18 अक्टू॰ 2025·8 मिनट
डेटा इम्पोर्ट, एक्सपोर्ट और वैधता के लिए वेब ऐप कैसे बनाएं
CSV/Excel/JSON आयात‑निर्यात, स्पष्ट त्रुटियों के साथ डेटा मान्यकरण, रोल्स का समर्थन, ऑडिट लॉग और भरोसेमंद प्रोसेसिंग डिजाइन करना सीखें।
CSV/Excel/JSON आयात‑निर्यात, स्पष्ट त्रुटियों के साथ डेटा मान्यकरण, रोल्स का समर्थन, ऑडिट लॉग और भरोसेमंद प्रोसेसिंग डिजाइन करना सीखें।
स्क्रीन डिज़ाइन या फ़ाइल पार्सर चुनने से पहले यह स्पष्ट कर लें कि कौन आपके प्रोडक्ट में डेटा ला‑रहा/लेजा‑रहा है और क्यों. इंटर्नल ऑपरेटर्स के लिए बना एक डेटा इम्पोर्ट ऐप ग्राहकों द्वारा इस्तेमाल किये जाने वाले सेल्फ‑सर्व एक्सेल इम्पोर्ट टूल से काफी अलग दिखेगा।
पहले उन рол्स की सूची बनाइए जो इम्पोर्ट/एक्सपोर्ट से जुड़ेंगे:
हर रोल के लिए अपेक्षित स्किल‑लेवल और जटिलता सहिष्णुता परिभाषित करें। कस्टमर आमतौर पर कम विकल्प और बेहतर इन‑प्रोडक्ट व्याख्याएँ चाहते हैं।
अपने शीर्ष परिदृश्यों को लिखें और प्राथमिकता दें। आम उदाहरण:
फिर सफलता मेट्रिक्स परिभाषित करें जिन्हें आप माप सकते हैं। उदाहरण: कम फेल्ड इम्पोर्ट्स, एरर‑रिज़ॉल्यूशन का तेज़ समय, और “मेरी फ़ाइल अपलोड नहीं हो रही” पर कम सपोर्ट टिकट्स। ये मेट्रिक्स बाद में trade‑offs करने में मदद करेंगे (जैसे स्पष्ट एरर रिपोर्टिंग में निवेश बनाम और अधिक फ़ाइल फॉर्मैट का समर्थन)।
दिने‑एक पर आप क्या सपोर्ट करेंगे यह स्पष्ट करें:
अंत में, जल्दी से कंप्लायंस ज़रूरतें पहचानें: क्या फ़ाइलों में PII है, रिटेंशन की ज़रूरतें (फ़ाइलें कितनी देर रखें), और ऑडिट ज़रूरतें (किसने क्या इम्पोर्ट किया, कब, और क्या बदला)। ये निर्णय स्टोरेज, लॉगिंग, और परमीशन्स को प्रभावित करेंगे।
किसी फैंसी कॉलम‑मैपिंग UI या CSV पार्सिंग नियम पर जाने से पहले ऐसा आर्किटेक्चर चुनें जिसे आपकी टीम भरोसे से शिप और ऑपरेट कर सके। इम्पोर्ट/एक्सपोर्ट "बोरिंग" इंफ्रास्ट्रक्चर होते हैं — iteration की गति और डिबग्गेबिलिटी नवीनता से ज़्यादा मायने रखती हैं।
कोई भी मेनस्ट्रीम वेब स्टैक डेटा इम्पोर्ट वेब ऐप चला सकता है। मौजूदा कौशल और हायरिंग रियलिटीज के आधार पर चुनें:
कुंजी है सुसंगतता: स्टैक ऐसा होना चाहिए जिससे नए इम्पोर्ट प्रकार, नए डेटा वैलिडेशन नियम, और नए एक्सपोर्ट फॉर्मैट जोड़ना बिना बड़े री‑राइट के आसान हो।
यदि आप प्रोटोटाइप के लिए तेजी चाहते हैं, तो एक कोड‑जनरेटिंग प्लेटफ़ॉर्म जैसे Koder.ai मददगार हो सकता है: आप अपने इम्पोर्ट फ्लो (upload → preview → mapping → validation → background processing → history) का वर्णन चैट में कर सकते हैं, React UI के साथ Go + PostgreSQL बैकएंड जेनरेट कर सकते हैं, और planning mode तथा snapshots/rollback से तेज़ी से iterate कर सकते हैं।
संरचित रिकॉर्ड्स, upserts, और डेटा‑परिवर्तन के ऑडिट के लिए रिलेशनल डेटाबेस (Postgres/MySQL) का उपयोग करें।
मूल अपलोड्स (CSV/Excel) को object storage (S3/GCS/Azure Blob) में स्टोर करें। raw फ़ाइलें सपोर्ट के लिए अमूल्य होती हैं: आप पार्सिंग इश्यूज़ reproduce कर सकते हैं, जॉब्स री‑रन कर सकते हैं, और एरर‑हैंडलिंग निर्णय समझा सकते हैं।
छोटी फ़ाइलें सिंक्रोनस (upload → validate → apply) चल सकती हैं ताकि UX स्नैपी रहे। बड़ी फ़ाइलों के लिए काम को बैकग्राउंड जॉब्स में ले जाएँ:
यह retries और rate‑limited writes के लिए भी अच्छा सेटअप है।
यदि आप SaaS बना रहे हैं, तो जल्दी तय करें कि आप टेनेंट डेटा कैसे अलग करेंगे (रो‑लेवल स्कोपिंग, अलग स्कीमा, या अलग DB)। यह निर्णय आपके डेटा एक्सपोर्ट API, परमीशन्स, और प्रदर्शन को प्रभावित करेगा।
अपटाइम टारगेट, मैक्स फ़ाइल साइज, एक इम्पोर्ट पर अपेक्षित रोज़, पूरा होने का समय, और लागत‑लिमिट लिखें। ये संख्याएँ जॉब क्यू चॉइस, बैचिंग स्ट्रैटेजी, और इंडेक्सिंग को प्रभावित करेंगी—UI पॉलिश करने से पहले।
इंटेक फ्लो हर इम्पोर्ट का टोन सेट करता है। अगर यह अनुमान्य और माफ़ी‑लायक लगे, तो यूज़र गलती होने पर फिर से कोशिश करेंगे—और सपोर्ट टिकट घटेंगे।
वेब UI के लिए drag‑and‑drop जोन के साथ क्लासिक फ़ाइल पिकर ऑफर करें। ड्रैग‑एंड‑ड्रॉप पावर‑यूज़र्स के लिए तेज़ है, जबकि फ़ाइल पिकर अधिक सुलभ और परिचित है।
यदि आपके कस्टमर दूसरे सिस्टम से इम्पोर्ट करते हैं, तो एक API endpoint भी जोड़ें। यह multipart अपलोड (file + metadata) स्वीकार कर सकता है या बड़े फ़ाइलों के लिए pre‑signed URL फ्लो।
अपलोड पर हल्का पार्सिंग करें ताकि बिना कमिट किये एक “preview” बनाया जा सके:
यह प्रीव्यू बाद के कदमों जैसे कॉलम मैपिंग और वैलिडेशन का आधार बनता है।
हमेशा मूल फ़ाइल को सुरक्षित रूप से स्टोर करें (object storage सामान्य है). इसे immutable रखें ताकि आप:
हर अपलोड को एक प्रथम‑कक्षा रिकॉर्ड मानें। अपलोडर, टाइमस्टैम्प, स्रोत सिस्टम, फ़ाइल नाम, और checksum जैसे मेटाडेटा सेव करें (डुप्लिकेट्स पहचानने और इंटिग्रिटी सुनिश्चित करने के लिए)। यह ऑडिटबिलिटी और डिबगिंग के लिए अमूल्य बनता है।
तेज़ प्री‑चेक तुरंत चलाएँ और ज़रूरी होने पर जल्दी फेल करें:
यदि प्री‑चेक फेल होता है, तो स्पष्ट संदेश लौटाएँ और दिखाएँ क्या सुधारना है। लक्ष्य है कि वास्तव में खराब फ़ाइलों को जल्दी ब्लॉक करें—बिना उन वैध परिदृश्यों को रोकने के जो बाद में मैप/क्लीन किए जा सकते हैं।
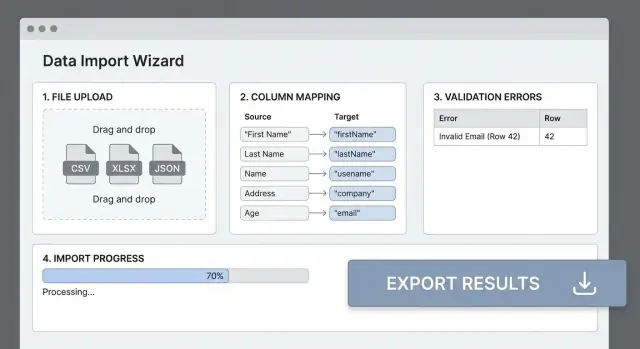
अधिकतर इम्पोर्ट फेल्यर इसलिए होते हैं क्योंकि फ़ाइल का हैडर आपके ऐप के फील्ड से मेल नहीं खाता। एक स्पष्ट कॉलम मैपिंग स्टेप “गन्दा CSV” को predictable इनपुट में बदल देता है और यूज़र्स को ट्रायल‑एंड‑एरर से बचाता है।
سادा टेबल दिखाएँ: Source column → Destination field. संभावित मेल (case‑insensitive हैडर मैचिंग, synonyms जैसे “E‑mail” → email) ऑटो‑डिटेक्ट करें, पर हमेशा यूज़र को ओवरराइड करने दें।
कुछ यूज़र‑सहायक फीचर शामिल करें:
यदि कस्टमर हर हफ्ते वही फॉर्मैट इम्पोर्ट करता है, तो एक‑क्लिक पर इसे संभव बनाएं। टेम्पलेट्स को स्कोप करें:
जब नई फ़ाइल अपलोड हो, तो कॉलम ओवरलैप के आधार पर एक टेम्पलेट सुझाएँ। वर्जनिंग भी सपोर्ट करें ताकि यूज़र टेम्पलेट अपडेट कर सकें बिना पुराने रन तोड़े।
हर मैप्ड फ़ील्ड के लिए हल्के ट्रांसफ़ॉर्म जोड़ें:
UI में ट्रांसफ़ॉर्म स्पष्ट रखें (“Applied: Trim → Parse Date”) ताकि आउटपुट explainable रहे।
पूरी फ़ाइल प्रोसेस करने से पहले (उदा. 20 रो) मैप्ड परिणामों का प्रीव्यू दिखाएँ। मूल वैल्यू, ट्रांसफ़ॉर्म किया हुआ वैल्यू, और वार्निंग्स (जैसे “Could not parse date”) दिखाएँ। यहाँ यूज़र्स जल्दी समस्याएँ पकड़ते हैं।
यूज़र्स से एक key field (email, external_id, SKU) चुनवाएँ और बताएं कि डुप्लिकेट्स पर क्या होगा। भले ही आप बाद में upserts संभालें, यह स्टेप उम्मीदें सेट करता है: आप फ़ाइल में डुप्लिकेट कीज के बारे में वार्न कर सकते हैं और सुझाव दे सकते हैं कि कौन‑सा रिकॉर्ड “जीतेगा” (first, last, या error)।
वैलिडेशन ही “फ़ाइल अपलोडर” और भरोसेमंद इम्पोर्ट फीचर के बीच फर्क है। लक्ष्य सख्त होना नहीं है—बल्कि खराब डेटा के फैलने को रोकना और यूज़र्स को स्पष्ट, actionable फीडबैक देना है।
वैलिडेशन को तीन अलग चेक के रूप में ट्रीट करें, हर एक का अलग उद्देश्य है:
email स्ट्रिंग है?”, “क्या amount नंबर है?”, “क्या customer_id मौजूद है?” यह तेज़ है और पार्सिंग के बाद तुरंत चलाया जा सकता है।country=US है तो state आवश्यक है”, “end_date को start_date के बाद होना चाहिए”, “Plan name इस workspace में मौजूद होना चाहिए।” ये अक्सर कॉन्टेक्स्ट (अन्य कॉलम या DB लुकअप) मांगते हैं।इन परतों को अलग रखना सिस्टम को बढ़ाने और UI में समझाने में आसान बनाता है।
पहले तय करें कि इम्पोर्ट:
आप दोनों सपोर्ट भी कर सकते हैं: default strict और एडमिन्स के लिए “Allow partial import” विकल्प।
हर एरर को यह उत्तर देना चाहिए: क्या हुआ, कहाँ हुआ, और इसे कैसे ठीक करें.
उदाहरण: “Row 42, Column ‘Start Date’: YYYY‑MM‑DD फॉर्मैट में मान्य तारीख होनी चाहिए।”
तफ़नी करें:
यूज़र्स शायद सब कुछ एक पास में ठीक न करें। री‑अपलोड को painless बनाइए—वैलिडेशन परिणाम इम्पोर्ट अटेम्प्ट से जुड़े रहें और यूज़र को करेक्टेड फ़ाइल री‑अपलोड करने दें। यह downloadable error reports के साथ जोड़ें ताकि वे बुल्क में समस्याएँ ठीक कर सकें।
एक व्यावहारिक दृष्टिकोण हाइब्रिड है:
यह वैलिडेशन को लचीला बनाता है बिना इसे debugging‑मज़ाक बना दिए।
इम्पोर्ट्स अक्सर साधारण कारणों से फेल होते हैं: धीमा DB, पीक टाइम पर फ़ाइल स्पाइक्स, या एक “बुरी” रो जो पूरे बैच को ब्लॉक कर दे। विश्वसनीयता का अधिकांश हिस्सा भारी काम को request/response पथ से हटाने और हर स्टेप को फिर से चलाने के लिए सुरक्षित बनाने में है।
पार्सिंग, वैलिडेशन, और लिखाई को बैकग्राउंड जॉब्स (queues/workers) में चलाएँ ताकि अपलोड्स वेब टाइमआउट न मारें। यह वर्कर्स को स्वतंत्र रूप से scale करने का भी मौका देता है जब कस्टमर बड़े स्प्रेडशीट इम्पोर्ट करना शुरू करते हैं।
प्रैक्टिकल पैटर्न है कि काम को चंक्स में बाँटना (उदा. 1,000 रो प्रति जॉब). एक "parent" इम्पोर्ट जॉब chunk जॉब्स शेड्यूल करता है, परिणाम aggregate करता है, और प्रोग्रेस अपडेट करता है।
इम्पोर्ट को एक स्टेट मशीन के रूप में मॉडल करें ताकि UI और ऑप्स टीम हमेशा जानें क्या हो रहा है:
हर स्टेट‑ट्रांज़िशन के लिए टाइमस्टैम्प और attempt counts स्टोर करें ताकि आप बिना लॉग खोदे जवाब दे सकें कि “यह कब शुरू हुआ?” और “कितनी retries हुईं?”।
मापनीय प्रोग्रेस दिखाएँ: प्रोसेस हुए रो, शेष रो, और अब तक मिली त्रुटियाँ। यदि आप थ्रूपुट अनुमानित कर सकते हैं तो एक मोटा ETA जोड़ें—पर सटीक काउंटडाउन के बजाय “~3 मिनट” पसंद करें।
Retries डुप्लिकेट्स या डबल‑अपडेट नहीं पैदा करें। सामान्य तकनीकें:
प्रति workspace समवर्ती इम्पोर्ट्स पर rate‑limit करें और लिखाई‑भारी स्टेप्स (उदा. max N rows/sec) throttle करें ताकि DB ओवरवेल्म न हो और दूसरों का अनुभव खराब न हो।
यदि लोग समझ ही न पायें कि क्या गलत हुआ, तो वे वही फ़ाइल बार‑बार री‑ट्राई करेंगे। हर इम्पोर्ट को प्रथम‑कक्षा “रन” मानें और स्पष्ट पेपर‑ट्रेल और actionable एरर दें।
फ़ाइल सबमिट होते ही एक import run एंटिटी बनाइए। इस रिकॉर्ड में शामिल होनी चाहिए:
यह आपके इम्पोर्ट हिस्ट्री स्क्रीन का आधार बनेगा: रन की लिस्ट स्टेटस, काउंट्स, और “व्यू डिटेल्स” पेज के साथ।
एप्लिकेशन लॉग्स इंजीनियरों के लिए अच्छे हैं, पर यूज़र्स को क्वेरीयोग्य एरर्स चाहिए। एरर्स को संरचित रिकॉर्ड्स के रूप में स्टोर करें:
इस संरचना से आप तेज़ फ़िल्टरिंग और aggregate insights (उदा. “इस सप्ताह टॉप 3 एरर टाइप”) दे पाएंगे।
रन डिटेल्स पेज में कॉलम/टाइप/सीवेरिटी से फ़िल्टर, और एक सर्च बॉक्स (उदा. “email”) दें। फिर एक डाउनलोडेबल CSV एरर रिपोर्ट ऑफर करें जिसमें ऑरिजिनल रो, error_columns, और error_message जैसी अतिरिक्त कॉलम हों, साथ में स्पष्ट मार्गदर्शन जैसे “तिथि फ़ॉर्मैट को YYYY‑MM‑DD में ठीक करें।”
एक dry run सब कुछ उसी मैपिंग और नियमों के साथ वैलिडेट करता है पर डेटा नहीं लिखता। यह पहले‑बार के इम्पोर्ट के लिए आदर्श है और यूज़र्स को बिना कमिट किए iterate करने देता है।
इम्पोर्ट्स तब "हो गए" माने जाते हैं जब रोज़ आपके DB में उतर ही जाती हैं—पर दीर्घकालिक लागत अक्सर गंदे अपडेट्स, डुप्लिकेट्स, और अस्पष्ट परिवर्तन इतिहास में होती है। यह सेक्शन डेटा मॉडल को इस तरह डिज़ाइन करने के बारे में है कि इम्पोर्ट्स predictable, reversible, और explainable हों।
प्रत्येक एंटिटी के लिए परिभाषित करें कि एक इम्पोर्ट पंक्ति आपके डोमेन मॉडल से कैसे मैप होती है। तय करें कि इम्पोर्ट:
यह निर्णय इम्पोर्ट सेटअप UI में स्पष्ट होना चाहिए और इम्पोर्ट जॉब के साथ स्टोर किया जाना चाहिए ताकि व्यवहार repeatable रहे।
यदि आप "create or update" सपोर्ट करते हैं, तो स्थिर upsert कीज़ चाहिएँ—फील्ड्स जो हर बार एक ही रिकॉर्ड की पहचान करें। आम विकल्प:
external_id (सबसे अच्छा जब दूसरे सिस्टम से आ रहा हो)account_id + sku)कोलाइजन हैंडलिंग नियम परिभाषित करें: यदि दो रो एक ही की शेयर करते हैं, या की कई रिकॉर्ड्स से मैच करती है तो क्या होगा? अच्छे डिफॉल्ट्स हैं “उस रो को फेल करें स्पष्ट एरर के साथ” या “last row wins”, पर ये जानबूझकर चुनें।
जहाँ कंसिस्टेंसी बचाती है वहाँ ट्रांज़ैक्शन का उपयोग करें (उदा. एक parent और उसके children बनाना)। एक 200k‑रो फ़ाइल के लिए एक बड़ा ट्रांज़ैक्शन से बचें; यह टेबल्स लॉक कर सकता है और retries को कठिन बना देता है। चंकेड राइट्स (500–2,000 रो प्रति बैच) और idempotent upserts पसंद करें।
इम्पोर्ट्स रिश्तों का सम्मान करें: यदि एक रो parent रिकॉर्ड को रेफ़रेंस करती है (जैसे Company), तो या तो उसे मौजूद होना चाहिए या controlled स्टेप में बनाना चाहिए। “Missing parent” एरर के साथ जल्दी फेल करना आधे‑कनेक्टेड डेटा से बचाता है।
इम्पोर्ट‑ड्रिवन चेंजेज़ के लिए ऑडिट लॉग जोड़ें: किसने इम्पोर्ट ट्रिगर किया, कब, सोर्स फ़ाइल, और प्रति‑रिकॉर्ड का सारांश (old vs new)। यह सपोर्ट को आसान बनाता है, यूज़र विश्वास बनाता है, और रोलबैक को सरल बनाता है।
एक्सपोर्ट साधारण दिखते हैं जब तक ग्राहक अंतिम समय पर “सब कुछ” डाउनलोड करने की कोशिश न करें। एक स्केलेबल एक्सपोर्ट सिस्टम बड़ी datasets को बिना आपकी ऐप धीमी किए हैंडल कर सके।
तीन विकल्प से शुरू करें:
इंक्रेमेन्टल एक्सपोर्ट्स इंटीग्रेशन्स के लिए विशेष रूप से मददगार हैं और बार‑बार पूर्ण डम्प की तुलना में लोड कम करते हैं।
जो भी चुनें, संगत हैडर और स्थिर कॉलम‑क्रम रखें ताकि डाउनस्ट्रीम प्रोसेसेज़ टूटें नहीं।
बड़े एक्सपोर्टस सभी रोज़ को मेमोरी में लोड नहीं करने चाहिए। फेच करते वक्त रोज़ लिखने के लिए पेजिनेशन/स्ट्रीमिंग का उपयोग करें। इससे टाइमआउट्स बचते हैं और आपकी वेब ऐप रिस्पॉन्सिव रहती है।
बड़े datasets के लिए एक्सपोर्ट एक बैकग्राउंड जॉब में बनाएं और यूज़र को तैयार होने पर नोटिफाई करें। सामान्य पैटर्न:
यह आपके इम्पोर्ट बैकग्राउंड जॉब्स पैटर्न और एरर रिपोर्ट्स के साथ अच्छा मेल खाता है।
एक्सपोर्ट अक्सर ऑडिट होते हैं। हमेशा शामिल करें:
ये विवरण भ्रम घटाते हैं और भरोसेमंद reconciliation में मदद करते हैं।
इम्पोर्ट और एक्सपोर्ट शक्तिशाली फीचर हैं क्योंकि वे जल्दी से बहुत सारा डेटा मूव कर सकते हैं। यही कारण है कि यहाँ सुरक्षा बग अक्सर होते हैं: एक ओवर‑पर्मिसिव रोल, एक लीक हुआ फ़ाइल URL, या एक लॉग लाइन जिसमें गलती से पर्सनल डेटा शामिल हो।
शुरू करें उसी ऑथेंटिकेशन से जो आप पूरे ऐप में उपयोग करते हैं—इम्पोर्ट के लिए एक "स्पेशल" ऑथ पाथ न बनाएं।
यदि आपके यूज़र्स ब्राउज़र में काम करते हैं, तो session‑based auth (और वैकल्पिक SSO/SAML) आमतौर पर बेहतर फिट होती है। यदि इम्पोर्ट/एक्सपोर्ट ऑटोमेटेड हैं (नाइटली जॉब्स, इंटीग्रेशन पार्टनर्स), तो API keys या OAuth टोकन्स पर विचार करें जिनके स्पष्ट स्कोप और रोटेशन हों।
एक प्रैक्टिकल नियम: इम्पोर्ट UI और इम्पोर्ट API दोनों को एक ही परमीशन्स लागू करने चाहिए, भले ही वे अलग‑अलग ऑडियंस द्वारा इस्तेमाल हों।
इम्पोर्ट/एक्सपोर्ट क्षमताओं को स्पष्ट विशेषाधिकार के रूप में ट्रीट करें। सामान्य रोल्स:
“डाउनलोड फ़ाइल” को अलग परमीशन बनाइए। बहुत सारे सेंसिटिव लीक तब होते हैं जब कोई रन देख सकता है और सिस्टम यह मान लेता है कि वे ऑरिजिनल स्प्रेडशीट भी डाउनलोड कर सकते हैं।
साथ ही रो‑लेवल या टेनेंट‑लेवल बाउंड्री पर विचार करें: यूज़र केवल उसी अकाउंट/वर्कस्पेस का डेटा इम्पोर्ट/एक्सपोर्ट कर सके जिसको वे संबंधित हों।
स्टोर्ड फ़ाइल्स (अपलोड्स, जनरेटेड एरर CSVs, एक्सपोर्ट आर्काइव) के लिए प्राइवेट ऑब्जेक्ट स्टोरेज और शॉर्ट‑लाइव डाउनलोड लिंक उपयोग करें। आवश्यक होने पर rest पर encrypt करें, और सुनिश्चित करें कि मूल अपलोड, प्रोसेस्ड स्टेजिंग फ़ाइल, और कोई भी जनरेटेड रिपोर्ट एक ही नियमों का पालन करें।
लॉग्स के साथ सावधान रहें। संवेदनशील फ़ील्ड (ईमेल, फोन, IDs, पते) रेडैक्ट करें और डिफ़ॉल्ट रूप से कच्ची पंक्तियाँ लॉग न करें। जब डिबगिंग ज़रूरी हो, तो “verbose row logging” को admin‑only सेटिंग के पीछे रखें और सुनिश्चित करें कि वह एक्सपायर्ड हो जाए।
हर अपलोड को untrusted इनपुट मानें:
स्ट्रक्चर को जल्दी validate करें: स्पष्ट malformed फ़ाइलों को बैकग्राउंड जॉब्स तक पहुँचने से पहले रिजेक्ट करें और यूज़र को स्पष्ट संदेश दें कि क्या गलत है।
वो इवेंट्स रिकॉर्ड करें जो जांच में काम आएँ: किसने फ़ाइल अपलोड की, किसने इम्पोर्ट शुरू किया, किसने एक्सपोर्ट डाउनलोड किया, परमीशन बदले, और फेल्ड एक्सेस प्रयास।
ऑडिट एंट्रीज़ में actor, timestamp, workspace/tenant, और प्रभावित ऑब्जेक्ट (import run ID, export ID) शामिल हों, पर संवेदनशील रो डेटा स्टोर न करें। यह आपके इम्पोर्ट हिस्ट्री UI के साथ अच्छी तरह जुड़ता है और यह जल्दी जवाब देने में मदद करेगा कि “किसने क्या बदला, और कब?”।
यदि इम्पोर्ट/एक्सपोर्ट ग्राहक डेटा को छूते हैं, तो अंततः आपको एज‑केस मिलेंगे: अजीब एनकोडिंग, मर्ज़ की हुई सेल्स, आधी‑भरी पंक्तियाँ, डुप्लिकेट्स, और “कल काम कर रहा था” रहस्य। ऑपरेबिलिटी इन्हें सपोर्ट‑नाइटमेयर बनने से रोकती है।
सबसे दोष‑प्रवण भागों (पार्सिंग, मैपिंग, वैलिडेशन) के आसपास फ़ोकस्ड टेस्ट लिखें:
फिर कम से कम एक end‑to‑end test जोड़ें: upload → background processing → report generation। ये टेस्ट UI, API, और वर्कर्स के बीच अनुबंध मिसमैच पकड़ते हैं (उदा. जॉब पेलोड में मैपिंग कॉन्फ़िग गायब)।
ऐसे संकेत ट्रैक करें जो यूज़र इम्पैक्ट दिखाते हैं:
अलर्ट्स उन लक्षणों पर वायर्ड करें (बढ़ती फेल्यर्स, बढ़ता क्यू डेप्थ) बजाय हर exception पर।
आंतरिक टीम्स को छोटे एडमिन सतह दें ताकि वे जॉब्स री‑रन, अदालत कर सकें (cancel), और फेल्यर्स का निरीक्षण कर सकें (इनपुट फ़ाइल मेटाडेटा, उपयोग की गयी मैपिंग, एरर सारांश, और लॉग/ट्रेस के लिंक)।
यूज़र्स के लिए preventable एरर्स को inline टिप्स, डाउनलोडेबल सैंपल टेम्पलेट्स, और एरर स्क्रीन में स्पष्ट अगले कदम के साथ घटाएँ। इम्पोर्ट UI से सहायता पृष्ठ लिंक करें (उदा. /docs)।
एक इम्पोर्ट/एक्सपोर्ट सिस्टम शिप करना सिर्फ़ "प्रोडक्शन में पुश" नहीं है। इसे उत्पाद फ़ीचर की तरह ट्रीट करें—सुरक्षित डिफ़ॉल्ट्स, स्पष्ट रिकवरी पाथ, और विकसित होने की जगह के साथ।
अलग dev/staging/prod एनवायरनमेंट सेट करें जिनके अलग डेटाबेस और अलग ऑब्जेक्ट स्टोरेज बकेट्स (या प्रीफ़िक्स) हों। हर एनवायरनमेंट के लिए अलग encryption keys और credentials रखें, और सुनिश्चित करें कि बैकग्राउंड वर्कर सही क्यूज़ की ओर पॉइंट कर रहे हैं।
स्टेजिंग को प्रोडक्शन जैसा बनाएं: समान जॉब concurrency, टाइमआउट, और फ़ाइल साइज लिमिट। यहीं आप प्रदर्शन और परमीशन को बिना असली ग्राहक डेटा जोखिम के वैलिडेट कर सकते हैं।
इम्पोर्ट्स अक्सर "हमेशा के लिए" रहते हैं क्योंकि कस्टमर पुराने स्प्रेडशीट रखते हैं। DB माइग्रेशन्स की तरह, अपने इम्पोर्ट टेम्पलेट्स और मैपिंग प्रिसेट्स को भी वर्जन करें ताकि स्कीमा परिवर्तन पिछले CSV को तोड़े नहीं।
प्रैक्टिकल तरीका है कि हर इम्पोर्ट रन के साथ template_version स्टोर करें और पुरानी वर्जन्स के लिए कम्पैटिबिलिटी कोड रखें जब तक आप उन्हें डिप्रिकेट न कर सकें।
फीचर फ्लैग्स का उपयोग करके सुरक्षित रूप से बदलें:
फ़्लैग्स आपको आंतरिक यूज़र्स या छोटे कस्टमर कोहॉर्ट के साथ परीक्षण करने देते हैं पहले कि व्यापक रूप से चालू करें।
डॉक्यूमेंट करें कि सपोर्ट कैसे फेल्यर्स जांचेगा—इम्पोर्ट हिस्ट्री, जॉब IDs, और लॉग्स का उपयोग करके। एक साधारण चेकलिस्ट मदद करती है: टेम्पलेट वर्जन कन्फर्म करें, पहली फेलिंग रो देखें, स्टोरेज एक्सेस चेक करें, फिर वर्कर लॉग्स देखें। इसे अपने आंतरिक रनबुक में लिंक करें और जहाँ उपयुक्त हो, अपने एडमिन UI (उदा. /admin/imports) से जोड़ें।
एक बार कोर वर्कफ़्लो स्थिर हो जाए, इसे अपलोड से आगे बढ़ाएँ:
ये अपग्रेड्स मैनुअल काम घटाते हैं और आपके डेटा इम्पोर्ट वेब ऐप को कस्टमर के मौजूदा प्रोसेसेज़ में नेटीव महसूस कराते हैं।
यदि आप इसे एक प्रोडक्ट फ़ीचर की तरह बना रहे हैं और "पहले उपयोगयोग्य वर्जन" टाइमलाइन को छोटा करना चाहते हैं, तो Koder.ai का उपयोग करके इम्पोर्ट विज़ार्ड, जॉब स्टेटस पेजेस, और रन हिस्ट्री स्क्रीन एंड‑टू‑एंड प्रोटोटाइप करना और फिर स्रोत कोड एक्सपोर्ट करना एक व्यावहारिक रास्ता हो सकता है। यह दृष्टिकोण तब विशेष रूप से उपयोगी है जब लक्ष्य विश्वसनीयता और iteration‑speed हो (डے‑वन पर बेजोड़ UI पर नहीं)।
शुरुआत में स्पष्ट करें कि कौन इम्पोर्ट/एक्सपोर्ट कर रहा है (एडमिन्स, ऑपरेटर, कस्टमर) और आपके मुख्य उपयोग‑केस क्या हैं (ऑनबोर्डिंग में बुल्क लोड, periódic सिंक, एक‑बार के एक्सपोर्ट)।
दिन‑एक सीमाएँ लिखें:
ये निर्णय आर्किटेक्चर, UI जटिलता और सपोर्ट-बोझ को ड्राइव करेंगे।
सिंक्रोनस तब उपयोग करें जब फ़ाइलें छोटी हों और वैलिडेशन + लिखाई वेब रिक्वेस्ट टाइमआउट के भीतर पूरी हो जाएँ।
बैकग्राउंड जॉब्स तब चाहिए जब:
एक सामान्य पैटर्न: upload → enqueue → रन स्टेटस/प्रोग्रेस दिखाएँ → पूरा होने पर नोटिफाई करें।
दोनों को अलग रखें, अलग‑अलग कारणों के लिए:
Raw अपलोड को immutable रखें और इसे एक इम्पोर्ट रन रिकॉर्ड से जोड़ें।
एक preview स्टेप बनाइए जो अपलोड पर हैडर डिटेक्ट करे और एक छोटा सैंपल (उदा. 20–100 पंक्तियाँ) पार्स करे, इससे पहले कि आप कुछ भी commit करें।
सामान्य वैरिएबिलिटी संभालें:
सच्चे ब्लॉकर्स (unreadable file, missing required columns) पर फेल फास्ट करें, पर उन डेटा को रिजेक्ट न करें जिन्हें बाद में मैप या ट्रांसफॉर्म किया जा सकता है।
साधारण मैपिंग टेबल उपयोग करें: Source column → Destination field.
बेस्ट प्रैक्टिस:
हमेशा मैप्ड प्रीव्यू दिखाएँ ताकि यूज़र पूरे फ़ाइल को प्रोसेस करने से पहले गलतियाँ पकड़ सकें।
निम्नलिखित हल्के‑फुल्के ट्रांसफ़ॉर्म शुरुआती चरण में काफी उपयोगी होते हैं, और इन्हें स्पष्ट रखें ताकि यूज़र परिणामों की उम्मीद कर सकें:
ACTIVE)प्रीव्यू में “original → transformed” दिखाएँ और जब ट्रांसफ़ॉर्म लागू न हो सके तो वार्निंग दिखाएँ।
वैलिडेशन को परतों में बाँटें:
UI में एक्शन‑योग्य मैसेज दें जिनमें row/column रेफरेंस हों (उदा. “Row 42, Start Date: YYYY‑MM‑DD होना चाहिए”)।
निर्णय लें कि इम्पोर्ट (पूरी फ़ाइल फेल) हों या (वैध पंक्तियाँ स्वीकार हों), और एडमिन्स के लिए दोनों विकल्प देना विचारणीय है।
प्रोसेसिंग को retry‑safe बनाइए:
import_id + row_number या row hash)external_id) से upsert को प्राथमिकता दें बजाय “हमेशा insert” केफ़ाइल सबमिट होते ही एक import run रिकॉर्ड बनाएँ और संरचित, क्वेरीयोग्य त्रुटियाँ स्टोर करें—सिर्फ़ लॉग्स नहीं।
उपयोगी एरर‑रिपोर्टिंग फ़ीचर:
यह “बार‑बार retry करके काम होने” व्यवहार और सपोर्ट‑टिकट्स घटाने में मदद करता है।
इम्पोर्ट/एक्सपोर्ट को संवेदनशील एक्शन्स मानें:
यदि आप PII हैंडल करते हैं, तो रिटेंशन और डिलीट नियम पहले से तय कर लें ताकि संवेदनशील फ़ाइलें अनियंत्रित रूप से जमा न हों।
इसके अलावा, डेटाबेस और अन्य यूज़र्स की रक्षा के लिए वर्कस्पेस के प्रति समवर्ती इम्पोर्ट्स पर थ्रॉटल करें।