30 अक्टू॰ 2025·8 मिनट
उत्पाद के अनुसार प्रयोग परिणाम ट्रैक करने वाला वेब ऐप कैसे बनाएं
डेटा मॉडल, मेट्रिक्स, अनुमतियाँ, इंटीग्रेशन, डैशबोर्ड और विश्वसनीय रिपोर्टिंग सहित उत्पादों में प्रयोगों को ट्रैक करने वाला वेब ऐप कैसे बनाएं।
डेटा मॉडल, मेट्रिक्स, अनुमतियाँ, इंटीग्रेशन, डैशबोर्ड और विश्वसनीय रिपोर्टिंग सहित उत्पादों में प्रयोगों को ट्रैक करने वाला वेब ऐप कैसे बनाएं।
अधिकांश टीम्स विचारों की कमी के कारण प्रयोग में फेल नहीं होतीं—वे इसलिए फेल होती हैं क्योंकि परिणाम बिखरे हुए होते हैं। एक उत्पाद में चार्ट एनालिटिक्स टूल में होते हैं, दूसरे में स्प्रेडशीट, तीसरे में स्लाइड डेक में स्क्रीनशॉट। कुछ महीनों बाद कोई साधारण प्रश्नों का उत्तर नहीं दे पाता जैसे “क्या हमने यह पहले टेस्ट किया था?” या “किस वर्शन ने जीता, किस मेट्रिक परिभाषा के साथ?”
एक प्रयोग ट्रैकिंग वेब ऐप को क्या टेस्ट हुआ, क्यों, कैसे मापा गया और क्या हुआ—इन सबको केंद्रीकृत करना चाहिए—विभिन्न उत्पादों और टीमों में। इसके बिना टीमें रिपोर्ट फिर से बनाती हैं, नंबरों पर बहस होती है, और पुराने टेस्ट दोहराए जाते हैं क्योंकि सीखने searchable नहीं होते।
यह सिर्फ एक एनालिस्ट टूल नहीं है।
एक अच्छा ट्रैकर व्यवसायिक मूल्य इस तरह उत्पन्न करता है:
स्पष्ट बताएं: यह ऐप प्राथमिक रूप से परिणाम ट्रैकिंग और रिपोर्टिंग के लिए है—पूरा end-to-end प्रयोग चलाने के लिए नहीं। यह मौजूदा टूल्स (feature flagging, analytics, data warehouse) के आउट-लिंक्स कर सकता है जबकि प्रयोग और उसके अंतिम, सहमत व्याख्या के संरचित रिकॉर्ड का मालिक होगा।
एक MVP ट्रैकर को बिना दस्तावेज़ या स्प्रेडशीट के खोज किए दो प्रश्नों का उत्तर देना चाहिए: हम क्या टेस्ट कर रहे हैं और हमने क्या सीखा। ऐसे कुछ एंटिटीज़ और फ़ील्ड्स के साथ शुरुआत करें जो सभी उत्पादों में काम करें, और केवल तब ही विस्तार करें जब टीम्स को वास्तविक पीड़ा महसूस हो।
डेटा मॉडल इतना सरल रखें कि हर टीम इसे समान तरीके से इस्तेमाल करे:
शुरुआत से सबसे सामान्य पैटर्न्स का समर्थन करें:
भले ही रोलआउट प्रारंभ में औपचारिक सांख्यिकी का उपयोग न करें, उन्हें एक्सपेरिमेंट्स के साथ ट्रैक करना टीम्स को बिना रिकॉर्ड के उसी “टेस्ट” को दोहराने से बचने में मदद करता है।
निर्माण के समय केवल वही मांगे जो बाद में टेस्ट चलाने और व्याख्या करने के लिए जरूरी हों:
संरचना लागू कर के परिणामों की तुलना योग्य बनाएं:
यदि आप केवल यह बनाते हैं, तो टीमें बिना उन्नत एनालिटिक्स या ऑटोमेशन के भी प्रयोग ढूँढ सकती हैं, सेटअप समझ सकती हैं, और परिणाम रिकॉर्ड कर सकती हैं।
क्रॉस‑प्रोडक्ट प्रयोग ट्रैकर अपनी डेटा मॉडल पर टिका होता है। यदि IDs टकराती हैं, मेट्रिक्स ड्रिफ्ट होते हैं, या सेगमेंट असंगत होते हैं, तो आपका डैशबोर्ड “सही” दिख सकता है जबकि गलत कहानी बता रहा हो।
एक स्पष्ट आइडेंटिफायर रणनीति से शुरुआत करें:
checkout_free_shipping_banner) और एक अपरिवर्तनीय experiment_idcontrol, treatment_aयह आपको उत्पादों के पार परिणामों की तुलना करने देता है बिना यह अनुमान लगाए कि “Web Checkout” और “Checkout Web” एक ही हैं या नहीं।
कोर एंटिटीज़ को छोटा और स्पष्ट रखें:
भले ही गणना कहीं और होती हो, outputs (results) स्टोर करने से तेज़ डैशबोर्ड और भरोसेमंद इतिहास मिलता है।
मेट्रिक्स और प्रयोग स्थिर नहीं होते। मॉडल करें:
यह पिछले महीने के प्रयोगों को किसी ने KPI लॉजिक अपडेट करने पर बदलने से रोकता है।
उत्पादों में सुसंगत सेगमेंट के लिए योजना बनाएं: देश, डिवाइस, प्लान टियर, नया बनाम लौटता हुआ।
अंत में, एक ऑडिट ट्रेल जोड़ें जो किसने क्या और कब बदला इसे कैप्चर करे (status बदलाव, ट्रैफिक स्प्लिट, मेट्रिक परिभाषा अपडेट)। यह भरोसेमंदता, रिव्यू और गवर्नेंस के लिए अनिवार्य है।
यदि आपका ट्रैकर मेट्रिक गणित गलत करता है (या उत्पादों में असंगत है), तो “परिणाम” सिर्फ एक राय भर होगा। इसे रोकने का सबसे तेज़ तरीका मेट्रिक्स को साझा उत्पाद संपत्ति मानना है—न कि एड‑हॉक क्वेरी स्निपेट्स।
एक मेट्रिक कैटलॉग बनाएं जो परिभाषाएँ, गणना लॉजिक और उत्तरदायित्व का सिंगल सोर्स ऑफ़ ट्रुथ हो। हर मेट्रिक एंट्री में शामिल होने चाहिए:
कैटलॉग को जगह पर रखें जहाँ लोग काम करते हैं (उदा. प्रयोग निर्माण फ़्लो से लिंक), और इसे वर्शन करें ताकि आप ऐतिहासिक परिणाम समझा सकें।
पहले से तय कर लें कि हर मेट्रिक किस "unit of analysis" का उपयोग करेगी: per user, per session, per account, या per order। एक कनवर्ज़न रेट "per user" और "per session" में असहमति हो सकती है भले ही दोनों सही हों।
कन्फ्यूजन कम करने के लिए, मेट्रिक परिभाषा के साथ एग्रीगेशन विकल्प स्टोर करें, और प्रयोग सेटअप में इसे आवश्यक बनाएं। हर टीम को एड‑हॉक यूनिट चुनने को न दें।
कई उत्पादों में कन्वर्ज़न विंडो होती है (उदा. आज साइनअप, 14 दिनों में खरीद)। एट्रिब्यूशन नियम लगातार परिभाषित करें:
इन नियमों को डैशबोर्ड में स्पष्ट दिखाएँ ताकि रीडर्स जानें वे क्या देख रहे हैं।
तेज़ डैशबोर्ड और ऑडिटेबिलिटी के लिए दोनों स्टोर करें:
यह तेज़ रेंडरिंग सक्षम करता है और साथ ही परिभाषा बदलने पर पुनःगणना की अनुमति देता है।
ऐसा नामकरण मानक अपनाएँ जो अर्थ एन्कोड करे (उदा. activation_rate_user_7d, revenue_per_account_30d)। यूनिक IDs आवश्यक बनाएं, एलियास लागू करें, और मेट्रिक निर्माण के दौरान नज़दीकी‑डुप्लिकेट्स को फ़्लैग करें ताकि कैटलॉग साफ़ रहे।
आपका एक्सपेरिमेंट ट्रैकर उतना ही विश्वसनीय है जितना वह डेटा जो वह لیتا है। लक्ष्य हर उत्पाद के लिए विश्वसनीय रूप से दो प्रश्नों का उत्तर देना है: किसे किस वेरिएंट का एक्सपोज़र मिला, और उसने बाद में क्या किया? बाकी सब—मेट्रिक्स, स्टैटिस्टिक्स, डैशबोर्ड—उस नींव पर निर्भर करते हैं।
अधिकांश टीमें इन पैटर्न्स में से एक चुनती हैं:
जो भी चुनें, हर उत्पाद में न्यूनतम इवेंट सेट मानकीकृत करें: exposure/assignment, प्रमुख conversion events, और उन्हें जोड़ने के लिए पर्याप्त संदर्भ (user ID/device ID, timestamp, experiment ID, variant)।
रॉ इवेंट्स से उन मेट्रिक्स तक स्पष्ट मैपिंग परिभाषित करें जो ट्रैकर रिपोर्ट करेगा (उदा. purchase_completed → Revenue, signup_completed → Activation)। यह मैपिंग प्रत्येक उत्पाद के लिए बनाए रखें, लेकिन नामकरण को उत्पादों के पार सुसंगत रखें ताकि आपका A/B टेस्ट परिणाम डैशबोर्ड "like with like" तुलना कर सके।
पूर्णता की जल्दी सत्यापित करें:
हर लोड पर चलने वाले चेक बनाएं और जब वे फेल हों तेज़ी से अलर्ट करें:
इन्हें प्रयोग से जुड़ी चेतावनियों के रूप में ऐप में दिखाएँ, न कि लॉग्स में छिपा हुआ।
पाइपलाइन्स बदलते हैं। जब आप इंस्ट्रूमेंटेशन बग या डेडुप लॉजिक ठीक करते हैं, तब आपको ऐतिहासिक डेटा रीप्रोसेस करने की ज़रूरत पड़ेगी ताकि मेट्रिक्स और KPIs सुसंगत रहें।
योजना बनाएं:
इंटीग्रेशन्स को एक उत्पाद फीचर की तरह मानें: समर्थित SDKs, इवेंट स्कीमा, और ट्रबलशूटिंग स्टेप्स दस्तावेज़ करें। यदि आपके पास डॉक्स एरिया है तो इसे रिलेटिव पाथ के रूप में लिंक करें जैसे /docs/integrations।
यदि लोग नंबरों पर भरोसा नहीं करते तो वे ट्रैकर का उपयोग नहीं करेंगे। लक्ष्य जटिल गणित से प्रभावित करना नहीं है—बल्कि निर्णयों को दोहराने योग्य और उत्पादों में औपचारिक बनाने का है।
पहले तय करें कि आपकी ऐप frequentist परिणाम (p-values, confidence intervals) रिपोर्ट करेगी या Bayesian परिणाम (सुधार की संभावना, credible intervals)। दोनों काम कर सकते हैं, लेकिन उत्पादों के पार मिश्रण कन्फ्यूज़न पैदा करता है ("एक टेस्ट 97% जीतने की संभावना दिखाता है, जबकि दूसरा p=0.08 दिखाता है—क्यों?").
एक व्यावहारिक नियम: वह अप्रोच चुनें जिसे आपका संगठन पहले से समझता है, फिर शब्दावली, डिफ़ॉल्ट और थ्रेशहोल्ड्स स्टैंडर्डाइज़ करें।
कम से कम, आपके परिणाम दृश्य में ये आइटम अस्पष्ट न रहें:
साथ में दिखाएँ analysis window, गिने गए यूनिट्स (users, sessions, orders), और मेट्रिक परिभाषा वर्शन जिसका उपयोग हुआ। ये “डिटेल्स” सुसंगत रिपोर्टिंग और बहस के बीच फर्क करते हैं।
यदि टीमें कई वेरिएंट, कई मेट्रिक्स, या रोज़ाना परिणाम चेक करती हैं, तो झूठे पॉज़िटिव्स संभाव्य हो जाते हैं। आपकी ऐप को एक नीति एनकोड करनी चाहिए बजाय इसे हर टीम पर छोड़ने के:
ऐसे ऑटोमेटेड फ्लैग जोड़ें जो परिणाम के पास दिखें, लॉग्स में छिपे न हों:
नंबर्स के पास एक छोटा व्याख्यान जोड़ें जो गैर‑तकनीकी पाठक पर भरोसा कर सके, जैसे: “सर्वोत्तम अनुमान +2.1% लिफ्ट है, पर असली प्रभाव संभवतः -0.4% से +4.6% के बीच हो सकता है। हमारे पास अभी निर्णायक साक्ष्य नहीं हैं कि विजेता हो।”
अच्छा एक्सपेरिमेंट टूलिंग लोगों को दो प्रश्नों के उत्तर जल्दी देने में मदद करता है: अगले क्या देखना चाहिए? और इसके बारे में हमें क्या करना चाहिए? UI को संदर्भ के लिए खोजना कम से कम करना चाहिए और “निर्णय स्थिति” स्पष्ट बनानी चाहिए।
शुरुआत तीन पृष्ठों से करें जो अधिकतर उपयोग को कवर करते हैं:
लिस्ट और उत्पाद पृष्ठों पर फिल्टर्स तेज़ और स्टिकी रखें: product, owner, date range, status, primary metric, और segment। लोग कुछ ही सेकंड में "Checkout experiments, owned by Maya, running this month, primary metric = conversion, segment = new users" जैसी खोज कर सकें।
स्टेटस को नियंत्रित शब्दावली की तरह ट्रीट करें, फ्री‑टेक्स्ट नहीं:
Draft → Running → Stopped → Shipped / Rolled back
स्टेटस को हर जगह दिखाएँ (लिस्ट रोज़, डिटेल हेडर, और शेयर लिंक) और रिकॉर्ड करें किसने क्यों बदला। यह "चुप्पी में लॉन्च" और अस्पष्ट परिणामों को रोकता है।
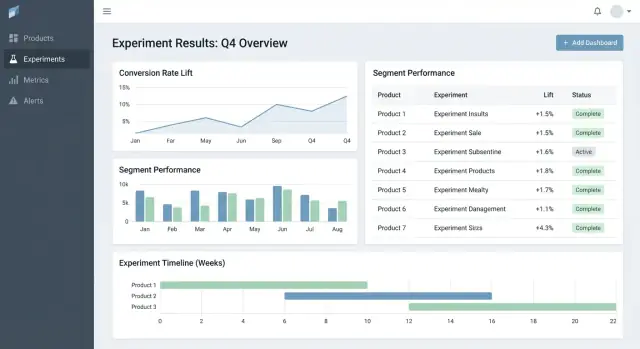
एक्सपेरिमेंट डिटेल व्यू में, मेट्रिक प्रति तालिका के साथ लीड करें:
उन्नत चार्ट्स को "More details" सेक्शन में रखें ताकि निर्णय‑निर्धारक ओवरव्हेल्म न हों।
एनालिस्ट्स के लिए CSV export और स्टेकहोल्डर्स के लिए shareable links जोड़ें, पर एक्सेस लागू करें: लिंक रोल्स और प्रोडक्ट परमिशन का सम्मान करें। एक साधारण “Copy link” बटन और “Export CSV” एक्शन अधिकांश सहयोग ज़रूरतों को कवर करता है।
यदि आपका ट्रैकर कई उत्पादों में फैला है, तो एक्सेस कंट्रोल और ऑडिटेबिलिटी वैकल्पिक नहीं हैं। यही टूल को अपनाने में सुरक्षित और रिव्यू के दौरान भरोसेमंद बनाता है।
सरल रोल्स से शुरुआत करें और उन्हें पूरे ऐप में सुसंगत रखें:
RBAC निर्णयों को केंद्रीकृत रखें (एक पॉलिसी लेयर), ताकि UI और API दोनों एक ही नियम लागू करें।
कई ऑर्ग्स को प्रोडक्ट‑स्कोप्ड एक्सेस चाहिए: टीम A केवल उत्पाद A के प्रयोग देख पाए पर उत्पाद B नहीं। इसे स्पष्ट रूप से मॉडल करें (उदा. user ↔ product memberships), और हर क्वेरी को product द्वारा फ़िल्टर करें।
संवेदनशील मामलों के लिए (उदा. पार्टनर डेटा, विनियमित सेगमेंट) ऊपर रो-स्तर प्रतिबंध जोड़ें। व्यावहारिक दृष्टिकोण: प्रयोगों (या परिणाम स्लाइस) को संवेदनशीलता स्तर से टैग करें और देखने के लिए अतिरिक्त अनुमति आवश्यक करें।
दो चीज़ें अलग-अलग लॉग करें:
चेंज हिस्ट्री को UI में पारदर्शिता के लिए एक्सपोज़ करें, और जाँच के लिए गहरी लॉग्स रखें।
इनके लिए रिटेंशन नियम परिभाषित करें:
रिटेंशन उत्पाद और संवेदनशीलता के अनुसार कॉन्फ़िगर करने योग्य रखें। जब डेटा हटाना आवश्यक हो, तो एक न्यूनतम टॉम्बस्टोन रिकॉर्ड रखें (ID, deletion time, कारण) ताकि रिपोर्टिंग इंटीग्रिटी बनी रहे बिना संवेदनशील सामग्री रखे।
एक ट्रैकर तब वास्तव में उपयोगी बनता है जब वह पूरे प्रयोग लाइफ़साइकल को कवर करता है, सिर्फ अंतिम p-value नहीं। वर्कफ़्लो फ़ीचर्स बिखरे हुए डॉक, टिकट और चार्ट्स को एक दोहराने योग्य प्रक्रिया में बदल देते हैं जो गुणवत्ता बढ़ाती है और सीखने को आसान बनाती है।
प्रयोगों को स्टेट्स की श्रेणी के रूप में मॉडल करें (Draft, In Review, Approved, Running, Ended, Readout Published, Archived)। हर स्टेट का स्पष्ट "exit criteria" होना चाहिए ताकि आवश्यक चीज़ें जैसे hypothesis, primary metric, और guardrails बिना हों प्रायोगिक रूप से लाइव न जाएँ।
अनुमोदन भारी होने की ज़रूरत नहीं है। एक सरल रिव्युअर स्टेप (उदा. प्रोडक्ट + डेटा) और किसने क्या अनुमोदित किया उसका ऑडिट ट्रेल अप्रिय गलतियों को रोक सकता है। पूरा होने के बाद, एक छोटा पोस्ट‑mortem आवश्यक करें ताकि परिणाम और संदर्भ कैप्चर हो सकें फिर प्रयोग "Published" चिह्नित किया जाए।
टेम्प्लेट्स जोड़ें:
टेम्प्लेट्स "खाली पन्ना" बाधा घटाते हैं और समीक्षा तेज करते हैं क्योंकि हर कोई जानता है कहाँ देखना है। इन्हें प्रति उत्पाद संपादनीय रखें पर एक सामान्य कोर संरक्षित रखें।
प्रयोग अकेले कम ही रहते हैं—लोगों को आस-पास का संदर्भ चाहिए। उपयोगकर्ताओं को टिकट/स्पेक्स और संबंधित राइट‑अप्स जोड़ने दें (उदा. /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist)। संरचित “Learning” फ़ील्ड्स स्टोर करें जैसे:
गरार्डरैइल्स के regress होने पर (उदा. error rate, cancellations) या लेट डेटा या मेट्रिक पुनःगणना के बाद जब परिणाम सामरिक रूप से बदलें तो नोटिफ़िकेशन्स सपोर्ट करें। अलर्ट को actionable बनाएं: मेट्रिक, थ्रेशहोल्ड, टाइमफ़्रेम, और एक ओनर दिखाएँ जिसे acknowledge या escalate करना है।
एक लाइब्रेरी प्रदान करें जो उत्पाद, फीचर एरिया, ऑडियंस, मेट्रिक, परिणाम और टैग्स (उदा. “pricing,” “onboarding,” “mobile”) से फिल्टर करे। "Similar experiments" सुझाव जोड़ें साझा टैग/मेट्रिक्स के आधार पर ताकि टीमें वही टेस्ट दोबारा न चलाएँ और बजाय इसके पिछले सीखों पर निर्माण करें।
एक परफेक्ट स्टैक की ज़रूरत नहीं होती—पर स्पष्ट सीमाएँ चाहिए: डेटा कहाँ रहता है, गणनाएँ कहाँ होती हैं, और टीमें परिणामों तक कैसे पहुँचती हैं।
कई टीम्स के लिए एक सरल और स्केलेबल सेटअप ऐसा दिखता है:
यह विभाजन transactional वर्कफ़्लोज़ को तेज़ रखता है जबकि वेयरहाउस बड़े‑पैमाने पर गणना संभालता है।
यदि आप UI प्रोटोटाइप जल्दी उठाना चाहते हैं (experiments list → detail → readout) बिना पूरे इंजीनियरिंग चक्र के, तो एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai आपको चैट स्पेक से React + बैकएंड फ़ाउंडेशन जनरेट करने में मदद कर सकता है। यह विशेष रूप से एंटिटीज़, फार्म्स, RBAC स्कैफ़ोल्डिंग, और ऑडिट‑फ्रेंडली CRUD लगाने में उपयोगी है, फिर आप अपने एनालिटिक्स टीम के साथ डेटा कॉन्ट्रैक्ट्स पर इटरेट कर सकते हैं।
आमतौर पर आपके पास तीन विकल्प होते हैं:
यदि आपका डेटा टीम पहले से भरोसेमंद SQL रखती है तो warehouse-first अक्सर सरल होता है। बैकएंड‑भारी तब काम कर सकता है जब आपको लो‑लेटेंसी अपडेट्स या कस्टम लॉजिक चाहिए, पर इससे ऐप जटिलता बढ़ती है।
एक्सपेरिमेंट डैशबोर्ड अक्सर वही क्वेरी बार‑बार दोहराते हैं (टॉप‑लाइन KPI, टाइम सीरीज़, सेगमेंट कट)। योजना बनाएं:
यदि आप कई उत्पादों या बिज़नेस यूनिट्स सपोर्ट करते हैं, तो जल्दी निर्णय लें:
एक सामान्य समझौता साझा इंफ्रास्ट्रक्चर के साथ मजबूत tenant_id मॉडल और प्रवृत्त रो‑स्तर एक्सेस लागू करना है।
API सतह को छोटा और स्पष्ट रखें। अधिकांश सिस्टम्स को endpoints चाहिए: experiments, metrics, results, segments, और permissions (साथ में ऑडिट‑फ्रेंडली रीड्स)। इससे नए उत्पाद जोड़ना आसान होता है बिना प्लंबिंग दोबारा लिखे।
एक्सपेरिमेंट ट्रैकर तब ही उपयोगी है जब लोग उस पर भरोसा करें। यह भरोसा अनुशासित टेस्टिंग, स्पष्ट मॉनिटरिंग, और अनुमानित ऑपरेशन्स से आता है—खासकर जब कई उत्पाद और पाइपलाइन्स उसी डैशबोर्ड में डेटा फीड करें।
प्रत्येक महत्वपूर्ण चरण के लिए स्ट्रक्चर्ड लॉगिंग से शुरुआत करें: इवेंट इनजेशन, असाइनमेंट, मेट्रिक रोलअप्स, और परिणाम कम्प्यूटेशन। पहचानकर्ता शामिल करें जैसे product, experiment_id, metric_id, और pipeline run_id ताकि सपोर्ट एकल परिणाम को उसके इनपुट्स तक ट्रेस कर सके।
सिस्टम मेट्रिक्स (API latency, job runtimes, queue depth) और डेटा मेट्रिक्स (इवेंट्स प्रोसेस्ड, % लेट इवेंट्स, % ड्रॉप्ड बाय वैलिडेशन) जोड़ें। सर्विसेज़ के पार ट्रेसिंग भी जोड़ें ताकि आप जवाब दे सकें, "यह प्रयोग कल के डेटा क्यों मिस कर रहा है?"।
डेटा फ्रेशनेस चेक सबसे तेज़ तरीका है साइलेंट फेल्यर्स रोकने का। यदि SLA "रोज़ाना 9am तक" है, तो उत्पाद और स्रोत के हिसाब से फ्रेशनेस मॉनिटर करें और अलर्ट करें जब:
तीन स्तरों पर टेस्ट बनाएँ:
एक छोटा "golden dataset" रखें ताकि आप रिलीज़ से पहले रिग्रेशन पकड़ सकें।
माइग्रेशन्स को ऑपरेशन्स का हिस्सा मानें: अपने मेट्रिक परिभाषाओं और परिणाम कम्प्यूटेशन लॉजिक को वर्शन करें, और ऐतिहासिक प्रयोगों को बिना अनुरोध के पुनःलिखित न करें। जब बदलाव आवश्यक हों, तो नियंत्रित बैकफिल पथ दें और ऑडिट ट्रेल में क्या बदला इसका दस्तावेज़ रखें।
एक एडमिन व्यू प्रदान करें ताकि किसी विशेष प्रयोग/तिथि‑रेंज के लिए पाइपलाइन फिर से चलाई जा सके, वैलिडेशन त्रुटियाँ निरीक्षण की जा सकें, और घटनाओं को स्थिति अपडेट के साथ टैग किया जा सके। प्रभावित प्रयोगों से सीधे incident नोट्स लिंक करें ताकि उपयोगकर्ता देरी समझें और अधूरी डेटा पर निर्णय न लें।
एक्सपेरिमेंट ट्रैकिंग वेब ऐप को उत्पादों में रोलआउट करना "लॉन्च डे" की बात नहीं है—यह अस्पष्टता को निरंतर कम करने के बारे में है: क्या ट्रैक होता है, किसका मालिक कौन है, और क्या नंबर वास्तविकता से मेल खाते हैं।
एक उत्पाद और एक छोटा, उच्च‑कॉनफिडेंस मेट्रिक सेट (उदा. conversion, activation, revenue) से शुरू करें। लक्ष्य आपका end-to-end वर्कफ़्लो मान्य करना है—एक प्रयोग बनाना, एक्सपोज़र और परिणाम कैप्चर करना, परिणामों की गणना, और निर्णय रिकॉर्ड करना—इससे पहले कि आप जटिलता बढ़ाएँ।
पहले उत्पाद के स्थिर होने पर, उत्पाद दर उत्पाद विस्तार करें एक पूर्वानुमेय ऑनबोर्डिंग cadence के साथ। हर नया उत्पाद एक दोहराने योग्य सेटअप जैसा महसूस होना चाहिए, कोई कस्टम परियोजना नहीं।
यदि आपकी संस्था लंबे "प्लेटफ़ॉर्म बिल्ड" चक्रों में फँसती है, तो एक दो‑ट्रैक दृष्टिकोण पर विचार करें: दृढ़ डेटा कॉन्ट्रैक्ट्स (इवेंट्स, IDs, मेट्रिक परिभाषाएँ) को एक साथ बनाएं और एक पतली एप्लिकेशन लेयर को समानांतर में बनाएं। टीमें कभी‑कभी Koder.ai का उपयोग उस पतली परत को जल्दी खड़ा करने के लिए करती हैं—फार्म्स, डैशबोर्ड, परमिशन्स, और एक्सपोर्ट—फिर अपनाने बढ़ने पर इसे हार्डन करती हैं (स्रोत कोड एक्सपोर्ट और स्नैपशॉट्स के माध्यम से इटरेटिव रोलबैक सहित)।
उत्पादों और इवेंट स्कीमाज़ को सुसंगत रूप से ऑनबोर्ड करने के लिए एक हल्की चेकलिस्ट उपयोग करें:
जहाँ अपनाने में मदद मिले वहाँ प्रयोग परिणामों से "next steps" संबंधित उत्पाद क्षेत्रों की ओर लिंक करें (उदा. प्राइसिंग‑संबंधी प्रयोग /pricing को लिंक कर सकते हैं)। लिंक सूचनात्मक और न्यूट्रल रखें—कोई निहित परिणाम नहीं।
मापें कि टूल निर्णयों के लिए डिफ़ॉल्ट जगह बन रहा है या नहीं:
अमल में, अधिकांश रोलआउट कुछ दोहराने वाले कारणों पर अटकते हैं:
इन सावधानियों के साथ आप धीरे‑धीरे अस्पष्टता कम कर के संगठन के लिए एक भरोसेमंद प्रयोग रिकॉर्ड बना सकते हैं।
प्रत्येक प्रयोग का अंतिम, सहमत रिकॉर्ड केंद्रीकृत करके शुरुआत करें:
आप फीचर-फ्लैग टूल और एनालिटिक्स सिस्टमों के लिंक जोड़ सकते हैं, लेकिन ट्रैकर को संरचित इतिहास का मालिक होना चाहिए ताकि परिणाम समय के साथ खोजने योग्य और तुलनात्मक बने रहें।
नहीं—स्कोप को स्पष्ट रखें: यह ऐप परिणामों को ट्रैक और रिपोर्ट करने पर केंद्रित होना चाहिए।
एक व्यावहारिक MVP में शामिल है:
इससे आप पूरा एक्सपेरिमेंटेशन प्लेटफ़ॉर्म फिर से बनाने से बचते हुए “छितरे हुए परिणाम” की समस्या सुलझा लेते हैं।
एक न्यूनतम मॉडल जो टीमों के बीच काम करता है:
डिस्प्ले नामों को एडिटेबल लेबल मानते हुए स्थिर IDs का उपयोग करें:
product_id: बदलना नहीं चाहिए, भले ही उत्पाद का नाम बदलेexperiment_id: आंतरिक अपरिवर्तनीय IDexperiment_key: पठनीय स्लग (प्रति-उत्पाद यूनिक बनाया जा सकता है)सेटअप के समय “सक्सेस क्राइटेरिया” को स्पष्ट रखें:
इस संरचना से बाद में बहस कम होती है क्योंकि पाठक देख सकते हैं कि टेस्ट से पहले "जीत" का क्या मतलब था।
एक कैनोनिकल मेट्रिक कैटलॉग बनाकर:
जब लॉजिक बदलती है, तो इतिहास में बदलाव करने की बजाय नया मेट्रिक वर्शन पब्लिश करें—और हर प्रयोग में किस वर्शन का उपयोग हुआ, वह स्टोर करें।
न्यूनतम इंस्ट्रूमेंटेशन और डेटा क्वालिटी चेक जो चाहिए:
फिर इन चेक्स को ऑटोमेट करें जैसे:
एक “डायलैक्ट” चुनें और उसी पर टिके रहें:
जो भी चुनें, UI में हमेशा दिखाएँ:
पहले से ही मानक के रूप में एक्सेस कंट्रोल को लें, न कि बाद में जोड़ें:
और दो ऑडिट ट्रेल रखें:
रोलआउट को दोहराने योग्य क्रम में करें:
सामान्य पिटफॉल्स से बचें:
product_id)experiment_id + पठनीय experiment_key)control, treatment_a, आदि)यदि आप अपेक्षा करते हैं तो शुरुआत में Segment और Time window भी जोड़ें (उदा. new vs returning, 7-day vs 30-day)।
variant_key: स्थिर स्ट्रिंग जैसे control, treatment_aयह से नाम टकराव रोकता है और नामकरण ड्रिफ्ट होने पर भी क्रॉस-प्रोडक्ट रिपोर्टिंग विश्वसनीय बनाता है।
इन चेतावनियों को प्रयोग पेज पर दिखाएँ ताकि इन्हें अनदेखा न किया जा सके।
संगति जटिलता से अधिक मायने रखती है जब संगठन-व्यापी भरोसा बनाना हो।
यही चीज़ ट्रैकर को उत्पादों और टीमों में अपनाने के लिए सुरक्षित बनाती है।
इनका ध्यान रखकर आप अपनाने को आसान बना सकते हैं।