17 मार्च 2025·8 मिनट
VMware और Broadcom: जब वर्चुअलाइजेशन नियंत्रण‑परत बन जाता है
सरल शब्दों में देखें कि कैसे VMware एंटरप्राइज़ IT का कंट्रोल‑प्लेन बन गया, और Broadcom के स्वामित्व से बजट, टूल और टीमों पर क्या असर पड़ सकता है।
सरल शब्दों में देखें कि कैसे VMware एंटरप्राइज़ IT का कंट्रोल‑प्लेन बन गया, और Broadcom के स्वामित्व से बजट, टूल और टीमों पर क्या असर पड़ सकता है।
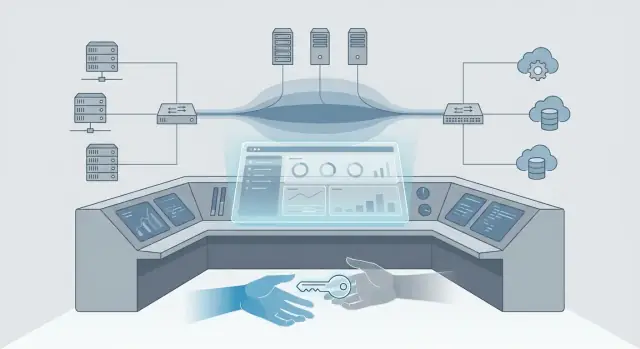
साधारण शब्दों में वर्चुअलाइजेशन एक तरीके है जिससे कई “वर्चुअल” सर्वर एक फ़िजिकल मशीन पर चल सकते हैं—एक बॉक्स कई सर्वरों जैसा सुरक्षित रूप से व्यवहार कर सकता है। एक कंट्रोल‑प्लेन उन टूल्स और नियमों का सेट है जो तय करते हैं कि सिस्टम में क्या कहाँ चलेगा, कौन इसे बदल सकता है, और कैसे मॉनिटर किया जाएगा। अगर वर्चुअलाइजेशन इंजन है, तो कंट्रोल‑प्लेन डैशबोर्ड, स्टीयरिंग व्हील और ट्रैफिक‑कानून है।
VMware ने केवल संगठनों को कम सर्वर खरीदने में मदद नहीं की। समय के साथ, vSphere और vCenter वह जगह बन गए जहाँ टीमें:
इसीलिए VMware सिर्फ "VMs चलाने" से परे मायने रखता है। कई बड़े उद्यमों में यह प्रभावी रूप से इन्फ्रास्ट्रक्चर की ऑपरेटिंग लेयर बन गया—वह बिंदु जहाँ निर्णय लागू होते और ऑडिट किए जाते हैं।
यह लेख देखेगा कि कैसे वर्चुअलाइजेशन एक एंटरप्राइज़ कंट्रोल‑प्लेन में बदल गया, वह पद क्यों रणनीतिक रूप से महत्वपूर्ण है, और मालिकाना हक और उत्पाद रणनीति बदलने पर आमतौर पर क्या बदलता है। हम संक्षेप में इतिहास देखेंगे, फिर IT टीमों पर व्यावहारिक प्रभावों पर ध्यान देंगे: संचालन, बजट सिग्नल, जोखिम, इकोसिस्टम निर्भरताएँ, और अगले 6–18 महीनों के भीतर वास्तविक विकल्प (ठहरना, विविधीकरण, या माइग्रेट)।
हम गोपनीय रोडमैप्स का अनुमान नहीं लगाएंगे और न ही विशिष्ट वाणिज्यिक चालों की भविष्यवाणी करेंगे। इसके बजाय, हम निरीक्षण योग्य पैटर्न पर ध्यान केंद्रित करेंगे: अधिग्रहण के बाद पहले क्या बदलाव अक्सर होते हैं (पैकेजिंग, लाइसेंसिंग, सपोर्ट मोशन्स), ये बदलाव रोज़मर्रा के संचालन को कैसे प्रभावित करते हैं, और अधूरी जानकारी के साथ निर्णय कैसे लें—बिना अटकने या overreact करने के।
वर्चुअलाइजेशन किसी भव्य "प्लैटफॉर्म" विचार के रूप में शुरू नहीं हुआ। यह एक व्यावहारिक समाधान के रूप में शुरू हुआ: बहुत सारे underused सर्वर, हार्डवेयर फैलाव, और उन–रात के आउटेज जहां एक एप्लिकेशन पूरे फिजिकल बॉक्स पर राज कर रहा था।
आदिम दिनों में पिच सीधी थी—एक फिजिकल होस्ट पर कई वर्कलोड चलाएँ और इतने सारे सर्वर खरीदना बंद करें। यह जल्दी ही एक ऑपरेशनल आदत में बदल गया।
एक बार वर्चुअलाइजेशन आम हो गया, सबसे बड़ा लाभ केवल "हमने हार्डवेयर पर पैसा बचाया" नहीं था। यह था कि टीमें हर जगह एक ही पैटर्न दोहरा सकती थीं।
हर लोकेशन के अलग सर्वर सेटअप के बजाय, वर्चुअलाइजेशन ने एक सुसंगत बेसलाइन को प्रोत्साहित किया: समान होस्ट बिल्ड्स, सामान्य टेम्पलेट्स, अनुमानित कैपेसिटी प्लानिंग, और पैचिंग व रिकवरी के साझा अभ्यास। यह संगति मायने रखती थी:
भले ही नीचे की हार्डवेयर अलग हो, ऑपरेशनल मॉडल ज्यादातर समान रह सकता था।
जैसे‑जैसे वातावरण बढ़े, गुरुत्वाकर्षण बिंदु व्यक्तिगत होस्ट्स से केंद्रीकृत प्रबंधन की ओर शिफ्ट हुआ। vCenter जैसे टूल केवल "वर्चुअलाइजेशन का प्रबंधन" नहीं करते—वे वह जगह बन गए जहाँ एडमिनिस्ट्रेटर्स रोज़मर्रा का काम करते हैं: एक्सेस कंट्रोल, इन्वेंटरी, अलार्म, क्लस्टर हेल्थ, रिसोर्स अलोकेशन, और सुरक्षित मेंटेनेंस विंडोज़।
कई संगठनों में, अगर कुछ मैनेजमेंट कंसोल में दिखाई नहीं देता था, तो वह व्यवहार में प्रबंधनीय नहीं माना जाता था।
एकल स्टैंडर्ड प्लेटफॉर्म कई बेस्ट‑ऑफ‑ब्रिड टूल्स के संग्रह से बेहतर प्रदर्शन कर सकता है जब आप रिपीटेबिलिटी को महत्व देते हैं। “हर जगह अच्छा” अक्सर मतलब होता है:
इसी तरह वर्चुअलाइजेशन एक लागत‑बचत टैक्टिक से मानक अभ्यास में बदल कर एंटरप्राइज़ कंट्रोल‑प्लेन बनने का मंच तैयार करता है।
वर्चुअलाइजेशन ने शुरू में अधिक वर्कलोड कम सर्वरों पर चलाने का तरीका दिया। पर एक बार जब अधिकांश एप्लिकेशन साझा वर्चुअल प्लेटफॉर्म पर आने लगे, तो “पहली क्लिक की जाने वाली जगह” वही जगह बन गई जहाँ निर्णय लागू होते हैं। इसी तरह एक हाइपरवाइज़र स्टैक एंटरप्राइज़ कंट्रोल‑प्लेन में विकसित होता है।
आईटी टीमें केवल "कंप्यूट" का प्रबंधन नहीं करतीं। रोज़ाना का संचालन फैलता है:
जब ये परतें एक कंसोल से ऑर्केस्ट्रेट होती हैं, वर्चुअलाइजेशन व्यवहारिक रूप से ऑपरेशन्स का केंद्र बन जाता है—भले ही नीचला हार्डवेयर विविध हो।
एक मुख्य बदलाव यह है कि provisioning नीति‑चालित हो जाता है। "सर्वर बनाओ" के बजाय टीमें गार्डरैइल्स परिभाषित करती हैं: अनुमोदित इमेज, साइजिंग लिमिट्स, नेटवर्क ज़ोन्स, बैकअप नियम, और अनुमतियाँ। अनुरोध मानकीकृत परिणामों में बदल जाते हैं।
इसीलिए vCenter जैसे प्लेटफॉर्म डेटा सेंटर के लिए ऑपरेटिंग सिस्टम की तरह काम करने लगते हैं: इसलिए नहीं कि वे आपके ऐप्स चलाते हैं, बल्कि इसलिए कि वे तय करते हैं कैसे ऐप्स बनाए जाते हैं, कहाँ रखे जाते हैं, कैसे सुरक्षित होते हैं, और कैसे बनाए रखे जाते हैं।
टेम्पलेट्स, गोल्डन इमेजेज और ऑटोमेशन पाइपलाइन्स धीरे‑धीरे व्यवहारों को लॉक कर देते हैं। एक बार टीमें VM टेम्पलेट, टैगिंग स्कीम, या पैचिंग और रिकवरी वर्कफ़्लो पर स्टैंडर्डाइज़ कर लेती हैं, यह पूरे विभागों में फैल जाता है। समय के साथ, प्लेटफॉर्म सिर्फ वर्कलोड होस्ट नहीं कर रहा होता—यह ऑपरेटिंग आदतों को embed कर रहा होता है।
जब एक कंसोल "सब कुछ" चलाता है, तो गुरुत्वाकर्षण सर्वर से गवर्नेंस की ओर बढ़ता है: अनुमोदन, अनुपालन साक्ष्य, कर्तव्यों का पृथक्करण, और चेंज कंट्रोल। इसलिए मालिकाना हक या रणनीति में बदलाव केवल प्राइसिंग को ही प्रभावित नहीं करते—वे यह बदलते हैं कि आईटी कैसे चलता है, कितनी तेज़ी से प्रतिक्रिया दे सकता है, और कितनी सुरक्षित रूप से बदलाव कर सकता है।
जब लोग VMware को "कंट्रोल‑प्लेन" कहते हैं, उनका मतलब यह नहीं कि यह केवल वही जगह है जहाँ वर्चुअल मशीनें चलती हैं। उनका मतलब यह है कि यह वह जगह है जहाँ दैनिक काम समन्वित होते हैं: कौन क्या कर सकता है, क्या बदलना सुरक्षित है, और समस्याएँ कैसे पता लगती और हल होती हैं।
अधिकांश आईटी प्रयास प्रारंभिक डिप्लॉयमेंट के बाद होता है। VMware वातावरण में कंट्रोल‑प्लेन वही जगह है जहाँ Day‑2 संचालन रहते हैं:
क्योंकि ये कार्य केंद्रीकृत हैं, टीमें इनके चारों ओर रिपीटेबल रनबुक बनाती हैं—चेंज विंडोज, अनुमोदन चरण, और "जानकारी में अच्छा" अनुक्रम।
समय के साथ, VMware ज्ञान ऑपरेशनल मसल‑मेमोरी बन जाता है: नामकरण मानक, क्लस्टर डिज़ाइन पैटर्न, और रिकवरी ड्रिल्स। इसे बदलना कठिन इसलिए है क्योंकि विकल्प मौजूद न होने के कारण नहीं, बल्कि संगति जोखिम घटाती है। एक नया प्लेटफॉर्म अक्सर किनारों के केसों को फिर से सीखने, रनबुक्स को लिखने, और दबाव में धारणाओं को पुनःमान्य करने का मतलब होता है।
एक आउटेज के दौरान, प्रतिक्रिया देने वाले कंट्रोल‑प्लेन पर निर्भर होते हैं:
यदि ये वर्कफ़्लोज़ बदलते हैं, तो mean time to recovery भी बदल सकता है।
वर्चुअलाइजेशन अकेला कम ही चलता है। बैकअप, मॉनिटरिंग, डिजास्टर रिकवरी, कॉन्फ़िगरेशन मैनेजमेंट और टिकटिंग सिस्टम vCenter और इसके APIs के साथ गहराई से जुड़े होते हैं। DR योजनाएँ विशिष्ट रेप्लिकेशन व्यवहार मान सकती हैं; बैकअप जॉब स्नैपशॉट्स पर निर्भर कर सकते हैं; मॉनिटरिंग टैग्स और फ़ोल्डर्स पर निर्भर कर सकती है। जब कंट्रोल‑प्लेन शिफ्ट होता है, ये इंटीग्रेशंस अक्सर पहले "सरप्राइज़" होते हैं जिन्हें आपको इन्वेंटरी और टेस्ट करना चाहिए।
जब VMware जैसी केंद्रीय प्लेटफॉर्म का मालिक बदलता है, तकनीक अचानक नहीं टूटती। जो सबसे पहले बदलता है वह अक्सर उसके चारों ओर का वाणिज्यिक आवरण होता है: आप इसे कैसे खरीदते हैं, कैसे रिन्यू करते हैं, और बजटिंग व सपोर्ट में "सामान्य" कैसे दिखता है।
कई टीमें अभी भी vSphere और vCenter से भारी ऑपरेशनल वैल्यू पाती हैं—स्टैंडर्डाइज्ड provisioning, सुसंगत संचालन, और परिचित टूलचेन। यह वैल्यू तब भी स्थिर रह सकती है जब कमर्शियल शर्तें तेज़ी से बदलें।
इनको दो अलग बातचीत की तरह सोचें:
नया मालिक अक्सर कैटलॉग को सरल बनाने, औसत अनुबंध मूल्य बढ़ाने, या ग्राहकों को कम बंडलों में शिफ्ट करने की प्राथमिकता देता है। इसका अनुवाद इन बदलावों में हो सकता है:
सबसे व्यावहारिक चिंताएँ अक्सर बोरिंग पर असल होती हैं: "अगले साल इसका क्या खर्च होगा?" और "क्या हमें मल्टी‑ईयर भविष्यवाणी मिल सकती है?" वित्त स्थिर पूर्वानुमान चाहता है; आईटी चाहता है कि रिन्यूअल उस परिवर्तन के लिए जल्दबाज़ी में स्थापत्य निर्णय करने पर मजबूर न करे।
संख्याओं पर बात करने से पहले एक साफ तथ्य‑आधार बनाइए:
इन सबके साथ, आप स्पष्टता से नेगोशिएट कर सकते हैं—चाहे आपकी योजना ठहरने, विविधीकरण करने, या माइग्रेशन पथ तैयार करने की ही क्यों न हो।
जब किसी प्लेटफॉर्म विक्रेता की रणनीति बदलती है, तो सबसे पहली चीज़ जो कई टीमें महसूस करती हैं वह नया फीचर नहीं—बल्कि खरीदने और योजना बनाने का नया तरीका होता है। VMware ग्राहकों के लिए Broadcom की दिशा‑निर्देश देखते समय, व्यावहारिक प्रभाव अक्सर बंडलों, रोडमैप प्राथमिकताओं, और किन उत्पादों पर सबसे अधिक ध्यान दिया जाता है में दिखता है।
बंड्लिंग वास्तव में सहायक हो सकती है: कम SKUs, कम "क्या हमने सही ऐड‑ऑन खरीदा?" बहसें, और टीमों में स्पष्ट स्टैंडर्डाइज़ेशन।
ट्रेड‑ऑफ लचीलापन है। अगर बंडल में वे घटक शामिल हैं जिनका आप उपयोग नहीं करते (या मानक बनाना नहीं चाहते), तो आपको शेल्फवेयर के लिए भुगतान करना पड़ सकता है या एक "वन साइज फिट्स मोस्ट" आर्किटेक्चर की ओर धकेला जा सकता है। बंडल्स यह भी कठिन बना सकते हैं कि वैकल्पिकों को धीरे‑धीरे पायलट किया जाए—क्योंकि आप अब केवल उस हिस्से को नहीं खरीद रहे जो आपको चाहिए।
उत्पाद रोडमैप उन ग्राहक सेगमेंट्स को प्राथमिकता देने की प्रवृत्ति रखते हैं जो सबसे अधिक राजस्व और रिन्यूअल ड्राइव करते हैं। इसका अर्थ हो सकता है:
यह कोई जरूरी रूप से बुरा नहीं है—पर यह बदल देता है कि आपको अपग्रेड और निर्भरताओं की योजना कैसे बनानी चाहिए।
अगर कुछ क्षमताएँ अप्राथमिकता प्राप्त करती हैं, टीमें अक्सर उस गैप को पॉइंट सोल्यूशंस (बैकअप, मॉनिटरिंग, सुरक्षा, ऑटोमेशन) से भरती हैं। यह तत्काल समस्याओं को हल कर सकता है पर दीर्घकालिक टूल स्प्रॉल बना सकता है: अधिक कंसोल, अधिक कॉन्ट्रैक्ट, अधिक इंटीग्रेशन्स बनाए रखने के लिए, और अधिक जगहों पर घटनाएँ छिप सकती हैं।
स्पष्ट प्रतिबद्धताओं और सीमाओं के लिए पूछें:
ये जवाब "रणनीति शिफ्ट" को बजट, स्टाफिंग, और जोखिम के लिए ठोस इनपुट में बदल देते हैं।
जब VMware को कंट्रोल‑प्लेन के रूप में माना जाता है, तो लाइसेंसिंग या पैकेजिंग परिवर्तन केवल procurement पर नहीं टिकते। यह बदल देता है कि काम IT में कैसे बहते हैं: कौन परिवर्तन मंजूर कर सकता है, कितनी तेज़ी से वातावरण प्रदान किए जा सकते हैं, और टीमों के बीच "स्टैंडर्ड" का क्या मतलब है।
प्लेटफ़ॉर्म एडमिन अक्सर प्रथम‑कक्षा प्रभाव महसूस करते हैं। अगर एंटाइटिलमेंट्स कम बंडलों में सरल किए जाते हैं, तो रोज़मर्रा का संचालन कम लचीला हो सकता है: आपको किसी फीचर का उपयोग करने से पहले आंतरिक अनुमोदन चाहिए जो पहले “बस वहाँ” था, या आपको कम कॉन्फ़िगरेशन पर स्टैंडर्डाइज़ करना पड़ सकता है।
यह उन जगहों पर अधिक एडमिन वर्कलोड के रूप में दिखता है जिन्हें लोग हमेशा नहीं देखते—प्रोजेक्ट शुरू होने से पहले लाइसेंस चेक, अपग्रेड्स सिंक्रोनाइज़ करने के लिए टैटेड चेंज विंडोज, और पैचिंग व कॉन्फ़िगरेशन ड्रिफ्ट के बारे में सुरक्षा व ऐप टीमों के साथ अधिक समन्वय।
एप टीमों का मालिकाना प्रदर्शन और अपटाइम पर मापा जाता है, पर प्लेटफॉर्म शिफ्ट उन नींव‑मान्यताओं को बदल सकता है। अगर क्लस्टर्स को रीबैलेंस किया गया, होस्ट काउंट बदला गया, या नई एंटाइटिलमेंट्स के अनुरूप फीचर उपयोग समायोजित किया गया, तो एप्लिकेशन ओनर्स को संगतता फिर से परीक्षण करनी पड़ सकती है और परफॉर्मेंस को री‑बेसलाइन करना पड़ सकता है।
यह विशेष रूप से सच है उन वर्कलोड्स के लिए जो विशिष्ट स्टोरेज, नेटवर्किंग, या HA/DR व्यवहार पर निर्भर करते हैं। व्यावहारिक परिणाम: अधिक संरचित परीक्षण चक्र और परिवर्तन अनुमोदन से पहले "इस ऐप को क्या चाहिए" का स्पष्ट दस्तावेज।
अगर वर्चुअलाइजेशन परत आपका प्रवर्तन‑बिंदु है segmentation, privileged access और ऑडिट ट्रेल्स के लिए, किसी भी टूलिंग या स्टैंडर्ड कॉन्फ़िगरेशन में बदलाव अनुपालन को प्रभावित करता है।
सिक्योरिटी टीमें कड़े कर्तव्यों के पृथक्करण (कौन vCenter ऑपरेशन्स में क्या बदल सकता है), सुसंगत लॉग रिटेंशन, और कम "एक्सेप्शन" कॉन्फ़िगरेशन चाहेंगी। IT टीमों को अधिक औपचारिक एक्सेस समीक्षाओं और चेंज रिकॉर्ड की उम्मीद करनी चाहिए।
भले ही ट्रिगर लागत हो, प्रभाव ऑपरेशनल ही होता है: चार्जबैक/शोबैक मॉडल अपडेट करने पड़ सकते हैं, कॉस्ट सेंटर्स यह फिर से तय कर सकते हैं कि क्या "शामिल" माना जाता है, और पूर्वानुमान प्लेटफ़ॉर्म टीमों के साथ सहयोग बन जाता है।
एक अच्छा संकेत कि आप वर्चुअलाइजेशन को कंट्रोल‑प्लेन की तरह व्यवहार कर रहे हैं वह है जब IT और फाइनेंस साथ मिलकर योजना बनाते हैं, बजाय कि रिन्यूअल के बाद आश्चर्य का सामना करने के।
जब VMware जैसे प्लेटफॉर्म का मालिकाना हक और रणनीति बदलती है, सबसे बड़े जोखिम अक्सर आईटी के "शांत" हिस्सों में दिखाई देते हैं: कंटीन्यूटी योजनाएँ, सपोर्ट अपेक्षाएँ, और दिन‑प्रतिदिन की ऑपरेशनल सुरक्षा। भले ही कुछ तुरंत न टूटे, उन धारणाओं में बदलाव आ सकता है जिन पर आप दशकों से भरोसा करते हैं।
एक बड़ा प्लेटफॉर्म शिफ्ट बैकअप, DR और रिटेंशन में सूक्ष्म तरीकों से असर डाल सकता है। बैकअप उत्पाद विशिष्ट APIs, vCenter अनुमतियाँ, या स्नैपशॉट व्यवहार पर निर्भर कर सकते हैं। DR रनबुक्स अक्सर कुछ क्लस्टर फीचर्स, नेटवर्किंग डिफॉल्ट और ऑर्केस्ट्रेशन स्टेप्स मानती हैं। रिटेंशन योजनाएँ भी प्रभावित हो सकती हैं अगर स्टोरेज इंटीग्रेशन या आर्काइव वर्कफ़्लोज़ बदलते हैं।
कार्रवाईयोग्य takeaway: केवल बैकअप सक्सेस की जाँच नहीं बल्कि उन सिस्टम्स के लिए end‑to‑end restore प्रक्रियाओं को वैलिडेट करें जो सबसे महत्वपूर्ण हैं—tier‑0 identity, मैनेजमेंट टूलिंग, और मुख्य बिजनेस ऐप्स।
सामान्य जोखिम क्षेत्र अधिकतर संविदात्मक नहीं बल्कि ऑपरेशनल होते हैं:
व्यावहारिक जोखिम "अनजान अनजानों" से होने वाला डाउनटाइम है, सिर्फ़ अधिक लागत नहीं।
जब एक प्लेटफॉर्म प्रभुत्व रखता है, आप स्टैंडर्डाइज़ेशन, छोटे कौशल फुटप्रिंट, और सुसंगत टूलिंग पाते हैं। ट्रेड‑ऑफ निर्भरता है: अगर लाइसेंसिंग, सपोर्ट, या उत्पाद फोकस बदलता है तो बचने के रास्ते कम होते हैं। निर्भरता जोखिम तब सबसे अधिक होता है जब VMware न केवल वर्कलोड्स को आधार देता है बल्कि आइडेंटिटी, बैकअप, लॉगिंग और ऑटोमेशन भी उसका आधार हों।
आप जो भी दिशा अगली हो, ऑपरेशनल जोखिम कम करने के लिए क्या कर सकते हैं: आप जो वास्तव में चलाते हैं उसका दस्तावेज़ीकरण (वर्ज़न्स, निर्भरता, और इंटीग्रेशन पॉइंट्स), vCenter/admin रोल्स के लिए एक्सेस समीक्षाएँ कड़ी करें, और एक परीक्षण तालिका बनाएँ: तिमाहीवार restore टेस्ट, अर्धवार्षिक DR अभ्यास, और एक प्री‑अपग्रेड वैलिडेशन चेकलिस्ट जिसमें हार्डवेयर संगतता और तृतीय‑पक्ष विक्रेता पुष्टियाँ शामिल हों।
ये कदम किसी भी रणनीति‑पथ के लिए ऑपरेशनल जोखिम घटाते हैं।
VMware शायद अकेला कम ही चलता है। अधिकांश वातावरण हार्डवेयर विक्रेताओं, MSPs, बैकअप प्लेटफॉर्म, मॉनिटरिंग टूल्स, सिक्योरिटी एजेंट्स, और DR सर्विसेज़ के जाल पर निर्भर करते हैं। जब मालिकाना हक और उत्पाद रणनीति बदलती है, "ब्लास्ट रेडियस" अक्सर सबसे पहले इस इकोसिस्टम में दिखाई देता है—कभी‑कभी इससे पहले कि आप vCenter के अंदर कुछ नोटिस करें।
हार्डवेयर विक्रेता, MSPs, और ISVs अपने समर्थन को विशिष्ट वर्ज़न्स, एडिशंस, और डिप्लॉयमेंट पैटर्न के अनुसार जोड़ते हैं। उनकी सर्टिफिकेशन्स और सपोर्ट मैट्रिस निर्धारित करते हैं कि वे क्या ट्रबलशूट करेंगे—और क्या नहीं।
एक लाइसेंसिंग या पैकेजिंग परिवर्तन अप्रत्यक्ष रूप से अपग्रेड को बाध्य कर सकता है (या रोक सकता है), जो फिर प्रभावित करता है कि आपका सर्वर मॉडल, HBA, NIC, स्टोरेज एरे, या बैकअप प्रॉक्सी सपोर्ट लिस्ट में रहता है या नहीं।
कई थर्ड‑पार्टी टूल्स ने ऐतिहासिक रूप से "per socket", "per host", या "per VM" जैसी धारणाओं के आसपास प्राइस/पैकेज किया है। अगर प्लेटफॉर्म की कमर्शियल मॉडल बदलती है, तो वे टूल्स उपयोग को कैसे गिनते हैं, किन फीचर्स के लिए ऐड‑ऑन चाहिए, या किन इंटीग्रेशन्स को शामिल किया जाता है—ये बदल सकते हैं।
सपोर्ट अपेक्षाएँ भी बदल सकती हैं। उदाहरण के लिए, कोई ISV विशिष्ट API पहुँच, प्लगइन संगतता, या न्यूनतम vSphere/vCenter वर्ज़न की मांग कर सकता है ताकि इंटीग्रेशन सपोर्ट करे। समय के साथ, "पहले काम करता था" बन सकता है "यह काम करता है, पर केवल इन वर्ज़न्स और इन टीयर्स पर"।
कंटेनर और Kubernetes अक्सर VM स्प्रॉल पर दबाव कम करते हैं, पर वे कई एंटरप्राइज़ में वर्चुअलाइजेशन की ज़रूरत खत्म नहीं करते। टीमें आमतौर पर Kubernetes को VMs पर चलाती हैं, वर्चुअल नेटवर्किंग और स्टोरेज नीतियों पर निर्भर करती हैं, और मौजूदा बैकअप और DR पैटर्न का उपयोग करती हैं।
इसका मतलब है कि कंटेनर टूलिंग और वर्चुअलाइजेशन परत के बीच इंटरऑपरेबिलिटी अभी भी मायने रखती है—खासकर आइडेंटिटी, नेटवर्किंग, स्टोरेज और ऑब्ज़र्वेबिलिटी के संदर्भ में।
"ठहरना, विविधीकरण, या माइग्रेट" के लिए कमिट करने से पहले उन इंटीग्रेशन्स की सूची बनाइए जिन पर आप निर्भर हैं: बैकअप, DR, मॉनिटरिंग, CMDB, वल्नरेबिलिटी स्कैनिंग, MFA/SSO, नेटवर्क/सिक्योरिटी ओवरले, स्टोरेज प्लगइन्स, और MSP रनबुक्स।
फिर तीन बातों को वैलिडेट करें: आज क्या सपोर्ट है, अगले अपग्रेड पर क्या सपोर्ट रहेगा, और पैकेजिंग/लाइसेंसिंग में बदलाव किस तरीके से deployment या management को अप्रसादित कर देगा।
एक बार वर्चुअलाइजेशन आपका दिन‑प्रतिदिन कंट्रोल‑प्लेन बन जाए, इसे सिर्फ़ "प्लेटफॉर्म स्वैप" नहीं कहा जा सकता। अधिकांश संगठन चार रास्तों में से एक पर जाते हैं—कभी‑कभी संयोजन में।
रहना "कुछ नहीं करना" जैसा नहीं है। आमतौर पर इसका मतलब है इन्वेंटरी कसी हुई बनाना, क्लस्टर डिज़ाइनों को स्टैंडर्ड करना, और आकस्मिक स्प्रॉल हटाना ताकि आप वही भुगतान कर रहे हों जो आप वाकई चला रहे हैं।
अगर आपका प्राथमिक लक्ष्य लागत नियंत्रण है, तो होस्ट्स को राइट‑साइज़ करके, अंडरयूज़्ड क्लस्टर्स घटाकर, और जिन फीचर्स की आपको वाकई ज़रूरत है उन्हें सत्यापित करके शुरू करें। अगर लक्ष्य रेज़िलिएन्स है, तो ऑपरेशनल हाइजीन पर ध्यान दें: पैच कैडेंस, बैकअप टेस्टिंग, और दस्तावेजीकृत रिकवरी कदम।
ऑप्टिमाइज़ेशन सबसे सामान्य निकट‑मियादी कदम है क्योंकि यह जोखिम घटाता है और समय खरीदता है। सामान्य कार्रवाइयाँ हैं: प्रबंधन डोमेन्स का कंसोलिडेशन, टेम्पलेट्स/स्नैपशॉट्स की सफ़ाई, और स्टोरेज/नेटवर्क मानकों को संरेखित करना ताकि भविष्य की माइग्रेशन्स कम दर्दनाक हों।
विविधीकरण तब सबसे अच्छा काम करता है जब आप बिना पूरे रिफ्रेम के किसी सुरक्षित जोन में दूसरे स्टैक को पेश करें। सामान्य उपयुक्तताएँ:
लक्ष्य आमतौर पर वेंडर विविधीकरण या चपलता है, न कि तत्काल प्रतिस्थापन।
"माइग्रेट" का मतलब VMs स्थानांतरित करने से अधिक है। पूरे बंडल की योजना बनाइए: वर्कलोड्स, नेटवर्किंग (VLANs, राउटिंग, फ़ायरवॉल, लोड‑बैलेंसर्स), स्टोरेज (डेटास्टोर्स, रेप्लिकेशन), बैकअप, मॉनिटरिंग, आइडेंटिटी/एक्सेस, और—अक्सर कम आँका गया—कौशल और ऑपरेटिंग प्रक्रियाएँ।
शुरुआत में स्पष्ट लक्ष्य निर्धारित करें: क्या आप कीमत, डिलीवरी की गति, जोखिम में कमी, या रणनीतिक लचीलापन के लिए अनुकूल कर रहे हैं? स्पष्ट प्राथमिकताएँ माइग्रेशन को अनंत पुनर्निर्माण बनने से रोकती हैं।
अगर VMware आपका ऑपरेशनल कंट्रोल‑प्लेन है, तो VMware/Broadcom रणनीति‑शिफ्ट के बारे में निर्णय vendor प्रेस‑रिलीज़ से शुरू नहीं होने चाहिए—वे आपके वातावरण से शुरू होने चाहिए। अगले 6–18 महीनों में लक्ष्य यह होना चाहिए कि धारणाओं को मापने‑योग्य तथ्यों से बदलें, फिर जोखिम और ऑपरेशनल फिट के आधार पर रास्ता चुनें।
एक ऐसी इन्वेंटरी बनाइए जिस पर आपकी ऑपरेशन्स टीम किसी घटना के दौरान भरोसा कर सके, न कि procurement के लिए बनाई गई स्प्रेडशीट।
यह इन्वेंटरी समझ का आधार होगी कि vCenter ऑपरेशन्स वास्तव में क्या सक्षम करते हैं—और क्या कहीं और reproduce करना कठिन होगा।
vSphere लाइसेंसिंग या वैकल्पिक प्लेटफॉर्म पर बहस करने से पहले अपना बेसलाइन मात्रित करें और स्पष्ट वेस्ट निकालें।
ध्यान दें:
राइट‑साइज़िंग तुरंत वर्चुअलाइजेशन लागत घटा सकता है और किसी भी माइग्रेशन की योजना को अधिक सटीक बनाता है।
अपने निर्णय मानदंड लिखें और उन्हें वज़न दें। सामान्य श्रेणियाँ:
एक प्रतिनिधि वर्कलोड चुनें (सबसे आसान न चुनें) और इस प्रकार पायलट चलाएँ:
पायलट को Day‑2 ऑपरेशन्स के लिए एक रिहर्सल मानिए—न कि सिर्फ माइग्रेशन डेमो।
वास्तविक वातावरणों में, कंट्रोल‑प्लेन का बड़ा हिस्सा उसके चारों ओर के छोटे सिस्टम होते हैं: इन्वेंटरी ट्रैकर्स, रिन्यूअल डैशबोर्ड, एक्सेस रिव्यू वर्कफ़्लोज़, रनबुक चेकलिस्ट, और चेंज‑विंडो समन्वय।
यदि आपको वह टूलिंग जल्दी बनानी या आधुनिक बनानी है, तो एक ऐसा प्लेटफ़ॉर्म जैसे Koder.ai टीमों को चैट इंटरफ़ेस के माध्यम से हल्के इंटरनल वेब ऐप्स बनाने में मदद कर सकता है (योजना मोड, स्नैपशॉट/रोलबैक, और सोर्स कोड एक्सपोर्ट के साथ)। उदाहरण के लिए, आप एक vCenter इंटीग्रेशन इन्वेंटरी ऐप या एक रिन्यूअल रेडीनेस डैशबोर्ड प्रोटोटाइप कर सकते हैं (React फ्रंट‑एंड, Go + PostgreSQL बैक‑एंड), इसे कस्टम डोमेन पर होस्ट करें, और ज़रूरतों के बदलने के साथ जल्दी iterate करें—बिना पूर्ण डेवलपमेंट साइकल के इंतजार के।
आपको एक "प्लेटफ़ॉर्म स्ट्रैटजी" पूरी करने की ज़रूरत नहीं है ताकि प्रगति कर सकें। इस सप्ताह का लक्ष्य अनिश्चितता कम करना है: अपनी तारीखें जानें, कवरेज जानें, और जानें कि निर्णय आते समय किन्हें कमरे में होना चाहिए।
मीटिंग में दिखाने के लिए तथ्यों से शुरू करें।
मालिकाना हक और लाइसेंसिंग शिफ्ट अलग‑अलग टीमों के लिए आश्चर्य पैदा कर सकते हैं।
एक छोटा वर्किंग ग्रुप लाएं: प्लेटफ़ॉर्म/वर्चुअलाइजेशन, सिक्योरिटी, ऐप ओनर्स, और फाइनेंस/प्रोक्योरमेंट। सहमत हों:
"जोखिम और लागत का अनुमान लगाने के लिए पर्याप्त" उद्देश्य रखिए—न कि एक परफेक्ट इन्वेंटरी।
इसे एक एक‑बार का कार्यक्रम न समझें—इसे एक लगातार प्रबंधन चक्र बनाइए।
तिमाहीवार समीक्षा करें: विक्रेता रोडमैप/लाइसेंसिंग अपडेट्स, रन‑रेट लागत बनाम बजट, और ऑपरेशनल KPIs (घटनाओं की मात्रा, पैच अनुपालन, रिकवरी टेस्ट परिणाम)। परिणामों को अपने अगले रिन्यूअल और माइग्रेशन योजना नोट्स में जोड़ें।
एक हाइपरवाइजर VMs चलाता है। एक कंट्रोल‑प्लेन वह निर्णय और गवर्नेंस लेयर है जो तय करता है:
कई एंटरप्राइज़ में, vCenter वह “पहली जगह” बन जाता है जिस पर लोग क्लिक करते हैं—इसीलिए यह सिर्फ वर्चुअलाइज़ेशन टूल नहीं, बल्कि कंट्रोल‑प्लेन की तरह काम करता है।
क्योंकि ऑपरेशनल वैल्यू स्टैंडर्डाइज़ेशन और रिपीटेबिलिटी में केंद्रित हो जाती है, न कि सिर्फ कंसोलिडेशन में। vSphere/vCenter अक्सर सामान्य इंटरफ़ेस बन जाते हैं जहाँ से आप:
एक बार ये आदतें जड़ पकड़ लेती हैं, प्लेटफॉर्म बदलना दिन‑2 के ऑपरेशंस को उतना ही प्रभावित करता है जितना ये VMs कहाँ चलते हैं।
Day‑2 संचालन वे नियमित कार्य हैं जो प्रारंभिक डिप्लॉयमेंट के बाद कैलेंडर भरते हैं। VMware‑केंद्रित वातावरण में यह आमतौर पर शामिल है:
यदि आपके रनबुक इन वर्कफ़्लोज़ पर निर्भर हैं, तो मैनेजमेंट लेयर प्रभावी रूप से आपके ऑपरेशनल सिस्टम का हिस्सा बन जाती है।
वे चीज़ें जो आमतौर पर असफल होती हैं जब मान्यताओं में बदलाव आता है। सामान्य छिपी निर्भरताएँ:
इन्हें जल्दी इन्वेंटरी करें और अपग्रेड या पायलट्स के दौरान टेस्ट करें, न कि केवल नवीनीकरण के बाद जब समय सीमा ज़बरदस्ती आ जाए।
आम तौर पर पहले बदलने वाला हिस्सा तकनीक नहीं, बल्कि कमर्शियल रैपर होता है: आप कैसे खरीदते हैं, रिन्यू करते हैं, और बजटिंग/सपोर्ट सामने कैसे दिखते हैं। टीमें अक्सर सबसे पहले इन बदलावों को महसूस करती हैं:
उत्पाद वैल्यू को ऑपरेशनल रूप से बरकरार रखना और व्यावसायिक अनिश्चितता को संविदात्मक रूप से कम करना—दो अलग ट्रैक की तरह सोचें।
संख्या के लिए तथ्यात्मक आधार बनाइए ताकि procurement बातचीत अनुमान पर न चले:
इससे आप स्पष्टता के साथ बातचीत कर सकते हैं और विकल्पों का वास्तविक दायरा समझकर मूल्यांकन कर पाएँगे।
यह रिकवरी धीमी कर सकता है और जोखिम बढ़ा सकता है क्योंकि रिस्पॉन्डर कंट्रोल‑प्लेन पर निर्भर होते हैं:
यदि टूलिंग, रोल या वर्कफ़्लोज़ बदलते हैं, तो MTTR बनाए रखने के लिए की योजना बनाएं।
बंडल्स हमेशा बुरे नहीं होते। वे खरीद को सरल बना सकते हैं और डिप्लॉयमेंट्स को स्टैंडर्डाइज़ कर सकते हैं, पर ज़रूरी ट्रेड‑ऑफ़ होते हैं:
प्रैक्टिकल कदम: प्रत्येक बंडल्ड कंपोनेंट को वास्तविक ऑपरेशनल ज़रूरत से मैप करें (या उसे अपनाने की स्पष्ट योजना) इससे पहले कि आप इसे "नया स्टैंडर्ड" मान लें।
अनिश्चितता घटाने और समय खरीदने से शुरू करें:
ये कदम आप रुके रहें, विविधता अपनाएँ या माइग्रेट करें—किसी भी रास्ते पर जोखिम कम करते हैं।
निम्नलिखित नियंत्रणों के साथ एक नियंत्रित पायलट चलाएँ जो केवल माइग्रेशन मैकेनिक्स नहीं, बल्कि ऑपरेशन्स को भी आजमाए:
पायलट को Day‑2 ऑपरेशन्स (patching, मॉनिटरिंग, बैकअप, एक्सेस कंट्रोल) के लिए एक रिहर्सल की तरह ट्रीट करें—एक‑ऑफ़ डेमो नहीं।