Perché TCP/IP è la base nascosta del software moderno
La maggior parte delle app sembra “istantanea”: tocchi un pulsante, un feed si aggiorna, un pagamento si completa, un video parte. Quello che non vedi è il lavoro che avviene sotto per muovere piccoli pezzi di dati attraverso Wi‑Fi, reti cellulari, router domestici e data center—spesso attraversando più Paesi—senza che tu debba pensare alle parti disordinate nel mezzo.
Quell'invisibilità è la promessa che TCP/IP mantiene. Non è un singolo prodotto o una funzionalità cloud. È un insieme di regole condivise che permette a dispositivi e server di parlarsi in modo che di solito sembra fluido e affidabile, anche quando la rete è rumorosa, congestionata o parzialmente guasta.
Bob Kahn fu una delle persone chiave che rese questo possibile. Insieme a collaboratori come Vint Cerf, Kahn contribuì a plasmare le idee fondamentali che divennero TCP/IP: un “linguaggio” comune per le reti e un metodo per consegnare dati in modo che le applicazioni possano fidarsi. Senza enfasi inutile—questo lavoro contò perché trasformò connessioni poco affidabili in qualcosa su cui il software poteva costruire in modo prevedibile.
Reti a pacchetto, spiegate per chi è indaffarato
Invece di inviare un messaggio intero come flusso continuo, la rete a pacchetto lo spezza in piccoli pezzi chiamati pacchetti. Ogni pacchetto può seguire il proprio percorso verso la destinazione, come buste separate che passano attraverso uffici postali diversi.
Cosa imparerai in questo articolo
Analizzeremo come TCP crea la sensazione di affidabilità, perché IP intenzionalmente non promette la perfezione e come il layering mantiene il sistema comprensibile. Alla fine potrai immaginare cosa succede quando un'app chiama un'API—e perché queste idee, vecchie di decenni, alimentano ancora i servizi cloud moderni.
Il problema che TCP/IP doveva risolvere
Le prime reti di calcolatori non nacquero come "Internet". Furono costruite per gruppi specifici con obiettivi specifici: una rete universitaria qui, una rete militare là, una rete di ricerca altrove. Ognuna poteva funzionare bene internamente, ma spesso usava hardware, formati di messaggi e regole diverse per come i dati dovevano viaggiare.
Questo creava una realtà frustrante: anche se due computer erano entrambi “in rete”, potevano comunque non riuscire a scambiarsi informazioni. È un po' come avere molti sistemi ferroviari con scartamenti diversi e segnali che significano cose diverse. Puoi muovere i treni all'interno di un sistema, ma attraversarne un altro è disordinato, costoso o impossibile.
Internetworking: collegare reti, non solo computer
La sfida chiave di Bob Kahn non fu semplicemente “connettere il computer A al computer B”. Fu: come connettere reti tra loro in modo che il traffico possa passare attraverso più sistemi indipendenti come se fossero un unico sistema più grande?
Questo è ciò che significa “internetworking”: costruire un metodo affinché i dati saltino da una rete all'altra, anche quando quelle reti sono progettate in modo diverso e gestite da organizzazioni diverse.
Perché le regole condivise (protocolli) erano importanti
Per far funzionare l'internetworking su scala, tutti avevano bisogno di un insieme comune di regole—protocolli—che non dipendessero dal design interno di una singola rete. Quelle regole dovevano anche riflettere vincoli reali:
- Le reti avrebbero fallito, perso dati o consegnato fuori ordine.
- Nessun operatore centrale poteva gestire ogni connessione nel dettaglio.
- Nuove reti sarebbero state aggiunte nel tempo.
TCP/IP divenne la risposta pratica: un “accordo” condiviso che permetteva a reti indipendenti di interconnettersi e comunque muovere dati in modo sufficientemente affidabile per applicazioni reali.
Il contributo di Bob Kahn in parole semplici
Bob Kahn è conosciuto soprattutto come uno degli architetti delle "regole della strada" di Internet. Negli anni '70, mentre lavorava con DARPA, contribuì a trasformare il networking da esperimento di ricerca in qualcosa che potesse collegare molti tipi diversi di reti—senza obbligarle tutte a usare lo stesso hardware, cablaggio o design interno.
L'idea centrale: far parlare tra loro le reti
ARPANET dimostrò che i computer potevano comunicare su collegamenti a commutazione di pacchetto. Ma emersero anche altre reti—sistemi radio, collegamenti satellitari e reti sperimentali—ognuna con le sue particolarità. L'attenzione di Kahn fu l'interoperabilità: permettere a un messaggio di viaggiare attraverso più reti come se fosse una singola rete.
Invece di costruire una rete “perfetta”, sostenne un approccio in cui:
- Ogni rete locale potesse mantenere il proprio design.
- Un protocollo comune stesse sopra e muovesse i dati attraverso i confini di rete.
- Il “collante” fosse sufficientemente generale da funzionare anche su reti future non ancora inventate.
Lavorando con Vint Cerf, Kahn co‑disegnò ciò che divenne TCP/IP. Un risultato duraturo fu la netta separazione delle responsabilità: IP gestisce indirizzamento e forwarding tra reti, mentre TCP gestisce la consegna affidabile per le applicazioni che ne hanno bisogno.
Perché gli sviluppatori ne beneficiano ancora oggi
Se hai mai chiamato un'API, caricato una pagina web o inviato log da un container a un servizio di monitoraggio, stai facendo affidamento sul modello di internetworking che Kahn sostenne. Non devi preoccuparti se i pacchetti passano via Wi‑Fi, fibra, LTE o backbone cloud. TCP/IP fa apparire tutto come un sistema continuo—così il software può concentrarsi sulle funzionalità, non sul cablaggio.
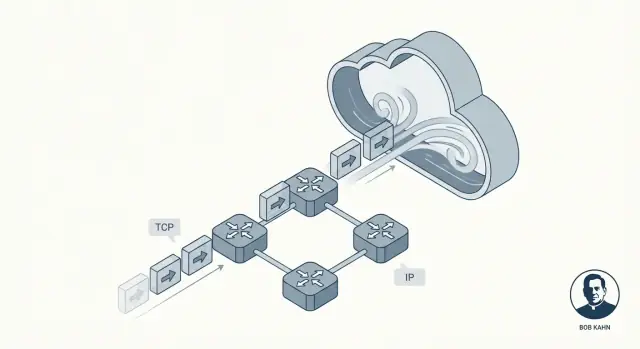
L'idea del layering di TCP/IP: semplice ma potente
Una delle idee più intelligenti dietro TCP/IP è il layering: invece di costruire un enorme sistema di rete che faccia tutto, si impilano pezzi più piccoli dove ogni livello fa bene una cosa sola.
Questo è importante perché le reti non sono tutte uguali. Cavi diversi, radio, router e provider possono comunque interoperare quando concordano poche responsabilità chiare.
IP: indirizzamento e instradamento tra reti
Pensa a IP (Internet Protocol) come alla parte che risponde: Dove sta andando questo dato e come lo avviciniamo a quel posto?
IP fornisce indirizzi (così le macchine possono essere identificate) e un instradamento basilare (così i pacchetti possono saltare da una rete all'altra). Importante: IP non cerca di essere perfetto. Si concentra sull'inoltrare i pacchetti, un passo alla volta, anche se il percorso cambia.
TCP: consegna affidabile sopra IP
Poi TCP (Transmission Control Protocol) sta sopra IP e risponde: Come facciamo a far sembrare questa connessione affidabile?
TCP gestisce il lavoro di “affidabilità” che le applicazioni solitamente vogliono: ordinare correttamente i dati, rilevare parti mancanti, ritrasmettere quando serve e modulare la consegna in modo che il mittente non sommerga il ricevitore o la rete.
Un'analogia postale semplice (senza forzature)
Un modo utile per immaginare la divisione è il sistema postale:
- IP è come l'indirizzamento e la rete di instradamento che sposta le buste tra città e uffici postali.
- TCP è come il tracciamento e la conferma che assicura che una spedizione multi‑pezzo arrivi completa e nell'ordine giusto.
Non chiedi all'indirizzo di garantire che il pacco arrivi; costruisci quell'assicurazione sopra.
Perché questo “stack semplice” è rimasto potente
Perché le responsabilità sono separate, puoi migliorare un livello senza ridisegnare tutto il resto. Nuove reti fisiche possono trasportare IP, e le applicazioni possono contare sul comportamento di TCP senza dover capire come funziona l'instradamento. Questa divisione pulita è una ragione principale per cui TCP/IP è diventato il fondamento invisibile sotto quasi ogni app e API che usi.
Commutazione a pacchetto: velocità, flessibilità e caos
La commutazione a pacchetto è l'idea che rese pratiche le reti di grandi dimensioni: invece di riservare una linea dedicata per tutto il tuo messaggio, lo spezzetti in piccoli pezzi e mandi ogni pezzo indipendentemente.
Cos'è un “pacchetto” (e perché i pezzi vincono)
Un pacchetto è un piccolo pacchetto di dati con un header (chi lo manda, a chi è destinato e altre info di instradamento) più una fetta del contenuto.
Spezzare i dati in pezzi aiuta perché la rete può:
- Condividere i link tra molti utenti (nessuno “possiede” il filo).
- Instradare attorno a parti lente o rotte.
- Recuperare dai problemi ritrasmettendo solo le parti mancanti, non l'intero file.
Percorsi diversi, ordine misto
Qui inizia il “caos”. I pacchetti della stessa download o chiamata API possono prendere percorsi diversi attraverso la rete, a seconda di cosa è occupato o disponibile in quel momento. Ciò significa che possono arrivare fuori ordine—il pacchetto #12 può arrivare prima del #5.
La commutazione a pacchetto non cerca di prevenire questo. Prioritizza il passaggio rapido dei pacchetti, anche se l'ordine di arrivo è disordinato.
Perché i pacchetti si perdono
La perdita di pacchetti non è rara e non è sempre colpa di qualcuno. Cause comuni includono:
- Congestione: i router esauriscono lo spazio nei buffer e scartano i pacchetti.
- Rumore/interferenza: soprattutto su link wireless.
- Interruzioni e reindirizzamenti: un collegamento fallisce a metà flusso e alcuni pacchetti non arrivano.
L'imperfezione è una caratteristica, non un bug
La scelta di design chiave è permettere alla rete di essere imperfetta. IP si concentra sull'inoltrare i pacchetti al meglio, senza promettere consegna o ordine. Quella libertà è ciò che permette alle reti di scalare—ed è per questo che i livelli superiori (come TCP) esistono per mettere ordine nel caos.
Come TCP fa sembrare affidabili le reti inaffidabili
Testa su una rete reale
Distribuisci e ospita la tua app per testare latenza e throughput con utenti reali.
IP consegna i pacchetti su base “best effort”: alcuni possono arrivare in ritardo, fuori ordine, duplicati o non arrivare affatto. TCP sta sopra e crea qualcosa su cui le applicazioni possono fare affidamento: un singolo flusso di byte ordinato e completo—il tipo di connessione che ti aspetti quando carichi un file, carichi una pagina web o chiami un'API.
Affidabilità, in parole semplici
Quando si dice che TCP è “affidabile”, di solito si intende:
- Ordinato: i dati vengono consegnati all'app nello stesso ordine in cui sono stati inviati.
- Completo: le parti mancanti vengono rilevate e ritrasmesse.
- Senza gap: l'app legge un flusso continuo, non pacchetti sparsi.
I meccanismi chiave (e perché funzionano)
TCP spezza i tuoi dati in pezzi e li etichetta con numeri di sequenza. Il ricevitore invia acknowledgment (ACK) per confermare ciò che ha ricevuto.
Se il mittente non vede un ACK in tempo, assume che qualcosa sia andato perso e procede a una ritrasmissione. Questa è l'illusione centrale: anche se la rete può perdere pacchetti, TCP continua a provare finché il ricevitore non conferma la ricezione.
Flow control vs. congestion control
Sembrano simili ma risolvono problemi diversi:
- Flow control protegge il ricevitore. Dice: “Sono occupato—invia più lentamente così il mio buffer non si riempie.”
- Congestion control protegge la rete. Dice: “Il percorso è sovraccarico—ritirati per evitare di peggiorare l'ingorgo.”
Insieme aiutano TCP a rimanere veloce senza essere sconsiderato.
Timeout che si adattano
Un timeout fisso fallirebbe sia su reti lente sia su reti veloci. TCP aggiusta continuamente il timeout basandosi sul tempo di andata/ritorno misurato. Se le condizioni peggiorano aspetta di più prima di ritrasmettere; se accelerano diventa più reattivo. Questa adattabilità è il motivo per cui TCP funziona su Wi‑Fi, reti mobili e collegamenti a lunga distanza.
Una scelta di design che ha scalato: pensare end-to-end
Una delle idee più importanti dietro TCP/IP è il principio end-to-end: mettere le “intelligenze” ai margini della rete (gli endpoint) e mantenere il centro della rete relativamente semplice.
Intelligenza ai bordi
In parole semplici, gli endpoint sono i dispositivi e i programmi che si preoccupano effettivamente dei dati: il tuo telefono, il tuo laptop, un server e i sistemi operativi e applicazioni che girano su di essi. Il nucleo della rete—router e link intermedi—si concentra principalmente sul muovere i pacchetti.
Invece di cercare di rendere ogni router “perfetto”, TCP/IP accetta che il centro sarà imperfetto e lascia agli endpoint le parti che richiedono contesto.
Perché un core più semplice ha permesso la crescita
Mantenere il core più semplice ha reso più facile espandere Internet. Nuove reti potevano unirsi senza richiedere che ogni dispositivo intermedio capisse le necessità di ogni applicazione. I router non hanno bisogno di sapere se un pacchetto fa parte di una chiamata video, di un download o di una richiesta API—they semplicemente lo inoltrano.
Cosa appartiene dove (con esempi)
Agli endpoint si gestisce tipicamente:
- Affidabilità: ritrasmissioni, ordinamento, deduplicazione (TCP).
- Sicurezza: crittografia e identità (spesso TLS a livello applicazione/OS).
- Comportamento dell'app: timeout, retry, caching, rate limit.
Nella rete, si gestisce per lo più:
- Indirizzamento e forwarding (IP).
- Gestione base dei pacchetti e segnali di congestione.
Il compromesso
Il pensare end-to-end scala bene, ma sposta la complessità verso l'esterno. Sistemi operativi, librerie e applicazioni diventano responsabili di “far funzionare” il tutto su reti disordinate. Questo è ottimo per la flessibilità, ma significa anche che bug, timeout mal configurati o retry troppo aggressivi possono creare problemi visibili agli utenti.
Perché il modello “best effort” di IP fu una caratteristica
Prototipa un'API consapevole del TCP
Costruisci una piccola API e osserva come timeout e retry TCP si manifestano nella pratica.
IP (Internet Protocol) fa una promessa semplice: proverà a muovere i tuoi pacchetti verso la destinazione. Solo questo. Nessuna garanzia su se un pacchetto arriva, arriva una sola volta, nell'ordine giusto o entro un tempo specifico.
Questo potrebbe sembrare un difetto—finché non guardi a ciò di cui Internet aveva bisogno per diventare: una rete globale formata da molte reti più piccole, possedute da diverse organizzazioni e in continuo cambiamento.
Cosa fanno (e non fanno) i router
I router sono i “direttori del traffico” di IP. Il loro compito principale è l'inoltro: quando arriva un pacchetto, il router guarda l'indirizzo di destinazione e sceglie l'hop successivo che sembra migliore in quel momento.
I router non tracciano una conversazione come farebbe un centralino. Generalmente non riservano capacità per te e non aspettano conferme. Mantenendo i router concentrati sull'inoltro, il cuore della rete resta semplice—e può scalare a un numero enorme di dispositivi e connessioni.
Perché il “best effort” scala a livello globale
Le garanzie sono costose. Se IP cercasse di garantire consegna, ordine e tempi per ogni pacchetto, ogni rete sulla Terra dovrebbe coordinarsi strettamente, mantenere molto stato e recuperare i guasti nello stesso modo. Questo onere di coordinamento rallenterebbe la crescita e renderebbe i guasti più severi.
Invece, IP tollera la confusione. Se un link fallisce, un router può inviare pacchetti su un'altra rotta. Se un percorso si congestiona, i pacchetti possono essere ritardati o scartati, ma il traffico spesso può continuare tramite rotte alternative.
Il risultato è resilienza: Internet può continuare a funzionare anche quando parti di essa si rompono o cambiano—perché la rete non è costretta a essere perfetta per essere utile.
Dalle app e API ai pacchetti: cosa succede davvero
Quando fai fetch() di un'API, clicchi “Salva” o apri una websocket, non stai “parlando con il server” in un flusso liscio unico. La tua app passa i dati al sistema operativo, che li frammenta in pacchetti e li invia attraverso molte reti separate—ogni hop prende decisioni proprie.
Una mappatura semplice: azioni dello sviluppatore → comportamento TCP/IP
- Richiesta HTTP / chiamata API: la tua app scrive byte (una richiesta HTTP). TCP trasforma quel flusso in segmenti, li numera e si aspetta ack. IP incapsula ogni segmento in un pacchetto e lo instrada.
- Apertura di una connessione: un handshake TCP imposta stato condiviso (numeri di sequenza, dimensioni delle finestre). Non è gratuito—aggiunge tempo prima del primo byte utile.
- Upload di un file: TCP può avere tanto throughput disponibile, ma le prestazioni possono comunque sembrare lente se la latenza è alta.
Latenza vs throughput (e perché la tua app “sembra” lenta)
- Latenza è quanto ci mette un messaggio ad andare e tornare (round trip). L'alta latenza penalizza pattern chatty: molte richieste piccole, tanti redirect, chiamate API ripetute.
- Throughput è quanti dati al secondo possono essere consegnati. Basso throughput penalizza trasferimenti grandi: immagini, backup, video.
Una sorpresa comune: puoi avere ottimo throughput e comunque un'interfaccia utente lenta perché ogni richiesta aspetta round trip.
Retry e timeout: perché le app rifanno cose che TCP già prova
TCP ritenta pacchetti persi, ma non può sapere cosa significa “troppo tempo” per l'esperienza utente. Ecco perché le applicazioni aggiungono:
- Timeout: “Se nessuna risposta in 2 secondi, mostra un errore.”
- Retry: “Riprova una volta.” Utile per cadute transitorie, ma rischioso per operazioni come pagamenti a meno che le richieste non siano idempotenti.
Quando i “bug” sono realtà di rete
I pacchetti possono essere ritardati, riordinati, duplicati o scartati. La congestione può far esplodere la latenza. Un server può rispondere ma la risposta potrebbe non arrivare. Questi si manifestano come test flakky, 504 casuali o “funziona sulla mia macchina.” Spesso il codice è corretto—il percorso tra macchine no.
TCP/IP nel cloud: stesse regole, scala maggiore
Le piattaforme cloud possono sembrare un tipo completamente nuovo di calcolo—database gestiti, funzioni serverless, scalabilità “infinita”. Sotto, le tue richieste viaggiano ancora sulle stesse fondamenta TCP/IP che Bob Kahn aiutò a mettere in moto: IP muove i pacchetti tra le reti, e TCP (o talvolta UDP) modella come le applicazioni percepiscono la rete.
Cosa cambia nel cloud (soprattutto packaging)
Virtualizzazione e container cambiano dove il software gira e come è impacchettato:
- Un “server” può essere una VM, un container o una funzione di breve durata.
- Le reti sono spesso definite dal software e tessute dal provider.
Ma sono dettagli di deployment. I pacchetti usano ancora indirizzi IP e routing, e molte connessioni dipendono ancora da TCP per consegna ordinata e affidabile.
Cosa resta uguale (i pattern riconoscibili)
Le architetture cloud comuni sono costruite con mattoni di networking familiari:
- Load balancer accettano connessioni TCP client (spesso HTTPS) e distribuiscono il traffico ai backend.
- Chiamate service-to-service all'interno di un cluster sono comunque chiamate di rete—HTTP/gRPC su TCP è comune—solo tra IP privati.
- Database e cache (gestiti o self-hosted) si raggiungono con protocolli standard che viaggiano su TCP (ad esempio un driver DB mantiene una sessione TCP).
Anche quando non “vedi” un indirizzo IP, la piattaforma li assegna, instrada pacchetti e traccia connessioni dietro le quinte.
L'affidabilità è ancora un lavoro condiviso
TCP può recuperare pacchetti persi, riordinare e adattarsi alla congestione—but non può promettere l'impossibile. Nei sistemi cloud l'affidabilità è uno sforzo di squadra:
- Rete: instradamento, capacità, perdita pacchetti, guasti transitori.
- OS/runtime: buffer socket, timeout, caching DNS, riuso delle connessioni.
- Applicazione: retry con backoff, idempotenza, timeout sensati e degradazione elegante.
Per questo anche piattaforme che generano e deployano app full-stack (ad es. Koder.ai) dipendono dalle stesse fondamenta. Koder.ai può aiutarti a lanciare rapidamente una web app React con backend Go e PostgreSQL, ma nel momento in cui quell'app parla con un'API, un database o un client mobile, sei di nuovo nel territorio TCP/IP—connessioni, timeout, retry e tutto il resto.
TCP vs UDP e cosa scelgono oggi gli sviluppatori
Aggiungi timeout nel modo giusto
Crea un servizio con timeout di richiesta sensati e messaggi di errore chiari per reti instabili.
Quando si parla genericamente di “la rete”, spesso si sceglie tra due trasporti principali: TCP e UDP. Entrambi stanno sopra IP, ma fanno compromessi molto diversi.
TCP: lo stream affidabile (e i suoi costi nascosti)
TCP è ideale quando vuoi che i dati arrivino in ordine, senza buchi, e sei disposto ad aspettare piuttosto che indovinare. Pensa: pagine web, chiamate API, trasferimenti di file, connessioni a database.
Per questo gran parte di Internet quotidiano ciaggia su TCP—HTTPS corre su TCP (via TLS) e la maggior parte del software request/response si basa sul comportamento di TCP.
Il lato negativo: l'affidabilità di TCP può aggiungere latenza. Se un pacchetto manca, quelli successivi possono essere tenuti indietro fino a che il gap non viene riempito ("head‑of‑line blocking"). Per esperienze interattive quell'attesa può essere peggiore di un glitch occasionale.
UDP: semplice, veloce e controllato dall'app
UDP è più vicino a “invia un messaggio e spera arrivi”. Non c'è ordinamento, ritrasmissione o gestione della congestione a livello UDP.
Gli sviluppatori scelgono UDP quando il tempo è più importante della perfezione, come audio/video live, giochi o telemetria in tempo reale. Molte di queste app costruiscono la propria affidabilità leggera (o nessuna) in base a ciò che gli utenti percepiscono.
Un esempio moderno importante: QUIC corre su UDP, permettendo setup di connessione più veloci ed evitando alcuni colli di bottiglia di TCP—senza modificare la rete IP sottostante.
Guida pratica per la scelta
Scegli in base a:
- Necessità di affidabilità: ogni byte deve arrivare in ordine? Preferisci TCP.
- Sensibilità alla latenza: “ora” è più importante di “perfetto”? Considera UDP.
- Controllo: vuoi che l'app decida cosa ritentare, cosa saltare e come recuperare? UDP (o QUIC) dà più margine di progettare il comportamento.
Cosa l'“affidabile” non può ancora garantire: insidie reali
TCP è spesso descritto come “affidabile”, ma questo non significa che la tua app sembrerà sempre affidabile. TCP può recuperare da molti problemi di rete, ma non può garantire bassa latenza, throughput costante o una buona esperienza utente quando il percorso tra due sistemi è instabile.
Problemi di rete comuni che incontrerai
Perdita di pacchetti forza TCP a ritrasmettere. L'affidabilità è preservata, ma le prestazioni possono crollare.
Alta latenza (RTT lungo) rallenta ogni ciclo richiesta/risposta, anche se non ci sono perdite.
Bufferbloat accade quando router o code OS trattengono troppi dati. TCP vede meno perdite, ma gli utenti vedono enormi ritardi e interazioni "laggy".
MTU mal configurata può causare frammentazione o blackholing (i pacchetti spariscono perché "troppo grandi"), creando guasti confusi che sembrano timeout casuali.
Come si manifestano dentro le app
Piuttosto che un chiaro “errore di rete”, spesso vedrai:
- Timeout su chiamate API che di solito funzionano.
- Upload o download lenti che partono veloci e poi rallentano.
- Connessioni instabili: riconnessioni ripetute, stream bloccati o caricamenti parziali.
Questi sintomi sono reali, ma non sempre causati dal tuo codice. Spesso sono TCP che fa il suo lavoro—ritrasmettendo, rallentando e aspettando—mentre il tuo orologio dell'app continua a correre.
Punti di partenza pratici per il debug
Classifica prima: il problema è soprattutto perdita, latenza o cambi di percorso?
- Controlli in stile ping aiutano a ragionare su latenza e perdita (anche se ICMP può essere bloccato).
- Pensiero in stile traceroute aiuta a individuare dove iniziano ritardi o drop.
- Aggiungi log e metriche: durata richiesta, conteggio timeout, conteggio retry e segnali di backpressure/queue.
Se stai sviluppando velocemente (per esempio prototipando un servizio in Koder.ai e distribuendolo con hosting e domini custom), vale la pena includere queste basi di osservabilità fin dall'inizio—perché i guasti di rete appaiono prima come timeout e retry, non come eccezioni ordinate.
Progetta pensando al fallimento
Assumi che le reti si comportino male. Usa timeout, retry con backoff esponenziale e rendi le operazioni idempotenti così i retry non addebitino due volte, non creino duplicati o non corrompano lo stato.