Definisci gli obiettivi e gli utenti
Prima di schizzare schermate o scegliere uno stack tecnico, decidi cosa significa successo per la tua app di tracciamento logistico. “Tracciare” può voler dire molte cose, e obiettivi vaghi portano spesso a un prodotto confuso che nessuno ama.
Parti da un obiettivo di business chiaro
Scegli un obiettivo primario e un paio di obiettivi di supporto. Esempi:
- Meno consegne in ritardo (e meno penali)
- Meno chiamate in entrata “Dov’è il mio autista?”
- Maggiore visibilità per il dispatch quando capitano eccezioni (traffico, ritardi, stop falliti)
Un buon obiettivo è abbastanza specifico da guidare le decisioni. Per esempio, “ridurre le consegne in ritardo” ti spingerà verso ETA accurate e gestione delle eccezioni—non solo una mappa più bella.
Definisci gli utenti (e cosa serve a ciascuno)
La maggior parte dei software di tracking ha più audience. Definisci i ruoli presto così non costruirai tutto per un unico ruolo.
- Dispatcher: ha bisogno di una dashboard live, riassegnazioni rapide e fiducia su cosa succede in questo momento.
- Autista: ha bisogno di un flusso semplice (inizia percorso → arriva → completa stop), digitazione minima e navigazione affidabile.
- Manager/Responsabile operativo: ha bisogno di report sulle prestazioni, trend nel tempo e responsabilità tracciabili.
- Supporto clienti: ha bisogno di risposte rapide: ultimo stato noto, ultimo aggiornamento dell’autista e prossimo passo previsto.
Scegli 3 risultati misurabili
Limitali a tre per mantenere l’MVP focalizzato. Metriche comuni:
- Tasso di consegne puntuali (es. migliorare dal 92% al 96%)
- Stop falliti / tasso di ri-tentativi (indirizzo sbagliato, cliente assente)
- Tempo di inattività (stop non pianificati, tempo tra consegne)
Chiarisci cosa significa “tracciare” per il tuo team
Annota i segnali esatti che il sistema catturerà:
- Tracciamento posizione: ultimo punto GPS noto, frequenza di aggiornamento e regole su quando la posizione è “stale”
- Aggiornamenti di stato: planned → assigned → en route → arrived → delivered/failed
- Proof of delivery: foto, firma, nome, timestamp e note opzionali
Questa definizione diventa il contratto condiviso per le decisioni di prodotto e le aspettative del team.
Mappa il workflow di consegna e gli stati
Prima di progettare schermate o scegliere strumenti, concorda una sola “verità” su come una consegna attraversa l’operazione. Un workflow chiaro evita confusione del tipo “Questo stop è ancora aperto?” o “Perché non posso riassegnare questo lavoro?”—e rende i report più affidabili.
Il flusso core della consegna (end-to-end)
La maggior parte dei team logistici può allinearsi su una backbone semplice:
Create jobs → assign driver → navigate → deliver → close out.
Anche se il tuo business ha casi speciali (reship, percorsi multi-drop, pagamento alla consegna), mantieni la backbone consistente e aggiungi variazioni come eccezioni piuttosto che inventare un nuovo flusso per ogni cliente.
Stati che tutti usano allo stesso modo
Definisci stati in linguaggio semplice e rendili mutuamente esclusivi. Un set pratico è:
- Planned: il job esiste, non ancora assegnato a un autista
- Assigned: l’autista è responsabile ma non si è ancora mosso
- En route: l’autista è in viaggio verso lo stop successivo
- Arrived: l’autista ha raggiunto la posizione dello stop
- Delivered: completato con successo con proof
- Failed: tentato ma non completato (con motivo)
Concorda cosa causa ogni cambio di stato. Per esempio, “En route” potrebbe essere automatico quando l’autista preme “Start navigation”, mentre “Delivered” dovrebbe essere sempre esplicito.
Azioni di autista e dispatcher (e chi può fare cosa)
Azioni autista da supportare:
- Inizia turno, accetta job
- Scannerizza/conferma articoli, raccoglie firma/foto
- Segna come delivered o failed con motivo
Azioni dispatcher da supportare:
- Riassegna un job, modifica gli stop
- Contatta l’autista (scorciatoie chiamata/messaggio)
- Marca eccezioni (es. cliente chiuso, problema indirizzo)
Per ridurre le dispute, registra ogni modifica con chi, quando e perché (specialmente per Failed e riassegnazioni).
Progetta il modello dati (Deliveries, Drivers, Routes)
Un modello dati chiaro è quello che trasforma una “mappa con punti” in un software di tracking affidabile. Se definisci bene gli oggetti core, la dashboard di dispatch è più facile da costruire, i report sono accurati e l’operazioni non dipendono da soluzioni provvisorie.
Deliveries (il “job”)
Modella ogni delivery come un job che attraversa stati (planned, assigned, en route, delivered, failed, ecc.). Includi campi che supportano decisioni reali di dispatch, non solo indirizzi:
- Indirizzo di ritiro e consegna (salva i campi normalizzati oltre al testo originale)
- Finestra temporale (earliest/latest) per ogni stop
- Nome contatto + telefono, più istruzioni/note di consegna
- COD (cash on delivery) e regole sul metodo di pagamento
- Priorità (normale/urgente) e tipo di servizio (same-day, standard)
Suggerimento: tratta pickup e drop-off come “stop” così un job può espandersi in multi-stop senza riprogettare.
Autisti (e veicoli)
Gli autisti sono più di un nome su un percorso. Cattura vincoli operativi così l’ottimizzazione dei percorsi e il dispatch rimangono realistici:
- Nome, telefono e disponibilità/orari di turno
- Tipo di veicolo, targa e capacità (peso/volume)
- Certificazioni (hazmat, refrigerato, sponda) quando rilevanti
Routes (il piano)
Un percorso dovrebbe conservare l’elenco ordinato degli stop, più ciò che il sistema si aspettava rispetto a ciò che è avvenuto:
- Stop ordinati con ETA pianificate e tempi di servizio
- Distanza totale e durata pianificata
- Vincoli (tipo veicolo, ore massime, zone restrittive)
Eventi / audit log (la verità)
Aggiungi un log eventi immutabile: chi ha cambiato cosa e quando (aggiornamenti di stato, modifiche, riassegnazioni). Questo supporta dispute con i clienti, compliance e l’analisi del perché qualcosa è stato in ritardo—soprattutto se unito a proof of delivery ed eccezioni.
Pianifica le schermate chiave e l’esperienza utente
Un buon software di tracking è soprattutto un problema di UX: l’informazione giusta, al momento giusto, con il minimo numero di click. Prima di costruire funzionalità, abbozza le schermate core e decidi cosa ogni utente deve poter fare in meno di 10 secondi.
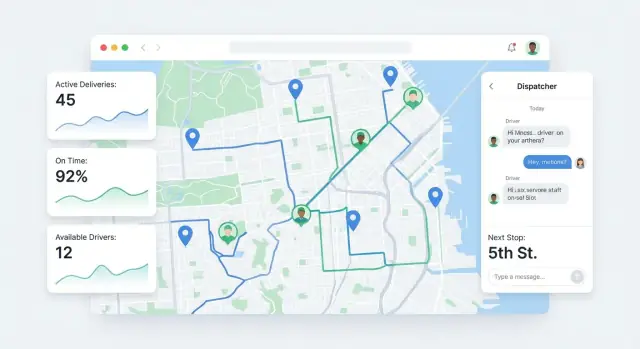
Dispatcher dashboard (centro di controllo)
Qui si assegnano i lavori e si gestiscono i problemi. Rendila “glanceable” e orientata all’azione:
- Job del giorno con filtri (unassigned, in progress, late, failed)
- Pannello eccezioni (no risposta, problema indirizzo, cliente non a casa, pacco danneggiato)
- Indicatore rischio ritardo (basato su programma vs progresso attuale)
- Assegna/riassegna con un click, più azioni bulk per cambi last-minute
Mantieni la vista lista veloce, ricercabile e ottimizzata per uso da tastiera.
Vista mappa (consapevolezza situazionale)
I dispatcher hanno bisogno di una mappa che spieghi la giornata, non solo punti su una mappa.
Mostra posizioni driver live, pin stop e stati colorati (Planned, En route, Arrived, Delivered, Failed). Aggiungi toggle semplici: “mostra solo late risk”, “mostra solo non assegnati”, e “segui autista”. Cliccare un pin dovrebbe aprire una scheda stop compatta con ETA, note e azioni successive.
Vista autista (fai la cosa giusta dopo l’altra)
La schermata autista deve concentrarsi sul prossimo stop, non sull’intero piano.
Includi: indirizzo prossimo stop, istruzioni (codice cancello, note di consegna), pulsanti di contatto (chiama/invia SMS a dispatcher o cliente) e un aggiornamento di stato rapido con digitazione minima. Se supporti proof of delivery, mantienila nello stesso flusso (foto/firma + nota breve).
Report manager (migliora l’operazione)
I manager hanno bisogno di trend, non di eventi grezzi: puntualità, tempo di consegna per zona e principali motivi di fallimento. Rendi i report facili da esportare e confrontare settimana su settimana.
Suggerimento di design: definisci un vocabolario di stati e un sistema di colori coerente su tutte le schermate—riduce il tempo di training e evita incomprensioni costose.
Costruisci mappe, geocoding e pianificazione percorsi
Le mappe sono dove la tua app trasforma “una lista di stop” in qualcosa su cui dispatcher e autisti possono agire. L’obiettivo non è cartografia sofisticata, ma meno errori di percorso, ETA più chiare e decisioni più veloci.
Scegli i blocchi costitutivi della mappa
La maggior parte delle app logistiche ha bisogno dello stesso set di funzionalità mappa:
- Geocoding: convertire indirizzi in coordinate per routing e pin sulla mappa.
- Distance matrix: tempi e distanze tra molti stop (critico per pianificazione ed ETA).
- Route drawing: mostrare chiaramente il percorso scelto e la sequenza di stop.
- ETA: mostrare orari di arrivo previsti per ogni stop e per l’intero percorso.
Decidi presto se affidarti a un singolo provider (più semplice) o astrarre i provider dietro un servizio interno (più lavoro ora, più flessibilità dopo).
Non ignorare la qualità degli indirizzi
Gli indirizzi errati sono una delle principali cause di consegne fallite. Costruisci guardrail:
- Validazione e suggerimenti mentre l’utente digita (autocomplete, formattazione standard)
- Indicatori di confidenza (es. “match a livello di strada” vs “match a livello di città”)
- Posizionamento manuale della puntina sulla mappa quando l’indirizzo è incompleto (nuovi edifici, aree rurali, magazzini con cancelli interni)
Salva il testo indirizzo originale e le coordinate risolte separatamente così puoi auditare e correggere problemi ricorrenti.
Pianificazione percorsi: manuale vs ottimizzazione semplice
Inizia con ordinamento manuale (drag-and-drop degli stop) più helper pratici: “raggruppa stop vicini”, “sposta stop falliti alla fine” o “prioritizza stop urgenti”. Poi aggiungi regole di ottimizzazione base (next-nearest, minimizza tempo di guida, evita backtracking) man mano che impari il comportamento reale del dispatch.
Supporta vincoli del mondo reale
Anche un MVP di pianificazione dovrebbe capire vincoli come:
- Finestre temporali (orari di apertura cliente, appuntamenti)
- Capacità (dimensioni veicolo, numero di pacchi)
- Strade ristrette (limiti per camion, evitamento pedaggi)
- Multi-depot (start/end da hub diversi)
Se documenti questi vincoli chiaramente nell’UI, i dispatcher si fideranno del piano—e sapranno quando sovrascriverlo.
Implementa il tracciamento posizione autisti in tempo reale
Itera senza paura
Usa snapshot e rollback per testare modifiche in sicurezza quando le regole di dispatch evolvono.
Il tracciamento in tempo reale è utile solo se è affidabile, comprensibile e rispettoso della batteria. Prima di scrivere codice, decidi cosa significa “reale” per la tua operazione: i dispatcher hanno bisogno di movimento secondo-per-secondo, o è sufficiente ogni 30–60 secondi per rispondere ai clienti e reagire ai ritardi?
Scegli una frequenza di aggiornamento (e proteggi la batteria)
Frequenze più alte rendono il movimento più fluido sulla dashboard, ma consumano batteria e dati.
Un punto di partenza pratico:
- Durante consegna attiva: ogni 10–30 secondi (o ogni 50–100 metri)
- Tra gli stop / inattivo: ogni 60–180 secondi
- App in background: aggiornamenti più lenti a meno che non serva
Puoi anche triggerare aggiornamenti su eventi significativi (arrivato allo stop, partito) invece di ping costanti.
Aggiornamenti live vs refresh periodico
Per la vista dispatcher hai due pattern comuni:
- Live updates (WebSockets): le posizioni appaiono immediatamente, ottimo per dashboard affollate.
- Refresh periodico (polling): il browser aggiorna le posizioni ogni X secondi, più semplice da costruire e spesso “sufficientemente buono”.
Molti team partono con polling e aggiungono WebSockets quando il volume cresce.
Conserva la cronologia delle posizioni (non solo il punto)
Non salvare solo la coordinata più recente. Conserva track points (timestamp + lat/long + velocità/accuratezza opzionale) così puoi:
- mostrare una breadcrumb per una finestra di consegna
- investigare dispute (“Dov’era l’autista alle 15:12?”)
- mostrare una ultima posizione nota chiara quando l’autista è offline
Gestisci l’offline con grazia
Le reti cadono. L’app driver deve accodare eventi di posizione localmente quando il segnale è assente e sincronizzare automaticamente al ritorno. In dashboard, marca l’autista come “Ultimo aggiornamento: 7 min fa” invece di fingere che il punto sia corrente.
Ben fatto, il tracciamento GPS in tempo reale costruisce fiducia: il dispatch vede cosa succede e gli autisti non vengono penalizzati per connettività inaffidabile.
Aggiungi notifiche, eccezioni e proof of delivery
Notifiche e gestione delle eccezioni trasformano un’app base in un sistema di tracking su cui contare. Aiutano il team ad agire presto e diminuiscono le chiamate dei clienti.
Notifiche che aiutano (non spam)
Inizia con un set ristretto di eventi rilevanti: dispatched, arriving soon, delivered e failed delivery. Lascia scegliere il canale—push, SMS o email—e chi riceve cosa (solo dispatcher, solo cliente o entrambi).
Una regola pratica: invia messaggi al cliente solo quando qualcosa cambia e tieni i messaggi operativi più dettagliati (motivo stop, tentativi di contatto, note).
Allarmi per eccezioni e segnali di “rischio ritardo”
Le eccezioni devono essere innescate da condizioni chiare, non da sensazioni. Comuni nel last-mile:
- Late risk: l’ETA devia oltre la finestra promessa.
- Missed time window: la consegna non è completata nella fascia concordata.
- Autista fermo troppo a lungo: posizione immutata oltre una soglia (es. 15–30 minuti) fuori da stop noti.
Quando scatta un’eccezione, mostra un passo suggerito in dashboard: “chiama destinatario”, “riassegna” o “segna come ritardato”. Questo mantiene decisioni coerenti.
Proof of Delivery (POD) affidabile
La POD deve essere semplice per gli autisti e verificabile in caso di dispute. Opzioni tipiche:
- Firma (dito/stilo) con nome del destinatario
- Foto (pacco davanti alla porta / area di ricezione)
- Scan barcode/QR per confermare il pacco corretto
- Timestamp + coordinate GPS catturate automaticamente
Conserva la POD nel record di consegna e rendila scaricabile per il supporto clienti.
Template, quiet hours e configurazione
Clienti diversi vogliono wording diversi. Aggiungi template di messaggi e impostazioni per cliente (finestre temporali, regole di escalation e quiet hours). Questo rende l’app adattabile senza modifiche al codice man mano che il volume cresce.
Gestisci account, ruoli e permessi
Consegna una dashboard per dispatcher velocemente
Genera una dashboard React con backend in Go e PostgreSQL in pochi minuti, poi iterare rapidamente.
Accessi e controllo sono facili da dimenticare fino alla prima disputa, al primo nuovo deposito o alla prima richiesta “Chi ha cambiato questa consegna?”. Un modello di permessi chiaro previene modifiche accidentali, protegge dati sensibili e rende il team più veloce.
Basi di autenticazione (e cosa aggiungere dopo)
Inizia con email/password semplice, ma pronta per l’uso in produzione:
- Verifica email per nuovi utenti
- Password reset con scadenza rapida (es. 15–60 minuti)
- 2FA opzionale per admin e dispatcher
Se i tuoi clienti usano identity provider (Google Workspace, Microsoft Entra ID/AD), prevedi SSO come percorso di upgrade. Anche se non lo costruisci nell’MVP, progetta i record utente per poter collegare un’identità SSO senza duplicare account.
Ruoli: pochi ma significativi
Evita decine di micro-permessi all’inizio. Definisci un set ridotto di ruoli che rispecchino i lavori reali, poi raffina.
Ruoli comuni:
- Dispatcher: crea/modifica job, assegna autisti, aggiusta ETA
- Driver: vede stop assegnati, aggiorna stati, cattura POD
- Operations manager: dashboard prestazioni, esportazioni
- Admin: gestisce utenti, depositi, integrazioni e impostazioni di sicurezza
Poi decidi chi può compiere azioni sensibili:
- Modificare o cancellare job dopo “En route” (o dopo “Out for delivery” se usi quella label)
- Vedere prezzi/costi e campi margine
- Esportare dati (CSV/PDF) e accedere a report storici
Visibilità multi-branch (deposito/team)
Se hai più depositi, vuoi una separazione tipo tenant presto:
- Utenti appartengono a un branch/depot (o a più)
- Deliveries e drivers sono scorporati per branch
- Accesso cross-branch concesso solo a manager regionali/admin
Questo mantiene i team focalizzati e riduce modifiche accidentali a lavori di altri depositi.
Auditabilità: registro eventi immutabile
Per dispute, chargeback e “perché è stato deviato?” costruisci un event log append-only per azioni chiave:
- Cambi di stato (chi, quando, dove)
- Riassegnazioni driver
- Modifiche indirizzo e finestre temporali
- Upload POD e firme
Rendi le voci di audit immutabili e interrogabili per delivery ID e utente. Mostrare anche una timeline “Attività” leggibile sul dettaglio consegna aiuta ops a risolvere problemi senza scavare i dati grezzi.
Pianifica integrazioni e API
Le integrazioni trasformano uno strumento di tracking in un hub operativo. Prima di scrivere codice, elenca i sistemi che usi e decidi quale è la “fonte di verità” per ordini, dati cliente e fatturazione.
Connetti i sistemi che già usi
La maggior parte dei team tocca più piattaforme: OMS, WMS, TMS, CRM e contabilità. Decidi cosa importi (ordini, indirizzi, finestre, conteggi articoli) e cosa esporti (aggiornamenti stato, POD, eccezioni, addebiti).
Una regola semplice: evita la doppia immissione. Se i dispatcher creano job nell’OMS, non costringerli a ricreare le consegne nella tua app.
Progetta un’API che rispecchi i workflow reali
Mantieni l’API centrata sugli oggetti che il team conosce:
- Jobs/Deliveries: create, assign, update status, attach POD
- Drivers/Vehicles: disponibilità, assegnazioni, identificatori device
- Tracking events: ping, arrivi stop, eccezioni, timestamp
REST funziona bene nella maggior parte dei casi, e webhooks gestiscono aggiornamenti realtime verso sistemi esterni (es. “delivered”, “failed delivery”, “ETA changed”). Rendi l’idempotenza obbligatoria per aggiornamenti di stato così i retry non duplicano eventi.
Pianifica import/export e sync
Anche con API, i team operativi chiederanno CSV:
- Import massivo di deliveries per una giornata
- Export di link POD e timestamp per il customer service
Aggiungi sync schedulati (orari/notturni) dove serve, più report chiari sugli errori: cosa è fallito, perché e come risolverlo.
Non dimenticare le integrazioni hardware
Se il tuo flusso usa scanner barcode o stampanti etichette, definisci come interagiscono con l’app (scan per confermare stop, scan per verificare pacco, stampa in deposito). Parti con un set piccolo supportato, documentalo ed espandi dopo l’MVP.
Sicurezza, privacy e retention dei dati
Tracciare consegne e autisti significa gestire dati operativi sensibili: indirizzi cliente, numeri di telefono, firme e GPS in tempo reale. Alcune decisioni iniziali possono prevenire incidenti costosi.
Proteggi i dati sensibili (ovunque)
Al minimo, cripta i dati in transito con HTTPS/TLS. Per i dati a riposo, abilita la crittografia dove il provider di hosting lo supporta (database, object storage per foto, backup). Conserva chiavi API e token in un secrets manager sicuro—non nel codice sorgente o in fogli condivisi.
Privacy delle posizioni in base al lavoro
Il GPS è potente, ma non dovrebbe essere più dettagliato del necessario. Molti team hanno bisogno solo di:
- posizione approssimativa per il dispatch (es. “vicino a questa zona”)
- posizione precisa solo per stop attivi o eccezioni
Definisci periodi di retention chiari. Per esempio: conserva ping ad alta frequenza per 7–30 giorni, poi downsample (punti orari/giornalieri) per reportistica storica.
Salvaguardie operative: rate limit, log e recovery
Aggiungi rate limiting su login, tracking e link pubblici di POD per ridurre abusi. Centralizza i log (eventi app, azioni admin e richieste API) così puoi rispondere rapidamente a “chi ha cambiato questo stato?”.
Pianifica anche backup e restore dal primo giorno: backup giornalieri automatizzati, procedure di restore testate e una checklist di incident response pronta all’uso.
Compliance base e politiche chiare
Raccogli solo ciò che serve e documenta perché. Fornisci consenso e avviso per il tracciamento autisti e definisci come gestisci richieste di accesso o cancellazione dati. Una policy breve e in linguaggio semplice—condivisa internamente e con i clienti—allinea le aspettative e riduce sorprese.
Test, pilot e adozione del team
Pianifica l'app prima di codificare
Usa la Modalità Pianificazione per mappare utenti, schermate chiave e oggetti dati prima di scrivere codice.
Un’app di tracking ha successo o fallisce nella vita reale: indirizzi sporchi, autisti in ritardo, connettività scadente e dispatcher sotto pressione. Un piano di test solido, un pilot controllato e training pratici trasformano “software funzionante” in “software che la gente usa davvero”.
Testa gli scenari che rompono le consegne
Vai oltre i test felici e ricrea il caos quotidiano:
- Edge routing: più stop con stesso nome di via, comunità gated, strade ristrette, drop duplicati e errori “consegna prima del ritiro”.
- Indirizzi cattivi: CAP mancanti, città sbagliata, indirizzi solo interno appartamento, puntina lontana dall’ingresso reale.
- Aggiornamenti offline: autista marca uno stop completato senza segnale, poi si riconnette—assicurati che l’app si sincronizzi e non duplichi.
- Finestre temporali: arrivi anticipati, ritardi e finestre sovrapposte—assicurati che il dispatch veda i conflitti.
Includi flussi web (dispatch) e mobile (driver), più flussi di eccezione come delivery failed, return-to-depot o cliente non a casa.
Tracciamento e mappe possono sembrare lenti prima di cadere. Testa:
- Rendering mappa con molti stop e percorsi in schermo
- Liste grandi (centinaia o migliaia di deliveries)
- Ore di punta tracking quando molti driver aggiornano contemporaneamente
Misura i tempi di caricamento e reattività, poi fissa obiettivi di performance da monitorare.
Pilot con criteri di successo chiari
Parti con un deposito o una regione, non con tutta l’azienda. Definisci criteri di successo (es. % di deliveries con POD, meno chiamate “dov’è l’autista?”, miglior tasso di puntualità). Raccogli feedback settimanale, risolvi problemi velocemente e poi scala.
Training che entra nella giornata lavorativa
Crea una guida quick-start, aggiungi tip in-app per i primi usi e stabilisci un processo di supporto chiaro: chi contatta l’autista on the road e come il dispatch segnala bug. L’adozione migliora quando le persone sanno esattamente cosa fare quando qualcosa va storto.
Scope MVP, stack tecnologico e pianificazione costi
Se stai costruendo un’app logistica per la prima volta, il modo più veloce per spedire è definire un MVP ristretto che dimostri valore per dispatch e autisti, poi aggiungere automazione e analytics una volta stabilizzato il workflow.
Scope MVP: must-have vs nice-to-have
Must-have per la prima release solitamente includono: una dashboard dispatch per creare deliveries e assegnare autisti, una vista mobile semplice per autisti per vedere la lista stop, aggiornamenti di stato base (es. Picked up, Arrived, Delivered) e una vista mappa per la visibilità dei percorsi.
Nice-to-have che spesso rallentano: regole complesse di ottimizzazione percorsi, pianificazione multi-depot, ETA cliente automatiche, report custom e integrazioni estese. Tieni fuori questi dall’MVP a meno che non guidino già il fatturato.
Scelte tecnologiche tipiche
Uno stack pratico per sviluppo di app logistica:
- Frontend web: React, Vue o Angular per la dashboard dispatch
- Backend API: Node.js/TypeScript, Python (Django/FastAPI) o Java/.NET per CRUD stabile + auth
- Database: PostgreSQL per entità core; Redis per caching e sessioni realtime
- Realtime: WebSockets (o pub/sub gestito) per aggiornamenti tracciamento
- Maps/geocoding: Google Maps, Mapbox o HERE (costi e copertura variano)
Un percorso più veloce per l’MVP (se vuoi validare in fretta)
Se la tua sfida principale è la velocità alla prima versione, un approccio “vibe-coding” può aiutare a validare il workflow prima di investire in build custom. Con Koder.ai, i team possono descrivere la dashboard dispatcher, il flusso autista, gli stati e il modello dati in chat, poi generare un’app funzionante (React) con backend Go + PostgreSQL.
Questo è utile per piloti:
- CRUD base per deliveries/drivers/routes
- Accesso basato sui ruoli (dispatcher/driver/manager)
- Timeline attività / fondazione audit log
- Snapshot e rollback mentre il team itera rapidamente
Quando l’MVP dimostra valore, puoi esportare il codice sorgente e proseguire con una pipeline tradizionale, o continuare a deployare tramite la piattaforma.
Cosa incide sui costi (e sorprende il budget)
I maggiori driver di costo sono spesso legati all’uso:
- Map tiles, geocoding e routing per richiesta
- SMS/WhatsApp per messaggio
- Storage foto per POD (e banda)
- Infrastruttura tracking realtime (frequenza aggiornamenti + concorrenza)
Se ti serve aiuto per stimare questi costi, vale la pena richiedere un preventivo rapido su /pricing o discutere il tuo flusso su /contact.
Funzionalità successive da pianificare (ma non buildare subito)
Una volta stabile l’MVP, upgrade comuni sono: link di tracking per i clienti, ottimizzazione percorsi più forte, analytics di consegna (on-time %, dwell time) e report SLA per account chiave.