05 mag 2025·8 min
Crea un'app web per gestire le timeline di escalation dei clienti
Piano passo-passo per costruire un’app web che traccia escalation clienti, scadenze, SLA, ownership e avvisi—con reporting e integrazioni.
Piano passo-passo per costruire un’app web che traccia escalation clienti, scadenze, SLA, ownership e avvisi—con reporting e integrazioni.
Prima di progettare schermate o scegliere lo stack tecnologico, definisci con precisione cosa significa “escalation” nella tua organizzazione. È un ticket di supporto che invecchia, un incidente che minaccia la disponibilità, un reclamo da un cliente chiave o qualsiasi richiesta che supera una soglia di gravità? Se team diversi usano la parola con significati differenti, la tua app codificherà confusione.
Scrivi una definizione in una frase su cui tutto il team può concordare e aggiungi alcuni esempi. Per esempio: “Un’escalation è qualsiasi problema cliente che richiede un livello di supporto superiore o l’intervento della direzione, e ha un impegno temporale.”
Definisci anche cosa non conta (es. ticket di routine, attività interne) così la v1 non si gonfia.
I criteri di successo dovrebbero riflettere ciò che vuoi migliorare — non solo ciò che vuoi costruire. Risultati core comuni includono:
Scegli 2–4 metriche che puoi tracciare fin da subito (es. tasso di breach, tempo in ogni fase, numero di riassegnazioni).
Elenca gli utenti primari (agenti, team lead, manager) e gli stakeholder secondari (account manager, on-call engineering). Per ciascuno annota cosa devono fare rapidamente: prendere ownership, estendere una scadenza con motivo, vedere il passo successivo o riassumere lo stato per un cliente.
Raccogli modalità di fallimento attuali con storie concrete: handoff mancati tra tier, orari di scadenza poco chiari dopo una riassegnazione, dibattiti su “chi ha approvato l’estensione?”.
Usa queste storie per separare i must-have (timeline + ownership + auditabilità) dalle aggiunte future (dashboard avanzati, automazioni complesse).
Con obiettivi chiari, descrivi come un’escalation si muove attraverso il team. Un workflow condiviso previene che i “casi speciali” diventino gestione incoerente e S L A mancati.
Inizia con un set semplice di fasi e transizioni consentite:
Documenta cosa significa ogni fase (criteri di ingresso) e cosa deve essere vero per uscirne (criteri di uscita). Qui eviti ambiguità come “Risolto ma ancora in attesa del cliente”.
Le escalation dovrebbero essere create da regole che puoi spiegare in una sola frase. Trigger comuni includono:
Decidi se i trigger creano automaticamente un’escalation, suggeriscono una escalation all’agente o richiedono approvazione.
La tua timeline è valida quanto gli eventi che registra. Al minimo, cattura:
Scrivi regole per i cambi di ownership: chi può riassegnare, quando servono approvazioni (es. handoff cross-team o vendor), e cosa succede se un owner termina il turno.
Infine, mappa le dipendenze che influenzano i tempi: orari on-call, livelli tier (T1/T2/T3) e vendor esterni (inclusi i loro tempi di risposta). Questo guiderà i calcoli delle timeline e la matrice di escalation più avanti.
Un’app di escalation affidabile è principalmente un problema di dati. Se timeline, SLA e cronologia non sono modellati chiaramente, l’interfaccia e le notifiche sembreranno sempre “sbagliate”. Inizia nominando le entità core e le loro relazioni.
Al minimo, prevedi:
Tratta ogni milestone come un timer con:
start_at (quando inizia il conteggio)due_at (scadenza calcolata)paused_at / pause_reason (opzionale)completed_at (quando viene rispettata)Conserva perché esiste una data di scadenza (la regola), non solo il timestamp calcolato. Questo rende più semplice risolvere dispute.
SLA raramente significano “sempre”. Modella un calendario per ogni policy SLA: orari lavorativi vs 24/7, festività e orari specifici per regione.
Calcola le scadenze in un tempo server coerente (UTC), ma salva sempre il fuso orario del case (o del cliente) così l’interfaccia può mostrare scadenze correttamente e gli utenti possono ragionarci sopra.
Decidi presto tra:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), oPer conformità e responsabilità, preferisci un event log (anche se mantieni colonne di stato corrente per performance). Ogni cambiamento dovrebbe registrare chi, cosa è cambiato, quando, e sorgente (UI, API, automazione), più un correlation ID per tracciare azioni correlate.
I permessi sono il punto in cui gli strumenti di escalation guadagnano fiducia — o vengono aggirati con fogli di calcolo a parte. Definisci chi può fare cosa prima possibile, poi applicalo in modo coerente su UI, API ed export.
Mantieni la v1 semplice con ruoli che rispecchiano il lavoro reale dei team di supporto:
Rendi i controlli di ruolo espliciti nel prodotto: disabilita i controlli invece di lasciare che gli utenti incorrano in errori cliccando.
Le escalation spesso coinvolgono più gruppi (Tier 1, Tier 2, CSM, incident response). Prevedi supporto multi-team scalandone la visibilità usando una o più di queste dimensioni:
Un buon default: gli utenti accedono ai casi in cui sono assegnati, watcher o appartengono al team proprietario — più eventuali account condivisi esplicitamente con il loro ruolo.
Non tutti i dati dovrebbero essere visibili a tutti. Campi sensibili comuni includono PII del cliente, dettagli contrattuali e note interne. Implementa permessi a livello di campo come:
Per la v1, email/password con supporto MFA è solitamente sufficiente. Progetta il modello utente in modo da poter aggiungere SSO (SAML/OIDC) senza riscrivere i permessi (es. conserva ruoli/team internamente, mappa i gruppi SSO al login).
Tratta i cambi di permessi come azioni auditable. Registra eventi come aggiornamenti di ruolo, riassegnazioni di team, download di esportazioni e modifiche di configurazione — chi l’ha fatto, quando e cosa è cambiato. Questo ti protegge durante incidenti e semplifica le review di accesso.
La tua app di escalation riesce o fallisce sulle schermate quotidiane: cosa vede prima un support lead, quanto velocemente capisce un caso e se la prossima scadenza è impossibile da perdere.
Inizia con poche pagine che coprono il 90% del lavoro:
Mantieni la navigazione prevedibile: una sidebar a sinistra o tab in alto con “Queue”, “My Cases”, “Reports”. Rendi la coda la pagina di atterraggio predefinita.
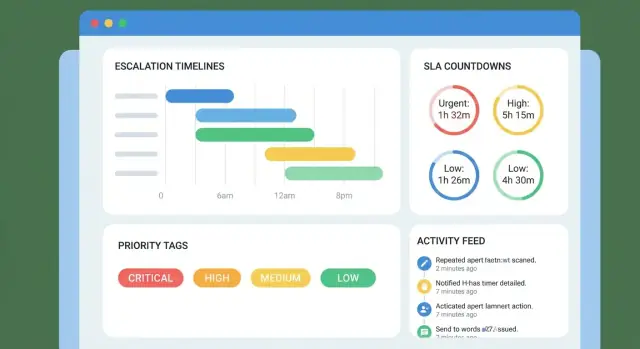
Nella lista casi mostra solo i campi che aiutano a decidere cosa fare dopo. Una riga utile include: cliente, priorità, owner corrente, stato, prossima scadenza, e un indicatore di avviso (es. “Scade tra 2h” o “In ritardo di 1g”).
Aggiungi filtri veloci e pratici:
Progetta per la scansione: larghezze colonne coerenti, chip di stato chiari e un unico colore di evidenza usato solo per l’urgenza.
La vista caso dovrebbe rispondere, a colpo d’occhio:
Posiziona le azioni rapide in alto (non sepolte nei menu): Reassign, Escalate, Add milestone, Add note, Set next deadline. Ogni azione dovrebbe confermare la modifica e aggiornare la timeline immediatamente.
La timeline dovrebbe leggere come una sequenza chiara di impegni. Includi:
Usa disclosure progressiva: mostra prima gli eventi più recenti, con opzione per espandere la cronologia. Se hai un audit trail, collega ad esso dalla timeline (es. “View change log”).
Usa contrasto di colore leggibile, abbina colore e testo (“Overdue”), assicurati che tutte le azioni siano raggiungibili da tastiera e scrivi etichette nel linguaggio degli utenti (“Imposta prossima scadenza aggiornamento cliente”, non “Update SLA”). Questo riduce i click sbagliati sotto pressione.
Gli avvisi sono il “battito” di una timeline di escalation: mantengono i casi in movimento senza costringere le persone a fissare una dashboard tutto il giorno. L’obiettivo è semplice — notificare la persona giusta, al momento giusto, con il minimo rumore.
Inizia con un piccolo set di eventi che mappano direttamente ad azioni:
Per la v1 scegli canali che puoi consegnare in modo affidabile e misurabile:
SMS o tool chat possono arrivare dopo, quando regole e volumi sono stabili.
Rappresenta l’escalation come soglie basate sul tempo legate alla timeline del caso:
Rendi la matrice configurabile per priorità/coda così i P1 non seguono lo stesso schema delle richieste di fatturazione.
Implementa deduplica (“non inviare lo stesso avviso due volte”), batching (digest di avvisi simili) e quiet hours che posticipano i promemoria non critici pur registrandoli.
Ogni avviso dovrebbe supportare:
Registra queste azioni nell’audit trail così i report possono distinguere tra “nessuno l’ha visto” e “qualcuno l’ha visto e posticipato”.
La maggior parte delle app di timeline di escalation fallisce quando richiedono di ridigitare dati che esistono già altrove. Per la v1 integra solo ciò che serve per mantenere le timeline accurate e le notifiche tempestive.
Decidi quali canali possono creare o aggiornare un caso di escalation:
Mantieni i payload inbound piccoli: case ID, customer ID, stato corrente, priorità, timestamp e un breve sommario.
La tua app dovrebbe notificare altri sistemi quando succede qualcosa di importante:
Usa webhooks con richieste firmate e un event ID per la deduplica.
Se sincronizzi in entrambe le direzioni, dichiara una source of truth per campo (es. lo strumento di ticketing possiede lo stato; la tua app possiede i timer SLA). Definisci regole di conflitto (“last write wins” raramente è corretto) e aggiungi retry con backoff più una dead-letter queue per i fallimenti.
Per la v1 importa clienti e contatti usando ID esterni stabili e uno schema minimale: nome account, tier, contatti chiave e preferenze di escalation. Evita un mirror profondo del CRM.
Documenta una breve checklist (metodo auth, campi richiesti, rate limit, retry, ambiente di test). Pubblica un contratto API minimale (anche una pagina) e versionalo così le integrazioni non si rompono all’improvviso.
Il backend deve fare due cose bene: mantenere la tempistica delle escalation accurata e rimanere veloce all’aumentare del volume di casi.
Scegli l’architettura più semplice che il team può mantenere. Una classica app MVC con API REST è spesso sufficiente per la v1 di un workflow di supporto. Se usi già GraphQL con successo, può andare bene — evita di aggiungerlo “solo perché”. Abbinalo a un database gestito (es. Postgres) così passi tempo sulla logica di escalation, non sulle operazioni DB.
Se vuoi validare il workflow end-to-end prima di impegnarti per settimane di engineering, una piattaforma di prototipazione come Koder.ai può aiutarti a prototipare il ciclo core (queue → case detail → timeline → notifications) da un’interfaccia chat, iterare in planning e poi esportare il codice quando sei pronto. Il suo stack di default (React web, Go + PostgreSQL backend) è un abbinamento pratico per app con forti requisiti di audit.
Le escalation dipendono dal lavoro schedulato, quindi ti servirà elaborazione in background per:
Implementa job idempotenti (sicuri da eseguire due volte) e retryabili. Conserva un timestamp “last evaluated at” per case/timeline per prevenire azioni duplicate.
Conserva tutti i timestamp in UTC. Converti nel fuso utente solo al confine UI/API. Aggiungi test per casi limite: cambi ora legale, anni bisestili e clock “in pausa” (es. SLA in pausa in attesa del cliente).
Usa paginazione per code e viste di audit trail. Aggiungi indici che rispecchiano filtri e ordinamenti comuni — tipicamente (due_at), (status), (owner_id) e compositi come (status, due_at).
Pianifica lo storage dei file separatamente dal DB: impone limiti di dimensione/tipo, scansione upload (o integrazione con provider) e regole di retention (es. cancellare dopo 12 mesi salvo legal hold). Conserva i metadata nelle tabelle di case; il file fisico in object storage.
Il reporting è dove la tua app di escalation smette di essere una inbox condivisa e diventa uno strumento di gestione. Per la v1 punta a una singola pagina di report che risponda a due domande: “Stiamo rispettando gli SLA?” e “Dove si bloccano le escalation?” Mantienila semplice, veloce e basata su definizioni condivise.
Un report è affidabile quanto le definizioni sottostanti. Metti tutto per iscritto in linguaggio chiaro e riflettile nel modello dati:
Decidi anche quale clock SLA riportare: first response, next update o resolution (o tutti e tre).
Il dashboard può essere leggero ma azionabile:
Aggiungi viste operative per il bilanciamento giornaliero:
L’export CSV è di solito sufficiente per la v1. Collegalo ai permessi (accesso per team, controlli di ruolo) e registra un entry nell’audit log per ogni export (chi, quando, filtri usati, numero di righe). Questo previene “fogli misteriosi” e aiuta la compliance.
Spedisci la prima pagina di reporting velocemente, poi rivedila settimanalmente con i lead del support per un mese. Raccogli feedback su filtri mancanti, definizioni confuse e momenti in cui “non riesco a rispondere a X” — sono i migliori input per la v2.
Testare un’app di timeline di escalation non è solo “funziona?” ma “si comporta come i team di supporto si aspettano sotto pressione?” Concentrati su scenari realistici che stressano regole di timeline, notifiche e handoff.
Investi la maggior parte dei test sui calcoli delle timeline, perché piccoli errori qui generano grandi dispute SLA.
Copri casi come conteggio di ore lavorative, festività e fusi orari. Aggiungi test per pause, cambi di priorità a caso in corso ed escalation che spostano i target. Testa anche condizioni limite: caso creato un minuto prima della chiusura o una pausa che inizia esattamente al confine SLA.
Le notifiche spesso falliscono nei gap tra sistemi. Scrivi integration test che verifichino:
Se usi email, chat o webhooks, asserisci payload e timing, non solo che “qualcosa è stato inviato”.
Crea dati campione realistici che rivelino problemi UX: clienti VIP, casi di lunga durata, riassegnazioni frequenti, incidenti riaperti e picchi di coda. Questo aiuta a validare che code, vista caso e timeline siano leggibili senza spiegazioni.
Esegui un pilota con un singolo team per 1–2 settimane. Raccogli problemi giornalieri: campi mancanti, etichette confuse, rumore di notifiche ed eccezioni alle regole di timeline.
Traccia cosa gli utenti fanno fuori dall’app (foglio di calcolo, canali laterali) per identificare le lacune.
Scrivi cosa significa “done” prima del lancio esteso: le metriche SLA principali corrispondono ai risultati attesi, le notifiche critiche sono affidabili, gli audit sono completi e il team pilota può gestire le escalation end-to-end senza workaround.
Rilasciare la prima versione non è il traguardo. Un’app di timeline diventa “reale” solo quando sopravvive ai fallimenti quotidiani: job mancanti, query lente, notifiche mal configurate e cambi inevitabili alle regole SLA. Tratta deployment e operazioni come parte del prodotto.
Mantieni il processo di rilascio noioso e ripetibile. Al minimo, documenta e automatizza:
Se hai staging, popolala con dati realistici (sanitizzati) così comportamento delle timeline e notifiche possono essere verificate prima della produzione.
I controlli di uptime tradizionali non cattureranno i peggiori problemi. Aggiungi monitor dove le escalation possono rompersi silenziosamente:
Crea un piccolo playbook on-call: “Se i promemoria SLA non partono, controlla A → B → C.” Questo riduce i tempi di inattività durante incidenti ad alta pressione.
I dati di escalation spesso includono nomi clienti, email e note sensibili. Definisci le policy presto:
Rendi la retention configurabile così non servono cambi di codice per aggiornare policy.
Anche in v1 gli admin hanno bisogno di strumenti per mantenere il sistema sano:
Scrivi documenti brevi e task-based: “Crea un’escalation”, “Metti in pausa una timeline”, “Sovrascrivi lo SLA”, “Audita chi ha cambiato cosa”.
Aggiungi un flusso di onboarding leggero in-app che punti gli utenti verso code, vista caso e azioni timeline, più un link alla pagina /help per riferimento.
La v1 deve dimostrare il ciclo core: un caso ha una timeline chiara, l’orologio SLA si comporta in modo prevedibile e le persone giuste ricevono le notifiche. La v2 può aggiungere potenza senza trasformare la v1 in un sistema “tutto insieme”. La chiave è mantenere un backlog breve ed esplicito di miglioramenti da inserire solo dopo aver visto l’uso reale.
Un buon item per la v2 è qualcosa che (a) riduce lavoro manuale su scala, o (b) previene errori costosi. Se aggiunge principalmente opzioni di configurazione, posticipalo finché non hai evidenza che più team lo richiedono davvero.
Calendari SLA per cliente sono spesso la prima espansione significativa: orari diversi, festività o tempi di risposta contrattuali diversi.
Poi aggiungi playbook e template: step di escalation preconfezionati, stakeholder raccomandati e bozze di messaggi che rendono le risposte coerenti.
Quando l’assegnazione diventa un collo di bottiglia, valuta routing basato su skill e orari on-call. Mantieni la prima iterazione semplice: poche skill, fallback owner di default e controlli di override chiari.
L’auto-escalation può innescarsi quando compaiono segnali (cambi gravità, parole chiave, sentiment, contatti ripetuti). Inizia con “suggested escalation” (un prompt) prima di “automatic escalation”, e registra sempre la ragione di ogni trigger per fiducia e auditabilità.
Aggiungi campi obbligatori prima dell’escalation (impatto, gravità, tier cliente) e step di approvazione per escalation ad alta gravità. Questo riduce il rumore e aiuta i report a restare accurati.
Se vuoi esplorare pattern di automazione prima di costruirli, vedi /blog/workflow-automation-basics. Se stai allineando lo scope al packaging, verifica come le feature mappano ai tier su /pricing.
Inizia con una definizione in una frase su cui tutti concordano (e aggiungi alcuni esempi). Includi anche esplicitamente cosa non è escalation (ticket di routine, attività interne) così che la v1 non diventi un sistema di ticketing generico.
Poi scrivi 2–4 metriche di successo misurabili immediatamente, come la frequenza di violazione SLA, il tempo in ogni fase o il numero di riassegnazioni.
Scegli risultati che riflettano miglioramenti operativi, non il completamento di funzionalità. Metriche pratiche per la v1 includono:
Seleziona un piccolo insieme che puoi calcolare dai timestamp di day one.
Usa un piccolo insieme condiviso di fasi con criteri di ingresso/uscita chiari, ad esempio:
Documenta cosa deve essere vero per entrare ed uscire da ciascuna fase. Questo evita ambiguità come “Risolto ma in attesa del cliente”.
Acquisisci gli eventi minimi necessari per ricostruire la timeline e difendere le decisioni sugli SLA:
Se non sai come userai un timestamp, non raccoglierlo in v1.
Modella ogni milestone come un timer con:
start_atdue_at (calcolato)paused_at e pause_reason (opzionali)completed_atConserva anche la regola che ha prodotto (policy + calendario + motivo). Questo rende gli audit e le dispute molto più semplici rispetto a memorizzare solo la scadenza finale.
Conserva i timestamp in UTC, ma mantieni il fuso orario del caso/cliente per la visualizzazione e il ragionamento degli utenti. Modella esplicitamente i calendari SLA (24/7 vs orari lavorativi, festività, orari regionali).
Testa i casi limite come i cambi di ora legale, casi creati vicino alla chiusura del lavoro e pause che iniziano esattamente al confine dello SLA.
Mantieni i ruoli della v1 semplici e allineati ai flussi reali:
Aggiungi regole di scope (team/regione/account) e controlli a livello di campo per dati sensibili come note interne e PII.
Progetta prima le schermate quotidiane:
Ottimizza per la scansione: le azioni rapide non devono essere nascose nei menu.
Inizia con un piccolo set di notifiche ad alto segnale:
Scegli 1–2 canali per la v1 (di solito in-app + email), poi aggiungi una matrice di escalation con soglie chiare (T–2h, T–0h, T+1h). Previeni il sovraccarico con deduplica, batching e quiet hours, e rendi acknowledge/snooze tracciabili nell’audit.
Integra solo ciò che mantiene le timeline accurate:
Se fai sync bidirezionale, definisci una source of truth per ogni campo e regole di conflitto (evita “last write wins”). Pubblica un contratto API minimale e versionato così le integrazioni non si rompono. Per più dettagli su automazione, vedi /blog/workflow-automation-basics; per aspetti di packaging, vedi /pricing.
due_at