01 सित॰ 2025·8 मिनट
एक AI-सहायित वर्कफ़्लो में विचार से लाइव ऐप तक
एक व्यावहारिक एंड-टू-एंड वर्णन जो दिखाता है कि एक AI-सहायित वर्कफ़्लो का उपयोग करते हुए ऐप आइडिया से तैनात प्रोडक्ट तक कैसे पहुंचें — चरण, प्रॉम्प्ट और जाँच।
एक व्यावहारिक एंड-टू-एंड वर्णन जो दिखाता है कि एक AI-सहायित वर्कफ़्लो का उपयोग करते हुए ऐप आइडिया से तैनात प्रोडक्ट तक कैसे पहुंचें — चरण, प्रॉम्प्ट और जाँच।
कल्पना कीजिए एक छोटे, उपयोगी ऐप की: “Queue Buddy” — कैफ़े कर्मचारी एक बटन दबाकर ग्राहक को वेटिंग लिस्ट में जोड़ता है और जब टेबल तैयार हो तो उसे ऑटोमैटिक टेक्स्ट भेजा जाता है। सफलता का मेट्रिक सरल और मापनीय है: दो हफ्तों में औसत वेट-टाइम संबंधित भ्रमित कॉल्स में 50% कटौती, और स्टाफ़ का ऑनबोर्डिंग 10 मिनट से कम।
यही इस लेख की भावना है: एक स्पष्ट, सीमित विचार चुनें, तय करें "अच्छा" क्या है, और फिर एक ही कहानी और सीमाओं के साथ विचार से लाइव डिप्लॉयमेंट तक जाएँ—बार-बार टूल्स, डॉक्स और मानसिक मॉडल न बदलते हुए।
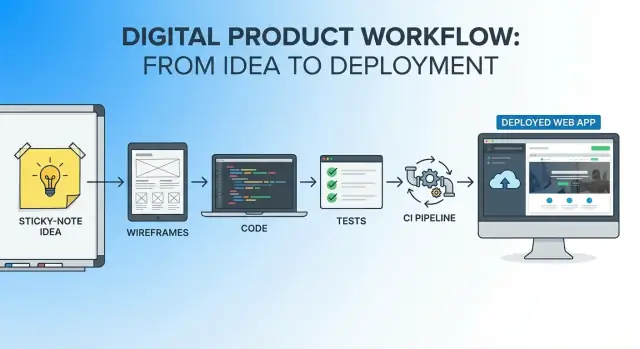
एक सिंगल वर्कफ़्लो है विचार के पहले वाक्य से लेकर पहली प्रोडक्शन रिलीज तक एक लगातार धागा:
आप अभी भी कई टूल्स का उपयोग करेंगे (एडिटर, रेपो, CI, होस्टिंग), पर आप प्रत्येक चरण पर प्रोजेक्ट को "रीस्टार्ट" नहीं करेंगे। वही नैरेटिव और सीमाएँ आगे बढ़ती हैं।
AI सबसे ज़्यादा तब उपयोगी है जब वह:
पर यह प्रोडक्ट फैसलों की जिम्मेदारी नहीं लेता—आप लेते हैं। वर्कफ़्लो इस तरह डिज़ाइन किया गया है कि आप हमेशा सत्यापित कर रहे हों: क्या यह बदलाव मेट्रिक को आगे बढ़ाता है? क्या इसे शिप करना सुरक्षित है?
आगामी सेक्शनों में आप कदम-दर-कदम चलेंगे:
अंत तक आपके पास एक दोहराने योग्य तरीका होना चाहिए जिससे आप विचार से लाइव ऐप तक जा सकें और स्कोप, क्वालिटी, और सीखने को घनिष्ठ रूप से जुड़े रखें।
AI से स्क्रीन, API, या DB टेबल ड्राफ्ट करवाने से पहले एक नुकीला लक्ष्य चाहिए। यहाँ थोड़ी स्पष्टता घंटों के “लगभग सही” आउटपुट को बचा लेती है।
आप ऐप इसलिए बना रहे हैं क्योंकि एक विशिष्ट समूह बार-बार एक ही बाधा का सामना कर रहा है: उनके पास मौजूद टूल्स से वे महत्वपूर्ण कार्य जल्दी, भरोसेमंद या आत्मविश्वास के साथ पूरा नहीं कर पा रहे। v1 का लक्ष्य उस वर्कफ़्लो का एक दर्दनाक कदम हटाना है—सारी चीज़ें ऑटोमेट करने की कोशिश नहीं—ताकि उपयोगकर्ता मिनटों में "मुझे X करना है" से "X हो गया" तक पहुँचें, एक स्पष्ट रिकॉर्ड के साथ।
एक मुख्य उपयोगकर्ता चुनें। सेकेंडरी उपयोगकर्ता बाद में हो सकते हैं।
धारणाएँ वही जगह हैं जहाँ अच्छे विचार चुपचाप फेल होते हैं—इन्हें दिखाएँ:
Version 1 एक छोटी जीत होनी चाहिए जिसे आप शिप कर सकें:
एक हल्का requirements doc (सोचें: एक पेज) "कूल आइडिया" और "बिल्डेबल प्लान" के बीच सेतु है। यह आपको फोकस्ड रखता है, AI असिस्टेंट को सही संदर्भ देता है, और पहले वर्जन को महीनों के प्रोजेक्ट में बदलने से रोकता है।
छोटा और स्किमेबल रखें। एक सरल टेम्पलेट:
5–10 फीचर तक रखें, आउटकम के रूप में लिखें। फिर रैंक करें:
यह रैंकिंग AI-जनरेटेड योजनाओं और कोड को निर्देशित करने का तरीका भी है: "पहले सिर्फ Must-haves इम्प्लीमेंट करें।"
टॉप 3–5 फीचरों के लिए 2–4 acceptance criteria जोड़ें। सादे भाषा और टेस्टेबल बयान रखें।
उदाहरण:
अंत में छोटे "Open Questions" की सूची रखें—ऐसी चीज़ें जिन्हें आप एक चैट, एक कस्टमर कॉल, या एक त्वरित सर्च से हल कर सकते हैं।
उदाहरण: "क्या उपयोगकर्ताओं को Google login चाहिए?" "हमें न्यूनतम कौन सा डेटा स्टोर करना चाहिए?" "क्या admin approval चाहिए?"
यह डॉक पेपरवर्क नहीं है; यह साझा सत्य का स्रोत है जिसे आप बिल्ड के दौरान अपडेट करते रहेंगे।
AI से स्क्रीन जनरेट करवाने से पहले प्रोडक्ट की कहानी सही रखें। एक त्वरित जर्नी स्केच सबको संरेखित रखता है: उपयोगकर्ता क्या करने की कोशिश कर रहा है, सफलता कैसी दिखती है, और कहाँ चीज़ें गलत हो सकती हैं।
हैप्पी पाथ से शुरू करें: सबसे सरल क्रम जो मुख्य वैल्यू देता है।
उदाहरण फ्लो (सामान्य):
फिर कुछ एज केस्स जोड़ें जो संभाव्य हैं और संभाले जाने पर महंगे हो सकते हैं:
बड़े डायग्राम की ज़रूरत नहीं। नम्बर की हुई सूची और नोट्स प्रोटोटाइपिंग और कोड जनरेशन को गाइड करने के लिए पर्याप्त हैं।
प्रत्येक स्क्रीन के लिए छोटा "job to be done" लिखें। आउटकम-फोकस्ड रखें, UI-फोकस्ड नहीं।
अगर आप AI के साथ काम कर रहे हैं, तो यह लिस्ट बढ़िया प्रॉम्प्ट मैटेरियल बन जाती है: "Generate a Dashboard that supports X, Y, Z and includes empty/loading/error states."
इसे 'नैपकिन स्कीमा' स्तर पर रखें—पर्याप्त ताकि स्क्रीन और फ्लोज़ सपोर्ट हों।
रिलेशनशिप्स नोट करें (User → Projects → Tasks) और किसी भी ऐसी चीज़ को जो परमिशन को प्रभावित करे।
उन बिंदुओं को मार्क करें जहाँ गलती विश्वास तोड़ देगी:
यह ओवर-इंजीनियरिंग के बारे में नहीं—बल्कि उन आश्चर्यों को रोकने के बारे में है जो एक "वर्किंग डेमो" को लॉन्च के बाद सपोर्ट सिरदर्द बना देते हैं।
Version 1 की वास्तुकला एक चीज़ अच्छी तरह करनी चाहिए: सबसे छोटा उपयोगी प्रोडक्ट शिप करने देना बिना खुद को पिंजरे में डालने के। एक अच्छा नियम है "एक रेपो, एक डिप्लॉयेबल बैकएंड, एक डिप्लॉयेबल फ्रंटएंड, एक डेटाबेस"—और अतिरिक्त पीस तभी जोड़ें जब कोई स्पष्ट आवश्यकता हो।
यदि आप सामान्य वेब ऐप बना रहे हैं, तो एक समझदारीपूर्ण डिफ़ॉल्ट है:
सर्विसेज की संख्या कम रखें। v1 के लिए "मॉड्यूलर मोनोलिथ" (अच्छी तरह व्यवस्थित कोडबेस, पर एक बैकएंड सर्विस) अक्सर माइक्रोसर्विसेस से आसान होता है।
यदि आप AI-फ़र्स्ट एन्वायरनमेंट पसंद करते हैं जहाँ वास्तुकला, टास्क और जनरेटेड कोड कड़ा रूप से जुड़े रहें, तो प्लेटफ़ॉर्म जैसे Koder.ai उपयुक्त हो सकते हैं: आप v1 स्कोप को चैट में वर्णित कर सकते हैं, "planning mode" में इटरेट कर सकते हैं, और फिर React फ्रंटएंड के साथ Go + PostgreSQL बैकएंड जनरेट कर सकते हैं—फिर भी समीक्षा और नियंत्रण आपके हाथ में रहता है।
कोड जनरेट करने से पहले एक छोटा API टेबल लिखें ताकि आप और AI एक ही लक्ष्य साझा करें। उदाहरण स्वरूप:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }स्टेटस कोड्स, एरर फ़ॉर्मैट (उदा., { error: { code, message } }), और कोई पेजिनेशन नोट्स जोड़ें।
यदि v1 सार्वजनिक या सिंगल-यूज़र हो सकता है तो auth स्किप कर दें और तेज़ शिप करें। अगर अकाउंट्स चाहिए तो मैनेज्ड प्रोवाइडर (email magic link या OAuth) का उपयोग करें और परमिशन सरल रखें: "user owns their records." जटिल रोल्स तब तक टालें जब तक असली उपयोग मांग न करे।
कुछ व्यावहारिक सीमाएँ डॉक्यूमेंट करें:
ये नोट्स AI-सहायित कोड जनरेशन को कुछ deployable की दिशा में गाइड करेंगे, सिर्फ़ functional नहीं।
तेज़ momentum मारने का सबसे तेज़ तरीका है टूल्स पर सप्ताह भर बहस करना और फिर भी रनन योग्य कोड न होना। आपका लक्ष्य: "hello app" तक पहुँचना जो लोकल में स्टार्ट हो, एक दिखाई देने वाला स्क्रीन हो, और एक अनुरोध स्वीकार कर सके—पर छोटा इतना कि हर बदलाव की समीक्षा आसान हो।
AI को टाइट प्रॉम्प्ट दें: फ्रेमवर्क चॉइस, बेसिक पेजेस, एक स्टब API, और अपेक्षित फ़ाइलें। आप predictable conventions चाह रहे हैं, ना कि cleverness।
एक अच्छा पहला पास संरचना है:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
यदि एक ही रेपो का उपयोग कर रहे हैं, तो बेसिक राउट्स पूछें (उदा., / और /settings) और एक API endpoint (उदा., GET /health या GET /api/status) — यह साबित करने के लिए कि प्लंबिंग काम कर रही है।
यदि आप Koder.ai इस्तेमाल कर रहे हैं, तो यह भी एक स्वाभाविक जगह है: एक मिनिमल “web + api + database-ready” स्केलेटन माँगे, और जब आप संरचना और कन्वेंशंस से संतुष्ट हों तो सोर्स एक्सपोर्ट करें।
UI को जानबूझकर साधारण रखें: एक पेज, एक बटन, एक कॉल।
उदाहरण बिहेवियर:
यह आपको त्वरित फीडबैक लूप देता है: अगर UI लोड होता है पर कॉल फेल होता है तो आप जानते हैं कहाँ देखना है (CORS, पोर्ट, राउटिंग, नेटवर्क एरर्स)। अभी auth, DB, या जटिल स्टेट जोड़ने से बचें—ये स्केलेटन स्थिर होने के बाद करेंगे।
पहले दिन .env.example बनाइए। इससे "works on my machine" समस्याएँ कम होती हैं और ऑनबोर्डिंग आसान होता है।
उदाहरण:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
फिर README को 1 मिनट में runnable बनाइए:
.env.example को .env में कॉपी करेंइस चरण को साफ़ नींव की तरह ट्रीट करें। हर छोटी जीत के बाद कमिट करें: "init repo", "add web shell", "add api health endpoint", "wire web to api"। छोटे कमिट AI-सहायित इटरेशन को सुरक्षित बनाते हैं: अगर जनरेटेड बदलाव गलत हुआ तो आप बिना दिन गंवाए revert कर सकेंगे।
एक बार स्केलेटन एंड-टू-एंड रन करने लगे, तो सब कुछ पूरा करने की जल्दी मत कीजिए। बजाय इसके, एक संकीर्ण वर्टिकल स्लाइस बनाएं जो DB, API, और UI को छूता है (यदि लागू हो), फिर दोहराएँ। पतले स्लाइस्स रिव्यू तेज़, बग छोटे और AI सहायता की जाँच आसान रखते हैं।
वह एक मॉडल चुनें जिसके बिना ऐप काम नहीं कर सकता—अक्सर वह "वस्तु" जिसे उपयोगकर्ता बनाते/प्रबंधित करते हैं। इसे सपष्ट रूप से परिभाषित करें (फ़ील्ड्स, required vs optional, defaults), फिर माइग्रेशन्स जोड़ें यदि आप रिलेशनल DB इस्तेमाल कर रहे हैं। पहले वर्जन को साधारण रखें: बुद्धिमत्ता और प्रीमेच्योर फ्लेक्सिबिलिटी से बचें।
यदि आप AI से मॉडल ड्राफ्ट करवा रहे हैं, तो उसे हर फ़ील्ड और डिफ़ॉल्ट के लिए एक वाक्य में न्याय करने के लिए कहें। जिसे वह एक वाक्य में नहीं समझा सकता, शायद v1 में नहीं होना चाहिए।
वह केवल एंडपॉइंट्स बनाएं जो पहले यूज़र जर्नी के लिए चाहिए: आमतौर पर create, read, और न्यूनतम update। वैलिडेशन बॉउंडरी के पास रखें (request DTO/schema), और नियम स्पष्ट रखें:
वैलिडेशन फीचर का हिस्सा है, न कि केवल पॉलिश—यह गंदे डेटा को रोकेगा जो बाद में आपको धीमा कर सकता है।
एरर मैसेजेस को डिबग और सपोर्ट के UX के रूप में ट्रीट करें। क्लियर, एक्शन योग्य मैसेज लौटाएँ (क्या फेल हुआ और इसे कैसे ठीक करें) जबकि क्लाइंट रिस्पॉन्स में संवेदनशील विवरण न दें। सर्वर-साइड पर तकनीकी संदर्भ लॉग करें और request ID दें ताकि आप घटनाओं को बिना अनुमान लगाये ट्रेस कर सकें।
AI से incremental PR-आकार के बदलाव माँगें: एक माइग्रेशन + एक एंडपॉइंट + एक टेस्ट एक बार में। डिफ्स की समीक्षा वैसा ही करें जैसे किसी टीम-मेम्बर का काम: नामकरण, एज केस्स, सुरक्षा मान्यताएँ, और क्या बदलाव वास्तव में उपयोगकर्ता की "छोटी जीत" का समर्थन करता है। अगर यह अतिरिक्त फीचर जोड़ता है, तो काट दें और आगे बढ़ें।
Version 1 को एंटरप्राइज़-ग्रेड सुरक्षा की ज़रूरत नहीं—पर उन अनुमानित विफलताओं से बचना चाहिए जो एक वादे वाले ऐप को सपोर्ट सिरदर्द बना दें। लक्ष्य "पर्याप्त सुरक्षित": खराब इनपुट रोکें, डिफ़ॉल्ट से एक्सेस रोकें, और जब कुछ गलत हो तो उपयोगी प्रमाण छोड़ें।
हर बॉउंड्री को अनट्रस्टेड मानें: फॉर्म फ़ील्ड्स, API पेलोड्स, क्वेरी पैरामीटर्स, और इंटरनल वेबहुक्स भी। प्रकार, लंबाई, और अनुमत मान वैलिडेट करें, और स्टोर करने से पहले डेटा सामान्यीकरण करें (स्ट्रिंग ट्रिम, केस कनवर्ज़न)।
कुछ व्यावहारिक डीफ़ॉल्ट्स:
अगर आप AI से हैंडलर्स जनरेट करवा रहे हैं, तो उससे वैलिडेशन नियम स्पष्ट रूप से शामिल करने के लिए कहें (उदा., "max 140 chars" या "must be one of: …") न कि सिर्फ़ "validate input."
सरल परमिशन मॉडल v1 के लिए अक्सर पर्याप्त है:
Ownership checks को केंद्रीय और पुन: उपयोग योग्य बनाइए (middleware/policy functions), ताकि आप पूरे कोडबेस में "if userId == …" न फैलाएँ।
अच्छे लॉग यह जवाब देते हैं: क्या हुआ, किसके साथ हुआ, और कहाँ हुआ? इसमें शामिल करें:
update_project, project_id)इवेंट्स को लॉग करें, न कि सीक्रेट्स: पासवर्ड्स, टोकन, या पूरा पेमेंट विवरण कभी लॉग न करें।
ऐप को "पर्याप्त सुरक्षित" कहने से पहले चेक करें:
टेस्टिंग का उद्देश्य परफेक्ट स्कोर नहीं है—बल्कि उन विफलताओं को रोकना है जो उपयोगकर्ताओं को नुकसान पहुँचाते हैं, भरोसा तोड़ते हैं, या महँगा ड्रामा पैदा करते हैं। AI-सहायित वर्कफ़्लो में, टेस्ट एक "कॉन्ट्रैक्ट" की तरह काम करते हैं जो जनरेटेड कोड को आपके वास्तविक इरादे के साथ संरेखित रखते हैं।
कवर बहुत बढ़ाने से पहले यह पहचानें कि कहाँ गलतियाँ महंगी होंगी। सामान्य उच्च-जोखिम क्षेत्र: पैसे/क्रेडिट, परमिशन, डेटा ट्रांसफ़ॉर्मेशन, और एज-केस वैलिडेशन।
इन हिस्सों के लिए यूनिट टेस्ट लिखें। उन्हें छोटा और विशिष्ट रखें: इनपुट X पर आउटपुट Y या एक त्रुटि अपेक्षित हो। अगर किसी फ़ंक्शन की शाखाएँ इतनी अधिक हैं कि साफ़ तरीके से टेस्ट नहीं की जा सकतीं, तो यह संकेत है कि उसे सरल बनाना चाहिए।
यूनिट टेस्ट लॉजिक बग पकड़ते हैं; इंटीग्रेशन टेस्ट "वायरिंग" बग पकड़ते हैं—राउट्स, DB कॉल, auth चेक्स और UI फ्लो का एक साथ काम।
मुख्य जर्नी चुनें और उसे एंड-टू-एंड ऑटोमेट करें:
कुछ मजबूत इंटीग्रेशन टेस्ट अक्सर दर्जनों छोटे टेस्ट्स की तुलना में अधिक घटनाओं को रोकते हैं।
AI टेस्ट का ढांचा और वो एज केस्स सुझाने में अच्छा है जो आप मिस कर सकते हैं। उससे माँगे:
फिर हर जेनरेटेड assertion की समीक्षा करें। टेस्ट को बिहेवियर वेरिफाई करना चाहिए, इम्प्लीमेंटेशन डिटेल नहीं। अगर टेस्ट किसी बग के बाद भी पास होगा तो वह अपना काम नहीं कर रहा।
एक मामूली लक्ष्य चुनें (उदा., कोर मॉड्यूल्स पर 60–70%) और इसे गार्डरेल बनाकर रखें, न कि ट्रॉफी। तेज़ और रिपीटेबल टेस्ट्स पर ध्यान दें जो CI में जल्दी चलते हों और सही कारणों से फेल हों। फ्लेकी टेस्ट भरोसा नष्ट कर देते हैं—एक बार लोग सूट पर भरोसा खो देते हैं, यह आपको बचाने बंद कर देता है।
ऑटोमेशन वह जगह है जहाँ AI-सहायित वर्कफ़्लो "मेरे लैपटॉप पर चलने वाला प्रोजेक्ट" से "विश्वास के साथ शिप करने लायक" बनता है। लक्ष्य फैंसी टूल नहीं—दोहराने योग्यता है।
एक कमांड चुनें जो लोकल और CI दोनों में वही नतीजा दे। Node में यह npm run build हो सकता है; Python में make build; मोबाइल में Gradle/Xcode स्टेप।
डेव और प्रोड कॉन्फ़िग अलग रखें। सरल नियम: dev defaults सुविधाजनक; production defaults सुरक्षित।
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
लिंटर जोखिम भरे पैटर्न पकड़ेगा (unused variables, unsafe async)। फॉर्मैटर "स्टाइल बहस" को शोर से बचायेगा। v1 के लिए नियम मामूली रखें, पर उन पर लगातार पालन करें।
प्रैक्टिकल गेट ऑर्डर:
पहला CI वर्कफ़्लो छोटा हो सकता है: dependencies इंस्टॉल करें, गेट्स चलाएँ, और फेल फ़ास्ट। इससे टूटे हुए कोड के चुपके से लैंड होने को रोका जा सकता है।
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
निर्णय लें कि सीक्रेट्स कहाँ रहेंगे: CI सीक्रेट स्टोर, पासवर्ड मैनेजर, या आपकी डिप्लॉयमेंट प्लेटफ़ॉर्म की environment settings। कभी भी इन्हें git में कमिट न करें—.env को .gitignore में डालें, और सुरक्षित placeholders के साथ .env.example रखें।
अगर आप एक साफ़ अगला कदम चाहते हैं, तो इन गेट्स को अपने डिप्लॉयमेंट प्रोसेस से जोड़ दें ताकि "ग्रीन CI" ही प्रोडक्शन तक जाने का एकमात्र रास्ता बने।
शिप करना एक बटन क्लिक नहीं है—यह एक दोहराने योग्य रूटीन है। v1 के लिए लक्ष्य सरल है: अपने स्टैक से मेल खाने वाला डिप्लॉयमेंट टार्गेट चुनें, छोटे increments में डिप्लॉय करें, और हमेशा वापस जाने का तरीका रखें।
ऐसी प्लेटफ़ॉर्म चुनें जो आपके ऐप के रन तरीके से मेल खाती हों:
"इजी टू री-डिप्लॉय" के लिए ऑप्टिमाइज़ करना अक्सर इस चरण में "अधिक कंट्रोल" चुनने से बेहतर है।
यदि आपका उद्देश्य टूल स्विचिंग कम करना है, तो ऐसे प्लेटफ़ॉर्म विचार करें जो बिल्ड + होस्टिंग + रोलबैक प्रिमिटिव्स को बUNDLE करते हैं। उदाहरण के लिए, Koder.ai डिप्लॉयमेंट और होस्टिंग के साथ snapshots और rollback सपोर्ट करता है ताकि आप रिलीज़ को रिवर्सिबल स्टेप की तरह ट्रीट कर सकें।
एक बार लिखें और हर रिलीज़ के लिए दोहराएँ। छोटी रखें ताकि लोग सचमुच इसका पालन करें:
अगर आप इसे रेपो में रखें (उदा., /docs/deploy.md), तो यह स्वाभाविक रूप से कोड के पास रहेगा।
एक हल्का एंडपॉइंट बनाएं जो जवाब दे: "क्या ऐप चालू है और क्या यह अपनी निर्भरताओं तक पहुँच सकता है?" सामान्य पैटर्न:
GET /health लोड बैलेंसर और अपटाइम मॉनिटर के लिएGET /status बेसिक ऐप वर्शन + dependency checks लौटाता हैरिस्पॉन्स तेज़, cache-free और सुरक्षित रखें (कोई सीक्रेट या आंतरिक विवरण नहीं)।
रोलबैक प्लान स्पष्ट होना चाहिए:
जब डिप्लॉयमेंट रिवर्सिबल होती है, तो रिलीज़ रूटीन बन जाती है—और आप कम तनाव के साथ अधिक बार शिप कर सकते हैं।
लॉन्च सबसे उपयोगी चरण की शुरुआत है: असली उपयोगकर्ता क्या करते हैं, कहाँ ऐप टूटता है, और कौन से छोटे बदलाव आपकी सफलता मेट्रिक को आगे बढ़ाते हैं। लक्ष्य है उसी AI-सहायित वर्कफ़्लो को बनाए रखना — अब इसे अनुमानों की बजाय साक्ष्यों की ओर निर्देशित करना।
मिनिमम मॉनिटरिंग स्टैक तीन सवालों का जवाब दे: क्या यह चालू है? क्या यह फेल हो रहा है? क्या यह धीमा है?
उपटाइम चेक्स सरल हो सकते हैं (हेल्थ एंडपॉइंट पर पीरियोडिक हिट)। एरर ट्रैकिंग स्टैक ट्रेसेस और रिक्वेस्ट संदर्भ कैप्चर करे (बिना संवेदनशील डेटा के)। प्रदर्शन मॉनिटरिंग की शुरुआत प्रमुख एंडपॉइंट्स के response times और फ्रंट-एंड पेज लोड मेट्रिक्स से करें।
AI से मदद लें:
सब कुछ ट्रैक न करें—उस चीज़ को ट्रैक करें जो साबित करे कि ऐप काम कर रहा है। एक प्रमुख सफलता मेट्रिक पर ध्यान दें (उदा., "completed checkout", "created first project", या "invited a teammate")। फिर एक छोटा फ़नल इंस्ट्रूमेंट करें: प्रवेश → मुख्य क्रिया → सफलता।
AI से इवेंट नाम और प्रॉपर्टीज़ सुझाव लें, फिर गोपनीयता और स्पष्टता के लिए उनकी समीक्षा करें। इवेंट्स को स्थिर रखें; हर हफ्ते नाम बदलना ट्रेंड्स को बेकार कर देता है।
एक सरल इन्टेक बनाएं: इन-ऐप फीडबैक बटन, एक छोटा ईमेल एलियास, और एक हल्का बग टेम्पलेट। साप्ताहिक ट्रायाज करें: फीडबैक को थीम में जोड़ें, एनालिटिक्स से जोड़ें, और अगले 1–2 सुधारों का निर्णय लें।
मॉनिटरिंग अलर्ट्स, एनालिटिक्स ड्रॉप, और फीडबैक थीम्स को नए "requirements" की तरह ट्रीट करें। उन्हें उसी प्रक्रिया में फीड करें: डॉक अपडेट करें, छोटा चेंज प्रपोज़ल जनरेट करें, पतले स्लाइस में इम्प्लीमेंट करें, एक लक्षित टेस्ट जोड़ें, और उसी रिवर्सिबल रिलीज़ प्रोसेस के जरिये डिप्लॉय करें। टीम्स के लिए, एक साझा "Learning Log" पेज (रेपो या इंटरनल docs से लिंक) निर्णयों को दृश्यमान और दोहराने योग्य रखता है।
एक "सिंगल वर्कफ़्लो" एक निरंतर थ्रेड है जो विचार से प्रोडक्शन तक चलता है, जहाँ:
आप कई टूल इस्तेमाल कर सकते हैं, लेकिन हर चरण पर प्रोजेक्ट को "फिर से शुरू" करने से बचते हैं।
AI से आप विकल्प और ड्राफ्ट बनवाइए — निर्णय और सत्यापन आपका काम है:
नियम रखें: "क्या यह मेट्रिक को आगे बढ़ाता है, और क्या इसे शिप करना सुरक्षित है?"
मापक सफलता मेट्रिक और संकुचित v1 "definition of done" तय करें। उदाहरण के तौर पर:
जो फीचर इन लक्ष्यों का समर्थन नहीं करता, वह v1 का नॉन-गोला होना चाहिए।
एक स्किमेबल, एक-पेज PRD रखें जिसमें शामिल हो:
फिर 5–10 कोर फीचर रखें और उन्हें Must/Should/Nice के अनुसार रैंक करें। यह रैंकिंग AI से बने प्लान और कोड को सीमित करने के काम आएगी।
आपके टॉप 3–5 फीचरों के लिए 2–4 टेस्टेबल स्टेटमेंट डालें। अच्छे acceptance criteria:
उदाहरण: वैलिडेशन नियम, अपेक्षित रिडायरेक्ट, एरर मैसेज और परमिशन बिहेवियर (उदा., “अनधिकृत उपयोगकर्ता स्पष्ट एरर देखता है और कोई डेटा लीक नहीं होता”)।
सबसे पहले एक क्रमिक हैप्पी पाथ लिखें, फिर उच्च-संभाव्यता और उच्च-लागत वाले फेल्यर्स की सूची बनाएं:
एक सरल नंबर वाली सूची काफी है; इसका उद्देश्य UI स्टेट्स, API रिस्पॉन्स और टेस्ट गाइड करना है।
v1 के लिए सामान्यतः एक "मॉड्यूलर मोनोलिथ" समझदार रहता है:
सिर्फ़ तभी अतिरिक्त सर्विस जोड़ें जब कोई वास्तविक आवश्यकता हो। इससे समन्वय कम रहता है और AI-सहायित इटरेशन को समीक्षा व रोलबैक करना आसान होता है।
कोड जनरेशन से पहले एक छोटा “API contract” टेबल लिखें:
{ error: { code, message } })यह UI, बैकएंड और टेस्ट्स के बीच mismatch रोकता है और टेस्ट को एक स्थिर लक्ष्य देता है।
प्लंबिंग साबित करने वाला “hello app” बनाएं:
/health) को कॉल करे.env.example और एक README जो 1 मिनट में रन होछोटे माइलस्टोन्स को जल्दी-कमिट करें ताकि जनरेटेड बदलाव खराब जाने पर रिवर्ट आसान हो।
AI-सहायित वर्कफ़्लो के लिए सबसे ज़्यादा जरूरी परीक्षण और CI गेट्स:
CI में सरल गेट्स इस क्रम में लागू करें:
टेस्ट्स स्थिर और तेज़ रखें; flaky सूट आपका सुरक्षा कवच कमजोर कर देते हैं।