09 nov 2025·8 min
Costruire una web app per gestire le contestazioni di un marketplace end-to-end
Scopri come pianificare, progettare e costruire una web app per gestire contestazioni marketplace: intake casi, raccolta prove, workflow, ruoli, audit trail, integrazioni e reporting.
Cosa deve risolvere un'app per le contestazioni di un marketplace
Un'app per le contestazioni non è solo un “modulo di supporto con uno status.” È il sistema che decide come si muovono denaro, oggetti e fiducia nel tuo marketplace quando qualcosa va storto. Prima di disegnare schermate o tabelle, definisci chiaramente lo spazio del problema—altrimenti costruirai uno strumento facile da usare ma difficile da far rispettare.
Definisci cosa significa “contestazione” per il tuo marketplace
Inizia elencando i tipi di contestazione che devi davvero gestire e come differiscono. Categorie comuni includono:
- Articolo non ricevuto (ritardi di spedizione, indirizzo errato, pacco perso)
- Non conforme / danneggiato (problemi di qualità, parti mancanti)
- Frode / acquisto non autorizzato (account compromesso, metodo di pagamento rubato)
- Chargeback (contestazioni mosse dalla banca con prove e scadenze rigide)
Ogni tipo tende a richiedere prove diverse, finestre temporali e esiti (rimborso, sostituzione, rimborso parziale, inversione del pagamento al venditore). Tratta il tipo di contestazione come un driver del workflow—non solo come una etichetta.
Chiarisci gli obiettivi (così puoi fare compromessi)
La gestione delle contestazioni solitamente si confronta su velocità, coerenza e prevenzione delle perdite. Scrivi cosa significa successo nel tuo contesto:
- Risoluzione più veloce: meno scambi di messaggi e scadenze più chiare
- Meno errori: decisioni standardizzate e meno eccezioni “caso speciale”
- Migliore esperienza acquirente/venditore: trasparenza, chiarezza sullo stato, passaggi successivi prevedibili
- Perdite inferiori: ridurre rimborsi non necessari, prevenire abusi ripetuti, vincere più chargeback
Questi obiettivi influenzano tutto, dai dati che raccogli alle azioni che automatizzi.
Identifica chi usa il sistema (e cosa serve a ciascuno)
La maggior parte dei marketplace ha più di un semplice “supporto clienti.” Gli utenti tipici includono acquirenti, venditori, agenti di supporto, admin e finance/risk. Ogni gruppo necessita di una vista diversa:
- Acquirenti e venditori: passaggi semplici, richieste di prove chiare, promemoria sulle scadenze
- Agenti di supporto: code, template, note interne, guida alla decisione
- Admin/finance: audit trail, controlli sui payout, esportazioni per chargeback, reporting
Decidi cosa va in v1 e cosa dopo
Un v1 solido si concentra solitamente su: creazione del caso, raccolta prove, messaggistica, tracciamento delle scadenze e registrazione di una decisione con un audit trail.
Rilasci successivi possono aggiungere: regole di rimborso automatiche, segnali antifrode, analytics avanzati e integrazioni più profonde. Mantenere il perimetro ridotto all'inizio evita un sistema “che fa tutto” di cui nessuno si fida.
Se muovi veloce, può aiutare prototipare il workflow end-to-end prima di impegnarti in una build completa. Ad esempio, i team a volte usano Koder.ai (una piattaforma vibe-coding) per lanciare una dashboard admin React + backend Go/PostgreSQL partendo da una specifica via chat, e poi esportare il codice sorgente una volta che gli stati del caso e i permessi sono consolidati.
Modella il workflow delle contestazioni e gli stati
Un'app per le contestazioni vince o perde in base a quanto rispecchia come le contestazioni muovono effettivamente nel tuo marketplace. Inizia mappando il percorso attuale end-to-end, poi trasforma quella mappa in un piccolo insieme di stati e regole che il sistema può imporre.
Mappa il percorso della contestazione (passo dopo passo)
Scrivi il “percorso ideale” come una timeline: intake → raccolta prove → revisione → decisione → payout/rimborso. Per ogni passo annota:
- Chi agisce dopo (acquirente, venditore, agente, check automatico)
- Quali informazioni sono richieste (foto, tracking, messaggi)
- Cosa cambia nello stato dell'ordine/pagamento (bloccare fondi, avviare rimborso)
Questo diventa la spina dorsale per automazioni, promemoria e reporting.
Definisci stati chiari (e cosa significano)
Mantieni gli stati mutuamente esclusivi e facili da capire. Una baseline pratica:
- Opened: contestazione creata, in attesa di informazioni iniziali
- Waiting on buyer / Waiting on seller: azione richiesta da una delle parti
- Under review: agente o regole automatiche che valutano le prove
- Resolved: decisione eseguita (refund/release/sostituzione)
- Appealed: decisione contestata, revisione di secondo livello
Per ogni stato, definisci criteri di ingresso, transizioni permesse e campi richiesti prima di avanzare. Questo evita casi bloccati e risultati incoerenti.
Limiti temporali, SLA e regole di escalation
Collega scadenze agli stati (es. il venditore ha 72 ore per fornire il tracking). Aggiungi promemoria automatici e decidi cosa succede quando il tempo scade: chiusura automatica, decisione predefinita o escalation a revisione manuale.
Esiti e azioni
Modella gli esiti separatamente dagli stati così puoi tracciare cosa è successo: rimborso, rimborso parziale, sostituzione, rilascio fondi, restrizione/account ban, o credito goodwill.
Gestisci le eccezioni precocemente
Le contestazioni si complicano. Includi percorsi per tracking mancante, spedizioni frazionate, prove di consegna per beni digitali e ordini con più articoli (decisioni a livello di singolo articolo vs decisioni sull'intero ordine). Progettare questi rami in anticipo evita gestioni one-off che rompono la coerenza più avanti.
Progetta il modello dati (Casi, Prove, Decisioni)
Un'app per le contestazioni riesce o fallisce in base a quanto il modello dati risponde a domande reali: “Cosa è successo?”, “Qual è la prova?”, “Cosa abbiamo deciso?” e “Possiamo mostrare un audit trail dopo?”. Inizia nominando un piccolo insieme di entità core e sii rigoroso su cosa può cambiare.
Entità core (e perché esistono)
Al minimo, modella:
- Order (cosa è stato comprato, quando, da chi)
- Payment (importi, valuta, riferimenti authorization/capture/refund)
- User (acquirente, venditore, agente/admin)
- Dispute / Case (contenitore che traccia il workflow)
- Claim reason (codici motivo standardizzati e descrizioni)
- Evidence (file, link, fatti strutturati come tracking ID)
- Message (cronologia conversazioni e notifiche di sistema)
- Decision (esito, motivazione, importi, date di efficacia)
Mantieni il “Dispute” focalizzato: deve referenziare order/payment, memorizzare status, scadenze e puntatori a prove e decisioni.
Dati immutabili vs modificabili
Tratta tutto ciò che deve essere difendibile in seguito come append-only:
- Cambi di stato (chi/quando/perché)
- Decisioni e revoche
- Upload e cancellazioni di prove (registra tombstone, non hard delete)
- Variazioni di importo legate a rimborsi/chargeback
Consenti modifiche solo per praticità operativa:
- Note interne, tag, assegnazione code
- Metadati solo per la visualizzazione (es. “seller tier”) che possono essere resincrovinati
Questa divisione è più semplice con una tabella audit trail (event log) più i campi “snapshot” correnti sul caso.
Campi obbligatori e validazione
Definisci validazioni rigide presto:
- Reason codes da una lista controllata (mappabili ai codici del payment processor se necessario)
- Importi con valuta, regole di precisione e vincoli non negativi
- Date per apertura/ricezione, scadenze di risposta, tempo di risoluzione
- Allegati richiesti per certi motivi (es. tracking per “articolo non ricevuto”)
Allegati, sicurezza e retention
Pianifica lo storage delle prove: tipi file ammessi, limiti di dimensione, scansione antivirus e regole di retention (es. cancellazione automatica dopo X mesi se la policy lo consente). Memorizza i metadati del file (hash, uploader, timestamp) e tieni il blob in object storage.
ID caso e metadata ricercabili
Usa uno schema di case ID coerente e leggibile (es. DSP-2025-000123). Indicizza campi ricercabili come order ID, buyer/seller ID, status, reason, intervallo importo e date chiave così gli agenti trovano i casi rapidamente dalla coda.
Ruoli, permessi e controlli sui dati sensibili
Le contestazioni coinvolgono più parti e dati ad alto rischio. Un modello di ruoli chiaro riduce errori, accelera le decisioni e aiuta a rispettare requisiti di compliance.
Definisci ruoli e cosa può fare ciascuno
Inizia con un set piccolo e esplicito di ruoli e mappali alle azioni—non solo alle schermate:
- Buyer / Seller: creare una contestazione, caricare prove, vedere solo le informazioni consentite, rispondere ai messaggi, accettare o rifiutare soluzioni proposte
- Agent: triage dei casi, richieste di info, impostare scadenze, redigere decisioni e applicare esiti standard (rimborso, sostituzione, rifiuto)
- Supervisor: sovrascrivere decisioni, riaprire casi, approvare escalation e gestire template/policy
- Finance: eseguire o approvare movimenti di denaro (rimborsi, blocchi/rilascio payout) e vedere solo i campi di pagamento necessari
- Admin: configurare ruoli, integrazioni e regole di retention—idealmente senza leggere per default il contenuto dei casi
Usa impostazioni di minimo privilegio e aggiungi l’accesso “break glass” solo per emergenze tracciate.
Autenticazione e accessi privilegiati
Per il personale, supporta SSO (SAML/OIDC) quando disponibile così l'accesso segue il ciclo di vita HR. Richiedi MFA per i ruoli privilegiati (supervisor, finance, admin) e per qualsiasi azione che modifica denaro o una decisione finale.
I controlli di sessione contano: token a breve vita per gli strumenti staff, refresh vincolati al dispositivo quando possibile e logout automatico per postazioni condivise.
PII, dati di pagamento e visibilità a livello di campo
Separa i “fatti del caso” dai campi sensibili. Applica permessi a livello di campo per:
- Dati identificativi personali (indirizzo, telefono, email)
- Dettagli di pagamento (mai memorizzare il PAN completo; tokenizza e maschera)
- Note interne e flag di rischio
Redigi di default nell'UI e nei log. Se qualcuno necessita accesso, registra il motivo.
Audit trail e regole di visibilità delle prove
Mantieni un log immutabile per azioni sensibili: cambi decisione, rimborsi, blocchi payout, cancellazioni di prove, cambi permessi. Includi timestamp, attore, vecchio/nuovo valore e fonte (API/UI).
Per le prove, definisci regole di consenso e condivisione: cosa può vedere l'altra parte, cosa rimane interno (es. segnali antifrode) e cosa deve essere parzialmente redatto prima della condivisione.
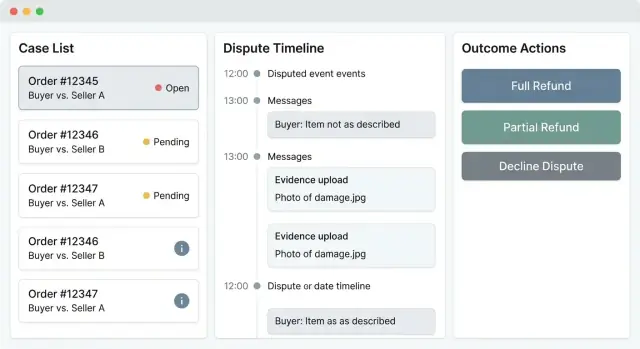
Esperienza utente: Coda casi e schermata dettaglio caso
Uno strumento per contestazioni vive o muore in base alla rapidità: quanto velocemente un agente può triage un caso, capire cosa è successo e intraprendere un'azione sicura. L'UI dovrebbe rendere ovvio “chi deve fare cosa ora”, mantenendo però i dati sensibili e le decisioni irreversibili difficili da cliccare per errore.
Coda casi: triage veloce con filtri utili
La tua lista casi dovrebbe comportarsi come una console operativa, non come una tabella generica. Includi filtri che riflettono come i team lavorano: status, reason, importo, age/SLA, venditore e risk score. Aggiungi viste salvate (es. “New high-value”, “Overdue”, “Awaiting buyer response”) così gli agenti non ricreano filtri ogni giorno.
Rendi le righe scansionabili: case ID, chip di status, giorni aperti, importo, parte (buyer/seller), indicatore di rischio e prossima scadenza. Mantieni l'ordinamento prevedibile (default per urgenza/SLA). Le azioni di massa sono utili, ma limitale ad operazioni sicure come assegna/deseleziona o aggiungi tag interni.
Dettaglio caso: tutto il necessario, niente distrazioni
La pagina dettaglio caso dovrebbe rispondere a tre domande in pochi secondi:
- Cosa è successo?
- Quali prove abbiamo?
- Qual è la prossima azione e la scadenza?
Un layout pratico è una timeline al centro (eventi, cambi di stato, segnali pagamento/spedizione), con un pannello snapshot a destra per il contesto ordine/pagamento (totale ordine, metodo di pagamento, stato spedizione, rimborsi/chargeback, ID chiave). Mantieni link profondi a oggetti correlati come riferimenti testuali tipo /orders/123 e /payments/abc.
Aggiungi un'area messaggi e una galleria prove che supporti anteprima rapida (immagini, PDF) più metadati (chi ha inviato, quando, tipo, stato verifica). Gli agenti non dovrebbero mai dover cercare tra gli allegati per capire l'ultimo aggiornamento.
Azioni chiare e sicure (con guardrail)
Le azioni di decisione (refund, deny, request more info, escalate) devono essere inequivocabili. Usa conferme per passaggi irreversibili e richiedi input strutturati: nota obbligatoria, reason code e template di decisione opzionali per coerenza.
Separa i canali di collaborazione: note interne (solo agenti, per passaggi di consegna) vs messaggi esterni (visibili ad acquirente/venditore). Includi controlli di assegnazione e un “proprietario corrente” visibile per evitare lavoro duplicato.
Accessibilità e recensioni mobile-friendly
Progetta per navigazione da tastiera, contrasto leggibile degli status e etichette per screen reader—soprattutto sui pulsanti di azione e campi form. Le viste mobile devono dare priorità allo snapshot, all'ultimo messaggio, alla prossima scadenza e a un accesso con un tap alla galleria prove per revisioni rapide durante turni on-call.
Messaggistica, notifiche e scadenze
Design Safer Permissions
Progetta ruoli e permessi, poi genera azioni UI protette per rimborsi e override.
Le contestazioni sono per lo più problemi di comunicazione con un timer attaccato. La tua app dovrebbe rendere ovvio chi deve fare cosa, entro quando, e tramite quale canale—senza costringere le persone a scavare in thread email.
Canali: in-app prima di tutto, email sempre, SMS opzionale
Usa la messaggistica in-app come fonte di verità: ogni richiesta, risposta e allegato dovrebbe vivere nella timeline del caso. Poi replica aggiornamenti chiave via email (nuovo messaggio, richiesta prove, scadenza in avvicinamento, decisione emessa). Se aggiungi SMS, usalo per solleciti temporali (es. “Scadenza tra 24 ore”) evitando dettagli sensibili nel testo.
Template che riducono i botta-e-risposta
Crea template di messaggi per richieste comuni così gli agenti restano coerenti e gli utenti sanno quale prova è “buona”:
- Richiesta proof of delivery (carrier, link tracking, scan di consegna)
- Richiesta foto (condizione articolo, imballaggio, numero seriale)
- Istruzioni di reso (indirizzo, RMA, scadenza, corrieri ammessi)
Permetti placeholder come order ID, date e importi, più una breve area di “modifica umana” così le risposte non sembrano robotiche.
Scadenze, promemoria e cosa succede se il tempo scade
Ogni richiesta dovrebbe generare una scadenza (es. il venditore ha 3 giorni lavorativi per rispondere). Mostrala in modo prominente sul caso, invia promemoria automatici (48h e 24h) e definisci esiti chiari per chi non risponde (es. auto-close, auto-refund o escalation).
Multilingue e sicurezza di default
Se servi più regioni, memorizza i contenuti dei messaggi con un tag lingua e fornisci template localizzati. Per prevenire abusi, aggiungi limiti di frequenza per caso/utente, limiti su dimensione/tipo allegati, scansione antivirus e rendering sicuro (niente HTML inline, sanitizza i nomi file). Mantieni un audit trail di chi ha inviato cosa e quando.
Raccolta e verifica delle prove
Le prove sono dove la maggior parte delle contestazioni si vincono o si perdono, quindi la tua app dovrebbe trattarle come un workflow di prima classe—non come un ammasso di allegati.
Pianifica le prove che accetterai
Inizia definendo i tipi di prove che ti aspetti nei casi comuni: link di tracking e scan di consegna, foto dell'imballaggio o del danno, fatture/scontrini, log chat, etichette di reso e note interne. Rendere espliciti questi tipi aiuta a validare gli input, standardizzare la revisione e migliorare il reporting.
Richiedi prove in base al motivo della contestazione
Evita prompt generici “carica qualsiasi cosa”. Genera richieste strutturate in base al motivo (es. “Articolo non ricevuto” → tracking corriere + prova di consegna; “Non conforme” → snapshot della scheda prodotto + foto dell'acquirente). Ogni richiesta dovrebbe includere:
- Cosa caricare
- Un breve esempio (come appare una prova “buona”)
- Una data di scadenza allineata al tuo SLA
Questo riduce i botta-e-risposta e rende i casi confrontabili tra revisori.
Aggiungi controlli di integrità e catena di custodia
Tratta le prove come record sensibili. Per ogni upload conserva:
- Un hash crittografico (es. SHA-256) del file
- Timestamp server-side
- Identità dell'uploader (utente/servizio), ruolo e IP (se appropriato)
- Eventi immutabili di audit per upload, download e cancellazioni
Questi controlli non “provano” che il contenuto sia veritiero, ma provano se il file è stato alterato dopo l'invio e chi lo ha gestito.
Crea un export “evidence packet”
Le contestazioni spesso finiscono in revisioni esterne (payment processor, corriere, arbitrato). Fornisci un export con un click che impacchetta file chiave più un sommario: fatti del caso, timeline, metadata dell'ordine e indice delle prove. Mantienilo consistente così i team possono fidarsi sotto pressione.
Retention e workflow di cancellazione
Le prove possono contenere dati personali. Implementa regole di retention per tipo di contestazione e regione, più un processo di cancellazione tracciato (con approvazioni e log) quando richiesto legalmente.
Decisioni, esiti e ricorsi
Collect Evidence the Right Way
Crea flussi di raccolta prove per acquirenti e venditori con upload, modelli e scadenze.
La decisione è il punto dove un'app per contestazioni costruisce fiducia o genera ulteriore lavoro. L'obiettivo è la coerenza: casi simili devono avere esiti simili, e entrambe le parti devono capire perché.
Scrivi le policy decisionali in linguaggio chiaro
Inizia definendo le policy come regole leggibili, non come testo legale. Per ogni motivo di contestazione documenta:
- Cosa qualifica per approve, decline o partial relief
- Quali prove sono richieste (e cosa è “utile avere”)
- Quali timeline si applicano (finestre di spedizione, scadenze di risposta, scan di consegna)
Versiona queste policy così puoi spiegare decisioni prese con regole precedenti e ridurre la “deriva” delle policy.
Costruisci aiuti alla decisione, non solo pulsanti
Una buona schermata di decisione spinge il revisore verso esiti completi e difendibili.
Usa checklist per motivo che appaiono automaticamente nella vista caso (esempio: “carrier scan presente”, “foto mostra il danno”, “la scheda prometteva X”). Ogni elemento di checklist può:
- Collegarsi alla prova rilevante già presente nel caso
- Segnalare prove mancanti prima che il revisore finalizzi
- Aggiungere testo motivazionale templato (“Consegna confermata dal corriere il…”) che il revisore può modificare
Questo crea un audit trail coerente senza costringere tutti a scrivere da zero.
Esiti che riflettono il denaro reale
La decisione dovrebbe calcolare l'impatto finanziario, non lasciarlo a fogli di calcolo. Memorizza e mostra:
- Importo del rimborso (intero/parziale), valuta e regole di arrotondamento
- Commissioni (processor, marketplace, dispute fees), costi di spedizione, importi di reso
- Rischio previsto di chargeback o esposizione (anche come semplice punteggio)
Rendi chiaro se il sistema emetterà automaticamente il rimborso o genererà un task per finance/support (soprattutto quando i pagamenti sono divisi o parzialmente catturati).
Ricorsi: consentili, ma controllali
I ricorsi riducono la frustrazione quando emergono nuove informazioni—ma possono diventare loop infiniti.
Definisci: quando sono permessi i ricorsi, cosa significa “nuova” prova, chi rivede (se possibile una fila/revisore diverso) e quante volte sono ammessi. Su un ricorso congela la decisione originale e crea un record di ricorso collegato così il reporting distingue esito iniziale da esito finale.
Spiega le decisioni a entrambe le parti
Ogni decisione dovrebbe generare due messaggi: uno per l'acquirente e uno per il venditore. Usa linguaggio chiaro, elenca le prove chiave considerate e indica i passaggi successivi (inclusa l'eleggibilità al ricorso e le scadenze). Evita gergo e di incolpare le parti—focalizzati sui fatti e sulla policy.
Integrazioni: Ordini, Pagamenti, Spedizioni e Strumenti di Supporto
Le integrazioni trasformano uno strumento di contestazioni da “app note” in un sistema che può verificare fatti ed eseguire esiti in sicurezza. Inizia elencando i sistemi esterni che devono concordare sulla realtà: order management (cosa è stato acquistato), payments (cosa è stato catturato/rimborsato), corrieri (cosa è stato consegnato) e provider email/SMS (cosa è stato comunicato e quando).
Scegli la strategia di sincronizzazione giusta (webhook vs scheduled)
Per cambiamenti sensibili al tempo—come alert di chargeback, stato rimborso o aggiornamenti ticket—preferisci i webhooks. Riduce i ritardi e mantiene la timeline del caso accurata.
Usa sincronizzazione schedulata quando i webhooks non sono disponibili o affidabili (comune con i corrieri). Un ibrido pratico è:
- Webhook per pagamenti e eventi interni ordine
- Polling per scan spedizione e conferme di consegna
Qualunque strategia tu scelga, memorizza lo “stato esterno ultimo noto” sul caso e conserva il payload raw per audit e debug.
Idempotenza: la cintura di sicurezza per i movimenti di denaro
Le azioni finanziarie devono essere ripetibili in sicurezza. Retry di rete, doppio click e re-delivery di webhook possono altrimenti innescare rimborsi duplicati.
Rendi ogni chiamata che tocca denaro idempotente:
- Genera una chiave azione unica per outcome del caso (es.
case_id + decision_id + action_type) - Persisti un record di “integration action” prima di chiamare l'API di pagamento
- Tratta richieste ripetute con la stessa chiave come no-op (restituisci il risultato originale)
Questo pattern vale anche per rimborsi parziali, void e inversioni di fee.
Log eventi di integrazione per supporto e troubleshooting
Quando qualcosa non combacia (un rimborso risulta “pending” o manca uno scan di consegna), il team ha bisogno di visibilità. Logga ogni evento di integrazione con:
- Timestamp, provider, endpoint/tipo evento
- Payload request/response (con campi sensibili redatti)
- Correlation ID che colleghi eventi a un caso e tra loro
Esponi una tab leggera “Integration” nel dettaglio caso così il supporto può investigare da solo.
Sandbox e modalità test
Pianifica ambienti sicuri fin dal giorno uno: sandbox del payment processor, numeri tracking test del corriere (o risposte mockate) e “test recipients” per email/SMS. Aggiungi un banner visibile “test mode” in non produzione così QA non lancerà rimborsi reali per errore.
Se costruisci tooling admin, documenta credenziali richieste e scope su una pagina interna tipo /docs/integrations così la configurazione è ripetibile.
Scelte architetturali che mantengono l'app manutenibile
Un sistema di gestione contestazioni cresce rapidamente oltre “qualche schermata”. Aggiungerai upload di prove, lookup pagamenti, promemoria scadenze e reporting—quindi l'architettura dovrebbe restare noiosa e modulare.
Scegli uno stack che il tuo team può consegnare
Per v1, dai priorità a ciò che il tuo team già conosce. Una configurazione convenzionale (React/Vue + API REST/GraphQL + Postgres) è generalmente più veloce da consegnare che sperimentare nuovi framework. L'obiettivo è consegna prevedibile, non novità.
Se vuoi accelerare la prima iterazione senza vincolarti a una black box, una piattaforma come Koder.ai può essere utile per generare una base React + Go + PostgreSQL a partire da una specifica workflow, lasciando comunque la possibilità di esportare il codice sorgente e prendere piena proprietà.
Separa le responsabilità fin da subito
Mantieni confini chiari tra:
- Frontend app: dashboard admin e eventuali viste buyer/seller
- API service: business logic, permessi, validazione, audit trail
- Background jobs: notifiche, export, elaborazione prove, integrazioni
- File storage: i file delle prove devono vivere fuori dal DB (object storage), con i metadata nelle tabelle
Questa separazione rende più semplice scalare parti specifiche (come il processing in background) senza riscrivere tutta la web app di gestione casi.
Usa una coda per lavori lunghi
La raccolta e verifica delle prove spesso implica scansione antivirus, OCR, conversione file e chiamate a servizi esterni. Export e promemoria schedulati possono essere pesanti. Metti questi task in coda così l'UI resta reattiva e gli utenti non reinviano azioni. Traccia lo stato dei job sul caso così gli operatori capiscono cosa è pendente.
Pianifica performance di ricerca e filtro
Le code casi vivono e muoiono per la ricerca. Progetta il filtro per status, SLA/scadenze, metodo di pagamento, flag di rischio e agente assegnato. Aggiungi indici presto e considera la ricerca full-text solo se gli indici base non bastano. Progetta anche paginazione e “saved views” per i flussi comuni.
Ambienti, deployment e rollback
Definisci staging e production fin dall'inizio, con seed data che rispecchi scenari reali di contestazione (workflow chargeback, automazione rimborsi, ricorsi). Usa migrazioni versionate, feature flag per cambi rischiosi e un piano di rollback così puoi deployare spesso senza rompere casi attivi.
Se il tuo team apprezza iterazione rapida, funzionalità come snapshot e rollback (presenti in piattaforme come Koder.ai) possono essere un complemento pratico ai controlli di rilascio tradizionali—soprattutto mentre i workflow e i permessi evolvono.
Reporting, analytics e miglioramento continuo
Make an Evidence Packet Export
Costruisci esportazioni che raggruppano file chiave e una timeline per chargeback e ricorsi.
Un sistema di gestione contestazioni migliora quando vedi rapidamente cosa succede across i casi. Il reporting non è solo per dirigenti; aiuta agenti a prioritizzare, manager a individuare rischi operativi e il business a regolare policy prima che i costi aumentino.
Inizia con metriche che cambiano decisioni
Traccia un piccolo set di KPI azionabili e rendili visibili ovunque:
- Resolution time (media e p90), diviso per reason code e segmento venditore
- Backlog size e bucket di aging (es. 0–2 giorni, 3–7, 8+)
- Win rate per chargeback e ricorsi, per metodo di pagamento e tipo di prova
- Totali rimborsi e tasso di rimborso, più rimborsi evitabili (gap di policy)
- Recidivi (acquirenti e venditori), con soglie e trend
Cruscotti per agenti vs manager
Gli agenti hanno bisogno di una vista operativa: “Cosa devo lavorare dopo?” Costruisci una dashboard stile coda che evidenzi SLA violati, scadenze imminenti e casi con prove mancanti.
I manager hanno bisogno di rilevare pattern: picchi in certi reason code, venditori ad alto rischio, totali rimborsi insoliti e calo dei win-rate dopo cambi policy. Una semplice vista settimanale spesso batte una pagina di grafici sovraccarica.
Esportazioni senza perdere dati sensibili
Supporta esportazioni CSV e report schedulati, ma metti guardrail:
- Permessi di esportazione basati su ruolo
- Redazione a livello di colonna (PII, identificatori di pagamento)
- Log di audit su chi ha esportato cosa e quando
Migliora la qualità dei dati con tag e reason codes
L'analytics funziona solo se i casi sono etichettati in modo coerente. Usa reason codes controllati, tag (opzionali ma normalizzati) e prompt di validazione quando un agente tenta di chiudere un caso con “Other”.
Trasforma insight in policy e automazione migliori
Tratta il reporting come un ciclo di feedback: rivedi i motivi di perdita principali mensilmente, aggiusta le checklist di prova, affina le soglie di auto-refund e documenta i cambi così i miglioramenti emergono nelle coorti future.
Test, checklist di lancio e readiness operativa
Rilasciare un sistema di contestazioni è meno questione di perfezione UI e più di sapere che si comporta correttamente sotto stress: prove mancanti, risposte in ritardo, edge case di pagamento e controllo accessi rigorosi.
Testa l'intero ciclo del caso (e i percorsi brutti)
Scrivi test che seguono flussi reali end-to-end: open → richiesta/prove ricevute → decisione → payout/refund/hold. Includi percorsi negativi e transizioni basate sul tempo:
- Il venditore non risponde; la scadenza scade e il caso avanza automaticamente.
- Le prove arrivano dopo la scadenza; verifica come vengono segnalate e se sono ammissibili.
- Rimborsi parziali, spedizioni frazionate, più articoli in un ordine.
- Retry per operazioni idempotenti (es. “rimborso già emesso”).
Automatizza questi con test di integrazione sulle API e sui background job; tieni un set piccolo di script esplorativi manuali per regression UI.
Permessi e dati sensibili: testa come un attaccante
I fallimenti nel controllo accessi sono ad alto impatto. Costruisci una matrice di test permessi per ogni ruolo (buyer, seller, agent, supervisor, finance, admin) e verifica:
- Chi può vedere/modificare prove, PII e note interne
- Regole a livello di campo (masking, restrizioni di download, redazione)
- Completezza dell'audit trail: ogni cambio decisione, ogni rimborso, ogni esportazione sensibile
Monitoraggio, alert e “cosa succede se si rompe?”
Le app di contestazioni dipendono da job e integrazioni (ordini, pagamenti, spedizioni). Aggiungi monitoraggio per:
- Job in background falliti, casi bloccati, trigger di scadenze mancati
- Errori di integrazione e failure webhook, con soglie di alert
- Picchi anomali (es. errori rimborsi, errori upload, backlog coda)
Runbook + rollout graduale
Prepara un runbook interno che copra problemi comuni, percorsi di escalation e override manuali (riaprire caso, estendere scadenza, correggere un rimborso, richiedere nuovamente prove). Poi rilascia in fasi:
- Pilot con un piccolo team e tipi di contestazione limitati.
- Aumenta il volume, poi abilita gradualmente le regole di automazione.
- Raccogli feedback dagli agenti settimanalmente e aggiorna i workflow prima di scalare ulteriormente.
Quando iteri veloce, una “planning mode” strutturata (come quella offerta in Koder.ai) può aiutare ad allineare stakeholder su stati, ruoli e integrazioni prima di lanciare cambi in produzione.
Domande frequenti
What should a marketplace dispute app actually solve (beyond a support form)?
Inizia definendo i tipi di contestazione (articolo non ricevuto, non conforme/danneggiato, frode/acquisto non autorizzato, chargeback) e mappando per ciascuno i requisiti di prova, le finestre temporali e gli esiti possibili. Tratta il tipo di contestazione come un driver di workflow così che il sistema possa applicare passaggi e scadenze coerenti.
What features belong in v1 versus later releases?
Un v1 pratico solitamente include: creazione del caso, raccolta strutturata delle prove, messaggistica in-app replicata via email, scadenze SLA con promemoria, una coda base per gli agenti e la registrazione delle decisioni con un audit trail immutabile. Rimanda automazioni avanzate (scoring antifrode, regole di auto-refund, analytics complessi) finché il workflow di base non è affidabile.
How do I model dispute states without creating a confusing workflow?
Usa un set piccolo e mutuamente esclusivo come:
- Opened
- Waiting on buyer / Waiting on seller
- Under review
- Resolved
- Appealed
Per ogni stato definisci criteri di ingresso, transizioni permesse e campi obbligatori prima di procedere (es. non puoi entrare in “Under review” senza le prove richieste per quel reason code).
How should SLAs, deadlines, and escalations work in a dispute system?
Imposta scadenze per stato/azione (es. “il venditore ha 72 ore per fornire il tracking”), automatizza promemoria (48h/24h) e definisci outcome di default quando il tempo scade (auto-close, auto-refund o escalation). Rendi le scadenze visibili sia nella coda (per la priorità) sia nel dettaglio caso (per chiarezza).
Why should outcomes be modeled separately from case states?
Separa lo stato (dove si trova il caso nel flusso) dall'esito (cosa è avvenuto). Gli esiti includono spesso refund, partial refund, replacement, release funds, reversal di payout, restrizione account o credito goodwill. Questo permette di fare report accurati anche quando lo stesso stato (“Resolved”) può significare azioni finanziarie molto diverse.
What’s the minimum data model for disputes, evidence, and decisions?
Al minimo modello: Order, Payment, User, Case/Dispute, Claim reason (codici controllati), Evidence, Messages e Decision. Mantieni le informazioni difendibili in append-only tramite un event log (cambi stato, upload prove, decisioni, movimenti di denaro), permettendo modifiche limitate per campi operativi come note interne, tag e assegnazioni.
Which records should be immutable, and how do I implement an audit trail?
Considera append-only gli artefatti sensibili e difendibili:
- Cambi di stato con attore/tempo/motivo
- Upload delle prove e tombstone per le cancellazioni (no hard delete)
- Decisioni e inversioni
- Variazioni di importi per rimborsi/chargeback
Affianca questo a uno “snapshot” corrente sul caso per query UI rapide. Così indagini, ricorsi e pacchetti per chargeback risultano più semplici da giustificare.
How do I design roles and permissions for sensitive dispute data?
Definisci ruoli espliciti (buyer, seller, agent, supervisor, finance, admin) e assegna permessi per azione, non solo per schermo. Applica least-privilege, SSO + MFA per ruoli privilegiati, e masking a livello di campo per PII/dati di pagamento. Mantieni note interne e segnali di rischio nascosti alle parti esterne, con accesso “break glass” tracciato per eccezioni.
What should the agent case queue include to support fast triage?
Costruisci una coda operativa con filtri che rispecchiano il triage reale: status, reason, importo, età/SLA, venditore e punteggio di rischio. Rendi le righe leggibili a colpo d’occhio (case ID, status, giorni aperto, importo, parte, rischio, prossima scadenza) e aggiungi viste salvate come “Overdue” o “New high-value”. Limita le azioni di massa a operazioni sicure come assegnazione o tagging.
How should messaging and evidence requests be structured to reduce back-and-forth?
Usa la messaggistica in-app come fonte di verità, copia eventi chiave via email e riserva SMS a solleciti urgenti senza contenuti sensibili. Guida le richieste di prova dal reason code con template (proof of delivery, foto, istruzioni di reso) e allega sempre una data di scadenza così che l’utente sappia esattamente cosa fare dopo.