16 giu 2025·8 min
Come costruire un'app web per la gestione delle dipendenze di progetto
Progetta, sviluppa e rilascia un'app web che traccia dipendenze cross-funzionali, responsabili, rischi e timeline con workflow chiari, avvisi e report.
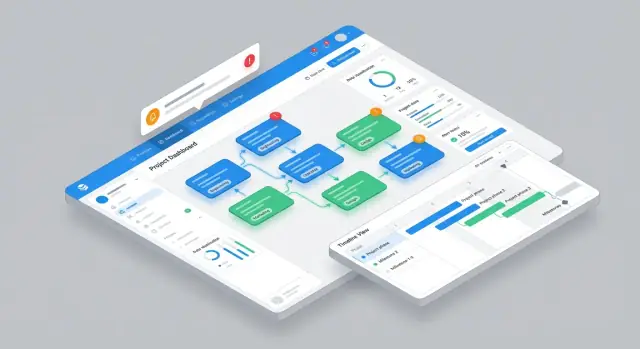
Progetta, sviluppa e rilascia un'app web che traccia dipendenze cross-funzionali, responsabili, rischi e timeline con workflow chiari, avvisi e report.
Prima di progettare schermate o scegliere uno stack tecnologico, definisci con precisione il problema che vuoi risolvere. Un'app per le dipendenze fallisce quando diventa “un altro posto da aggiornare”, mentre il vero dolore—sorprese e consegne in ritardo tra team—continua.
Inizia con una frase semplice che puoi ripetere in ogni riunione:
Le dipendenze cross-funzionali causano ritardi e sorprese dell'ultimo minuto perché responsabilità, tempistiche e stato non sono chiari.
Rendila specifica per la tua organizzazione: quali team sono più colpiti, quali tipi di lavoro vengono bloccati e dove si perde tempo (handoff, approvazioni, deliverable, accesso ai dati, ecc.).
Elenca gli utenti principali e come useranno l'app:
Mantieni i “job” stretti e testabili:
Scrivi una definizione in un paragrafo. Esempi: un handoff (Team A fornisce dati), un'approvazione (firma legale), o un deliverable (spec di design). Questa definizione diventa il modello dati e la spina dorsale del workflow.
Scegli un piccolo set di risultati misurabili:
Se non puoi misurarlo, non puoi dimostrare che l'app sta migliorando l'esecuzione.
Prima di progettare schermate o database, chiarisci chi partecipa alle dipendenze e come il lavoro si muove tra loro. La gestione delle dipendenze cross-funzionali fallisce più per aspettative disallineate che per strumenti scadenti: “Chi è responsabile?”, “Cosa significa fatto?”, “Dove vediamo lo stato?”
Le informazioni sulle dipendenze sono solitamente sparse. Fai un inventario rapido e cattura esempi (screenshot reali o riferimenti di documento) di:
Questo ti dice quali campi le persone già usano (date di scadenza, link, priorità) e cosa manca (proprietario chiaro, criteri di accettazione, stato).
Scrivi il flusso attuale in linguaggio semplice, tipicamente:
request → accept → deliver → verify
Per ogni passo, annota:
Cerca pattern come proprietari non chiari, date mancanti, stato “silenzioso” o dipendenze scoperte tardi. Chiedi agli stakeholder di classificare gli scenari più dolorosi (es.: “accettato ma mai consegnato” vs. “consegnato ma non verificato”). Ottimizza prima il top 1–2.
Scrivi 5–8 user story che riflettano la realtà, ad esempio:
Queste story diventano le guardie del scope quando le richieste di funzionalità iniziano ad accumularsi.
Un'app per le dipendenze riesce o fallisce in base a quanto tutti si fidano dei dati. L'obiettivo del modello dati è catturare chi ha bisogno di cosa, da chi, entro quando, e mantenere un registro chiaro di come gli impegni cambiano nel tempo.
Inizia con una singola entità “Dipendenza” che sia leggibile da sola:
Rendi questi campi obbligatori dove possibile; i campi opzionali tendono a rimanere vuoti.
Le dipendenze riguardano il tempo, quindi memorizza le date in modo esplicito e separato:
Questa separazione previene discussioni future (“richiesto” non è uguale a “promesso”).
Usa un modello di stato semplice e condiviso: proposed → pending → accepted → delivered, con eccezioni come at risk e rejected.
Modella le relazioni come link one-to-many in modo che ogni dipendenza possa collegarsi a:
Rendi le modifiche tracciabili con:
Se sistemi lo storico fin da subito, eviterai dibattiti “l'ha detto/l'ha detto” e faciliterai i handoff.
Un'app per le dipendenze funziona solo se tutti concordano su cosa sia un “progetto”, cosa sia una “milestone” e chi è responsabile quando le cose slittano. Mantieni il modello sufficientemente semplice perché i team lo mantengano davvero.
Traccia i progetti al livello con cui le persone pianificano e rendicontano—di solito un'iniziativa che dura settimane/mesi e ha un risultato chiaro. Evita di creare un progetto per ogni ticket; quello appartiene agli strumenti di delivery.
Le milestone dovrebbero essere poche e significative, checkpoint che possono sbloccare altri (es., “contratto API approvato”, “beta launch”, “security review completato”). Se le milestone diventano troppo dettagliate, gli aggiornamenti diventano un compito e la qualità dei dati cala.
Una regola pratica: i progetti dovrebbero avere 3–8 milestone, ciascuna con un owner, una data target e uno stato. Se ne servono di più, considera di rendere il progetto più piccolo.
Le dipendenze falliscono quando le persone non sanno a chi parlare. Aggiungi una directory leggera dei team che supporti:
Questa directory deve essere usabile anche da partner non tecnici, quindi mantieni i campi leggibili e ricercabili.
Decidi in anticipo se permettere ownership condivisa. Per le dipendenze, la regola più pulita è:
Se due team condividono davvero la responsabilità, modellalo come due milestone (o due dipendenze) con un handoff chiaro, invece di elementi “co-proprietari” che nessuno guida.
Rappresenta le dipendenze come link tra un progetto/milestone richiedente e un progetto/milestone fornitore, con una direzione (“A ha bisogno di B”). Questo abilita viste di programma in seguito: puoi aggregare per iniziativa, trimestre o portfolio senza cambiare il modo in cui i team lavorano giorno per giorno.
I tag aiutano a segmentare i report senza imporre una nuova gerarchia. Parti con un set piccolo e controllato:
Preferisci dropdown rispetto a testo libero per tag core per evitare che “Payments”, “payments” e “Paymnts” diventino tre categorie diverse.
Un'app per la gestione delle dipendenze ha successo quando le persone possono rispondere a due domande in pochi secondi: “Cosa devo consegnare?” e “Cosa mi blocca?” Progetta la navigazione attorno a questi job-to-be-done, non attorno agli oggetti del database.
Inizia con quattro viste core, ognuna ottimizzata per un diverso momento della settimana:
Mantieni la navigazione globale minimale (es., Inbox, Dipendenze, Timeline, Report) e lascia che gli utenti saltino tra viste senza perdere i filtri.
Rendi la creazione di una dipendenza rapida come inviare un messaggio. Fornisci template (es., “contratto API”, “revisione design”, “export dati”) e un drawer Quick Add.
Richiedi solo ciò che serve per instradare il lavoro correttamente: team richiedente, team proprietario, data di scadenza, breve descrizione e stato. Tutto il resto può essere opzionale o mostrato progressivamente.
Le persone vivranno nei filtri. Supporta ricerca e filtri per team, intervallo di date, rischio, stato, progetto, oltre a “assegnato a me”. Permetti agli utenti di salvare combinazioni comuni (“I miei lanci Q1”, “Rischio alto questo mese”).
Usa indicatori di rischio sicuri per il colore (icona + etichetta, non solo colore) e garantisci piena navigazione da tastiera per creare, filtrare e aggiornare stati.
Gli empty-state devono insegnare. Quando una lista è vuota, mostra un breve esempio di una dipendenza ben formata:
“Team Pagamenti: fornire chiavi API sandbox per Checkout v2 entro il 14 mar; necessario per l'inizio del QA mobile.”
Questo tipo di guida migliora la qualità dei dati senza aggiungere processo.
Uno strumento per dipendenze ha successo quando rispecchia come i team collaborano—senza costringerli in lunghe riunioni di stato. Progetta il workflow attorno a pochi stati riconoscibili da tutti e fai sì che ogni cambio di stato risponda a una domanda: “Cosa succede dopo e chi lo possiede?”
Inizia con un modulo guidato “Crea dipendenza” che catturi il minimo necessario per agire: progetto richiedente, risultato necessario, data target e impatto se mancante. Poi instrada automaticamente al team proprietario basandoti su una regola semplice (owner del servizio/componente, directory team, o owner selezionato manualmente).
L'accettazione deve essere esplicita: il team proprietario accetta, rifiuta o chiede chiarimenti. Evita le “accettazioni morbide”—falla diventare un pulsante che crea responsabilità e timbri la decisione.
Quando si accetta, richiedi una definition of done leggera: deliverable (es., endpoint API, revisione spec, export dati), test di accettazione o passo di verifica, e il firmatario per il lato richiedente.
Questo evita il caso comune in cui una dipendenza è “consegnata” ma inutilizzabile.
I cambiamenti sono normali; le sorprese no. Ogni modifica dovrebbe:
Dai agli utenti un chiaro flag a rischio con livelli di escalation (es., Team Lead → Program Lead → Exec Sponsor) ed eventuali SLA (risposta entro X giorni, aggiornamento ogni Y giorni). L'escalation deve essere un'azione di workflow, non un thread di messaggi arrabbiati.
Chiudi una dipendenza solo dopo due passaggi: evidenza di consegna (link, allegato o nota) e verifica da parte del richiedente (o chiusura automatica dopo una finestra definita). Cattura un breve campo retrospettivo (“cosa ci ha bloccato?”) per migliorare la pianificazione futura senza eseguire una postmortem completa.
La gestione delle dipendenze fallisce quando le persone non sanno chi può impegnarsi, chi può modificare e chi ha cambiato cosa. Un modello di permessi chiaro previene cambi accidentali di date, protegge lavori sensibili e costruisce fiducia tra i team.
Inizia con un set piccolo di ruoli e amplia solo quando serve:
Implementa permessi a livello di oggetto—dipendenze, progetti, milestone, commenti/note—e poi per azione:
Un buon default è il principio del least-privilege: i nuovi utenti non dovrebbero poter cancellare record o sovrascrivere impegni.
Non tutti i progetti devono avere la stessa visibilità. Aggiungi scope di visibilità come:
Definisci chi può accettare/rifiutare richieste e chi può cambiare date impegnate—di solito il team lead ricevente (o delegato). Rendi la regola esplicita nell'UI: “Solo il team proprietario può impegnare date.”
Infine, aggiungi un audit log per eventi chiave: cambi di stato, modifiche di date, cambi di ownership, aggiornamenti permessi e cancellazioni (incluso chi, quando e cosa è cambiato). Se supporti SSO, abbinalo all'audit log per rendere chiaro accesso e accountability.
Gli avvisi sono il punto in cui uno strumento per dipendenze diventa realmente utile—o diventa rumore che tutti imparano a ignorare. L'obiettivo è semplice: far muovere il lavoro tra i team notificando le persone giuste al momento giusto, con il giusto livello di urgenza.
Definisci gli eventi che contano di più per le dipendenze cross-funzionali:
Collega ogni trigger a un owner e a un “prossimo passo”, così una notifica non è solo informativa—è azionabile.
Supporta più canali:
Rendilo configurabile a livello utente e team. Un lead di dipendenza potrebbe volere ping Slack; uno sponsor esecutivo potrebbe preferire un riassunto email giornaliero.
I messaggi in tempo reale sono migliori per decisioni (accettare/rifiutare) ed escalation. I digest sono migliori per awareness (scadenze imminenti, elementi in attesa).
Includi impostazioni come: “immediato per assegnazioni”, “digest giornaliero per scadenze” e “riassunto settimanale per lo stato di salute”. Questo riduce la fatica da notifiche mantenendo le dipendenze visibili.
I promemoria dovrebbero rispettare giorni lavorativi, fusi orari e orari di silenzio. Per esempio: invia un promemoria 3 giorni lavorativi prima della scadenza e non notificare mai fuori dalle 9–18 ora locale.
Le escalation entrano in gioco quando:
Escala al livello responsabile successivo (team lead, program manager) e includi il contesto: cosa è bloccato, da chi e quale decisione è richiesta.
Le integrazioni rendono utile un'app per le dipendenze fin dal primo giorno perché la maggior parte dei team già traccia il lavoro altrove. L'obiettivo non è “sostituire Jira” (o Linear, GitHub, Slack)—è collegare le decisioni di dipendenza ai sistemi dove avviene l'esecuzione.
Inizia con strumenti che rappresentano lavoro, tempo e comunicazione:
Scegli 1–2 da pilotare per primi. Troppe integrazioni all'inizio possono trasformare il debug nel tuo lavoro principale.
Usa un import CSV one-time per bootstrapare dipendenze, progetti e owner esistenti. Mantieni il formato opinato (es., titolo dipendenza, team richiedente, team fornitore, data scadenza, stato).
Poi aggiungi sync continuo solo per i campi che devono rimanere coerenti (come lo stato dell'issue esterno o la data di scadenza). Questo riduce cambiamenti a sorpresa e facilita il troubleshooting.
Non tutti i campi esterni devono essere copiati nel tuo database.
Un pattern pratico: memorizza sempre gli ID esterni, sincronizza un piccolo set di campi e permetti override manuale solo dove la tua app è la source of truth.
Il polling è semplice ma rumoroso. Preferisci webhook quando possibile:
Quando arriva un evento, metti in coda un job background per recuperare il record via API e aggiornare l'oggetto dipendenza.
Scrivi quali sistemi possiedono ogni campo:
Regole chiare di source-of-truth prevengono “guerre di sync” e semplificano governance e audit.
I dashboard sono il punto in cui l'app guadagna fiducia: i leader smettono di chiedere “un'altra slide di stato” e i team smettono di inseguire aggiornamenti in chat. L'obiettivo non è una parete di grafici—è un modo rapido per rispondere a: “Cosa è a rischio, perché e chi è il prossimo a muoversi?”
Inizia con pochi flag di rischio che si possano calcolare in modo consistente:
Questi segnali devono essere visibili sia a livello di dipendenza sia aggregati a livello progetto/program.
Crea viste che rispecchino come si svolgono le riunioni di steering:
Un buon default è una singola pagina che risponde: “Cosa è cambiato dall'ultima settimana?” (nuovi rischi, blocker risolti, shift di date).
I dashboard spesso devono uscire dall'app. Aggiungi export che preservino il contesto:
Quando esporti, includi owner, date di scadenza, stato e ultimo commento così il file sia autonomo. Così i dashboard sostituiscono slide manuali invece di crearne di nuove.
L'obiettivo non è scegliere la tecnologia “perfetta”—è scegliere uno stack che il tuo team possa costruire e gestire con fiducia mantenendo le viste sulle dipendenze veloci e affidabili.
Un baseline pratico è:
Questo mantiene il sistema facile da capire: le azioni utente sono sincrone, mentre il lavoro lento (invio avvisi, ricalcolo metriche di salute) è asincrono.
La gestione dipendenze richiede query tipo “trova tutti gli elementi bloccati da X”. Un modello relazionale funziona bene, specialmente con gli indici giusti.
Al minimo, prevedi tabelle come Projects, Milestone/Deliverables e Dependencies (from_id, to_id, type, status, date, owners). Aggiungi indici per filtri comuni (team, stato, data scadenza, progetto) e per traversals (from_id, to_id). Questo evita che l'app rallenti mano a mano che i link crescono.
Grafo di dipendenze e timeline Gantt possono diventare costose. Scegli librerie che supportino la virtualizzazione (render solo ciò che è visibile) e aggiornamenti incrementali. Tratta le viste “mostrami tutto” come modalità avanzate, e defaulta su viste circoscritte (per progetto, per team, per intervallo di date).
Pagine di default, e cache dei risultati computati comuni (es., “conteggio bloccati per progetto”). Per i grafi, precarica solo il quartiere attorno a un nodo selezionato e poi espandi su richiesta.
Usa ambienti separati (dev/staging/prod), aggiungi monitoraggio e error tracking e registra eventi rilevanti per l'audit. Un'app per dipendenze diventa rapidamente una source of truth—downtime e failure silenziosi costano coordinazione reale.
Se l'obiettivo principale è validare workflow e UI rapidamente (inbox, acceptance, escalation, dashboard) prima di impegnare ingegneria, puoi prototipare un'app di gestione dipendenze su una piattaforma di vibe-coding come Koder.ai. Ti permette di iterare sul modello dati, ruoli/permessi e schermate chiave via chat, poi esportare il codice sorgente quando sei pronto per la produzione (comunemente React per la web, Go + PostgreSQL per il backend). Questo è utile per un pilot con 2–3 team dove la velocità di iterazione conta più dell'architettura perfetta al day one.
Un'app per dipendenze aiuta solo se le persone si fidano. Questa fiducia si guadagna con test accurati, un pilot contenuto e un rollout che non interrompa i team in piena delivery.
Inizia validando il “percorso felice”: un team richiede una dipendenza, il team proprietario accetta, il lavoro è consegnato e la dipendenza è chiusa con un risultato chiaro.
Poi prova gli edge case che spesso rompono l'uso reale:
Le app per dipendenze tendono a fallire quando i permessi sono troppo restrittivi (le persone non possono fare il loro lavoro) o troppo permissivi (i team perdono il controllo).
Testa scenari come:
Le alert devono far agire, non far spegnere l'attenzione.
Verifica:
Prima di coinvolgere i team, carica demo realistici di progetti, milestone e dipendenze cross-team. Buoni dati seed mettono in luce etichette confuse, stati mancanti e gap di report più velocemente dei record test sintetici.
Pilota con 2–3 team che si dipendono a vicenda. Imposta una finestra breve (2–4 settimane), raccogli feedback settimanali e iterare su:
Una volta che i team del pilot dicono che lo strumento fa risparmiare tempo, rilascia per ondate e pubblica un chiaro documento “come lavoriamo ora” (anche un semplice doc interno) linkato dall'intestazione dell'app in modo che le aspettative restino coerenti.
Inizia con una frase-problema che puoi ripetere: le dipendenze stanno causando ritardi perché responsabilità, tempistiche e stato non sono chiari. Poi scegli un piccolo set di risultati misurabili, come:
Se non puoi misurare il miglioramento, non potrai giustificare l'adozione.
Mantieni ruoli e bisogni semplici:
Progetta le viste predefinite attorno a “Cosa devo consegnare?” e “Cosa mi blocca?” invece che attorno agli oggetti del database.
Scrivi un paragrafo di definizione e attieniti a quello. Esempi comuni:
Questa definizione determina i campi richiesti, gli stati del workflow e come si dichiara “fatto”.
Un buon record minimo cattura chi ha bisogno di cosa, da chi, entro quando, più tracciabilità:
Evita campi opzionali che restano vuoti; rendi obbligatori i campi di instradamento.
Usa un flusso semplice condiviso e rendi esplicita l'accettazione:
L'accettazione dovrebbe essere un'azione deliberata (pulsante + timestamp), non qualcosa implicito in una conversazione. Questo crea responsabilità e report puliti.
Scegli una granularità che le persone già pianificano e su cui rendicontano:
Se le milestone diventano troppo dettagliate, gli aggiornamenti diventano lavoro e la qualità dei dati cala—riporta i dettagli a livello di ticket in Jira/Linear/etc.
Parti dal principio del minimo privilegio e proteggi gli impegni:
Questo evita modifiche accidentali e riduce le discussioni su “chi ha detto cosa”.
Inizia con trigger che richiedono davvero un'azione:
Offri alert in tempo reale per decisioni/escalation e digest per awareness (giornalieri/settimanali). Aggiungi throttling per evitare tempeste di notifiche.
Non cercare di sostituire gli strumenti di esecuzione. Usa integrazioni per connettere le decisioni dove il lavoro avviene:
Definisci regole di source-of-truth (es. Jira possiede lo stato dell'issue; la tua app possiede la relazione di dipendenza e le date di impegno).
Pilota con 2–3 team che si dipendono a vicenda per 2–4 settimane:
Espandi solo quando i team del pilot confermano che lo strumento fa risparmiare tempo; rilascia a ondate e pubblica una semplice pagina “come lavoriamo ora” linkabile dall'intestazione dell'app.