07 अग॰ 2025·8 मिनट
वितरित डेटाबेस: स्थिरता बनाम उपलब्धता का व्यापार-ऑफ़
जानिए क्यों वितरित डेटाबेस अक्सर विफलताओं के दौरान उपलब्ध रहने के लिए स्थिरता ढीली करते हैं, CAP और क्वोरम कैसे काम करते हैं, और कब किसे चुनना चाहिए।
जानिए क्यों वितरित डेटाबेस अक्सर विफलताओं के दौरान उपलब्ध रहने के लिए स्थिरता ढीली करते हैं, CAP और क्वोरम कैसे काम करते हैं, और कब किसे चुनना चाहिए।
जब कोई डेटाबेस कई मशीनों (रेप्लिकाओं) में बँट जाता है, तो आपको गति और प्रतिरोधकता मिलती है—पर साथ ही ऐसे समय भी आते हैं जब ये मशीनें पूरी तरह सहमत नहीं रहतीं या उनका आपस में भरोसेमंद संवाद नहीं होता।
स्थिरता का मतलब है: एक सफल लिखाई के बाद, हर कोई वही मान पढ़ता है। यदि आप अपना प्रोफ़ाइल ईमेल अपडेट करते हैं, तो अगली पढ़ाई—चाहे कोई भी रेप्लिका जवाब दे—नया ईमेल लौटाती है।
व्यवहार में, जो सिस्टम स्थिरता को प्राथमिकता देते हैं वे विफलताओं के दौरान कुछ अनुरोधों को देरी कर सकते हैं या अस्वीकार कर सकते हैं ताकि विरोधी उत्तर न लौटें।
उपलब्धता का मतलब है: सिस्टम हर रिक्वेस्ट का जवाब देता है, भले ही कुछ सर्वर डाउन हों या अलग हों। आपको नवीनतम डेटा न मिल सकता हो, पर आपको जवाब मिल जाएगा।
व्यवहार में, उपलब्धता-प्राथमिक सिस्टम लेखन स्वीकार कर सकते हैं और पढ़ाइयाँ परोस सकते हैं भले ही रेप्लिकाएँ असहमत हों, और बाद में मतभेद सुलझाते हैं।
एक ट्रेड-ऑफ़ का मतलब है कि हर विफलता पर दोनों लक्ष्यों को अधिकतम नहीं किया जा सकता। अगर रेप्लिकाएँ समन्वय नहीं कर सकतीं, तो डेटाबेस को या तो:
सही संतुलन उस पर निर्भर करता है कि आप किस प्रकार की गलतियों को सहन कर सकते हैं: एक छोटा आउटेज, या एक छोटा समय जिसमें डेटा गलत/पुराना दिखे। अधिकांश वास्तविक सिस्टम बीच का कोई बिंदु चुनते हैं—और ट्रेड-ऑफ़ को स्पष्ट करते हैं।
जब एक डेटाबेस डेटा कई मशीनों (नोड्स) पर संग्रहीत और परोसा जाता है, तो वह "वितरित" कहलाता है। एप्लिकेशन के लिए यह अभी भी एक डेटाबेस जैसा दिख सकता है—पर अंदर, अनुरोध अलग-अलग नोड्स से हैंडल हो सकते हैं।
अधिकांश वितरित डेटाबेस डेटा की प्रतिकृतियाँ रखते हैं: वही रिकॉर्ड कई नोड्स पर स्टोर होता है। टीमें ऐसा इसलिए करती हैं ताकि वे:
रिप्लिकेशन शक्तिशाली है, पर यह तुरंत एक सवाल उठाता है: अगर दो नोड्स के पास एक ही डेटा की कॉपी है, तो आप कैसे सुनिश्चित करें कि वे हमेशा सहमत रहें?
एक ही सर्वर पर "डाउन" आमतौर पर स्पष्ट होता है: मशीन चालू है या नहीं। पर वितरित सिस्टम में विफलता अक्सर आंशिक होती है। एक नोड ज़िंदा पर धीमा हो सकता है। एक नेटवर्क लिंक पैकेट ड्रॉप कर सकता है। एक पूरा रैक कनेक्टिविटी खो सकता है जबकि बाकी क्लस्टर चलता रहे।
यह इसलिए महत्वपूर्ण है क्योंकि नोड्स तुरंत नहीं जान पाते कि कोई दूसरा नोड सचमुच डाउन है, अस्थायी रूप से पहुंच से बाहर है, या बस देरी में है। जब वे यह पता लगाने के लिए इंतज़ार कर रहे होते हैं, तो उन्हें इनकमिंग पढ़ने और लिखने के साथ क्या करना है यह निर्णय लेना पड़ता है।
एक सर्वर के साथ, एक स्रोत-तथ्य होता है: हर पढ़ाई नवीनतम सफल लिखाई देखती है।
कई नोड्स के साथ, "नवीनतम" समन्वय पर निर्भर होता है। अगर एक लिखाई नोड A पर सफल हो जाती है पर नोड B पहुँच से दूर है, तो क्या डेटाबेस:
यह तनाव—जो असंपूर्ण नेटवर्कों से वास्तविक होता है—ही वितरण के नियम बदलने का कारण है।
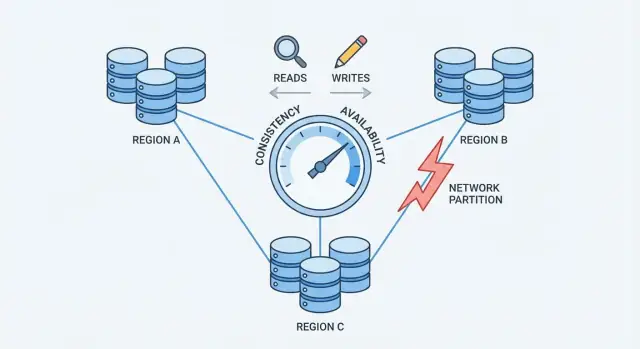
नेटवर्क विभाजन संचार में टूट का वह स्थिति है जहाँ वे नोड्स जो एक डेटाबेस के रूप में काम करने चाहिए, संदेश भरोसेमंद तरीके से एक्सचेंज नहीं कर पाते। नोड्स अभी भी रन कर सकते हैं और स्वस्थ दिख सकते हैं, पर स्विच फेल, लोडेड लिंक, गलत राउटिंग, फ़ायरवॉल मिसकन्फिग, या क्लाउड में शोर करने वाले पड़ोसी जैसी वजहों से वे संदेश नहीं भेज पाते।
जब सिस्टम कई मशीनों में फैला होता है (अक्सर रैक, ज़ोन, या रीजन में), तो आप उन सभी हॉप्स पर नियंत्रण नहीं रखते। नेटवर्क पैकेट ड्रॉप करते हैं, देरी डालते हैं, और कभी-कभी "आइलैंड" बना लेते हैं। छोटे पैमाने पर ये घटनाएँ दुर्लभ हो सकती हैं; बड़े पैमाने पर ये रूटीन बन जाती हैं। एक छोटा व्यवधान भी महत्वपूर्ण हो सकता है, क्योंकि डेटाबेस को यह तय करने के लिए लगातार समन्वय की ज़रूरत होती है कि क्या हुआ।
विभाजन के दौरान, दोनों पक्ष अनुरोध पाते रहते हैं। अगर उपयोगकर्ता दोनों तरफ लिख सकते हैं, तो हर तरफ ऐसे अपडेट स्वीकार किये जा सकते हैं जिन्हें दूसरी तरफ नहीं दिखते।
उदाहरण: नोड A किसी उपयोगकर्ता का पता "New Street" कर देता है। उसी समय, नोड B उसे "Old Street Apt 2" कर देता है। हर साइड अपनी लिखाई को सबसे हालिया मानती है—क्योंकि वे वास्तविक समय में नोट्स की तुलना नहीं कर सकतीं।
विभाजन साफ़ एरर मैसेज की तरह नहीं दिखता; यह भ्रमित करने वाले व्यवहार के रूप में दिखता है:
यह वह दबाव बिंदु है जो एक निर्णय को मजबूर करता है: जब नेटवर्क संचार सुनिश्चित नहीं कर सकता, तो एक वितरित डेटाबेस को स्थिरता या उपलब्धता में से किसी एक को प्राथमिकता देनी होगी।
CAP सपाट तरीके से बताता है कि जब डेटाबेस कई मशीनों में फैला हो तो क्या होता है।
जब कोई विभाजन नहीं है, कई सिस्टम दोनों—स्थिरता और उपलब्धता—प्रदर्शित कर सकते हैं।
जब विभाजन हो, आपको प्राथमिकता चुननी होगी:
balance = 100 लिखता है।balance = 80।CAP यह नहीं कहता कि "हमेशा के लिए केवल दो चुनें"। इसका मतलब है जब विभाजन होता है, तब आप दोनों Consistency और Availability की गारंटी एक साथ नहीं दे सकते। विभाजन के बाहर, कई सिस्टम अक्सर दोनों के काफी नज़दीक दिखते हैं—जब तक नेटवर्क सही रहता है।
स्थिरता चुनने का मतलब है सिस्टम "हर कोई एक ही सत्य देखे" को प्राथमिकता देता है बजाय कि हमेशा जवाब देने के। व्यवहार में, यह अक्सर मजबूत स्थिरता की ओर इशारा करता है, जिसे कभी-कभी लिनियराइज़ेबल कहा जाता है: एक बार लिखाई स्वीकार हो जाने पर कोई भी बाद की पढ़ाई (कहीं से भी) वह वैल्यू वापस करती है, जैसे कि एक ही अद्यतन कॉपी हो।
जब नेटवर्क बँट जाता है और रेप्लिकाएँ आपस में भरोसेमंद रूप से बात नहीं कर सकतीं, एक मजबूत स्थिरता वाला सिस्टम स्वतंत्र रूप से दोनों तरफ अपडेट सुरक्षित रूप से स्वीकार नहीं कर सकता। सहीपन की रक्षा के लिए यह आमतौर पर:
उपयोगकर्ता के नज़रिये से यह तब ऐसा लग सकता है जैसे आउटेज हो, भले ही कुछ मशीनें चल रही हों।
मुख्य लाभ है सरल सोच। एप्लिकेशन को ऐसा व्यवहार करने के लिए लिखा जा सकता है जैसे वह एक ही डेटाबेस से बात कर रही हो, न कि कई रेप्लिकाओं से जिनमें मतभेद हो सकते हैं। इससे उन अजीब परिस्थितियों की संख्या घटती है जैसे:
आपको ऑडिटिंग, बिलिंग और किसी भी ऐसी चीज़ के लिए साफ़ मानसिक मॉडल मिलते हैं जिसे पहली बार में सही होना चाहिए।
स्थिरता की असली कीमतें हैं:
अगर आपका प्रोडक्ट आंशिक आउटेज के दौरान विफल रिक्वेस्ट को सहन नहीं कर सकता, तो मजबूत स्थिरता महंगी लग सकती है—भले ही यह सही विकल्प हो।
उपलब्धता चुनने का मतलब है आप एक सरल वादा ऑप्टिमाइज़ करते हैं: सिस्टम जवाब देता है, भले ही इंफ्रास्ट्रक्चर का कुछ हिस्सा अस्वस्थ हो। व्यवहार में, "उच्च उपलब्धता" का अर्थ यह नहीं कि "कभी त्रुटि नहीं"—बल्कि यह कि नोड फेल, ओवरलोडेड रेप्लिका, या टूटे नेटवर्क लिंक के दौरान भी अधिकांश रिक्वेस्ट का जवाब मिल जाता है।
जब नेटवर्क बँट जाता है, रेप्लिकाएँ आपस में भरोसेमंद रूप से बात नहीं कर सकतीं। उपलब्धता-प्राथमिक डेटाबेस आमतौर पर पहुँच योग्य साइड से ट्रैफ़िक परोसना चालू रखता है:
यह एप्लिकेशन को चलाता रखता है, पर इसका अर्थ है कि अलग-अलग रेप्लिकाएँ अस्थायी रूप से अलग सत्य स्वीकार कर सकती हैं।
आपको बेहतर अपटाइम मिलता है: उपयोगकर्ता अभी भी ब्राउज़ कर सकते हैं, कार्ट में आइटम डाल सकते हैं, कमेंट पोस्ट कर सकते हैं, या इवेंट रिकॉर्ड कर सकते हैं—even अगर कोई रीजन आंशिक रूप से अलग पड़ा हो।
आपको तनाव के दौरान बेहतर यूएक्स भी मिलता है। टाइमआउट्स के बजाय आपकी ऐप व्यवहार को जारी रख सकती है ("आपका अपडेट सेव हो गया") और बाद में सिंक कर सकती है। कई कंज़्यूमर और एनालिटिक्स वर्कलोड के लिए यह ट्रेड-ऑफ़ उपयुक्त होता है।
कीमत यह है कि डेटाबेस स्टेल रीड्स दे सकता है। कोई उपयोगकर्ता एक रेप्लिका पर प्रोफ़ाइल अपडेट कर सकता है, और तुरंत दूसरे रेप्लिका से पढ़ते समय पुराना मान देख सकता है।
आपको राइट कॉन्फ्लिक्ट्स का जोखिम भी है: विभाजन के दौरान विभिन्न साइड्स पर एक ही रिकॉर्ड पर अलग उपयोगकर्ता अपडेट कर सकते हैं। विभाजन ठीक होने पर सिस्टम को अलग इतिहासों को सुलझाना होगा। नियमों के आधार पर, एक लिखाई जीत सकती है, फील्ड्स मर्ज हो सकते हैं, या कॉन्फ्लिक्ट ऐप्लिकेशन लॉजिक की मांग कर सकता है।
उपलब्धता-प्रथम डिज़ाइन अस्थायी असहमति को स्वीकार करने के बारे में है ताकि उत्पाद जवाब देता रहे—और फिर आप यह निवेश करते हैं कि असहमति का पता कैसे लगाना और मरम्मत कैसे करना है।
क्वोरम कई प्रतिलिपि डेटाबेस में स्थिरता और उपलब्धता के बीच संतुलन के लिए उपयोग की जाने वाली एक व्यावहारिक वोटिंग तकनीक है। एक रेप्लिका पर भरोसा करने के बजाय, सिस्टम पर्याप्त रेप्लिकाओं से सहमति मांगता है।
आप अक्सर क्वोरम में तीन संख्याएँ देखेंगे:
एक सामान्य नियम यह है: यदि R + W > N, तो हर पढ़ाई कम-से-कम एक ऐसी रेप्लिका के साथ ओवरलैप करेगी जिसमें नवीनतम सफल लिखाई है, जिससे स्टेल रीड की संभावना घटती है।
यदि आपके पास N=3 रेप्लिकाएँ हैं:
कुछ सिस्टम W=3 (सभी रेप्लिकाएँ) जैसी सेटिंग्स चुनते हैं मजबूत स्थिरता के लिए, पर इससे किसी भी रेप्लिका के धीमे/डाउन होने पर अधिक लिखाई-फेलियर हो सकते हैं।
क्वोरम विभाजन समस्याओं को ख़त्म नहीं करते—वे परिभाषित करते हैं किसे प्रगति करने की अनुमति है। यदि नेटवर्क 2–1 में बँट गया है, तो उस साइड के पास जिसका आकार 2 है वह R=2 और W=2 को पूरा कर सकता है, जबकि अलग-थलग एकल रेप्लिका नहीं कर सकती। इससे विरोधी अपडेट्स कम होते हैं, पर कुछ क्लाइंट्स को एरर या टाइमआउट का सामना करना पड़ सकता है।
क्वोरम आमतौर पर अधिक लेटेंसी (अधिक नोड्स से संपर्क), अधिक लागत (क्रॉस-नोड ट्रैफ़िक), और अधिक जटिल फेलियर व्यवहार (टाइमआउट्स अनुपलब्धता जैसा लग सकता है) का मतलब होते हैं। लाभ यह है कि यह एक समायोज्य मध्य मार्ग देता है: आप R और W को ताज़ा पढ़ाइयों या उच्च लेखन सफलता की ओर घुमा सकते हैं, जो जरूरी हो।
अंततः स्थिरता का मतलब है रेप्लिकाएँ अस्थायी रूप से असंगत रहने की अनुमति देती हैं, बशर्ते वे बाद में एक ही मान पर मिल जाएँ।
इसे एक कॉफी शॉप श्रृंखला की तरह सोचें जो साझा "सोल्ड आउट" साइन अपडेट करती है। एक स्टोर उसे सोल्ड आउट बताता है, पर अपडेट दूसरे स्टोर्स तक कुछ मिनट बाद पहुँचता है। उस विंडो के दौरान, कोई और स्टोर अभी भी "उपलब्ध" दिखा सकता है और आख़िरी आइटम बेच सकता है। सिस्टम "टूटी" नहीं है—अपडेट्स बस पकड़ रहे होते हैं।
जब डेटा अभी फैल रहा होता है, क्लाइंट्स ऐसे व्यवहार देख सकते हैं जो चौंकाने वाले लगते हैं:
अंततः स्थिरता सिस्टम असंगति विंडो घटाने के लिए पृष्ठभूमि मैकेनिज़्म जोड़ते हैं:
यह उन मामलों के लिए उपयुक्त है जहाँ उपलब्धता का महत्व वर्तमान सटीकता से ज्यादा है: एक्टिविटी फीड्स, व्यू काउंटर, सिफारिशें, कैश्ड प्रोफ़ाइल, लॉग/टेलीमेट्री, और अन्य गैर-क्रिटिकल डेटा जहाँ "कुछ समय में सही" स्वीकार्य है।
जब डेटाबेस कई रेप्लिकाओं पर लेखन स्वीकार करता है, तो अंततः संघर्ष हो सकता है: एक ही आइटम पर अलग-अलग नोड्स पर स्वतंत्र रूप से हुए अपडेट्स जब वे बाद में मिलते हैं तो तुलना में टकराते हैं।
क्लासिक उदाहरण है: एक उपयोगकर्ता एक डिवाइस पर शिपिंग पता बदल रहा है और दूसरे पर फोन नंबर—अगर हर अपडेट अलग रेप्लिका पर जाता है तो विभाजन के दौरान दोनों अलग-अलग स्वीकार हो सकते हैं।
कई सिस्टम last-write-wins से शुरू करते हैं: जो अपडेट नया टाइमस्टैम्प रखता है वह बाकियों को ओवरराइट कर देता है।
यह आकर्षक है क्योंकि इसे लागू करना आसान है और गणना तेज़ है। कमी यह है कि यह मौन रूप से डेटा खो सकता है। "नवीनतम" जीतने का मतलब यह हो सकता है कि एक पुराना परंतु महत्वपूर्ण परिवर्तन हट जाए—यह तब भी हो सकता है जब दोनों अपडेट अलग फील्ड्स को छू रहे हों।
यह यह भी मानता है कि क्लॉक भरोसेमंद हैं। मशीनों (या क्लाइंट्स) के बीच क्लॉक स्क्यू गलत अपडेट को जीतने दे सकता है।
सुरक्षित संघर्ष-हैंडलिंग आमतौर पर कारणात्मक इतिहास को ट्रैक करने की मांग करती है।
सैद्धांतिक रूप से, वर्शन वेक्टर (और सरल वैरिएंट) हर रिकॉर्ड के साथ थोड़ा मेटाडेटा जोड़ते हैं जो सारांश करता है "किस रेप्लिका ने कौन से अपडेट देखे हैं।" जब रेप्लिकाएँ वर्शन एक्सचेंज करती हैं, तो डेटाबेस पता लगा सकता है कि क्या एक वर्शन दूसरे को शामिल करता है (कोई संघर्ष नहीं) या वे विभेदित हैं (सुलह की ज़रूरत)।
कुछ सिस्टम लॉजिकल टाइमस्टैम्प (जैसे लैम्पोर्ट क्लॉक्स) या हाइब्रिड लॉजिकल क्लॉक्स का उपयोग करते हैं ताकि वॉल-क्लॉक समय पर कम निर्भरता रहे पर फिर भी क्रम का संकेत मिले।
एक बार संघर्ष का पता चलने पर आपके पास विकल्प होते हैं:
सर्वश्रेष्ठ तरीका आपके डेटा के लिए "सही" क्या है उस पर निर्भर करता है—कभी-कभी एक लिखाई खो जाना स्वीकार्य होता है, और कभी-कभी यह व्यापारिक रूप से गंभीर बग होता है।
कंसिस्टेंसी/उपलब्धता मुद्रा कोई दार्शनिक बहस नहीं है—यह एक उत्पाद निर्णय है। शुरू करें यह पूछकर: क्षणिक रूप से गलत होने की लागत क्या है, और "बाद में फिर से कोशिश करें" कहने की लागत क्या है?
कुछ डोमेन को लिखने के समय एक एकल अधिकारिक उत्तर चाहिए क्योंकि "लगभग सही" भी गलत है:
यदि अस्थायी असंगति का प्रभाव कम या उलट होने योग्य है, तो आप आमतौर पर अधिक उपलब्धता की ओर झुक सकते हैं।
कई यूएक्स थोड़े पुराने रीड के साथ ठीक काम कर लेते हैं:
स्पष्ट बताएं कि कितना पुराना ठीक है: सेकंड, मिनट, या घंटे। यह टाइम बजट आपकी रिप्लिकेशन और क्वोरम पसंदें तय करेगा।
जब रेप्लिकाएँ सहमत नहीं हो पातीं, तो आमतौर पर UX तीन में से एक होता है:
फ़ीचर के हिसाब से सबसे कम हानिकारक विकल्प चुनें, न कि वैश्विक रूप से।
यदि: गलत परिणाम वित्तीय/कानूनी जोखिम, सुरक्षा मुद्दे, या अपरिवर्तनीय क्रिया बना देता है—तो C की ओर झुकें।
यदि: उपयोगकर्ता प्रतिक्रियाशीलता को महत्व देते हैं, स्टेल डेटा सहनीय है, और कॉन्फ्लिक्ट्स बाद में सुरक्षित तरीके से तय किए जा सकते हैं—तो A की ओर झुकें।
संदेह होने पर, सिस्टम को विभाजित करें: महत्वपूर्ण रिकॉर्ड्स को मजबूत स्थिर रखें, और व्युत्पन्न व्यूज़ (फीड्स, कैश, एनालिटिक्स) को उपलब्धता के लिए अनुकूल बनायें।
आपको शायद पूरे सिस्टम के लिए एक ही "स्थिरता सेटिंग" चुननी ही नहीं पड़ेगी। कई आधुनिक वितरित डेटाबेस प्रति-ऑपरेशन स्थिरता चुनने देते हैं—और स्मार्ट एप्लिकेशन इसका फायदा उठाती हैं ताकि यूएक्स को चिकना रखा जा सके बिना यह दिखाये कि ट्रेड-ऑफ़ मौजूद नहीं है।
स्थिरता को एक डायल की तरह समझें जिसे आप उपयोगकर्ता की क्रिया के आधार पर घुमा सकते हैं:
यह हर चीज़ पर सबसे मजबूत स्थिरता लागत चुकाने से बचाता है, फिर भी उन ऑपरेशनों को सुरक्षित रखता है जिन्हें वास्तव में चाहिए।
एक आम पैटर्न है लिखने के लिए मजबूत, पढ़ने के लिए कमजोर:
कुछ मामलों में उल्टा भी काम करता है: तेज़ लेखन (कतारबद्ध/अंततः) और मजबूत रीड्स जब परिणाम की पुष्टि करनी हो ("क्या मेरा ऑर्डर प्लेस हुआ?")।
नेटवर्क डगमगाने पर क्लाइंट री-ट्राइ करेगा। री-ट्राइज़्स को सुरक्षित बनाएं आइडेम्पोटेंसी कीज़ के साथ ताकि "ऑर्डर सबमिट" दो बार चलने पर दो ऑर्डर न बने। समान की देखने पर पहला परिणाम स्टोर करें और फिर उपयोग करें।
सर्विसेज़ के पार बहु-कदम क्रियाओं के लिए, सागा का उपयोग करें: हर कदम के लिए एक कम्पेन्सेटिंग कार्रवाई हो (रिफंड, रिज़र्वेशन रिलीज़, शिपमेंट रद्द)। इससे सिस्टम बहालनीय रहता है भले ही कुछ हिस्से अस्थायी रूप से असहमत या फेल हों।
अगर आप इसे देख नहीं सकते तो आप ट्रेड-ऑफ़ का प्रबंधन नहीं कर सकते। प्रोडक्शन समस्याएँ अक्सर "रैंडम फेलियर्स" जैसी दिखती हैं जब तक आप सही मीट्रिक्स और टेस्ट न जोड़ें।
एक छोटे सेट से शुरू करें जो सीधे उपयोगकर्ता प्रभाव से जुड़ा हो:
यदि संभव हो, मीट्रिक्स को कंसिस्टेंसी मोड (क्वोरम बनाम लोकल) और रीजन/ज़ोन के हिसाब से टैग करें ताकि कहीं व्यवहार अलग दिखे तो पकड़ा जा सके।
वास्तविक आउटेज का इंतज़ार न करें। स्टेजिंग में कैओस प्रयोग चलाएँ जो यह सिमुलेट करें:
सिर्फ़ यह सत्यापित न करें कि "सिस्टम चालू रहता है", पर यह भी देखें कि कौन सी गारंटियाँ बनी रहती हैं: क्या रीड्स ताज़ा रहते हैं, क्या राइट्स ब्लॉक होते हैं, क्या क्लाइंट्स को स्पष्ट एरर मिलते हैं?
अलर्ट जोड़ें:
अंत में, गारंटियाँ स्पष्ट रखें: अपने सिस्टम का कागजी वादा दस्तावेज़ करें कि सामान्य ऑपरेशन और विभाजन के दौरान क्या वादा किया गया है, और प्रोडक्ट व सपोर्ट टीम्स को यह सिखाएँ कि उपयोगकर्ता क्या देख सकते हैं और कैसे जवाब दें।
यदि आप नए प्रोडक्ट में इन ट्रेड-ऑफ़ की खोज कर रहे हैं, तो मान्य करना जल्दी सहायक होता है—खासकर विफलता मोड्स, री-ट्राय व्यवहार, और UI में "स्टेल" कैसा दिखता है।
एक व्यावहारिक तरीका है वर्कफ़्लो का छोटा प्रोटोटाइप बनाना (राइट पाथ, रीड पाथ, री-ट्राय/आइडेम्पोटेंसी, और एक सुलह जॉब) इससे पहले कि आप पूर्ण आर्किटेक्चर अपनाएँ। Koder.ai जैसे उपकरणों से टीमें चैट-ड्रिवन वर्कफ़्लो के ज़रिए वेब ऐप्स और बैकएंड जल्दी स्पिन अप कर सकती हैं, डेटा मॉडल और API पर जल्दी इटरेट कर सकती हैं, और अलग-अलग स्थिरता पैटर्न (उदा., कड़े राइट्स + ढीले रीड्स) बिना पारंपरिक बिल्ड पाइपलाइन के ओवरहेड के टेस्ट कर सकती हैं। जब प्रोटोटाइप वांछित व्यवहार से मेल खाता है, तो आप सोर्स को एक्सपोर्ट करके इसे प्रोडक्शन में विकसित कर सकते हैं।
एक प्रतिलिपिकृत डेटाबेस में "एक ही" डेटा कई मशीनों (नोड्स) पर रहता है। यह लचीलापन और कम लेटेंसी देता है, लेकिन समन्वय की समस्या भी लाता है: नोड धीमे हो सकते हैं, पहुँच से बाहर हो सकते हैं, या नेटवर्क द्वारा अलग हो सकते हैं, इसलिए वे हमेशा तुरंत एक ही नवीनतम लेखन पर सहमत नहीं हो पाते।
स्थिरता का मतलब है: एक सफल लेखन के बाद, किसी भी बाद की पढ़ाई उसी वैल्यू को लौटाए—चाहे कोई भी रेप्लिका सेवा दे रहा हो। व्यवहार में, सिस्टम अक्सर पढ़ने/लिखने को तब तक रोकते या अस्वीकार करते हैं जब तक पर्याप्त रेप्लिका (या लीडर) अपडेट की पुष्टि न कर दें।
उपलब्धता का मतलब है कि सिस्टम हर रिक्वेस्ट को एक गैर-एरर प्रतिक्रिया लौटाता है, भले ही कुछ नोड्स डाउन हों या संवाद न कर पा रहे हों। प्रतिक्रिया पुरानी या आंशिक हो सकती है, या स्थानीय जानकारी पर आधारित हो सकती है, लेकिन सिस्टम विफलताओं के दौरान उपयोगकर्ताओं को ब्लॉक नहीं करता।
एक नेटवर्क विभाजन वह घटना है जहाँ उन नोड्स के बीच संचार टूट जाता है जो एक ही सिस्टम की तरह काम करने चाहिए। नोड्स स्वस्थ रह सकते हैं, पर संदेश भरोसेमंद तरीके से पार नहीं जा पाते—जिससे डेटाबेस को चुनना पड़ता है:
विभाजन के दौरान दोनों साइडें अपडेट स्वीकार कर सकती हैं जिन्हें वे तुरंत साझा नहीं कर पातीं। इससे हो सकता है:
ये सब उपयोगकर्ता-स्तर पर दिखाई देने वाले लक्षण हैं जब रेप्लिकासा अस्थायी रूप से समन्वय नहीं कर पातीं।
यह हमेशा "दो में से दो चुनें" जैसा नहीं है। इसका मतलब है: जब विभाजन हो, आप दोनों—
को एक साथ गारंटी नहीं दे सकते। विभाजन के बाहर कई सिस्टम अक्सर दोनों के साथ अच्छी तरह दिखते हैं—जब तक नेटवर्क गलत न हो जाए।
क्वोरम रेप्लिकाओं के बीच वोटिंग का एक व्यावहारिक तरीका है:
सामान्य मार्गदर्शक: R + W > N तो हर पढ़ाई कम-से-कम एक ऐसी रेप्लिका से ओवरलैप करेगी जिसमें नवीनतम सफल लिखाई मौजूद है। क्वोरम विभाजन समस्याओं को ख़त्म नहीं करते; वे यह तय करते हैं कि किस तरफ प्रगति कर सकती है (जैसे बहुमत वाला साइड)।
अंततः स्थिरता का मतलब है कि रेप्लिका अस्थायी रूप से असमंजस में रहे सकती हैं, बशर्ते वे बाद में एक-दूसरे से मेल खा लें। सामान्य असंगतियों में शामिल हैं:
सिस्टम इन्हें कम करने के लिए , , और नियमित जैसी पृष्ठभूमि प्रक्रियाएँ चलाते हैं।
विभाजन ठीक होने पर संघर्ष तब होते हैं जब अलग-अलग रेप्लिका ने एक ही आइटम पर स्वतंत्र रूप से अलग लिखाई स्वीकार कर ली हो। समाधान के तरीके:
सही रणनीति आपके डेटा के लिए "सही" क्या है उस पर निर्भर करती है।
निर्णय आपके उत्पाद जोखिम और उपयोगकर्ता पर प्रभाव पर आधारित होना चाहिए:
व्यावहारिक पैटर्न: प्रति-ऑपरेशन स्थिरता स्तर, आइडेम्पोटेंसी की योजना बनाना, और मल्टी-स्टेप वर्कफ़्लो के लिए सागाज़/कम्पेन्सेशन।