29 mar 2025·8 min
Costruire un'app web per gestire i flussi di moderazione dei contenuti
Impara a progettare e costruire un'app web per la moderazione dei contenuti: code, ruoli, policy, escalation, log di audit, analytics e integrazioni sicure.
Impara a progettare e costruire un'app web per la moderazione dei contenuti: code, ruoli, policy, escalation, log di audit, analytics e integrazioni sicure.
Prima di progettare un flusso di moderazione, decidi cosa stai effettivamente moderando e cosa significa “bene”. Un ambito chiaro evita che la coda si riempia di casi al limite, duplicati e richieste che non c'entrano.
Annota ogni tipo di contenuto che può creare rischio o danno per gli utenti. Esempi comuni includono testo generato dagli utenti (commenti, post, recensioni), immagini, video, livestream, campi profilo (nomi, bio, avatar), messaggi diretti, gruppi della community e inserzioni di marketplace (titoli, descrizioni, foto, prezzi).
Segnala anche le fonti: invii degli utenti, importazioni automatiche, modifiche a elementi esistenti e segnalazioni da altri utenti. Questo evita di costruire un sistema che funziona solo per le “nuove pubblicazioni” e ignora modifiche, ri-caricamenti o abusi nei DM.
La maggior parte dei team bilancia quattro obiettivi:
Sii esplicito su quale obiettivo è primario in ogni area. Ad esempio, abusi ad alta gravità possono privilegiare la velocità rispetto alla perfetta coerenza.
Elenca l'insieme completo di esiti richiesti dal tuo prodotto: approvare, rifiutare/rimuovere, modificare/oscurare, etichettare/blocco per età, limitare la visibilità, mettere sotto revisione, scalare a un responsabile e azioni a livello di account come avvertimenti, blocchi temporanei o ban.
Definisci obiettivi misurabili: tempo mediano e 95° percentile di revisione, dimensione del backlog, tasso di annullamento sui ricorsi, accuratezza delle policy da campionamento QA e percentuale di elementi ad alta gravità gestiti entro uno SLA.
Includi moderatori, team lead, policy, supporto, engineering e legale. Il disallineamento qui causa rifacimenti più tardi—soprattutto su cosa significhi “escalation” e chi detiene le decisioni finali.
Prima di costruire schermate e code, schizza il ciclo di vita completo di un singolo contenuto. Un workflow chiaro previene “stati misteriosi” che confondono i revisori, rompono le notifiche e rendono gli audit dolorosi.
Inizia con un modello di stato semplice, end-to-end, che puoi inserire in un diagramma e nel database:
Submitted → Queued → In review → Decided → Notified → Archived
Mantieni gli stati mutuamente esclusivi e definisci quali transizioni sono consentite (e da chi). Ad esempio: “Queued” può passare a “In review” solo quando è assegnato, e “Decided” dovrebbe essere immutabile salvo tramite un flusso di appeal.
Classificatori automatici, corrispondenze di parole chiave, limiti di velocità e segnalazioni degli utenti dovrebbero essere trattati come segnali, non decisioni. Un design con intervento umano mantiene il sistema onesto:
Questa separazione rende anche più semplice migliorare i modelli in seguito senza riscrivere la logica delle policy.
Le decisioni saranno contestate. Aggiungi flussi di prima classe per:
Modella i ricorsi come nuovi eventi di revisione anziché modificare la storia. In questo modo puoi raccontare tutta la storia di ciò che è successo.
Per audit e dispute, definisci quali passaggi devono essere registrati con timestamp e attori:
Se non riesci a spiegare una decisione in seguito, dovresti presumere che non sia avvenuta.
Uno strumento di moderazione vive o muore sul controllo degli accessi. Se tutti possono fare tutto, otterrai decisioni incoerenti, esposizione accidentale di dati e nessuna chiara responsabilità. Inizia definendo ruoli che corrispondono a come il tuo team Trust & Safety lavora realmente, poi traducili in permessi che la tua app può far rispettare.
La maggior parte dei team ha bisogno di un piccolo insieme di ruoli chiari:
Questa separazione aiuta a evitare “cambi di policy accidentali” e mantiene la governance delle policy distinta dall'applicazione quotidiana.
Implementa il controllo accessi basato sui ruoli in modo che ogni ruolo ottenga solo ciò di cui ha bisogno:
can_apply_outcome, can_override, can_export_data) invece che per pagina.Se in seguito aggiungi nuove funzionalità (export, automazioni, integrazioni di terze parti), potrai associarle ai permessi senza ridefinire tutta la struttura organizzativa.
Pianifica per più team fin da subito: pod per lingua, gruppi basati su regione o linee separate per prodotti diversi. Modella i team esplicitamente, poi limita code, visibilità dei contenuti e assegnazioni per team. Questo previene revisioni incrociate tra regioni e mantiene misurabili i carichi di lavoro per gruppo.
Gli admin a volte devono impersonare utenti per debug o per riprodurre un problema del revisore. Tratta l'impersonazione come un'azione sensibile:
Per azioni irreversibili o ad alto rischio, aggiungi approvazione amministrativa (o revisione a due persone). Quella piccola frizione protegge sia dagli errori che dall'abuso interno, mantenendo però rapida la moderazione di routine.
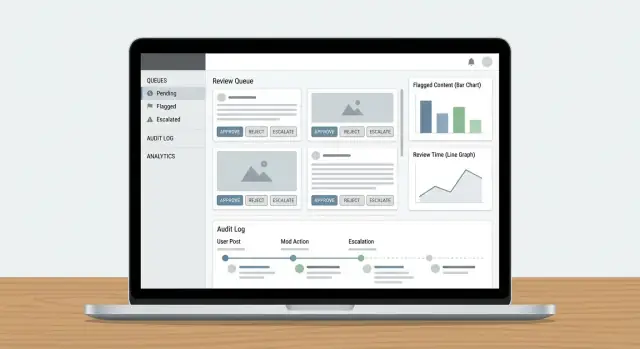
Le code rendono il lavoro di moderazione gestibile. Invece di una lista infinita, suddividi il lavoro in code che riflettano rischio, urgenza e intento—e rendi difficile che gli elementi cadano nelle crepe.
Inizia con un piccolo insieme di code che corrispondano a come il tuo team opera realmente:
Mantieni le code quanto più possibile mutuamente esclusive (un elemento dovrebbe avere una “casa”) e usa tag per attributi secondari.
All'interno di ogni coda, definisci regole di scoring che determinano cosa sale in cima:
Rendi le priorità spiegabili nell'UI (“Perché sto vedendo questo?”) così i revisori si fidano dell'ordinamento.
Usa claiming/locking: quando un revisore apre un elemento, viene assegnato a lui ed è nascosto agli altri. Aggiungi un timeout (es. 10–20 minuti) così gli elementi abbandonati ritornano in coda. Registra sempre eventi di claim, rilascio e completamento.
Se il sistema premia la velocità, i revisori possono scegliere i casi rapidi e saltare quelli difficili. Contrasta questo con:
L'obiettivo è copertura coerente, non solo alto throughput.
Una policy che esiste solo in PDF verrà interpretata diversamente da ogni revisore. Per rendere le decisioni coerenti (e auditabili), traduci il testo delle policy in dati strutturati e scelte nell'interfaccia che il workflow può far rispettare.
Inizia suddividendo la policy in un vocabolario condiviso che i revisori possono selezionare. Una tassonomia utile di solito include:
Questa tassonomia diventa la base per code, escalation e analisi successivamente.
Invece di chiedere ai revisori di scrivere una decisione da zero ogni volta, fornisci template di decisione collegati agli elementi della tassonomia. Un template può precompilare:
I template rendono il “percorso felice” rapido, pur permettendo eccezioni.
Le policy cambiano. Conserva le policy come record versionati con date di efficacia, e registra quale versione è stata applicata per ogni decisione. Questo evita confusione quando casi più vecchi vengono appellati e garantisce che tu possa spiegare gli esiti mesi dopo.
Il testo libero è difficile da analizzare e facile da dimenticare. Richiedi ai revisori di selezionare una o più motivazioni strutturate (dalla tua tassonomia) e opzionalmente aggiungere note. Le motivazioni strutturate migliorano la gestione dei ricorsi, il campionamento QA e i report di trend—senza costringere i revisori a scrivere saggi.
Un cruscotto per revisori ha successo quando minimizza la ricerca di informazioni e massimizza decisioni fiduciose e ripetibili. I revisori dovrebbero poter capire cosa è successo, perché è importante e cosa fare dopo—senza aprire cinque tab.
Non mostrare solo un post isolato e aspettarti coerenza. Presenta un pannello contesto compatto che risponda alle domande comuni a colpo d'occhio:
Mantieni la vista predefinita concisa, con opzioni di espansione per approfondire. I revisori dovrebbero raramente dover lasciare il cruscotto per decidere.
La barra delle azioni dovrebbe rispecchiare gli esiti di policy, non pulsanti CRUD generici. Pattern comuni includono:
Rendi visibili le azioni e rendi espliciti i passaggi irreversibili (conferma solo quando necessario). Registra un breve codice motivo più note opzionali per i successivi audit.
Il lavoro ad alto volume richiede bassa attrito. Aggiungi scorciatoie da tastiera per le azioni principali (approva, rifiuta, elemento successivo, aggiungi etichetta). Mostra una cheat-sheet delle scorciatoie nell'UI.
Per code con lavoro ripetitivo (es. spam ovvio), supporta la selezione in blocco con protezioni: mostra il conteggio in anteprima, richiedi un codice motivo e registra l'azione batch.
La moderazione può esporre le persone a materiale dannoso. Aggiungi impostazioni di sicurezza di default:
Queste scelte proteggono i revisori mantenendo le decisioni accurate e coerenti.
I log di audit sono la tua “fonte di verità” quando qualcuno chiede: Perché questo post è stato rimosso? Chi ha approvato il ricorso? È stato il modello o un umano a prendere la decisione finale? Senza tracciabilità, le indagini diventano congetture e la fiducia dei revisori crolla.
Per ogni azione di moderazione, registra chi l'ha fatta, cosa è cambiato, quando è avvenuto e perché (codice policy + note testuali). Ugualmente importante: conserva snapshot before/after degli oggetti rilevanti—testo del contenuto, hash dei media, segnali rilevati, etichette e risultato finale. Se l'elemento può cambiare (modifiche, cancellazioni), gli snapshot prevengono che “il record” deragli.
Un pattern pratico è un record evento append-only:
{
"event": "DECISION_APPLIED",
"actor_id": "u_4821",
"subject_id": "post_99102",
"queue": "hate_speech",
"decision": "remove",
"policy_code": "HS.2",
"reason": "slur used as insult",
"before": {"status": "pending"},
"after": {"status": "removed"},
"created_at": "2025-12-26T10:14:22Z"
}
Oltre alle decisioni, registra le meccaniche del workflow: claimed, released, timed out, reassigned, escalated e auto-routed. Questi eventi spiegano “perché ci sono volute 6 ore” o “perché questo elemento è rimbalzato tra i team” e sono essenziali per rilevare abusi (es. revisori che scelgono solo casi facili).
Dai agli investigatori filtri per utente, content ID, codice policy, intervallo temporale, coda e tipo di azione. Includi esportazione in un file di caso, con timestamp immutabili e riferimenti ad elementi correlati (duplicati, ri-caricamenti, ricorsi).
Stabilisci finestre di conservazione chiare per eventi di audit, snapshot e note dei revisori. Mantieni la policy esplicita (es. 90 giorni per i log di coda di routine, periodi più lunghi per legal hold) e documenta come le richieste di redazione o cancellazione influenzano le prove conservate.
Uno strumento di moderazione è utile solo se chiude il ciclo: le segnalazioni diventano task di revisione, le decisioni raggiungono le persone giuste e le azioni a livello utente vengono eseguite coerentemente. Qui molti sistemi falliscono—qualcuno risolve la coda, ma nulla cambia altrove.
Tratta segnalazioni utenti, flag automatici (spam/CSAM/hash match/segnali di tossicità) e escalation interne (supporto, community manager, legale) come lo stesso oggetto centrale: un report che può generare uno o più task di revisione.
Usa un unico router di report che:
Se le escalation dal supporto fanno parte del flusso, collegale direttamente (es. /support/tickets/1234) così i revisori non cambiano contesto.
Le decisioni di moderazione dovrebbero generare notifiche templated: contenuto rimosso, avvertimento emesso, nessuna azione o sanzione a livello di account. Mantieni i messaggi coerenti e minimali—spiega l'esito, fai riferimento alla policy rilevante e fornisci istruzioni per il ricorso.
Operativamente, invia notifiche tramite un evento come moderation.decision.finalized, così email/in-app/push possono sottoscriversi senza rallentare il revisore.
Le decisioni spesso richiedono azioni oltre un singolo contenuto:
Rendi queste azioni esplicite e reversibili, con durate e motivazioni chiare. Collega ogni azione alla decisione e al report sottostante per tracciabilità e fornisci un percorso rapido verso i ricorsi così le decisioni possono essere riconsiderate senza lavoro investigativo manuale.
Il tuo modello dati è la “fonte di verità” su ciò che è successo a ogni elemento: cosa è stato revisionato, da chi, sotto quale policy e quale è stato il risultato. Se questa layer è corretta, tutto il resto—code, cruscotti, audit e analisi—diventa più semplice.
Evita di memorizzare tutto in un unico record. Un pattern pratico è mantenere:
HARASSMENT.H1 o NUDITY.N3, memorizzati come riferimenti così le policy possono evolvere senza riscrivere la storia.Questo mantiene l'applicazione delle policy coerente e rende più chiare le reportistiche (es. “codici policy più violati questa settimana”).
Non mettere immagini/video grandi direttamente nel database. Usa object storage e conserva solo chiavi oggetto + metadata nella tabella content.
Per i revisori, genera short-lived signed URLs così i media sono accessibili senza renderli pubblici. Le signed URL permettono anche di controllare scadenza e revoca dell'accesso.
Code e indagini dipendono da lookup veloci. Aggiungi indici per:
Modella la moderazione come stati espliciti (es. NEW → TRIAGED → IN_REVIEW → DECIDED → APPEALED). Memorizza eventi di transizione di stato (con timestamp e attore) così puoi rilevare elementi che non sono avanzati.
Una salvaguardia semplice: un campo last_state_change_at più alert per elementi che superano uno SLA, e un job di riparazione che rimettere in coda gli elementi rimasti IN_REVIEW dopo un timeout.
Gli strumenti Trust & Safety spesso gestiscono i dati più sensibili del tuo prodotto: contenuti generati dagli utenti, segnalazioni, identificatori di account e talvolta richieste legali. Tratta l'app di moderazione come un sistema ad alto rischio e progetta sicurezza e privacy fin dall'inizio.
Inizia con autenticazione forte e controlli di sessione stretti. Per la maggior parte dei team questo significa:
Abbina questo al controllo accessi basato sui ruoli così i revisori vedono solo ciò di cui hanno bisogno (per esempio: una coda, una regione o un tipo di contenuto).
Cripta i dati in transito (HTTPS ovunque) e at rest (encryption gestita DB/storage). Poi concentrati sulla minimizzazione dell'esposizione:
Se gestisci consenso o categorie speciali di dati, rendi quei flag visibili ai revisori e applicali nell'UI (es. visualizzazione ristretta o regole di retention).
Gli endpoint di segnalazione e ricorso sono obiettivi frequenti per spam e molestie. Aggiungi:
Infine, rendi ogni azione sensibile tracciabile con un audit trail così puoi investigare errori dei revisori, account compromessi o abusi coordinati.
Inizia elencando ogni tipo di contenuto che gestirai (post, commenti, DM, profili, annunci, media), più ogni fonte (nuove segnalazioni, modifiche, importazioni, segnalazioni degli utenti, flag automatici). Poi definisci cosa è fuori scope (ad es. note interne amministrative, contenuti generati di sistema) così la tua coda non diventi una discarica.
Un controllo pratico: se non riesci a nominare il tipo di contenuto, la fonte e il team proprietario, probabilmente non dovrebbe ancora generare un task di moderazione.
Scegli un piccolo set di KPI operativi che riflettano sia velocità che qualità:
Definisci target per coda (es. high-risk vs backlog) così non ottimizzi per lavoro a bassa urgenza mentre contenuti dannosi restano in attesa.
Usa un modello di stato semplice e esplicito ed applica le transizioni consentite, ad esempio:
SUBMITTED → QUEUED → IN_REVIEW → DECIDED → NOTIFIED → ARCHIVEDRendi gli stati mutuamente esclusivi e tratta “Decided” come immutabile tranne che tramite un flusso di appeal/re-review. Questo previene “stati misteriosi”, notifiche rotte e modifiche difficili da auditare.
Tratta i sistemi automatici come segnali, non come esiti finali:
Questo mantiene l'applicazione delle policy spiegabile e facilita il miglioramento dei modelli senza riscrivere la logica decisionale.
Costruisci i ricorsi come oggetti di prima classe collegati alla decisione originale:
Inizia con un set RBAC chiaro:
Usa più code con una chiara proprietà “home”:
Dai priorità all'interno di una coda usando segnali spiegabili come gravità, portata, segnalazioni uniche e timer SLA. Nell'interfaccia mostra “Perché vedo questo?” così i revisori si fidano dell'ordine e puoi rilevare eventuali abusi.
Implementa claiming/locking con timeout:
Questo riduce lavoro duplicato e ti fornisce dati per diagnosticare colli di bottiglia e comportamenti di cherry-picking.
Trasforma la tua policy in una tassonomia strutturata e in template di decisione:
Questo migliora la coerenza, rende le analisi significative e semplifica audit e ricorsi.
Registra tutto il necessario per ricostruire la storia:
Rendi i log ricercabili per attore, content ID, codice policy, coda e intervallo temporale, e definisci regole di retention (inclusi legal hold e come le richieste di cancellazione influenzano le evidenze).
Registra sempre quale versione delle policy è stata applicata inizialmente e quale versione viene applicata durante il ricorso.
Poi applica il principio del minimo privilegio a livello di capability (es. can_export_data, can_apply_account_penalty) così nuove funzionalità non compromettono il modello di accesso.