15 mag 2025·8 min
Come costruire un'app web per l'arricchimento dei dati cliente
Impara a costruire un'app web che arricchisce i record clienti: architettura, integrazioni, matching, validazione, privacy, monitoraggio e consigli per il rollout.
Definisci obiettivi, utenti e ambito dell'arricchimento
Prima di scegliere strumenti o disegnare diagrammi architetturali, chiarisci precisamente cosa significa “arricchimento” per la tua organizzazione. I team spesso mescolano più tipi di arricchimento e poi fanno fatica a misurare i progressi — o discutono su cosa significhi “completo”.
Cosa conta come arricchimento?
Inizia nominando le categorie di campo che vuoi migliorare e perché:
- Firmografico: dimensione azienda, settore, sede centrale, fase di finanziamento
- Contatto: job title, email/telefono verificati, seniority, ruolo
- Comportamentale: segnali d'uso del prodotto, intenti, punteggi di engagement
- Campi personalizzati: territorio interno, livello account, punteggio di fit ICP
Annota quali campi sono obbligatori, quali sono desiderabili e quali non devono mai essere arricchiti (per esempio attributi sensibili).
Chi userà l'app — e per cosa?
Identifica gli utenti principali e i loro compiti principali:
- Sales ops: ridurre i duplicati, standardizzare account, migliorare il routing
- Marketing ops: arricchire lead per segmentazione e targeting più efficaci
- Support: mostrare il contesto account durante i ticket
- Analisti: dataset affidabili per reportistica
Ogni gruppo utente tende a necessitare flussi diversi (elaborazione in blocco vs revisione singola), quindi cattura questi bisogni fin da subito.
Definisci risultati, confini e metriche di successo
Elenca risultati in termini misurabili: tasso di match più alto, meno duplicati, routing lead/account più veloce o miglior performance della segmentazione.
Stabilisci confini chiari: quali sistemi sono in scope (CRM, fatturazione, analytics prodotto, support desk) e quali no — almeno per la prima release.
Infine, concorda metriche di successo e tassi di errore accettabili (es. copertura arricchimento, tasso di verifica, tasso di duplicati e regole di “fail sicuro” quando l'arricchimento è incerto). Questo diventa la tua stella polare per il resto del progetto.
Modella i dati cliente e identifica i gap
Prima di arricchire qualsiasi cosa, chiarisci cosa significa “cliente” nel tuo sistema — e cosa già sai di lui. Questo evita di pagare per arricchimenti che non puoi salvare e previene fusioni confuse in seguito.
Fai l'inventario dei campi e delle sorgenti attuali
Inizia con un catalogo semplice di campi (es. nome, email, azienda, dominio, telefono, indirizzo, job title, settore). Per ogni campo, annota da dove proviene: input utente, import CRM, sistema di fatturazione, tool di supporto, form di registrazione prodotto o un provider di arricchimento.
Cattura anche come è raccolto (obbligatorio vs opzionale) e quanto spesso cambia. Per esempio, job title e dimensione azienda cambiano nel tempo, mentre un ID cliente interno non dovrebbe mai cambiare.
Definisci il modello d'identità: persona, azienda, account
La maggior parte dei workflow di arricchimento coinvolge almeno due entità:
- Persona (contatto/lead): individuo con email, telefoni, ruoli
- Azienda (organizzazione): impresa con dominio, località, firmografici
Decidi se serve anche un Account (una relazione commerciale) che colleghi più persone a un'azienda con attributi come piano, date contrattuali e stato.
Scrivi le relazioni che supporti (es. molte persone → una azienda; una persona → più aziende nel tempo).
Documenta i problemi di dati comuni
Elenca i problemi ricorrenti: valori mancanti, formati incoerenti ("US" vs "United States"), duplicati creati da import, record obsoleti e fonti in conflitto (indirizzo fatturazione vs indirizzo CRM).
Scegli chiavi necessarie e imposta livelli di fiducia
Scegli gli identificatori che userai per matching e aggiornamenti — tipicamente email, dominio, telefono e un ID cliente interno.
Assegna a ciascuno un livello di fiducia: quali chiavi sono autorevoli, quali sono “best effort” e quali non devono mai essere sovrascritte.
Chiarisci proprietà e permessi di modifica
Concorda chi possiede quali campi (Sales ops, Support, Marketing, Customer success) e definisci regole di modifica: cosa può cambiare un umano, cosa può cambiare l'automazione e cosa richiede approvazione.
Questa governance fa risparmiare tempo quando i risultati di arricchimento confliggono con i dati esistenti.
Scegli sorgenti di arricchimento e contratti dati
Prima di scrivere codice di integrazione, decidi da dove arriveranno i dati di arricchimento e cosa sei autorizzato a farne. Questo evita un fallimento comune: consegnare una funzione che funziona tecnicamente ma viola costi, affidabilità o regole di conformità.
Sorgenti tipiche di arricchimento
Di solito combinerai più input:
- Sistemi interni: CRM, fatturazione, ticket di supporto, analytics prodotto, piattaforma email, data warehouse
- API di terze parti: firmografici aziendali, validazione contatti, codici di settore, tecnografici, segnali di rischio
- Liste caricate: CSV da sales, eventi, partner o data provider
- Webhook: aggiornamenti in tempo reale da tool che già osservano cambiamenti (es. verifica email, identity provider)
Come valutare le sorgenti
Per ogni sorgente, valutala su copertura (quanto spesso restituisce informazioni utili), freschezza (quanto rapidamente si aggiorna), costo (per chiamata/per record), limiti di velocità e termini d'uso (cosa puoi memorizzare, quanto a lungo e per quale scopo).
Verifica anche se il provider restituisce punteggi di confidenza e una provenienza chiara (da dove proviene un campo).
Definisci un contratto dati
Tratta ogni sorgente come un contratto che specifica nomi e formati dei campi, campi richiesti vs opzionali, frequenza di aggiornamento, latenza prevista, codici d'errore e semantica della confidenza.
Includi una mappatura esplicita ("campo provider → tuo campo canonico") e regole per null e valori in conflitto.
Decisioni su fallback e storage
Pianifica cosa succede quando una sorgente non è disponibile o restituisce risultati a bassa confidenza: retry con backoff, mettere in coda per elaborazione successiva o usare una sorgente secondaria.
Decidi cosa memorizzi (attributi stabili necessari per ricerca/report) e cosa calcoli al volo (lookup costosi o sensibili al tempo).
Infine, documenta restrizioni sulla memorizzazione di attributi sensibili (es. identificatori personali, demografici inferiti) e imposta regole di retention.
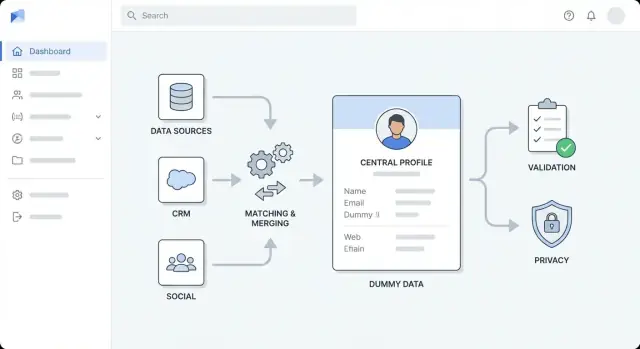
Progetta l'architettura ad alto livello
Prima di scegliere strumenti, decidi la forma dell'app. Un'architettura chiara mantiene prevedibile il lavoro di arricchimento, evita "fix rapidi" diventati permanenti e aiuta il team a stimare lo sforzo.
Scegli uno stile architetturale adatto al team
Per la maggior parte dei team, inizia con un monolite modulare: un'unica applicazione distribuibile, internamente divisa in moduli ben definiti (ingestione, matching, arricchimento, UI). È più semplice da costruire, testare e debug.
Passa a servizi separati quando c'è una ragione chiara — ad es. throughput di arricchimento alto, necessità di scalare indipendentemente o team differenti che possiedono parti diverse. Una suddivisione comune è:
- Servizio API (richieste sync, auth, CRUD record)
- Worker (arricchimento asincrono, retry)
- UI (review, approvazioni, azioni batch)
Separa le responsabilità in layer
Mantieni confini espliciti per evitare che le modifiche si propaghino ovunque:
- Layer di ingestione: import da CRM/file e normalizzazione input
- Layer di arricchimento: chiamate a vendor/sorgenti interne e salvataggio risultati
- Layer di validazione: regole di qualità dati e segnalazione eccezioni
- Layer di storage: profili cliente, payload raw, cronologia audit
- Layer di presentazione: viste UI, code di revisione, approvazioni
Progetta l'arricchimento asincrono fin dall'inizio
L'arricchimento è lento e soggetto a errori (rate limit, timeout, dati parziali). Trattalo come job:
- L'API crea un job e risponde rapidamente
- I worker processano i job tramite una coda (con retry e backoff)
- La UI mostra lo stato del job e permette di rilanciarlo se necessario
Pianifica ambienti e configurazione
Allestisci dev/staging/prod presto. Conserva chiavi vendor, soglie e feature flag in configurazione (non nel codice) e rendi facile cambiare provider per ambiente.
Allinea con un diagramma su una pagina
Schizza un diagramma semplice che mostri: UI → API → database, più queue → worker → provider di arricchimento. Usalo nelle review così tutti concordano sulle responsabilità prima dell'implementazione.
Prototipazione rapida (opzionale)
Se l'obiettivo è validare workflow e schermate di revisione prima di investire in un ciclo d'ingegneria completo, una piattaforma di vibe-coding come Koder.ai può aiutare a prototipare rapidamente l'app core: UI React per revisione/approvazioni, layer API in Go e storage su PostgreSQL.
Questo è utile per provare il modello di job (arricchimento asincrono con retry), la cronologia di audit e i pattern di accesso basati sui ruoli, poi esportare il codice sorgente quando sei pronto per la produzione.
Configura storage, code e servizi di supporto
Prima di collegare provider di arricchimento, sistema gli "impicci". Le decisioni su storage e background processing sono difficili da cambiare dopo e impattano affidabilità, costi e auditabilità.
Database primario: profili + storico
Scegli un database primario per i profili cliente che supporti dati strutturati e attributi flessibili. Postgres è una scelta comune perché può memorizzare campi core (nome, dominio, settore) affiancati ad attributi semi-strutturati (JSON).
Ugualmente importante: memorizza la cronologia delle modifiche. Invece di sovrascrivere valori silenziosamente, registra chi/cosa ha cambiato un campo, quando e perché (es. “vendor_refresh”, “manual_approval”). Questo facilita le approvazioni e semplifica rollback.
Coda: arricchimento e retry
L'arricchimento è intrinsecamente asincrono: API rate-limit, reti falliscono e alcuni vendor rispondono lentamente. Aggiungi una job queue per il lavoro in background:
- Richieste di arricchimento (singole e bulk)
- Retry con backoff
- Refresh pianificati (es. ogni 30/90 giorni)
- Dead-letter per job che falliscono ripetutamente
Questo mantiene la UI reattiva e impedisce che problemi con i vendor abbattano l'app.
Cache: lookup veloci e tracking rate-limit
Una piccola cache (spesso Redis) aiuta lookup frequenti (es. “azienda per dominio”) e traccia i limiti dei vendor e le finestre di cooldown. È utile anche per chiavi di idempotenza così import ripetuti non scatenano arricchimenti duplicati.
Storage di file e retention
Pianifica object storage per import/export CSV, report di errori e file “diff” usati nei flussi di revisione.
Definisci regole di retention presto: conserva i payload raw dei vendor solo quanto necessario per debug e audit, ed elimina i log secondo una policy conforme.
Costruisci pipeline di ingestione e normalizzazione
Costruisci rapidamente l'app core
Genera un'interfaccia di revisione in React con una API in Go e PostgreSQL come backend in un unico posto.
La tua app di arricchimento è buona quanto i dati che le fornisci. L'ingestione è dove decidi come le informazioni entrano nel sistema, e la normalizzazione è dove rendi quei dati abbastanza coerenti per matchare, arricchire e riportare.
Decidi come i dati entrano
La maggior parte dei team ha bisogno di un mix di punti d'ingresso:
- Endpoint API per il tuo prodotto o tool interni per inviare nuovi/aggiornati clienti
- Webhook da CRM o sistemi di fatturazione per cambi near-real-time
- Pull schedulati (sync notturno) per sistemi che non supportano push
- Import CSV per backfill e upload una tantum
Qualunque cosa supporti, mantieni il passo di “raw ingest” leggero: accetta dati, autentica, registra metadata e mette in coda il lavoro per l'elaborazione.
Normalizza e standardizza presto
Crea un layer di normalizzazione che trasformi input disordinati in una forma interna coerente:
- Nomi: trim spazi, separa nome completo quando possibile, gestisci il casing
- Telefoni: converti in formato E.164 e memorizza assunzioni sul paese
- Indirizzi: standardizza campi (street, locality, region, postal code) e conserva il testo originale
- Domini/email: minuscolo, rimuovi parametri di tracciamento dagli URL, valida sintassi
Valida, metti in quarantena e resta idempotente
Definisci campi richiesti per tipo di record e rifiuta o metti in quarantena record che non superano i controlli (es. email/domino mancanti per il matching azienda). Gli elementi in quarantena devono essere visibili e correggibili nella UI.
Aggiungi chiavi di idempotenza per evitare doppie elaborazioni quando avvengono retry (comune con webhook e reti instabili). Un approccio semplice è hashare (source_system, external_id, event_type, event_timestamp).
Traccia la lineage per campo
Memorizza la provenienza per ogni record e, idealmente, per ogni campo: sorgente, tempo di ingestione e versione della trasformazione. Questo rende le domande successive chiaramente rispondibili: “Perché questo numero di telefono è cambiato?” o “Quale import ha prodotto questo valore?”.
Implementa matching, deduplicazione e merge
Arricchire correttamente dipende dall'identificare affidabilmente chi è chi. L'app necessita regole di matching chiare, comportamento di merge prevedibile e una rete di sicurezza quando il sistema non è sicuro.
Definisci regole di matching (e soglie di confidenza)
Inizia con identificatori deterministici:
- Chiavi esatte: email (normalizzata in minuscolo), ID cliente, partita IVA o dominio verificato
Poi aggiungi matching probabilistico per casi in cui mancano chiavi esatte:
- Match fuzzy: nome + dominio azienda, nome + località, somiglianza telefono
Assegna un punteggio di match e imposta soglie, ad esempio:
- Auto-merge solo sopra una soglia alta
- Metti in coda per revisione manuale nell'intervallo “forse”
- Rifiuta sotto una soglia bassa
Pianifica logica di deduplicazione e merge
Quando due record rappresentano lo stesso cliente, decidi come scegliere i campi:
- Precedenza dei campi: “email verificata batte non verificata”, “timestamp più recente vince”, “CRM sovrascrive l'arricchimento per ownership del contatto”
- Punteggi di fiducia delle sorgenti: classifica le sorgenti (CRM, fatturazione, provider di arricchimento) per risolvere conflitti
- Gestione dei conflitti: conserva entrambi i valori dove possibile (es. più numeri di telefono) o archivia il valore perdente nello storico
Cronologia audit e workflow di revisione
Ogni merge dovrebbe creare un evento di audit: chi/che cosa l'ha innescato, valori prima/dopo, punteggio di match e ID dei record coinvolti.
Per match ambigui, fornisci una schermata di revisione con confronto affiancato e opzioni “unisci / non unire / chiedi più dati”.
Salvaguardie contro fusioni massive accidentali
Richiedi conferme extra per merge bulk, limita i merge per job e supporta anteprime in “dry run”.
Aggiungi anche una via di undo (o inversione del merge) usando la cronologia audit così gli errori non siano permanenti.
Integra API di arricchimento e gestisci l'affidabilità
L'arricchimento è il punto in cui la tua app incontra il mondo esterno — molti provider, risposte incoerenti e disponibilità imprevedibile.
Tratta ogni provider come un connettore “pluggabile” così puoi aggiungere, sostituire o disabilitare sorgenti senza toccare il resto della pipeline.
Costruisci connettori provider (auth, retry, mappatura errori)
Crea un connettore per ogni provider di arricchimento con un'interfaccia coerente (es. enrichPerson(), enrichCompany()). Mantieni la logica specifica del provider dentro il connettore:
- Autenticazione (API key, token OAuth, refresh token)
- Retry standardizzati per errori transitori
- Mappatura errori (trasforma errori provider nelle tue categorie come
invalid_request,not_found,rate_limited,provider_down)
Questo semplifica i workflow a valle: gestiscono i tuoi tipi d'errore, non le peculiarità di ogni provider.
Gestisci rate limit con throttling e backoff
La maggior parte delle API di arricchimento impone quote. Aggiungi throttling per provider (e a volte per endpoint) per restare sotto i limiti.
Quando raggiungi un limite, usa backoff esponenziale con jitter e rispetta gli header Retry-After se forniti.
Prevedi anche i "slow failure": timeout e risposte parziali devono essere trattati come eventi retryabili, non come drop silenziosi.
Memorizza confidenza e evidenze (nel rispetto delle policy)
I risultati di arricchimento raramente sono assoluti. Memorizza i punteggi di confidenza forniti dal provider quando disponibili, oltre al tuo punteggio basato su qualità del match e completezza del campo.
Dove consentito da contratto e policy privacy, conserva evidenze raw (URL sorgente, identificatori, timestamp) per supportare audit e fiducia degli utenti.
Strategia multi-provider: selezione del “migliore disponibile”
Supporta più provider definendo regole di selezione: cheapest-first, highest-confidence o selezione campo-per-campo “migliore disponibile”.
Registra quale provider ha fornito ogni attributo per poter spiegare cambi e ripristinare se necessario.
Regole di refresh pianificate
L'arricchimento invecchia. Implementa politiche di refresh come “riarricchire ogni 90 giorni”, “refresh su modifica di campo chiave” o “refresh solo se la confidenza cala”.
Rendi gli schedule configurabili per cliente e per tipo di dato per controllare costi e rumore.
Aggiungi regole di qualità dati e validazione
Testa revisione e approvazioni
Crea schermate di revisione per le fusioni e la cronologia di audit in anticipo, prima di impegnarti nella piena implementazione.
L'arricchimento aiuta solo se i nuovi valori sono affidabili. Tratta la validazione come una funzionalità di primo piano: protegge gli utenti da import sporchi, risposte terze parti inaffidabili e corruzione accidentale durante i merge.
Definisci regole di validazione a livello di campo
Inizia con un semplice “catalogo regole” per campo, condiviso da UI, pipeline di ingestione e API pubbliche.
Regole comuni includono controlli di formato (email, telefono, CAP), valori consentiti (codici paese, liste di settore), range (numero dipendenti, fasce di fatturato) e dipendenze richieste (se country = US, allora state è richiesto).
Mantieni le regole versionate così puoi cambiarle in sicurezza nel tempo.
Aggiungi controlli qualità che riflettano l'uso reale
Oltre alla validazione base, esegui controlli qualità che rispondano a domande di business:
- Completezza: abbiamo i campi minimi per usare il record?
- Unicità: identificatori “unici” (dominio, partita IVA) sono duplicati?
- Coerenza: campi correlati concordano (paese vs prefisso telefono)?
- Tempestività: quanto è vecchio un valore e andrebbe rinfrescato?
Scoraggia record e sorgenti
Trasforma i controlli in una scheda di qualità: a livello record (salute complessiva) e a livello sorgente (quanto spesso fornisce valori validi e aggiornati).
Usa il punteggio per guidare l'automazione — per esempio, applica automaticamente gli arricchimenti solo sopra una certa soglia.
Instrada i fallimenti in modo prevedibile
Quando un record non supera la validazione, non scartarlo.
Invialo a una coda “data-quality” per retry (problemi transitori) o revisione manuale (input errato). Memorizza payload fallito, regole violate e suggerimenti di correzione.
Rendi gli errori comprensibili
Restituisci messaggi chiari e azionabili per import e client API: quale campo è fallito, perché e un esempio di valore valido.
Questo riduce il carico sul supporto e accelera la pulizia.
Crea la UI per revisione, approvazioni e lavoro in blocco
La pipeline di arricchimento offre valore quando le persone possono rivedere cosa è cambiato e spingere con fiducia gli aggiornamenti nei sistemi a valle.
La UI dovrebbe rendere ovvio “cosa è successo, perché e cosa devo fare dopo?”.
Schermate principali da progettare
La scheda profilo cliente è la base. Mostra identificatori chiave (email, dominio, nome azienda), valori correnti e un badge di stato arricchimento (es. Non arricchito, In corso, Richiede revisione, Approvato, Rifiutato).
Aggiungi una timeline della cronologia delle modifiche che spieghi gli aggiornamenti in linguaggio semplice: “Dimensione azienda aggiornata da 11–50 a 51–200.” Rendi ogni voce cliccabile per vedere i dettagli.
Fornisci suggerimenti di merge quando vengono rilevati duplicati. Mostra i due (o più) record candidati affiancati con il record “survivor” raccomandato e un’anteprima del risultato del merge.
Lavoro in blocco che rispecchia le operazioni reali
La maggior parte dei team lavora per batch. Includi azioni bulk come:
- Arricchire record selezionati (o metterli in coda per processo notturno)
- Approvare/rifiutare merge suggeriti
- Esportare risultati (CSV) per audit o revisione offline
Usa un passaggio di conferma chiaro per azioni distruttive (merge, overwrite) con una finestra di “undo” quando possibile.
Ricerca veloce, filtri e provenance a livello di campo
Aggiungi ricerca globale e filtri per email, dominio, azienda, stato e punteggio di qualità.
Permetti di salvare viste come “Richiede revisione” o “Aggiornamenti a bassa confidenza”.
Per ogni campo arricchito mostra la provenienza: sorgente, timestamp e confidenza.
Un semplice pannello “Perché questo valore?” costruisce fiducia e riduce scambi continui.
Workflow guidati per utenti non tecnici
Mantieni le decisioni binarie e guidate: “Accetta valore suggerito”, “Mantieni esistente” o “Modifica manualmente”. Se serve controllo più profondo, nascondilo dietro un toggle “Avanzate” invece di renderlo predefinito.
Sicurezza, privacy e basi di conformità
Prototipa il workflow di arricchimento
Prototipa la tua app di arricchimento da un piano in chat, poi perfezionala con la modalità di pianificazione.
Le app di arricchimento cliente toccano identificatori sensibili (email, telefono, dettagli aziendali) e spesso attingono da terze parti. Tratta sicurezza e privacy come funzionalità core, non come attività “da dopo”.
Controllo accessi basato su ruoli (RBAC)
Inizia con ruoli chiari e default a minimo privilegio:
- Admin: gestisce utenti, ruoli, connettori e policy di retention
- Ops: esegue job di arricchimento, risolve conflitti, approva merge
- Viewer: accesso in sola lettura per report e supporto
Mantieni permessi granulari (es. “esporta dati”, “visualizza PII”, “approva merge”) e separa ambienti così i dati di produzione non siano disponibili in dev.
Proteggi i dati sensibili
Usa TLS per tutto il traffico e crittografia at-rest per database e object storage.
Conserva le API key in un secrets manager (non in file env nel codice), ruotale regolarmente e limita lo scope per ambiente.
Se mostri PII nella UI, adotta default sicuri come campi mascherati (es. mostra le ultime 2–4 cifre) e richiedi permessi espliciti per rivelare valori completi.
Consenso e vincoli d'uso dei dati
Se l'arricchimento dipende da consenso o termini contrattuali specifici, codifica quei vincoli nel workflow:
- Traccia sorgente dati, scopo e usi consentiti per campo
- Documenta cosa conservi e perché (una breve policy interna come /privacy o /docs/data-handling aiuta)
- Evita di raccogliere campi non necessari — meno dati significa meno rischio
Audit, retention e cancellazione
Crea una traccia di audit sia per accessi che per modifiche:
- Registra chi ha visto/esportato record
- Registra chi ha cambiato cosa e quando (valori prima/dopo, job ID, provider arricchimento)
Infine, supporta le richieste di privacy con strumenti pratici: policy di retention, cancellazione record e workflow di “dimentica” che rimuovono anche copie in log, cache e backup dove possibile (o le segnano per scadenza).
Monitoraggio, analytics e controlli operativi
Il monitoraggio non è solo uptime — è come mantieni l'arricchimento affidabile mentre volumi, provider e regole cambiano.
Tratta ogni esecuzione di arricchimento come un job misurabile con segnali chiari che puoi trendare nel tempo.
Metriche che aiutano davvero
Inizia con un piccolo set di metriche operative legate a risultati:
- Throughput job (record/min) e time-to-complete per run
- Success rate vs failure rate, suddivisi per tipo di errore (validazione, matching, provider)
- Latenza provider (p50/p95) e timeout per sorgente di arricchimento
- Match rate (quanto spesso colleghiamo con confidenza)
- Duplicati prevenuti (quanti sarebbero stati fusi in modo errato senza i controlli)
Questi numeri rispondono rapidamente: “Stiamo migliorando i dati o li stiamo solo spostando?”.
Alert e guardrail
Aggiungi alert che scattano su cambi, non sul rumore:
- Picchi di failure o record in quarantena
- Accumuli in coda o consumer lenti (segnale di pipeline bloccata)
- Raffiche di errori provider (429/5xx), aumento della latenza o timeout
Collega gli alert ad azioni concrete, come mettere in pausa un provider, abbassare la concorrenza o passare a dati cache/stale.
Dashboard operativa per gli operatori
Fornisci una vista admin per run recenti: stato, conteggi, retry e lista di record in quarantena con motivazioni.
Includi controlli di “replay” e azioni bulk sicure (retry per timeout provider, rilanciare solo matching).
Tracciabilità con log
Usa log strutturati e un correlation ID che segua un record end-to-end (ingest → match → arricchimento → merge).
Questo accelera molto supporto clienti e debug incidenti.
Playbook incidenti e rollback
Scrivi playbook brevi: cosa fare quando un provider degrada, quando il match rate crolla o quando i duplicati sfuggono.
Mantieni un'opzione di rollback (es. revert dei merge per una finestra temporale) e documentala in /runbooks.
Test, rollout e piano di iterazione
I test e il rollout sono dove un'app di arricchimento diventa sicura da usare. L'obiettivo non è “più test” ma fiducia che matching, merging e validazione si comportino in modo prevedibile con dati reali e disordinati.
Testa prima le parti rischiose
Dai priorità ai test sulla logica che può danneggiare silenziosamente i record:
- Regole di matching: test unitari per match esatti, fuzzy e compositi (es. email + dominio azienda). Includi near-duplicate e campi scambiati.
- Esiti dei merge: testa precedenza campi (priorità sorgente), gestione conflitti e regole “non sovrascrivere”.
- Casi limite di validazione: email malformate, formati telefonici internazionali, paese mancante, identificatori duplicati e valori “unknown”.
Usa dataset sintetici (nomi, domini, indirizzi generati) per validare accuratezza senza esporre dati reali.
Mantieni un set “golden” versionato con output di match/merge attesi così le regressioni sono evidenti.
Gradualità del rollout per ridurre il raggio d'azione
Inizia in piccolo, poi espandi:
- Pilot: un team o un segmento (es. solo SMB lead)
- Azioni limitate: inizia con “aggiornamenti suggeriti” che richiedono approvazione prima di scrivere nel CRM
- Rampa: aumenta il volume dei record, poi abilita scritture automatiche per campi a basso rischio
Definisci metriche di successo prima di partire (precisione match, tasso di approvazione, riduzione delle modifiche manuali e tempo per arricchire).
Documenta workflow e checklist di integrazione
Crea documenti brevi per utenti e integratori (link dall'area prodotto o /pricing se limiti funzionalità). Includi una checklist di integrazione:
- Metodo di auth API, rate limit e comportamento di retry
- Campi richiesti per richieste di arricchimento
- Payload webhook/event (e versioning)
- Codici d'errore e regole di “arricchimento parziale”
- Aspettative su audit log e retention
Per migliorare continuamente, programma un cadence leggero di review: analizza validazioni fallite, override manuali frequenti e mismatch, poi aggiorna regole e aggiungi test.
Un riferimento pratico per irrigidire le regole: /blog/data-quality-checklist.
Costruire vs accelerare: nota pratica
Se conosci già i workflow target ma vuoi accorciare il tempo da specifica → app funzionante, considera l'uso di Koder.ai per generare un'implementazione iniziale (UI React, servizi Go, storage PostgreSQL) a partire da un piano strutturato in chat.
I team spesso usano questo approccio per allestire rapidamente UI di revisione, processamento job e cronologia audit — poi iterano con modalità di pianificazione, snapshot e rollback man mano che i requisiti evolvono. Quando serve pieno controllo, puoi esportare il codice sorgente e continuare nella tua pipeline. Koder.ai offre tier free, pro, business ed enterprise per adattare sperimentazione e produzione.