Definisci l'obiettivo del monitoraggio SLA
Prima di progettare schermate o scrivere la logica di rilevamento, chiarisci esattamente cosa l'app vuole prevenire. “Monitoraggio SLA” può significare qualsiasi cosa, da un report giornaliero a una predizione delle violazioni secondo per secondo—sono prodotti molto diversi con esigenze architetturali molto diverse.
Decidi cosa significa “tempo reale” (e perché)
Inizia concordando la finestra di reazione che il tuo team può realisticamente rispettare.
Se il tuo supporto opera in cicli di 5–10 minuti (code di triage, rotazioni di paging), allora “tempo reale” potrebbe significare aggiornamenti della dashboard ogni minuto con avvisi entro 2 minuti. Se gestisci incidenti ad alta severità dove i minuti contano, potresti aver bisogno di un loop di rilevamento e notifica di 10–30 secondi.
Scrivilo come obiettivo misurabile, per esempio: “Rilevare potenziali violazioni entro 60 secondi e notificare l'on‑call entro 2 minuti.” Questo diventa un vincolo per i compromessi futuri su architettura e costi.
Chiarisci quali SLA devi monitorare
Elenca le promesse specifiche che stai tracciando e definisci ognuna in linguaggio semplice:
- First response time (es.: “rispondere entro 1 ora”)
- Resolution time (es.: “risolvere entro 24 ore”, spesso con regole di pausa)
- Uptime/disponibilità (es.: “99,9% mensile”)
Annota anche come queste si rapportano a SLO e SLA nella tua organizzazione. Se il tuo SLO interno differisce dall'SLA rivolto al cliente, l'app potrebbe dover tracciare entrambi: uno per il miglioramento operativo, l'altro per il rischio contrattuale.
Identifica stakeholder e responsabili delle decisioni
Nomina i gruppi che useranno o si affideranno al sistema: supporto, engineering, customer success, team lead/manager e incident response/on‑call.
Per ciascun gruppo, cattura cosa devono decidere sul momento: “Questo ticket è a rischio?”, “Chi lo possiede?”, “Serve escalation?” Questo modellerà la dashboard, l'instradamento degli avvisi e i permessi.
Definisci le azioni che l'app deve attivare
Lo scopo non è solo visibilità—è azione tempestiva. Decidi cosa deve succedere quando il rischio aumenta o si verifica una violazione:
- Inviare avvisi in tempo reale su Slack/email/pager
- Escalare in base a severità, tier cliente o orario lavorativo
- Creare automaticamente un task (Jira/Linear) e assegnare un proprietario
Un buon risultato atteso: “Ridurre le violazioni SLA abilitando il rilevamento dei breach e la risposta agli incidenti entro la nostra finestra di reazione concordata.”
Mappa le regole SLA e i casi limite
Prima di costruire la logica di rilevamento, scrivi esattamente cosa è “buono” e cosa è “cattivo” per il tuo servizio. La maggior parte dei problemi di monitoraggio SLA non è tecnica—sono problemi di definizione.
SLA vs SLO vs KPI (linguaggio semplice)
Una SLA (Service Level Agreement) è una promessa ai clienti, di solito con conseguenze (crediti, penali, clausole contrattuali). Un SLO (Service Level Objective) è un obiettivo interno che cerchi di raggiungere per restare al di sopra dell'SLA. Un KPI (Key Performance Indicator) è qualsiasi metrica che monitori (utile, ma non sempre legata a una promessa).
Esempio: SLA = “rispondere entro 1 ora.” SLO = “rispondere entro 30 minuti.” KPI = “tempo medio di prima risposta.”
Definisci chiaramente i tipi di violazione
Elenca ogni tipo di violazione che devi rilevare e l'evento che avvia il timer.
Categorie comuni di violazione:
- Missed response time: es., ticket creato alle 10:00; la prima risposta dell'agente deve avvenire entro le 11:00.
- Missed resolution time: es., ticket aperto; deve essere marcato come risolto entro 24 ore (escludendo pause approvate).
- Soglia di downtime: es., disponibilità del servizio sotto il 99,9% mensile, o un singolo outage che supera i 15 minuti.
Sii esplicito su cosa conta come “risposta” (reply pubblico vs nota interna) e “risoluzione” (resolved vs closed), e se la riapertura azzera o meno il timer.
Orari lavorativi, 24/7 e regole sui fusi orari
Molti SLA contano il tempo solo durante gli orari lavorativi. Definisci il calendario: giorni lavorativi, festività, orari di inizio/fine e il fuso orario usato per il calcolo (del cliente, del contratto o del team). Decidi anche cosa succede quando il lavoro attraversa questi confini (es., ticket arriva alle 16:55 con SLA di 30 minuti).
Condizioni di pausa ed esclusioni
Documenta quando l'orologio SLA si ferma, ad esempio:
- In attesa cliente (informazioni richieste non fornite)
- Finestra di manutenzione programmata
- Dipendenza di terze parti in attesa (se il contratto lo permette)
Scrivi queste condizioni come regole che l'app può applicare in modo consistente e conserva esempi di casi complessi per i test successivi.
Scegli sorgenti dati ed eventi da tracciare
Il monitor SLA è buono quanto i dati che lo alimentano. Inizia identificando i “sistemi di record” per ogni orologio SLA. Per molte squadre, lo strumento di ticketing è la fonte di verità per i timestamp del ciclo di vita, mentre monitoring e logging spiegano perché qualcosa è accaduto.
Scegli i sistemi che contengono la verità
La maggior parte delle soluzioni real‑time preleva dati da un set ridotto di sistemi core:
- Ticketing/helpdesk (es., Zendesk, ServiceNow, Jira Service Management): priorità, stato, assegnatario, cliente, timestamp
- Strumenti di monitoring/incident (es., Datadog, PagerDuty): incidente aperto/acknowledged/resolved, azioni on‑call
- CRM/dati account (es., Salesforce, HubSpot): tier cliente, SLA contrattuale, piano di supporto
- Log e audit trail (log applicativi, log di workflow): contesto dettagliato per indagini e dispute
Se due sistemi non sono d'accordo, decidi in anticipo quale prevale per ciascun campo (per esempio: “stato ticket da ServiceNow, tier cliente dal CRM”).
Elenca gli eventi necessari (e quelli che la gente dimentica)
Come minimo, traccia gli eventi che avviano, fermano o cambiano il timer SLA:
- Ticket created (parte l'SLA)
- Status changed (inclusi “waiting on customer”, “on hold”, o stati di “paused”)
- Assigned / reassigned (spesso impatta le regole di escalation)
- Priority o severity changed (può cambiare l'obiettivo a metà processo)
- First response sent e resolved/closed (si ferma l'SLA)
Considera anche eventi operativi: cambi al calendario degli orari lavorativi, aggiornamenti del fuso orario del cliente e modifiche al programma di festività.
Decidi come recuperare i dati
Preferisci webhook per aggiornamenti near‑real‑time. Usa polling quando i webhook non sono disponibili o non sono affidabili. Mantieni export API/backfill per riconciliazioni (per esempio, job notturni che riempiono i gap). Molte squadre finiscono con un ibrido: webhook per velocità, polling periodico per sicurezza.
Pianifica problemi di qualità dei dati
I sistemi reali sono disordinati. Aspettati:
- Timestamp mancanti (memorizza “sconosciuto” e segnala per revisione)
- Eventi duplicati (usa chiavi di idempotenza e regole di dedup)
- Consegna fuori ordine e skew di clock (ordina per timestamp di origine + tempo di ingestione e rileva durate negative)
Tratta questi come requisiti di prodotto, non come “casi limite”—il rilevamento dei breach dipende dalla loro corretta gestione.
Progetta un'architettura ad alto livello semplice
Un buon monitor SLA è più facile da costruire (e mantenere) quando l'architettura è chiara e intenzionalmente semplice. A livello alto, stai costruendo una pipeline che trasforma segnali operativi grezzi in “stato SLA”, poi usa quello stato per avvisare le persone e alimentare una dashboard.
I componenti core
Pensa a cinque blocchi:
- Ingest: raccogli eventi e metriche da ticketing, monitoraggio, log o app interne.
- Process: normalizza i dati, correlali a clienti/servizi e calcola timer e soglie SLA.
- Store: conserva sia lo stato SLA corrente (letture veloci) che i record storici/audit (tracciabilità).
- Alert: genera notifiche ed escalation quando un breach è previsto o avviene.
- Display: una web app per “cosa è a rischio ora”, più drill‑down per le indagini.
Questa separazione mantiene pulite le responsabilità: l'ingest non dovrebbe contenere la logica SLA e le dashboard non dovrebbero eseguire calcoli pesanti.
Streaming vs ricalcolo frequente
Decidi presto quanto “real‑time” ti serve davvero.
- Event streaming (consigliato per reazione rapida): quando arrivano eventi (incidente aperto, stato cambiato, servizio giù), aggiorna immediatamente lo stato SLA. Questo supporta predizione dei breach a bassa latenza e avvisi rapidi.
- Ricalcolo frequente (più semplice per iniziare): esegui un job schedulato ogni N minuti che ricalcola il rischio SLA dai dati recenti. Funziona per SLA con finestre di ore, ma può perdere picchi brevi o creare avvisi rumorosi intorno ai cicli di refresh.
Un approccio pragmatico è partire con ricalcolo frequente per una o due regole SLA, poi spostare in streaming le regole ad alto impatto.
Parti con un modello di deployment semplice
Evita complessità multi‑regione e multi‑ambiente all'inizio. Una singola regione, un ambiente di produzione e un staging minimale sono solitamente sufficienti finché non valuti la qualità dei dati e l'utilità degli avvisi. Fai del “scalare dopo” un vincolo di progetto, non un requisito di partenza.
Se vuoi accelerare la versione funzionante iniziale della dashboard e dei workflow, una piattaforma di sviluppo guidato come Koder.ai può aiutarti a scaffolding una UI React e un backend Go + PostgreSQL rapidamente da uno spec chat‑driven, poi iterare su schermate e filtri mentre verifichi cosa servono davvero i responder.
Requisiti non funzionali da fissare ora
Annotali prima di implementare:
- Obiettivo di disponibilità per il sistema di monitoraggio stesso (es., 99,9%).
- Latenza end‑to‑end da evento a dashboard/avviso (es., <60 secondi).
- Retention per cronologia e audit (es., 13 mesi).
- Auditabilità: ogni cambiamento di stato SLA deve essere spiegabile (“quale evento ha causato questo?”).
Costruisci ingestion e normalizzazione degli eventi
L'ingestione degli eventi è il punto in cui il tuo sistema di monitoraggio SLA diventa affidabile—o rumoroso e confuso. L'obiettivo è semplice: accettare eventi da tanti strumenti, convertirli in un formato unico “veritiero” e memorizzare abbastanza contesto per spiegare ogni decisione SLA in seguito.
Definisci uno schema evento chiaro
Inizia standardizzando cosa è un “evento rilevante per SLA”, anche se i sistemi upstream variano. Uno schema di base pratico include:
ticket_id (o ID caso/work item)timestamp (quando è avvenuto il cambiamento, non quando lo hai ricevuto)status (opened, assigned, waiting_on_customer, resolved, ecc.)priority (P1–P4 o equivalente)customer (identificatore account/tenant)sla_plan (quali regole SLA si applicano)
Versiona lo schema (es., schema_version) così puoi evolvere i campi senza rompere i produttori più vecchi.
Normalizza prima di calcolare
Sistemi differenti chiamano le stesse cose in modo diverso: “Solved” vs “Resolved”, “Urgent” vs “P1”, differenze di fuso orario o priorità mancanti. Costruisci un piccolo layer di normalizzazione che:
- mappi gli status a un insieme coerente
- converta i timestamp in UTC
- riempia i valori di default (o segnali i record) quando mancano campi obbligatori
- allega campi derivati (come
is_customer_wait o is_pause) che semplificano la logica dei breach dopo
Idempotenza: non contare gli eventi due volte
Le integrazioni fanno retry. L'ingest deve essere idempotente così eventi ripetuti non creano duplicati. Approcci comuni:
- richiedere un
event_id dal produttore e rifiutare i duplicati
- generare una chiave deterministica (es.,
ticket_id + timestamp + status) e fare upsert
Conserva una traccia di audit spiegabile
Quando qualcuno chiede “Perché abbiamo inviato un avviso?” serve una pista di carta. Memorizza ogni evento raw accettato e ogni evento normalizzato, più chi/che cosa lo ha modificato. Questa cronologia di audit è essenziale per conversazioni con clienti e revisioni interne.
Gestione dead‑letter per i fallimenti
Alcuni eventi falliranno il parsing o la validazione. Non scartarli silenziosamente. Instradali in una dead‑letter queue/tabella con motivo dell'errore, payload originale e conteggio retry, così puoi correggere le mappature e riprodurli in sicurezza.
Scegli dove salvare stato, cronologia e audit
Genera l'app full‑stack
Genera rapidamente una UI React e un backend Go + PostgreSQL in pochi minuti, poi affina i flussi di lavoro.
La tua app SLA ha bisogno di due “memorie” diverse: ciò che è vero ora (per attivare avvisi) e cosa è successo nel tempo (per spiegare e provarne il motivo).
Conserva lo stato corrente per decisioni veloci
Lo stato corrente è l'ultimo stato noto di ogni work item (ticket/incidente/ordine) più i timer SLA attivi (start time, paused time, due time, minuti rimanenti, owner corrente).
Scegli uno store ottimizzato per letture/scritture veloci per ID e filtri semplici. Opzioni comuni sono un database relazionale (Postgres/MySQL) o un key‑value store (Redis/DynamoDB). Per molte squadre, Postgres è sufficiente e mantiene semplice il reporting.
Mantieni il modello di stato piccolo e query‑friendly. Lo leggerai costantemente per viste come “in scadenza a breve”.
Conserva la cronologia come log di eventi append‑only
La cronologia dovrebbe catturare ogni cambiamento come record immutabile: creato, assegnato, priorità cambiata, stato aggiornato, cliente ha risposto, on‑hold iniziato/terminato, ecc.
Una tabella append‑only degli eventi (o event store) rende possibili audit e replay. Se poi scopri un bug nella logica dei breach, puoi riprocessare gli eventi per ricostruire lo stato e confrontare i risultati.
Pattern pratico: tabella stato + tabella eventi nello stesso database all'inizio; passa a uno storage analitico separato se il volume cresce.
Decisioni su retention e archiviazione
Definisci la retention per scopo:
- Viste operative: conserva stato recente e una finestra di storia corta in modo rapido (es., 30–90 giorni).
- Audit/compliance: conserva gli eventi più a lungo (es., 1–7 anni), poi archivia in storage più economico.
Usa partizionamenti (per mese/trimestre) per rendere archiviazione ed eliminazioni prevedibili.
Indici e query per le schermate principali
Progetta intorno alle domande che la dashboard farà più spesso:
- “Breaching soon”: indice su
due_at e status (e possibilmente queue/team).
- “Breached today”: indice su
breached_at (o flag breach calcolato) e data.
- Viste per cliente o servizio: indici compositi come
(customer_id, due_at).
Qui si vince in performance: struttura lo storage attorno alle tue top 3–5 viste, non a ogni possibile report.
Implementa la logica di rilevamento breach in tempo reale
Il rilevamento breach in tempo reale riguarda soprattutto una cosa: trasformare workflow umani disordinati (assegnato, in attesa cliente, riaperto, trasferito) in timer SLA chiari e affidabili.
Costruisci i timer SLA: start, stop, pause, resume
Inizia definendo quali eventi controllano l'orologio SLA per ogni tipo di ticket o richiesta. Schemi comuni:
- Start: quando un ticket è creato, o quando entra per la prima volta in uno stato “support active”.
- Pause: quando passa a “Waiting for customer” o “On hold”.
- Resume: quando il cliente risponde o il ticket torna in una coda attiva.
- Stop: quando è resolved/closed (o quando una SLA di prima risposta è soddisfatta).
Da questi eventi calcola un due time. Per SLA rigorose può essere “created_at + 2 ore”. Per SLA basate su orari lavorativi è “2 ore lavorative”, che richiede un calendario.
Modulo calendario aziendale riutilizzabile
Crea un piccolo modulo calendario che risponda consistentemente a due domande:
- “Quanto tempo lavorativo è passato tra A e B?”
- “Qual è il timestamp N minuti lavorativi dopo A?”
Tieni festività, orari lavorativi e fusi orari in un unico posto così ogni regola SLA usa la stessa logica.
Tempo rimanente e rischio di breach
Una volta calcolato il due time, il tempo rimanente è semplice: due_time - now (in minuti lavorativi se applicabile). Poi definisci soglie di rischio breach come “scade entro 15 minuti” o “meno del 10% dell'SLA rimanente”. Questo alimenta badge di urgenza e instradamento degli avvisi.
Ricalcolo continuo vs tick programmati
Puoi:
- Ricalcolare continuamente (su ogni evento rilevante + ad ogni lettura): concettualmente semplice, ma può essere costoso a scala.
- Usare tick programmati (es., ogni minuto): aggiorna il tempo rimanente e innesca transizioni di “rischio” in batch.
Un ibrido pratico è aggiornamenti event‑driven per accuratezza, più un tick a minuto per catturare crossing di soglie basate sul tempo anche quando non arrivano eventi.
Configura alerting, escalation e notifiche
Rendi l'accesso semplice
Metti la dashboard SLA interna su un dominio personalizzato così i team la trovano subito.
Gli avvisi sono dove il monitor SLA diventa operativo. Lo scopo non è “più notifiche”—è far arrivare la persona giusta all'azione giusta prima della scadenza.
Definisci i tipi di avviso (e cosa significano)
Usa un set piccolo di tipi di avviso con intento chiaro:
- Risk warning: l'SLA è ancora salva, ma tende a violazione (es., “probabile violazione tra 30 minuti”).
- Breach confirmed: l'SLA è ufficialmente violata, con timestamp e ambito impattato.
- Escalation step: follow‑up temporizzato quando il problema non è stato riconosciuto o risolto.
Mappa ogni tipo a urgenza e canale di consegna differenti (chat per warning, paging per breach confermati, ecc.).
Instrada gli avvisi per team, servizio, priorità e tier cliente
L'instradamento dovrebbe essere guidato dai dati, non hard‑coded. Usa una tabella regole semplice come: service → team proprietario, poi applica modificatori:
- Priorità/severità (P0–P3)
- Tier cliente (enterprise vs standard)
- Orari lavorativi vs on‑call fuori orario
Questo evita il “broadcast a tutti” e rende visibile la proprietà.
Aggiungi deduplica per prevenire spam di avvisi
Lo stato SLA può flipparsi rapidamente durante la risposta a un incidente. Deduplica con una chiave stabile come (ticket_id, sla_rule_id, alert_type) e applica:
- una breve finestra di cooldown (es., 5–15 minuti)
- invio basato sullo stato (notificare solo su transizioni)
Considera anche di raggruppare più warning in un unico sommario periodico.
Includi contesto chiaro in ogni avviso
Ogni notifica dovrebbe rispondere a “che cosa, quando, chi, ora cosa”:
- Owner/team e target on‑call
- Due time e tempo rimanente
- Prossima azione (acknowledge, assign, respond)
- Link diretto al work item sorgente (es., /tickets/123) e alla vista SLA (es., /sla/tickets/123)
Se qualcuno non riesce ad agire entro 30 secondi dalla lettura, l'avviso necessita di più contesto.
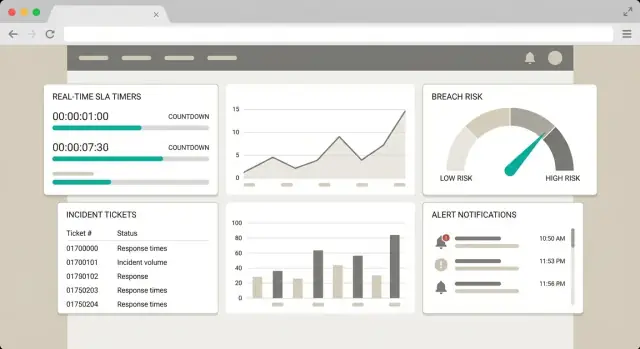
Progetta la dashboard e i flussi utente
Una buona dashboard SLA è meno grafici e più aiutare qualcuno a decidere cosa fare nei prossimi 60 secondi. Progetta l'UI attorno a tre domande: Cosa è a rischio? Perché? Che azione devo fare?
Viste core che rispecchiano il lavoro dei team
Inizia con quattro viste semplici, ognuna con uno scopo chiaro:
- Overview: snapshot del carico e del rischio (totale aperti, in scadenza, violati, clienti più impattati).
- Breaching soon: l'inbox operativo per oggi—elementi con la massima urgenza.
- Breached: ciò che necessita risposta incidente, escalation o aggiornamenti al cliente.
- Compliance trends: report settimanali/mensili per i manager per individuare problemi ricorrenti (per team, cliente, piano SLA).
Mantieni la vista predefinita focalizzata su breaching soon, perché è lì che avviene la prevenzione.
Filtri semplici (ma utili)
Dai agli utenti un set piccolo di filtri che mappano a proprietà reali di ownership e triage:
- Team/coda (chi ne è proprietario)
- Priorità (impatto)
- Cliente (focus account)
- Piano SLA (termini contrattuali)
- Range temporale (ultimi 24h, 7d, 30d per trend)
Rendi i filtri sticky per utente così non li reimpostano a ogni visita.
Spiega perché un ticket è a rischio
Ogni riga in “breaching soon” dovrebbe includere una breve spiegazione in inglese semplice, per esempio:
- SLA clock: 2h 10m rimanenti (target 4h)
- Tempo in pausa: 1h 30m escluso (in attesa cliente)
- Regola applicata: “P1 Business Hours (Mon–Fri)”
- Prossima scadenza: 15:40 ora locale
Aggiungi un drawer “Dettagli” che mostra la timeline delle modifiche dello stato SLA (started, paused, resumed, breached), così l'utente può fidarsi del calcolo senza fare conti.
Flusso di lavoro e pulsanti di azione
Progetta il flusso predefinito come: review → open → act → confirm.
Ogni elemento dovrebbe avere pulsanti di azione che saltano alla fonte di verità:
- Open ticket: /tickets/{id}
- View customer: /customers/{id}
- Escalation policy: /oncall/{team}
Se supporti azioni rapide (assign, change priority, add note), mostrale solo dove possono essere applicate in modo coerente e audita la modifica.
Aggiungi sicurezza, permessi e governance dei dati
Un'app di monitoraggio SLA in tempo reale diventa rapidamente un sistema di record per performance, incidenti e impatto cliente. Trattala come software di produzione fin dal giorno uno: limita chi può fare cosa, proteggi i dati dei clienti e documenta come i dati sono memorizzati ed eliminati.
Definisci ruoli e permessi
Inizia con un modello di permessi piccolo e chiaro e espandi solo quando serve. Una configurazione comune è:
- Viewer: accesso in sola lettura a dashboard e report.
- Operator: può acknowledge gli avvisi, aggiungere note, creare incidenti e triggerare escalation.
- Admin: gestisce definizioni SLA, integrazioni, regole di instradamento, utenti e policy dati.
Allinea i permessi ai flussi di lavoro. Per esempio, un operator può aggiornare lo stato incidente, ma solo un admin può cambiare i timer SLA o le regole di escalation.
Proteggi campi sensibili e audita gli accessi
Il monitor SLA spesso include identificatori cliente, tier contrattuale e contenuto ticket. Minimizza l'esposizione:
- Maschera o redigi i dettagli cliente per default (mostra valori completi solo ai ruoli autorizzati).
- Separa “display name” da “unique ID” così le dashboard restano utili senza rivelare dati privati.
- Registra accessi a viste sensibili ed export (chi ha visto cosa, quando e da dove).
Metti in sicurezza le integrazioni end‑to‑end
Le integrazioni (ticketing, chat, metriche, strumenti incident) sono un punto debole frequente:
- Usa scope least‑privilege: solo i permessi necessari per leggere eventi o inviare notifiche.
- Conserva i token in un secrets manager (non nel codice o nelle impostazioni della dashboard).
- Ruota i token regolarmente e immediatamente dopo cambi di personale o sospette esposizioni.
- Preferisci webhook con verifica della firma o credenziali a breve durata dove possibile.
Stabilisci policy di trattamento dati presto
Definisci le policy prima di accumulare mesi di cronologia:
- Retention: quanto conservare eventi raw, stati SLA calcolati e log di audit.
- Cancellazione: come eliminare i dati cliente su richiesta (e cosa non può essere cancellato per compliance).
- Export: chi può esportare report operativi, in quali formati e con quali redazioni.
Documenta queste regole e riflettile nell'UI così il team sa cosa il sistema conserva—e per quanto tempo.
Testa, valida e monitora il sistema
Distribuisci la tua app di monitoraggio
Passa da prototipo locale a app ospitata senza ricostruire l’intera configurazione.
Testare un'app di monitoraggio SLA riguarda meno il “la UI si carica?” e più il “i timer, le pause e le soglie sono calcolati esattamente come previsto dal contratto—ogni volta”. Un piccolo errore (fusi orari, orari lavorativi, eventi mancanti) può generare avvisi rumorosi o, peggio, violazioni non rilevate.
Valida le regole con scenari realistici
Trasforma le regole SLA in scenari concreti che puoi simulare end‑to‑end. Includi flussi normali e casi limite scomodi:
- Ticket creati subito prima della chiusura dell'orario lavorativo
- Cambi di priorità a metà incidente (il clock si resetta?)
- Risposta cliente che pausa il timer (e riprende correttamente)
- Eventi duplicati, fuori ordine e mancate chiusure “resolved”
Dimostra che la logica di rilevamento è stabile sotto il disordine operativo reale, non solo con dati di demo puliti.
Usa fixture di eventi riproducibili
Crea fixture di eventi riproducibili: una piccola libreria di “timeline di incidente” che puoi rilanciare attraverso ingest e calcolo ogni volta che cambi la logica. Questo aiuta a verificare i calcoli nel tempo e a prevenire regressioni.
Conserva le fixture versionate (in Git) e includi output attesi: tempo rimanente calcolato, momento di breach, finestre di pausa e trigger di avviso.
Monitora il sistema di monitoraggio
Tratta il monitor SLA come qualsiasi sistema di produzione e aggiungi i suoi segnali di salute:
- Lag di ingest (quanto sei indietro rispetto al real‑time)
- Conteggi di eventi falliti / dead‑letter
- Errori nei calcoli timer (per tipo SLA)
- Tasso di successo di consegna avvisi e tempo di consegna
Se la tua dashboard mostra “verde” mentre gli eventi sono bloccati, perderai fiducia rapidamente.
Runbook per pipeline bloccate e ricalcolo
Scrivi un runbook breve e chiaro per i fallimenti comuni: consumer bloccati, cambi di schema, outage upstream e backfill. Includi passi per riprodurre eventi e ricalcolare i timer in sicurezza (che periodo, quali tenant e come evitare doppio avviso). Collegalo dalla doc interna o a una pagina semplice come /runbooks/sla-monitoring.
Distribuisci in modo incrementale e pianifica le iterazioni
Rilasciare un'app di monitoraggio SLA è più semplice se la tratti come un prodotto, non come un progetto una tantum. Parti con una release minima che dimostri il loop end‑to‑end: ingest → valutazione → avviso → conferma che ha aiutato qualcuno ad agire.
Parti con una release minima valida
Scegli una sorgente dati, un tipo di SLA e avvisi di base. Per esempio, monitora la “first response time” usando un singolo feed dal sistema di ticketing e invia un avviso quando il timer sta per scadere (non solo dopo la violazione). Questo mantiene il perimetro stretto mentre convalidi le parti difficili: timestamp, finestre temporali e ownership.
Quando l'MVP è stabile, amplia a piccoli passi: aggiungi un secondo tipo di SLA (es., resolution), poi una seconda sorgente dati e infine workflow più ricchi.
Pianifica ambienti e rollout sicuri
Prepara dev, staging e production presto. Lo staging dovrebbe rispecchiare le configurazioni di produzione (integrazioni, schedule, percorsi di escalation) senza notificare i responder reali.
Usa feature flag per:
- Rilasciare nuove regole di breach a un team pilota
- Nuove integrazioni in modalità “solo osservazione” (log dei rilevamenti, nessun avviso)
- Cambi UI dietro toggle così puoi tornare indietro velocemente
Se costruisci rapidamente con una piattaforma come Koder.ai, snapshot e rollback sono utili: puoi inviare UI e regole a un pilota e ripristinare velocemente se gli avvisi diventano rumorosi.
Documenta l'onboarding perché i team lo adottino davvero
Scrivi documentazione breve e pratica: “Connetti la sorgente dati”, “Crea una SLA”, “Testa un avviso”, “Cosa fare quando arrivi una notifica”. Tienila vicino al prodotto, come una pagina interna /docs/sla-monitoring.
Costruisci il backlog di iterazione
Dopo l'adozione iniziale, prioritizza miglioramenti che aumentano fiducia e riducono il rumore:
- Rilevamento semplice di anomalie per volumi insoliti o picchi repentini di rischio SLA
- Pagine di stato cliente visibile (opzionale)
- Report operativi schedulati (sommario SLA settimanale, cause principali di breach, trend)
Itera in base agli incidenti reali: ogni avviso dovrebbe insegnarti cosa automatizzare, chiarire o rimuovere.