21 set 2025·8 min
Come C e C++ continuano a muovere sistemi operativi, database e motori di gioco
Scopri come C e C++ continuano a costituire il nucleo di sistemi operativi, database e motori di gioco—grazie a controllo della memoria, velocità e accesso a basso livello.
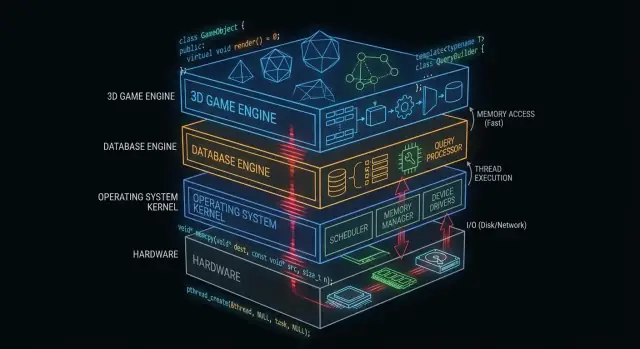
Perché C e C++ contano ancora dietro le quinte
“Sotto il cofano” è tutto ciò da cui dipende la tua app ma che raramente tocchi direttamente: kernel dei sistemi operativi, driver di dispositivo, motori di archiviazione dei database, stack di rete, runtime e librerie critiche per le prestazioni.
Al contrario, ciò che molti sviluppatori applicativi vedono quotidianamente è la superficie: framework, API, runtime gestiti, gestori di pacchetti e servizi cloud. Quegli strati sono costruiti per essere sicuri e produttivi—anche quando nascondono intenzionalmente la complessità.
Perché alcuni livelli devono restare vicini all'hardware
Alcuni componenti software hanno requisiti difficili da soddisfare senza controllo diretto:
- Prestazioni e latenza prevedibili (es. schedulazione della CPU, gestione degli interrupt, streaming di asset)
- Controllo preciso della memoria (layout, allineamento, comportamento della cache, evitare pause)
- Accesso diretto all'hardware (registri, DMA, driver, filesystem e dispositivi a blocchi)
- Binarî piccoli e portabili che possono essere eseguiti presto all'avvio o in ambienti vincolati
C e C++ sono ancora comuni qui perché compilano in codice nativo con sovraccarico minimo a runtime e danno agli ingegneri un controllo granulare sulla memoria e sulle chiamate di sistema.
Dove C e C++ sono più diffusi oggi
A un livello alto, troverai C e C++ che alimentano:
- Nuclei dei sistemi operativi e librerie di basso livello
- Driver e firmware embedded
- Motori di database (esecuzione di query, storage, indicizzazione)
- Motori di gioco e sottosistemi in tempo reale (rendering, fisica, audio)
- Compilatori, toolchain e runtime di linguaggi su cui si appoggiano altri linguaggi
Cosa tratterà (e non tratterà) questo articolo
Questo articolo si concentra sulla meccanica: cosa fanno questi componenti “dietro le quinte”, perché traggono vantaggio dal codice nativo e quali compromessi comporta quel potere.
Non affermerà che C/C++ siano la scelta migliore per ogni progetto, né diventerà una guerra tra linguaggi. L'obiettivo è una comprensione pratica di dove questi linguaggi mantengono il loro valore—e perché gli stack software moderni continuano a costruirsi su di essi.
Cosa rende C e C++ adatti al software di sistema
C e C++ sono ampiamente usati per il software di sistema perché permettono programmi “vicini al metallo”: piccoli, veloci e strettamente integrati con OS e hardware.
Compilati in codice nativo (parole semplici)
Quando il codice in C/C++ viene compilato, diventa istruzioni macchina che la CPU può eseguire direttamente. Non c'è un runtime obbligatorio che traduce le istruzioni mentre il programma gira.
Questo è importante per i componenti infrastrutturali—kernel, motori di database, motori di gioco—dove anche piccoli sovraccarichi possono sommarsi sotto carico.
Prestazioni prevedibili per l'infrastruttura core
Il software di sistema ha spesso bisogno di tempistiche coerenti, non solo di una buona velocità media. Per esempio:
- Uno scheduler del sistema operativo deve rispondere rapidamente sotto carico.
- Un database deve mantenere la latenza stabile mentre molti utenti interpellano contemporaneamente.
- Un motore di gioco deve rispettare un budget per frame (ad esempio ~16 ms per 60 FPS).
C/C++ offrono controllo sull'uso della CPU, sul layout della memoria e sulle strutture dati, il che aiuta gli ingegneri a mirare a prestazioni prevedibili.
Accesso diretto alla memoria e ai puntatori
I puntatori permettono di lavorare con indirizzi di memoria direttamente. Questa potenza può sembrare intimidatoria, ma sblocca capacità che molti linguaggi di alto livello astraggono via:
- Allocatori personalizzati ottimizzati per carichi di lavoro specifici
- Formati compatti in memoria (utili in database e cache)
- Pattern di I/O a zero-copia dove i dati non vengono duplicati ripetutamente
Usato con cura, questo livello di controllo può offrire guadagni di efficienza significativi.
Compromessi: sicurezza, complessità e tempo di sviluppo
La stessa libertà è anche il rischio. I compromessi comuni includono:
- Sicurezza: errori possono causare crash, corruzione di dati o vulnerabilità di sicurezza.
- Complessità: la gestione manuale della memoria e il comportamento indefinito richiedono disciplina.
- Tempo di sviluppo: testing, code review e tooling diventano non negoziabili per l'affidabilità.
Un approccio comune è mantenere il nucleo critico per le performance in C/C++, poi circondarlo con linguaggi più sicuri per le funzionalità di prodotto e l'UX.
C/C++ nei kernel dei sistemi operativi
Il kernel del sistema operativo si trova più vicino all'hardware. Quando il tuo laptop si risveglia, il browser si apre o un programma richiede più RAM, il kernel coordina quelle richieste e decide cosa fare dopo.
Cosa fa realmente un kernel
A livello pratico, i kernel gestiscono alcuni compiti chiave:
- Schedulazione: decidere quale programma (e quale thread) ottiene tempo CPU e per quanto.
- Gestione della memoria: allocare memoria ai processi, mantenerli isolati e recuperare memoria in sicurezza.
- Gestione dei dispositivi: parlare con l'hardware tramite driver (disco, rete, tastiera, GPU, ecc.).
- Confini di sicurezza: far rispettare i permessi in modo che un programma non possa leggere o corrompere i dati di un altro.
Poiché queste responsabilità sono al centro del sistema, il codice del kernel è sia sensibile alle prestazioni sia alla correttezza.
Perché il controllo stretto favorisce C (e talvolta C++)
Gli sviluppatori del kernel hanno bisogno di controllo preciso su:
- Layout della memoria: strutture a dimensione fissa, allineamento e comportamento di allocazione prevedibile.
- Istruzioni CPU e convenzioni di chiamata: interazione con interrupt, context switch e sincronizzazione a basso livello.
- Registri hardware: lettura/scrittura di indirizzi specifici e gestione di modalità CPU speciali.
C resta un linguaggio comune per i kernel perché mappa chiaramente ai concetti a livello macchina, rimanendo leggibile e portabile tra architetture. Molti kernel si appoggiano anche all'assembly per le parti più piccole e specifiche dell'hardware, con C che svolge la maggior parte del lavoro.
C++ può comparire nei kernel, ma di solito in uno stile ristretto (feature runtime limitate, politiche di eccezioni attente e regole severe sulle allocazioni). Dove è usato, serve tipicamente a migliorare l'astrazione senza rinunciare al controllo.
Codice “vicino al kernel” spesso scritto in C/C++
Anche quando il kernel è conservativo, molti componenti adiacenti sono in C/C++:
- Driver di dispositivo (soprattutto quelli critici per le prestazioni)
- Librerie standard e runtime (parti di libc, threading di basso livello)
- Bootloader e codice di avvio precoce
- Servizi di sistema che richiedono velocità nativa (es. helper per rete o storage)
Per saperne di più su come i driver collegano software e hardware, vedere /blog/device-drivers-and-hardware-access.
Driver di dispositivo e accesso all'hardware
I driver di dispositivo traducono tra un sistema operativo e l'hardware fisico—schede di rete, GPU, controller SSD, dispositivi audio e altro. Quando premi “play”, copi un file o ti connetti al Wi‑Fi, un driver è spesso il primo codice che deve rispondere.
Poiché i driver sono sul percorso critico per l'I/O, sono estremamente sensibili alle prestazioni. Qualche microsecondo in più per pacchetto o per richiesta disco può sommarsi rapidamente su sistemi molto occupati. C e C++ restano comuni qui perché possono chiamare direttamente le API del kernel, controllare il layout della memoria con precisione ed eseguire con sovraccarico minimo.
Interrupt, DMA e perché le API di basso livello sono importanti
L'hardware non aspetta educatamente il suo turno. I dispositivi segnalano la CPU tramite interrupt—notifiche urgenti che qualcosa è accaduto (è arrivato un pacchetto, un trasferimento è terminato). Il codice del driver deve gestire questi eventi rapidamente e correttamente, spesso sotto vincoli stretti di tempo e threading.
Per alte prestazioni, i driver si affidano anche al DMA (Direct Memory Access), dove i dispositivi leggono/scrivono la memoria di sistema senza che la CPU copi ogni byte. Configurare il DMA tipicamente comporta:
- Preparare buffer nel formato e allineamento corretti
- Fornire al dispositivo indirizzi fisici o descrittori mappati
- Sincronizzare la proprietà della memoria tra dispositivo e CPU
Questi compiti richiedono interfacce a basso livello: registri mappati in memoria, flag di bit e ordinamento attento di letture/scritture. C/C++ rendono pratico esprimere questa logica “vicina al metallo” pur rimanendo portabili tra compilatori e piattaforme.
La stabilità è non negoziabile
A differenza di una app normale, un bug in un driver può bloccare l'intero sistema, corrompere dati o aprire falle di sicurezza. Questo rischio plasma come il codice driver viene scritto e revisionato.
I team riducono il pericolo usando standard di codifica rigorosi, controlli difensivi e revisioni a strati. Pratiche comuni includono limitare l'uso pericoloso dei puntatori, validare input da hardware/firmware e far girare analisi statica nella CI.
Gestione della memoria: potere e insidie
Build from chat
Crea un'app React, Go o Flutter a partire da una semplice chat con Koder.ai.
La gestione della memoria è uno dei principali motivi per cui C e C++ dominano ancora parti di sistemi operativi, database e motori di gioco. È anche uno dei posti più facili in cui creare bug sottili.
Cosa significa “gestione della memoria”
A livello pratico, la gestione della memoria include:
- Allocare memoria (ottenere un blocco per conservare dati)
- Liberare memoria (restituirla quando non serve più)
- Gestire la frammentazione (buchi residui che rallentano o complicano allocazioni future)
In C questo è spesso esplicito (malloc/free). In C++ può essere esplicito (new/delete) o incapsulato in pattern più sicuri.
Perché il controllo manuale può essere un vantaggio
Nei componenti critici per le prestazioni, il controllo manuale può essere una caratteristica:
- Si possono evitare pause imprevedibili dovute alla garbage collection.
- Si può scegliere dove e come la memoria viene allocata (es. allocatori a pool o ad arena), migliorando la coerenza.
- Si possono adattare i pattern di allocazione ai carichi reali (molti oggetti piccoli vs blocchi grandi contigui).
Questo conta quando un database deve mantenere una latenza costante o un motore di gioco deve rispettare il budget per frame.
Modalità di guasto comuni (e perché sono gravi)
La stessa libertà crea problemi classici:
- Memory leak: dimenticare di liberare memoria, facendo crescere l'utilizzo fino a degradazione o crash del processo.
- Buffer overflow: scrivere oltre la fine di un array, corrompendo dati o abilitando exploit.
- Use-after-free: usare un puntatore dopo aver liberato la memoria, portando a crash difficili da riprodurre.
Questi bug possono essere sottili perché il programma può “sembrare a posto” finché un carico di lavoro specifico non scatena il guasto.
Come le pratiche moderne aiutano
Il C++ moderno riduce il rischio senza rinunciare al controllo:
- RAII (Resource Acquisition Is Initialization) associa la durata delle risorse allo scope così la pulizia avviene automaticamente.
- Smart pointer (come
std::unique_ptrestd::shared_ptr) rendono esplicita la proprietà e prevengono molte perdite. - Sanitizer (AddressSanitizer, UndefinedBehaviorSanitizer) e l'analisi statica individuano problemi presto, spesso in CI.
Usati bene, questi strumenti mantengono C/C++ veloci riducendo la probabilità che bug di memoria raggiungano la produzione.
Concorrenza e prestazioni multi-core
Le CPU moderne non stanno migliorando drasticamente la velocità per core—stanno aggiungendo più core. Questo sposta la domanda di prestazioni da “Quanto velocemente è il mio codice?” a “Quanto bene il mio codice può girare in parallelo senza ostacolarsi?”. C e C++ sono popolari qui perché permettono controllo a basso livello su threading, sincronizzazione e comportamento della memoria con pochissimo overhead.
Thread, core e schedulazione
Un thread è l'unità con cui il tuo programma svolge lavoro; un core CPU è dove quel lavoro viene eseguito. Lo scheduler del sistema operativo mappa thread eseguibili sui core disponibili, facendo continui trade-off.
Dettagli minuti di schedulazione contano nel codice critico per le prestazioni: sospendere un thread al momento sbagliato può bloccare una pipeline, creare code di attesa o produrre comportamento a scatti. Per lavoro CPU-bound, mantenere i thread attivi allineati al numero di core spesso riduce il thrashing.
Basi del locking: mutex, atomic e contesa
- Mutex sono facili da ragionare, ma la condivisione pesante crea contenzione—tempo speso ad aspettare invece che a lavorare.
- Atomic possono essere più veloci per piccoli aggiornamenti a stato condiviso, ma richiedono progettazione attenta per evitare bug di correttezza sottili.
L'obiettivo pratico non è “non bloccare mai”. È: bloccare meno, bloccare in modo più intelligente—tenere le sezioni critiche piccole, evitare lock globali e ridurre lo stato mutabile condiviso.
Perché gli spike di latenza contano
Database e motori di gioco non si preoccupano solo della velocità media—contano i picchi di pausa. Un convoglio di lock, un page fault o un worker bloccato può causare micro-interruzioni percepibili, query lente che violano uno SLA o stuttering nel gameplay.
Pattern comuni in C/C++
Molti sistemi ad alte prestazioni si basano su:
- Thread pool per riutilizzare worker e mantenere la schedulazione prevedibile.
- Work-stealing queue per bilanciare il carico tra core.
- Queue lock-free (in alcuni percorsi caldi) per ridurre il blocking—usate con attenzione perché la correttezza è più difficile da dimostrare.
Questi pattern mirano a throughput costante e latenza coerente sotto pressione.
Motori di database: dove C/C++ portano velocità
Un motore di database non si limita a “memorizzare righe”. È un ciclo serrato di lavoro CPU e I/O che gira milioni di volte al secondo, dove piccole inefficienze si sommano rapidamente. Per questo molti motori e componenti core sono ancora scritti principalmente in C o C++.
Il compito principale del motore: parse, pianifica, esegui
Quando invii SQL, il motore:
- Parse (trasforma il testo in una rappresentazione strutturata)
- Pianifica (sceglie un modo efficiente per rispondere alla query)
- Esegue (scan, lookup di indici, join, sort, aggregazioni e restituisce le righe)
Ogni fase beneficia di controllo accurato sulla memoria e sul tempo CPU. C/C++ abilitano parser veloci, meno allocazioni durante la pianificazione e un percorso di esecuzione snello—spesso con strutture dati personalizzate progettate per il carico di lavoro.
Motore di storage: pagine, indici, buffering
Sotto lo strato SQL, il motore di storage gestisce i dettagli essenziali:
- Pagine: i dati vengono letti e scritti in blocchi a dimensione fissa, non riga per riga.
- Indici: B-tree, LSM-tree e strutture correlate devono essere aggiornate in modo efficiente.
- Buffering: un buffer pool decide cosa resta in memoria, cosa viene espulso e come vengono raggruppate letture/scritture.
C/C++ è un buon abbinamento qui perché questi componenti dipendono da layout di memoria prevedibile e controllo diretto dei confini di I/O.
Strutture dati cache-friendly (perché conta)
Le prestazioni moderne dipendono spesso più dalle cache CPU che dalla sola velocità della CPU. Con C/C++, gli sviluppatori possono impacchettare i campi usati di frequente insieme, memorizzare colonne in array contigui e minimizzare l'inseguimento di puntatori—pattern che mantengono i dati vicini alla CPU e riducono gli stall.
Dove compaiono ancora i linguaggi di alto livello
Anche nei database dominati da C/C++, linguaggi di livello più alto spesso alimentano tool di admin, backup, monitoring, migrazioni e orchestrazione. Il core critico per le prestazioni resta nativo; l'ecosistema circostante privilegia velocità di iterazione e usabilità.
Storage, caching e I/O nei database
Own your codebase
Esporta il codice sorgente ogni volta che hai bisogno del controllo completo o di tool personalizzati.
I database sembrano istantanei perché lavorano duramente per evitare il disco. Anche su SSD veloci, leggere dallo storage è ordini di grandezza più lento che leggere dalla RAM. Un motore di database scritto in C o C++ può controllare ogni passo di quell'attesa—e spesso evitarla.
Buffer pool e page cache in termini quotidiani
Pensa ai dati su disco come a scatole in un magazzino. Recuperare una scatola (lettura da disco) richiede tempo, quindi tieni gli oggetti più usati sulla scrivania (RAM).
- Buffer pool: la “scrivania” del database, che contiene pagine usate di recente (blocchi a dimensione fissa di tabelle e indici).
- Page cache: la “scrivania” del sistema operativo, che fa caching dei dati di file letti di recente.
Molti database gestiscono il proprio buffer pool per prevedere cosa deve rimanere caldo ed evitare di competere con l'OS per la memoria.
Perché il disco è lento—e come il caching lo nasconde
Lo storage non è solo lento; è anche imprevedibile. Spike di latenza, code e accesso casuale aggiungono ritardi. Il caching mitiga questo:
- Servendo le letture dalla RAM la maggior parte delle volte
- Raggruppando le scritture in operazioni I/O meno frequenti e più grandi
- Prefetching di pagine che probabilmente serviranno dopo (es. durante scansioni di indici)
Scelte di design che beneficiano del controllo a basso livello
C/C++ permette ai motori di database di ottimizzare dettagli che contano ad alto throughput: letture allineate, direct I/O vs buffered I/O, politiche di espulsione personalizzate e layout in memoria studiati per indici e buffer di log. Queste scelte possono ridurre copie, evitare contesa e mantenere le cache CPU alimentate con dati utili.
Compressione e checksum possono diventare vincoli CPU
Il caching riduce l'I/O, ma aumenta il lavoro della CPU. Decomprimere pagine, calcolare checksum, cifrare log e validare record possono diventare colli di bottiglia. Poiché C e C++ offrono controllo sui pattern di accesso alla memoria e cicli favorevoli a SIMD, vengono spesso usati per spremere più lavoro da ogni core.
Motori di gioco: vincoli in tempo reale
I motori di gioco operano sotto aspettative in tempo reale: il giocatore muove la camera, preme un pulsante e il mondo deve rispondere immediatamente. Questo si misura in tempo per frame, non in throughput medio.
Budget per frame: perché i millisecondi contano
A 60 FPS hai circa 16,7 ms per produrre un frame: simulazione, animazione, fisica, mixing audio, culling, invio del rendering e spesso streaming di asset. A 120 FPS il budget scende a 8,3 ms. Superare il budget viene percepito come stutter, input lag o pacing incoerente.
Questo è il motivo per cui la programmazione in C e la programmazione in C++ restano comuni nei core dei motori: prestazioni prevedibili, basso overhead e controllo fine sulla memoria e l'uso della CPU.
Sottosistemi core spesso scritti in C/C++
La maggior parte dei motori usa codice nativo per i compiti pesanti:
- Rendering (attraversamento della scena, costruzione delle draw-call, gestione delle risorse GPU)
- Fisica (rilevamento collisioni, vincoli, corpi rigidi)
- Animazione (blending scheletrico, IK, valutazione delle pose)
- Audio (mixaggio in tempo reale, spazializzazione)
Questi sistemi girano ogni frame, quindi piccole inefficienze si moltiplicano rapidamente.
Cicli serrati e layout dei dati
Molte prestazioni nei giochi derivano da cicli serrati: iterare entità, aggiornare trasformazioni, testare collisioni, skinning dei vertici. C/C++ rende più semplice strutturare la memoria per efficienza cache (array contigui, meno allocazioni, meno indirezioni virtuali). Il layout dei dati può contare tanto quanto la scelta dell'algoritmo.
Dove si inserisce lo scripting (e dove no)
Molti studi usano linguaggi di scripting per la logica di gameplay—quest, regole UI, trigger—perché la velocità di iterazione è importante. Il core del motore tipicamente resta nativo, e gli script chiamano i sistemi C/C++ tramite binding. Un pattern comune: gli script orchestrano; C/C++ esegue le parti costose.
Compilatori, toolchain e interoperabilità
Go from code to running
Distribuisci e ospita ciò che crei, poi continua a migliorarlo con lo stesso flusso di lavoro in chat.
C e C++ non si limitano a “essere eseguiti”—vengono costruiti in binari nativi che corrispondono a una CPU e un sistema operativo specifici. Questa pipeline di build è una ragione fondamentale per cui questi linguaggi restano centrali in OS, database e motori di gioco.
Cosa succede davvero durante una build
Una build tipica ha alcune fasi:
- Compilatore: trasforma il sorgente C/C++ in file oggetto specifici per la macchina.
- Linker: unisce gli oggetti con le librerie per produrre un eseguibile o una libreria condivisa.
- Output binario: l'artefatto finale che l'OS può caricare direttamente (spesso con simboli di debug separati).
La fase di linking è dove emergono molti problemi reali: simboli mancanti, versioni di librerie incompatibili o impostazioni di build incongruenti.
Perché toolchain e supporto piattaforma contano
Una toolchain è l'insieme completo: compilatore, linker, libreria standard e strumenti di build. Per il software di sistema, la copertura piattaforma è spesso decisiva:
- SDK per console e mobile possono richiedere compilatori e linker specifici.
- Database e software backend hanno bisogno di build stabili su diverse distribuzioni Linux e tipi di CPU.
- Lavori su OS e driver possono richiedere cross-compiler, flag severi e disciplina ABI.
I team scelgono spesso C/C++ anche perché le toolchain sono mature e disponibili ovunque—da dispositivi embedded ai server.
Interfacciarsi con altri linguaggi (FFI)
C è spesso trattato come “adattatore universale.” Molti linguaggi possono chiamare funzioni C tramite FFI, perciò i team mettono spesso la logica critica per le prestazioni in una libreria C/C++ ed espongono una piccola API al codice di livello più alto. Per questo motivo Python, Rust, Java e altri avvolgono frequentemente componenti C/C++ esistenti invece di riscriverli.
Debugging e profiling: cosa misurano i team
I team C/C++ tipicamente misurano:
- Tempo CPU (funzioni calde, stack di chiamata)
- Uso della memoria (allocazioni, leak, frammentazione)
- Latenza (tempo per frame nei giochi, tempo di query nei database)
- Comportamento I/O (cache miss, letture da disco, syscall)
Il flusso è coerente: trova il collo di bottiglia, conferma con i dati, poi ottimizza il pezzo più piccolo che conta.
Scegliere C/C++ oggi: guida pratica alla decisione
C e C++ sono ancora ottimi strumenti—quando costruisci software in cui contano davvero pochi millisecondi, pochi byte o un'istruzione CPU specifica. Non sono la scelta predefinita per ogni feature o team.
Quando scegliere C/C++
Scegli C/C++ quando il componente è critico per le prestazioni, ha bisogno di controllo stretto della memoria o deve integrarsi strettamente con OS o hardware.
Adatti tipici includono:
- Percorsi caldi dove la latenza è visibile (parsing, compressione, rendering, esecuzione di query)
- Moduli di basso livello che devono essere prevedibili (allocator, scheduler, primitive di rete)
- Librerie cross-platform dove il codice nativo è il prodotto (SDK, engine, embedded)
- Situazioni dove la portabilità fra compilatori/toolchain è un requisito vincolante
Quando preferire altri linguaggi
Scegli un linguaggio di livello più alto quando la priorità è sicurezza, velocità di iterazione o manutenibilità su larga scala.
Spesso è più sensato usare Rust, Go, Java, C#, Python o TypeScript quando:
- Il team è grande e il turnover è previsto (meno piè-di-capra è meglio)
- La feature cambia frequentemente e la correttezza pesa più che spremere cicli CPU
- Hai bisogno di garanzie di safety sulla memoria
- La produttività degli sviluppatori e il bacino di assunzione sono vincoli più grandi della velocità bruta
Nella pratica, la maggior parte dei prodotti è mista: librerie native per il percorso critico e servizi/UI di alto livello per il resto.
Nota pratica per i team di app (dove si inserisce Koder.ai)
Se costruisci principalmente funzionalità web, backend o mobile, spesso non devi scrivere C/C++ per beneficiarne—lo consumi tramite OS, database, runtime e dipendenze. Piattaforme come Koder.ai sfruttano questa separazione: puoi produrre rapidamente app React, backend Go + PostgreSQL o app Flutter tramite un flusso di lavoro guidato in chat, integrando componenti nativi quando serve (per esempio chiamando una libreria C/C++ esistente tramite un confine FFI). In questo modo la maggior parte della superficie di prodotto resta in codice che si itera velocemente, senza ignorare quando il codice nativo è lo strumento giusto.
Checklist pratica (componente per componente)
Fai queste domande prima di impegnarti:
- È sul cammino critico? Misura prima; non indovinare.
- Quali sono le modalità di fallimento? La corruzione di memoria in C/C++ può essere catastrofica.
- Qual è il confine dell'interfaccia? Puoi isolare il codice nativo dietro una piccola API?
- Avete le competenze? Review, testing e profiling sono non negoziabili.
- Qual è il target di deployment? Console, embedded, kernel e driver favoriscono spesso C/C++.
- Come testerete e profilerete? Pianificate tooling e CI fin dal primo giorno.
Letture successive suggerite
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing