21 ago 2025·8 min
6 JOIN SQL che devi conoscere (con esempi semplici e chiari)
Impara i 6 JOIN SQL che ogni analista dovrebbe conoscere — INNER, LEFT, RIGHT, FULL OUTER, CROSS e SELF — con esempi pratici e errori comuni.
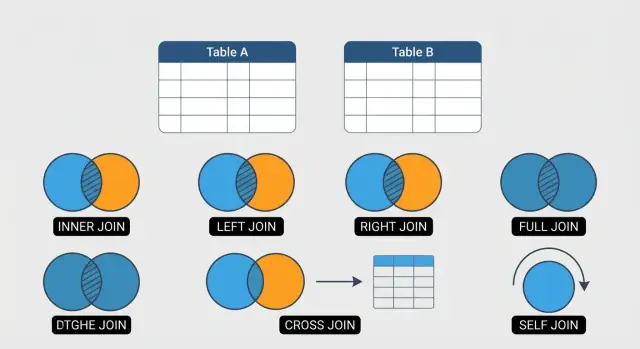
Cosa sono i JOIN in SQL e perché li usi
Un JOIN SQL ti permette di combinare le righe di due (o più) tabelle in un unico risultato facendo corrispondere una colonna correlata — di solito un ID.
Perché i JOIN sono importanti
La maggior parte dei database reali è volutamente divisa in tabelle separate per evitare di ripetere le stesse informazioni. Per esempio, il nome di un cliente sta nella tabella customers, mentre i suoi acquisti stanno nella tabella orders. I JOIN sono il modo per ricollegare quei pezzi quando ti servono risposte.
Per questo i JOIN compaiono ovunque in reporting e analisi:
- Costruire un report di vendite che includa nomi clienti, totali ordini e stato del pagamento
- Trovare clienti che non hanno ancora effettuato ordini
- Controllare discrepanze, come ordini senza pagamenti
- Creare riepiloghi “una riga per cliente” a partire da molte righe correlate
Senza i JOIN saresti bloccato a eseguire query separate e combinare i risultati manualmente — lento, soggetto a errori e difficile da ripetere.
Se stai costruendo prodotti sopra un database relazionale (dashboard, pannelli admin, tool interni, portali clienti), i JOIN sono anche ciò che trasforma le “tabelle grezze” in viste utilizzabili. Piattaforme come Koder.ai (che genera app React + Go + PostgreSQL da chat) continuano a fare affidamento sui fondamenti dei JOIN quando ti servono pagine di elenco accurate, report e schermate di riconciliazione — perché la logica del database non scompare, anche quando lo sviluppo è più veloce.
I 6 tipi di JOIN che userai di più
Questa guida si concentra su sei JOIN che coprono la maggior parte del lavoro SQL quotidiano:
- INNER JOIN: restituisce solo le righe che corrispondono in entrambe le tabelle (ottimo per “mostrami relazioni confermate”).
- LEFT JOIN: conserva ogni riga dalla tabella di sinistra e abbina quello che può dalla destra (ottimo per “includi i dati correlati mancanti”).
- RIGHT JOIN: lo specchio del LEFT JOIN (meno comune, ma utile a seconda dello stile di query o della leggibilità).
- FULL OUTER JOIN: conserva tutte le righe da entrambe le tabelle, abbinate quando possibile (ideale per riconciliazioni e per trovare gap).
- CROSS JOIN: produce tutte le combinazioni di righe (utile per generare calendari, scenari o dati di test — facile da usare male).
- SELF JOIN: unisci una tabella a se stessa (comodo per gerarchie come dipendenti/manager).
Una breve nota sulla sintassi
La sintassi dei JOIN è molto simile nella maggior parte dei database SQL (PostgreSQL, MySQL, SQL Server, SQLite). Ci sono alcune differenze — specialmente sul supporto di FULL OUTER JOIN e su alcuni comportamenti nei casi limite — ma i concetti e i pattern principali si trasferiscono facilmente.
Le tabelle d'esempio che useremo (Customers, Orders, Payments)
Per mantenere semplici gli esempi di JOIN, useremo tre piccole tabelle che rispecchiano una configurazione reale comune: i clienti fanno ordini e gli ordini possono (o no) avere pagamenti.
Una piccola nota prima di iniziare: le tabelle di esempio qui sotto mostrano solo poche colonne, ma alcune query successive fanno riferimento a campi aggiuntivi (come order_date, created_at, status o paid_at) per dimostrare pattern comuni. Tratta quelle colonne come campi “tipici” che troveresti spesso in schemi di produzione.
1) customers
Chiave primaria: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
2) orders
Chiave primaria: order_id
Chiave esterna: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Nota che order_id = 104 fa riferimento a customer_id = 5, che non esiste in customers. Questa “corrispondenza mancante” è utile per vedere il comportamento di LEFT JOIN, RIGHT JOIN e FULL OUTER JOIN.
3) payments
Chiave primaria: payment_id
Chiave esterna: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Due dettagli didattici importanti qui:
order_id = 102ha due righe di pagamento (pagamento diviso). Quando unisciordersconpayments, quell'ordine comparirà due volte — qui è dove i duplicati spesso sorprendono.payment_id = 9004fa riferimento aorder_id = 999, che non esiste inorders. Questo crea un altro caso “non corrispondente”.
Cosa aspettarsi quando uniamo queste tabelle
- Righe corrispondenti: per esempio, cliente 1 ↔ ordini 101/102; ordine 101 ↔ pagamento 9001.
- Righe non corrispondenti: per esempio, i clienti 3 e 4 non hanno ordini; l'ordine 104 non ha cliente; il pagamento 9004 non appartiene a nessun ordine.
- Duplicati: unendo
ordersapaymentsl'ordine 102 verrà ripetuto perché ha due pagamenti correlati.
INNER JOIN: conserva solo le righe che corrispondono
Un INNER JOIN restituisce solo le righe in cui esiste una corrispondenza in entrambe le tabelle. Se un cliente non ha ordini, non apparirà nel risultato. Se un ordine fa riferimento a un cliente inesistente (dati errati), anche quell'ordine non apparirà.
Lo schema di base
Scegli una tabella “sinistra”, fai il join con la tabella “destra” e collegale con una condizione nella clausola ON.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
L'idea chiave è la riga ON o.customer_id = c.customer_id: dice a SQL come le righe sono correlate.
Caso d'uso reale: clienti che hanno effettuato ordini
Se vuoi una lista solo dei clienti che hanno effettivamente fatto almeno un ordine (e i dettagli dell'ordine), INNER JOIN è la scelta naturale:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Questo è utile per cose come “invia una email di follow-up per l'ordine” o “calcola il fatturato per cliente” (quando ti interessano solo i clienti con acquisti).
Errore comune: condizioni di join mancanti o poco chiare
Se scrivi un join ma dimentichi la condizione ON (o fai il join sulle colonne sbagliate), puoi creare accidentalmente un prodotto cartesiano (ogni cliente combinato con ogni ordine) o produrre corrispondenze errate.
Da non fare:
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Assicurati sempre di avere una condizione di join chiara in ON (o USING nei casi specifici in cui si applica — trattato più avanti).
LEFT JOIN: conserva tutto dalla tabella di sinistra
Un LEFT JOIN restituisce tutte le righe dalla tabella di sinistra, aggiungendo i dati della tabella destra quando esiste una corrispondenza. Se non c'è corrispondenza, le colonne della destra saranno NULL.
Quando usarlo
Usa un LEFT JOIN quando vuoi una lista completa dalla tua tabella principale, più i dati correlati opzionali.
Esempio: “Mostrami tutti i clienti, e includi i loro ordini se ne hanno.”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
- I clienti con ordini appariranno con i dettagli degli ordini.
- I clienti senza ordini appariranno comunque, ma
o.order_id(e altre colonne diorders) sarannoNULL.
Trovare le righe “senza corrispondenza” (pattern classico)
Un motivo molto comune per usare LEFT JOIN è trovare elementi che non hanno record correlati.
Esempio: “Quali clienti non hanno mai effettuato un ordine?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Quella condizione WHERE ... IS NULL mantiene solo le righe della tabella sinistra dove il join non ha trovato corrispondenza.
Attenzione: più corrispondenze moltiplicano le righe
Il LEFT JOIN può “duplicare” le righe della tabella sinistra quando ci sono più righe corrispondenti a destra.
Se un cliente ha 3 ordini, quel cliente apparirà 3 volte — una per ogni ordine. È previsto, ma può sorprendere se stai cercando di contare clienti.
Ad esempio, questo conta gli ordini (non i clienti):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Se il tuo obiettivo è contare i clienti, di solito conterai la chiave cliente (spesso con COUNT(DISTINCT c.customer_id)), a seconda di cosa stai misurando.
RIGHT JOIN: conserva tutto dalla tabella di destra
Un RIGHT JOIN conserva tutte le righe dalla tabella di destra, e solo le righe corrispondenti dalla sinistra. Se non c'è corrispondenza, le colonne della sinistra saranno NULL. È essenzialmente l'immagine speculare di un LEFT JOIN.
Un esempio semplice
Usando le tabelle di esempio, immagina che tu voglia elencare tutti i pagamenti, anche quelli che non si possono collegare a un ordine (forse l'ordine è stato cancellato o i dati dei pagamenti sono sporchi).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Cosa ottieni:
- Tutti i pagamenti sono inclusi (perché
paymentsè a destra). - Se un pagamento non ha ordine corrispondente, allora
o.order_ideo.customer_idsarannoNULL.
La stessa query come LEFT JOIN (spesso preferita)
La maggior parte delle volte puoi riscrivere un RIGHT JOIN come LEFT JOIN invertendo l'ordine delle tabelle:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Questo restituisce lo stesso risultato, ma molti trovano più leggibile: inizi con la tabella “principale” che ti interessa (qui, payments) e poi opzionalmente prendi i dati correlati.
Leggibilità: perché molte squadre evitano RIGHT JOIN
Molte linee guida di stile SQL scoraggiano RIGHT JOIN perché costringe il lettore a invertire mentalmente il pattern comune:
- “Comincia con la tabella principale”
- “LEFT JOIN sulle tabelle aggiuntive”
Quando le relazioni opzionali sono scritte coerentemente come LEFT JOIN, le query diventano più facili da scorrere.
Quando RIGHT JOIN può essere comodo
Un RIGHT JOIN può essere utile quando stai modificando una query esistente e ti rendi conto che la tabella “da conservare” è attualmente a destra. Invece di riscrivere tutta la query (soprattutto se è lunga con molti join), cambiare un join in RIGHT JOIN può essere una modifica rapida e a basso rischio.
FULL OUTER JOIN: conserva tutte le righe di entrambe le tabelle
Practice JOINs in an app
Build a PostgreSQL-backed app and apply your JOIN logic in a real UI.
Un FULL OUTER JOIN restituisce tutte le righe di entrambe le tabelle.
- Se una riga corrisponde sulla chiave di join, ottieni una singola riga combinata (come
INNER JOIN). - Se una riga esiste solo nella tabella sinistra, apparirà comunque — con
NULLper le colonne della destra. - Se una riga esiste solo nella tabella destra, apparirà comunque — con
NULLper le colonne della sinistra.
Quando è utile
Un caso d'uso classico è la riconciliazione ordini vs. pagamenti:
- Vuoi vedere ordini pagati (corrispondenze)
- ordini non pagati (ordine esiste, pagamento mancante)
- pagamenti “sconnessi” (il pagamento esiste ma non c'è ordine — errore dati, rimborso, riferimento sbagliato, ecc.)
Esempio:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
Supporto nei database (chi può eseguirlo direttamente)
FULL OUTER JOIN è supportato in PostgreSQL, SQL Server e Oracle.
Non è disponibile in MySQL e SQLite (servirà una soluzione alternativa).
Alternativa portabile: UNION di LEFT JOIN e RIGHT JOIN
Se il tuo database non supporta FULL OUTER JOIN, puoi simularlo combinando:
- tutte le righe di
orders(con i pagamenti quando disponibili), e - tutte le righe di
paymentsche non hanno corrispondenza inorders.
Un pattern comune:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Suggerimento: quando vedi NULL da un lato, è il segnale che la riga era “mancante” nell'altra tabella — esattamente quello che vuoi per audit e riconciliazioni.
CROSS JOIN: crea tutte le combinazioni (usa con cautela)
Un CROSS JOIN restituisce ogni possibile abbinamento di righe tra due tabelle. Se la tabella A ha 3 righe e la tabella B ne ha 4, il risultato avrà 3 × 4 = 12 righe. Questo è anche chiamato prodotto cartesiano.
Sembra spaventoso — e può esserlo — ma è davvero utile quando vuoi generare combinazioni.
Un esempio piccolo e sicuro: taglie × colori (creare SKU)
Immagina di mantenere le opzioni prodotto in tabelle separate:
sizes: S, M, Lcolors: Red, Blue
Un CROSS JOIN può generare tutte le varianti possibili (utile per creare SKU, pre-costruire un catalogo o testare):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Risultato (3 × 2 = 6 righe):
- S / Red
- S / Blue
- M / Red
- M / Blue
- L / Red
- L / Blue
Grande avvertimento: i risultati crescono in fretta
Poiché il numero di righe si moltiplica, il CROSS JOIN può esplodere rapidamente:
- 10.000 clienti × 50 prodotti = 500.000 righe
- 100.000 × 100.000 = 10.000.000.000 righe
Questo può rallentare le query, esaurire la memoria e produrre output inutilizzabile. Se hai bisogno di combinazioni, mantieni le tabelle di input piccole e considera limiti o filtri controllati.
SELF JOIN: unire una tabella con sé stessa
Design tables the JOIN-friendly way
Map customers, orders, and payments clearly before you write a single query.
Un SELF JOIN è esattamente quello che sembra: unisci una tabella a se stessa. È utile quando una riga in una tabella è correlata a un'altra riga nella stessa tabella — più comunemente in relazioni padre/figlio come dipendenti e i loro manager.
Perché servono gli alias (e come aiutano)
Poiché stai usando la stessa tabella due volte, devi dare a ciascuna “copia” un alias diverso. Gli alias rendono la query leggibile e dicono a SQL a quale lato ti riferisci.
Un pattern comune è:
eper l'impiegatomper il manager
Esempio pratico: dipendenti e i loro manager
Immagina una tabella employees come questa:
idnamemanager_id(punta all'iddi un altro dipendente)
Per elencare ogni dipendente con il nome del proprio manager:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Gestire i top-level (manager_id NULL)
Nota che la query usa un LEFT JOIN, non un INNER JOIN. Questo è importante perché alcuni dipendenti potrebbero non avere un manager (ad esempio, il CEO). In quei casi, manager_id è spesso NULL, e un LEFT JOIN conserva la riga del dipendente mostrando manager_name come NULL.
Se avessi usato un INNER JOIN, quei dipendenti top-level scomparirebbero dai risultati perché non esiste una riga manager corrispondente.
Condizioni di join: ON vs USING (e perché conta)
Un JOIN non “sa” magicamente come due tabelle sono correlate — devi dirglielo. Quella relazione si definisce nella condizione di join, e appartiene accanto al JOIN perché spiega come le tabelle si abbinano, non come vuoi filtrare il risultato finale.
ON: il più flessibile (e il più comune)
Usa ON quando vuoi pieno controllo sulla logica di matching — colonne con nomi diversi, condizioni multiple o regole extra.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON è anche dove puoi definire abbinamenti più complessi (per esempio, su due colonne) senza trasformare la query in un gioco di indovinelli.
USING: più corto, ma solo per colonne con lo stesso nome
Alcuni database (come PostgreSQL e MySQL) supportano USING. È una scorciatoia comoda quando entrambe le tabelle hanno una colonna con lo stesso nome e vuoi fare il join su quella colonna.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Un vantaggio: USING tipicamente restituisce una sola colonna customer_id nell'output (invece di due copie).
Evita nomi di colonna ambigui: qualifica sempre nei join
Dopo aver fatto join, i nomi delle colonne spesso si sovrappongono (id, created_at, status). Se scrivi SELECT id, il database potrebbe restituire un errore di “colonna ambigua” — o peggio, potresti leggere l'id sbagliato.
Preferisci i prefissi di tabella (o alias) per chiarezza:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
Evita SELECT * nelle query con join
SELECT * diventa rapidamente disordinato con i join: importi colonne non necessarie, rischi nomi duplicati e rendi più difficile capire cosa intende produrre la query.
Meglio selezionare esattamente le colonne necessarie. Il risultato è più pulito, più manutenibile e spesso più efficiente — specialmente quando le tabelle sono larghe.
Filtrare i dati uniti: WHERE vs ON
Quando unisci le tabelle, WHERE e ON entrambi “filtrano”, ma lo fanno in momenti diversi.
- ON decide quali righe corrispondono durante il join.
- WHERE filtra il risultato finale dopo che il join è stato formato.
Questa differenza di tempistica è la ragione per cui le persone trasformano accidentalmente un LEFT JOIN in un INNER JOIN.
Come WHERE può rompere accidentalmente un LEFT JOIN
Supponi di voler avere tutti i clienti, anche quelli senza ordini recenti pagati.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date \u003e= DATE '2025-01-01';
Problema: per i clienti senza ordini corrispondenti, o.status e o.order_date sono NULL. La clausola WHERE rifiuta quelle righe, quindi i clienti non corrispondenti scompaiono — il tuo LEFT JOIN si comporta come un INNER JOIN.
Sposta le condizioni legate al join in ON per mantenere le righe non corrispondenti
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date \u003e= DATE '2025-01-01';
Ora i clienti senza ordini qualificanti compaiono comunque (con colonne order a NULL), che è di solito l'obiettivo di un LEFT JOIN.
Checklist rapida: cosa mettere in ON vs WHERE?
- Metti le condizioni in ON quando descrivono quali righe della tabella destra possono corrispondere (filtri su status/data/tipo della tabella joinata).
- Metti le condizioni in WHERE quando descrivono quali righe finali vuoi mantenere (filtri sulla tabella sinistra, o quando richiedi intenzionalmente una corrispondenza).
- Se vuoi “mantenere tutte le righe di sinistra ma limitare quelle di destra”, preferisci LEFT JOIN + condizioni in ON.
- Se realmente intendi “solo righe con corrispondenza”, usa INNER JOIN (o
WHERE o.order_id IS NOT NULLesplicitamente).
Evitare righe duplicate e sorprese many-to-many
Own your generated code
Take the source code with you when your JOIN-heavy logic needs custom changes.
I join non solo “aggiungono colonne” — possono anche moltiplicare le righe. Questo è spesso il comportamento corretto, ma sorprende quando i totali raddoppiano (o peggio).
Perché le righe si moltiplicano
Un join restituisce una riga di output per ogni coppia di righe corrispondenti.
- One-to-many: Un cliente può avere molti ordini. Se unisci
customersconorders, ogni cliente può apparire più volte — una per ogni ordine. - Many-to-many (la vera trappola): Se unisci
ordersconpaymentse ogni ordine può avere più pagamenti (rate, retry, rimborsi parziali), puoi ottenere più righe per ordine. Se poi unisci anche con un'altra tabella “many” (comeorder_items), puoi creare un effetto moltiplicatore:payments × itemsper ordine.
Aggrega prima di unire
Se il tuo obiettivo è “una riga per ordine” o “una riga per cliente”, riassumi prima il lato “many”, poi fai il join.
-- Una riga per ordine a partire dai pagamenti
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Questo mantiene la “forma” del join prevedibile: una riga ordine resta una riga ordine.
DISTINCT è l'ultima risorsa
SELECT DISTINCT può sembrare di risolvere i duplicati, ma può nascondere il vero problema:
- Può eliminare righe legittime.
- Può mascherare una condizione di join errata (come la mancanza di parte di una chiave composta).
- Può corrompere i totali (soprattutto somme e conteggi).
Usalo solo quando sei sicuro che i duplicati sono accidentali e comprendi perché si sono verificati.
Controllo rapido: verifica i conteggi
Prima di fidarti dei risultati, confronta i conteggi delle righe:
- Conta le righe nella tua tabella principale (es. ordini).
- Conta le righe dopo il join.
- Se il numero salta inaspettatamente, ispeziona quali chiavi causano più corrispondenze e decidi se ti serve una pre-aggregazione o un percorso di join diverso.
Nozioni di base sulle performance e una cheat sheet sui JOIN
I JOIN spesso vengono “incolpati” per query lente, ma la vera causa è solitamente quanto dato chiedi al database di combinare e quanto facilmente può trovare le righe corrispondenti.
Indici (concettualmente) e perché aiutano i JOIN
Pensa a un indice come a un indice analitico di un libro. Senza di esso, il database potrebbe dover scansionare molte righe per trovare le corrispondenze per la tua condizione di JOIN. Con un indice sulla chiave di join (per esempio, customers.customer_id e orders.customer_id), il database può saltare direttamente alle righe rilevanti molto più velocemente.
Non serve conoscere i dettagli interni per usare bene questo principio: se una colonna è frequentemente usata per abbinare righe (ON a.id = b.a_id), è un buon candidato per avere un indice.
Fai join su chiavi stabili (non nomi o email)
Quando possibile, fai join su identificatori stabili e unici:
- Buono:
customers.customer_id = orders.customer_id - Rischioso:
customers.email = orders.emailocustomers.name = orders.name
I nomi cambiano e possono ripetersi. Le email possono cambiare, mancare o differire per maiuscole/minuscole. Gli ID sono progettati per un matching coerente e sono comunemente indicizzati.
Riduci il lavoro il prima possibile
Due abitudini rendono i JOIN visibilmente più veloci:
- Seleziona meno colonne. Evita
SELECT *quando fai join di più tabelle — le colonne extra aumentano uso di memoria e rete. - Limita le righe prima o durante il JOIN. Filtra il più presto possibile.
Esempio: limita gli ordini prima, poi fai il join:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at \u003e= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Se stai iterando su queste query dentro la costruzione di un'app (per esempio, creando una pagina di report basata su PostgreSQL), strumenti come Koder.ai possono accelerare lo scaffolding — schema, endpoint, UI — mentre mantieni il controllo della logica dei JOIN che determina la correttezza.
Cheat sheet rapida sui JOIN
- INNER JOIN → solo righe che corrispondono in entrambe le tabelle
- LEFT JOIN → tutte le righe dalla tabella sinistra, più le corrispondenze dalla destra (i non-corrispondenti diventano
NULL) - RIGHT JOIN → tutte le righe dalla tabella destra, più le corrispondenze dalla sinistra (
NULLquando mancano) - FULL OUTER JOIN → tutte le righe di entrambe le tabelle; le corrispondenze si fondono, i non-corrispondenti mostrano
NULL - CROSS JOIN → ogni combinazione di righe (la dimensione si moltiplica; usare con cautela)
- SELF JOIN → una tabella unita a se stessa (utile per gerarchie e confronti)
Domande frequenti
Cos'è un JOIN SQL in parole semplici?
Un JOIN SQL combina le righe di due (o più) tabelle in un unico risultato facendo corrispondere colonne correlate — solitamente una chiave primaria con una chiave esterna (per esempio, customers.customer_id = orders.customer_id). È il modo in cui “ricongiungi” tabelle normalizzate quando ti servono report, controlli o analisi.
Quando dovrei usare INNER JOIN?
Usa INNER JOIN quando vuoi solo le righe in cui la relazione esiste in entrambe le tabelle.
- I clienti senza ordini non appariranno.
- Gli ordini che puntano a un cliente mancante non appariranno.
È ideale per rapporti su relazioni “confermate”, come elencare solo i clienti che hanno effettivamente effettuato acquisti.
Come trovo le righe che non hanno una corrispondenza in un'altra tabella?
Usa LEFT JOIN quando ti servono tutte le righe dalla tabella principale (sinistra) e i dati correlati della destra solo se esistono.
Per trovare i “mancanti”, fai il join e poi filtra la parte destra su NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
Ho davvero bisogno di RIGHT JOIN, e come lo sostituisco con LEFT JOIN?
RIGHT JOIN conserva tutte le righe della tabella destra e riempie con NULL le colonne della sinistra quando non c'è corrispondenza. Molte squadre lo evitano perché si legge “al contrario”.
Nella maggior parte dei casi puoi riscriverlo come LEFT JOIN invertendo l'ordine delle tabelle:
FROM payments p
orders o o.order_id p.order_id
Per cosa è meglio usare FULL OUTER JOIN?
Usa FULL OUTER JOIN per riconciliazioni: vuoi vedere i match, le righe solo a sinistra e le righe solo a destra in un unico output.
È ottimo per audit come “ordini senza pagamenti” e “pagamenti senza ordini”, perché i lati non corrispondenti compaiono con colonne NULL.
Cosa succede se il mio database non supporta FULL OUTER JOIN?
Alcuni database (in particolare MySQL e SQLite) non supportano FULL OUTER JOIN direttamente. Una soluzione comune è combinare due query:
orders LEFT JOIN payments- più le righe trovate solo sul lato payments
Di solito questo si fa con UNION (o UNION ALL con filtri attenti) per conservare sia i record “solo sinistra” che quelli “solo destra”.
Cos'è un CROSS JOIN e quando è veramente utile?
Un CROSS JOIN restituisce ogni combinazione possibile di righe tra due tabelle (prodotto cartesiano). È utile per generare scenari (per esempio size × color) o costruire una griglia di calendario.
Attenzione: il numero di righe cresce rapidamente, quindi può esplodere la dimensione dell'output e rallentare le query se le tabelle di input non sono piccole e controllate.
Cos'è un SELF JOIN e perché ho bisogno di alias per le tabelle?
Un self join è il join di una tabella con sé stessa per mettere in relazione righe nella stessa tabella (comune per gerarchie come dipendente → manager).
Devi usare alias per distinguere le due “copie”:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
Qual è la differenza tra filtrare in ON vs WHERE per i join?
ON definisce come le righe si abbinano durante il join; WHERE filtra dopo che il risultato del join è stato formato. Con un LEFT JOIN, una condizione in WHERE sulla tabella destra può rimuovere le righe NULL corrispondenti e trasformarlo in un INNER JOIN effettivo.
Se vuoi mantenere tutte le righe di sinistra ma limitare quali righe di destra possono corrispondere, metti il filtro sulla tabella destra in .
Perché i join creano duplicati e come evito i conteggi doppi?
I join possono moltiplicare le righe quando la relazione è one-to-many (o many-to-many). Per esempio, un ordine con due pagamenti apparirà due volte se fai il join orders → payments.
Per mantenere “una riga per ordine” o “una riga per cliente”, aggrega prima il lato “many” (ad esempio SUM(amount) raggruppato per order_id) e poi fai il join. Usa DISTINCT solo come ultima risorsa perché può nascondere problemi reali del join e rompere i totali.