क्या क्वेरी किया, यह ट्रैक करें ताकि सुरक्षा और अनुपालन टीमें बिना अटकलों के सवालों का जवाब दे सकें।
गवर्नेंस साझा करने और सेल्फ‑सर्विस को कैसे बदलता है
अच्छी गवर्नेंस शेयरिंग को सुरक्षित और स्केलेबल बनाती है। जब आपका शेयरिंग मॉडल रोल्स, नीतियों और ऑडिटेड एक्सेस पर आधारित हो, तो आप आत्म‑सेवा को आत्मविश्वास से सक्षम कर सकते हैं (ज्यादा उपयोगकर्ता डेटा एक्सप्लोर कर सकें) बिना आकस्मिक एक्सपोज़र के दरवाज़े खोलें।
यह अनुपालन प्रयासों के लिए भी घर्षण घटाता है: नीतियाँ एक‑बार‑बार लागू होने वाले नियंत्रण बन जाती हैं बजाए वन‑ऑफ अपवादों के। जब datasets कई परियोजनाओं, विभागों, या बाहरी पार्टनर्स में पुनः उपयोग किए जाते हैं तो यह महत्वपूर्ण होता है।
भविष्य के दर्द से बचने वाले व्यावहारिक सुझाव
- नैमिंग कन्वेंशंस: डेटाबेस/स्कीमा के नामों को स्टैंडर्डाइज़ करें ताकि उद्देश्य और संवेदनशीलता संकेत मिले (उदा.,
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X)। संगति रिव्यूज़ तेज़ करती है और त्रुटियाँ कम करती है।
- एनवायरनमेंट पृथक्करण: DEV/TEST/PROD को तार्किक रूप से अलग रखें, PROD में कड़े नियंत्रण रखें। उत्पादन डेटा को अपवाद मानें, डिफ़ॉल्ट नहीं।
- एक्सेस रिव्यूज़: एक कैडेंस सेट करें (उच्च‑जोखिम डेटा के लिए मासिक, अन्य के लिए त्रैमासिक)। रोल सदस्यता, स्टेल यूज़र्स, और आकर्षित रोल्स की समीक्षा करें।
विश्वास बड़े पैमाने पर ऐसा कुछ नहीं है कि एक "परफेक्ट" नियंत्रण हो—बल्कि छोटे, विश्वसनीय आदतों का सिस्टम है जो एक्सेस को इरादतन और समझाने योग्य बनाये रखता है।
वर्कलोड्स और बेस्ट‑प्रैक्टिस पैटर्न
अपना Snowflake पायलट प्लान करें
2–4 सप्ताह के पायलट ऐप का प्लान तैयार करें और प्लानिंग मोड में इसे चरण-दर-चरण लागू करें।
Snowflake तब चमकता है जब कई लोग और टूल एक ही डेटा को अलग‑अलग कारणों से क्वेरी करने की ज़रूरत रखते हैं। चूंकि कंप्यूट स्वतंत्र "वेयरहाउस" में पैक होता है, आप प्रत्येक वर्कलोड को एक आकार और शेड्यूल से मैप कर सकते हैं जो फिट हो।
सामान्य वर्कलोड मैपिंग
Analytics & dashboards: BI टूल्स को एक समर्पित वेयरहाउस पर रखें जिसे स्थिर, पूर्वानुमेय क्वेरी वॉल्यूम के लिए साइज किया गया हो। इससे डैशबोर्ड रिफ्रेश एड‑हॉक eksploration से धीमा नहीं होगा।
Ad hoc analysis: एनालिस्ट्स को एक अलग वेयरहाउस दें (अक्सर छोटा) जिसमें ऑटो‑सस्पेंड सक्षम हो। आप तेज़ iteration पाते हैं बिना निष्क्रिय समय के लिए भुगतान किए।
Data science & experimentation: एक वेयरहाउस रखें जो भारी स्कैन और कभी‑कभी के बर्स्ट के लिए साइज किया गया हो। अगर प्रयोग स्पाइक करें, तो इस वेयरहाउस को अस्थायी रूप से ऊपर स्केल करें बिना BI उपयोगकर्ताओं को प्रभावित किए।
Data apps & embedded analytics: एप ट्रैफिक को प्रोडक्शन‑समान सेवा की तरह ट्रीट करें—अलग वेयरहाउस, संरक्षण‑युक्त टाइमआउट्स, और रिसोर्स मॉनिटर्स ताकि अप्रत्याशित खर्च न हो।
यदि आप हल्के इंटरनल डेटा एप्स बना रहे हैं (उदा., एक ऑप्स पोर्टल जो Snowflake को क्वेरी करके KPIs दिखाता है), तो एक तेज़ रास्ता है: एक कार्यशील React + API स्कैफोल्ड जेनरेट करें और स्टेकहोल्डर्स के साथ इटरेट करें। प्लेटफ़ॉर्म्स जैसे Koder.ai (एक वेब/सर्वर/मोबाइल ऐप्स को चैट से बनाता vibe‑coding प्लेटफ़ॉर्म) टीमों को इन Snowflake‑बैक्ड ऐप्स को जल्दी प्रोटोटाइप करने में मदद कर सकते हैं, फिर जब आप ऑपरेशनलाइज़ करने के लिए तैयार हों तो स्रोत कोड एक्सपोर्ट कर सकते हैं।
टिकाऊ बेस्ट‑प्रैक्टिस पैटर्न
एक सरल नियम: दर्शकों और उद्देश्यों के अनुसार वेयरहाउस अलग रखें (BI, ELT, एड‑हॉक, ML, एप)। इसे अच्छी क्वेरी आदतों के साथ जोڑें—बड़े SELECT * से बचें, जल्दी फ़िल्टर करें, और अप्रमाणिक जॉइन पर नजर रखें। मॉडलिंग पक्ष पर, उन संरचनाओं को प्राथमिकता दें जो लोगों के क्वेरी करने के तरीके से मेल खाती हों (अक्सर एक साफ सिमेंटिक लेयर या अच्छी परिभाषित marts), बजाय कि फिजिकल लेआउट्स को ज़्यादा अनुकूलित करने के।
कब विकल्पों या पूरक की सोचें
Snowflake हर चीज़ का रिप्लेसमेंट नहीं है। उच्च‑थ्रूपुट, कम‑लेटेंसी ट्रांज़ैक्शनल वर्कलोड्स (टिपिकल OLTP) के लिए एक विशेष डेटाबेस आम तौर पर बेहतर होता है; Snowflake का उपयोग एनालिटिक्स, रिपोर्टिंग, शेयरिंग, और डाउनस्ट्रीम डेटा प्रोडक्ट्स के लिए किया जाता है। हाइब्रिड सेटअप सामान्य और अक्सर सबसे व्यावहारिक होते हैं।
माइग्रेशन विचार: मूव करने से पहले क्या योजना बनाएं
Snowflake माइग्रेशन शायद ही कभी “लिफ्ट‑एंड‑शिफ्ट” जैसा होता है। स्टोरेज/कंप्यूट विभाजन उस तरीके को बदल देता है जिससे आप वर्कलोड्स का साइज, ट्यून और भुगतान करते हैं—इसलिए पहले से योजना बनाने से बाद में आश्चर्य रोके जा सकते हैं।
एक व्यावहारिक माइग्रेशन अनुक्रम
सबसे पहले इन्वेंटरी बनाएं: कौन से डेटा स्रोत वेयरहाउस को फीड करते हैं, कौन‑सी पाइपलाइंस उन्हें ट्रांसफॉर्म करती हैं, कौन‑से डैशबोर्ड निर्भर हैं, और प्रत्येक का मालिक कौन है। फिर व्यवसायिक प्रभाव और जटिलता के आधार पर प्राथमिकता सेट करें (उदा., महत्वपूर्ण फाइनेंस रिपोर्टिंग पहले, परीक्षण सैंडबॉक्स बाद में)।
इसके बाद SQL और ETL लॉजिक को कन्वर्ट करें। अधिकांश सामान्य SQL ट्रांसफर होती है, पर फ़ंक्शंस, डेट हैंडलिंग, प्रोसीजरल कोड, और टेम्प‑टेबल पैटर्न जैसे विवरण अक्सर राइट‑राइट करने की ज़रूरत पड़ती है। जल्दी मान्य करें: समानांतर आउटपुट चलाएँ, रो काउंट और एग्रीगेट्स की तुलना करें, और एज‑केस (nulls, time zones, dedup लॉजिक) कंफर्म करें। अंत में कटओवर की योजना बनाएं: एक फ्रीज़ विंडो, रोलबैक पाथ, और प्रत्येक dataset/report के लिए स्पष्ट "डिफ़िनिशन ऑफ़ डन"।
देखने के लिए सामान्य जोखिम
छुपी निर्भरताएँ सबसे आम होती हैं: एक स्प्रेडशीट एक्स्ट्रैक्ट, हार्ड‑कोडेड कनेक्शन स्ट्रिंग, एक डाउनस्ट्रीम जॉब जिसे कोई याद नहीं रखता। प्रदर्शन आश्चर्य तब होता है जब पुराने ट्यूनिंग मान्यताएँ लागू नहीं रहतीं (उदा., बहुत छोटे वेयरहाउस का अत्यधिक उपयोग, या कई छोटी क्वेरियों को चलाना बिना कॉनकरेंसी पर विचार किए)। लागत स्पाइक्स अक्सर वेयरहाउस छोड़ देने, अनियंत्रित retries, या डुप्लिकेट DEV/TEST वर्कलोड्स से आते हैं। अनुमतियों के गैप़ तब दिखाई देते हैं जब आप खाल्टी रोल्स से अधिक‑सूक्ष्म गवर्नेंस की ओर माइग्रेट कर रहे होते हैं—टेस्ट्स में "least privilege" उपयोगकर्ता रन शामिल होना चाहिए।
परिवर्तन प्रबंधन (इसे स्किप न करें)
एक ओनरशिप मॉडल सेट करें (कौन डेटा, पाइपलाइंस, और लागत का मालिक है), एनालिस्ट्स और इंजीनियर्स के लिए रोल‑आधारित ट्रेनिंग दें, और कटओवर के बाद के पहले हफ्तों के लिए एक सपोर्ट योजना परिभाषित करें (ऑन‑कॉल रोटेशन, इंसिडेंट रनबुक, और मुद्दों रिपोर्ट करने की जगह)।
प्लेटफ़ॉर्म का आकलन कैसे करें: पूछने वाले प्रश्न (और एक पायलट योजना)
आधुनिक डेटा प्लेटफ़ॉर्म चुनना केवल पीक बेंचमार्क स्पीड के बारे में नहीं है। यह इस बारे में है कि क्या प्लेटफ़ॉर्म आपकी वास्तविक वर्कलोड्स, आपकी टीम के काम करने के तरीकों, और उन टूल्स के साथ फिट बैठता है जिन पर आप पहले से भरोसा करते हैं।
व्यावहारिक मूल्यांकन चेकलिस्ट
इन प्रश्नों का उपयोग अपनी शॉर्टलिस्ट और विक्रेता वार्ताओं के मार्गदर्शन के लिए करें:
- वर्कलोड्स: क्या आप मुख्यतः शेड्यूल्ड डैशबोर्ड्स, एड‑हॉक एनालिसिस, डेटा साइंस, ELT/ETL, या कस्टमर‑फेसिंग एप्स चला रहे हैं? क्या आपको पूर्वानुमेय बैच विंडोज चाहिए, या इलास्टिक बर्स्ट क्षमता?
- कॉनकरेंसी जरूरतें: एक साथ कितने लोग (या एप्लिकेशंस) क्वेरी चलाएँगे, और बिज़नेस घंटों के दौरान उपयोग कितना "स्पाइकी" है?
- डेटा शेयरिंग आवश्यकताएँ: क्या आपको पार्टनर्स, बिज़नेस यूनिट्स, या ग्राहकों के साथ लाइव डेटा शेयर करने की आवश्यकता है बिना फाइल्स भेजे? क्या आप थर्ड‑पार्टी datasets खपत करने की उम्मीद रखते हैं?
- टूलिंग फिट: क्या आपके BI टूल्स, ऑर्केस्ट्रेशन, कैटलॉग, और CI/CD वर्कफ़्लोज़ सहजता से इंटीग्रेट होंगे? अगर आप मूव करते हैं तो क्या टूटेगा?
- गवर्नेंस और सुरक्षा: क्या आपको फाइन‑ग्रेन्ड एक्सेस कंट्रोल, ऑडिट ट्रेल्स, मास्किंग, रिटेंशन नीतियाँ, और कर्तव्य पृथक्करण चाहिए?
- लागत सीमाएँ: कौन‑सी लागतें सबसे महत्वपूर्ण हैं—स्थिर‑राज्य खर्च, पीक‑घंटे खर्च, या कंप्यूट को बंद करने की क्षमता? आप "हमेशा‑ऑन" वेस्टेज को कैसे रोकेगें?
एक छोटा पायलट प्लान (2–4 सप्ताह)
दो या तीन प्रतिनिधि datasets चुनें (खिलौना सैम्पल नहीं): एक बड़ा fact टेबल, एक गन्दा सेमी‑संरचित स्रोत, और एक "बिज़नेस‑क्रिटिकल" डोमेन।
फिर असली यूज़र क्वेरीज़ चलाएँ: सुबह के पीक के दौरान डैशबोर्ड्स, एनालिस्ट एक्सप्लोरेशन, शेड्यूल्ड लोड्स, और कुछ worst‑case जॉइंस। ट्रैक करें: क्वेरी समय, कॉनकरेंसी व्यवहार, ingest समय, ऑपरेशनल प्रयास, और प्रति‑वर्कलोड लागत।
यदि आपके मूल्यांकन में यह भी शामिल है कि "हम कितनी जल्दी कुछ ऐसा भेज सकते हैं जिसे लोग वास्तव में उपयोग करें", तो पायलट में एक छोटा डिलिवरेबल जोड़ना विचार करें—जैसे एक अंदरूनी मैट्रिक्स ऐप या एक गवर्न्ड डेटा‑रिक्वेस्ट वर्कफ़्लो जो Snowflake को क्वेरी करता है। यह पतला परत बनाना अक्सर इंटीग्रेशन और सुरक्षा हकीकतों को बेंचमार्क से तेज़ी से उजागर कर देता है, और Koder.ai जैसे टूल प्रोटोटाइप‑टू‑प्रोडक्शन चक्र को चैट के जरिए ऐप संरचना जनरेट करके तेज कर सकते हैं और फिर आप जब तैयार हों तो कोड एक्सपोर्ट कर सकते हैं।
सुझाए गए अगले कदम
यदि आप खर्च का अनुमान लगाने और विकल्पों की तुलना करने में मदद चाहते हैं, तो /pricing से शुरुआत करें。
माइग्रेशन और गवर्नेंस मार्गदर्शन के लिए, /blog में संबंधित लेख ब्राउज़ करें।