26 nov 2025·8 min
Come creare un'app web per monitorare i colli di bottiglia operativi
Guida passo passo per pianificare, progettare e rilasciare un'app web che cattura i dati dei workflow, individua i colli di bottiglia e aiuta i team a correggere i ritardi.
Parti dal problema e dalle decisioni
Un'app per tracciare i processi aiuta solo se risponde a una domanda specifica: “Dove ci stiamo bloccando e cosa dovremmo fare al riguardo?” Prima di disegnare schermate o scegliere un'architettura per l'app, definisci cosa significa “collo di bottiglia” nella tua operazione.
Definisci cosa conta come collo di bottiglia
Un collo di bottiglia può essere un passo (es., “revisione QA”), un team (es., “evasione ordini”), un sistema (es., “gateway di pagamento”) o persino un fornitore (es., “ritiro corriere”). Scegli le definizioni che davvero intendi gestire. Per esempio:
- Un passo è un collo di bottiglia quando il suo tempo medio di coda supera le 24 ore.
- Un team è un collo di bottiglia quando il lavoro in corso rimane sopra una soglia fissata per 3 giorni.
- Un sistema è un collo di bottiglia quando gli incidenti causano un picco dei tempi di ciclo oltre un intervallo concordato.
Elenca le decisioni che l'app deve abilitare
Il tuo cruscotto operativo dovrebbe guidare l'azione, non solo il reporting. Scrivi le decisioni che vuoi prendere più velocemente e con maggiore fiducia, come:
- Staffing: “Spostiamo una persona dal Team A al Team B questa settimana?”
- Prioritizzazione: “Quali ordini/ticket devono saltare la coda per proteggere gli SLA?”
- Automazione: “Quale passo è abbastanza stabile (e costoso) da automatizzare per primo?”
Identifica gli utenti principali e cosa gli serve
Utenti diversi hanno viste diverse:
- Manager operativi hanno bisogno di una vista chiara “dove intervenire oggi”.
- Team lead hanno bisogno di drill-down su code individuali, blocchi e passaggi di consegne.
- Analisti hanno bisogno di definizioni coerenti ed esportazioni per l'analisi dei flussi di lavoro.
Definisci metriche di successo per l'app stessa
Decidi come riconoscere che l'app funziona. Buone misure includono adozione (utenti attivi settimanali), tempo risparmiato sul reporting e risoluzione più rapida (riduzione del tempo di rilevamento e di risoluzione dei colli di bottiglia). Queste metriche mantengono il focus sugli esiti, non sulle funzionalità.
Scegli il flusso di lavoro e scrivi una mappa di processo semplice
Prima di progettare tabelle, dashboard o avvisi, scegli un flusso che puoi descrivere in una frase. L'obiettivo è tracciare dove il lavoro attende—quindi inizia in piccolo e scegli uno o due processi che contano e generano volume costante, come evasione ordini, ticket di supporto o onboarding dei dipendenti.
Un ambito ristretto mantiene chiara la definizione di fatto compiuto e impedisce al progetto di bloccarsi perché team diversi non concordano su come il processo dovrebbe funzionare.
Inizia con 1–2 processi ad alto segnale
Scegli workflow che:
- Succedono frequentemente (abbastanza dati per individuare pattern)
- Attraversano almeno un passaggio di consegna (dove si formano le code)
- Hanno un impatto cliente chiaro (tempo, costo, soddisfazione)
Per esempio, “ticket di supporto” è spesso meglio di “customer success” perché ha un'unità di lavoro ovvia e azioni timestampate.
Mappa passi e passaggi di consegna in linguaggio semplice
Scrivi il workflow come una lista semplice di passi usando parole già usate dal team. Non stai documentando policy—stai identificando gli stati attraverso i quali l'elemento di lavoro si sposta.
Una mappa di processo leggera potrebbe apparire così:
- Ticket creato → triage → assegnato → agente al lavoro → in attesa del cliente → risolto
In questa fase, segnala esplicitamente i passaggi di consegna (triage → assegnato, agente → specialista, ecc.). I passaggi di consegna sono dove il tempo di coda tende a nascondersi, e sono i momenti che vorrai misurare in seguito.
Definisci eventi di inizio/fine e cosa significa “fatto” per ogni passo
Per ogni passo, scrivi due cose:
- Evento di inizio (cosa prova che il passo è iniziato?)
- Evento di fine (cosa prova che il passo è terminato?)
Mantienili osservabili. “L'agente inizia a investigare” è soggettivo; “status cambiato in In Progress” o “prima nota interna aggiunta” è misurabile.
Definisci anche cosa significa “fatto” così l'app non confonde un completamento parziale con il completamento. Per esempio, “risolto” potrebbe significare “messaggio di risoluzione inviato e ticket marcato come Risolto”, non solo “lavoro completato internamente”.
Nota le eccezioni comuni che traccerai in seguito
Le operazioni reali includono percorsi disordinati: rifacimenti, escalation, informazioni mancanti e riaperture. Non cercare di modellare tutto dal giorno uno—semplicemente annota le eccezioni così potrai aggiungerle intenzionalmente più avanti.
Una semplice nota come “10–15% dei ticket vengono escalati al Tier 2” è sufficiente. Userai queste note per decidere se le eccezioni diventano passi propri, tag o flussi separati quando espandi il sistema.
Definisci metriche che rivelano davvero i colli di bottiglia
Un collo di bottiglia non è una sensazione—è un rallentamento misurabile in uno specifico passo. Prima di costruire grafici, decidi quali numeri proveranno dove il lavoro si accumula e perché.
Scegli un piccolo set di misure core
Inizia con quattro metriche che funzionano nella maggior parte dei workflow:
- Tempo di ciclo (cycle time): quanto impiega un elemento dal inizio al fine.
- Tempo di attesa/coda: quanto un elemento resta inerte tra i passi.
- Throughput: quanti elementi sono completati per periodo.
- WIP (work in progress): quanti elementi sono attualmente “nel sistema”.
Coprono velocità (ciclo), inattività (coda), output (throughput) e carico (WIP). La maggior parte dei “ritardi misteriosi” emerge come aumento del tempo di coda e del WIP in un passo particolare.
Definisci i calcoli (inclusi i casi limite)
Scrivi definizioni su cui tutto il team può concordare, poi implementale esattamente.
- Cycle time =
done_timestamp − start_timestamp.- Casi limite: elementi riaperti (trattarli come un nuovo ciclo vs estendere l'originale), elementi mai iniziati (escluderli dal cycle time ma contarli nel WIP), timestamp mancanti (segnalarli come qualità dati).
- Queue time = somma dei gap tra i passi dove lo stato è “in attesa”.
- Casi limite: notti/weekend (tempo calendario vs ore lavorative), stati bloccati (contarli separatamente dall'attesa normale se vuoi cause più chiare).
- Throughput = conteggio degli elementi con
done_timestampnella finestra.- Casi limite: cancellazioni (escludere o tracciare separatamente), completamenti parziali.
- WIP = conteggio degli elementi non in stato terminale in un dato istante.
- Casi limite: elementi on-hold (ancora WIP, ma potresti volere una “WIP bloccata” separata).
Scegli le segmentazioni che guidano le decisioni
Scegli le suddivisioni che i tuoi manager usano davvero: team, canale, linea di prodotto, regione e priorità. L'obiettivo è rispondere a: “Dove è lento, per chi e in quali condizioni?”
Imposta finestre temporali e obiettivi
Decidi il ritmo di reporting (giornaliero e settimanale sono comuni) e definisci obiettivi come soglie SLA/SLO (per esempio, “80% degli elementi ad alta priorità completati entro 2 giorni”). Gli obiettivi rendono il cruscotto azionabile invece che decorativo.
Pianifica le sorgenti dati e il metodo di raccolta
Il modo più veloce per bloccare un'app di monitoraggio colli di bottiglia è presumere che i dati “siano lì”. Prima di progettare tabelle o grafici, annota da dove originerà ogni evento e timestamp—and come manterrai la coerenza nel tempo.
Inventario delle sorgenti già disponibili
La maggior parte dei team operativi già traccia il lavoro in pochi posti. Punti di partenza comuni includono:
- Fogli di calcolo usati per passaggi, registri giornalieri o conteggi di produzione
- Sistemi ERP/CRM (ordini, clienti, passi di evasione)
- Strumenti di ticketing (code di supporto, richieste di modifica, attività di manutenzione)
- Database interni (scansioni di magazzino, tabelle di schedulazione lavori, dati di esecuzione produzione)
Per ogni sorgente, nota cosa può fornire: un ID record stabile, una cronologia degli status (non solo lo status corrente) e almeno due timestamp (entrata passo, uscita passo). Senza questi, il monitoraggio del tempo di coda e il tracciamento del tempo di ciclo saranno congetture.
Scegli un metodo di cattura adatto alla sorgente
In generale hai tre opzioni, e molte app finiscono per usare un mix:
- API pull: sincronizzazione programmata da ERP/CRM/strumenti di ticketing. Facile da ragionare, ma devi gestire paginazione, rate limit e aggiornamenti incrementali.
- Webhooks: push di aggiornamenti quando il lavoro cambia. Ottimo per avvisi quasi in tempo reale sui colli di bottiglia, ma devi progettare retry e eventi fuori ordine.
- Inserimento manuale / import CSV: utile per team che partono da fogli o per casi di confine. Rendilo sicuro con template, validazione e messaggi di errore chiari.
Pianifica la qualità dei dati (perché succederà)
Aspettati timestamp mancanti, duplicati e status incoerenti (“In Progress” vs “Working”). Costruisci regole presto:
- Preferisci un log di eventi immutabile rispetto alla sovrascrittura dei record
- Deduplica per source ID + event time + status
- Normalizza gli status nel modello canonico dell'app
- Segnala i record che non possono produrre un ciclo di tempo affidabile
Decidi la frequenza di aggiornamento
Non tutti i processi richiedono aggiornamenti in tempo reale. Scegli in base alle decisioni:
- Tempo reale: dispatching, triage supporto, rischio SLA
- Orario: throughput magazzino, monitoraggio tempo di coda
- Giornaliero: reportistica settimanale, revisioni di miglioramento continuo
Annotalo ora; guida la strategia di sincronizzazione, i costi e le aspettative per il cruscotto operativo.
Progetta un modello dati pensato per l'analisi temporale
Un'app per tracciare i colli di bottiglia vive o muore da quanto bene risponde a domande temporali: “Quanto ha impiegato questo?”, “Dove ha atteso?”, “Cosa è cambiato subito prima che le cose rallentassero?” Il modo più semplice per supportare queste domande in seguito è modellare i dati attorno a eventi e timestamp fin dal primo giorno.
Inizia con le entità core
Mantieni il modello piccolo e ovvio:
- Process: il workflow complessivo (es., “Evasione ordini”).
- Step: una fase all'interno del processo (es., “Pick”, “Pack”, “Ship”).
- Work item: l'unità che si muove tra i passi (ticket, ordine, reclamo).
- Event: un cambiamento di stato registrato (entrata in passo, assegnato, bloccato, completato).
- User/Team e Assignment: chi possedeva il lavoro in un dato momento.
Questa struttura ti permette di misurare il tempo di ciclo per passo, il tempo di coda tra passi e il throughput su tutto il processo senza inventare casi speciali.
Preferisci un log di eventi ai campi “stato corrente”
Tratta ogni cambiamento di stato come un record evento immutabile. Invece di sovrascrivere current_step e perdere la storia, appendi un evento tipo:
- work_item_id
- from_step → to_step (o “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Puoi comunque memorizzare uno snapshot di “stato corrente” per velocità, ma le tue analisi dovrebbero basarsi sul log di eventi.
Rendi tempo e tracciabilità non negoziabili
Memorizza i timestamp in UTC in modo coerente. Conserva anche identificatori originali della sorgente (es., Jira issue key, ERP order ID) su work item ed eventi, così ogni grafico può essere ricondotto a un record reale.
Cattura le eccezioni senza creare lavoro inutile
Pianifica campi leggeri per i momenti che spiegano i ritardi:
- reason_code (opzioni standard come “In attesa cliente”)
- comment (testo opzionale)
- blocked_flag o severity
Rendili opzionali e facili da compilare, così impari dalle eccezioni senza trasformare l'app in un esercizio di compilazione form.
Scegli un'architettura adatta al tuo team
Mantieni il controllo completo del sorgente
Porta con te il codice sorgente generato quando sarai pronto per la proprietà a lungo termine.
L'“architettura migliore” è quella che il tuo team sa costruire, comprendere e gestire per anni. Parti scegliendo uno stack che corrisponda al bacino di assunzione e alle competenze esistenti—scelte comuni e ben supportate includono React + Node.js, Django o Rails. La coerenza batte la novità quando gestisci un cruscotto operativo da cui le persone dipendono quotidianamente.
Separa le responsabilità così il sistema resta modificabile
Un'app per tracciare colli di bottiglia funziona meglio quando è divisa in livelli chiari:
- Ingestione: ricevere eventi (cambi di stato, timestamp, passaggi) da form, integrazioni o import.
- Storage: un database transazionale per scritture affidabili e storico audit.
- Query analitiche: query o view ottimizzate per leggere e calcolare tempo di ciclo, tempo di coda e throughput.
- UI/API: endpoint e schermate che mantengono i dashboard veloci e prevedibili.
Questa separazione ti permette di cambiare una parte (per esempio aggiungere una nuova sorgente dati) senza riscrivere tutto.
Decidi dove devono vivere i calcoli
Alcune metriche sono abbastanza semplici da calcolare in query di database (es., “tempo medio di coda per passo ultimi 7 giorni”). Altre sono costose o richiedono pre-elaborazione (es., percentili, rilevamento anomalie, coorti settimanali). Una regola pratica:
- Fai filtri e breakdown in tempo reale nel database.
- Usa job in background per precomputare aggregati pesanti e salvarli per caricamenti rapidi del dashboard.
- Aggiungi un livello analytics solo se il tuo team saprà mantenerlo con fiducia.
Pianifica le prestazioni presto
I cruscotti operativi falliscono quando sembrano lenti. Usa indici su timestamp, ID passo del workflow e tenant/team ID. Aggiungi paginazione per i log di eventi. Cache le viste dashboard comuni (come “oggi” e “ultimi 7 giorni”) e invalida le cache quando arrivano nuovi eventi.
Se vuoi approfondire i compromessi, conserva un breve registro decisionale nel repo così i cambiamenti futuri non devieranno.
Un percorso più veloce per team che vogliono spedire rapidamente
Se l'obiettivo è validare analytics di workflow e alerting prima di impegnarsi in una build completa, una piattaforma vibe-coding come Koder.ai può aiutarti a mettere in piedi una prima versione più velocemente: descrivi il workflow, le entità e le dashboard in chat, poi iteri sull'UI React generata e sul backend Go + PostgreSQL mentre affini la strumentazione KPI.
Il vantaggio pratico per un'app di monitoraggio colli di bottiglia è la rapidità del feedback: puoi pilotare l'ingestione (API pull, webhooks o import CSV), aggiungere schermate di drill-down e adattare le definizioni metriche senza settimane di scaffolding. Quando sei pronto, Koder.ai supporta anche l'esportazione del codice sorgente e il deployment/hosting, rendendo più facile spostare il prototipo verso uno strumento interno manutenibile.
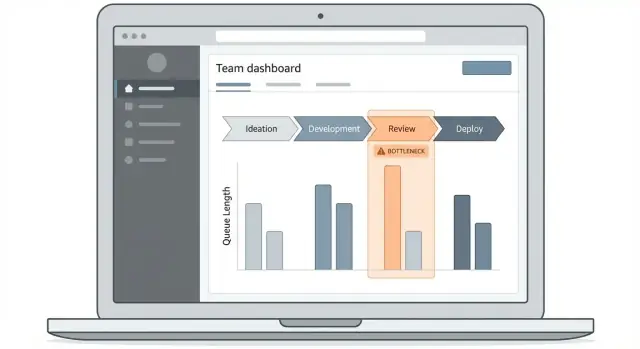
Progetta l'esperienza del dashboard e del drill-down
Un'app per tracciare i colli di bottiglia riesce o fallisce in base al fatto che le persone riescano a rispondere rapidamente a una domanda: “Dove il lavoro si sta bloccando adesso, e quali elementi lo stanno causando?” Il tuo cruscotto dovrebbe rendere ovvio quel percorso, anche per chi vi accede solo una volta alla settimana.
Inizia con 2–3 schermate core
Mantieni la prima release compatta:
- Cruscotto panoramico: il “status board” per tempo di ciclo, tempo di coda e passi più bloccati.
- Lista work-item: una tabella ricercabile e filtrabile degli elementi colpiti dai ritardi.
- Dettaglio workflow: una vista passo-passo che mostra il tempo in ogni fase e i punti di consegna.
Queste schermate creano un flusso di drill-down naturale senza costringere gli utenti a imparare un'interfaccia complessa.
Usa visual che spiegano tempo e flusso
Scegli tipi di grafico che corrispondono a domande operative:
- Funnel per fase: mostra dove il volume si accumula (utile per individuare code).
- Barre tempo-in-fase: confrontano i passi per mediana e percentile, non solo per medie.
- Linee di trend: rispondono a “sta migliorando o peggiorando?” nel tempo.
- Heatmap: rivelano pattern come “lunedì in revisione” o “passaggi turno notte”.
Mantieni le etichette semplici: “Tempo d'attesa” invece di “Queue latency”.
Rendi i filtri coerenti e difficili da perdere
Usa una barra filtri condivisa tra le schermate (stessa posizione, stessi default): intervallo data, team, priorità e passo. Mostra i filtri attivi come chip così le persone non interpretano male i numeri.
Progetta percorsi di drill-down chiari
Ogni riquadro KPI dovrebbe essere cliccabile e portare a qualcosa di utile:
KPI → passo → lista elementi impattati
Esempio: cliccando “Tempo di coda più lungo” si apre il dettaglio passo, poi un singolo click mostra gli elementi esattamente in attesa lì—ordinati per età, priorità e proprietario. Questo trasforma la curiosità in una lista di cose da fare concreta, che è ciò che rende il cruscotto usato invece che ignorato.
Aggiungi avvisi e segnali di preallarme
Progetta i permessi presto
Includi viewer, manager e admin oltre a tracciamento delle modifiche audit-friendly.
I dashboard sono ottimi per le revisioni, ma i colli di bottiglia di solito fanno danno tra le riunioni. Gli avvisi trasformano la tua app in un sistema di preallarme: trovi i problemi mentre si stanno formando, non dopo che la settimana è persa.
Inizia con regole chiare e noiose
Comincia con un piccolo set di tipi di avviso che il team già considera “fatti negativi”:
- Superamenti soglia: tempo di ciclo o tempo di coda sopra un limite noto (es., “Review step > 24 hours”).
- Aumenti anomali: la mediana del tempo di ciclo di oggi è aumentata del 30% vs la settimana scorsa.
- Elementi bloccati: nessun cambio di status per N ore/giorni, o elementi che superano un'età massima.
Mantieni la prima versione semplice. Poche regole deterministiche catturano la maggior parte dei problemi e sono più facili da fidarsi rispetto a modelli complessi.
Aggiungi controlli di anomalia leggeri
Quando le soglie sono stabili, aggiungi segnali base del tipo “è strano questo?”:
- Variazione percentuale vs settimana scorsa (confrontare lo stesso giorno della settimana riduce falsi allarmi).
- Deriva della media mobile (es., media a 7 giorni in aumento costante).
- Discrepanze di volume (input che cresce più rapidamente dell'output in un passo).
Rendi le anomalie suggerimenti, non emergenze: etichettale come “Heads up” finché gli utenti non confermano che sono utili.
Consegnare gli avvisi dove le persone lavorano
Supporta canali multipli così i team scelgono ciò che si adatta:
- Email per manager e sommari giornalieri
- Slack/Microsoft Teams per triage in tempo reale
- Notifiche in-app per i responsabili dentro lo strumento
Rendi ogni avviso azionabile
Un avviso dovrebbe rispondere a “cosa, dove e cosa fare dopo”:
- Quale passo è impattato, e l'intervallo temporale
- I principali fattori (es., team, categoria, priorità)
- Un link diretto per indagare, come:
/dashboard?step=review&range=7d&filter=stuck
Se gli avvisi non portano a una azione concreta, le persone li silenzieranno—perciò tratta la qualità degli avvisi come una feature di prodotto, non un extra.
Gestisci permessi, sicurezza e auditabilità
Un'app per tracciare colli di bottiglia diventa rapidamente una “fonte di verità”. Fantastico—finché la persona sbagliata non modifica una definizione, esporta dati sensibili o condivide un cruscotto fuori dal proprio team. Permessi e tracce di audit non sono burocrazia; proteggono la fiducia nei numeri.
Definisci ruoli e regole di accesso
Inizia con un modello di ruoli piccolo e chiaro e allarcalo solo se necessario:
- Viewer: accesso in sola lettura a dashboard e report.
- Manager: può filtrare per team, creare viste salvate, riconoscere avvisi e aggiungere note (ma non può cambiare impostazioni globali).
- Admin: gestisce definizioni di processo, formule KPI, integrazioni e accessi utente.
Sii esplicito su cosa può fare ogni ruolo: vedere eventi grezzi vs metriche aggregate, esportare dati, modificare soglie e gestire integrazioni.
Separa i dati per team o unità di business
Se più team usano l'app, applica la separazione al livello dati—non solo nell'interfaccia. Opzioni comuni:
- Multi-tenant: ogni record ha un
tenant_id, e ogni query è scodata su di esso. - Partizioni/progetti: workspace separati per unità di business, con impostazioni e dashboard indipendenti.
Decidi presto se i manager possono vedere i dati di altri team. Rendi la visibilità cross-team un permesso deliberato, non il default.
Autenticazione sicura (SSO o pronta per MFA)
Se l'organizzazione ha SSO (SAML/OIDC), usalo in modo che il de-provisioning e il controllo accessi siano centralizzati. Altrimenti, implementa un login che sia MFA-ready (TOTP o passkeys), supporti reset password in modo sicuro e applichi timeout di sessione.
Rendi le modifiche auditabili
Registra le azioni che possono cambiare esiti o esporre dati: esportazioni, cambi di soglia, modifiche al workflow, aggiornamenti permessi e impostazioni di integrazione. Cattura chi l'ha fatta, quando, cosa è cambiato (prima/dopo) e dove (workspace/tenant). Fornisci una vista “Audit Log” così i problemi possono essere investigati rapidamente.
Trasforma gli insight in azioni e miglioramenti di processo
Un cruscotto sui colli di bottiglia conta solo se cambia ciò che le persone fanno dopo. L'obiettivo di questa sezione è trasformare “grafici interessanti” in un ritmo operativo ripetibile: decidere, agire, misurare e mantenere ciò che funziona.
Crea una review leggera dei colli di bottiglia
Stabilisci una cadenza settimanale semplice (30–45 minuti) con proprietari chiari. Inizia con i primi 1–3 colli di bottiglia per impatto (es., maggior tempo di coda o maggior calo di throughput), poi concorda un'azione per ciascun collo.
Mantieni il flusso piccolo:
- Owner: una persona responsabile per azione
- Data di scadenza: prossima review come default
- Definition of done: un cambiamento misurabile (non “investigare ancora”)
Registra le decisioni direttamente nell'app così il dashboard e il registro delle azioni restano collegati.
Traccia i miglioramenti come esperimenti
Tratta le correzioni come esperimenti per imparare rapidamente ed evitare “atti di ottimizzazione casuale”. Per ogni cambiamento, registra:
- Ipotesi (cosa rallenta e perché)
- Cambiamento (cosa farai)
- Impatto atteso (quale metrica dovrebbe muoversi e quanto)
- Risultato (cosa è successo davvero)
Col tempo, questo diventa un playbook di cosa riduce il tempo di ciclo, cosa riduce il rifacimento e cosa no.
Aggiungi contesto con annotazioni
I grafici possono fuorviare senza contesto. Aggiungi annotazioni semplici sulle timeline (es., nuovo assunto onboarded, outage sistema, aggiornamento policy) così chi guarda può interpretare correttamente spostamenti di tempo di coda o throughput.
Rendi la condivisione semplice
Fornisci opzioni di esportazione per analisi e report—download CSV e report schedulati—così i team possono includere i risultati nelle update operative e nelle review di leadership. Se hai già una pagina reportistica, collegala dal tuo cruscotto (es., /reports).
Distribuisci, monitora e mantieni i dati freschi
Spedisci il cruscotto principale
Avvia un cruscotto operativo con tempo di ciclo, tempo di attesa, throughput e WIP.
Un'app per tracciare colli di bottiglia è utile solo se è costantemente disponibile e i numeri restano affidabili. Tratta il deployment e la freschezza dei dati come parte del prodotto, non come un pensiero successivo.
Usa ambienti separati e deploy ripetibili
Configura dev / staging / prod presto. Lo staging dovrebbe rispecchiare la produzione (stesso motore DB, volume dati simile, stesse background job) così puoi intercettare query lente e migrazioni rotte prima che le vedano gli utenti.
Automatizza i deploy con una pipeline unica: esegui i test, applica le migrazioni, distribuisci e poi fai un rapido smoke check (login, carica il cruscotto, verifica che l'ingestione funzioni). Mantieni deploy piccoli e frequenti; riduce il rischio e rende realistico il rollback.
Monitora l'app e la pipeline
Vuoi monitoraggio su due fronti:
- Salute app: tassi di errore, latenza, endpoint lenti e query lente.
- Salute dati: fallimenti di ingestione, dimensione backlog e “tempo dall'ultimo evento ricevuto”.
Allerta su sintomi che gli utenti percepiscono (dashboards che timeout) e su segnali precoci (una coda che cresce per 30 minuti). Traccia anche i fallimenti di calcolo metriche—tempi di ciclo mancanti possono sembrare “miglioramento”.
Mantieni i dati freschi: eventi tardivi, correzioni e backfill
I dati operativi arrivano in ritardo, fuori ordine o vengono corretti. Pianifica per:
- Ingestione idempotente (reprocessare lo stesso evento non duplica i conteggi).
- Backfill per intervalli di date quando una sorgente era giù.
- Ricalcoli quando cambiano dati di riferimento (es., calendari di turno aggiornati).
Definisci cosa significa “fresco” (es., 95% degli eventi entro 5 minuti) e mostra la freschezza nell'interfaccia.
Scrivi runbook così le correzioni non sono lasciate al caso
Documenta runbook passo-passo: come riavviare una sync rotta, validare i KPI di ieri e confermare che un backfill non ha cambiato i numeri storici in modo inaspettato. Conservali con il progetto e collega i runbook da /docs così il team può rispondere rapidamente.
Itera con gli utenti ed espandi la copertura
Un'app per colli di bottiglia ha successo quando le persone si fidano di essa e la usano davvero. Questo accade solo dopo aver osservato utenti reali provare a rispondere a domande reali (“Perché le approvazioni sono lente questa settimana?”) e poi aver affinato il prodotto attorno a quei workflow.
Inizia con un pilot e impara cosa si rompe
Parti con un team pilota e un numero limitato di workflow. Mantieni lo scope abbastanza ristretto da poter osservare l'uso e rispondere rapidamente.
Nella prima settimana o due, concentrati su cosa confonde o manca:
- Quali grafici gli utenti fraintendono?
- Dove si bloccano durante il drill-down?
- Quali dati si aspettano di vedere ma non trovano?
- Quali colli di bottiglia operativi sembrano “ovvi” per loro ma non sono riflessi nell'app?
Raccogli feedback nello strumento stesso (un semplice “È stato utile?” su schermate chiave funziona bene) così non dipendi dalla memoria delle riunioni.
Convalida le metriche per evitare “litigi sul cruscotto”
Prima di espandere ad altri team, blocca le definizioni con le persone che saranno tenute responsabili. Molti rollout falliscono perché i team non si mettono d'accordo sul significato di una metrica.
Per ogni KPI (tempo di ciclo, tempo di coda, tasso di rifacimento, violazioni SLA), documenta:
- Eventi esatti di inizio e fine
- Gestione delle pause, weekend e timestamp mancanti
- Come vengono contate le eccezioni (cancellazioni, escalation, riaperture)
Poi rivedi queste definizioni con gli utenti e aggiungi tooltip brevi nell'interfaccia. Se modifichi una definizione, mostra un changelog chiaro così le persone capiscano perché i numeri si sono mossi.
Espandi la copertura senza trasformare l'app in un pasticcio
Aggiungi funzionalità con cura e solo quando le analytics del team pilota sono stabili. Espansioni comuni includono passi personalizzati (team diversi etichettano fasi in modo differente), sorgenti aggiuntive (ticket + CRM + fogli di calcolo) e segmentazione avanzata (per linea prodotto, regione, priorità, tier cliente).
Una regola utile: aggiungi una nuova dimensione alla volta e verifica che migliori le decisioni, non solo il reporting.
Rendi l'onboarding semplice e ripetibile
Man mano che distribuisci ad altri team, ti servirà coerenza. Crea una breve guida di onboarding: come collegare i dati, come interpretare il cruscotto operativo e come agire sugli avvisi per i colli di bottiglia.
Collega le persone alle pagine rilevanti dentro il prodotto e ai contenuti, come /pricing e /blog, così i nuovi utenti possono trovare risposte in autonomia invece di aspettare sessioni di training.