20 mar 2025·8 min
Come costruire un'app web di supporto clienti per ticket e SLA
Pianifica, progetta e costruisci un'app web di supporto clienti con workflow per ticket, monitoraggio SLA e knowledge base ricercabile—più ruoli, analytics e integrazioni.
Definisci obiettivi, utenti e ambito
Un prodotto per ticketing diventa confuso quando è costruito attorno a funzionalità anziché ai risultati. Prima di progettare campi, code o automazioni, allineatevi su chi userà l'app, quale problema risolve e cosa significa “bene”.
Identifica i tuoi utenti (e le loro attività quotidiane)
Inizia elencando i ruoli e cosa ognuno deve portare a termine in una settimana tipo:
- Agenti: smistare, rispondere, risolvere e documentare le soluzioni rapidamente.
- Team lead: riequilibrare il carico, individuare ticket bloccati, far rispettare gli SLA, coachare gli agenti.
- Admin: configurare canali, categorie, automazioni, permessi e modelli.
- Clienti (opzionale): inviare richieste, tracciare lo stato, aggiungere dettagli, trovare risposte in un portale.
Se salti questo passaggio, finirai per ottimizzare per gli admin mentre gli agenti si trovano in difficoltà nella coda.
Scrivi i problemi che risolvi
Mantieni la lista concreta e legata a comportamenti osservabili:
- SLA mancati: i ticket invecchiano silenziosamente; le escalation arrivano troppo tardi.
- Code disordinate: proprietà poco chiare, lavoro duplicato e confusione su “dove va questo?”.
- Domande ripetute: le stesse risposte vengono digitare continuamente, rallentando le risoluzioni.
Decidi dove verrà usata l'app
Sii esplicito: è uno strumento interno o prevedi anche un portale per i clienti? I portali cambiano i requisiti (autenticazione, permessi, contenuti, branding, notifiche).
Scegli le metriche di successo fin da subito
Scegli un piccolo set da monitorare fin dal giorno uno:
- Tempo alla prima risposta
- Tempo di risoluzione
- Tasso di deflessione (problemi risolti tramite knowledge base anziché ticket)
Crea una dichiarazione di ambito per la v1
Scrivi 5–10 frasi che descrivono cosa è incluso nella v1 (workflow indispensabili) e cosa viene dopo (nice‑to‑have come routing avanzato, suggerimenti AI o report approfonditi). Questo diventa il tuo criterio quando le richieste cresceranno.
Progetta il modello di ticket e il ciclo di vita
Il modello di ticket è la “fonte di verità” per tutto il resto: code, SLA, reporting e ciò che gli agenti vedono a schermo. Sistemalo presto per evitare migrazioni dolorose.
Mappa un ciclo di vita che puoi spiegare in una frase
Parti da uno set chiaro di stati e definisci cosa significano operativamente:
- New: creato, non ancora triato
- Assigned: assegnato a un agente o a un team
- In progress: in lavorazione attiva
- Waiting: bloccato (risposta cliente, terze parti, engineering)
- Solved: l'agente ritiene risolto (spesso scatena una notifica)
- Closed: stato finale (bloccato o con modifiche limitate)
Aggiungi regole per le transizioni. Ad esempio, solo i ticket Assigned/In progress possono essere impostati su Solved, e un ticket Closed non può riaprirsi senza creare un follow‑up.
Decidi come i ticket entrano nel sistema
Elenca ogni percorso di ingresso che supporterai ora (e cosa aggiungerai dopo): form web, email in entrata, chat e API. Ogni canale dovrebbe creare lo stesso oggetto ticket, con pochi campi specifici del canale (intestazioni email o ID della trascrizione chat). La coerenza mantiene automazioni e report gestibili.
Scegli i campi obbligatori (e mantienili minimi)
Al minimo, richiedi:
- Oggetto e descrizione
- Richiedente (identità del cliente)
- Priorità (quanto è urgente)
- Categoria (che tipo di problema)
Tutto il resto può essere opzionale o derivato. Un form gonfio riduce la qualità delle compilazioni e rallenta gli agenti.
Pianifica tag e campi custom per team reali
Usa tag per filtraggi leggeri (es. “billing”, “bug”, “vip”) e campi personalizzati quando serve reporting o routing strutturato (es. “Area prodotto”, “Order ID”, “Regione”). Assicurati che i campi possano essere limitati a team in modo che un dipartimento non intasi gli altri.
Definisci la collaborazione all'interno di un ticket
Gli agenti hanno bisogno di uno spazio sicuro per coordinarsi:
- Note interne (non visibili ai clienti)
- @menzioni e liste follower/CC
- Ticket collegati (duplicati, incidenti parent/child)
La UI dell'agente dovrebbe rendere questi elementi a portata di un clic nella timeline principale.
Costruisci code di ticket e workflow di assegnazione
Code e assegnazioni sono il punto in cui un sistema di ticketing smette di essere una inbox condivisa e diventa uno strumento operativo. Il tuo obiettivo è semplice: ogni ticket deve avere una “prossima azione” ovvia e ogni agente deve sapere cosa lavorare ora.
Progetta una coda agente che risponda a “cosa faccio adesso?”
Crea una vista di coda che di default mostri il lavoro più urgente. Opzioni di ordinamento comuni che gli agenti useranno davvero sono:
- Priorità (es. P1–P4)
- Tempo rimanente SLA (prima scade)
- Ultimo aggiornamento (per intercettare conversazioni ferme)
Aggiungi filtri rapidi (team, canale, prodotto, livello cliente) e una ricerca veloce. Mantieni la lista densa: oggetto, richiedente, priorità, stato, conto alla rovescia SLA e assegnatario sono di solito sufficienti.
Regole di assegnazione: automatico quando possibile, manuale quando serve
Supporta pochi percorsi di assegnazione così i team possono evolvere senza cambiare strumenti:
- Assegnazione manuale per casi limite e momenti di training
- Round‑robin per distribuire il carico equamente
- Routing per competenze (lingua, area prodotto, fatturazione vs tecnico)
- Routing per team (es. “Payments”, “Enterprise”, “Resi”)
Rendi le decisioni sulle regole visibili (“Assegnato da: Competenze → Francese + Fatturazione”) così gli agenti si fidano del sistema.
Stati e template che mantengono il lavoro in movimento
Stati come Waiting on customer e Waiting on third party evitano che i ticket sembrino “inattivi” quando l'azione è bloccata, e rendono il reporting più veritiero.
Per velocizzare le risposte, includi risposte predefinite e template di risposta con variabili sicure (nome, numero ordine, data SLA). I template dovrebbero essere ricercabili e modificabili da lead autorizzati.
Previeni collisioni (due agenti, un ticket)
Aggiungi gestione delle collisioni: quando un agente apre un ticket, mostra un breve “lock view/edit” o un banner “attualmente gestito da”. Se un altro prova a rispondere, avvisa e richiedi una conferma prima dell'invio (o blocca l'invio) per evitare risposte duplicate o contraddittorie.
Implementa regole SLA, timer e escalation
Gli SLA aiutano solo se tutti concordano su cosa si misura e l'app lo applica in modo coerente. Trasforma “rispondiamo velocemente” in politiche che il sistema può calcolare.
Definisci le politiche SLA (cosa misurerai)
La maggior parte dei team inizia con due timer per ticket:
- Tempo alla prima risposta: tempo dalla creazione del ticket alla prima risposta di un agente (o prima risposta pubblica non automatizzata).
- Tempo di risoluzione: tempo dalla creazione del ticket a “Solved/Closed”.
Mantieni le politiche configurabili per priorità, canale o livello cliente (per esempio: VIP 1 ora per la prima risposta, Standard 8 ore lavorative).
Decidi quando i clock SLA partono e si fermano
Scrivi le regole prima di codificare, perché i casi limite crescono in fretta:
- Orari lavorativi vs 24/7: definisci un calendario (fuso orario, giorni, festivi).
- Stati di pausa: ferma il timer quando il ticket è in “Waiting on customer” o “Pending external vendor”.
- Condizioni di ripresa: riavvia quando il cliente risponde o lo stato torna a “Open/In progress”.
Memorizza gli eventi SLA (start, pause, resume, breach) così potrai spiegare perché qualcosa ha infranto l'SLA.
Rendi lo stato SLA ovvio nell'interfaccia
Gli agenti non dovrebbero aprire un ticket per scoprire che sta per violare i tempi. Aggiungi:
- Un contatore in conto alla rovescia (tempo rimanente)
- Flag di overdue con gravità chiara (avviso vs violazione)
- Avvisi opzionali (in‑app, email o chat) quando una soglia è vicina
Costruisci percorsi di escalation
L'escalation deve essere automatica e prevedibile:
- Notifica un lead al 80% del tempo consentito
- Riassegna a una coda on‑duty se scade
- Aumenta la priorità o aggiungi un tag “Escalated”
Pianifica i report SLA
Al minimo, traccia conteggio violazioni, tasso di violazione e trend nel tempo. Registra anche motivi di breach (pausa troppo lunga, priorità errata, coda sottodimensionata) così i report portino ad azioni, non a colpe.
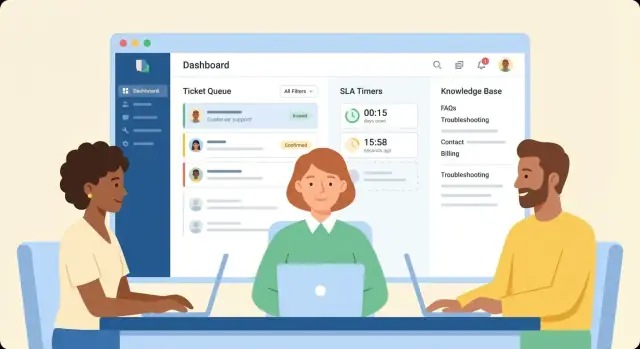
Crea una Knowledge Base che riduca i ticket ripetuti
Una buona knowledge base (KB) non è solo una cartella di FAQ: è una feature di prodotto che dovrebbe ridurre misurabilmente le domande ricorrenti e velocizzare le risoluzioni. Progettala come parte del flusso di ticketing, non come un sito di documentazione separato.
Struttura: rendi i contenuti facili da mantenere
Inizia con un modello informativo semplice che scala:
- Categorie → sezioni → articoli (navigazione semplice per clienti e agenti)
- Tag per argomenti trasversali (fatturazione, accesso, integrazioni) senza duplicare articoli
- Proprietà chiare (chi revisiona cosa) così i contenuti restano aggiornati
Mantieni i template degli articoli coerenti: descrizione del problema, soluzione passo‑passo, screenshot opzionali e “Se non ha funzionato…” che indirizzi al modulo o canale giusto.
Ricerca che trovi davvero risposte
La maggior parte dei fallimenti della KB è fallimento nella ricerca. Implementa la ricerca con:
- Tuning della rilevanza (boost su titolo/intestazioni, boost per freschezza)
- Sinonimi (es. “invoice” ↔ “bill”, “2FA” ↔ “authentication code”)
- Tolleranza a errori e stemming (plurale/singolare)
Indicizza anche gli oggetti dei ticket (anonimizzati) per imparare il linguaggio reale dei clienti e alimentare la lista di sinonimi.
Bozze, revisioni e approvazioni di pubblicazione
Aggiungi un workflow leggero: draft → review → published, con pubblicazione programmata opzionale. Conserva la cronologia delle versioni e includi metadata “ultimo aggiornamento”. Abbina ruoli (autore, revisore, publisher) in modo che non tutti gli agenti possano modificare i contenuti pubblici.
Misura ciò che riduce i ticket
Traccia più delle visualizzazioni. Metriche utili includono:
- Voti utili (sì/no) e feedback “cosa mancava?”
- Segnali di deflessione: ricerca → articolo visualizzato → nessun ticket creato entro X ore
- Ricerche principali senza risultati (gap di contenuto)
Collega articoli ai ticket dove si lavora
Nell'editor di risposta dell'agente, mostra articoli suggeriti in base a oggetto, tag e intento rilevato. Un clic dovrebbe inserire un link pubblico (es. /help/account/reset-password) o uno snippet interno per risposte più rapide.
Ben fatta, la KB diventa la prima linea di supporto: i clienti risolvono da soli e gli agenti gestiscono meno ticket ripetuti con maggiore coerenza.
Imposta ruoli, permessi e tracciabilità
Plan the workflow first
Usa Planning Mode per mappare stati, campi e SLA prima di generare codice.
I permessi sono il punto in cui uno strumento di ticketing resta sicuro e prevedibile — o diventa rapidamente disordinato. Non aspettare il lancio per “bloccare” l'accesso. Modella i permessi presto così i team lavorano veloci senza esporre ticket sensibili o permettere modifiche errate.
Separa i ruoli (e mantienili semplici)
Inizia con pochi ruoli chiari e aggiungi sfumature solo quando serve davvero:
- Agent: gestisce ticket, aggiunge note, risponde, aggiorna campi.
- Lead: tutto ciò che fa un agente, più riassegnazione, gestione code e workflow di coaching.
- Admin: impostazioni di sistema come canali, gestione utenti e configurazioni.
- Content editor: crea e pubblica articoli della knowledge base.
- Read‑only: auditing, finance, legal o stakeholder che hanno bisogno di visibilità senza modifiche.
Definisci permessi per capacità
Evita accessi “tutto o niente”. Tratta le azioni principali come permessi espliciti:
- Visualizzare vs modificare ticket (incluse note private)
- Gestire macro/risposte predefinite
- Modificare regole SLA, timer ed escalation
- Pubblicare/non pubblicare contenuti KB
Questo facilita il principio di minor privilegio e supporta la crescita (nuovi team, regioni, contractor).
Accesso basato su team per code sensibili
Alcune code dovrebbero essere limitate di default—billing, security, VIP o richieste HR. Usa l'appartenenza al team per controllare:
- Quali code sono visibili
- Chi può riassegnare o unire ticket
- Se i campi con dati cliente sono mascherati
Log di audit che userai davvero
Registra azioni chiave con chi, cosa, quando e i valori prima/dopo: cambi di assegnazione, cancellazioni, modifiche SLA/politiche, cambi ruoli e pubblicazione KB. Rendi i log ricercabili ed esportabili così le indagini non richiedono accesso al db.
Pianifica multi‑brand o multi‑inbox fin da subito
Se supporti più brand o inbox, decidi se gli utenti possono cambiare contesto o se l'accesso è partizionato. Questo influenza i controlli di permesso e il reporting e dovrebbe essere coerente dal giorno uno.
Progetta l'esperienza utente per agenti e admin
Un sistema di ticketing vince o perde in base a quanto velocemente gli agenti comprendono la situazione e fanno la prossima azione. Tratta lo spazio agente come la tua “home screen”: deve rispondere subito a tre domande—cosa è successo, chi è questo cliente e cosa devo fare dopo.
Layout dell'area agente
Inizia con una vista divisa che mantiene il contesto mentre si lavora:
- Thread di conversazione (email/chat/messaggi) con timestamp chiari, allegati e citazioni.
- Pannello cliente con identità, piano/tiers, organizzazione, ticket passati e note chiave.
- Campi ticket (stato, priorità, coda, assegnatario, tag, timer SLA) raggruppati logicamente.
Mantieni il thread leggibile: differenzia cliente vs agente vs eventi di sistema e rendi le note interne visivamente distinte per evitare invii accidentali.
Azioni one‑click che riducono l'attrito
Metti le azioni comuni dove il cursore è già—vicino all'ultimo messaggio e in cima al ticket:
- Assegna / riassegna
- Cambia stato (incluso “waiting on customer”)
- Aggiungi nota interna
- Applica macro (risposta precompilata + aggiornamenti campi)
Punta a “un clic + commento opzionale”. Se un'azione richiede una modale, che sia breve e ottimizzata per tastiera.
Funzionalità di velocità per team ad alto volume
Il supporto ad alto throughput richiede scorciatoie prevedibili:
- Shortcut da tastiera per rispondere, aggiungere nota, assegnare a me, chiudere e ticket successivo
- Azioni in blocco nelle liste (tag, assegna, chiudi, unisci)
- Palette di comandi veloce per power user
Accessibilità e sicurezza UI
Costruisci l'accessibilità fin da subito: contrasto sufficiente, stati di focus visibili, navigazione completa da tastiera e label per screen reader su controlli e timer. Previeni errori costosi con piccoli accorgimenti: conferma azioni distruttive, etichetta chiaramente “public reply” vs “internal note” e mostra cosa verrà inviato prima dell'invio.
UX per admin e portale cliente
Gli admin hanno bisogno di schermate semplici e guidate per code, campi, automazioni e template—evita di nascondere elementi essenziali dietro impostazioni annidate.
Se i clienti possono inviare e tracciare i problemi, progetta un portale leggero: crea ticket, vedi lo stato, aggiungi aggiornamenti e visualizza articoli suggeriti prima dell'invio. Mantienilo coerente con il brand pubblico e linkalo da /help.
Pianifica integrazioni, API e intake omnicanale
Start with a solid backend
Avvia Go più PostgreSQL per ticket, eventi e timer SLA con prompt chiari.
Un'app di ticketing diventa utile quando si connette ai luoghi dove i clienti già parlano e agli strumenti che il team usa per risolvere i problemi.
Parti dai sistemi che devi collegare
Elenca le integrazioni “day‑one” e i dati necessari da ciascuna:
- Email (inbox condivise, regole di inoltro, SMTP in uscita)
- Chat (widget sito, WhatsApp, strumenti tipo Intercom)
- CRM (contesto account, owner, tier)
- Billing (stato abbonamento, fatture, rimborsi)
- Identity provider (SSO via Google/Microsoft, provisioning SCIM)
Documenta in che direzione viaggia il dato (read‑only vs write‑back) e chi possiede ogni integrazione internamente.
Progetta API e webhook fin da subito
Anche se rilascerai integrazioni dopo, definisci primitive stabili ora:
- Endpoint API per creare, aggiornare, cercare ticket, più commenti/messaggi e cambi di stato.
- Webhooks per eventi chiave (ticket.created, ticket.updated, message.received, sla.breached) così sistemi esterni possano reagire.
Mantieni l'autenticazione prevedibile (API key per server; OAuth per app installate dagli utenti) e versiona l'API per evitare rotture.
Previeni ticket duplicati con un threading email solido
L'email è dove i casi limite appaiono per primi. Pianifica come:
- Threadare le risposte usando header Message‑ID / In‑Reply‑To / References
- Analizzare messaggi inoltrati e firme comuni in sicurezza
- Deduplicare rilevando payload inbound ripetuti (specialmente dai provider di posta)
Un piccolo investimento qui evita disastri come “ogni risposta crea un nuovo ticket”.
Gestisci gli allegati in sicurezza
Supporta allegati, ma con regole: limiti di tipo/dimensione, storage sicuro e integrazioni per scansione virus. Valuta di rimuovere formati pericolosi e non rendere HTML non affidabile inline.
Documenta la configurazione come una feature di prodotto
Crea una guida di integrazione breve: credenziali richieste, configurazione passo passo, troubleshooting e test. Se mantieni la documentazione, menziona il tuo hub integrazioni su /docs così gli admin non avranno bisogno dell'aiuto degli ingegneri per connettere sistemi.
Aggiungi analytics e reporting per le performance di supporto
L'analytics trasforma il tuo sistema di ticketing da “posto dove lavorare” a “modo per migliorare”. L'obiettivo è catturare gli eventi giusti, calcolare poche metriche coerenti e presentarle a pubblici diversi senza esporre dati sensibili.
Parti da una traccia di eventi (non solo dallo stato corrente)
Conserva i momenti che spiegano perché un ticket è come è. Al minimo, traccia: cambi di stato, risposte cliente e agente, assegnazioni e riassegnazioni, aggiornamenti priorità/categoria e eventi timer SLA (start/stop, pause, breach). Questo ti permette di rispondere a domande tipo “Abbiamo infranto l'SLA perché eravamo sotto staffati o perché abbiamo atteso il cliente?”.
Mantieni gli eventi append‑only dove possibile; rende audit e reporting più affidabili.
Dashboard per i team lead
I lead hanno bisogno di viste operative su cui agire oggi:
- Backlog per coda, priorità e categoria
- Ticket in aging (es. più vecchi aperti, più vecchi in attesa cliente)
- Rischio SLA (ticket che probabilmente violeranno entro X ore)
- Carico agente (conteggio assegnati, lavoro attivo, tempo dall'ultimo aggiornamento)
Rendi le dashboard filtrabili per intervallo, canale e team—senza costringere i manager in fogli di calcolo.
Report per gli executive
Gli executive si interessano meno dei singoli ticket e più delle tendenze:
- Volume per categoria/canale, incluse ore e giorni di picco
- Trend di prima risposta e risoluzione (mediana e 90° percentile)
- Trend CSAT (e tasso di risposta, per non fuorviare i punteggi)
Se colleghi i risultati alle categorie, puoi giustificare staffing, formazione o cambi prodotto.
Filtri, export e controlli d'accesso
Aggiungi esportazione CSV per viste comuni, ma proteggila con permessi (e idealmente controlli a livello di campo) per evitare fughe di email, contenuti di messaggi o identificatori cliente. Registra chi ha esportato cosa e quando.
Conservazione dei dati senza promesse rischiose
Definisci per quanto tempo conservi eventi ticket, contenuti messaggi, allegati e aggregati analitici. Preferisci impostazioni configurabili di retention e documenta cosa cancelli davvero vs anonimizzato così non fai promesse non verificabili.
Scegli un'architettura e uno stack pratici
Un prodotto di ticketing non ha bisogno di un'architettura complessa per essere efficace. Per la maggior parte dei team, una soluzione semplice è più veloce da rilasciare, più facile da mantenere e scala bene.
Parti da un diagramma di sistema semplice
Un baseline pratico somiglia a questo:
- Frontend web: UI agente/admin e form/portale lato cliente
- API backend: regole di business per ticket, SLA, utenti e KB
- Database: fonte di verità per ticket, utenti, eventi e impostazioni
- Job in background: task time‑based o di lunga durata
Questo approccio “modular monolith” (un backend con moduli chiari) mantiene la v1 gestibile lasciando spazio a separare servizi in seguito.
Se vuoi accelerare una v1 senza reinventare la pipeline di delivery, una piattaforma vibe‑coding come Koder.ai può aiutarti a prototipare la dashboard agente, il ciclo di vita ticket e le schermate admin via chat—poi esportare il codice sorgente quando sei pronto.
Sappi cosa deve girare in background
I sistemi di ticketing sembrano in tempo reale, ma molto lavoro è asincrono. Pianifica job in background per:
- Timer SLA ed escalation (es. “prima risposta entro 30 minuti”)
- Notifiche (email, in‑app, webhook)
- Indicizzazione ricerca (ticket e articoli KB)
- Elaborazione email in entrata (parsing, allegati, threading)
Se il background è un ripensamento, gli SLA diventano inaffidabili e gli agenti perdono fiducia.
Conserva i dati per correttezza, cerca per velocità
Usa un database relazionale (PostgreSQL/MySQL) per record core: ticket, commenti, stati, assegnazioni, politiche SLA e tabella eventi/audit.
Per ricerche veloci e rilevanti, mantieni un indice di ricerca separato (Elasticsearch/OpenSearch o equivalente gestito). Non cercare di far fare full‑text search scalabile al DB relazionale se il prodotto dipende da essa.
Decidi build vs buy (e perché)
Tre aree spesso risparmiano mesi se acquistate:
- Autenticazione: usa un provider affidabile (SSO, MFA, policy password)
- Invio email: servizio email transazionale per deliverability e bounce handling
- Ricerca: search gestita se non hai expertise in‑house
Costruisci ciò che ti differenzia: regole di workflow, comportamento SLA, logica di routing e l'esperienza agente.
Pianifica milestone con una lista v1 chiara
Stima lo sforzo per milestone, non per singole feature. Una solida lista v1 è: CRUD ticket + commenti, assegnazione base, timer SLA (core), notifiche email, reporting minimo. Mantieni i “nice‑to‑have” (automazioni avanzate, ruoli complessi, analytics profondi) fuori dall'ambito finché l'uso della v1 non dimostra cosa conta.
Copri basi di sicurezza, privacy e affidabilità
Ship a KB that deflects
Costruisci struttura e flussi di ricerca per la knowledge base, poi iterali in base alle query reali.
Decisioni di sicurezza e affidabilità sono più facili (e meno costose) se considerate presto. Un'app di supporto tratta conversazioni sensibili, allegati e dettagli account—trattala come un sistema core, non un tool secondario.
Proteggi i dati cliente per impostazione predefinita
Parti con crittografia in transito ovunque (HTTPS/TLS), incluse chiamate interne servizio‑a‑servizio se hai più servizi. Per i dati at rest, cifra i database e l'object storage (allegati) e conserva i segreti in un vault gestito.
Usa il principio del minor privilegio: gli agenti vedono solo i ticket che possono gestire, e gli admin elevano i diritti solo quando necessario. Aggiungi logging di accesso così puoi rispondere “chi ha visto/esportato cosa e quando?” senza incertezze.
Scegli l'autenticazione in base al tuo pubblico
L'autenticazione non è unica per tutti. Per team piccoli email + password può bastare. Se vendi a organizzazioni più grandi, l'SSO (SAML/OIDC) può essere requisito. Per portali clienti leggeri, una magic link riduce l'attrito.
Qualunque sia la scelta, assicurati sessioni sicure (token a breve durata, refresh, cookie sicuri) e aggiungi MFA per account admin.
Previeni attacchi comuni prima che inizino
Metti rate limiting su login, creazione ticket e endpoint di ricerca per rallentare brute‑force e spam. Valida e sanitizza gli input per prevenire injection e HTML non sicuro nei commenti.
Se usi cookie, aggiungi protezione CSRF. Per le API, applica regole CORS stringenti. Per gli upload, scansiona malware e limita tipi/dimensioni.
Backup, recovery e obiettivi misurabili
Definisci RPO/RTO (quanto dato puoi perdere, quanto velocemente devi tornare online). Automatizza backup per database e storage file e—soprattutto—testa i restore su base programmata. Un backup che non puoi ripristinare non è backup.
Basi di privacy che gli utenti chiederanno
Le app di supporto sono spesso soggette a richieste di privacy. Fornisci un modo per esportare e cancellare i dati cliente e documenta cosa viene rimosso rispetto a cosa resta per motivi legali/audit. Mantieni audit trail e log di accesso disponibili per gli admin (vedi /security) per indagare rapidamente incidenti.
Testa, lancia e migliora con team di supporto reali
Rilasciare un'app di supporto non è il traguardo—è l'inizio dell'apprendimento su come gli agenti lavorano sotto pressione reale. L'obiettivo di test e rollout è proteggere l'operatività quotidiana mentre validi che il sistema di ticketing e la gestione SLA funzionino correttamente.
Scrivi scenari end‑to‑end che rispecchino il lavoro reale
Oltre ai test unitari, documenta (e automatizza quando possibile) alcuni scenari end‑to‑end a rischio più alto:
- Creazione ticket: intake via email/web form/API crea il ticket con i campi giusti, identità cliente e stato iniziale.
- Risposte e threading: le risposte cliente si agganciano al ticket corretto, le risposte agente notificano il cliente, le note interne rimangono interne.
- Violation SLA: i timer partono/si fermano correttamente (es. pausa su “Waiting on customer”), le violazioni scatenano le escalation giuste e l'audit registra cosa è successo.
- Ricerca KB: gli agenti trovano articoli rilevanti dalla vista ticket e i clienti vedono suggerimenti utili prima dell'invio.
Se hai uno staging, popola dati realistici (clienti, tag, code, orari di lavoro) così i test non passino solo “in teoria”.
Esegui un pilota e raccogli feedback settimanale
Parti con un piccolo gruppo di supporto (o una singola coda) per 2–4 settimane. Stabilite una ritualità settimanale di feedback: 30 minuti per rivedere cosa ha rallentato, cosa ha confuso i clienti e quali regole hanno creato sorprese.
Mantieni il feedback strutturato: “Quale attività?”, “Cosa ti aspettavi?”, “Cosa è successo?” e “Quanto spesso succede?”. Aiuta a prioritizzare correzioni che impattano throughput e rispetto SLA.
Crea una checklist di onboarding per admin e agenti
Rendi l'onboarding ripetibile così il rollout non dipenda da una sola persona.
Includi essenziali come: login, viste coda, rispondere vs nota interna, assegnare/menzionare, cambiare stato, usare macro, leggere indicatori SLA e trovare/creare articoli KB. Per gli admin: gestione ruoli, orari lavorativi, tag, automazioni e reporting base.
Pianifica un rollout graduale (con opzione di rollback)
Rilascia per team, canale o tipo di ticket. Definisci una strada di rollback in anticipo: come torni temporaneamente alla vecchia intake, quali dati necessitano resync e chi prende la decisione.
I team che costruiscono su Koder.ai spesso usano snapshot e rollback durante i piloti per iterare su workflow (code, SLA e form portale) senza interrompere l'operatività.
Definisci una roadmap di iterazione
Quando il pilota si stabilizza, pianifica miglioramenti a onde:
- Migliori regole di automazione (macro, trigger, auto‑tagging)
- Routing avanzato (assignment per competenze, bilanciamento carico)
- Workflow KB più ricchi (revisioni articoli, feedback, metriche di deflessione)
Tratta ogni onda come un piccolo rilascio: testa, pilota, misura, poi espandi.