23 अप्रैल 2025·8 मिनट
कैसे वेक्टर डेटाबेस AI ऐप्स के लिए सार्थक सर्च को चलाते हैं
जानें कि वेक्टर डेटाबेस कैसे एम्बेडिंग्स स्टोर करते हैं, तेज़ समानता खोज चलाते हैं, और सार्थक खोज, RAG चैटबॉट, रिकमेंडेशन्स और अन्य AI ऐप्स का समर्थन करते हैं।
जानें कि वेक्टर डेटाबेस कैसे एम्बेडिंग्स स्टोर करते हैं, तेज़ समानता खोज चलाते हैं, और सार्थक खोज, RAG चैटबॉट, रिकमेंडेशन्स और अन्य AI ऐप्स का समर्थन करते हैं।
सार्थक खोज एक ऐसी खोज है जो आपके द्वारा टाइप किए गए शब्दों पर नहीं, बल्कि आप जो मतलब पूछना चाहते हैं उस पर ध्यान देती है।
अगर आपने कभी कुछ खोजा है और सोचा है, “जवाब तो यहाँ ही है—फिर भी क्यों नहीं मिल रहा?”, तो आपने कीवर्ड सर्च की सीमाएँ महसूस की हैं। पारंपरिक सर्च शब्दों का मिलान करती है। यह तब काम करती है जब आपकी क्वेरी और कंटेंट में शब्दों का ओवरलैप हो।
कीवर्ड सर्च निम्न मामलों में फेल होती है:
यह रिपीट हुए शब्दों को ओवरवैल्यू कर सकती है, ऐसे परिणाम लाकर जो सतह पर प्रासंगिक दिखते हैं पर असल में प्रश्न का सही उत्तर नहीं देते।
मान लीजिए एक हेल्प सेंटर में एक लेख है जिसका शीर्षक है “Pause or cancel your subscription.” कोई उपयोगकर्ता खोज करता है:
“stop my payments next month”
अगर उस लेख में “stop” या “payments” नहीं हैं तो कीवर्ड सिस्टम उसे ऊपर रैंक नहीं कर सकता। सार्थक खोज समझने के लिए बनी है कि “stop my payments” और “cancel subscription” का अर्थ मिलता-जुलता है, और इसलिए वह लेख टॉप पर लाएगा—क्योंकि उनका मतलब मेल खाता है।
ऐसा करने के लिए सिस्टम कंटेंट और क्वेरी को “अर्थ की फिंगरप्रिंट” (नंबर्स जो समानता को कैप्चर करते हैं) के रूप में प्रदर्शित करते हैं। फिर उन्हें इन फिंगरप्रिंट्स में से मिलते-जुलते मिलान तेज़ी से खोजना पड़ता है—कभी-कभी लाखों।
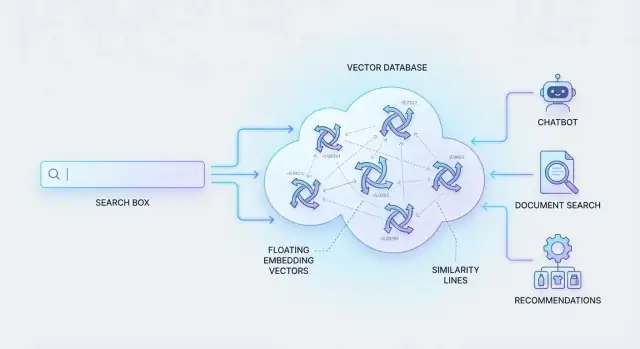
यही वह काम है जिसके लिए वेक्टर डेटाबेस बनाए जाते हैं: ये इन संख्यात्मक प्रतिनिधियों को स्टोर करते हैं और सबसे समान मैच प्रभावी तरीके से रिट्रीव करते हैं, ताकि सार्थक खोज बड़े पैमाने पर भी तात्कालिक लगे।
एक एम्बेडिंग अर्थ का न्यूमेरिक प्रतिनिधि है। डाक्यूमेंट को keywords से बताने के बजाय, आप उसे संख्याओं की लिस्ट (एक “वेक्टर”) के रूप में व्यक्त करते हैं जो कंटेंट किस बारे में है यह दिखाती है। दो कंटेंट जो समान अर्थ रखें वेक्टर स्पेस में एक-दूसरे के पास आ जाते हैं।
एम्बेडिंग को आप एक बहुत उच्च-आयामी मानचित्र पर एक निर्देशांक के रूप में सोच सकते हैं। आप आमतौर पर संख्याएँ सीधे नहीं पढ़ते—ये मानव-पठनीय नहीं होतीं। इनकी उपयोगिता इस बात में है कि वे कैसे बर्ताव करती हैं: अगर “cancel my subscription” और “how do I stop my plan?” के वेक्टर पास-पास बनते हैं, तो सिस्टम उन्हें संबंधित मान सकता है भले ही शब्दों में ओवरलैप कम हो।
एम्बेडिंग्स सिर्फ टेक्स्ट तक सीमित नहीं हैं।
इसी तरह एक ही वेक्टर डेटाबेस “इमेज से खोज”, “समान गाने खोजो” या “ऐसा प्रोडक्ट सुझाओ” जैसे अनुभवों का समर्थन कर सकता है।
वेक्टर मैन्युअली टैग करके नहीं बनते। इन्हें मशीन लर्निंग मॉडल जनरेट करते हैं जो अर्थ को संख्याओं में संपीड़ित करना सीखते हैं। आप कंटेंट को एम्बेडिंग मॉडल (खुद होस्ट किया हुआ या प्रोवाइडर) को भेजते हैं, और वह एक वेक्टर लौटाता है। आपका ऐप उस वेक्टर को मूल कंटेंट और मेटाडेटा के साथ स्टोर करता है।
जो एम्बेडिंग मॉडल आप चुनते हैं वह परिणामों पर गहरा प्रभाव डालता है। बड़े या विशेषीकृत मॉडल अक्सर प्रासंगिकता सुधारते हैं पर महंगे और धीमे हो सकते हैं। छोटे मॉडल सस्ते और तेज़ हो सकते हैं, लेकिन डोमेन-विशिष्ट भाषा, बहु-भाषा या छोटे क्वेरीज़ में नज़ाकत मिस कर सकते हैं। कई टीमें शुरुआत में कुछ मॉडल टेस्ट कर के सही ट्रेड-ऑफ चुनती हैं।
एक वेक्टर डेटाबेस का मूल विचार साधारण है: “अर्थ” (एक वेक्टर) को उस जानकारी के साथ स्टोर करें जो परिणाम को पहचानने, फ़िल्टर करने और दिखाने के लिए जरूरी हो।
अधिकांश रिकॉर्ड इस तरह दिखते हैं:
doc_18492 या एक UUID)उदाहरण के लिए, एक हेल्प-सेंटर आर्टिकल स्टोर कर सकता है:
kb_123{ \"title\": \"Reset your password\", \"url\": \"/help/reset-password\", \"tags\": [\"account\", \"security\"] }वेक्टर वह है जो सार्थक समानता चलाता है। ID और मेटाडेटा वे चीजें हैं जो परिणामों को उपयोगी बनाती हैं।
मेटाडेटा दो काम करता है:
बिना अच्छे मेटाडेटा के, आप सही अर्थ निकाल सकते हैं पर गलत संदर्भ दिखा सकते हैं।
एम्बेडिंग साइज मॉडल पर निर्भर करती है: 384, 768, 1024, और 1536 डाइमेंशन्स आम हैं। ज़्यादा डाइमेंशन्स नाज़ुकता कैप्चर कर सकती हैं, पर साथ में बढ़ती हैं:
एक मोटी कल्पना: डाइमेंशन्स दोगुना होने से लागत और लेटेंसी भी अक्सर बढ़ जाती है जब तक आप इंडेक्सिंग विकल्प या कम्प्रेशन से पूरा न करें।
रियल डेटासेट बदलते रहते हैं, तो वेक्टर डेटाबेस आमतौर पर सपोर्ट करते हैं:
शुरू में ही अपडेट्स की योजना बनाना “स्टेल नॉलेज” की समस्या से बचाता है जहाँ सर्च ऐसा कंटेंट लौटाता है जो अब सही नहीं है।
एक बार जब आपका टेक्स्ट, इमेज या प्रोडक्ट एम्बेडिंग्स में बदल जाता है, तब खोज ज्योमेट्री की समस्या बन जाती है: “इस क्वेरी वेक्टर के सबसे नज़दीकी वेक्टर्स कौन से हैं?” इसे nearest-neighbor search कहते हैं। कीवर्ड मिलान की जगह, सिस्टम अर्थ की तुलना करके नज़दीकी चीज़ें निकालता है।
हर कंटेंट को एक विशाल बहु-आयामी स्पेस में एक बिंदु के रूप में सोचिए। जब यूज़र खोज करता है, उसका प्रश्न एक और बिंदु बन जाता है। समानता खोज उन आइटम्स को लौटाती है जिनके बिंदु सबसे नज़दीक हैं—आपके “nearest neighbors।” वे neighbors संभावित रूप से इरादा, विषय या संदर्भ साझा करते हैं, भले ही शब्द एक जैसे न हों।
वेक्टर डेटाबेस आमतौर पर कुछ मानक तरीक़े सपोर्ट करते हैं:
विभिन्न एम्बेडिंग मॉडल किसी विशेष मीट्रिक के अनुरूप प्रशिक्षित होते हैं, इसलिए मॉडल प्रोवाइडर द्वारा सुझाए गए मीट्रिक का उपयोग करना महत्वपूर्ण है।
Exact खोज हर वेक्टर की जाँच करके सच्चे nearest neighbors देती है। यह सटीक है, पर स्केल पर धीमा और महँगा हो सकता है।
अधिकांश सिस्टम approximate nearest neighbor (ANN) खोज का उपयोग करते हैं। ANN स्मार्ट इंडेक्सिंग स्ट्रक्चर इस्तेमाल करके खोज के दायरे को सीमित कर देता है। आम तौर पर परिणाम “काफी क़रीब” होते हैं—बहुत तेज़।
ANN लोकप्रिय है क्योंकि यह आपकी ज़रूरत के अनुसार ट्यून करने देता है:
यही ट्यूनिंग वजह है कि वेक्टर सर्च वास्तविक ऐप्स में अच्छा काम करता है: आप रिस्पॉन्स को तेज रख सकते हैं और फिर भी प्रासंगिक परिणाम लौटाते हैं।
सार्थक खोज एक साधारण पाइपलाइन के रूप में समझना आसान है: आप टेक्स्ट को अर्थ में बदलते हैं, समान अर्थ खोजते हैं, फिर सबसे उपयोगी मैच प्रस्तुत करते हैं।
यूज़र कोई सवाल टाइप करता है (उदा.: “How do I cancel my plan without losing data?”)। सिस्टम उस टेक्स्ट को एम्बेडिंग मॉडल में चलाता है और एक वेक्टर बनता है—वो क्वेरी के शब्दों की बजाय उसके अर्थ का प्रतिनिधि होता है।
यह क्वेरी वेक्टर वेक्टर डेटाबेस को भेजा जाता है, जो आपकी स्टोर की गई सामग्री में से “सबसे नज़दीकी” वेक्टर्स खोजता है।
अधिकांश सिस्टम top-K मैच लौटाते हैं: K सबसे समान चंक्स/दस्तावेज़।
समानता खोज स्पीड के लिए ऑप्टिमाइज़्ड होती है, इसलिए प्रारंभिक top-K में कुछ near-miss हो सकते हैं। एक reranker दूसरा मॉडल होता है जो क्वेरी और हर कैंडिडेट रिज़ल्ट को एक साथ देख कर उन्हें फिर से क्रमबद्ध करता है।
इसे ऐसे सोचिए: वेक्टर सर्च एक मजबूत शॉर्टलिस्ट देता है; रीरेंकर सबसे अच्छा क्रम चुनता है।
अंत में, आप सर्वश्रेष्ठ मैच यूज़र को लौटाते हैं (सर्च रिज़ल्ट के रूप में), या उन्हें एक AI असिस्टेंट को भेजते हैं (उदा., एक RAG सिस्टम) जैसा कि “ग्राउंडिंग” संदर्भ।
अगर आप इस तरह का वर्कफ़्लो किसी ऐप में बना रहे हैं, तो प्लेटफ़ॉर्म जैसे Koder आपकी प्रोटोटाइपिंग में मदद कर सकते हैं: आप semantic search या RAG अनुभव को चैट इंटरफ़ेस में वर्णन करते हैं, फिर React फ्रंट-एंड और Go/PostgreSQL बैक-एंड पर इटरटे करते हुए retrieval पाइपलाइन (embedding → vector search → वैकल्पिक rerank → answer) को उत्पाद के एक प्राथमिक हिस्से के रूप में बनाए रखते हैं।
अगर आपकी हेल्प-सेंटर आर्टिकल में लिखा है “terminate subscription” और उपयोगकर्ता खोजता है “cancel my plan,” तो keyword search उसे मिस कर सकती है क्योंकि “cancel” और “terminate” मेल नहीं खाते।
Semantic search आमतौर पर इसे निकाल लेगी क्योंकि एम्बेडिंग दोनों वाक्यों के इरादे को पकड़ लेती है। रीरैंक जोड़ें, और टॉप परिणाम अक्सर सिर्फ़ “समान” नहीं बल्कि सीधे उपयोगकर्ता के प्रश्न के लिए कार्रवाई योग्य बन जाते हैं।
प्योर वेक्टर सर्च “अर्थ” में बहुत अच्छा है, पर यूज़र हमेशा अर्थ से खोज नहीं करते। कभी-कभी उन्हें सटीक मिलान चाहिए: किसी व्यक्ति का पूरा नाम, SKU, invoice ID, या लॉग से कॉपी किया गया error code। हाइब्रिड सर्च इन्हें semantic सिग्नल्स (वेक्टर) और lexical सिग्नल्स (परंपरागत कीवर्ड/BM25) के साथ जोड़कर हल करता है।
एक हाइब्रिड क्वेरी सामान्यतः दो retrieval पाथ्स को समानांतर चलाती है:
फिर सिस्टम उन कैंडिडेट रिज़ल्ट्स को मिलाकर एक रैंक्ड सूची बनाता है।
हाइब्रिड सर्च तब चमकती है जब आपके डेटा में “must-match” स्ट्रिंग्स हों:
सिर्फ़ सार्थक सर्च व्यापक संबंधित पेज लौटाएगा; सिर्फ़ कीवर्ड सर्च उन उत्तरों को छोड़ सकता है जो अलग शब्दों में हैं। हाइब्रिड दोनों विफलता मोड्स को कवर करता है।
मेटाडेटा फ़िल्टर्स रिट्रीवल को रैंकिंग से पहले (या साथ में) सीमित करते हैं, जिससे प्रासंगिकता और गति सुधरती है। सामान्य फ़िल्टर्स:
अधिकांश सिस्टम व्यवहारिक मिश्रण अपनाते हैं: दोनों सर्च चलाते हैं, स्कोर सामान्यीकृत कर के तुलनीय बनाते हैं, फिर वज़न लागू करते हैं (उदा., “IDs के लिए keywords पर ज़्यादा झुकाव”)। कुछ उत्पाद merged shortlist को रीरैंक करने के लिए हल्के मॉडल या नियम भी जोड़ते हैं, जबकि फ़िल्टर सुनिश्चित करते हैं कि आप सही उपसमुच्चय को रैंक कर रहे हैं।
Retrieval-Augmented Generation (RAG) एक व्यावहारिक पैटर्न है जिससे LLM से अधिक भरोसेमंद उत्तर मिलते हैं: पहले प्रासंगिक जानकारी खोजो, फिर उस खोजी हुई संदर्भ के आधार पर उत्तर जनरेट करो।
मॉडल से आपकी कंपनी के डॉक्स “याद” रखने की उम्मीद करने की बजाय, आप उन डॉक्स को (एम्बेडिंग्स के रूप में) वेक्टर डेटाबेस में स्टोर करते हैं, प्रश्न के समय सबसे प्रासंगिक चंक्स रिट्रीव करते हैं, और उन्हें LLM को सपोर्टिंग कंटेक्स्ट के रूप में पास करते हैं।
LLM लिखने में माहिर हैं, पर जब जरूरी तथ्य न हों तो वे आत्मविश्वास के साथ भरमार कर देते हैं। वेक्टर डेटाबेस आपके नॉलेज बेस से सबसे “क्लोज़-मीनिंग” पैसजेज लाकर प्रॉम्प्ट में देने को आसान बनाता है।
यह ग्राउंडिंग मॉडल को “उत्तर गढ़ो” की बजाय “इन स्रोतों का सारांश और व्याख्या करो” की तरफ़ ले जाता है। यह उत्तरों को ऑडिट करने में भी आसान बनाता है क्योंकि आप यह ट्रैक रख सकते हैं कि कौन से चंक्स निकाले गए थे और चाहें तो उद्धरण दिखा सकते हैं।
RAG की गुणवत्ता अक्सर मॉडल से अधिक chunking पर निर्भर करती है。
इस फ़्लो की कल्पना करें:
यूज़र प्रश्न → क्वेरी एम्बेड → वेक्टर DB से top-k चंक्स निकाले (+ वैकल्पिक मेटाडेटा फ़िल्टर) → निकाले गए चंक्स के साथ प्रॉम्प्ट बनाएँ → LLM उत्तर जनरेट करे → उत्तर लौटाएँ (और स्रोत दिखाएँ)।
वेक्टर डेटाबेस बीच में “तेज़ मेमोरी” की तरह बैठता है जो हर अनुरोध के लिए सबसे प्रासंगिक साक्ष्य उपलब्ध कराता है।
वेक्टर डेटाबेस केवल सर्च को “ज़्यादा बुद्धिमान” नहीं बनाते—वे उन उत्पाद अनुभवों को सक्षम करते हैं जहाँ उपयोगकर्ता प्राकृतिक भाषा में जो चाहते हैं वह बताकर भी प्रासंगिक परिणाम पाते हैं। नीचे कुछ व्यावहारिक उपयोग केस हैं जिन्हें बार-बार देखा जाता है।
सपोर्ट टीम के पास अक्सर नॉलेज बेस, पुराने टिकट, चैट ट्रांस्क्रिप्ट और रिलीज नोट्स होते हैं—पर कीवर्ड सर्च समानार्थी शब्दों, पैराफ्रेज़ और अस्पष्ट समस्या वर्णनों से जूझती है।
सार्थक सर्च के साथ, एक एजेंट (या चैटबॉट) पुराने टिकट निकाल सकता है जो वही मतलब रखते हों भले ही शब्द अलग हों। इससे रिज़ॉल्यूशन तेज़ होता है, डुप्लिकेट काम कम होता है, और नए एजेंट तेजी से सीखते हैं। प्रोडक्ट लाइ़न, भाषा, इश्यू टाइप, और तारीख रेंज जैसे मेटाडेटा फ़िल्टर्स से परिणाम फोकस्ड रहते हैं।
खरीदार अक्सर सटीक प्रोडक्ट नाम नहीं जानते। वे ऐसे इरादे खोजते हैं जैसे “छोटा बैग जिसमें लैपटॉप फिट हो और प्रोफेशनल दिखे।” एम्बेडिंग्स उन प्राथमिकताओं—स्टाइल, फ़ंक्शन, सीमाएँ—को पकड़ते हैं, इसलिए परिणाम एक मानव सेल्स असिस्टेंट जैसे महसूस होते हैं।
यह रिटेल कैटलॉग, ट्रैवल लिस्टिंग, रियल एस्टेट, जॉब बोर्ड और मार्केटप्लेस के लिए काम करता है। आप सिमेंटिक प्रासंगिकता को मूल्य, साइज, उपलब्धता, या लोकेशन जैसे स्ट्रक्चर्ड कंस्ट्रेंट्स के साथ भी मिला सकते हैं।
“इसी जैसा” निकालना वेक्टर डेटाबेस की क्लासिक सुविधा है। जब यूज़र कोई आइटम देखता है, आर्टिकल पढ़ता है या वीडियो देखता है, आप और ऐसी कंटेंट रिट्रीव कर सकते हैं जिनका अर्थ या गुण मिलते-जुलते हों—यहां तक कि जब कैटेगरी मैच न भी करें।
यह उपयोगी है:
कंपनियों के अंदर जानकारी दस्तावेज़ों, विकी, PDF और मीटिंग नोट्स में बिखरी होती है। सार्थक सर्च कर्मचारियों को नेचुरल भाषा में सवाल पूछकर सही स्रोत ढूंढ़ने में मदद करती है (“हमारी सम्मेलन के लिए reimbursement पॉलिसी क्या है?”)।
यहाँ गैर-समझौता योग्य हिस्सा एक्सेस कंट्रोल है। परिणामों को अनुमतियों के अनुसार फ़िल्टर करना चाहिए—अक्सर टीम, डॉक्यूमेंट ओनर, गोपनीयता स्तर या ACL लिस्ट के आधार पर—ताकि उपयोगकर्ता केवल वही प्राप्त करें जो उन्हें देखने की अनुमति है।
यदि आप इसे आगे ले जाना चाहते हैं, तो यही रिट्रीवल लेयर grounded Q&A सिस्टम्स (RAG सेक्शन में कवर) को भी शक्ति देती है।
एक सार्थक सर्च सिस्टम उतना ही अच्छा होता है जितना उसे खिलाने वाली पाइपलाइन। अगर दस्तावेज़ असंगठित आते हैं, गलत तरीके से chunk किए जाते हैं, या संपादन के बाद कभी re-embed नहीं होते, तो परिणाम उपयोगकर्ताओं की अपेक्षा से दूर हो जाते हैं।
अधिकांश टीमें निम्न अनुक्रम का पालन करती हैं:
“Chunk” चरण वह जगह है जहाँ कई पाइपलाइंस जीत या हार जाती हैं। प्राकृतिक संरचना (हैडिंग्स, पैरा, Q&A पेयर्स) के अनुसार chunking करना और निरंतरता के लिए थोड़ा ओवरलैप रखना एक व्यावहारिक उपाय है।
कंटेंट लगातार बदलता रहता है—पॉलिसीज़ अपडेट होती हैं, प्राइस बदलते हैं, आर्टिकल्स संशोधित होते हैं। एम्बेडिंग्स को derived डेटा मानकर उन्हें दोबारा बनाना चाहिए।
साधारण तरीके:
यदि आप कई भाषाओं को सर्व करते हैं, तो या तो एक मल्टीलिंगुअल एम्बेडिंग मॉडल (सरल) या प्रति-भाषा मॉडल (कभी-कभी उच्च गुणवत्ता) इस्तेमाल कर सकते हैं। मॉडल के साथ प्रयोग करते समय अपनी एम्बेडिंग्स का वर्जन रखें (उदा., embedding_model=v3) ताकि आप A/B टेस्ट कर सकें और बिना सर्च तोड़े रोलबैक कर सकें।
सार्थक सर्च डेमो में "अच्छा" लग सकता है और प्रोडक्शन में फेल भी हो सकता है। फर्क मापने में है: आपको स्पष्ट प्रासंगिकता मीट्रिक्स और स्पीड टार्गेट चाहिए, जो असली उपयोगकर्ता व्यवहार जैसे क्वेरीज पर मापे गए हों।
एक छोटा सेट मीट्रिक्स चुनें और समय के साथ उनके साथ बने रहें:
मूल्यांकन सेट बनाते समय:
टेस्ट सेट का वर्शन रखें ताकि आप रिलीज़ के across तुलना कर सकें।
ऑफलाइन मीट्रिक्स सब कुछ कैप्चर नहीं करते। A/B टेस्ट चलाएँ और हल्के संकेत इकट्ठा करें:
इस फीडबैक का उपयोग प्रासंगिकता निर्णय अपडेट करने और फेलर पैटर्न पहचानने में करें।
प्रदर्शन बदल सकता है जब:
किसी भी बदलाव के बाद अपना टेस्ट सूट फिर चलाएँ, मीट्रिक ट्रेंड्स को साप्ताहिक रूप से मॉनिटर करें, और MRR/nDCG में अचानक गिरावट या p95 लेटेंसी में spike के लिए अलर्ट सेट करें।
वेक्टर सर्च यह बदलता है कि डेटा कैसे रिट्रीव होता है, पर यह तय नहीं करता कि कौन उसे देख सकता है। अगर आपका सार्थक सर्च या RAG सिस्टम सही चंक ढूँढ सकता है, तो वह गलती से उपयोगकर्ता के लिए न होने वाला चंक भी लौटा सकता है—जब तक आप रिट्रीवल स्टेप में अनुमतियाँ और प्राइवेसी न जोड़ें।
सबसे सुरक्षित नियम सरल है: यूज़र केवल वही सामग्री रिट्रीव करे जिसे वह पढ़ने की अनुमति रखता है। ऐप पर भरोसा करके परिणाम छिपाना मत—क्योंकि उस समय तक कंटेंट पहले ही आपके स्टोरेज बॉउंड्री से बाहर जा चुका होगा।
प्रायोगिक तरीके:
कई वेक्टर डेटाबेस मेटाडेटा-आधारित फ़िल्टर्स सपोर्ट करते हैं (जैसे tenant_id, department, project_id, visibility) जो समानता खोज के साथ चलते हैं। सही उपयोग करने पर यह रिट्रीवल के समय अनुमतियाँ लागू करने का साफ़ तरीका है।
एक मुख्य बात: सुनिश्चित करें कि फ़िल्टर अनिवार्य और सर्वर-साइड हो, क्लाइंट-लॉजिक पर निर्भर न करें। अगर आपकी permission मॉडल जटिल है, तो "effective access groups" प्रीकम्प्यूट करें या एक ऑथराइज़ेशन सर्विस का इस्तेमाल करें जो क्वेरी-टाइम फ़िल्टर टोकन जारी करे।
एम्बेडिंग्स मूल टेक्स्ट से अर्थ एनकोड कर सकती हैं। इसका मतलब यह नहीं कि वे सीधे रॉ PII बाहर निकालती हैं, पर जोखिम बढ़ सकता है (उदा., संवेदनशील तथ्यों को ढूँढना आसान हो सकता है)।
काम करने की गाइडलाइन:
अपने वेक्टर इंडेक्स को प्रोडक्शन डेटा की तरह ट्रीट करें:
अच्छी तरह किया जाए तो ये प्रैक्टिसेस सार्थक सर्च को उपयोगकर्ताओं के लिए जादुई बनाती हैं—बगैर बाद में सुरक्षा आश्चर्य के।
वेक्टर डेटाबेस "प्लग-एंड-प्ले" लग सकते हैं, पर अधिकांश नाखुशियाँ आस-पास के फैसलों से आती हैं: आप डेटा कैसे chunk करते हैं, कौन सा एम्बेडिंग मॉडल चुनते हैं, और कितनी विश्वसनीयता से आप सब कुछ अपडेट रखते हैं।
खराब chunking सबसे बड़ा कारण है। बहुत बड़े चंक्स अर्थ dilute कर देते हैं; बहुत छोटे चंक्स संदर्भ खो देते हैं। अगर उपयोगकर्ता अक्सर कहते हैं “यह सही दस्तावेज़ मिला पर गलत पैसज आया”, तो आपका chunking स्ट्रैटेजी काम नहीं कर रही।
गल एम्बेडिंग मॉडल लगातार सिमेंटिक मिसमैच के रूप में दिखता है—नतीजे प्रवाही हैं पर टॉपिक से हटे हुए। यह तब होता है जब मॉडल आपके डोमेन (कानूनी, मेडिकल, सपोर्ट टिकट्स) या कंटेंट टाइप (टेबल्स, कोड, बहुभाषी टेक्स्ट) के लिए उपयुक्त नहीं होता।
पुराना डेटा भरोसा जल्दी खो देता है: उपयोगकर्ता नवीनतम पॉलिसी ढूंढते हैं पर पिछली तिमाही का वर्शन मिलता है। अगर आपका सोर्स बदलता है, तो एम्बेडिंग्स और मेटाडेटा भी अपडेट होने चाहिए (और डिलीशन्स को वास्तव में हटाना चाहिए)।
शुरुआत में आपके पास बहुत कम कंटेंट, कम क्वेरीज या ट्यूनिंग के लिए पर्याप्त फीडबैक नहीं हो सकता। इसकी योजना बनाएं:
खर्च आम तौर पर चार जगह से आता है:
वेंडर्स की तुलना करते समय अपने अपेक्षित डॉक्यूमेंट काउंट, औसत चंक साइज और पीक QPS के साथ एक साधारण मासिक अनुमान पूछें। कई आश्चर्य इंडेक्सिंग और ट्रैफिक स्पाइक्स के दौरान आते हैं।
किसी वेक्टर डेटाबेस को चुनते समय निम्न छोटी सूची का उपयोग करें:
अच्छा चुनाव नया इंडेक्स टाइप खोजने के बजाय भरोसेमंदता के बारे में होना चाहिए: क्या आप डेटा ताज़ा रख सकते हैं, एक्सेस कंट्रोल कर सकते हैं, और गुणवत्ता बनाए रख सकते हैं क्योंकि आपका कंटेंट और ट्रैफ़िक बढ़ता है?
Keyword search सिर्फ ठीक शब्दों को मिलाता है। Semantic search अर्थ से मिलान करता है—हेमबेडिंग (वेक्टर) की मदद से—इसलिए यह तब भी प्रासंगिक परिणाम दे सकता है जब क्वेरी अलग तरीके से लिखी हो (उदा., “stop payments” → “cancel subscription”)।
एक वेक्टर डेटाबेस एम्बेडिंग्स (नम्बरों का एरे) के साथ IDs और मेटाडेटा स्टोर करता है, फिर तेज़ nearest-neighbor लुकअप करके उस क्वेरी से सबसे नज़दीकी अर्थ वाले आइटम ढूंढता है। यह बड़े पैमाने पर समानता खोज (अक्सर मिलियन्स वेक्टर्स) के लिए अनुकूलित होता है।
एम्बेडिंग एक मॉडल-जनरेटेड न्यूमेरिक “फिंगरप्रिंट” है जो कंटेंट का अर्थ कैप्चर करता है। आप संख्याओं को सीधे नहीं पढ़ते; आप उन्हें समानता मापने के लिए इस्तेमाल करते हैं。
व्यवहार में:
अधिकांश रिकॉर्ड में शामिल होते हैं:
मेटाडेटा दो महत्वपूर्ण क्षमताएँ देता है:
बिना मेटाडेटा के, आप सही अर्थ निकाल सकते हैं पर संदर्भ गलत दिखा सकते हैं या restricted कंटेंट लीक कर सकते हैं।
सामान्य विकल्प:
आपको वही मीट्रिक इस्तेमाल करनी चाहिए जिसके लिए आपका एम्बेडिंग मॉडल प्रशिक्षित है; गलत मीट्रिक रैंकिंग को प्रभावित कर सकता है।
Exact search हर वेक्टर की तुलना करता है—यह स्केल होने पर धीमा और महंगा हो सकता है। ANN (approximate nearest neighbor) इंडेक्स का उपयोग करके कम उम्मीदवारों में खोज कर के तेज़ परिणाम देता है।
आप ट्यून कर सकते हैं:
Hybrid search जोड़ती है:
जब आपका कॉर्पस “must-match” स्ट्रिंग्स रखता हो, तब hybrid अक्सर बेहतर डिफ़ॉल्ट होता है।
RAG (Retrieval-Augmented Generation) relevant chunks को आपके डेटा से निकालकर LLM को संदर्भ के रूप में देता है ताकि मॉडल के जवाब grounded और कम hallucinate हों।
साधारण फ्लो:
तीन उच्च-प्रभाव वाले pitfalls:
रोकथाम: संरचना के अनुसार chunking, एम्बेडिंग का versioning, और सर्वर-साइड अनिवार्य मेटाडेटा फिल्टर (जैसे , ACL फ़ील्ड) लागू करें।
title, url, tags, language, created_at, tenant_id)वेक्टर सार्थक समानता को चलाता है; मेटाडेटा परिणामों को उपयोगी बनाता है (फिल्टरिंग, एक्सेस कंट्रोल, डिस्प्ले)।
tenant_id