12 जून 2025·8 मिनट
यूज़र स्टोरीज़ से डेटाबेस स्कीमा तक: एक AI-निर्देशित विधि
यूज़र स्टोरीज़, एंटिटीज़ और वर्कफ़्लो को साफ़ डेटाबेस स्कीमा में बदलने की व्यवहारिक विधि सीखें — और कैसे AI reasoning गैप्स और नियमों की जाँच में मदद कर सकता है।
यूज़र स्टोरीज़, एंटिटीज़ और वर्कफ़्लो को साफ़ डेटाबेस स्कीमा में बदलने की व्यवहारिक विधि सीखें — और कैसे AI reasoning गैप्स और नियमों की जाँच में मदद कर सकता है।
एक डेटाबेस स्कीमा आपके ऐप के याद रखने के तरीके की योजना है। व्यवहारिक रूप से यह है:
Order एक Customer से जुड़ा होता है; एक Customer के कई Orders हो सकते हैं)जब स्कीमा असली काम से मेल खाता है, तो वह वही दर्शाता है जो लोग वास्तव में करते हैं—create, review, approve, schedule, assign, cancel—बजाय इसके कि बस whiteboard पर सुंदर लगे।
यूज़र स्टोरीज़ और एक्सेप्टेंस क्राइटेरिया सामान्य भाषा में असली ज़रूरतें बताते हैं: कौन क्या करता है, और “done” का क्या मतलब है। अगर आप इन्हें स्रोत मानें, तो स्कीमा महत्वपूर्ण विवरण चूकेगा कम (जैसे “हमें यह ट्रैक करना है कि किसने refund approve किया” या “एक booking कई बार reschedule हो सकती है”)।
स्टोरीज़ से शुरू करने से आपको स्कोप के प्रति ईमानदार भी रखा जाता है। अगर कोई चीज़ स्टोरीज़ (या वर्कफ़्लो) में नहीं है, तो उसे ऑप्शनल मानें बजाय कि चुपचाप जटिल मॉडल बना लें “बस क्या पता काम आ जाए” के कारण।
AI आपको तेज़ी से आगे बढ़ाने में मदद कर सकता है:
AI भरोसेमंद तरीके से नहीं कर सकता:
AI को एक मजबूत सहायक मानें, निर्णय-निर्माता नहीं।
अगर आप उस सहायक को momentum में बदलना चाहते हैं, तो एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai आपको स्कीमा निर्णयों से React + Go + PostgreSQL ऐप बनाने में तेज़ कर सकता है—फिर भी आपको मॉडल, constraints, और migrations पर नियंत्रण रखने देता है।
स्कीमा डिज़ाइन एक लूप है: draft → stories के खिलाफ टेस्ट → गायब डेटा खोजें → refine. लक्ष्य परफेक्ट पहले आउटपुट नहीं है; बल्कि एक ऐसा मॉडल है जिसे आप हर यूज़र स्टोरी तक ट्रेस कर सकें और निश्चिंत होकर कह सकें: “हाँ, हम इस वर्कफ़्लो की हर ज़रूरत स्टोर कर सकते हैं—और बता सकते हैं कि हर टेबल क्यों मौजूद है।”
टेबल्स में आवश्यकता डालने से पहले यह स्पष्ट करें कि आप क्या मॉडल कर रहे हैं। एक अच्छा स्कीमा शायद खाली पन्ने से नहीं शुरू होता—यह उन ठोस कामों से शुरू होता है जो लोग करते हैं और जिस सबूत की बाद में ज़रूरत होगी (screens, outputs, और edge cases)।
यूज़र स्टोरीज़ मुख्य हेडलाइन हैं, लेकिन अकेले काफी नहीं। इकट्ठा करें:
अगर आप AI का उपयोग कर रहे हैं, ये इनपुट मॉडल को grounded रखते हैं। AI जल्दी से entities और fields प्रस्ताव कर सकता है, पर उसे असली आर्टिफैक्ट्स चाहिये ताकि वह ऐसी संरचना न बना दे जो आपके प्रोडक्ट से मेल न खाती हो।
अक्सर एक्सेप्टेंस क्राइटेरिया सबसे महत्वपूर्ण डेटाबेस नियम रखते हैं, भले ही वे स्पष्ट रूप से डेटा का उल्लेख न करें। इन बातों पर ध्यान दें:
अस्पष्ट स्टोरीज़ (“As a user, I can manage projects”) कई एंटिटी और वर्कफ़्लो छुपाती हैं। एक और सामान्य गैप है एज केस मिसिंग होना जैसे cancellations, retries, partial refunds, या reassignment।
टेबल या डायग्राम के बारे में सोचने से पहले, यूज़र स्टोरीज़ पढ़ें और nouns को हाइलाइट करें। requirements लेखन में, संज्ञाएँ अक्सर उन “चीजों” की ओर इशारा करती हैं जिन्हें आपका सिस्टम याद रखेगा—ये अक्सर आपकी स्कीमा में entities बनती हैं।
एक तेज मानसिक मॉडल: nouns → entities, जबकि verbs → actions/workflows. अगर स्टोरी कहती है “A manager assigns a technician to a job,” तो संभावित entities हैं manager, technician, और job—और “assigns” एक रिलेशनशिप का संकेत है जिसे आप बाद में मॉडल करेंगे।
हर noun को टेबल बनाने की ज़रूरत नहीं होती। कोई noun मजबूत एंटिटी का उम्मीदवार है जब:
अगर कोई noun केवल एक बार दिखता है, या सिर्फ किसी और चीज़ का वर्णन करता है (“red button”, “Friday”), तो वह शायद entity नहीं है।
हर डिटेल को टेबल में बदलना एक आम गलती है। यह नियम अपनाएँ:
Customer.phone_number).दो क्लासिक उदाहरण:
AI स्टोरीज़ स्कैन करके candidate nouns की ड्राफ्ट लिस्ट दे कर entity खोज में तेज़ी ला सकता है और उन्हें थीम के अनुसार ग्रुप कर सकता है (people, work items, documents, locations)। उपयोगी प्रॉम्प्ट: “ऐसी संज्ञाएँ निकालें जिन्हें हमें स्टोर करना चाहिए, और डुप्लिकेट/सिनोनिम्स ग्रुप करें।”
आउटपुट को शुरुआत मानें, उत्तर नहीं। फॉलो-अप पूछें:
Step 1 का लक्ष्य एक छोटा, साफ़ सूची है जिसे आप असली स्टोरीज़ से defend कर सकें।
एक बार जब आपने entities (जैसे Order, Customer, Ticket) नामित कर लिए, अगला काम है उन डिटेल्स को पकड़ना जो बाद में चाहिए होंगे। डेटाबेस में ये fields (या attributes) होते हैं—वे reminders जो आपका सिस्टम भूलने का खतरनाक नहीं ले सकता।
स्टोरीज़ से शुरू करें, फिर एक्सेप्टेंस क्राइटेरिया को चेकलिस्ट की तरह पढ़ें कि क्या स्टोर करना अनिवार्य है।
अगर requirement कहती है “Users can filter orders by delivery date,” तो delivery_date अनिवार्य है—यह फ़ील्ड के रूप में मौजूद होना चाहिए (या किसी भरोसेमंद तरीके से अन्य स्टोर किए गए डेटा से निकाला जा सके)। अगर कहा है “Show who approved the request and when,” तो आपको संभवतः approved_by और approved_at चाहिए।
एक व्यावहारिक टेस्ट: क्या कोई इसे display, search, sort, audit, या calculate करने के लिए चाहिएगा? अगर हाँ, तो शायद यह फ़ील्ड होना चाहिए।
कई स्टोरीज़ में शब्द आते हैं जैसे “status,” “type,” या “priority.” इन्हें controlled vocabularies के रूप में ट्रीट करें—एक सीमित सेट ऑफ़ allowed values।
अगर सेट छोटा और स्थिर है, तो एक सरल enum-शैली फ़ील्ड काम कर सकता है। अगर यह बढ़ सकता है, लेबल्स चाहिए, या permissions की ज़रूरत है (उदा., admin-managed categories), तो अलग lookup टेबल (उदा., status_codes) और एक reference स्टोर करें।
इसी तरह स्टोरीज़ फ़ील्ड्स बन कर भरोसेमंद, searchable, reportable, और गलत दर्ज होने से बचने वाले बनती हैं।
एक बार जब आपने entities (User, Order, Invoice, Comment, आदि) और उनके फ़ील्ड्स ड्राफ्ट कर लिए, अगला कदम है उन्हें जोड़ना। रिलेशनशिप्स वे “कैसे ये चीज़ें इंटरैक्ट करती हैं” लेयर हैं जो आपकी स्टोरीज़ से निहित होती हैं।
One-to-one (1:1) मतलब “एक चीज़ की ठीक एक दूसरी चीज़ होती है.”
User ↔ Profile (अक्सर इन्हें merge किया जा सकता है जब अलग रखने का कारण नहीं हो)।One-to-many (1:N) मतलब “एक चीज़ के कई दूसरे चीज़ हो सकते हैं.” यह सबसे आम है।
User → Order (Order पर user_id रखें).Many-to-many (M:N) मतलब “कई चीज़ें कई चीज़ों से जुड़ सकती हैं.” इसके लिए एक अतिरिक्त टेबल चाहिए।
डेटाबेस में Order के अंदर “product IDs की सूची” रखना बाद में समस्याएँ लाता है (सर्च, अपडेट, रिपोर्टिंग)। इसके बजाय एक join table बनाएं जो रिलेशनशिप को स्वयं दर्शाए।
उदाहरण:
OrderProductOrderItem (join table)OrderItem आमतौर पर शामिल करता है:
order_idproduct_idquantity, unit_price, discountध्यान दें कि अक्सर स्टोरी का डिटेल (जैसे “quantity”) रिलेशनशिप पर होना चाहिए, न कि किसी एक एंटिटी पर।
स्टोरीज़ यह भी बताती हैं कि कोई कनेक्शन अनिवार्य है या कभी-कभी गैप्ड.
Order को user_id चाहिए (खाली न रहने दें).phone खाली रह सकता है।shipping_address_id डिजिटल orders के लिए खाली हो सकता है।तेज़ जाँच: अगर स्टोरी बताती है कि आप रिकॉर्ड बनाए बग़ैर लिंक नहीं कर सकते, तो इसे required मानें। अगर स्टोरी में “can”, “may”, या exceptions हैं, तो optional मानें।
जब आप कोई स्टोरी पढ़ें, उसे एक जोड़ीदार वाक्य में फिर से लिखें:
User 1:N CommentComment N:1 Userहर इंटरैक्शन के लिए यह करें। अंत तक, आपके पास एक जुड़ा हुआ मॉडल होगा जो वर्क के तरीके को दर्शाता है—उससे पहले कि आप कभी ER डायग्राम टूल खोलें।
यूज़र स्टोरीज़ बताती हैं क्या चाहिए। वर्कफ़्लो दिखाते हैं काम वास्तव में कैसे आगे बढ़ता है, कदम-दर-कदम। एक वर्कफ़्लो को डेटा में ट्रांसलेट करने से आप जल्दी पाते हैं कि “हमने यह स्टोर करना भूल दिया”—पहले ही।
वर्कफ़्लो को एक्शन और स्टेट चेंज के क्रम के रूप में लिखें। उदाहरण:
वे बोल्ड शब्द अक्सर status फ़ील्ड बन जाते हैं (या एक छोटी “state” टेबल), जिनके allowed values स्पष्ट होते हैं।
हर स्टेप के दौरान पूछें: “बाद में हमें क्या जानना होगा?” वर्कफ़्लोज़ आमतौर पर ऐसे फ़ील्ड्स दिखाते हैं:
submitted_at, approved_at, completed_atcreated_by, assigned_to, approved_byrejection_reason, approval_notesequenceअगर वर्कफ़्लो में waiting, escalation, या handoffs हैं, तो आमतौर पर कम से कम एक timestamp और एक “किसके पास अब है” फ़ील्ड चाहिए।
कुछ वर्कफ़्लो स्टेप्स सिर्फ फ़ील्ड नहीं होते—वे अलग डेटा संरचनाएँ होते हैं:
AI को दोनों दें: (1) यूज़र स्टोरीज़ और एक्सेप्टेंस क्राइटेरिया, और (2) वर्कफ़्लो स्टेप्स। उससे कहें कि वह हर स्टेप सूचीबद्ध करे और हर स्टेप के लिए आवश्यक डेटा (state, actor, timestamps, outputs) बताए, फिर उन किसी भी requirements को हाइलाइट करे जिन्हें मौजूदा फ़ील्ड्स/टेबल्स समर्थन नहीं करते।
Koder.ai जैसे प्लेटफ़ॉर्म पर यह “gap check” खासकर व्यावहारिक हो जाता है क्योंकि आप जल्दी इटरेट कर सकते हैं: स्कीमा मान्यताएँ बदलें, scaffolding regenerate करें, और बिना लंबी मैन्युअल boilerplate के आगे बढ़ें।
जब आप यूज़र स्टोरीज़ को टेबल्स में बदलते हैं, तो आप सिर्फ फ़ील्ड्स सूचीबद्ध नहीं कर रहे—आप यह भी तय कर रहे हैं कि डेटा समय के साथ कैसे पहचाना और consistent रहेगा।
एक primary key एक रिकॉर्ड को यूनिकली पहचानती है—इसे आप रो का स्थायी पहचान पत्र समझें।
क्यों हर रो को चाहिए: स्टोरीज़ अपडेट्स, रिफरेंसेस, और इतिहास बताती हैं। अगर स्टोरी कहती है “Support can view an order and issue a refund,” तो आपको ऑर्डर को एक स्थिर तरीके से प्वाइंट करने की ज़रूरत है—भले ही कस्टमर का email बदले, address edit हो, या order status बदल जाए।
व्यवहार में, यह आमतौर पर एक internal id होता है (नंबर या UUID) जो कभी नहीं बदलता।
एक foreign key एक टेबल को सुरक्षित तरीके से दूसरी टेबल की ओर इशारा करने देती है। अगर orders.customer_id customers.id को reference करता है, तो डेटाबेस सुनिश्चित कर सकता है कि हर order असली customer से जुड़ा है।
यह उन स्टोरीज़ से मेल खाता है जैसे “As a user, I can see my invoices.” Invoice तैरती नहीं होती; वह किसी customer (और अक्सर किसी order या subscription) से जुड़ी होती है।
यूज़र स्टोरीज़ अक्सर छिपे यूनिकनेस requirements रखती हैं:
invoice_number.ये नियम बाद में confusing duplicates को रोकते हैं जो महीनों बाद "data bugs" बन जाते हैं।
Indexes उन सर्चेज़ को तेज़ करते हैं जैसे “customer by email ढूँढो” या “list orders by customer.” सबसे आम क्वेरीज और uniqueness नियमों के अनुरूप indexes से शुरू करें।
क्या बाद में टालें: दुर्लभ रिपोर्ट्स या अनुमानित फ़िल्टर्स के लिए भारी इंडेक्सिंग। उन ज़रूरतों को स्टोरीज़ में कैप्चर करें, स्कीमा सत्यापित करें, फिर रीयल उपयोग और slow-query सबूत के आधार पर optimize करें।
नॉर्मलाइज़ेशन का एक सरल लक्ष्य है: conflicting duplicates रोकना। अगर वही तथ्य दो जगह सेव हो सकता है, तो अंततः वे असहमति में बदलेंगे (दो वर्तनी, दो कीमतें, दो “current” addresses)। एक normalized स्कीमा हर तथ्य को एक बार स्टोर करता है, फिर उसे reference करता है।
1) repeated groups देखें
अगर आप देखते हैं “Phone1, Phone2, Phone3” या “ItemA, ItemB, ItemC,” तो यह अलग टेबल (जैसे CustomerPhones, OrderItems) का संकेत है। repeated groups खोज, validation, और scale को कठिन बनाते हैं।
2) एक ही नाम/विवरण कई टेबल्स में कॉपी न करें
अगर CustomerName Orders, Invoices, और Shipments में है, तो आपने कई sources of truth बना दिए हैं। ग्राहक विवरण Customers में रखें और सिर्फ customer_id अन्य जगहों पर रखें।
3) एक ही चीज़ के लिए कई कॉलम से बचें
billing_address, shipping_address, home_address जैसे कॉलम ठीक हैं अगर वे वास्तव में अलग अवधारणाएँ हैं। पर अगर आप असल में “विभिन्न प्रकार के कई पते” मॉडल कर रहे हैं, तो Addresses टेबल और एक type फ़ील्ड का उपयोग करें।
4) lookups को free text से अलग रखें
अगर यूज़र किसी ज्ञात सेट से चुनते हैं (status, category, role), तो इसे सुसंगत रूप से मॉडल करें: या तो constrained enum या lookup table। इससे “Pending” vs “pending” vs “PENDING” जैसी असंगतियाँ नहीं होंगी।
5) जाँचें कि हर non-ID फ़ील्ड सही चीज़ पर निर्भर है
एक मददगार गट-चेक: किसी टेबल में अगर एक कॉलम उस टेबल की मुख्य एंटिटी के अलावा किसी और चीज़ का वर्णन करता है, तो वह शायद कहीं और होना चाहिए। उदाहरण: Orders में product_price तब तक नहीं होना चाहिए जब तक इसका मतलब “order के समय की कीमत” (historic snapshot) न हो।
कभी-कभी आप जानबूझकर duplicates स्टोर करते हैं:
कुंजी यह है कि यह जानबूझकर हो: दस्तावेज़ करें कौन सा फ़ील्ड source of truth है और कॉपी कैसे अपडेट होते हैं।
AI suspicious duplication (repeated columns, समान field नाम, inconsistent “status” fields) फ्लैग कर सकता है और टेबल्स में विभाजन सुझा सकता है। इंसान फिर trade-off—सादगी बनाम फ्लेक्सिबिलिटी बनाम प्रदर्शन—उसके आधार पर निर्णय लेता है कि प्रॉडक्ट कैसे उपयोग होगा।
एक उपयोगी नियम: वह तथ्य स्टोर करें जिसे आप भरोसेमंद तरीके से बाद में दोबारा नहीं बना पाएँ; बाकी सब कुछ कैलकुलेट करें।
स्टोर किया हुआ डेटा स्रोत सच्चाई है: individual line items, timestamps, status changes, किसने क्या किया। Calculated (derived) डेटा उन तथ्यों से निकाला जाता है: totals, counters, flags जैसे “is overdue”, और rollups।
अगर दो मान एक ही बेसिक facts से निकाले जा सकते हैं, तो facts स्टोर करें और बाकी कैलकुलेट करें। वरना आप विरोधाभास का जोखिम उठाते हैं।
Derived मान उनके inputs बदलने पर बदलते हैं। अगर आप inputs और derived result दोनों स्टोर करते हैं, तो आपको हर वर्कफ़्लो और एज केस (edits, refunds, partial shipments, backdated changes) के लिए उन्हें sync रखना होगा। एक missed update और database दो अलग बताने लगेगा।
उदाहरण: order_total स्टोर करना जबकि order_items भी स्टोर हैं। अगर कोई quantity बदले या discount लागू हो और total सही तरीके से अपडेट न हो, तो finance एक नंबर देखेगा और cart दूसरा।
वर्कफ़्लो बताते हैं कि आपको कब historical truth चाहिए, सिर्फ “current truth” नहीं। अगर यूज़र को यह जानना ज़रूरी है कि किसी समय मूल्य क्या था, तो snapshot स्टोर करें।
एक order के लिए आप स्टोर कर सकते हैं:
order_total checkout पर (snapshot), क्योंकि taxes, discounts, और pricing rules बाद में बदल सकते हैंइन्वेंटरी के लिए, "inventory level" अक्सर movements (receipts, sales, adjustments) से निकाला जाता है। लेकिन अगर audit trail चाहिए तो movements स्टोर करें और रिपोर्टिंग स्पीड के लिए periodic snapshots रखें।
लॉगिन ट्रैकिंग के लिए, last_login_at एक ईवेंट timestamp के रूप में स्टोर करें। “Is active in the last 30 days?” कैलकुलेट रहता है।
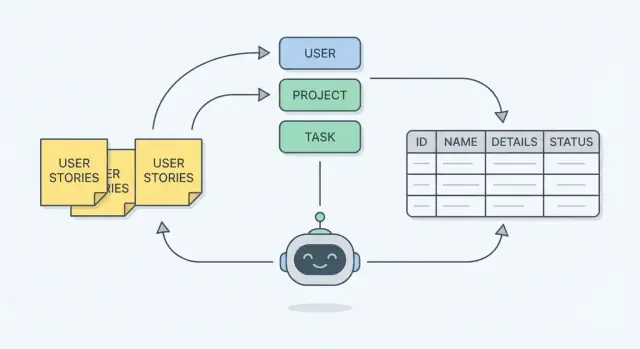
आइए एक परिचित support ticket ऐप लें। हम पांच यूज़र स्टोरीज़ से शुरू करेंगे और एक साधारण ER मॉडल बनाएँगे (entities + fields + relationships), फिर उसे एक वर्कफ़्लो के खिलाफ चेक करेंगे।
इन nouns से हमें मुख्य एंटिटीज़ मिलती हैं:
Ticket.category_id → Category.idTicket.requester_id → User.id (customer)Ticket.assignee_id → User.id (agent, nullable)Message.ticket_id → Ticket.idMessage.author_id → User.idTicket (status = “open”, created_at), insert TicketEvent(type = "created").Message या update Ticket.assignee_id, और insert TicketEvent(type = "assigned"/"replied", updated_at).Ticket.status = "closed", set closed_at, insert TicketEvent(type = "closed", actor_id = closer).Before (सामान्य गलती): Ticket में assignee_id है, पर हमने यह सुनिश्चित नहीं किया कि केवल agents ही assignee हो सकते हैं।
After: AI इसे फ्लैग करता है और आप एक व्यावहारिक नियम जोड़ते हैं: assignee User का role = "agent" होना चाहिए (इसे application validation या database constraint/policy के माध्यम से लागू करें)। इससे भविष्य में “कस्टमर को assign कर दिया” जैसी गलतियाँ रोकी जा सकती हैं।
एक स्कीमा तभी “done” माना जा सकता है जब हर यूज़र स्टोरी का जवाब ऐसा डेटा देकर दिया जा सके जिसे आप विश्वसनीय रूप से स्टोर और क्वेरी कर सकें। सबसे सरल सत्यापन कदम यह है कि हर स्टोरी उठाएँ और पूछें: “क्या हम इस प्रश्न का डेटाबेस से हर केस के लिए विश्वसनीय उत्तर दे सकते हैं?” अगर जवाब “शायद” है, तो मॉडल में गैप है।
हर यूज़र स्टोरी को एक या अधिक टेस्ट प्रश्नों के रूप में फिर से लिखें—ऐसी चीज़ें जो आप रिपोर्ट, स्क्रीन, या API से पूछना चाहेंगे। उदाहरण:
अगर आप किसी स्टोरी को स्पष्ट प्रश्न के रूप में व्यक्त नहीं कर सकते, तो स्टोरी अस्पष्ट है। अगर आप व्यक्त कर सकते हैं—पर अपने स्कीमा से इसका उत्तर नहीं दे पा रहे—तो आप किसी फ़ील्ड, रिलेशनशिप, स्टेट/इवेंट, या constraint की कमी में हैं।
एक छोटा dataset बनाएँ (प्रति मुख्य टेबल 5–20 रो) जिसमें सामान्य और awkward केस (duplicates, missing values, cancellations) शामिल हों। फिर उस डेटा से स्टोरीज़ को “प्ले थ्रू” करें। आप जल्दी ही समस्याएँ देख लेंगे जैसे “हम यह बता नहीं पा रहे कि किस address का उपयोग खरीद के समय हुआ” या “कहाँ स्टोर करें कि किसने change approve किया।”
AI से कहें कि वह प्रति स्टोरी validation प्रश्न जेनरेट करे (edge cases और deletion scenarios सहित), और बताए कि उन प्रश्नों के उत्तर के लिए कौन सा डेटा जरूरी होगा। उस सूची की तुलना अपने स्कीमा से करें: कोई भी mismatch एक ठोस एक्शन आइटम है।
AI डेटा मॉडलिंग में तेज़ी ला सकता है, पर यह संवेदनशील जानकारी लीक करने या गलत मान्यताएँ hard-code करने का जोखिम भी बढ़ा देता है। इसे एक बहुत तेज सहायक मानें: उपयोगी, पर गार्डरैल्स के साथ।
ऐसे इनपुट साझा करें जो मॉडलिंग के लिए यथार्थवादी हों, पर सुरक्षित भी:
invoice_total: 129.50, status: "paid")बचें उन चीज़ों से जो किसी व्यक्ति की पहचान या गोपनीय ऑपरेशंस का खुलासा कर सकें:
अगर आपको यथार्थवादी डेटाची चाहिए, तो synthetic samples जनरेट करें जो फॉर्मैट और रेंज मिलते हों—प्रोडक्शन रोस की प्रतिलिपि कभी न करें।
सबसे अधिक बार स्कीमा इसलिए फेल होते हैं क्योंकि “सबने अलग अंदाज़ में माना”। अपने ER मॉडल के पास (या उसी repo में) एक छोटा निर्णय-लॉग रखें:
यह AI आउटपुट को टीम ज्ञान बनाता है बजाय कि एक-बार का artifact।
आपका स्कीमा नई स्टोरीज़ के साथ विकसित होगा। इसे सुरक्षित रखने के तरीके:
अगर आप Koder.ai जैसे प्लेटफ़ॉर्म का उपयोग कर रहे हैं, snapshots और rollback जैसे गार्डरैल्स का उपयोग करें जब स्कीमा बदलाव इटरेट कर रहे हों, और ज़रूरत पड़े तो स्रोत कोड export कर लें।
स्टोरीज़ से शुरू करें और उन संज्ञाओं (nouns) को हाइलाइट करें जो सिस्टम को याद रखना चाहिए (जैसे Ticket, User, Category).
एक संज्ञा को एंटिटी बनाएं जब:
id चाहिएछोटी, कट्टर-सूची रखें जिसे आप किसी खास स्टोरी वाक्य से साबित कर सकें।
“Attribute vs entity” टेस्ट का इस्तेमाल करें:
customer.phone_number).एक तेज संकेत: अगर आपको कभी “इनका कई होना” चाहिए, तो शायद आपको अलग टेबल चाहिए।
एक्सेप्टेंस क्राइटेरिया को स्टोरेज चेकलिस्ट की तरह देखें. अगर किसी चीज़ को फिल्टर/सॉर्ट/डिस्प्ले/ऑडिट करना कहा गया है, तो उसे स्टोर करना होगा (या भरोसेमंद तरीके से निकाला जा सके)।
उदाहरण:
approved_by, approved_atdelivery_dateस्टोरी वाक्यों को रिलेशनशिप वाक्यों में लिखें:
orders पर customer_id रखें)order_items जोड़ें)अगर रिलेशनशिप पर खुद डेटा है (quantity, price, role), तो वह डेटा join टेबल पर होना चाहिए।
M:N को एक join टेबल से मॉडल करें जो दोनों foreign keys और रिलेशनशिप-विशिष्ट फ़ील्ड स्टोर करे.
साँचा आमतौर पर:
ordersproductsवर्कफ़्लो को कदम-दर-कदम पढ़ें और पूछें: “बाद में इसे साबित करने के लिए हमें क्या जानने की ज़रूरत होगी?”
आम जोड़ियाँ:
submitted_at, closed_atपहले जोड़ें:
id)orders.customer_id → customers.id)फिर उन सबसे आम lookups के लिए indexes जोड़ें (उदा., , , ). संभावित स्पेकुलेटिव इंडेक्सिंग बाद में करें जब रीयल क्वेरी पैटर्न दिखें।
एक तेज consistency चेक चलाएँ:
Phone1/Phone2 जैसी repeated groups देखते हैं, तो child टेबल पर जाएँ।परफॉर्मेंस, रिपोर्टिंग या audit snapshots जैसी स्पष्ट वजहों के बिना पहले से ज्यादा normalization मत हटाइए।
जो तथ्य आप बाद में भरोसेमंद तरीके से दोबारा नहीं बना पाएंगे, उन्हें स्टोर करें; बाकी सब कुछ निकालें।
अच्छा स्टोर करने योग्य:
अच्छा कैलकुलेट करने योग्य:
अगर आप derived values (जैसे ) स्टोर करते हैं, तो तय करें कि कैसे यह sync रहेगा और एज केस टेस्ट करें (refunds, edits)।
AI को ड्राफ्ट्स के लिए इस्तेमाल करें, फिर अपने आर्टिफैक्ट्स के खिलाफ सत्यापित करें।
प्रैक्टिकल प्रॉम्प्ट्स:
गार्डरैल्स:
email पर unique constraint/indexorder_items जिसमें order_id, product_id, quantity, unit_priceएक ही कॉलम में “IDs की सूची” न रखें—क्वेरी करना, अपडेट करना और इंटीग्रिटी लागू करना मुश्किल हो जाता है।
created_by, assigned_to, closed_byrejection_reasonअगर आपको यह जानना है कि “किसने कब स्टेटस बदला,” तो एक event/audit टेबल जोड़ें बजाय एक फ़ील्ड को ओवरराइट करने के।
emailcustomer_idstatus + created_atorder_total