16 mar 2025·8 min
Crea un'app web per le escalation clienti e il supporto prioritario
Scopri come pianificare, progettare e costruire un'app web che instrada le escalation, applica le SLA e mantiene il supporto prioritario organizzato con workflow e report chiari.
Chiarisci il workflow di escalation e gli obiettivi
Prima di costruire schermate o scrivere codice, decidi a cosa serve l'app e quale comportamento deve far rispettare. Le escalation non sono solo “clienti arrabbiati”: sono ticket che richiedono gestione più rapida, maggiore visibilità e coordinamento più stretto.
Cosa conta come escalation?
Definisci i criteri di escalation in linguaggio semplice così agenti e clienti non devono indovinare. Trigger comuni includono:
- Un'interruzione o degrado grave
- Un cliente VIP o con contratto di “supporto prioritario”
- Una imminente violazione di SLA (o violazioni ripetute)
- Un problema che impatta sicurezza, fatturazione o aspetti legali
Definisci anche cosa non è un'escalation (per esempio domande su come fare, richieste di funzionalità, bug minori) e come quelle richieste dovrebbero essere instradate invece.
Ruoli e responsabilità
Elenca i ruoli di cui il workflow ha bisogno e cosa può fare ciascun ruolo:
- Agente: triage e risolve, aggiorna il ticket, segue playbook
- Lead: esamina le escalation, riassegna il lavoro, approva i cambi di priorità
- Manager: si occupa di reportistica, standard di comunicazione col cliente, policy di escalation
- On-call: riceve alert urgenti e prende immediata ownership fuori orario
- Admin cliente: invia e monitora ticket, aggiunge stakeholder interni
Annota chi è il proprietario del ticket in ogni fase (inclusi i passaggi di consegna) e cosa significa “ownership” (obbligo di risposta, tempo per il prossimo aggiornamento e autorità per eseguire escalation).
Canali da supportare per primi
Parti con un set ridotto di input per poter rilasciare prima e mantenere il triage coerente. Molte squadre iniziano con email + form web, poi aggiungono chat quando le SLA e l'instradamento sono stabili.
Obiettivi e metriche di successo
Scegli risultati misurabili che l'app dovrebbe migliorare:
- Tempo alla prima risposta (generale e per le escalation)
- Tempo di risoluzione o tempo alla mitigazione per gli incidenti
- Tasso di riapertura e numero di “ping richiesti per aggiornamento”
- Tasso di SLA mancati e tempo passato senza proprietario
Queste decisioni diventano i requisiti di prodotto per il resto della build.
Progetta il modello dati per ticket, SLA ed escalation
Un'app di supporto prioritario vive o muore per il suo modello dati. Se metti bene le fondamenta, instradamento, reportistica e enforcement delle SLA diventano più semplici—perché il sistema avrà i fatti necessari.
Parti dai “fondamentali” del ticket (cosa gli agenti devono sempre sapere)
Al minimo, ogni ticket dovrebbe catturare: richiedente (un contatto), azienda (account cliente), oggetto, descrizione e allegati. Tratta la descrizione come la dichiarazione originale del problema; gli aggiornamenti successivi appartengono ai commenti così puoi vedere come si è evoluta la storia.
Aggiungi campi specifici per l'escalation (cosa rende questo “prioritario”)
Le escalation richiedono più struttura rispetto al supporto generale. Campi comuni includono severity (quanto grave), impact (quanti utenti/che ricavo), e priority (quanto velocemente risponderai). Aggiungi un campo servizio interessato (es. Billing, API, App Mobile) così il triage può instradare velocemente.
Per le scadenze, memorizza orari dovuti espliciti (come “first response due” e “resolution/next update due”), non solo un “nome SLA”. Il sistema può calcolare questi timestamp, ma gli agenti dovrebbero vedere gli orari esatti.
Modella le relazioni per il lavoro reale
Un modello pratico di solito include:
- Customers → molti Contacts
- Customers → molti Tickets
- Tickets → molti Comments (interni + pubblici)
- Tickets → molti Tasks (checklist, follow-up)
Questo mantiene la collaborazione pulita: conversazioni nei commenti, elementi d'azione nelle task e ownership sul ticket.
Definisci stati di status (e mantienili coerenti)
Usa un set di status piccolo e stabile come: New, Triaged, In Progress, Waiting, Resolved, Closed. Evita status “quasi uguali”—ogni stato in più rende meno affidabili report e automazioni.
Decidi cosa deve essere immutabile per audit
Per il tracciamento SLA e la responsabilità, alcuni dati dovrebbero essere append-only: timestamp di creazione/aggiornamento, cronologia dei cambi di stato, eventi di start/stop SLA, cambi di escalation e chi ha fatto ogni modifica. Preferisci un audit log (o tabella eventi) in modo da ricostruire cosa è successo senza congetture.
Imposta livelli di priorità e regole SLA
Le regole di priorità e SLA sono il “contratto” che la tua app applica: cosa viene gestito prima, con quale velocità e chi è responsabile. Mantieni lo schema semplice, documentalo chiaramente e rendilo difficile da sovrascrivere senza motivo.
Uno schema di priorità semplice (P1–P4)
Usa quattro livelli così gli agenti possono classificare rapidamente e i manager possono fare report coerenti:
- P1 — Outage critico / impatto severo: Il prodotto è giù, si verifica perdita di dati o si sospetta un incidente di sicurezza. Molti utenti o un intero account cliente sono bloccati.
- P2 — Degrado importante: Funzionalità core parzialmente rotte, workaround limitati e impatto aziendale elevato ma non totale.
- P3 — Problema standard: Un singolo utente o funzionalità non core è coinvolta. C'è un workaround. Molti ticket dovrebbero finire qui.
- P4 — Bassa urgenza / richieste: Domande su come fare, bug minori, richieste di funzionalità, questioni di fatturazione che non bloccano l'uso.
Definisci “impact” (quanti utenti/clienti) e “urgency” (quanto è sensibile al tempo) nell'interfaccia per ridurre i casi di misclassificazione.
Definisci le SLA per piano, tier cliente e priorità
Il tuo modello dati dovrebbe permettere alle SLA di variare per piano/tier cliente (es. Free/Pro/Enterprise) e priorità. Tipicamente, tieni almeno due timer:
- First response SLA (tempo per riconoscere e assumere ownership)
- Resolution SLA o next-update SLA (tempo per risolvere o fornire un aggiornamento significativo)
Esempio: Enterprise + P1 potrebbe richiedere una prima risposta in 15 minuti, mentre Pro + P3 potrebbe essere 8 ore lavorative. Mantieni la tabella regole visibile agli agenti e collegala dalla pagina del ticket.
Orari di lavoro, 24/7 e calendari festivi
Le SLA spesso dipendono se il piano include copertura 24/7.
- Per le SLA in orario di lavoro, memorizza una schedule (timezone, giorni settimanali, orari di inizio/fine).
- Per le SLA 24/7, l'orologio scorre sempre.
- Aggiungi un calendario festività (per regione se necessario) così i timer non “violano” in giorni in cui nessuno è previsto lavorare.
Mostra sul ticket sia “SLA rimanente” sia la schedule utilizzata (così gli agenti si fidano del timer).
Pause SLA, “in attesa del cliente” e gestione dei breach
I workflow reali richiedono pause. Una regola comune: mettere in pausa la SLA quando il ticket è Waiting on customer (o Waiting on third party), e riprendere quando il cliente risponde.
Sii esplicito su:
- Quali stati mettono in pausa quali timer SLA
- Se le pause si applicano alla response SLA, alla resolution SLA o a entrambe
- Cosa succede quando si verifica un breach (es. auto-escalation di priorità, paging on-call, notifica a un manager, tag "SLA Breached")
Evita breach silenziosi. La gestione dei breach dovrebbe creare un evento visibile nella cronologia del ticket.
Chi viene avvisato prima e dopo un breach
Imposta almeno due soglie di notifica:
- Avviso pre-breach (es. 50% e 80% SLA consumata): notifica il proprietario del ticket e il canale del team responsabile.
- Alert di breach: notifica on-call (per P1/P2), team lead e opzionalmente customer success per account di alto livello.
Instrada gli alert in base a priorità e tier così le persone non vengono pagate per rumore P4. Se vuoi più dettaglio, collega questa sezione alle tue regole on-call in /blog/notifications-and-on-call-alerting.
Costruisci la logica di triage, instradamento e ownership
Il triage e l'instradamento sono il punto in cui un'app di supporto prioritario risparmia tempo—o genera confusione. L'obiettivo è semplice: ogni nuova richiesta deve arrivare nel posto giusto rapidamente, con un proprietario chiaro e un prossimo passo ovvio.
Crea una inbox di triage di cui gli agenti si possono fidare
Inizia con una inbox di triage dedicata per i ticket non assegnati o da revisionare. Mantienila veloce e prevedibile:
- Ordinamento di default per segnali di urgenza (priorità, tempo SLA dovuto, tier cliente)
- Filtri per area prodotto, regione/timezone, canale (email/chat/web) e account “VIP”
- Vista “Nessun proprietario / Nessuna categoria” che evidenzia problemi di qualità dati
Una buona inbox minimizza i click: gli agenti dovrebbero poter reclamare, riassegnare o escalare dalla lista senza aprire ogni ticket.
Definisci regole di instradamento (e mantienile spiegabili)
L'instradamento dovrebbe essere basato su regole, ma leggibile dai non ingegneri. Input comuni:
- Area prodotto (selezionata dall'utente, rilevata dal form o inferita da tag)
- Parole chiave nell'oggetto/corpo (es. “outage”, “invoice”, “SSO”)
- Tier cliente (standard vs. priority)
- Regione (instrada a team allineati per timezone)
Memorizza il “perché” di ogni decisione di instradamento (es. “Matched keyword: SSO → Auth team”). Questo rende le dispute facili da risolvere e migliora la formazione.
Override manuale e percorsi di escalation
Anche le migliori regole hanno bisogno di un’uscita d'emergenza. Permetti agli utenti autorizzati di sovrascrivere l'instradamento e attivare percorsi di escalation come:
Agente → Team lead → On-call
Gli override dovrebbero richiedere una breve motivazione e creare una voce di audit. Se hai paging on-call più avanti, collega le azioni di escalation ad esso (vedi /blog/notifications-and-on-call-alerting).
Deduplicazione e collegamento di lavori correlati
I ticket duplicati consumano tempo SLA. Aggiungi strumenti leggeri:
- Suggerisci possibili duplicati basati su cliente + oggetto simile + finestra temporale
- Permetti agli agenti di collegare ticket a un incidente principale (“related to INC-123”)
I ticket collegati dovrebbero ereditare aggiornamenti di stato e comunicazioni pubbliche dal ticket principale.
Regole di ownership: un nome, una coda
Definisci chiaramente gli stati di ownership:
- Assegnatario singolo (una persona responsabile)
- Coda del team (non assegnato all'interno di un team; usa quando i passaggi sono frequenti)
- Handoff (trasferimento esplicito con note e un nuovo checkpoint SLA se necessario)
Rendi l'ownership visibile ovunque: vista lista, header del ticket e log attività. Quando qualcuno chiede “Chi ha questo?”, l'app dovrebbe rispondere istantaneamente.
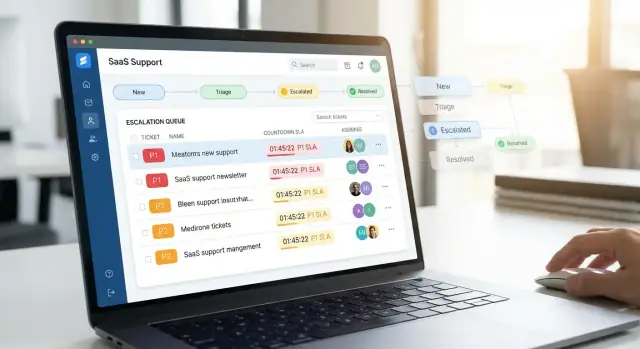
Crea una dashboard di supporto che gli agenti possano usare velocemente
Un'app di supporto prioritario riesce o fallisce nei primi 10 secondi che un agente le dedica. La dashboard dovrebbe rispondere subito a tre domande: cosa richiede attenzione ora, perché, e cosa posso fare dopo.
Viste chiave che gli agenti usano davvero
Parti con un piccolo insieme di viste ad alta utilità invece di una giungla di tab:
- Coda (worklist): vista predefinita con filtri per priorità, stato SLA, canale, area prodotto e assegnatario.
- Dettaglio ticket: si apre con un clic, con contesto e azioni above the fold.
- Profilo cliente: vista compatta di tier account, escalation recenti, incidenti attivi e contatti chiave.
- Board SLA: vista temporale che evidenzia cosa sta per violare, non solo cosa è già in ritardo.
Segnali visivi che riducono il carico cognitivo
Usa segnali chiari e coerenti così gli agenti non devono “leggere” ogni riga:
- Chip di priorità (P1–P4) con colore accessibile + testo (mai solo colore).
- Conto alla rovescia SLA (es. “45m alla prima risposta”) e un indicatore di “rischio di breach”.
- Badge blocco (Waiting on customer, Waiting on engineering, Needs approval) così il lavoro bloccato è visibile.
Mantieni la tipografia semplice: un colore di accento principale e una gerarchia stretta (titolo → cliente → stato/SLA → ultimo aggiornamento).
Azioni veloci e velocità di triage
Ogni riga di ticket dovrebbe supportare azioni rapide senza aprire la pagina completa:
- Assegna / riassegna, escala, cambia priorità, richiedi informazioni, imposta blocco, aggiungi nota interna.
Aggiungi azioni in blocco (assegna, chiudi, applica tag, imposta blocco) per ripulire rapidamente i backlog.
Tastiera, accessibilità e “nessuna sorpresa"
Supporta scorciatoie da tastiera per utenti power: / per cercare, j/k per muoversi, e per escalare, a per assegnare, g poi q per tornare alla coda.
Per l'accessibilità, garantisci contrasto sufficiente, stati di focus visibili, controlli etichettati e testo leggibile da screen reader (es. “SLA: 12 minuti rimanenti”). Rendi anche la tabella responsive in modo che lo stesso flusso funzioni su schermi più piccoli senza nascondere campi critici.
Notifiche e paging on-call
Mantieni il codice portabile
Esporta il codice sorgente in qualsiasi momento per mantenere il pieno controllo man mano che il workflow cresce.
Le notifiche sono il “sistema nervoso” di un'app di supporto prioritario: trasformano i cambiamenti di ticket in azione tempestiva. L'obiettivo non è notificare di più—è notificare le persone giuste, nel canale giusto, con contesto sufficiente per rispondere.
Mappa i tipi di notifica
Inizia con un set chiaro di eventi che attivano messaggi. Tipi comuni e ad alto segnale includono:
- Assegnazione: ticket assegnato o riassegnato a un agente o team
- Mention: qualcuno @menziona un agente in una nota interna
- Avviso SLA: un ticket si sta avvicinando a obiettivi di prima risposta o risoluzione
- Breach SLA: un obiettivo è mancato (con motivo se noto)
- Escalation: aumento di priorità, aggiunta di un executive/cliente o dichiarazione di incidente
Ogni messaggio dovrebbe includere ID ticket, nome cliente, priorità, proprietario corrente, timer SLA e un link profondo al ticket.
Scegli i canali senza perdere controllo
Usa notifiche in-app per il lavoro quotidiano e email per aggiornamenti durevoli e handoff. Per scenari on-call reali, aggiungi SMS/push come canale opzionale riservato agli eventi urgenti (come una escalation P1 o un breach imminente).
Previeni la fatica da alert
La fatica da alert uccide i tempi di risposta. Aggiungi controlli come raggruppamento, ore di silenzio e deduplica:
- Raggruppa avvisi SLA ripetuti in un unico thread
- Deduplica raffiche di “assegnazione cambiata” in una finestra breve
- Rispetta le quiet hours con override per incidenti critici
Template + storico di consegna
Fornisci template sia per gli aggiornamenti verso i clienti che per le note interne così tono e completezza restino coerenti. Monitora lo stato di consegna (inviato, consegnato, fallito) e mantieni una timeline notifiche per ticket per audit e follow-up. Una semplice tab “Notifications” nella pagina di dettaglio ticket rende questo facile da rivedere.
Pagina dettaglio ticket: collaborazione e comunicazione
La pagina di dettaglio è dove il lavoro di escalation avviene realmente. Deve aiutare gli agenti a capire il contesto in pochi secondi, coordinarsi con i colleghi e comunicare con il cliente senza errori.
Separa ciò che il cliente vede da ciò che resta interno
Rendi il composer esplicitamente a scelta tra Customer Reply o Internal Note, con styling diverso e anteprima chiara. Le note interne dovrebbero supportare formattazione rapida, link a runbook e tag privati (es. “needs engineering”). Le risposte al cliente dovrebbero partire da un template amichevole e mostrare esattamente cosa verrà inviato.
Conversazione threadata + allegati sicuri
Supporta un thread cronologico che include email, trascrizioni chat ed eventi di sistema. Per gli allegati, prioritizza la sicurezza:
- Scansione antivirus e whitelist di tipi di file
- Limiti di dimensione e link di download che scadono
- Avvisi di redazione per dati sensibili (token, password)
Se mostri file forniti dal cliente, chiarisci chi li ha caricati e quando.
Macro, risposte rapide e passi salvati
Aggiungi macro che inseriscono risposte pre-approvate più checklist di troubleshooting (es. “raccogli log”, “passi di restart”, “testo per status page”). Permetti ai team di mantenere una libreria di macro condivisa con cronologia delle versioni così le escalation restano coerenti e conformi.
Una timeline degli eventi chiave
Oltre ai messaggi, mostra una timeline compatta degli eventi: cambi di stato, aggiornamenti di priorità, pause/resume SLA, trasferimenti di assegnatario e cambi di livello di escalation. Questo previene “cosa è cambiato?” e aiuta nelle revisioni post-incident.
Strumenti di collaborazione che non creano rumore
Abilita @mention, follower e task collegati (ticket engineering, doc incidente). Le mention dovrebbero notificare solo le persone giuste e i follower dovrebbero ricevere riassunti quando il ticket cambia in modo significativo—non ad ogni battitura.
Sicurezza, privacy e permessi
Spedisci la dashboard per agenti
Crea viste pensate per gli agenti come code, pannelli SLA e profili cliente in un unico posto.
La sicurezza non è una funzione “da dopo” per un'app di escalation: le escalation spesso contengono email cliente, screenshot, log e note interne. Costruisci guardrail presto così gli agenti possono muoversi veloci senza condividere troppo o perdere fiducia.
Controllo accessi basato sui ruoli (RBAC) che rispecchia il lavoro reale
Inizia con un piccolo set di ruoli che puoi spiegare in una frase ciascuno (per esempio: Agente, Team Lead, On-Call Engineer, Admin). Poi definisci cosa ogni ruolo può visualizzare, modificare, commentare, riassegnare ed esportare.
Un approccio pratico è il permesso “default deny”:
- Visibilità escalation: restrizioni per team, coda e account cliente (es. solo agenti coda Enterprise possono aprire escalation Enterprise).
- Diritti di modifica: permetti agli agenti di aggiornare stato e aggiungere note, ma limita modifiche SLA, override priorità e cancellazioni di escalation a lead/admin.
- Campi sensibili: tratta PII cliente (email, telefono), log di sicurezza e allegati come permessi separati.
Privacy by design: privilegi minimi come default
Raccogli solo ciò che il workflow richiede. Se non ti servono corpi di messaggi completi o indirizzi IP completi, non memorizzarli. Quando memorizzi dati cliente, chiarisci quali campi sono obbligatori vs opzionali e evita di copiare dati da altri sistemi senza motivo.
Per i pattern di accesso, assumi “gli agenti vedono il minimo necessario per risolvere il ticket”. Usa scoping per account e coda prima di aggiungere regole complesse.
Proteggi le basi: autenticazione, sessioni e CSRF
Usa autenticazione collaudata (SSO/OIDC se possibile), richiedi password forti quando vengono usate e supporta MFA per ruoli elevati.
Indurisci le sessioni:
- Cookie Secure, HttpOnly; durate di sessione più corte per azioni admin
- Rotation al login e ai cambi di privilegio
- Protezione CSRF per richieste che cambiano stato
Segreti, log di audit e accesso sensibile
Conserva i segreti in uno store gestito (non nel source control). Registra chi accede ai dati sensibili (chi ha visualizzato un'escalation, scaricato un allegato, esportato un ticket) e rendi i log di audit resistenti alle manomissioni e ricercabili.
Retention ed esportazioni (senza promesse eccessive)
Definisci regole di retention per ticket, allegati e log di audit (es. cancellare allegati dopo N giorni, conservare log di audit più a lungo). Fornisci esportazioni per clienti o report interni, ma evita di promettere certificazioni di conformità specifiche a meno che tu non possa verificarle. Un semplice flusso “data export” più un workflow admin-only per “delete request” è un buon inizio.
Scegli uno stack tecnologico e l'architettura
La tua app di escalation sarà efficace solo se è facile da cambiare. Regole di escalation, SLA e integrazioni evolvono continuamente, quindi dai priorità a uno stack che il tuo team può mantenere e su cui puoi assumere persone.
Scegli uno stack che si adatta al tuo team
Scegli strumenti familiari piuttosto che i “più perfetti”. Alcune combinazioni consolidate:
- React + Node.js (Express/NestJS): buono se vuoi una dashboard altamente interattiva e molta UI in tempo reale.
- Django (Python): ottimo tooling admin, sviluppo CRUD veloce, ideale per app con workflow pesanti.
- Rails (Ruby): convenzioni eccellenti per costruire rapidamente prodotti in stile ticketing.
Se già gestisci un monolite altrove, allineare l'ecosistema spesso riduce tempi di onboarding e complessità operativa.
Se vuoi muoverti più in fretta senza un grande impegno ingegneristico iniziale, puoi anche prototipare (e iterare) il workflow in una piattaforma come Koder.ai—soprattutto per pezzi standard come una dashboard React, un backend Go/PostgreSQL e la logica SLA/notification basata su job.
Storage dati: relazionale prima, ricerca dove serve
Per i record core—ticket, clienti, SLA, eventi di escalation, assegnazioni—usa un database relazionale (Postgres è un default comune). Offre transazioni, vincoli e query adatte alla reportistica.
Per ricerche veloci su soggetti, testo di conversazioni e nomi cliente, considera un indice di ricerca in seguito (es. Elasticsearch/OpenSearch). Rendilo opzionale all'inizio: parti con Postgres full-text search e scala se necessario.
Job in background sono imprescindibili
Le app di escalation dipendono da lavoro basato sul tempo e integrazioni che non devono girare in una richiesta web:
- Timer SLA e controlli breach
- Notifiche (email/SMS/push)
- Paging on-call
- Sincronizzazione messaggi da email/chat/CRM
Usa una job queue (es. Celery, Sidekiq, BullMQ) e rendi i job idempotenti così i retry non generano alert duplicati.
Definisci API presto e mantienile coerenti
Sia che scegli REST o GraphQL, definisci i confini delle risorse in anticipo: tickets, comments, events, customers e users. Uno stile API coerente accelera integrazioni e UI. Prevedi anche endpoint webhook fin dall'inizio (signing secret, retry e rate limit).
Hosting e ambienti
Esegui almeno dev/staging/prod. Lo staging dovrebbe rispecchiare le impostazioni di prod (provider email, code, webhook) con credenziali test sicure. Documenta deployment e rollback, e conserva la configurazione in variabili d'ambiente—non nel codice.
Integrazioni: Email, chat, CRM e webhooks
Le integrazioni trasformano la tua app di escalation da “un altro posto da controllare” al sistema in cui il team lavora davvero. Parti dai canali che i clienti usano già, poi aggiungi hook di automazione così altri strumenti possono reagire a eventi di escalation.
Email: parsing inbound, invio outbound, threading
L'email è spesso l'integrazione più impattante. Supporta inoltri inbound (es. support@) e parse:
- From/To/Cc, oggetto, corpo (preferisci plain-text come fallback) e allegati
- Message-ID e In-Reply-To per il threading
- Dominio cliente e indizi di firma per la scoperta del contatto
Per l'outbound, invia dal ticket (reply/forward) e preserva header di threading così le risposte tornano nello stesso ticket. Memorizza una timeline pulita della conversazione: mostra ciò che il cliente ha visto, non le note interne.
Strumenti chat (opzionali): converti messaggi in ticket
Per la chat (Slack/Teams/widget tipo intercom), mantieni la semplicità: converti una conversazione in un ticket con una trascrizione chiara e i partecipanti. Evita di sincronizzare ogni messaggio di default—offri un pulsante “Attach last 20 messages” così gli agenti controllano il rumore.
Sync CRM/directory cliente: identifica tier e contatti
La sync col CRM rende automatico il “supporto prioritario”. Estrai azienda, piano/tier, account owner e contatti chiave. Mappa gli account CRM ai tenant così i nuovi ticket possono ereditare regole di priorità immediatamente.
Webhook per eventi chiave
Fornisci webhooks per eventi come ticket.escalated, ticket.resolved e sla.breached. Includi un payload stabile (ticket ID, timestamp, severity, customer ID) e firma le richieste così i receiver possono verificarne l'autenticità.
Documenta e semplifica la configurazione
Aggiungi un piccolo flow admin con pulsanti di test (“Send test email”, “Verify webhook”). Mantieni la doc in un posto unico (es. /docs/integrations) e mostra le soluzioni comuni (SPF/DKIM, header di threading mancanti, mappatura campi CRM).
Test, monitoraggio e affidabilità
Avvia lo stack core
Genera una dashboard React con backend in Go e PostgreSQL da una semplice chat.
Un'app di supporto prioritario diventa la “fonte di verità” nei momenti critici. Se i timer SLA slittano, l'instradamento sbaglia o i permessi lasciano trapelare dati, la fiducia svanisce rapidamente. Tratta l'affidabilità come una feature: testa ciò che conta, misura cosa succede e pianifica i guasti.
Testa le regole che guidano l'urgenza
Concentra i test automatici sulla logica che cambia i risultati:
- Calcoli SLA: condizioni di start/stop, orari di lavoro, pause, soglie breach e timestamp “next due”.
- Instradamento e ownership: regole di triage, assegnazione round-robin/skill-based e trigger di escalation.
- Permessi: RBAC per code, dettaglio ticket, note interne e messaggi visibili al cliente.
Aggiungi una piccola suite end-to-end che imiti il workflow agente (crea ticket → triage → escala → risolvi) per catturare assunzioni rotte tra UI e backend.
Dati seed e scenari realistici
Crea dati seed utili oltre le demo: alcuni clienti, tier multipli (standard vs. priority), priorità varie e ticket in stati differenti. Includi casi difficili come ticket riaperti, “waiting on customer” e assegnazioni multiple. Questo rende la pratica di triage significativa e aiuta QA a riprodurre edge case rapidamente.
Osservabilità: sapere prima che lo facciano i clienti
Strumenta l'app così puoi rispondere: “Cosa è fallito, per chi e perché?”
- Tracciamento errori per eccezioni in job SLA/instradamento.
- Log strutturati con ticket ID, rule ID e correlation ID.
- Monitoraggio delle performance sulle pagine critiche e sui worker di background.
Test di carico e recupero sicuro
Esegui test di carico su viste ad alto traffico come code, ricerca e dashboard—specialmente nei cambi turni.
Infine, prepara il tuo playbook d'incidente: feature flag per nuove regole, rollback di migrazioni DB e una procedura chiara per disabilitare automazioni mantenendo gli agenti produttivi.
Piano di lancio, reportistica e iterazione
Un'app di supporto prioritario è “completa” solo quando gli agenti le si fidano sotto pressione. Il modo migliore per arrivarci è lanciare in piccolo, misurare cosa succede realmente e iterare in cicli brevi.
Parti con un MVP che dimostri il workflow
Resisti alla tentazione di rilasciare ogni feature. Il primo rilascio dovrebbe coprire il percorso più breve da “nuova escalation” a “risolta con responsabilità”:
- Una coda di triage con ordinamento chiaro (priorità, SLA due, tier cliente)
- Una pagina dettaglio ticket che supporti aggiornamenti veloci e note interne
- Timer SLA visibili (prima risposta e risoluzione/next update quando applicabile)
- Alert di base per breach imminenti e cambi di stato
Se usi Koder.ai, questa forma di MVP si mappa bene ai default comuni (UI React, servizi Go, PostgreSQL) e la possibilità di fare snapshot/rollback è utile mentre affini calcoli SLA, regole di instradamento e confini di permessi.
Pilota con un piccolo team e revisioni settimanali
Rollout a un gruppo pilota (una regione, una linea prodotto o una rotazione on-call) e fai review settimanali dei feedback. Mantienile strutturate: cosa rallentava gli agenti, quali dati mancavano, quali notifiche erano rumorose e dove la gestione delle escalation falliva (handoff, ownership poco chiara o ticket instradati male).
Una tattica pratica: tieni un changelog leggero dentro l'app così gli agenti vedono i miglioramenti e si sentono ascoltati.
Aggiungi report che generano azione, non vanità
Quando hai un uso coerente, introduce report che rispondono a domande operative:
- Conformità SLA: tasso di breach per priorità, tier cliente e canale
- Volume escalation: trend nel tempo e picchi dopo release
- Principali cause: tag/motivi correlati alle escalation
- Carico agenti: ticket aperti per agente e tempo alla prima presa in carico
Questi report dovrebbero essere facili da esportare e semplici da spiegare agli stakeholder non tecnici.
Itera su regole e macro usando risultati reali
Le regole di instradamento e triage saranno sbagliate all'inizio—ed è normale. Affina le regole di triage basandoti su mis-instradamenti, tempi di risoluzione e feedback on-call. Fai lo stesso per macro e risposte predefinite: rimuovi quelle che non riducono i tempi e affina quelle che migliorano la comunicazione dell'incidente e la chiarezza.
Pubblica una roadmap semplice e risorse di aiuto
Mantieni la roadmap breve e visibile dentro il prodotto (“Prossimi 30 giorni”). Collega ai contenuti di help e FAQ così la formazione non diventi conoscenza tribale. Se mantieni info pubbliche, rendile facilmente raggiungibili tramite link interni come /pricing o /blog così i team possono auto-servirsi aggiornamenti e best practice.
Domande frequenti
Cosa dovrebbe contare come escalation in un'app per supporto prioritario?
Scrivi i criteri in linguaggio semplice e incorporali nell'interfaccia. I trigger di escalation tipici includono:
- Interruzione del servizio o degrado grave
- Cliente VIP / contratto di “supporto prioritario”
- Imminente o ripetuta violazione di SLA
- Problemi che impattano sicurezza, fatturazione o aspetti legali
Documenta anche cosa non è un'escalation (domande su come fare, richieste di funzionalità, bug minori) e dove devono essere instradate queste richieste.
Quali ruoli dovresti definire e come assegni la ownership?
Definisci i ruoli in base a ciò che possono fare nel workflow, poi mappa la proprietà (ownership) in ogni passaggio:
- : triage, risolve, aggiorna il ticket, segue playbook
Quali canali di supporto dovresti costruire per primi (email, web, chat)?
Parti con un set limitato per mantenere il triage coerente e poter rilasciare prima—di solito email + form web. Aggiungi chat quando:
- Le SLA sono stabili
- Le regole di instradamento funzionano
- La proprietà e i passaggi sono chiari
Questo riduce la complessità iniziale (threading, sincronizzazione delle trascrizioni, rumore in tempo reale) mentre convalidi il workflow di escalation core.
Quali campi sono essenziali nel modello dati di ticket ed escalation?
Al minimo, ogni ticket dovrebbe memorizzare:
- Richiedente (contatto) e azienda (account)
- Oggetto, descrizione, allegati
- Stato, assegnatario/coda, timestamp
Per le escalation, aggiungi campi strutturati come , , e (es. API, Billing). Per le SLA, memorizza timestamp di scadenza espliciti (es. , ) così gli agenti vedono le scadenze esatte.
Come dovrebbero essere progettati stati e cronologia di audit per report SLA affidabili?
Usa un set di stati piccolo e stabile (es. New, Triaged, In Progress, Waiting, Resolved, Closed) e definisci cosa significa ogni stato operativamente.
Per rendere le SLA e la responsabilità verificabili, conserva una cronologia append-only per:
- Cambi di stato (chi/quando)
- Eventi di start/stop/pausa SLA
- Cambi di priorità/escalation
Una tabella eventi o log di audit permette di ricostruire cosa è successo senza affidarsi solo allo “stato corrente”.
Come si impostano livelli di priorità e regole SLA che gli agenti seguiranno?
Mantieni la priorità semplice (es. P1–P4) e collega le SLA a tier/plan del cliente + priorità. Tieni almeno due timer:
- First response SLA: tempo per riconoscere e assumere ownership
- Resolution o next-update SLA: tempo per risolvere o fornire un aggiornamento significativo
Rendi gli override possibili ma controllati: richiedi una motivazione e registrala nella cronologia di audit per mantenere credibilità nei report.
Come gestire orari di lavoro, festività e pause SLA come “in attesa del cliente”?
Modella il tempo in modo esplicito:
- SLA in orario di lavoro: memorizza timezone, giorni lavorativi, orari di inizio/fine
- SLA 24/7: orologio sempre attivo
- Calendari festivi: evita falsi breach quando nessuno è previsto al lavoro
Definisci quali stati mettono in pausa quali timer (di solito ) e cosa succede in caso di breach (tag, notifica, auto-escalation, paging on-call). Evita breach “silenziosi”: crea un evento visibile sul ticket.
Qual è il modo migliore per implementare triage, regole di instradamento e override manuali?
Costruisci una inbox di triage per i ticket non assegnati/da revisionare con ordinamento per priorità + scadenza SLA + tier cliente. Mantieni le regole di instradamento basate su segnali spiegabili come:
- Area prodotto (campo del form, tag o inferenza)
- Parole chiave (es. “SSO”, “invoice”, “outage”)
- Tier cliente e regione/timezone
Registra la ragione per ogni decisione di instradamento (es. “Matched keyword: SSO → Auth team”) e permetti override autorizzati con nota obbligatoria e entry di audit.
Cosa dovrebbe dare priorità la dashboard e la lista ticket per la rapidità degli agenti?
Ottimizza per i primi 10 secondi:
- Una coda/worklist predefinita con filtri (priorità, rischio SLA, canale, area prodotto, assegnatario)
- Chiare indicazioni a livello di riga: chip di priorità (non solo colore), conto alla rovescia SLA, badge blocco
- Azioni rapide dalla lista: assegna, escala, cambia priorità, richiedi info, aggiungi nota interna
Aggiungi azioni bulk per ripulire backlog, scorciatoie da tastiera per utenti esperti e basi di accessibilità (contrasto, stati di focus, testo leggibile da screen reader).
Come gestire sicurezza (RBAC, privacy) e affidabilità (test/monitoraggio) in un'app di escalation?
Proteggi i dati di escalation fin dall'inizio con guardrail pratici:
- RBAC con “default deny” e scope per coda/account
- Permessi separati per campi sensibili (PII, log, allegati) e per azioni ad alto impatto (override SLA/priorità)
- Audit log cercabile e resistente alle manomissioni per accessi sensibili (visualizzazioni, download, esportazioni)
Per l'affidabilità, automatizza test sulle regole che influenzano i risultati (calcolo SLA, instradamento/proprietà, permessi) e usa job di background per timer e notifiche con retry idempotenti per evitare alert duplicati.