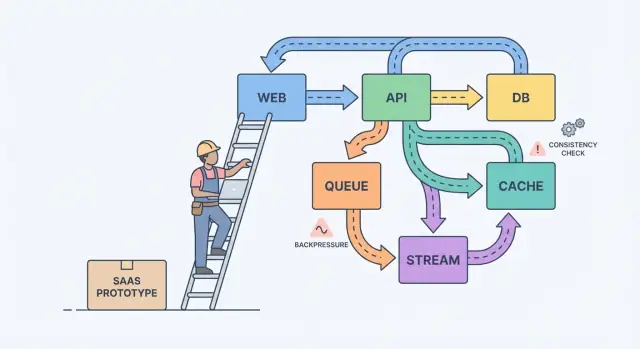
प्रोटोटाइप से SaaS तक: भ्रम वहीं से शुरू होता है\n\nएक प्रोटोटाइप किसी विचार को सिद्ध कर देता है। एक SaaS को असली उपयोग सहना होता है: पीक ट्रैफ़िक, गंदा डेटा, retries, और ग्राहक जो हर कमी को महसूस करते हैं। तभी सवाल बदल जाता है: “क्या यह काम करता है?” से “क्या यह चलता रहेगा?”\n\nअसली यूज़र्स के साथ, “यह कल ठीक था” साधारण कारणों से फेल हो जाता है। एक background job सामान्य से देर से चले। किसी ग्राहक ने टैस्ट डेटा से 10x बड़ी फ़ाइल अपलोड कर दी। एक पेमेंट प्रोवाइडर 30 सेकंड के लिए अटक गया। यह कुछ भी विदेशी नहीं है, लेकिन सिस्टम के हिस्से एक-दूसरे पर निर्भर होते ही इनका असर तेज़ हो जाता है।\n\nज़्यादातर जटिलताएँ चार जगह दिखती हैं: डेटा (एक ही तथ्य कई जगह मौजूद और drift करता है), लेटेंसी (50 ms कॉल कभी-कभी 5 सेकंड ले लेते हैं), फेलियर (timeouts, partial updates, retries), और टीमें (अलग लोग अलग सर्विसेज़ अलग शेड्यूल पर भेजते हैं)।\n\nएक सरल मानसिक मॉडल मदद करता है: कंपोनेंट्स, संदेश, और स्टेट।\n\nकंपोनेंट्स काम करते हैं (web app, API, worker, database). संदेश काम को कंपोनेंट्स के बीच ले जाते हैं (requests, events, jobs). स्टेट वह है जो आप याद रखते हैं (orders, user settings, billing status). स्केलिंग की तकलीफ अक्सर मिसमैच होती है: आप संदेश इतनी तेज़ी से भेजते हैं जितना कोई कंपोनेंट संभाल नहीं सकता, या आप स्टेट को दो जगह अपडेट करते हैं बिना किसी स्पष्ट source of truth के।\n\nएक क्लासिक उदाहरण बिलिंग है। एक प्रोटोटाइप एक invoice बनाता है, ईमेल भेजता है, और एक ही रिक्वेस्ट में यूज़र का प्लान अपडेट कर देता है। लोड के तहत, ईमेल धीमा हो जाता है, रिक्वेस्ट टाइमआउट हो जाता है, क्लाइंट retry करता है, और अब आपके पास दो invoices और एक plan change रह जाता है। रिलायबिलिटी का काम ज़्यादातर इन रोज़मर्रा की विफलताओं को यूज़र-फ़ेसिंग बग्स न बनने देना है।\n\n## कॉन्सेप्ट्स को लिखित निर्णयों में बदलना\n\nज़्यादातर सिस्टम इसलिए कठिन हो जाते हैं क्योंकि वे बिना सहमति के बढ़ते हैं कि क्या सही होना चाहिए, क्या तेज़ होना चाहिए, और कुछ फेल होने पर क्या होना चाहिए।\n\nशुरुआत करें उस सीमा को ड्रा करके जो आप यूज़र्स से वादा कर रहे हैं। उस सीमा के अंदर उन कार्रवाइयों को नाम दें जो हर बार सही होनी चाहिए (पैसे का लेनदेन, एक्सेस कंट्रोल, अकाउंट ओनरशिप)। फिर उन क्षेत्रों को नाम दें जहाँ “आख़िरकार सही” ठीक है (analytics counts, search indexes, recommendations)। यह विभाजन अस्पष्ट सिद्धांत को प्राथमिकताओं में बदल देता है।\n\nअगला, अपने source of truth को लिखें। यह वह जगह है जहाँ तथ्य एक बार, स्थायी रूप से, स्पष्ट नियमों के साथ दर्ज होते हैं। बाकी सब derived डेटा है जो स्पीड या सुविधा के लिए बनाया जाता है। अगर कोई derived view भ्रष्ट हो जाए, तो आपको उसे source of truth से फिर से बना पाने में सक्षम होना चाहिए।\n\nजब टीमें अटकी हों, ये सवाल अक्सर यह उभारकर लाते हैं कि क्या महत्वपूर्ण है:\n\n- कौन सा डेटा कभी खोना नहीं चाहिए, भले ही वह धीमा कर दे?\n- क्या दूसरी डेटा से फिर से बनाया जा सकता है, भले ही उसमें घंटे लग जाएँ?\n- यूज़र के नजरिए से क्या stale होना स्वीकार्य है, और कितनी देर तक?\n\n- आपके लिए कौन सी विफलता खराब है: duplicates, missing events, या delays?\n\nअगर एक यूज़र अपना बिलिंग प्लान अपडेट करता है, तो एक डैशबोर्ड लेट हो सकता है। लेकिन आप पेमेंट स्टैटस और वास्तविक एक्सेस के बीच किसी भी mismatch को बर्दाश्त नहीं कर सकते।\n\n## स्ट्रीम्स, क्यूज़, और लॉग्स: काम की सही आकृति चुनना\n\nअगर यूज़र किसी बटन पर क्लिक करके तुरंत परिणाम देखना चाहता है (प्रोफ़ाइल सेव करना, डैशबोर्ड लोड करना, परमिशन चेक करना), तो सामान्य request-response API अक्सर काफी होता है। इसे डायरेक्ट रखें।\n\nजैसे ही काम बाद में हो सकता है, उसे async में ले जाइए। सोचें: ईमेल भेजना, कार्ड चार्ज करना, रिपोर्ट बनाना, अपलोड रिसाइज़ करना, या डेटा को सर्च में सिंक करना। यूज़र को इनका इंतज़ार नहीं करना चाहिए, और आपका API इनके चलते बँधा नहीं रहना चाहिए।\n\nएक क्यू एक टू-डू सूची है: हर टास्क को एक worker द्वारा एक बार संभाला जाना चाहिए। एक स्ट्रीम (या लॉग) एक रिकॉर्ड है: इवेंट्स क्रम में रखे जाते हैं ताकि कई रीडर्स उन्हें replay कर सकें, catch up कर सकें, या बाद में नए फीचर बना सकें बिना producer को बदलने की आवश्यकता के।\n\nचुनने का एक व्यावहारिक तरीका:\n\n- जब यूज़र को तुरंत उत्तर चाहिए और काम छोटा है तब request-response का उपयोग करें।\n- बैकग्राउंड वर्क के लिए queue का उपयोग करें जहाँ retries हों और हर जॉब को केवल एक worker करना चाहिए।\n- जब आपको replay, audit trail, या कई consumers चाहिए जो एक सेवा से coupled न हों तो stream/log का उपयोग करें।\n\nउदाहरण: आपकी SaaS में “Create invoice” बटन है। API इनपुट को वैलिडेट करता है और invoice को Postgres में स्टोर करता है। फिर एक queue “send invoice email” और “charge card” संभालता है। अगर आप बाद में analytics, notifications, और fraud checks जोड़ते हैं, तो InvoiceCreated इवेंट की स्ट्रीम हर फीचर को सब्सक्राइब करने देती है बिना आपके कोर सर्विस को जटिल बनाए।\n\n## इवेंट डिज़ाइन: आप क्या प्रकाशित करते हैं और क्या रखना चाहिए\n\nजैसे-जैसे प्रोडक्ट बढ़ता है, इवेंट्स “अच्छा होना” से बढ़कर सुरक्षा जाल बन जाते हैं। अच्छा इवेंट डिज़ाइन दो सवालों पर आता है: आप कौन से तथ्य रिकॉर्ड करते हैं, और अन्य उत्पाद हिस्से बिना अनुमान लगाए कैसे प्रतिक्रिया कर सकते हैं?\n\nछोटे सेट के बिज़नेस इवेंट्स से शुरू करें। उन क्षणों को चुनें जो यूज़र्स और पैसे के लिए मायने रखते हैं: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.\n\nनाम कोड के बाहर भी अर्थ देते हैं। पूरा हुआ तथ्य बताने के लिए भूतकाल का उपयोग करें, उन्हें विशिष्ट रखें, और UI शब्दावली से बचें। PaymentSucceeded तब भी अर्थपूर्ण रहता है जब आप बाद में कूपन, retries, या कई पेमेंट प्रोवाइडर जोड़ें।\n\nइवेंट्स को कॉन्ट्रैक्ट की तरह ट्रीट करें। "UserUpdated" जैसे catch-all से बचें जिसमें हर स्प्रिंट में बदलने वाले फील्ड हों। वर्षों तक आप जिस सबसे छोटे तथ्य के पीछे खड़े रह सकते हैं, वही बेहतर है।\n\nसुरक्षित तरीके से विकसित करने के लिए, additive changes (नए optional फ़ील्ड) को प्राथमिकता दें। अगर ब्रेकिंग परिवर्तन चाहिए, तो नया इवेंट नाम (या स्पष्ट वर्ज़न) प्रकाशित करें और तब तक दोनों चलाएँ जब तक पुराने consumers न हट जाएँ।\n\nआप क्या स्टोर करें? अगर आप केवल डेटाबेस में नवीनतम पंक्तियाँ रखते हैं, तो आप यह कहानी खो देते हैं कि वहाँ कैसे पहुँचा गया।\n\nRaw events audit, replay, और debugging के लिए शानदार हैं। Snapshots तेज़ पढ़ने और त्वरित recovery के लिए अच्छे हैं। कई SaaS दोनों का उपयोग करते हैं: महत्वपूर्ण वर्कफ़्लोज़ (billing, permissions) के लिए raw events स्टोर करें और यूज़र-फेसिंग स्क्रीन के लिए snapshots बनाएँ।\n\n## संगति के ट्रेडऑफ जो यूज़र महसूस करते हैं\n\nसंगति ऐसे पलों में दिखती है जैसे: “मैंने अपना प्लान बदला, फिर भी क्यों Free दिख रहा है?” या “मैंने इनवाइट भेजा, फिर भी मेरा teammate लॉगिन क्यों नहीं कर पा रहा?”\n\nStrong consistency का मतलब है कि जैसे ही आप success संदेश पाते हैं, हर स्क्रीन तुरंत नए स्टेट को दर्शाए। Eventual consistency का मतलब है कि परिवर्तन समय के साथ फैलता है, और एक छोटे विंडो में ऐप के अलग-अलग हिस्से असहमत हो सकते हैं। कोई भी बेहतर नहीं है। आप उस आधार पर चुनते हैं कि mismatch से कितना नुकसान हो सकता है।\n\nStrong consistency आमतौर पर पैसे, एक्सेस, और सुरक्षा के लिए उपयुक्त है: कार्ड चार्ज करना, पासवर्ड बदलना, API keys रद्द करना, सीट लिमिट लागू करना। Eventual consistency अक्सर activity feeds, search, analytics dashboards, “last seen,” और notifications के लिए ठीक रहती है।\n\nअगर आप stale को स्वीकार करते हैं, तो इसे छिपाने के बजाय इसके लिए डिजाइन करें। UI को ईमानदार रखें: write के बाद तब तक “Updating…” स्टेट दिखाएँ जब तक पुष्टि न आ जाए, लिस्ट के लिए मैन्युअल रिफ़्रेश दें, और optimistic UI तभी उपयोग करें जब आप साफ़ तौर पर rollback कर सकें।\n\nRetries वो जगह है जहाँ संगति चालाकी से बदलती है। नेटवर्क गिरते हैं, क्लाइंट दो बार क्लिक करते हैं, और workers restart होते हैं। महत्वपूर्ण ऑपरेशन के लिए requests को idempotent बनाइए ताकि उसी क्रिया को दोहराने पर दो invoices, दो invites, या दो refunds न बने। एक सामान्य तरीका है हर कार्रवाई के लिए एक idempotency key और सर्वर-साइड नियम जो दोहराव पर मूल परिणाम लौटाता है।\n\n## बैकप्रेशर: सिस्टम को गलन से बचाना\n\nबैकप्रेशर तब चाहिए जब अनुरोध या इवेंट्स उस गति से आ रहे हों जितना आपका सिस्टम हैंडल कर सके। इसके बिना, काम मेमोरी में जमा हो जाता है, क्यूज़ बढ़ती हैं, और सबसे धीमा डिपेंडेंसी (अक्सर डेटाबेस) तय कर देता है कि सब कुछ कब फेल होगा।\n\nसादे शब्दों में: आपका producer लगातार बोलता रहता है जबकि consumer डूब रहा है। अगर आप और काम स्वीकार करते रहते हैं, तो आप सिर्फ़ धीमे नहीं होते। आप timeouts और retries की एक श्रृंखला ट्रिगर करते हैं जो लोड को गुणा कर देती है।\n\nचेतावनी संकेत आमतौर पर आउटेज से पहले दिखाई देते हैं: backlog लगातार बढ़ता है, spikes या deploys के बाद latency छलांग लगाती है, retries timeouts के साथ बढ़ते हैं, एक धीमे डिपेंडेंसी से unrelated endpoints फेल होते हैं, और डेटाबेस कनेक्शन्स लिमिट पर बैठे रहते हैं।\n\nजब आप उस बिंदु पर पहुँचते हैं, तो यह तय करें कि जब आप भर गए हैं तो क्या होगा। लक्ष्य हर चीज़ को किसी भी कीमत पर प्रोसेस करना नहीं है। लक्ष्य है ज़िंदा रहना और जल्दी recover करना। टीमें आमतौर पर एक या दो कंट्रोल से शुरू करती हैं: rate limits (प्रति यूज़र या API key), bounded queues जिनकी drop/delay नीति स्पष्ट हो, failing dependencies के लिए circuit breakers, और प्राथमिकताएँ ताकि interactive अनुरोध बैकग्राउंड जॉब्स पर जीतें।\n\nसबसे पहले डेटाबेस की रक्षा करें। कनेक्शन पूल्स छोटे और पूर्वानुमानित रखें, query timeouts सेट करें, और expensive endpoints जैसे ad-hoc रिपोर्ट्स पर हार्ड लिमिट लगाएँ।\n\n## बड़े बदलाव के बिना रिलायबिलिटी के लिए कदम-दर-कदम रास्ता\n\nरिलायबिलिटी शायद ही कभी बड़े री-राइट की ज़रूरत होती है। यह आमतौर पर कुछ निर्णयों से आता है जो विफलताओं को दिखाई देने योग्य, सीमित, और recoverable बनाते हैं।\n\nउन फ्लोज़ से शुरू करें जो भरोसा बनाती या तोड़ती हैं, फिर फीचर जोड़ने से पहले safety rails लगाएँ:\n\n1. क्रिटिकल पाथ्स मैप करें। साइनअप, लॉगिन, पासवर्ड रीसेट, और कोई भी पेमेंट फ्लो के सटीक कदम लिखें। हर कदम के लिए उसकी dependencies (database, email provider, background worker) सूचीबद्ध करें। इससे यह स्पष्ट होता है कि क्या तुरंत होना चाहिए और क्या "आख़िरकार" ठीक है।\n\n2. ऑब्ज़रवेबिलिटी बुनियादी जोड़ें। हर रिक्वेस्ट को एक ID दें जो लॉग्स में दिखे। कुछ मेट्रिक्स ट्रैक करें जो यूज़र के दर्द से मेल खाते हों: error rate, latency, queue depth, और slow queries। जहाँ रिक्वेस्ट सर्विसेज़ पार करे, वहाँ traces जोड़ें।\n\n3. धीमे या flaky वर्क को अलग करें। जो कुछ भी किसी बाहरी सर्विस से बात करता है या नियमित रूप से एक सेकंड से अधिक लेता है उसे jobs और workers में ले जाएँ।\n\n4. Retries और partial failures के लिए डिजाइन करें। मानकर चलें कि timeouts होते हैं। ऑपरेशन्स को idempotent बनाइए, backoff का उपयोग करें, समय सीमाएँ सेट करें, और यूज़र-फेसिंग एक्शन्स को छोटा रखें।\n\n5. Recovery का अभ्यास करें। बैकअप तब ही मायने रखते हैं जब आप उन्हें restore कर सकते हों। छोटे रिलीज़ का उपयोग करें और तेज़ rollback पथ रखें।\n\nअगर आपका टूलिंग स्नैपशॉट और रोलबैक सपोर्ट करती है (Koder.ai ऐसा करती है), तो उसे सामान्य डिप्लॉयमेंट आदत में शामिल करें बजाय इसे किसी इमरजेंसी ट्रिक की तरह रखने के।\n\n## उदाहरण: एक छोटे SaaS को भरोसेमंद बनाना\n\nकल्पना कीजिए एक छोटा SaaS जो टीमों को नए क्लाइंट्स ऑनबोर्ड करने में मदद करता है। फ्लो सरल है: एक यूज़र साइन अप करता है, प्लान चुनता है, पे करता है, और एक स्वागत ईमेल और कुछ “getting started” स्टेप्स पाता है।\n\nप्रोटोटाइप में सब कुछ एक ही रिक्वेस्ट में होता है: अकाउंट बनाना, कार्ड चार्ज करना, यूज़र पर "paid" फ्लिप करना, ईमेल भेजना। यह तब तक काम करता है जब तक ट्रैफ़िक बढ़ता है, retries होते हैं, और बाहरी सर्विसेज़ धीमी हो जाती हैं।\n\nइसे भरोसेमंद बनाने के लिए टीम मुख्य कार्रवाइयों को इवेंट्स में बदलती है और एक append-only इतिहास रखती है। वे कुछ इवेंट्स जोड़ते हैं: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. इससे उन्हें एक ऑडिट ट्रेल मिलता है, analytics आसान होते हैं, और धीमा काम साइनअप को ब्लॉक किए बिना बैकग्राउंड में हो सकता है।\n\nकुछ चुनाव सबसे ज़्यादा काम करते हैं:\n\n- एक्सेस के लिए भुगतान को स्रोत-ऑफ़-ट्रूथ मानें, न कि केवल एक "paid" फ्लैग।\n- PaymentSucceeded से entitlements दें और एक स्पष्ट idempotency key रखें ताकि retries से दोहरा-ग्राॅंट न हो।\n- चेकआउट रिक्वेस्ट से ईमेल भेजने के बजाय queue/worker से ईमेल भेजें।\n- यदि कोई हैंडलर फेल हो जाए तब भी इवेंट्स रिकॉर्ड करें, ताकि आप replay और recover कर सकें।\n- बाहरी प्रोवाइडर्स के चारों ओर timeouts और circuit breaker जोड़ें।\n\nअगर पेमेंट सफल हो पर एक्सेस अभी तक Granted नहीं है, तो यूज़र्स ठगे हुए महसूस करते हैं। समाधान यह नहीं है कि हर जगह Perfect consistency हो। समाधान यह तय करना है कि अभी क्या consistent होना चाहिए, और फिर UI में उस निर्णय को दर्शाना जैसे "Activating your plan" तब तक जब तक EntitlementGranted न आ जाए।\n\nखराब दिन पर, बैकप्रेशर फर्क कर देता है। अगर ईमेल API एक मार्केटिंग कैंपेन के दौरान अटक जाए, तो पुराना डिजाइन चेकआउट को टाइमआउट कर देता है और यूज़र्स retry करते हैं, जिससे duplicate charges और duplicate emails बनते हैं। बेहतर डिजाइन में, चेकआउट सफल रहता है, ईमेल रिक्वेस्ट्स कतार में लग जाते हैं, और एक replay job बैक्लॉग को पीढ़ीवार निकाल देता है जब प्रोवाइडर ठीक हो जाए।\n\n## जब सिस्टम स्केल करते हैं तो आम फँसने वाली चीज़ें\n\nज़्यादातर आउटेज किसी एक ही हीरोइक बग की वजह से नहीं आते। वे उन छोटे निर्णयों से आते हैं जो प्रोटोटाइप में समझ में आते थे और फिर आदत बन गए।\n\nएक आम फँसने वाली बात है बहुत जल्दी माइक्रोसर्विसेज़ में विभाजित हो जाना। आप ऐसे सर्विसेज़ पाते हैं जो ज्यादातर एक-दूसरे को कॉल करती हैं, मालिकाना स्पष्ट नहीं रहती, और बदलाव के लिए पांच deploys की आवश्यकता होती है बजाय एक के।\n\nएक और फँसने वाली बात है “eventual consistency” को एक मुफ्त पास की तरह इस्तेमाल करना। यूज़र्स को शब्दों से फर्क नहीं पड़ता—उन्हें फर्क पड़ता है कि उन्होंने Save पर क्लिक किया और बाद में पेज पुराना डेटा दिखाता है, या किसी invoice की स्थिति बार-बार बदलती रहती है। अगर आप delay स्वीकार करते हैं, तो आपको अभी भी यूज़र फीडबैक, टाइमआउट्स, और हर स्क्रीन पर "अच्छा पर्याप्त" की परिभाषा चाहिए।\n\nअन्य रिपीट ऑफेंडर्स: बिना reprocessing योजना के इवेंट्स प्रकाशित करना, अनबाउंडेड retries जो incidents के दौरान load को गुणा करते हैं, और हर सर्विस को एक ही डेटाबेस स्कीमा से डायरेक्ट बोलने देना ताकि एक बदलाव कई टीमों को तोड़ दे।\n\n## "प्रोडक्शन रेडी" कहने से पहले त्वरित जाँचें\n\n“प्रोडक्शन रेडी” उन निर्णयों का सेट है जिनका आप 2 बजे रात को हवाला दे सकें। स्पष्टता चालाकी से बेहतर है।\n\nशुरू करें अपने स्रोत-ऑफ़-ट्रूथ को नाम देकर। हर प्रमुख डेटा प्रकार (customers, subscriptions, invoices, permissions) के लिए तय करें कि अंतिम रिकॉर्ड कहाँ रहता है। अगर आपकी ऐप दो जगह से "सत्य" पढ़ती है, तो आप अंततः अलग-अलग यूज़र्स को अलग-जवाब दिखाएँगे।\n\nफिर retries देखें। मानिए कि हर महत्वपूर्ण कार्रवाई किसी न किसी समय दो बार चलेगी। अगर वही रिक्वेस्ट दो बार सिस्टम पर पड़े, क्या आप दो बार चार्जिंग, दो बार भेजना, या दो बार बनाना टाल सकते हैं?\n\nएक छोटी चेकलिस्ट जो अधिकांश दर्दनाक विफलताओं को पकड़ लेती है:\n\n- हर डेटा प्रकार के लिए आप source of truth बता सकते हैं और क्या derived है।\n- हर महत्वपूर्ण write retry-safe है (idempotency key या unique constraint)।\n- आपका async वर्क बिना सीमा के बढ़ नहीं सकता (आप lag, oldest message age ट्रैक करते हैं और यूज़र्स के नोटिस से पहले अलर्ट करते हैं)।\n\n- आपके पास परिवर्तन की योजना है (reversible migrations, event versioning)।\n- आपने अभ्यास किया है ताकि आप भरोसे के साथ रोलबैक और restore कर सकें।\n\n## अगले कदम: एक-एक निर्णय करें\n\nजब आप सिस्टम डिज़ाइन को विकल्पों की एक छोटी सूची के रूप में देखें, स्केलिंग आसान हो जाती है—न कि सिद्धांतों के ढेर के रूप में।\n\nअगले महीने में आप जिन 3–5 निर्णयों का सामना करने की उम्मीद करते हैं उन्हें सादा भाषा में लिखें: “क्या हम ईमेल भेजना बैकग्राउंड जॉब में ले जाएँ?” “क्या हम हल्का stale analytics स्वीकार करते हैं?” “कौन सी क्रियाएँ तुरंत consistent होना चाहिए?” उस सूची का उपयोग प्रोडक्ट और इंजीनियरिंग को संरेखित करने के लिए करें।\n\nफिर किसी एक वर्कफ़्लो को चुनें जो अभी synchronous है और केवल उसे async में बदलें। रसीदें, नोटिफिकेशन्स, रिपोर्ट्स, और फ़ाइल प्रोसेसिंग आम पहले कदम होते हैं। परिवर्तन से पहले और बाद में दो चीज़ें मापें: यूज़र-फेसिंग लेटेंसी (क्या पेज तेज़ महसूस हुआ?) और फेलियर व्यवहार (क्या retries ने duplicates या भ्रम बनाया?).\n\nअगर आप इन परिवर्तनों को जल्दी प्रोटोटाइप करना चाहते हैं, तो Koder.ai (koder.ai) React + Go + PostgreSQL SaaS पर इटरेट करते समय रोलबैक और स्नैपशॉट पास रखकर मददगार हो सकता है। मानक को सरल रखें: एक सुधार भेजें, असली ट्रैफ़िक से सीखें, फिर अगला फैसला लें।