09 दिस॰ 2025·8 मिनट
SQL बनाम NoSQL डेटाबेस: प्रमुख अंतर और उपयोग के मामले
डेटा मॉडल, स्केलेबिलिटी, कंसिस्टेंसी और प्रदर्शन के आधार पर SQL और NoSQL डेटाबेस के बीच वास्तविक अंतर जानें — और किस परिदृश्य में कौन सा बेहतर है।
डेटा मॉडल, स्केलेबिलिटी, कंसिस्टेंसी और प्रदर्शन के आधार पर SQL और NoSQL डेटाबेस के बीच वास्तविक अंतर जानें — और किस परिदृश्य में कौन सा बेहतर है।
SQL और NoSQL डेटाबेस के बीच चुनाव आपके एप्लिकेशन के डिज़ाइन, निर्माण और स्केलिंग को आकार देता है। डेटाबेस मॉडल डेटा संरचनाओं, क्वेरी पैटर्न, प्रदर्शन, विश्वसनीयता और टीम की उत्पादकता को प्रभावित करता है।
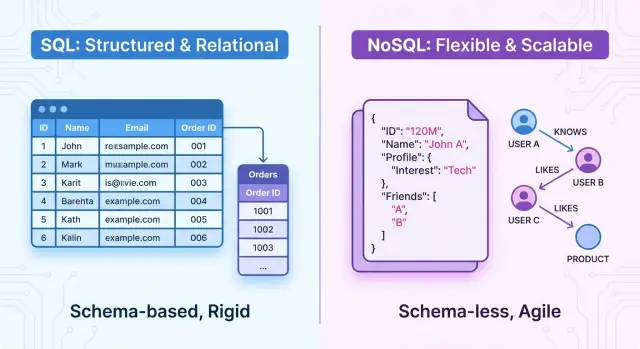
उच्च स्तर पर, SQL डेटाबेस रिलेशनल सिस्टम हैं। डेटा फिक्स्ड स्कीमा वाली तालिकाओं में व्यवस्थित होता है — पंक्तियाँ और स्तंभ। संस्थाओं के बीच संबंध स्पष्ट होते हैं (फॉरेन की के माध्यम से) और आप SQL का उपयोग करके क्वेरी करते हैं। ये सिस्टम ACID ट्रांज़ैक्शनों, मजबूत कंसिस्टेंसी और परिभाषित संरचना पर जोर देते हैं।
NoSQL डेटाबेस नॉन‑रिलेशनल सिस्टम हैं। वे एक एकल कठोर तालिका मॉडल की बजाय विभिन्न डेटा मॉडल पेश करते हैं, जैसे:
यानी “NoSQL” एक ही तकनीक नहीं है बल्कि कई दृष्टिकोणों का एक छत्र शब्द है, जिनमें लचीलापन, प्रदर्शन और डेटा मॉडलिंग के अलग‑अलग ट्रेडऑफ़ होते हैं। कई NoSQL सिस्टम उच्च स्केलेबिलिटी, उपलब्धता या कम लेटेंसी के लिए सख्त कंसिस्टेंसी गारंटियों को नरम कर देते हैं।
यह लेख SQL और NoSQL के मुख्य अंतर—डेटा मॉडल, क्वेरी भाषाएँ, प्रदर्शन, स्केलेबिलिटी और कंसिस्टेंसी (ACID बनाम एवेंटुअल कंसिस्टेंसी)—पर केंद्रित है। उद्देश्य यह है कि आप SQL और NoSQL के बीच चुनाव कैसे करें और कौन‑सा डेटाबेस किस परियोजना के लिए उपयुक्त है यह समझ सकें।
जरूरी नहीं कि आपको सिर्फ़ एक चुनना पड़े। कई आधुनिक आर्किटेक्चर में पॉलिग्लॉट परसिस्टेंस होता है, जहाँ SQL और NoSQL दोनों एक सिस्टम में सह‑अस्तित्व करते हैं और प्रत्येक अपने सर्वश्रेष्ठ वर्कलोड को संभालते हैं।
एक SQL (रिलेशनल) डेटाबेस डेटा को संरचित, तालिकात्मक रूप में संग्रहीत करता है और Structured Query Language (SQL) का उपयोग करके डेटा को परिभाषित, क्वेरी और संशोधित करता है। यह रिलेशन्स के गणितीय सिद्धांत पर टिका होता है, जिसे आप व्यवस्थित तालिकाओं के रूप में सोच सकते हैं।
डेटा तालिकाओं में व्यवस्थित होता है। हर तालिका एक प्रकार की इकाई का प्रतिनिधित्व करती है, जैसे customers, orders, या products।
email या order_date।हर तालिका का अनुसरण एक निश्चित स्कीमा करता है: यह निर्दिष्ट करता है
INTEGER, VARCHAR, DATE)NOT NULL, UNIQUE)स्कीमा को डेटाबेस लागू करता है, जिससे डेटा सुसंगत और अनुमाननीय रहता है।
रिलेशनल डेटाबेस यह मॉडल करने में उत्कृष्ट होते हैं कि कैसे संस्थाएँ एक‑दूसरे से जुड़ी हैं।
customer_id)।इन कीज़ के माध्यम से आप निम्न संबंध परिभाषित कर सकते हैं:
रिलेशनल डेटाबेस ट्रांज़ैक्शन्स—ऑपरेशनों के समूह जो एक एकल यूनिट की तरह व्यवहार करते हैं—का समर्थन करते हैं। ट्रांज़ैक्शन्स को ACID गुणों से परिभाषित किया जाता है:
ये गारंटियाँ वित्तीय सिस्टम, इन्वेंटरी मैनेजमेंट और किसी भी ऐसी एप्लिकेशन के लिए महत्वपूर्ण हैं जहाँ सटीकता मायने रखती है।
लोकप्रिय रिलेशनल सिस्टम में शामिल हैं:
ये सभी SQL को लागू करते हैं और अपने‑अपने एक्सटेंशन्स व टूलिंग प्रदान करते हैं।
NoSQL डेटाबेस वे नॉन‑रिलेशनल डेटा स्टोर्स हैं जो SQL प्रणालियों के पारंपरिक तालिका–रो–कॉलम मॉडल का उपयोग नहीं करते। इसके बजाय वे लचीले डेटा मॉडल, हॉरिजॉन्टल स्केलेबिलिटी और उच्च उपलब्धता पर ध्यान केंद्रित करते हैं, अक्सर सख्त ट्रांज़ैक्शनल गारंटियों की कीमत पर।
कई NoSQL डेटाबेस को स्कीमा‑लेस या स्कीमा‑फ्लेक्सिबल कहा जाता है। कठोर स्कीमा की जगह आप ऐसे रिकॉर्ड स्टोर कर सकते हैं जिनके फ़ील्ड या संरचनाएँ विभिन्न हों, लेकिन वे समान कलेक्शन या बकेट में हों।
यह विशेष रूप से उपयोगी है:
क्योंकि फ़ील्ड प्रति रिकॉर्ड जोड़े या हटाए जा सकते हैं, डेवलपर्स जल्दी इटरेट कर सकते हैं बिना हर संरचनात्मक परिवर्तन के लिए माइग्रेशन किए।
NoSQL कई अलग मॉडल्स का एक छत्र है:
कई NoSQL सिस्टम उपलब्धता और पार्टिशन‑टॉलरेंस को प्राथमिकता देते हैं, जिसके चलते वे पूरे डेटासेट पर सख्त ACID ट्रांज़ैक्शन्स के बजाय एवेंटुअल कंसिस्टेंसी प्रदान करते हैं। कुछ सिस्टम ट्यून करने योग्य कंसिस्टेंसी लेवल या सीमित ट्रांज़ैक्शनल सुविधाएँ (प्रति‑दस्तावेज़, पार्टिशन, या की‑रेंज) भी देते हैं, ताकि आप विशिष्ट ऑपरेशन्स के लिए मजबूत गारंटी या उच्च प्रदर्शन चुन सकें।
डेटा मॉडलिंग वह जगह है जहाँ SQL और NoSQL सबसे अलग अनुभव कराते हैं। यह तय करता है कि आप फीचर्स कैसे डिज़ाइन करते हैं, डेटा कैसे क्वेरी होता है और आपका एप्लिकेशन कैसे विकसित होता है।
SQL डेटाबेस संरचित, पूर्वनिर्धारित स्कीमाओं का उपयोग करते हैं। आप तालिकाएँ और कॉलम पहले डिजाइन करते हैं, सख्त प्रकार और प्रतिबंधों के साथ:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
हर रो को स्कीमा के अनुरूप होना चाहिए। बाद में इसका बदलना आमतौर पर माइग्रेशन्स (ALTER TABLE, बैकफिलिंग, आदि) की मांग करता है।
NoSQL डेटाबेस सामान्यतः लचीले स्कीमा का समर्थन करते हैं। एक डॉक्यूमेंट स्टोर में हर दस्तावेज़ में अलग‑अलग फ़ील्ड हो सकते हैं:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
फ़ील्ड प्रति दस्तावेज़ जोड़ी जा सकती हैं बिना एक केंद्रीय स्कीमा माइग्रेशन के। कुछ NoSQL सिस्टम वैकल्पिक या लागू किए जा सकने वाले स्कीमा भी देते हैं, पर आम तौर पर वे ढीले होते हैं।
रिलेशनल मॉडल नॉर्मलाइज़ेशन को बढ़ावा देता है: डेटा को संबंधित तालिकाओं में विभाजित करके डुप्लिकेशन से बचना और अखंडता बनाए रखना। यह तेज़, सुसंगत लेखन और छोटे स्टोरेज के पक्ष में है, पर जटिल रीड्स में कई तालिकाओं के बीच जॉइन की आवश्यकता हो सकती है।
NoSQL मॉडल अक्सर डेनेर्मलाइज़ेशन को प्राथमिकता देते हैं: संबंधित डेटा को पढ़ने के उद्देश्यों के अनुसार साथ में एम्बेड करना। इससे रीड प्रदर्शन बेहतर होता है और क्वेरीज सरल बनती हैं, पर उसी जानकारी के कई प्रतिलिपियाँ होने पर राइट्स जटिल या धीमे हो सकते हैं।
SQL में संबंध स्पष्ट और लागू होते हैं:
NoSQL में रिश्ते मॉडल किए जाते हैं:
चयन आपके एक्सेस पैटर्न पर निर्भर करता है:
SQL के साथ, स्कीमा परिवर्तन अधिक योजना मांगते हैं पर वे आपके डेटासेट पर मजबूत गारंटी देते हैं। रिफैक्टर्स स्पष्ट होते हैं: माइग्रेशन्स, बैकफिल, प्रतिबंध अद्यतन।
NoSQL के साथ, अल्पकाल में आवश्यकताओं का विकास सामान्यतः आसान होता है। आप तुरंत नए फ़ील्ड स्टोर कर सकते हैं और पुरानी दस्तावेज़ों को धीरे‑धीरे अपडेट कर सकते हैं। ट्रेड‑ऑफ यह है कि एप्लिकेशन को कई दस्तावेज़ आकृतियों और किन्हीं तरह के एज‑केस संभालने होंगे।
SQL बनाम NoSQL मॉडलिंग का निर्णय “कौन बेहतर है” से अधिक यह है कि आपका डेटा संरचना, लिखने की मात्रा और डोमेन मॉडल कितनी बार बदलता है इसके अनुरूप कैसे मेल खाता है।
SQL डेटाबेस को एक डिक्लेरेटिव भाषा से क्वेरी किया जाता है: आप यह बताते हैं कि आप क्या चाहते हैं, कैसे नहीं। SELECT, WHERE, JOIN, GROUP BY, और ORDER BY जैसी मूलभूत संरचनाएँ आपको कई तालिकाओं पर जटिल प्रश्न एक ही स्टेटमेंट में व्यक्त करने देती हैं।
क्योंकि SQL मानकीकृत (ANSI/ISO) है, अधिकांश रिलेशनल सिस्टमों का कोर सिंटैक्स साझा होता है। विक्रेता अपने एक्सटेंशन्स जोड़ते हैं, पर कौशल और क्वेरीज अक्सर PostgreSQL, MySQL, SQL Server वगैरह के बीच स्थानांतरित हो सकती हैं।
यह मानकीकरण ORMs, क्वेरी बिल्डर्स, रिपोर्टिंग टूल्स, BI डैशबोर्ड, माइग्रेशन फ्रेमवर्क और क्वेरी ऑप्टिमाइज़र्स का समृद्ध पारिस्थितिकी तंत्र लाता है। आप इनमे से कई टूल्स किसी भी SQL डेटाबेस में मामूली बदलाव के साथ लगा सकते हैं, जिससे vendor lock‑in कम होता है और विकास तेज़ होता है।
NoSQL सिस्टम्स क्वेरीज के लिए अधिक विविध तरीकों का प्रदर्शन करते हैं:
कुछ NoSQL डेटाबेस एग्रीगेशन पाइपलाइन्स या MapReduce‑समान तंत्र प्रदान करते हैं, पर क्रॉस‑कलेक्शन या क्रॉस‑पार्टिशन जॉइन सीमित या अनुपस्थित हो सकते हैं। इसके स्थान पर संबंधित डेटा अक्सर एक ही दस्तावेज़ में एम्बेड या रिकॉर्ड्स में डेनेर्मलाइज़्ड रहता है।
रिलेशनल क्वेरीज अक्सर JOIN‑हेवी पैटर्न पर निर्भर करती हैं: डेटा नॉर्मलाइज़ करो, फिर पढ़ते समय जॉइन्स से इकाइयाँ पुनर्निर्मित करो। यह एड‑हॉक रिपोर्टिंग और विकसित होने वाले प्रश्नों के लिए शक्तिशाली है, पर जटिल जॉइन्स को ऑप्टिमाइज़ करना मुश्किल हो सकता है।
NoSQL एक्सेस पैटर्न सामान्यतः डॉक्यूमेंट‑या‑की‑सेंट्रिक होते हैं: एप्लिकेशन के सबसे सामान्य क्वेरीज के चारों ओर डेटा डिज़ाइन करें। रीड्स तेज और सरल होते हैं—अक्सर एकल की लुकअप—पर बाद में एक्सेस पैटर्न बदलने पर डेटा को फिर से आकार देना पड़ सकता है।
सीखने और उत्पादकता के लिए:
जिन टीमों को रिलेशनशिप्स पर समृद्ध, एड‑हॉक क्वेरीज़ चाहिए वे आमतौर पर SQL चुनती हैं। जिन टीमों के एक्सेस पैटर्न स्थिर और अत्यधिक स्केल पर हैं वे अक्सर NoSQL मॉडल को अधिक उपयुक्त पाती हैं।
अधिकांश SQL डेटाबेस ACID ट्रांज़ैक्शन्स के इर्द‑गिर्द डिज़ाइन किए जाते हैं:
यह SQL डेटाबेस को तब उपयुक्त बनाता है जब करेक्शन कच्ची राइट थ्रूपुट से अधिक महत्वपूर्ण हो।
कई NoSQL डेटाबेस BASE गुणों की ओर झुकते हैं:
लिखन बहुत तेज और वितरित हो सकते हैं, पर पढ़ते समय अस्थायी रूप से स्टेल डेटा देखा जा सकता है।
CAP कहता है कि एक वितरित सिस्टम नेटवर्क विभाजन की स्थिति में नीचे चुनना होगा:
विभाजन के दौरान आप दोनों C और A की गारंटी नहीं दे सकते।
आम पैटर्न:
आधुनिक सिस्टम अक्सर मोड्स मिलाते हैं (उदा., ऑपरेशन के हिसाब से ट्यून‑एबल कंसिस्टेंसी) ताकि एप्लिकेशन के अलग हिस्से ज़रूरत के अनुसार गारंटियाँ चुन सकें।
परंपरागत SQL डेटाबेस एक शक्तिशाली नोड के लिए डिज़ाइन किए गए हैं।
आप आमतौर पर वर्टिकल स्केलिंग से शुरू करते हैं: अधिक CPU, RAM और तेज़ डिस्क एक सर्वर में जोड़ते हैं। कई इंज़न रीड रेप्लिकाज़ का समर्थन भी करते हैं: अतिरिक्त नोड्स सिर्फ पढ़ने के ट्रैफ़िक को संभालते हैं जबकि सभी लेखन प्राथमिक पर जाते हैं। यह पैटर्न निम्न स्थितियों में अच्छा काम करता है:
हालाँकि वर्टिकल स्केलिंग हार्डवेयर और लागत की सीमाएँ छू सकती है, और रीड रेप्लिकाज़ पढ़ने के लिए रेप्लिकेशन लेग पैदा कर सकते हैं।
NoSQL सिस्टम आमतौर पर हॉरिजॉन्टल स्केलिंग के लिए बने होते हैं: डेटा को शार्डिंग या पार्टिशनिंग के माध्यम से कई नोड्स पर फैलाया जाता है। हर शार्ड डेटा का एक सब‑सेट रखता है, इसलिए रीड और राइट दोनों वितरित हो सकते हैं और थ्रूपुट बढ़ता है।
यह उन केसों के लिए उपयुक्त है:
ट्रेड‑ऑफ उच्च ऑपरेशनल जटिलता है: शार्ड कीज़ चुनना, रीबैलेंसिंग संभालना और क्रॉस‑शार्ड क्वेरीज से निपटना।
जटिल जॉइन और एग्रीगेशन वाली रीड‑हेवी वर्कलोड के लिए, एक अच्छी तरह डिज़ाइन किया गया SQL डेटाबेस सूचकांकों के साथ बेहद तेज़ हो सकता है, क्योंकि ऑप्टिमाइज़र आँकड़े और क्वेरी प्लान का उपयोग करता है।
कई NoSQL सिस्टम सरल, की‑आधारित एक्सेस पैटर्न को प्राथमिकता देते हैं। वे पूर्वानुमेय क्वेरीज पर कम‑लेटेंसी लुकअप और हाई थ्रूपुट में उत्कृष्ट होते हैं।
NoSQL क्लस्टरों में लेटेंसी बहुत कम हो सकती है, पर क्रॉस‑पार्टिशन क्वेरीज, सेकेंडरी‑इंडेक्स और मल्टी‑डॉक्यूमेंट ऑपरेशन्स धीमे या सीमित हो सकते हैं। ऑपरेशनल रूप से, NoSQL स्केलिंग अक्सर अधिक क्लस्टर प्रबंधन मांगती है, जबकि SQL स्केलिंग आमतौर पर सीमित नोड्स पर अधिक हार्डवेयर और सावधान इंडेक्सिंग पर निर्भर करती है।
रिलेशनल डेटाबेस तब चमकते हैं जब आपको भरोसेमंद, उच्च‑वॉल्यूम OLTP (ऑनलाइन ट्रांज़ैक्शन प्रोसेसिंग) चाहिए:
ये सिस्टम ACID ट्रांज़ैक्शन्स, सख्त कंसिस्टेंसी और स्पष्ट रोलबैक व्यवहार पर निर्भर करते हैं। यदि एक ट्रांसफर कभी भी डबल‑चार्ज या पैसे खोने का जोखिम नहीं उठा सकता, तो SQL आम तौर पर अधिकांश NoSQL विकल्पों की तुलना में सुरक्षित विकल्प है।
जब आपका डेटा मॉडल अच्छी तरह समझा गया और स्थिर हो, और संस्थाएँ बहुत अंतर्संबंधित हों, तब रिलेशनल डेटाबेस प्राकृतिक चयन होता है। उदाहरण:
SQL के नॉर्मलाइज़्ड स्कीमा, फॉरेन कीज़, और जॉइन्स डेटा अखंडता लागू करना और बिना डुप्लिकेशन के जटिल संबंध क्वेरी करना सहज बनाते हैं।
स्पष्ट रूप से संरचित डेटा (स्टार/स्नोफ्लेक शेप्स, डेटा मार्ट्स) पर रिपोर्टिंग और BI के लिए SQL और SQL‑अनुकूल वेयरहाउस आमतौर पर पसंदीदा होते हैं। एनालिटिक्स टीमें SQL जानती हैं और मौजूदा टूल्स सीधा इंटीग्रेट करते हैं।
रिलेशनल बनाम नॉन‑रिलेशनल बहस अक्सर ऑपरेशनल परिपक्वता को अनदेखा कर देती है। SQL डेटाबेस प्रदान करते हैं:
जब ऑडिट, सर्टिफिकेशन या कानूनी जोखिम महत्वपूर्ण हों, SQL डेटाबेस अक्सर ज्यादा सीधे और बचाव योग्य विकल्प होते हैं।
NoSQL डेटाबेस तब बेहतर फिट होते हैं जब स्केल, लचीलापन और हमेशा‑ऑन पहुँच जटिल जॉइन्स और सख्त ट्रांज़ैक्शनल गारंटी से ज़्यादा महत्वपूर्ण हों।
यदि आप विशाल राइट वॉल्यूम, अनिश्चित ट्रैफ़िक स्पाइक्स, या टेराबाइट्स में बढ़ने वाले डेटासेट की उम्मीद करते हैं, तो NoSQL सिस्टम (की‑वैल्यू या वाइड‑कॉलम) हॉरिजॉन्टल स्केल के लिए आसान होते हैं। शार्डिंग और रेप्लिकेशन आम तौर पर इन प्लेटफ़ॉर्म में अंतर्निर्मित होते हैं, जिससे क्षमता बढ़ाने के लिए नोड्स जोड़े जा सकते हैं।
यह पैटर्न आम है:
जब आपका डेटा मॉडल बार‑बार बदलता है, तो लचीला या स्कीमा‑लेस डिज़ाइन मूल्यवान होता है। डॉक्यूमेंट डेटाबेस फ़ील्ड और संरचनाओं को बिना माइग्रेशन के विकसित करने देते हैं।
यह उपयुक्त है:
NoSQL स्टोर्स ऐपेंड‑हेवी और समय‑क्रमित वर्कलोड के लिए भी मजबूत होते हैं:
की‑वैल्यू और टाइम‑सीरीज़ डेटाबेस बहुत तेज़ राइट्स और सरल रीड्स के लिए ट्यून किए गए होते हैं।
कई NoSQL प्लेटफ़ॉर्म जियो‑रेप्लिकेशन और मल्टी‑रीजन राइट्स को प्राथमिकता देते हैं, जिससे दुनिया भर के उपयोगकर्ता लो‑लेटेंसी के साथ पढ़ और लिख सकें। यह उपयोगी है जब:
ट्रेड‑ऑफ यह है कि आप अक्सर क्षेत्रीय स्तर पर सख्त ACID व्यवहार की बजाय एवेंटुअल कंसिस्टेंसी स्वीकार करते हैं।
NoSQL चुनने का मतलब अक्सर उन सुविधाओं का त्याग करना होता है जो SQL में सामान्य मानी जाती हैं:
जब ये ट्रेड‑ऑफ स्वीकार्य हों, तो NoSQL पारंपरिक रिलेशनल डेटाबेस की तुलना में बेहतर स्केलेबिलिटी, लचीलापन और वैश्विक पहुँच दे सकता है।
पॉलिग्लॉट परसिस्टेंस का मतलब है कि आप जानबूझकर एक ही सिस्टम में कई डेटाबेस तकनीकों का उपयोग करते हैं, हर काम के लिए सर्वोत्तम टूल चुनते हैं बजाय कि सब कुछ एक स्टोर में ज़बरन फोर्स करने के।
एक सामान्य पैटर्न:
इससे “सिस्टम ऑफ़ रिकॉर्ड” रिलेशनल डेटाबेस में रहता है, जबकि अस्थायी या रीड‑हेवी वर्कलोड NoSQL पर ऑफ़लोड किए जाते हैं।
आप अलग NoSQL सिस्टम भी मिला सकते हैं:
उद्देश्य प्रत्येक डेटास्टोर को एक विशिष्ट एक्सेस पैटर्न के अनुरूप रखना है: सरल लुकअप्स, एग्रीगेट्स, सर्च, या समय‑आधारित रीड्स।
हाइब्रिड आर्किटेक्चर इंटीग्रेशन पॉइंट्स पर निर्भर करते हैं:
ट्रेड‑ऑफ है ऑपरेशनल ओवरहेड: सीखने, मॉनिटरिंग, सिक्योरिटी, बैकअप और ट्रबलशूटिंग के लिए अधिक टेक्नोलॉजीज़। पॉलिग्लॉट परसिस्टेंस तब सबसे अच्छा काम करता है जब हर अतिरिक्त डेटास्टोर स्पष्ट, नापने योग्य समस्या हल करे—ना कि सिर्फ इसलिए कि वह मॉडर्न दिखता है।
किसी प्रोजेक्ट के लिए चुनाव करना ट्रेंड फॉलो करने जैसा नहीं, बल्कि अपने डेटा और एक्सेस पैटर्न को सही टूल से मिलाना है।
पूछें:
यदि हाँ, तो रिलेशनल SQL डेटाबेस आमतौर पर डिफ़ॉल्ट होगा। यदि आपका डेटा डॉक्यूमेंट‑समान, नेस्टेड या प्रति‑रिकॉर्ड बहुत बदलता रहता है, तो डॉक्यूमेंट या अन्य NoSQL मॉडल बेहतर हो सकता है।
सख्त कंसिस्टेंसी और जटिल ट्रांज़ैक्शन्स आमतौर पर SQL का समर्थन करते हैं। उच्च लेखन थ्रूपुट के लिए और नरम कंसिस्टेंसी के साथ NoSQL बेहतर हो सकता है।
बहुत‑सी परियोजनाएँ SQL के साथ अच्छे‑खासे स्केल कर सकती हैं (अच्छी इंडेक्सिंग और हार्डवेयर के साथ)। यदि आप बेहद बड़े पैमाने और सरल एक्सेस पैटर्न की उम्मीद करते हैं तो NoSQL अधिक अर्थिक हो सकता है।
SQL जटिल क्वेरीज, BI टूल्स और एड‑हॉक एक्सप्लोरेशन के लिए उपयुक्त है। कई NoSQL डेटाबेस प्रीडिफाइंड एक्सेस पाथ्स के लिए ऑप्टिमाइज़्ड होते हैं और नई क्वेरीज़ कठिन या महँगी बना सकते हैं।
प्रोडक्शन ट्रबलशूटिंग और माइग्रेशन्स के लिए उन तकनीकों को प्राथमिकता दें जिन्हें आपकी टीम आत्मविश्वास से चला सकती है।
एक सिंगल मैनेज्ड SQL डेटाबेस अक्सर सस्ता और सरल होता है जब तक कि आप स्पष्ट रूप से उससे बाहर न बढ़ जाएँ।
बिना प्रतिबद्ध हुए पहले:
उन नापों का उपयोग करें—अनुमानों का नहीं—ताकि निर्णय लें। कई परियोजनाएँ SQL से शुरू करना सुरक्षा‑कदम होता है, और बाद में विशिष्ट उच्च‑स्केल या विशेष उपयोग‑केस के लिए NoSQL घटक जोड़ती हैं।
NoSQL का आगमन रिलेशनल डेटाबेस को ख़त्म करने के लिए नहीं हुआ; यह उन्हें पूरक करने के लिए आया।
रिलेशनल डेटाबेस अभी भी सिस्टम‑ऑफ‑रिकॉर्ड के लिए प्रभुत्व रखते हैं: वित्त, HR, ERP, इन्वेंटरी, और कोई भी वर्कफ़्लो जहाँ सख्त कंसिस्टेंसी और समृद्ध ट्रांज़ैक्शन्स ज़रूरी हों। NoSQL उस जगह चमकता है जहाँ लचीला स्कीमा, विशाल राइट थ्रूपुट या वैश्विक रीड ज़रूरी हों।
अधिकांश संगठन दोनों का उपयोग करते हैं, हर वर्कलोड के लिए सही टूल चुनते हैं।
रिलेशनल डेटाबेस पारंपरिक रूप से बड़े सर्वरों पर स्केल करते रहे हैं, पर आधुनिक इंज़न समर्थन करते हैं:
रिलेशनल सिस्टम को स्केल करना कुछ मामलों में NoSQL की तुलना में अधिक involved हो सकता है, पर यह असंभव नहीं है।
“स्कीमा‑लेस” का अर्थ वास्तव में यह है कि "स्कीमा डेटाबेस द्वारा नहीं, एप्लिकेशन द्वारा लागू किया जाता है।"
डॉक्यूमेंट, की‑वैल्यू और वाइड‑कॉलम स्टोर्स में भी संरचना होती है। बस वे प्रति‑रिकॉर्ड विकसित हो सकती है। यह लचीलापन शक्तिशाली है, पर स्पष्ट डेटा कॉन्ट्रैक्ट, गवर्नेंस और वैलिडेशन के बिना जल्दी गड़बड़ी हो सकती है।
प्रदर्शन बहुत अधिक हद तक डेटा मॉडलिंग, इंडेक्सिंग और एक्सेस पैटर्न पर निर्भर करता है, न कि केवल “SQL बनाम NoSQL” पर।
एक खराब इंडेक्स्ड NoSQL कलेक्शन कई क्वेरीज में एक अच्छी तरह‑ट्यून किए गए रिलेशनल टेबल से धीमा होगा। उसी तरह, एक रिलेशनल स्कीमा जो क्वेरी पैटर्न की अनदेखी करता है वह NoSQL मॉडल की तुलना में खराब प्रदर्शन कर सकता है।
कई NoSQL डेटाबेस मजबूत ड्यूरेबिलिटी, एन्क्रिप्शन, ऑडिटिंग और एक्सेस कंट्रोल सपोर्ट करते हैं। इसके विपरीत, एक गलत कॉन्फ़िगर किया गया रिलेशनल डेटाबेस भी असुरक्षित और नाज़ुक हो सकता है।
सुरक्षा और विश्वसनीयता किसी श्रेणी की नहीं बल्कि किसी विशेष उत्पाद, परिनियोजन, कॉन्फ़िगरेशन और ऑपरेशनल परिपक्वता का परिणाम हैं।
टीमें आमतौर पर दो कारणों से SQL और NoSQL के बीच चलती हैं: स्केलिंग और लचीलापन। एक उच्च‑ट्रैफ़िक उत्पाद अक्सर रिलेशनल डेटाबेस को सिस्टम‑ऑफ‑रिकॉर्ड के रूप में रखता है, फिर पढ़ने के लिए NoSQL जोड़ता है या नई सुविधाओं के लिए लचीला स्कीमा अपनाता है।
बड़ी‑बदली माइग्रेशन जोखिमभरी होती है। सुरक्षित विकल्प:
SQL से NoSQL में जाते समय टीमों को प्रलोभन होता है कि वे तालिकाओं को दस्तावेज़ों के रूप में सीधा नक़ल कर दें। इससे अक्सर होता है:
नई एक्सेस पैटर्न पहले योजना बनाएं, फिर NoSQL स्कीमा को वास्तविक क्वेरीज के चारों ओर डिज़ाइन करें।
एक सामान्य पैटर्न है SQL को प्राधिकृत डेटा के रूप में रखना और NoSQL को रीड‑हेवी व्यूज़ (फ़ीड्स, सर्च, कैश) के लिए उपयोग करना। जो भी मिश्रण हो, इसमें निवेश करें:
इससे माइग्रेशन नियंत्रित रहते हैं, न कि एक‑तरफ़ा दर्दनाक बदलाव।
SQL और NoSQL मुख्यतः चार क्षेत्रों में भिन्न हैं:
किसी श्रेणी में से कोई भी सार्वभौमिक रूप से बेहतर नहीं है। “सही” विकल्प आपके वास्तविक आवश्यकताओं पर निर्भर करता है, न कि ट्रेंड्स पर।
अपनी ज़रूरतें लिखें:
समझदारी से डिफ़ॉल्ट चुनें:
छोटा शुरू करें और नापें:
हाइब्रिड के लिए खुले रहें:
/docs/architecture/datastores पर)।गहराई में जाने के लिए, इस ओवरव्यू को आपकी इंजीनियरिंग हैंडबुक, माइग्रेशन चेकलिस्ट और /blog पर आगे पढ़ने के साथ बढ़ाएँ।
SQL (रिलेशनल) डेटाबेस:
NoSQL (नॉन‑रिलेशनल) डेटाबेस:
SQL डेटाबेस तब उपयोग करें जब:
अधिकांश नए बिजनेस सिस्टम ऑफ़ रिकॉर्ड के लिए SQL एक समझदारी भरा डिफ़ॉल्ट होता है।
NoSQL सबसे उपयुक्त तब होता है जब:
SQL डेटाबेस:
NoSQL डेटाबेस:
SQL डेटाबेस:
कई NoSQL सिस्टम:
यदि स्टेल रीड खतरनाक हैं तो SQL चुनें; यदि थोड़ा‑बहुत स्टेलनेस स्वीकार्य है और स्केल/अपटाइम ज़रूरी है तो NoSQL चुनें।
SQL डेटाबेस आमतौर पर:
NoSQL डेटाबेस आमतौर पर:
हाँ। पोलिग्लॉट परसिस्टेंस सामान्य है:
इंटीग्रेशन पैटर्न में शामिल हैं:
प्रत्येक अतिरिक्त डेटास्टोर तभी जोड़ें जब वह स्पष्ट समस्या हल करे।
सुरक्षित तरीके से कदम बढ़ाने के लिए:
बिग‑बैंग माइग्रेशन से बचें; क्रमिक, मॉनिटर किए गए कदम सुरक्षित रहते हैं।
यहां विचार करने योग्य मुख्य बातें:
सामान्य भ्रांतियाँ:
श्रेणी‑स्तर की मिथकों पर भरोसा न करें; विशिष्ट उत्पाद और आर्किटेक्चर का मूल्यांकन करें।
इसका मतलब है कि स्कीमा कंट्रोल SQL में डेटाबेस पर और NoSQL में अधिकतर एप्लिकेशन पर चला जाता है।
ट्रेड‑ऑफ: NoSQL क्लस्टर ऑपरेशनल रूप से जटिल होते हैं, जबकि SQL एकल नोड की सीमाओं से पहले सरल होते हैं।
महत्वपूर्ण फ्लोज़ के लिए दोनों विकल्पों का प्रोटोटाइप बनाकर लेटेंसी, थ्रूपुट और जटिलता मापें, फिर निर्णय लें।