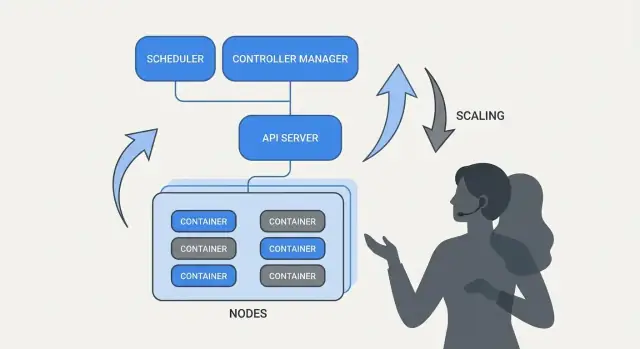
Perché Kubernetes ha cambiato le operazioni quotidiane
Kubernetes non ha introdotto solo un nuovo strumento: ha cambiato cosa significa fare “operazioni quotidiane” quando gestisci decine (o centinaia) di servizi. Prima dell'orchestrazione, i team spesso mettevano insieme script, runbook manuali e conoscenza tribale per rispondere alle stesse domande ricorrenti: Dove dovrebbe girare questo servizio? Come rilasciamo una modifica in sicurezza? Cosa succede se un nodo muore alle 2 di notte?
Cosa risolve davvero “orchestrazione"
Alla base, l'orchestrazione è il livello di coordinamento tra la tua intenzione (“esegui questo servizio in questo modo”) e la realtà disordinata delle macchine che falliscono, del traffico che si sposta e dei deploy continui. Invece di trattare ogni server come un fiocco di neve speciale, l'orchestrazione considera il calcolo come una piscina e i workload come unità schedulabili che possono spostarsi.
Kubernetes ha reso popolare un modello in cui i team descrivono cosa vogliono e il sistema lavora continuamente per far corrispondere la realtà a quella descrizione. Questo cambiamento conta perché rende le operazioni meno eroiche e più basate su processi ripetibili.
Tre risultati che i team hanno avvertito subito
Kubernetes ha standardizzato risultati operativi che la maggior parte dei team di servizio necessita:
- Deployment: un modo coerente per dichiarare cosa deve girare, aggiornarlo e verificarne la salute.
- Scaling: una strada pratica da una istanza a molte, senza ridisegnare il servizio o fornire macchine manualmente.
- Service operations: modi stabili per i servizi di trovarsi, instradare il traffico e mantenersi operativi mentre le istanze cambiano.
Nota su ambito e fonti
Questo articolo si concentra sulle idee e i pattern associati a Kubernetes (e a leader come Brendan Burns), non su una biografia personale. Quando parliamo di “come è iniziato” o “perché è stato progettato così”, è utile basare le affermazioni su fonti pubbliche—talks di conferenze, design doc e documentazione upstream—così la storia rimane verificabile e non mitica.
Brendan Burns nella storia di origine di Kubernetes (a grandi linee)
Brendan Burns è ampiamente riconosciuto come uno dei tre cofondatori originali di Kubernetes, insieme a Joe Beda e Craig McLuckie. Nei primi lavori su Kubernetes a Google, Burns contribuì a plasmare sia la direzione tecnica sia il modo in cui il progetto veniva spiegato agli utenti—specialmente attorno a “come si opera il software” piuttosto che solo “come eseguire container”. (Fonti: Kubernetes: Up & Running, O’Reilly; lista AUTHORS/maintainers del repository Kubernetes)
La collaborazione open source ha influenzato il design
Kubernetes non è stato semplicemente “rilasciato” come un sistema interno finito; è stato costruito in pubblico con un insieme crescente di contributori, casi d'uso e vincoli. Questa apertura spinse il progetto verso interfacce che potessero sopravvivere in ambienti diversi:
- API chiare e versionate piuttosto che dettagli implementativi nascosti
- comportamenti portabili tra cloud provider e setup on-prem
- punti di estensione così che il core potesse restare relativamente piccolo pur supportando molte esigenze
Questa pressione collaborativa conta perché ha influenzato ciò che Kubernetes ha privilegiato: primitive condivise e pattern ripetibili su cui molti team potevano accordarsi, anche se non erano d'accordo sugli strumenti.
Cosa significa davvero “standardizzare” qui
Quando si dice che Kubernetes ha “standardizzato” deployment e operazioni, di solito non si intende che ha reso ogni sistema identico. Si intende che ha fornito un vocabolario comune e una serie di workflow ripetibili tra team:
- “deployment”, “service”, “ingress”, “job”, “namespace” come termini condivisi
- un modello coerente per dichiarare ciò che desideri (e lasciare che il sistema lavori per ottenerlo)
- modi prevedibili per effettuare rollout, scalare e recuperare dai guasti
Quel modello condiviso rese più semplice trasferire documentazione, strumenti e pratiche tra aziende.
Kubernetes come progetto vs. ecosistema
È utile separare Kubernetes (il progetto open-source) dall'ecosistema Kubernetes.
Il progetto è il core API e i componenti del control plane che implementano la piattaforma. L'ecosistema è tutto ciò che è cresciuto attorno—distribuzioni, servizi gestiti, add-on e progetti CNCF adiacenti. Molte “feature Kubernetes” di cui le persone si fidano realmente (stack di osservabilità, motori di policy, strumenti GitOps) vivono in quell'ecosistema, non nel core del progetto stesso.
L'idea centrale: stato desiderato dichiarativo
La configurazione dichiarativa è uno spostamento semplice nel modo in cui descrivi i sistemi: invece di elencare i passi da compiere, dichiari ciò che vuoi come risultato finale.
In termini Kubernetes, non dici alla piattaforma “avvia un container, poi apri una porta, poi riavvialo se crasha.” Dichiari “devono esserci tre copie di questa app in esecuzione, raggiungibile su questa porta, usando questa immagine del container.” Kubernetes prende la responsabilità di far corrispondere la realtà a quella dichiarazione.
Stato desiderato vs. script imperativi
Le operazioni imperative sono come un runbook: una sequenza di comandi che ha funzionato l'ultima volta, eseguita di nuovo quando qualcosa cambia.
Lo stato desiderato assomiglia di più a un contratto. Registri l'esito voluto in un file di configurazione e il sistema lavora continuamente per raggiungerlo. Se qualcosa devia—un'istanza muore, un nodo scompare, una modifica manuale si infiltra—la piattaforma rileva la discrepanza e la corregge.
Prima/dopo: comandi di runbook vs YAML
Prima (mentalità runbook imperativa):
- SSH su un server
- Pull dell'immagine del container nuova
- Fermare il processo vecchio
- Avviare il processo nuovo
- Aggiornare una regola del load balancer
- Se il traffico sale, ripetere su altri server
Questo approccio è funzionante, ma è facile finire con server “fiocco di neve” e una lunga checklist di cui si fidano solo poche persone.
Dopo (stato desiderato dichiarativo):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Modifichi il file (per esempio aggiorni image o replicas), lo applichi e i controller di Kubernetes lavorano per riconciliare ciò che gira con ciò che è dichiarato.
Perché riduce il lavoro ripetitivo e la deriva
Lo stato desiderato dichiarativo riduce il lavoro operativo trasformando “fai questi 17 passi” in “mantieni così.” Riduce anche la deriva di configurazione perché la fonte di verità è esplicita e revisionabile—spesso in controllo versione—quindi le sorprese sono più facili da individuare, controllare e ripristinare coerentemente.
Controller e riconciliazione: il sistema che mantiene la verità
Kubernetes sembra “auto-gestirsi” perché è costruito attorno a un pattern semplice: descrivi ciò che vuoi e il sistema lavora continuamente per far corrispondere la realtà a quella descrizione. Il motore di questo pattern è il controller.
Cos'è un controller (in termini semplici)
Un controller è un loop che osserva lo stato corrente del cluster e lo confronta con lo stato desiderato che hai dichiarato in YAML (o via API). Quando nota una discrepanza, prende azione per ridurla.
Non è uno script eseguito una sola volta né aspetta che un umano prema un pulsante. Gira ripetutamente—osserva, decide, agisce—così può rispondere al cambiamento in qualsiasi momento.
Riconciliazione: come Kubernetes “mantiene le cose vere”
Quell'azione ripetuta di confrontare e correggere si chiama riconciliazione. È il meccanismo dietro alla promessa comune di “self-healing.” Il sistema non previene magicamente i guasti; nota la deriva e la corregge.
La deriva può accadere per motivi banali:
- un processo crasha
- un nodo scompare
- qualcuno scala qualcosa su o giù
- un deployment viene aggiornato
La riconciliazione significa che Kubernetes tratta quegli eventi come segnali per ricontrollare la tua intenzione e ripristinarla.
I risultati che interessano veramente le persone
I controller si traducono in risultati operativi familiari:
- Sostituire i pod falliti: se un pod muore, un controller nota che lo vuoi ancora e ne programma uno nuovo.
- Mantenere il conteggio delle repliche: se hai chiesto 5 repliche e ne girano solo 4, Kubernetes crea quella mancante.
- Mantenere il progresso del rollout: durante gli aggiornamenti, i controller guidano il sistema verso la nuova versione mantenendo la disponibilità desiderata.
La chiave è che non stai inseguendo manualmente i sintomi. Dichiari l'obiettivo e i loop di controllo fanno il lavoro continuo di “renderlo così”.
Perché questo scala oltre una singola feature
Questo approccio non è limitato a un solo tipo di risorsa. Kubernetes usa la stessa idea controller-e-riconciliazione su molti oggetti—Deployments, ReplicaSets, Jobs, Nodes, endpoints e altri. Quella consistenza è una grande ragione per cui Kubernetes è diventata una piattaforma: una volta capito il pattern, puoi prevedere il comportamento del sistema quando aggiungi nuove capacità (inclusi custom resources che seguono lo stesso loop).
Scheduling come feature di prodotto, non compito manuale
Spedisci un backend pulito
Crea un'API in Go con modelli PostgreSQL che si adatta a workflow di deployment ripetibili.
Se Kubernetes facesse solo “esegui container”, lascerebbe comunque ai team la parte più difficile: decidere dove ogni workload dovrebbe girare. Lo scheduling è il sistema integrato che posiziona automaticamente i Pod sui nodi giusti, basandosi su esigenze di risorse e regole che definisci.
Questo conta perché le decisioni di posizionamento influenzano direttamente uptime e costi. Un'API web su un nodo sovraccarico può diventare lenta o crashare. Un job batch vicino a servizi sensibili alla latenza può creare problemi di noisy-neighbor. Kubernetes trasforma questo in una capacità prodotto ripetibile invece che in una routine fatta con fogli di calcolo e SSH.
Cosa ottimizza lo scheduler
A livello base, lo scheduler cerca nodi che possano soddisfare le richieste del tuo Pod.
- Richieste CPU/memoria: le requests riservano capacità per le decisioni di posizionamento. Se richiedi 500m CPU e 1Gi di memoria, Kubernetes considererà solo nodi con capacità disponibile sufficiente.
Questa singola abitudine—impostare requests realistiche—spesso riduce l'instabilità “casuale” perché i servizi critici smettono di competere con tutto il resto.
Vincoli comuni usati nei cluster di produzione
Oltre alle risorse, la maggior parte dei cluster di produzione si basa su alcune regole pratiche:
- Affinity / anti-affinity: “metti questi insieme” (per località di cache) o “mantieni questi separati” (per evitare che un guasto nodo porti giù tutte le repliche).
- Taints e tolerations: segnala alcuni nodi come a scopo speciale (nodi GPU, nodi di sistema, nodi per compliance) e permetti solo ai workload approvati di atterrarci.
Come questo riduce i outage
Le funzionalità di scheduling aiutano i team a codificare l'intento operativo:
- distribuire le repliche su nodi diversi per sopravvivere ai guasti di nodo
- isolare i job “spiky” lontano dai servizi customer-facing
- evitare che nodi costosi (come GPU) vengano consumati dai workload sbagliati
Il takeaway pratico: tratta le regole di scheduling come requisiti di prodotto—scrivile, rivedile e applicale con costanza—così l'affidabilità non dipende da chi si ricorda il “nodo giusto” alle 2 di notte.
Scalabilità: da una istanza a migliaia senza riscrivere
Un'idea molto pratica di Kubernetes è che scalare non dovrebbe richiedere di cambiare il codice dell'app o inventare un nuovo approccio di deployment. Se l'app può girare come un container, la stessa definizione di workload può di solito crescere fino a centinaia o migliaia di copie.
La scalabilità ha due livelli
Kubernetes separa lo scaling in due decisioni correlate:
- Quanti pod far girare (più copie per maggiore throughput o ridondanza).
- Quanta capacità di cluster hai (nodi sufficienti—e delle dimensioni giuste—per posizionare quei pod).
Questa separazione è importante: puoi chiedere 200 pod, ma se il cluster ha spazio solo per 50, lo “scaling” diventa una coda di lavoro pendente.
Autoscaling, concettualmente (HPA, VPA, Cluster Autoscaler)
Kubernetes usa comunemente tre autoscaler, ognuno focalizzato su un diverso leva:
- Horizontal Pod Autoscaler (HPA): cambia il numero di pod basandosi su segnali come utilizzo CPU, memoria o metriche applicative custom.
- Vertical Pod Autoscaler (VPA): aggiusta requests/limits dei pod così ogni pod riceve più (o meno) CPU/memoria.
- Cluster Autoscaler: aggiunge o rimuove nodi così lo scheduler ha abbastanza spazio per posizionare i pod richiesti.
Usati insieme, questo trasforma lo scaling in policy: “mantieni la latenza stabile” o “tieni la CPU intorno a X%”, invece che in una routine manuale che sveglia qualcuno.
Da cosa dipende il “buon scaling”
Lo scaling funziona bene solo quanto sono buone le informazioni in ingresso:
- Metriche: la CPU è facile ma non sempre rappresentativa; il tasso di richieste, la profondità di coda e la latenza spesso riflettono meglio il carico reale.
- Requests/limits: dicono allo scheduler cosa serve a un pod. Senza di esse, il posizionamento e le decisioni di autoscaling diventano congetture.
- Pattern di carico: traffico a spike, warm-up lento e job pesanti in background cambiano la velocità con cui lo scaling dovrebbe reagire.
Trappole comuni
Due errori ricorrenti: scalare sulla metrica sbagliata (CPU bassa ma richieste timeout) e mancare le requests (gli autoscaler non possono prevedere la capacità, i pod vengono ammassati troppo e le prestazioni diventano incoerenti).
Deploy sicuri: rollout, health check e rollback
Un grande cambiamento che Kubernetes ha reso comune è trattare il “deploy” come un problema di controllo continuo, non come uno script che esegui alle 17 di venerdì. Rollout e rollback sono comportamenti di prima classe: dichiari quale versione vuoi e Kubernetes guida il sistema verso di essa controllando continuamente se la modifica è effettivamente sicura.
Rollout come transizione controllata
Con un Deployment, un rollout è una sostituzione graduale dei vecchi Pod con i nuovi. Invece di fermare tutto e riavviare, Kubernetes può aggiornare a passi—mantenendo capacità disponibile mentre la nuova versione dimostra di reggere il traffico reale.
Se la nuova versione inizia a fallire, il rollback non è una procedura d'emergenza: è un'operazione normale: puoi tornare a un ReplicaSet precedente (l'ultima versione nota buona) e lasciare che il controller ripristini lo stato vecchio.
Probes: evitare release “malate ma running”
I controlli di salute trasformano i rollout da “basati sulla speranza” a misurabili.
- Readiness probes determinano se un Pod dovrebbe ricevere traffico. Un container può essere in esecuzione ma non pronto (warm-up delle cache, attesa di dipendenze). La readiness evita di inviare traffico a istanze che non possono rispondere correttamente.
- Liveness probes rilevano quando un container è bloccato o malato e necessita di un riavvio. Questo evita la modalità di fallimento lento in cui un processo è vivo ma rotto.
Usate bene, le probe riducono i falsi successi—deploy che sembrano andati a buon fine perché i Pod sono partiti, ma in realtà falliscono richieste.
Strategie di deployment: rolling, blue/green, canary
Kubernetes supporta un rolling update out-of-the-box, ma i team spesso aggiungono pattern sopra:
- Blue/green: mantenere due ambienti completi e switchare il traffico dall'uno all'altro quando il nuovo è verificato.
- Canary: inviare una piccola percentuale di traffico alla nuova versione, osservare le metriche e poi espandere gradualmente.
Sicurezza misurabile (e automatizzabile)
I deployment sicuri dipendono da segnali: tasso di errore, latenza, saturazione e impatto utente. Molte squadre collegano le decisioni di promozione del rollout a SLO e budget di errore—se un canary consuma troppo budget, la promozione si ferma.
L'obiettivo è triggerare rollback automatici basati su indicatori reali (readiness fallita, aumento dei 5xx, spike di latenza), così il “rollback” diventa una risposta di sistema prevedibile—non un momento eroico a tarda notte.
Operazioni sui servizi: discovery, routing e networking stabile
Scegli un piano adatto
Passa da un prototipo personale a lavoro pronto per il team con il piano giusto.
Una piattaforma container sembra “automatica” solo se le altre parti del sistema riescono ancora a trovare la tua app dopo che si è spostata. Nei cluster di produzione i pod vengono creati, cancellati, rischedulati e scalati continuamente. Se ogni cambiamento richiedesse di aggiornare indirizzi IP nelle configurazioni, le operazioni si ridurrebbero a lavoro continuo—e gli outage sarebbero la norma.
Perché la service discovery è importante
La service discovery è la pratica di dare ai client un modo affidabile per raggiungere un insieme di backend che cambia. In Kubernetes, il cambiamento chiave è che smetti di indirizzare istanze individuali ("chiama 10.2.3.4") e inizi a indirizzare un nome di servizio ("chiama checkout"). La piattaforma gestisce quali pod servono attualmente quel nome.
Services, selector ed endpoints (in parole semplici)
Un Service è una porta d'ingresso stabile per un gruppo di pod. Ha un nome consistente e un indirizzo virtuale all'interno del cluster, anche quando i pod sottostanti cambiano.
Un selector è come Kubernetes decide quali pod sono “dietro” quella porta. Più comunemente corrisponde alle label, ad esempio app=checkout.
Endpoints (o EndpointSlices) sono la lista vivente degli IP dei pod che attualmente corrispondono al selector. Quando i pod scalano, fanno rollout o vengono rischedulati, questa lista si aggiorna automaticamente—i client continuano a usare lo stesso nome Service.
Indirizzi stabili, load balancing e instradamento del traffico
Operativamente, questo fornisce:
- Indirizzamento stabile: le app parlano a un nome DNS del Service invece di inseguire IP dei Pod.
- Load balancing: il traffico viene distribuito tra i pod sani dietro il Service.
- Instradamento prevedibile: puoi separare “chi dovrebbe ricevere traffico” (label/selector) da “dove i pod stanno girando”.
Per il traffico north–south (dall'esterno al cluster), Kubernetes usa tipicamente un Ingress o il più recente approccio Gateway. Entrambi forniscono un punto d'ingresso controllato dove puoi instradare le richieste per hostname o path e spesso centralizzano preoccupazioni come la terminazione TLS. L'idea importante è la stessa: mantenere l'accesso esterno stabile mentre i backend cambiano sotto il cofano.
Self-healing: cosa significa davvero in produzione
“Self-healing” in Kubernetes non è magia. È un insieme di reazioni automatizzate ai guasti: restart, reschedule e replace. La piattaforma osserva ciò che hai detto di volere (lo stato desiderato) e continua a spingere la realtà verso di esso.
Restart: quando un container crasha
Se un processo esce o un container diventa unhealthy, Kubernetes può riavviarlo sullo stesso nodo. Questo è solitamente guidato da:
- Liveness probes: “Questo container sta ancora funzionando?” Se no, riavvialo.
- Restart policies: regole su quando i riavvii devono avvenire.
Un pattern comune in produzione è: un container crasha → Kubernetes lo riavvia → il Service continua a instradare solo verso Pod sani.
Reschedule e replace: quando un nodo fallisce
Se un intero nodo va giù (problema hardware, panic del kernel, rete persa), Kubernetes marca il nodo come unavailable e ricomincia a spostare il lavoro altrove. A grandi linee:
- Il nodo viene marcato unhealthy/not ready.
- I Pod che giravano lì sono considerati persi.
- I controller creano Pod di sostituzione su altri nodi sani per ripristinare il conteggio delle repliche desiderato.
Questo è il “self-healing” a livello di cluster: il sistema rimpiazza capacità invece di aspettare che un umano faccia SSH.
Observability: come sai che si sta guarendo
Il self-healing conta solo se puoi verificarlo. I team tipicamente osservano:
- Log (log dell'app e eventi della piattaforma) per vedere cosa è stato riavviato e perché
- Metriche come conteggi di restart, probe fallite e readiness dei nodi
- Alert quando il healing non funziona (es. CrashLoopBackOff ripetuti, carenza di repliche o troppe eviction)
Errori di configurazione che rompono il self-healing
Anche con Kubernetes, il “healing” può fallire se le guardrail sono errate:
- Probes di liveness/readiness mancanti o sbagliate (falsi positivi o Pod che non diventano mai ready)
- Nessuna requests/limits, che porta a scheduling imprevedibile o OOM kill
- Troppe poche repliche (un singolo Pod non garantisce continuità)
- Tempi di probe troppo aggressivi che causano restart a catena
- Workload che dipendono dallo stato locale del nodo senza una strategia di storage duraturo
Quando il self-healing è ben configurato, gli outage diventano più piccoli e brevi—e più importante, misurabili.
Possiedi il codebase
Prendi il codice sorgente e applica le tue pratiche Kubernetes nella pipeline.
Kubernetes non ha vinto solo perché poteva eseguire container. Ha vinto perché ha offerto API standard per i bisogni operativi più comuni—deploy, scaling, networking e osservabilità. Quando i team si accordano sulla stessa “forma” degli oggetti (come Deployments, Services, Jobs), gli strumenti possono essere condivisi tra organizzazioni, la formazione è più semplice e i passaggi tra dev e ops smettono di dipendere dalla conoscenza tribale.
Perché le API standard cambiano i workflow dei team
Un'API consistente significa che la tua pipeline di deployment non deve conoscere le idiosincrasie di ogni app. Può applicare le stesse azioni—crea, aggiorna, rollback e verifica salute—usando gli stessi concetti Kubernetes.
Migliora anche l'allineamento: i team di sicurezza possono esprimere guardrail come policy; gli SRE possono standardizzare runbook attorno a segnali di salute comuni; gli sviluppatori possono ragionare sulle release con un vocabolario condiviso.
Estendere Kubernetes: CRD e Operator
Lo shift verso la “piattaforma” diventa evidente con le Custom Resource Definitions (CRD). Una CRD ti permette di aggiungere un nuovo tipo di oggetto al cluster (per esempio Database, Cache o Queue) e gestirlo con gli stessi pattern API degli oggetti built-in.
Un Operator affianca quegli oggetti custom a un controller che riconcilia continuamente la realtà allo stato desiderato—gestendo attività che prima erano manuali, come backup, failover o aggiornamenti di versione. Il beneficio chiave non è un'automazione magica; è riutilizzare lo stesso ciclo di controllo che Kubernetes applica a tutto il resto.
Fit con GitOps, CI/CD e controlli di policy
Poiché Kubernetes è guidato da API, si integra bene con workflow moderni:
- GitOps: lo stato desiderato vive in Git; le modifiche sono revisionate come codice.
- CI/CD: le pipeline applicano manifest, aspettano la readiness e promuovono le versioni.
- Controlli di policy: admission controller possono bloccare configurazioni rischiose prima che raggiungano la produzione.
Se vuoi guide pratiche su deployment e operazioni basate su queste idee, consulta il blog.
Cosa i team possono applicare oggi (anche fuori Kubernetes)
Le idee principali di Kubernetes—molte associate all'inquadratura iniziale di Brendan Burns—si traducono bene anche se stai eseguendo VM, serverless o un setup container più piccolo.
Pattern che migliorano le operazioni quotidiane
Scrivi lo “stato desiderato” e lascia che l'automazione lo faccia rispettare. Che sia Terraform, Ansible o una pipeline CI, tratta la configurazione come fonte di verità. Il risultato è meno passi manuali di deploy e molte meno sorprese del tipo “funzionava sulla mia macchina”.
Usa la riconciliazione, non script una tantum. Invece di script che girano una volta sperando nel meglio, costruisci loop che verificano continuamente proprietà chiave (versione, config, numero di istanze, salute). Questo è il modo per ottenere operazioni ripetibili e un recupero prevedibile dopo i guasti.
Rendi scheduling e scaling caratteristiche di prodotto. Definisci quando e perché aggiungi capacità (CPU, profondità delle code, SLO di latenza). Anche senza autoscaling Kubernetes, i team possono standardizzare regole di scala così la crescita non richiede riscrivere l'app o svegliare qualcuno.
Standardizza i rollout. Aggiornamenti rolling, health check e procedure di rollback rapide riducono il rischio delle modifiche. Puoi implementare questo con load balancer, feature flag e pipeline di deploy che mettono in gate le release su segnali reali.
Checklist di adozione sicura
- Definisci lo stato desiderato di un servizio: versione, config, dipendenze e conteggio minimo di istanze
- Aggiungi endpoint di salute (equivalenti a liveness e readiness) e collegali al load balancer o alla pipeline di deploy
- Automatizza i passaggi del rollout: deploy, verifica, shift del traffico e rollback su fallimento
- Crea un piccolo “reconciler”: controlli schedulati che correggono la deriva (config sbagliata, istanze mancanti)
- Aggiungi trigger di scaling con limiti chiari (max istanze, cooldown, regole di approvazione)
Cosa questo non risolve da solo
Questi pattern non risolveranno design applicativo povero, migrazioni di dati non sicure, o controllo dei costi. Hai ancora bisogno di API versionate, piani di migrazione, budgeting/limiti e osservabilità che colleghi i deploy all'impatto sui clienti.
Prossimi passi
Scegli un servizio rivolto al cliente e implementa la checklist end-to-end, poi estendi.
Se stai costruendo nuovi servizi e vuoi arrivare a “qualcosa distribuibile” più in fretta, Koder.ai può aiutarti a generare un'app web/backend/mobile completa da una specifica guidata in chat—tipicamente React sul frontend, Go con PostgreSQL sul backend e Flutter per il mobile—poi esportare il codice sorgente così puoi applicare gli stessi pattern Kubernetes discussi qui (configurazioni dichiarative, rollout ripetibili e operazioni rollback-friendly). Per i team che valutano costi e governance, puoi anche controllare i prezzi.